用于促进酶去除的his
‑
mbp标记的dna内切酶
1.序列表
2.本技术包含以ascii格式提交并通过引用整体并入本文的序列表。该ascii副本创建于2020年9月21日,命名为abcl
‑
hindiii_sl.txt,并且大小为9421字节。
背景技术:
3.dna核酸内切酶消化dna,并且限制性核酸内切酶消化特定序列的dna。如果要在内切酶消化后进行与dna寡聚体的反应,则必须首先从反应体系中去除内切酶;所以产品不会继续被消化。dna底物可以通过与固体支持物结合来纯化,这可以使用纯化柱或通过将dna与珠子结合来实现:然后该珠子与dna一起去除。特别地,磁珠可以通过将它们吸附到支持物上,然后支持物与珠子和结合的dna一起去除、或磁性吸附磁珠到孔或管的侧面或底部来促进纯化。
4.目前,热不稳定内切酶通常用于消化,在使用后,它们被热灭活以阻止进一步的消化。加热会影响反应中的其他试剂,甚至可能导致低聚体在某种程度上去退火。显然,需要用替代的方法来灭活酶。
技术实现要素:
5.本发明描述了将n
‑
末端组胺
‑
麦芽糖结合蛋白(“mbp”)标签添加到核酸内切酶上以形成融合蛋白。核酸内切酶优选为hind iii,为一种限制性核酸内切酶。一旦酶在溶液中消化了dna寡聚体,融合蛋白就结合到固体支持物、优选为磁珠上,以阻止进一步的消化。用于结合标记酶的优选珠子是磁珠,其可以通过与支持物结合而容易地从溶液中移除,或可以被吸附在反应混合物的一个区域(如孔或管的底部或侧面)中积累。一种适合的磁珠是结合亚氨基二乙酸(ida)或次氮基三乙酸的镍珠;两者都与mbp标签的组胺部分结合。
6.本发明包括与seq id no:1至少有80%、90%、95%、98%或99%相同的氨基酸序列和编码其的dna序列,包括与seq id no:2至少有80%、90%、95%、98%或99%相同的dna序列。标签的组胺部分可以是任何含有组胺的序列,包括具有六个或更多组胺残基的序列。在标签中,mbp可能被其他蛋白质取代,标签也可能被添加到除hindiii外的其他内切酶上。
附图说明
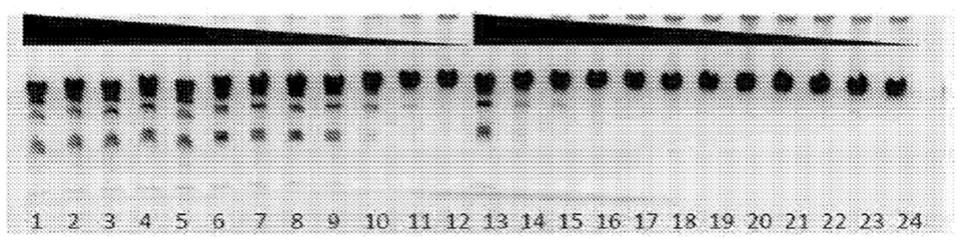
7.图1:在镍磁珠吸附前后hindiii
‑
hm(其为:n
‑
末端
‑
his
‑
mbp
‑
hindiii融合蛋白;如seq id no:2所示)对λdna吸附的活性测试。高浓度hindiii
‑
hm与镍
‑
ida磁珠在4℃下孵育1小时。然后对每个连续的泳道将上清液稀释2倍。泳道1
‑
12显示在没有珠吸附然后经凝胶电泳分离反应产物的情况下hindiii
‑
hm的活性。泳道13
‑
24显示在经珠吸附、然后再经凝胶电泳分离反应产物的情况下hindiii
‑
hm的活性。
8.图2:在磁珠吸附前后hindiii
‑
hm在反应混合物中残留的活性测试。泳道m是1kb dna标记,泳道1
‑
6显示在没有磁珠吸附的情况下连续两倍稀释(在每个泳道中)hind
‑
hm活性后的结果。泳道7
‑
12显示了hindiii
‑
hm磁珠吸附和连续两倍稀释(在每个泳道中)后
hindiii消化的结果。结果表明,puc19先运行,然而通过保留在每个反应孔中的镍磁珠吸附去除。然后,在每孔中加入λdna并再次孵育反应,然后通过镍磁珠吸附使酶失活。结果是如下的电泳分离,其中行标记显示puc19和λdna被酶消化成不同的条带的程度。
9.序列表
10.seq id no.:1:hindiii
‑
hm融合蛋白dna序列
11.atgaaaatccaccaccaccaccaccacgaagaaggtaaactggttatctggatcaacggtgacaaaggttacaacggtctggcggaagttggtaaaaaattcgaaaaagacaccggtatcaaagttaccgttgaacacccggacaaactggaagaaaaattcccgcaggttgcggcgaccggtgacggtccggacatcatcttctgggcgcacgaccgtttcggtggttacgcgcagtctggtctgctggcggaaatcaccccggacaaagcgttccaggacaaactgtacccgttcacctgggacgcggttcgttacaacggtaaactgatcgcgtacccgatcgcggttgaagcgctgtctctgatctacaacaaagacctgctgccgaacccgccgaaaacctgggaagaaatcccggcgctggacaaagaactgaaagcgaaaggtaaatctgcgctgatgttcaacctgcaggaaccgtacttcacctggccgctgatcgcggcggacggtggttacgcgttcaaatacggtgacatcaaagacgttggtgttgacaacgcgggtgcgaaagcgggtctgaccttcctggttgacctgatcaaaaacaaacacatgaacgcggacaccgactactctatcgcggaagcggcgttcaacaaaggtgaaaccgcgatgaccatcaacggtccgtgggcgtggtctaacatcgacacctctaaagttaactacggtgttaccgttctgccgaccttcaaaggtcagccgtctaaaccgttcgttggtgttctgtctgcgggtatcaacgcggcgtctccgaacaaagaactggcgaaagaattcctggaaaactacctgctgaccgacgaaggtctggaagcggttaacaaagacaaaccgctgggtgcggttgcgctgaaatcttacgaagaagaactggcgaaagacccgcgtatcgcggcgaccgcggaaaacgcggcgaaaggtgaaatcatgccgaacatcccgcagatgtctgcgttctggtacgcggttcgtaccgcggttatcaacgcggcgtctggtcgtcagaccgttgacgaagcgctgaaagacgcgcagaccaactcttcttctaacaataataacaataacaataacaacaacctgggtgaaaacctgtacttccagggtatgaaaaaatcagccttagaaaaactgctgtctctgatcgaaaatctgaccaatcaagagtttaaacaggctaccaatagtctgattagctttatctacaagctgaatcgtaatgaggtcatcgaactggttcgcagcatcggcatcctgccggaagctatcaaaccgtctagtacccaggaaaaactgtttagcaaagcgggcgatattgtgctggccaaagcctttcagttactgaatctgaatagcaaacctctggaacagcgtggtaatgcaggcgatgtgattgccctgtctaaagagttcaattatggcttagttgcggatgccaaatcatttcgcctgtcacgcacggctaaaaatcagaaagattttaaagttaaagcgttaagtgaatggcgcgaagataaagattatgcggtgctgaccgcaccgtttttccagtatccgacgaccaaatctcagatttttaaacagtcattagatgaaaatgtgttactgttttcatgggaacatctggccatcctgctacaactggatctggaagaaaccaatatctttccgtttgaacagctgtggaattttcctaaaaaacagtctaagaaaacgagtgtgagcgatgccgaaaacaattttatgcgcgattttaataagtattttatggatctgtttaaaattgataaagatacgctgaatcagttactgcaaaaagaaatcaattttatcgaagaacgctcactgattgaaaaagaatattggaaaaaacagatcaatattatcaaaaattttacacgcgaagaagccatcgaagccttactgaaagatattaatatgagtagcaaaatcgaaaccattgatagctttatcaaaggcatcaaatctaatgatcgcctgtatctgtaa
12.seq id no.:2:hindiii
‑
hm融合蛋白序列(n
‑
末端his标记加下划线,mbp部分加斜体):
13.mkihhhhhheegklviwingdkgynglaevgkkfekdtgikvtvehpdkleekfpqvaatgdgpdiifwahdrfggyaqsgllaeitpdkafqdklypftwdavryngkliaypiavealsliynkdllpnppktweeipaldkelkakgksalmfnlqepyftwpliaadggyafkygdikdvgvdnagakagltflvdliknkhmnadtdysiaeaafnkgetamtingpwawsnidtskvnygvtvlptfkgqpskpfvgvlsaginaaspnkelakeflenylltdegleavnkdk
plgavalksyeeelakdpriaataenaakgeimpnipqmsafwyavrtavinaasgrqtvdealkdaqtnsssnnnnnnnnnnlgenlyfqgmkksalekllslienltnqefkqatnslisfiyklnrnevielvrsigilpeaikpsstqeklfskagdivlakafqllnlnskpleqrgnagdvialskefnyglvadaksfrlsrtaknqkdfkvkalsewredkdyavltapffqypttksqifkqsldenvllfswehlaillqldleetnifpfeqlwnfpkkqskktsvsdaennfmrdfnkyfmdlfkidkdtlnqllqkeinfieersliekeywkkqiniiknftreeaieallkdinmsskietidsfikgiksndrlyl
14.seq id no:3:n
‑
末端组胺标签:mkihhhhhh
具体实施方式
15.术语“磁体”或“磁性”包括铁磁和顺磁材料,包括铁、氧化铁(可与粘结剂混合)、铁合金、稀土元素或合金、陶瓷(或铁氧体)磁铁(由粉末状氧化铁和碳酸钡/锶陶瓷的烧结复合物制成)和/或铝镍钴磁铁。合金可以包括以下中的一种或多种:nd2fe
14
b(钕)、smco5、smco7、smfe7、smcu7和smzr7。磁体材料可以包括与粘合剂结合的磁性材料,例如镍
‑
ida。
16.术语“珠”包括珠子和微珠,包括由聚乙烯、聚对苯二甲酸乙二醇酯、尼龙、聚丙烯、聚苯乙烯和聚甲基丙烯酸甲酯制成的那些。
17.术语“磁珠”包括带有磁芯的珠子和微珠。
18.术语“生物活性片段”是指具有体内或体外活性、即该生物分子特征的核酸内切酶的任何片段、衍生物、同源物或类似物。例如,核酸内切酶的特征在于包括dna结合活性和核苷酸消化活性的生物学活性。核酸内切酶的“生物活性片段”是可以消化核酸链的任何片段、衍生物、同源物或类似物。在一些实施方式中,突变体hindiii的生物活性片段、衍生物、同源物或类似物在体内或体外测定,例如dna结合测定、核苷酸聚合测定(其可以是模板依赖性的或模板非依赖性的)、引物延伸测定、链置换测定、逆转录酶测定、校对测定、准确度测定、热稳定性测定和离子稳定性测定等中具有10%、20%、30%、40%、50%、60%、70%、75%、80%、85%、90%、95%或98%或更高的核酸内切酶的生物活性。在一些实施方式中,生物活性片段可包括核酸内切酶的任何部分。在一些实施方式中,生物活性片段可任选地包括核酸内切酶的任何25、50、75、100、150或更多个连续氨基酸残基。修饰的核酸内切酶的生物活性片段可以包括与seq id no:2具有至少80%、85%、90%、95%、98%或99%同一性的至少25个连续氨基酸残基。本发明还包括编码任何前述氨基酸序列(其是seq id no:1的编码部分)的多核苷酸。生物活性片段可以来自转录后加工或选择性剪接的rna的翻译,或者可以通过改造、批量合成或其他合适的操作产生。生物活性片段包括在天然或内源细胞中表达的片段,以及在表达系统例如细菌、酵母、植物、昆虫或哺乳动物细胞中产生的片段。
19.如本文所用,“保守性氨基酸替换”或“保守性突变”是指一种氨基酸被另一种具有共同理化性质的氨基酸所取代。从功能上定义单个氨基酸之间共同性质的方法是分析同源生物中相应蛋白质之间氨基酸变化的标准化频率(schulz(1979)蛋白质结构原理,springer
‑
verlag)。根据这样的分析,可以定义氨基酸组,其中组内的氨基酸优先相互交换,因此在它们对整体蛋白质结构的影响方面彼此最相似(schulz(1979)同上)。以这种方式定义的氨基酸组包括:“带电荷/极性组”,包括glu、asp、asn、gln、lys、arg和his;“芳香族或环状组”,包括pro、phe、tyr和trp;以及“脂肪族组”,包括gly、ala、val、leu、ile、met、ser、thr和cys。在各个组中,还可以鉴定亚组。例如,带电荷/极性的氨基酸可以再分为包括
以下的亚组:包括lys、arg和his的“正电荷亚组”;和包括glu和asp的“负电荷亚组”;以及包括asn和gln的“极性亚组”。另外,芳香族或环状组可以再分为包括以下的亚组:包括pro、his和trp的“氮环亚组”;以及包括苯和甲苯的“苯基亚组”。在另一个进一步实例中,脂肪族组可再分为包括以下的亚组:包括val、leu和ile的“大脂肪族非极性亚组”;包括met、ser、thr和cys的“脂肪族微极性亚组”,以及包括gly和ala的“小残基亚组”。保守性突变的实例包括上述亚组内的氨基酸替换,例如但不限于:lys替换arg或反之亦然,使得保持正电荷;glu替换asp或反之亦然,使得保持负电荷;ser替换thr或反之亦然,使得保持一个游离
‑
oh;gln替换asn或反之亦然,使得保持游离
‑
nh2。“保守性变体”是包括一个或多个氨基酸的多肽,这些氨基酸已被取代以替换包含具有共同特性的氨基酸的参考多肽(例如,其序列在出版物或序列数据库中公开的多肽,或其序列已通过核酸测序确定)的一个或多个氨基酸,例如,属于与上述相同的氨基酸组或亚组。
[0020]“突变体”是指相对于天然或野生型基因具有至少一个碱基(核苷酸)改变、缺失或插入的基因。突变(一个或多个核苷酸的改变、缺失和/或插入)可以发生在基因的编码区,也可以发生在内含子、3'utr、5'utr或启动子区。作为非限制的实例,突变基因可以是在可增加或减少基因表达的启动子区域具有插入的基因;可以是具有缺失的基因,所述缺失导致产生非功能蛋白、截短蛋白、显性负蛋白或无蛋白;或者,可以是具有一个或多个点突变的基因,所述点突变导致所编码蛋白质的氨基酸发生变化或导致基因转录物的异常剪接。在本发明中,也可以指融合蛋白的mbp或组胺标签区的改变、缺失或插入。
[0021]“自然存在的”或“野生型”是指在自然中发现的形式。例如,自然存在的或野生型多肽或多核苷酸序列是存在于生物体中的序列,例如未经人工故意修饰的hindiii序列。
[0022]
关于核酸或多肽序列的术语“同一性百分比”或“同源性”被定义为候选序列中与已知多肽相同的核苷酸或氨基酸残基的百分比,其在将序列比对后获得最大百分比同一性且必要时引入间隔,以实现最大百分比同源性。n
‑
末端或c
‑
末端插入或缺失不应被解释为影响同源性。核苷酸或氨基酸序列水平的同源性或同一性可通过blast(basic local alignment search tool)分析,使用程序blastp、blastn、blastx、tblastn和tblastx所采用的算法(altschul(1997),nucleic acids res.25,3389
‑
3402,and karlin(1990),proc.natl.acad.sci.usa 87,2264
‑
2268)确定,其为序列相似度搜索定制。blast程序使用的方法是,首先考虑在查询序列和数据库序列之间具有和不具有间隔的相似段,然后评估所有识别出的匹配项的统计显著性,并最后仅总结那些满足预选的显著性阈值的匹配项。关于序列数据库相似度搜索的基本问题的讨论,参见altschul(1994),自然遗传学第6期,第119
‑
129页。直方图、描述、比对、期望(即报告与数据库序列匹配的统计显著性阈值)、截止值、矩阵和过滤器(低复杂性)的搜索参数可以采用默认设置。blastp、blastx、tblastn和tblastx使用的默认评分矩阵是blosum62矩阵(henikoff(1992),proc.natl.acad.sci.usa 89,10915
‑
10919),推荐用于长度超过85个单位(核苷酸碱基或氨基酸)的查询序列。
[0023]
使用hindiii
‑
hm蛋白
[0024]
在一些实施方式中,本发明涉及通过使hindiii
‑
hm融合蛋白或其生物活性片段与核酸模板接触来进行核苷酸消化反应的方法(以及相关的试剂盒、系统、装置和组合物)。在消化已进行到指定的程度或在指定的时间后,将融合蛋白或其生物活性片段移出以停止反应。去除融合蛋白的优选方法是使用亚氨基二乙酸(ida)或次氮基三乙酸(nta),这两者都
能结合组胺标签中的咪唑环。ida和nta可以结合到树脂、基质、珠子或其他固体支持物上,因此去除固体支持物能去除结合的融合蛋白或其生物活性片段。
[0025]
在一些实施方式中,可以使用磁珠(包括镍珠和与ida结合的镍珠)去除hindiii
‑
hm融合蛋白或其生物活性片段。磁珠被吸附到支持物上,例如磁棒插入到反应混合物中,移除磁棒可去除hindiii
‑
hm融合蛋白或其生物活性片段。另外,吸附磁珠和结合的融合蛋白到反应容器的一个区域也能抑制酶的活性。
[0026]
在一些实施方式中,该方法还可以包括使用传感器检测指示hindiii
‑
hm融合蛋白或其生物活性片段消化dna寡聚体的信号。在一些实施方式中,传感器是isfet。在一些实施方式中,所述传感器可包括聚合反应中的可检测标签或可检测试剂。
[0027]
在一些实施方式中,该方法还包括确定由hindiii
‑
hm融合蛋白或其生物活性片段消化的一个或多个核苷酸的特性。在一些实施方式中,该方法还包括确定由hindiii
‑
hm融合蛋白或其生物活性片段消化的核苷酸的数量。
[0028]
在一些实施方式中,本发明涉及用于在hindiii
‑
hm融合蛋白或其生物活性片段消化后扩增核酸片段并去除它的方法(和相关的试剂盒、系统、仪器和组合物)。优选采用聚合酶链式反应(pcr)、乳化液pcr、桥式pcr、等温扩增反应、重组酶聚合酶链式扩增反应、邻近连接扩增、滚圈扩增或链置换扩增等方式进行扩增。扩增产物可以在此之后进行分析。
[0029]
在一些实施方式中,本发明通常涉及使用突变hindiii或其生物活性片段在引物末端结合至少一个核苷酸来合成核酸的方法(和相关试剂盒、系统、仪器和组合物)。可选地,该方法还包括检测至少一个核苷酸在引物末端的结合。在一些实施方式中,该方法还包括确定引入引物末端的至少一个核苷酸中的至少一个的特性。在一些实施方式中,所述方法可包括确定引入引物末端的所有核苷酸的特性。在一些实施方式中,所述方法包括以模板依赖性的方式合成核酸。在一些实施方式中,该方法可以包括在溶液中、在固体支持物上或在乳剂中(例如empcr)合成核酸。
[0030]
制备突变型限制性内切酶
[0031]
为了提供可以在消化中起作用的hindiii
‑
hm融合蛋白或其生物活性片段,氨基酸取代可以是在一个或多个氨基酸、2个或更多个氨基酸、3个或更多个氨基酸,或更多个处,包括其中野生型hindiii序列中至多30%的氨基酸被取代,或者其中类似的取代如seq id no:2的融合蛋白。hindiii
‑
hm融合蛋白的实施方式可能与seq id no:2具有70%至99.99%同一性。
[0032]
hindiii
‑
hm融合蛋白或其生物活性片段可在任何合适的宿主系统中表达,包括细菌、酵母、真菌、杆状病毒、植物或哺乳动物宿主细胞。
[0033]
实施例
[0034]
材料
[0035]
直链淀粉树脂,puc19,λdna,c2566,1kb dna标记:new england biolabs,inc.,ma,usa
[0036]
镍
‑
ida磁珠:获自中国江苏beaverbio公司
[0037]
mbp常被用作蛋白质溶解度伴侣或融合蛋白标签,且其分子质量约为42.5千道尔顿。
[0038]
n
‑
末端组胺标签具有氨基酸序列mkihhhhhh,seq id no:3(在一个实施方式中)。
[0039]
限制性内切酶hindiii构建为包含n
‑
末端his
‑
mbp,其dna和蛋白质序列分别如seq id no:1和2所示。mbp提供了中等大小的标记,允许通用标记绑定。包含mbp标签也有助于seq id no:1的限制性内切酶部分表达。
[0040]
通过将his
‑
mbp标签与直链淀粉珠或其他吸附性珠(磁性或非磁性)结合、包括镍珠,可以将n
‑
末端his
‑
mbp标记的限制性内切酶从反应中去除。对珠子的吸附可使酶失活。磁珠是优选的,因为通过吸附到随后从反应室中取出的磁力或顺磁性支持物,从而将珠子带出反应室,因此可以在酶结合和失活后将它们很容易地从反应室中取出(通常是微滴度板孔或管)。
[0041]
在一个实施例中,his
‑
mbp标记的hindiii(“hindiii
‑
hm”)由按以下顺序的成分构建:n端
‑
his
‑
mbp标记的hindiii(参见seq id no:1和2)。seq id no:1优选在大肠杆菌c2566中表达。hindiii
‑
hm可以使用传统的fplc色谱柱纯化,或使用镍珠色谱柱然后使用直链淀粉珠色谱柱纯化。
[0042]
图1显示了从高浓度hindiii
‑
hm作用于λdna开始,以及镍
‑
ida磁珠吸附前后的活性变化。将hindiii
‑
hm与λdna(含或不含镍
‑
ida磁珠)在4℃下孵育1小时。反应组成及条件为:2μl酶,2μl的10x反应缓冲液,0.4μl的500ng/μlλdna,15.6μl水,在37℃下。反应缓冲液为:50mm nacl,10mm tris
‑
hcl,10mm mgcl2,在25℃下ph 7.9。对于泳道1
‑
12从左向右移动,每个连续泳道代表实验操作,其中对于每个连续操作,用50%甘油连续稀释反应溶液两倍。每次操作后,上清液中的dna进行凝胶电泳。对泳道13至24的每个连续泳道进行相同的连续稀释。
[0043]
泳道1
‑
12显示了其中镍
‑
ida磁珠不存在的结果。结果表明,泳道1
‑
9都显示出足够高的酶活性以将dna降解为相同或相似的不同条带。泳道13
‑
24显示了镍
‑
ida磁珠在溶液中的结果。仅在具有最高酶浓度(在任意稀释前)的第一泳道(13号)中完成酶消化(如泳道1
‑
9中的条带所证实)。因此,镍磁珠吸附并失活了99.6%的hindiii
‑
hm。
[0044]
图2显示了第一个底物消化后,接着磁珠吸附,然后另一个底物消化后的活性变化。首先,将10个单位的hindiii
‑
hm与1μg质粒puc19孵育1小时。反应缓冲液为:50mm nacl、10mm tris
‑
hcl,10mm mgcl2,在25℃下ph 7.9。反应组成和条件为:2μl的hindiii
‑
hm(10个单位),2μl的10x反应缓冲液,1μl的1μg/ul puc19,15μl水,在37℃下1h。
[0045]
反应结束后,将20μl的10%镍
‑
ida磁珠加入反应混合物中并孵育10分钟。然后用50%甘油以两倍连续稀释来稀释上清液。
[0046]
第二步反应组成为:2μl酶、2μl 10x反应缓冲液、0.4μl 500ng/μlλdna、15.6μl水;全部孵育另外一个小时。在图2中,泳道m为1kb dna标记物,无反应和随后的凝胶分离;泳道1
‑
6显示了两倍连续稀释hindiii
‑
hm活性后的结果,但没有磁珠存在或吸附;泳道7
‑
12显示了两倍连续稀释hindiii
‑
hm活性后的结果,但在反应后有磁珠存在和吸附。
[0047]
结果表明,在第二步反应中,酶根本不消化λdna,这意味着之前吸附到镍
‑
ida珠(步骤1反应后)使酶完全灭活(如泳道7
‑
12所示)。
[0048]
本发明已经在本文中广泛地和一般性地进行了描述。落入一般公开的每个较窄的物种和亚属组也构成本发明的一部分。已使用的术语和表达被用作描述而非限制,并且使用此类术语和表达无意排除所示和描述的特征或其部分的任何等同物,但应认识到在所要求保护的本发明的范围内可以进行各种修改。因此,应当理解,虽然本发明已经通过优选实
施方式和可选特征具体公开,但是本领域技术人员可以对这里公开的概念进行修改和变化,并且这种修改和变化被认为是属于所附权利要求书所限定的本发明范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。