技术特征:
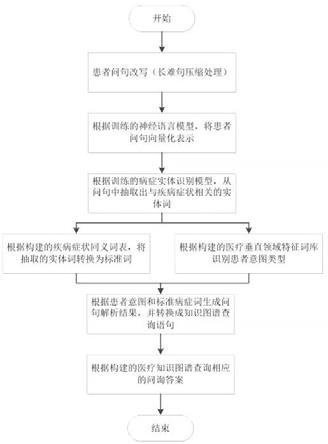
1.一种在线医疗问答方法,其特征在于:步骤如下,(1)患者问题接收后进行长短句压缩处理,得到改写后的问句;(2)将改写后的问句进行分词处理,分割成单词集合;(3)预先训练神经语言模型,将单词集合进行向量化处理,并进一步将问句进行向量化;(4)抽取出与疾病症状相关的实体词;(5)将抽取的实体词转为对应的标准词;(6)根据特征词库识别出患者意图类型;(7)根据标准词和患者意图类型生成问句解析结果;(8)根据医疗疾病知识库构建知识图谱;(9)将问句解析结果转换成查询语句,通过知识图谱查询获得答案。2.根据权利要求1所述在线医疗问答方法,其特征在于:所述步骤(1)中患者问题接收后通过标点分割成若干短句,对短句进一步分类成与医疗相关的句子以及与医疗无关的口水话语句;对短句进一步分类采用textcnn神经网络模型,textcnn神经网络模型的构建如下:s1输入层,从医疗网站在线采集医疗问答数据,作为数据集;将与医疗相关的问句打标签为1,与医疗无关的口水话语句打标签为0,并按照7:3的比例将数据集分为训练集和测试集,将训练集数据转化为embedding词向量后作为textcnn神经网络模型训练的输入;s2卷积层,通过卷积操作提取输入层embedding词向量的特征,每个卷积核输出一个一维特征向量;s3池化层,对卷积层输出的一维特征向量做池化操作,做抽象的特征提取;取每个一维特征向量的最大值,然后将所有特征向量的最大值进行拼接,输出拼接后的一维特征向量;s4输出层,将问句对应每个类别的概率映射到(0,1)之间,从而根据最大概率确定问句所属的类别;textcnn神经网络模型参数包括训练次数和学习率,所述模型训练次数为将整个训练集进行输入后的迭代计算次数;所述学习率为在模型进行参数更新时所采用的梯度下降算法中计算系数;textcnn神经网络模型构建完成后,将步骤(2)改写后的问句输入到构建的textcnn神经网络模型,获得短句所属的类别,去除类别为0的短句,保留与医疗相关的问句;所述步骤(2)利用不同符号对患者病情主诉信息进行粗分词,然后利用中文分词工具jieba结合自定义疾病症状词库进行细分词,得到病情主诉单词集合;所述不同符号包括:逗号、冒号、分号、&、百分号、等号和空格中的任意一种或几种;所述自定义疾病症状词库,为从医疗网站获取的疾病症状词进行构建的词库;所述分词工具jieba与疾病症状词库结合方式为,分词工具jieba提供行业领域词库接口,将自定义的疾病症状词库添加,保证患者病情主诉信息中专业的疾病、症状术语不会被错误分开;所述步骤(3)具体操作为:以word2vec算法来训练语言模型,输入为改写后的问句,输出为词表大小的向量,向量每一维度的值是基于当前输入词预测下一个词输入的概率;获取的医疗网站上患者的问答数据作为模型的训练数据集;设置模型的参数,包括训练次数、
词向量的维度;得到每个词的词向量之后,生成句子向量,根据步骤(2)得到单词集合,单词数目记为n,,定义词向量分别为[v1,v2,v3,
…
,v
n
],设句向量为s,则得到句向量为;;其中v
n
代表向量的每一维的数值,所述步骤(4)采用深度学习算法或基于词典的规则匹配算法、基于模板的匹配算法中的任意一种;所述步骤(5)从医疗网站的知识库爬取专业的疾病症状表述词和相应的同义词,将相同的词进行去重,含义相同但表述不同的词采用python的中文近义词工具包synonyms来进行同义合并,形成疾病症状知识库;将步骤(4)抽取的实体词作为标准表述词进行保留,其余非标准词采用相似度计算方法与标准词进行计算,获取相似度最高的标准词表述;所述步骤(6)采用穷举法定义不同疑问类型的特征词库,采用字符串匹配算法进行匹配,获取患者意图类型;所述步骤(8)包括数据收集、定义实体关系以及知识图谱构建,所述数据收集通过医疗网站、百度百科、医疗机构、研究单位公开的病历评测数据以及医疗书籍数据源进行;所述知识图谱构建以实体作为图谱的节点,以实体关系作为图谱中实体连接边,采用neo4j图数据库进行图谱存储;所述步骤(9)将步骤(7)获得的问句解析结果转换为neo4j图数据库的查询语言,使用cypher的match语句在neo4j存储的图谱中匹配查找,根据查询返回的数据组装形成答案。3.根据权利要求2所述在线医疗问答方法,其特征在于:所述卷积层的卷积核为2*2、3*3、4*4三种维度的卷积核,每种维度卷积核数量为128个;所述输出层采用softmax、sigmoid、svm中的任意一种分类算法进行;计算公式为,其中p
i
为每个科室类别的预测概率值,e
j
为输出向量的每一维度的值。4.根据权利要求2所述在线医疗问答方法,其特征在于:所述步骤(4)中深度学习算法为序列标注模型bilstm
‑
crf,输入为句向量表示的患者咨询问句,输出为标注结果;第一层输入层以咨询问句的向量表示,第二层采用双向的lstm神经网络提取问句的时序特征,数据量过大或出现效率过慢问题,采用lstm网络的变体代替;第三层输出层为条件随机场层,以lstm提取的特征作为观测序列,输出最大的状态序列;根据输出的状态序列,按照完整的实体bio规则提取出实体及对应的实体类型。5.根据权利要求2所述在线医疗问答方法,其特征在于,所述步骤(5)中相似度计算方法采用word2vec、余弦相似度计算、tf
‑
idf算法中的任意一种;所述步骤(6)采用python的ahocorasick包、正向或者反向最大匹配算法中的任意一种实现字符串的匹配。
技术总结
本发明属于互联网医疗技术领域,涉及一种在线医疗问答方法。患者问题接收后进行长短句压缩处理,得到改写后的问句,分词处理,分割成单词集合,训练神经语言模型,将单词集合进行向量化处理,并进一步将问句进行向量化,抽取实体词,将实体词转为标准词,根据特征词库识别出患者意图类型;生成问句解析结果,构建知识图谱;转换成查询语句,通过知识图谱查询获得答案。本发明可以有效解决患者对自身病情表述不专业,医疗系统无法识别的痛点,通过精准识别患者问询意图,针对患者病症,采用自构建的知识图谱给出患者推荐药品、视频及治疗等。视频及治疗等。视频及治疗等。
技术研发人员:王成伟 高中霞 艾延永
受保护的技术使用者:山东大学第二医院
技术研发日:2021.09.16
技术公布日:2021/12/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。