蛋白质赖氨酸乳酸酰化检测试剂和方法
1.对相关申请的引用
2.本专利申请要求2018年12月21日提交的第62/783926号美国临时专利申请的优先权,无论出于何种目的,其全部内容都并入本技术中作为参考。
3.受美国政府支持的引用
4.该项工作受到美国国家卫生研究院(nih)的资助(编号:dk107868)。美国对这项发明享有一定的权利。
发明领域
5.本发明涉及用于检测具有翻译后修饰的蛋白质的试剂和方法。具体地说,本发明涉及组成乳酸酰化赖氨酸的肽,及其用于开发检测蛋白质赖氨酸乳酸酰化的试剂和方法的用途。
6.发明背景
7.瓦伯格效应(最初用于描述癌症中乳酸生成的增加)与多种细胞过程有关,例如血管生成、缺氧、巨噬细胞极化和t细胞活化。该现象与多类疾病密切相关,如肿瘤、脓毒症和自身免疫性疾病。乳酸是瓦伯格效应发生过程中产生的一种化合物。众所周知,其是一种能量来源和代谢副产物。但在非代谢功能生理学和疾病方面,有关它的研究还尚未明确。
8.因而,目前仍然需要开发用于检测与各种疾病和症状相关的组蛋白或非组蛋白的翻译后修饰的试剂和方法。
发明概要
9.本发明涉及特异性结合肽中的乳酸酰化赖氨酸的亲和试剂及其制备和用途。该发明基于发明者发现的一种新型组蛋白标记:赖氨酸乳酸酰化。
10.本发明提供分离的亲和试剂可与肽中的乳酸酰化赖氨酸特异性结合。该肽来源于组蛋白或其片段。组蛋白可从选自于人类、小鼠、酿酒酵母、嗜热四膜虫、黑腹果蝇和秀丽隐杆线虫中的生物体中获得。所述肽可包含选自于序列号为:29
‑
87的氨基酸序列,该序列需与氨基酸序列的同源度达70%以上。该肽可包含选自于序列号为:29
‑
87的氨基酸序列,同时该肽可在所述乳酸酰化赖氨酸每一个n端和c端侧上皆包含至少一个或两个氨基酸残基。亲和试剂与肽的结合可取决于肽中的乳酸酰化赖氨酸的周围肽序列。亲和试剂可以是蛋白质,也可以是抗体。
11.本发明提供了一种检测蛋白质或其片段中的乳酸酰化赖氨酸的方法。该方法为,通过将所述蛋白质或其片段与亲和试剂接触,该亲和试剂可特异性地结合到肽中的乳酸酰化赖氨酸中,由此形成所述蛋白质或其片段与亲和试剂的结合复合物;同时,通过检测该结合复合物可得出,所述结合复合物的存在表明了所述蛋白质或其片段中存在乳酸酰化赖氨酸。检测方法可进一步包含量化的蛋白质或其片段中的乳酸酰化赖氨酸。
12.根据所述检测方法,该肽来源于组蛋白或其片段。组蛋白可从选自于人类、小鼠、酿酒酵母、嗜热四膜虫、黑腹果蝇和秀丽隐杆线虫中的生物体中获得。所述肽可包含选自于
序列号为:29
‑
87的氨基酸序列,该序列需与氨基酸序列的同源度达70%以上。该肽可包含选自于序列号为:29
‑
87的氨基酸序列,同时该肽可在所述乳酸酰化赖氨酸每一个n端和c端侧上皆包含至少一个或两个氨基酸残基。亲和试剂与肽的结合可取决于肽中的乳酸酰化赖氨酸的周围肽序列。亲和试剂可以是蛋白质,也可以是抗体。
13.本发明提供了分离特异性结合到肽中的乳酸酰化赖氨酸的亲和试剂的第一种方法。该方法为,将蛋白库暴露于包含乳酸酰化赖氨酸的肽中,由此来自于蛋白库的蛋白质可特异性结合到乳酸酰化赖氨酸中并与肽形成结合复合物;同时,其可从结合复合物中分离出蛋白质,该分离出的蛋白质即为亲和试剂。该肽可在所述乳酸酰化赖氨酸每一个n端和c端侧上皆包含至少一个或两个氨基酸残基。
14.本发明也提供了分离特异性结合到肽中的乳酸酰化赖氨酸的亲和试剂的第二种方法。该方法为,用包含乳酸酰化赖氨酸的肽免疫一宿主,由此使其产生抗体;之后从宿主中分离出抗体,所分离出的抗体即为亲和试剂。该肽可在所述乳酸酰化赖氨酸每一个n端和c端侧上皆包含至少一个或两个氨基酸残基
15.本发明提供的第一类试剂盒包含特异性结合到肽中的乳酸酰化赖氨酸的亲和试剂,以及根据本发明提供的检测方法,使用亲和试剂检测蛋白质或其片段中的乳酸酰化赖氨酸的说明书。
16.本发明提供的第二类试剂盒包含乳酸酰化赖氨酸的肽,以及用于分离根据本发明第一种或第二种分离方法的肽中特异性结合到乳酰化赖氨酸的亲和试剂的说明书。
17.本发明提供一种包含乳酸酰化赖氨酸的分离肽。该肽来源于组蛋白或其片段。组蛋白可从选自于人类、小鼠、酿酒酵母、嗜热四膜虫、黑腹果蝇和秀丽隐杆线虫中的生物体中获得。所述肽可包含选自于序列号为:29
‑
87的氨基酸序列,该序列需与氨基酸序列的同源度达70%以上。该肽可包含选自于序列号为:29
‑
87的氨基酸序列,同时该肽可在所述乳酸酰化赖氨酸每一个n端和c端侧上皆包含至少一个或两个氨基酸残基。
18.附图的简要说明
19.图1显示了组蛋白kla的鉴定与验证。a.kla结构示意图。b为来源于mcf
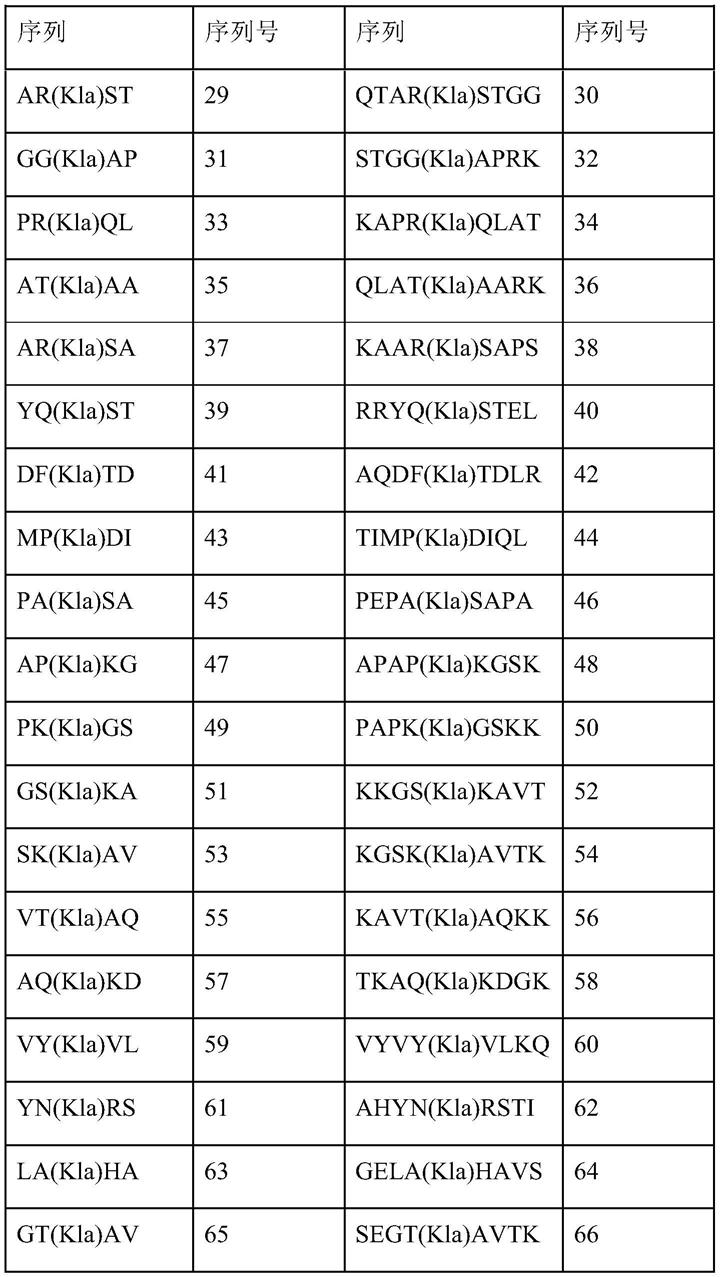
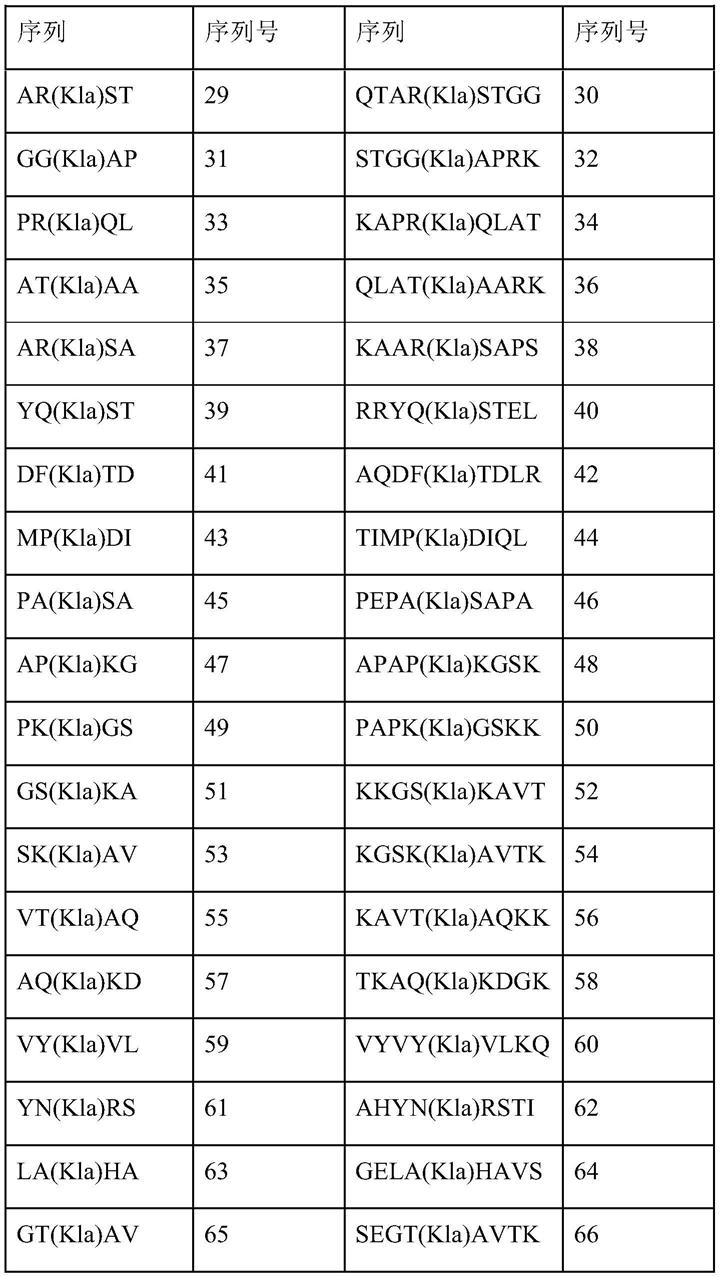
‑
7细胞(体内)的乳酸酰化组蛋白肽(h3k23la)及其合成对应物和混合物的ms/ms质谱图。b
‑
i指肽的氨基末端离子,y
‑
i指肽的羧基末端离子。图中数据代表两个独立的重复。c为在人和小鼠细胞中检验过的的组蛋白kla位点的示意图。
20.图2显示了乳酸对组蛋白kla的调节。图中数据为测定不同浓度葡萄糖和不同浓度2
‑
dg作用24小时后mcf
‑
7细胞内乳酸(a、d)和组蛋白kla(b、c)的水平。用乳酸比色试剂盒用于测定乳酸;n=3生物重复;统计显著性采用单因素方差分析和sidak多重比较检验确定。用酸提取的组蛋白样品需进行免疫印迹。泛抗kla和抗kac免疫印迹显示分子量在10kd和15kd之间。e为多种代谢调节剂对糖酵解和乳酸产生的调节。f为用指定的糖酵解调节剂处理mcf
‑
7细胞24小时,测定出的细胞内乳酸水平。n=3生物重复;统计显著性采用单因素方差分析和dunnett多重比较检验确定。g
‑
i为不同糖酵解调节剂对mcf
‑
7细胞酸提取组蛋白(鱼藤酮和dca)或全细胞裂解物(草氨酸盐)的免疫印迹反应。j为测定缺氧时mcf
‑
7细胞内乳酸水平。n=4生物重复;统计显著性采用未配对t检验(双尾)确定。k为在缺氧(1%氧气)条件下对mcf
‑
7细胞进行酸提取组蛋白免疫印迹。图a、d、f、j中数值用平均值及其标准误呈现。图b、c、g、h、i、k图中数据来自三个独立的重复。
21.图3显示了m1巨噬细胞极化期间组蛋白kla升高与m2类基因激活的相关性。a
‑
c为lps ifn激活骨髓源性巨噬细胞(bmdms)γ。用乳酸比色试剂盒测定细胞内乳酸(a)。n=3生物重复;统计显著性采用单因素方差分析和dunnett多重比较检验确定。用全细胞裂解物(b,c)进行免疫印迹分析组蛋白酰化。imagej用于定量;n=3技术重复。图中数据代表两个独立的重复。d为用pbs(m0)、lps ifnγ刺激bmdm细胞γ(m1)和白细胞介素
‑
4(m2)分别作用24小时的结果。酸提取组蛋白用于免疫印迹。e、f为散点图(e)和条形图(f),其显示了基因启动子以h3k18la(h3k18la
‑
log2[m1/m0]特异性升高为标志≥1和h3k18ac
‑
log2[m1/m0]≤0.5,h3k18la
‑
特异性),在h3k18la和h3k18ac中升高(h3k18la
‑
log2[m1/m0]≥1和h3k18ac
‑
log2[m1/m0]≥0.5,共用),或专门升高的h3k18ac(h3k18ac
‑
log2[m1/m0]≥1和h3k18la
‑
log2[m1/m0]≤0.5,h3k18ac
‑
特定性)。g、h热图显示了典型炎症基因(g)和h3k18la特异性基因(h)的基因表达动态(使用来自rna
‑
seq的每千碱基转录物每百万测序片段(rpkm)值)。颜色键表示在0h相对于基因表达的log2转化倍数变化。n=4生物重复。i、j中,bmdm细胞分别感染革兰氏阴性菌或lps。用免疫印迹法(i)在细菌激发24小时后测定组蛋白kla水平。“ ”表示低剂量,“ ”表示高剂量。用rt
‑
qpcr(j)分析细菌攻击后指定时间点的基因表达。n=3生物重复。k为免疫印迹法检测诱导型一氧化氮合酶(inos)和精氨酸1(arg1)的蛋白水平。图a、b、c、j中数值用平均值及其标准误呈现,图中数据代表三个独立的重复。
[0022]
图4显示了乳酸通过组蛋白kla激活m2类的基因表达。a
‑
d表示,当ldha缺乏时(髓系特异性ldha
‑
/
‑
),bmdm细胞乳酸分泌的减少会导致m1极化期间组蛋白kla水平和arg1表达的降低。用乳酸比色试剂盒(a)测定细胞内乳酸水平,用免疫印迹法(b)测定m1极化24小时后组蛋白的kla水平。c为在m1极化后的指定时间点用rt
‑
qpcr分析的基因表达。a
‑
c,n=3生物重复。d为用chip
‑
qpcr分析m1极化24小时后h3k18la的占用情况。数据代表来自混合样本中的三个技术重复。e
‑
h为外源性乳酸(25mm)在m1极化(lps ifn)γ)4小时后加入bmdm细胞,在m1极化后的指定时间点收集细胞,以进行细胞内乳酸测定(e)、组蛋白kla免疫印迹分析(f)、基因表达分析(g)和由chip
‑
qpc分析的h3k18la占用率(h)。e,n=3生物重复,f,图中数据代表3个不同实验。g,rpkm:每千碱基转录物每百万测序片段(rpkm)。n=4个生物重复复。h,数据代表来自混合样本中的三个技术重复。图a、c、d、e、g、h中数值用平均值及其标准误呈现;统计学显著性采用holm
‑
sidak法(a,c,e,g)校正的多重t检验确定。
[0023]
发明的详细说明
[0024]
本发明涉及乳酸酰化赖氨酸的分离肽、特异性结合肽中乳酸酰化赖氨酸的亲和试剂及其制备和用途。本发明基于发明者发现的乳酸衍生的组蛋白赖氨酸乳酸酰化,其可作为一种新的表观遗传修饰并证明组蛋白乳酸酰化直接刺激来自染色质的基因转录。发明者已经在人类和小鼠细胞的核心组蛋白上确定了28个乳酸酰化位点。缺氧和细菌挑战通过糖酵解诱导产生乳酸,而糖酵解又是刺激组蛋白乳酸酰化的前体。使用暴露于细菌的m1巨噬细胞作为模型系统,发明者发现组蛋白乳酸酰化与乙酰化具有不同的时间动态。在m1巨噬细胞极化的后期,组蛋白的乳酸酰化修饰增强,从而诱导涉及伤口愈合的稳态基因,包括arginase 1。总体而言,这些结果表明,细菌攻击的m1巨噬细胞中的内源性“乳酸时钟”打开基因表达以促进体内平衡。因此,组蛋白乳酸酰化提供了一个增进了解乳酸的功能及其在各种病理生理状况(包括感染和癌症)中作用的机会。
[0025]
本文中使用的术语“肽”是指通过肽键连接的两个或多个氨基酸的线性链。肽可包
含约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、30、40、50、100、200或更多氨基酸。肽的氨基酸可以被修饰、删除、添加或取代。肽可使用本领域已知的常规技术手段获得,例如,通过酶消化从天然或重组蛋白质中合成或获得。
[0026]
本文中使用的术语“多肽”指具有至少四个氨基酸、最好是在约20个氨基酸以上的肽,而不考虑翻译后修饰。本文中使用的术语“蛋白质”指由一种或多种多肽组成的生物分子,而不考虑翻译后修饰。蛋白质中的每一种多肽都可以是一个亚单位。多肽或蛋白质可以是天然的或修饰的形式,并且可以表现出生物功能或特性。
[0027]
如果蛋白质是单个多肽,则术语“蛋白质”和“多肽”可在本文中互换使用。多肽或蛋白质的片段是指该多肽或蛋白质的一部分,其氨基酸序列与该多肽或蛋白质的部分(而非全部)氨基酸序列相同。若多肽或蛋白质的片段表现出与多肽或蛋白质相同或相似的生物功能或特征,则更好。
[0028]
本文中使用的术语“衍生于”是指获得生物分子的源头或来源,并且其可包括天然存在的、重组的、未纯化的或纯化的分子。诸如肽(例如,多肽或蛋白质)之类的生物分子可从原始分子中衍生而来,并可变得与原始分子或原始分子的变体相同。例如,衍生自原始肽的肽可具有与其原始肽的氨基酸序列相同或相似的氨基酸序列,且都有至少一个氨基酸经修饰、删除、插入或取代。衍生肽可具有至少约5%、10%、20%、30%、40%、50%、60%、70%、80%、90%、95%、99%或100%的氨基酸序列,较好情况下为至少约50%、更好情况下为至少约80%、最好情况下为至少约90%,且其与其原始肽的氨基酸序列相同,并且无需考虑翻译后修饰。若衍生生物分子(例如肽)可表现出与原始生物分子相同或相似的生物功能或特征,则更好。
[0029]
本文中使用的术语“抗体”包括整个抗体、抗原结合片段(或抗原结合部分)及其单链。一个完整的抗体可以是两种类型中的任何一种。第一类是指通常具有两条重链和两条轻链的糖蛋白,并且包括抗原结合部分。例如,抗体可以是多克隆或单克隆抗体。本文所用有关抗体的术语“抗原结合部分”是指保留特异性结合到抗原的能力的抗体的一个或多个片段。第二类是骆驼体内的重链抗体,也被称为纳米抗体。本文所用有关抗体的术语“单链可变区片段”系指抗体的重链和轻链的可变区域的融合蛋白,其能够与例如约20
‑
25个氨基酸的短连接肽连接,并能保持特异性结合到抗原的能力。
[0030]
本发明提供一种包含乳酸酰化赖氨酸的分离肽。本文中使用的术语“乳酸酰化赖氨酸”是指经l
‑
乳酸基修饰的赖氨酸残基。本文中使用的术语“赖氨酸乳酸酰化位点”是指肽、多肽或蛋白质中的赖氨酸残基,其可在赖氨酸残基的ε氨基上被乳酸酰化。本文中使用的术语“赖氨酸乳酸酰化”是指在产生乳酸酰化赖氨酸的赖氨酸残基的ε氨基上的乳酸酰化。
[0031]
本发明中的肽可具有至少约3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、30、40、50、60、70、80、90、100、150或200个氨基酸。肽可具有约3
‑
25个氨基酸,较好情况下为5
‑
20个氨基酸,更好情况下为6
‑
14个氨基酸。
[0032]
本发明中的肽可使用本领域已知的常规技术手段获得。该肽可衍生自具有赖氨酸乳酸酰化位点的蛋白质,例如组蛋白或其片段。组蛋白可衍生自真核细胞。真核细胞的实例包括来自酵母的细胞(例如酿酒酵母)、秀丽隐杆线虫、果蝇(黑腹果蝇(s2))、四膜虫(例如嗜热四膜虫)、小鼠(例如小家鼠(mef))或人。较好情况下,真核细胞为哺乳动物细胞,来源
于人类、灵长类动物、小鼠、大鼠、马、牛、猪、绵羊、山羊、鸡、狗或猫的细胞。更好情况下,所述真核细胞为人类细胞。
[0033]
组蛋白可以是组蛋白连接蛋白或组蛋白核心蛋白。组蛋白连接蛋白可选自h1家族,包括h1f亚家族(例如,h1f0、h1fnt、h1foo和h1fx)和h1h1亚家族(例如,hist1h1a、hist1h1b、hist1h1c、hist1h1d、hist1h1e和hist1h1t)。组蛋白核心蛋白可以是h2a、h2b、h3或h4家族的成员。h2a家族中的组蛋白核心蛋白可以是h2af亚家族(例如,h2afb1、h2afb2、h2afb3、h2afj、h2afv、h2afx、h2afy、h2afy2和h2afz)、h2a1亚家族(例如,hist1h2aa、hist1h2ab、hist1h2ac、hist1h2ad、hist1h2ae、hist1h2ag、hist1h2ah、hist1h2ai、hist1h2aj、hist1h2ak、hist1h2al和hist1h2am)或h2a2亚家族(例如,hist2h2aa3、hist2h2aa4、hist2h2ab和hist2h2ac)中的成员。h2b家族中的组蛋白核心蛋白可以是h2bf亚家族(例如,h2bfm和h2bfwt)、h2b1亚家族(例如,hist1h2ba、hist1h2bb、hist1h2bc、hist1h2bd、hist1h2be、hist1h2bf、hist1h2bg、hist1h2bh、hist1h2bi、hist1h2bj、hist1h2bk、hist1h2bl、hist1h2bm、hist1h2bn和hist1h2bo)或h2b2亚家族(例如,hist2h2be和hist2h2bf)中的成员。h3家族中的组蛋白核心蛋白可以是h3a1亚家族(例如,hist1h3a、hist1h3b、hist1h3c、hist1h3d、hist1h3e、hist1h3f、hist1h3g、hist1h3h、hist1h3i和hist1h3j)、h3a2亚家族(例如,hist2h3a、hist2h3c和hist2h3d)或h3a3亚家族(例如,hist3h3)、h3a3亚家族(例如,h3f3a、h3f3b和h3f3c)中的成员。h4家族中的组蛋白核心蛋白可以是h41亚家族(例如,hist1h4a、hist1h4b、hist1h4c、hist1h4d、hist1h4e、hist1h4f、hist1h4g、hist1h4h、hist1h4i、hist1h4j、hist1h4k和hist1h4l)或h44亚家族(例如,hist4h4)中的成员。
[0034]
本发明中的各种物种的组蛋白的蛋白质和基因序列皆为本领域所知。例如,人类、小鼠、酿酒酵母、四膜虫、黑腹果蝇和秀丽隐杆线虫的组蛋白序列都可在genbank数据库accessionnos.p16403中查询到(h12人)(序列号:1)、p0c0s8(h2a1人)(序列号:2)、p62807(h2b1c人)(序列号:3)、p84243(h33人)(序列号:4)和p62805(h4人)(序列号:5)中找到;p15864(h12小鼠)(序列号:6)、p22752(h2a1小鼠)(序列号:7)、p10853(h2b1f小鼠)(序列号:8)、p84244(h33小鼠)(序列号:9)和p62806(h4小鼠)(序列号:10);p04911(h2a1酿酒酵母)(序列号:11),p02294(h2b2酿酒酵母)(序列号:12),p61830(h3酿酒酵母)(序列号:13)和p02309(h4酿酒酵母)(序列号:14);p35065(h2a1嗜热四膜虫)(序列号:15)、p08993(h2b1嗜热四膜虫)(序列号:16)、i7luz3(h3嗜热四膜虫)(序列号:17)和p69152(h4嗜热四膜虫)(序列号:18);p02255(h1黑腹果蝇)(序列号:19),p08985(h2av黑腹果蝇)(序列号:20),p02283(h2b黑腹果蝇)(序列号:21)、p02299(h3)(序列号:22)和p84040(h4黑腹果蝇)(序列号:23);p10771(h11秀丽隐杆线虫)(序列号:24),p09855(h2a秀丽隐杆线虫)(序列号:25),p04255(h2b1秀丽隐杆线虫)(序列号:26),p08898(h3秀丽隐杆线虫)(序列号:27)和p62784(h4秀丽隐杆线虫)(序列号:28)。
[0035]
组蛋白片段可具有与包含至少一个赖氨酸乳酸酰化位点的组蛋白氨基酸序列的一部分(而非全部)相同的氨基酸序列。组蛋白片段可具有至少约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、30、40、50、60、70、80、90、100、150或200个氨基酸。组蛋白片段可具有组蛋白的约3
‑
25个连续氨基酸、较好情况下为约5
‑
20个连续氨基酸、更好情况下为约6
‑
14个连续氨基酸,且该组蛋白应覆盖组蛋白中的至少一个赖氨酸乳酸酰化位
点。乳酸酰化位点可已被乳酸酰化的也可没有。表1提供包含乳酸酰化赖氨酸的肽段。
[0036]
表1.包含乳酸酰化赖氨酸(kla)的肽段
[0037]
[0038][0039]
肽可以是抗原肽或诱饵肽。抗原肽或诱饵肽可包含表1左栏所示的五个残基序列,也可包含表1所示五个残基序列中任何一个的四个连续残基,或表1所示九个残基序列中任何一个的至少六个连续残基。
[0040]
组蛋白可从生物样本中获得或使用重组技术进行制备。组蛋白片段可通过重组技术或通过酶(例如胰蛋白酶)消化组蛋白进行制备。组蛋白或片段中的赖氨酸乳酸酰化位点可以是天然的或人工的。可通过使用本领域已知的常规技术(例如,质谱法)来确认乳酸酰化赖氨酸的存在。
[0041]
本发明中的肽可包含与表1所示氨基酸序列相似的氨基酸序列,相似度至少约为70%、80%、90%、95%或99%,较好情况下为至少约90%,更好情况下为100%。该肽可包含任意乳酸酰化赖氨酸位点,并可包括或不包括其来自组蛋白的周围序列。同时,该肽可包含一种以上的乳酸酰化赖氨酸,也可包含除赖氨酸乳酸酰化以外的蛋白质翻译后修饰,例如赖氨酸乙酰化或甲基化。该肽可进一步包含至少约1、2、3、4、5、6、7、8、9、10或更多的残基,该残基需位于所述乳酸酰化赖氨酸的n端和c端侧的任一端或两端上。该肽可在所述乳酸酰化赖氨酸每一个n端和c端侧上皆包含至少一个或两个氨基酸残基。本发明的肽段如表1所示。
[0042]
本发明还提供分离的亲和试剂。该亲和试剂可与肽、多肽或蛋白质中的乳酸酰化赖氨酸特异性结合。所以该亲和试剂也被称为赖氨酸乳酸酰化特异亲和试剂。其中,该肽可衍生自组蛋白或其片段,而亲和试剂可以是蛋白质,例如,抗体。赖氨酸乳酸酰化位点可以是来自任意物种的任意组蛋白中的任意赖氨酸乳酸酰化位点。乳酸酰化赖氨酸可以是来自任意物种的任意组蛋白中的任意乳酸酰化赖氨酸。赖氨酸乳酸酰化位点或乳酸酰化赖氨酸的实例包括表1中所示范例,以及其他相应真核组蛋白中的同源赖氨酸位点。
[0043]
在一些实施方案中,当赖氨酸经乳酸酰化时,亲和试剂对肽、多肽或蛋白质中赖氨酸的结合亲和性至少比当赖氨酸未经乳酸酰化时对肽、多肽或蛋白质中赖氨酸的结合亲和
性高约10、50、100、500、1000或5000倍。
[0044]
在一些其它实施方案中,当赖氨酸未经乳酸酰化时,亲和试剂对肽、多肽或蛋白质中赖氨酸的结合亲和性至少比当赖氨酸经乳酸酰化时对肽、多肽或蛋白质中赖氨酸的结合亲和性高约10、50、100、500、1000或5000倍。
[0045]
亲和试剂可以是肽、多肽或蛋白质,也可以是抗体。所述肽最好为本发明中包含乳酸酰化赖氨酸的肽。
[0046]
在一些实施方案中,亲和试剂与肽、多肽或蛋白质中的乳酸酰化赖氨酸的结合取决于乳酸酰化赖氨酸的周围肽序列。所述周围肽序列可包含至少约1、2、3、4、5、6、7、8、9、10或更多的残基,且其应位于所述乳酸酰化赖氨酸的n端和c端侧的任一端或两端上。例如,该结合可能取决于乳酸酰化赖氨酸的n端侧和/或c端侧上的至少一个或两个氨基酸残基。
[0047]
在一些其它实施方案中,亲和试剂与肽、多肽或蛋白质中的乳酸酰化赖氨酸的结合不取决于乳酸酰化赖氨酸的周围肽序列。例如,亲和试剂可以是抗乳酸酰化赖氨酸泛抗体。
[0048]
本发明还提供了一种分离亲和试剂的方法,该亲和试剂可特异性地结合肽、多肽或蛋白质中的乳酸酰化赖氨酸。
[0049]
当亲和试剂为蛋白质时,该分离方法可包括将蛋白库(也称为展示库或退化蛋白库)暴露于包含乳酸酰化赖氨酸的肽中,使得来自蛋白库的蛋白质特异性结合到乳酸酰化赖氨酸中并与肽、多肽或蛋白质形成结合复合物。该方法还可从结合复合物中分离出蛋白质。该分离出的蛋白质即为亲和剂。
[0050]
蛋白库可包含许多退化蛋白质序列,其可包含两个区域:一个或多个固定肽序列区域和多个退化氨基酸序列。蛋白库可以是噬菌体蛋白库、酵母蛋白库、细菌蛋白库、核糖体蛋白库或包含具有随机氨基酸序列的肽的其他合成蛋白库。
[0051]
若亲和试剂是抗体,则其可以通过本领域已知的不同方法被分离出来。例如,分离方法可包括用包含乳酸酰化赖氨酸的肽、多肽或蛋白质免疫一宿主,由此使其产生抗体,从而进一步从宿主中分离出抗体。因此,分离出的抗体即为亲和剂。
[0052]
宿主可以是适于产生抗体的哺乳动物,例如,老鼠、兔子、山羊、骆驼科动物(如羊驼和骆驼)或软骨鱼。由于选用宿主的不同,产生的抗体可能包含两条链(重链和轻链)或被称为纳米抗体的一条链(骆驼科中仅有重链抗体)。
[0053]
该分离方法中,肽、多肽或蛋白质可在乳酸酰化赖氨酸的n端侧和/或c端侧上具有至少两个、三个、四个或五个氨基酸残基。
[0054]
该分离方法中,肽、多肽或蛋白质可衍生自包含赖氨酸乳酸酰化位点的组蛋白或其片段,其可被乳酸酰化或不被乳酸酰化,但最好被乳酸酰化。
[0055]
具有乳酸酰化赖氨酸的肽的实例可包含表1所示中的一个或多个肽。不具有乳酸酰化赖氨酸的肽的实例可包含与表1所示的那些相同的氨基酸序列,但赖氨酸乳酸酰化位点应未乳酸酰化。这些肽的n端或c端可延伸1
‑
20个残基。
[0056]
分离方法进一步包括从宿主的抗血清中纯化抗体,或利用来自宿主的脾细胞来产生单克隆抗体。在一些实施方案中,当位点被乳酸酰化时,抗体会特异性结合到具有赖氨酸乳酸酰化位点的组蛋白或片段中,但当该位点未被乳酸酰化时,则不会结合。在一些其它实施方案中,当位点未被乳酸酰化时,抗体会特异性结合到具有赖氨酸乳酸酰化位点的组蛋
白或片段中,但当该位点被乳酸酰化时,则不会结合。
[0057]
该方法还可进一步包括通过对分离的抗体进行高效液相色谱(hplc)
‑
质谱分析来推导抗体序列,然后对来自免疫宿主的骨髓(或b细胞)的所有可能的igg蛋白序列(源自cdna序列)进行蛋白质序列数据库搜索。iggcdna序列可使用已知技术,通过rt
‑
pcr产生的iggcdna的常规dna测序技术手段获得。衍生的重链和轻链可变区(vh和vl)可进行进一步配对(如果igg为来自诸如小鼠或兔子此类宿主的双链抗体)。此类配对无需在那些源于羊驼的纯重链抗体(或非抗体)的igg中进行。可通过使用已知技术手段,利用抗体序列信息来生成抗体。
[0058]
本发明提供了一种检测蛋白质或其片段中的乳酸酰化赖氨酸的方法。该检测方法包括(a)将蛋白质或其片段与本发明中的亲和试剂接触以形成蛋白质或其片段与亲和试剂的结合复合物,以及(b)检测结合复合物。且该蛋白质可以是组蛋白。亲和试剂可特异性结合到本发明肽中的乳酸酰化赖氨酸中。结合复合物的存在表明蛋白质或其片段中存在乳酸酰化赖氨酸。也可通过使用本领域的各种常规方法来检测结合复合物。该方法进一步包括定量蛋白质或其片段中的乳酸酰化赖氨酸。结合复合物的量可表明蛋白质或其片段中的乳酸酰化赖氨酸的量。
[0059]
本发明中的每种检测方法都会提供一种试剂盒。该试剂盒包含特异性结合到肽中的乳酸酰化赖氨酸的亲和试剂,也包括用于使用根据本发明提供的检测方法的亲和试剂检测蛋白质或其片段中的乳酸酰化赖氨酸的说明书。
[0060]
本发明中的每种分离方法都会提供一种试剂盒。该试剂盒包括包含乳酸酰化赖氨酸的肽。试剂盒还包含用于分离亲和试剂的说明书,且该亲和试剂可与根据本发明的分离方法的肽中的乳酸酰化赖氨酸进行特异性结合。
[0061]
本发明提供融合蛋白报告基因。该融合蛋白报告基因包含位于供体荧光部分和受体荧光部分侧翼的核心。所述核心包含肽,所述肽包含赖氨酸乳酸酰化位点和赖氨酸乳酸酰化结合域。本文中使用的术语“赖氨酸乳酸酰化结合域”是指蛋白质序列中能够特异性结合到赖氨酸乳酸酰化结合位点的区域,其可被乳酸酰化也可不被乳酸酰化。
[0062]
本发明中的融合蛋白报告基因可用于测定样品中的蛋白质赖氨酸乳酸酰化水平或通过使用荧光共振能量转移(fret)筛选能够调节蛋白质赖氨酸乳酸酰化的试剂。当荧光团接近时,fret会涉及到光子能量在荧光团之间的转移。在本领域中,供体荧光部分和受体荧光部分适合于fret已为人所知。在融合蛋白报告基因中,供体荧光部分可选自由青色荧光蛋白(cfp)、增强青色荧光蛋白(ecfp)及其a206k突变体组成的组,受体荧光部分可选自由黄色荧光蛋白(yfp)、增强黄色荧光蛋白(eyfp)、citrine、venus及其a206k突变体组成的组。
[0063]
融合蛋白报告基因中的肽可包含本发明中的肽。其可衍生自包含赖氨酸乳酸酰化位点的组蛋白或片段,并且该组蛋白或片段可在赖氨酸乳酸酰化位点处被乳酸酰化或不被乳酸酰化。
[0064]
赖氨酸乳酸酰化位点可位于组蛋白的n
‑
末端、c
‑
末端或核心区域。在本领域中,组蛋白(例如,人或小鼠h1.2、h2a、h2b、h3或h4)的n
‑
末端、c
‑
末端和核心区域已为人所知。
[0065]
所述融合蛋白报告基因可包含一个或多个赖氨酸乳酸酰化结合域。赖氨酸乳酸酰化结合域可衍生自本发明中的赖氨酸乳酸酰化特异性亲和试剂。
[0066]
在一些实施方案中,肽中的赖氨酸乳酸酰化位点未被乳酸酰化,并且当该位点被乳酸酰化时,赖氨酸乳酸酰化结合域会特异性地结合到肽中的赖氨酸乳酸酰化位点中,但当该位点未被乳酸酰化时,则不会结合。
[0067]
在其它实施方案中,肽中的赖氨酸乳酸酰化位点被乳酸酰化,并且当该位点未被乳酸酰化时,赖氨酸乳酸酰化结合域会特异性地结合到肽中的赖氨酸乳酸酰化位点中,但当该位点被乳酸酰化时,则不会结合。
[0068]
赖氨酸乳酸酰化位点可与具有连接分子的赖氨酸乳酸酰化结合域结合。连接分子可以是具有任何氨基酸序列的肽,并且可以具有约1
‑
50个氨基酸,较好情况下为1
‑
30个氨基酸,更好情况下为2
‑
15个氨基酸。在一些实施方案中,连接分子可以是
‑
gly
‑
gly
‑
。不论融合蛋白报告基因中的赖氨酸乳酸酰化位点是否被乳酸酰化或与赖氨酸乳酸酰化结合域结合,都可通过调整连接分子的长度和含量以优化供体荧光部分和受体荧光部分之间的潜在荧光共振能量转移(fret)。
[0069]
融合蛋白报告基因可进一步包含靶向多肽。靶向多肽可选自由受体配体、核定位序列(nls)、核输出信号(nes)、质膜靶向信号、组蛋白结合蛋白和核蛋白组成的组。
[0070]
一种测定样品中蛋白质赖氨酸乳酸酰化水平的方法。该方法包括检测样品中的乳酸酰化赖氨酸,也包括(a)将所述样品与本发明的融合蛋白报告基因接触,以及(b)将所述供体荧光部分与所述受体荧光部分在接触之前和接触之后的荧光共振能量转移(fret)水平进行比较。fret水平表示样品中蛋白质赖氨酸乳酸酰化的水平。接触后,fret水平可能增加也可能减少。
[0071]
本发明还提供了一种测定样品中蛋白质去赖氨酸乳酸酰化水平的方法。所述方法包括(a)将所述样品与本发明中的融合蛋白报告基因接触,以及(b)将所述供体荧光部分与所述受体荧光部分接触后的荧光共振能量转移(fret)水平与接触前的荧光共振能量转移(fret)水平进行比较。fret的水平表示样品中蛋白质去赖氨酸乳糖化的水平。接触后,fret水平可能增加或减少。
[0072]
对于本发明中的测定方法,样本可以是生物样本(例如体液或血清)。其中生物样本可包括细胞、组织活检或临床体液,其来源可从受试者(例如,小鼠、大鼠或人)中获得。受试者健康水平需正常,并可能患有或可能倾向于患有蛋白质赖氨酸乳酸酰化或去赖氨酸乳酸酰化相关的疾病,该疾病可能为分别与蛋白质赖氨酸乳酸酰化或去赖氨酸乳酸酰化的异常调节相关的任何疾病或病症。这种紊乱或疾病的实例可能包括癌症、神经退行性疾病、衰老、代谢紊乱和发育不良。
[0073]
本发明中的测定方法还可包括将样品中的fret水平与控制fret水平进行比较。控制fret水平可以是从健康或未患或易患赖氨酸乳酸酰化相关疾病的受试者中获得的对照样品中的fret水平。样品中的fret水平可能高于或低于控制fret水平。
[0074]
本发明中的测定方法还可以包括向样品中添加试剂。在一些实施方案中,可得出所述试剂能促进或抑制蛋白质赖氨酸乳酸酰化。在一些其它实施方案中,所述试剂是蛋白质赖氨酸乳酸酰化调节剂的筛选候选物。筛选候选物可以是化合物或生物分子。
[0075]
本发明中的每种测定方法都会提供一种试剂盒。该试剂盒包含本发明的融合蛋白。该试剂盒还可包括指导如何执行该方法的说明书。
[0076]
本发明还提供了一种用于分离含有乳酸酰化赖氨酸的肽的试剂盒。该试剂盒包含
分离的赖氨酸乳酸酰化特异性亲和试剂,该试剂能够特异性结合到包含乳酸酰化赖氨酸的肽。
[0077]
本发明提供了一种根据需要用于治疗或预防患有蛋白质赖氨酸乳酸酰化相关疾病的受试者的方法。该方法包括向受试者提供包含调节蛋白质赖氨酸乳酸酰化试剂的有效量的组合物。该试剂可以是通过本发明确定方法验证的筛选候选物。蛋白质赖氨酸乳酸酰化可以是组蛋白赖氨酸乳酸酰化。
[0078]
本发明提供了一种根据需要用于治疗或预防患有蛋白质或去赖氨酸乳酸酰化相关疾病的受试者的方法。该方法包括向受试者提供包含调节蛋白质去赖氨酸乳酸酰化试剂的有效量的组合物。该试剂可以是通过本发明确定方法验证的筛选候选物。蛋白质娶赖氨酸乳酸酰化可以是组蛋白去赖氨酸乳酸酰化。
[0079]
在这里,当提及诸如量、百分比等的可测量值时所使用的术语“关于”意指包括以下各项的变化:
±
20%或
±
10%,
±
5%时较好,
±
1%时更好,
±
规定值的0.1%甚至更加好,具体值需视情况而定。
[0080]
例1.组蛋白乳酸酰化对基因表达的代谢调节
[0081]
受衍生自细胞代谢物的各类组蛋白酰化这一发现的启发,研究人员预测并确定赖氨酸乳酸酰化(kla)是一种新型的组蛋白标记,且其可被乳酸刺激(如图1a所示)。该结论的初步证据来自于对来自mcf
‑
7细胞的胰蛋白酶消化核心组蛋白的高效液相色谱(hplc)
‑
质谱图(ms/ms)分析中检测到的三种蛋白水解肽中的赖氨酸残基的72.021道尔顿的质量偏移的观察(图1b)。该质量转移与向赖氨酸残基的ε氨基中添加乳酸基相同。
[0082]
为了验证组蛋白中赖氨酸乳酸酰化的存在,研究人员采用了四种正交法。在前两种方法中,研究人员将hplc
‑
ms/ms与一种合成肽及其体内衍生的对应物进行比较,以确定这两种版本的肽在hplc中的色谱洗脱和ms/ms中的裂解谱是否具有相同的化学性质。为此,研究人员制备了三种带有kla修饰的组蛋白肽:h3k23 qlatklaaar(序列号85)、h2bk5 pelaklasapapk(序列号86)和h4k8 ggklaglgk(序列号87)。每对肽在hplc中共同洗脱,且都具有可进行比较的ms/ms质谱图(图1b)。为了进一步证实这一修饰,研究人员研制了一种泛抗kla抗体。通过使用泛抗kla抗体得出的的免疫印迹证实了组蛋白kla的存在,并显示组蛋白kla水平在外源性l
‑
乳酸的作用下以剂量依赖性的方式升高。之后,质谱分析分别从人mcf
‑
7细胞和小鼠骨髓源性巨噬细胞(bmdm)中鉴定出26个和16个组蛋白kla位点(图1c)。最后,使用同位素l
‑
乳酸钠(
13
c3)进行代谢标记实验,然后进行ms/ms分析,证明了赖氨酸乳酸酰化可从乳酸中获得。总之,这些实验证明组蛋白kla是一种来自乳酸的体内蛋白质翻译后修饰。
[0083]
鉴于细胞外乳酸可以刺激组蛋白kla,研究人员假设细胞内乳酸的产生也会影响组蛋白kla的水平。研究人员将mcf
‑
7和其他细胞系暴露于不同浓度的葡萄糖中,该葡萄糖是细胞内乳酸的主要来源。结果可得出,葡萄糖以剂量依赖性的方式诱导乳酸的产生和组蛋白kla水平(图2a,b)。相反,2
‑
脱氧
‑
d
‑
葡萄糖(2
‑
dg),即一种不可代谢的葡萄糖类似物,却降低了乳酸的产生和组蛋白kla的水平(图2c,d)。此外,利用同位素葡萄糖(u
‑
13c6)进行的代谢标记实验和ms/ms分析表明,赖氨酸乳酸酰化是葡萄糖内源性衍生而来的。定量蛋白质组学分析表明,组蛋白kla和kac在mcf
‑
7细胞中具有不同的
13
c葡萄糖掺入动态。
13
c标记的组蛋白kac在6小时达到稳定状态,这类似于liu等人在hct116细胞中的观察(细胞175,
502
‑
513e513,doi:10.1016/j.cell.2018.08.040(2018)。相反,组蛋白kla在24小时内增加。免疫印迹结果证实了mcf
‑
7和其他细胞系的ms/ms数据。
[0084]
乳酸的产生取决于糖酵解和线粒体代谢之间的平衡。研究人员对在这两种途径下酶的活性是否可以调节乳酸水平进行了测试,进而使乳酸水平调节组蛋白kla(如图2e所示)。用二氯乙酸钠(dca)和草胺酸盐分别通过调节丙酮酸脱氢酶(pdh)和乳酸脱氢酶(ldh)的活性来抑制乳酸的产生。如预期所料,这两种化合物降低了细胞内乳酸水平(图2f)以及组蛋白kla水平(图2g,h)。相反,鱼藤酮,一种线粒体呼吸链复合物i的抑制剂,可以驱动细胞进行糖酵解,从而增加细胞内乳酸和组蛋白kla水平(图2f,i)。用细胞培养中的氨基酸稳定同位素标记法(silac)定量组蛋白kla和kac标记,ms/ms分析证实了dca
‑
和鱼藤酮处理的mcf
‑
7细胞的免疫印迹数据。此外,u
‑
13
c6葡萄糖标记实验表明,dca抑制了
13
c与组蛋白kla的结合,而非与kac的结合。总之,这些观察表明内源性乳酸的产生是组蛋白kla水平的关键决定因素。
[0085]
糖酵解和乳酸生成的增加与多种细胞过程有关。为研究组蛋白kla在生理条件下是否受糖酵解的调节,研究人员选择了两个模型系统:缺氧和m1巨噬细胞极化。在对缺氧的反应中,细胞通过抑制氧化磷酸化和增强糖酵解,刺激乳酸的产生来重编其代谢。缺氧诱导mcf
‑
7细胞内产生乳酸并增加组蛋白kla水平,但并不增加kac水平(图2j,k)。基于silac的组蛋白kla和kac的质谱定量证实了免疫印迹数据。在hela和raw264.7细胞中也获得了类似的结果。此外,研究人员发现ldh抑制剂(草胺酸盐)或pdk1抑制剂(dca)可减弱由缺氧诱导的乳酸和组蛋白kla的生成。在常氧条件下,删除ldha和ldhb可完全抑制hepg2细胞的乳酸和组蛋白kla的生成。由于细胞活力差,缺氧条件无法进行测试。
[0086]
新的证据表明,乳酸在先天性和适应性免疫细胞中都具有调节功能,并可诱导基因表达的剧烈变化,这表明乳酸不仅仅是糖酵解的“废物”。促炎性m1巨噬细胞会进行有氧糖酵解代谢重编,从而产生乳酸,而抗炎性m2巨噬细胞会触发氧化磷酸化和脂肪酸氧化增加的代谢程序。因此,研究人员对组蛋白kla标记及其动态的发现表明了在m1巨噬细胞极化过程中调节基因表达的作用。
[0087]
为了验证这一假设,研究人员检测了用脂多糖(lps)和干扰素
‑
γ(ifnγ)处理bmdms后,m1巨噬细胞极化过程中乳酸生成和组蛋白kla标记的动态变化。研究人员观察到m1激活后16至24小时内细胞内乳酸水平升高(图3a),这与组蛋白kla水平升高密切相关(图3b,c)。相反,组蛋白kac水平在这些时间点降低(图3b,c)。这种差异模式得到u
‑
13
c6葡萄糖标记实验证实,
13
c标记的组蛋白kac在标记后3h达到峰值,之后下降到稳定状态,而组蛋白kla则在24h内增加。另外,ldha特异性抑制剂gne
‑
140抑制了组蛋白kla中
13
c的掺入,但对kac的掺入无影响。由于每4小时用新鲜培养基补充细胞并不影响kla水平,所以可以得出组蛋白kla在m1极化过程中的增加是内生的,而非是受旁分泌影响,。乳酸生成和组蛋白kla的增加也对m1巨噬细胞具有特异性,因为它们在m2极化的bmdms中未被观察到(图3d),而后者更依赖于脂肪酸氧化。
[0088]
组蛋白修饰在基因表达调控中起重要作用。为了研究巨噬细胞m1极化24小时后组蛋白kla相关基因,研究人员使用抗h3k18la或抗h3k18ac抗体实施了rna
‑
seq和结合位点分析法,其特异性通过斑点印迹、chip
‑
qpcr分析和免疫印迹得到验证。
[0089]
研究人员的结合位点分析法数据显示h3k18la和h3k18ac都在启动子区域富集(
±
2kb左右的转录起始位点),并且mrna水平呈稳定状态。此外,h3k18la升高(增加2倍)比h3k18la降低(减少2倍)可标记更多的基因,而h3k18ac修饰则相反(图3e)。此外,大多数h3k18la升高的基因是特异性的,因为这些基因中的68%(1223/1787)没有显示显著升高的h3k18ac(图3e,f)。相反,未发现h3k18ac特异性基因(图3e,f)。
[0090]
为研究h3k18la标记与基因表达之间的相关性,研究人员在lps/ifnγ挑战后0、4、8、16和24小时进行了rna
‑
seq。如预期所料,炎症反应基因(如nos2)在lps/ifnγ挑战后4小时就被诱导,同时它们的表达水平也在稳步下降(图3g)。有趣的是,由h3k18la升高特异性标记的1223个基因更有可能在m1极化的稍后时间点(16或24小时)被激活或再次激活(图3h),这与稍后时间点的细胞内乳酸和组蛋白kla水平的诱导密切相关(图3a
‑
c)。基因本体(go)分析显示这些h3k18la特异性基因在独立于炎症的生物途径中富集。其中一个富集的途径是伤口愈合处(例如arg1),它与m2类表型有关(图3h)。为了用更多生理相关刺激物来证实这些发现,研究人员用活或死的革兰氏阴性细菌(大肠杆菌、鲍曼不动杆菌和铜绿假单胞杆菌)来刺激m1极化。与lps相似,细菌诱导生成乳酸和全局组蛋白kla,而非是组蛋白kac水平(图3i),同时早期细胞因子和晚期arg1表达的动态保持不变(图3j)。
[0091]
精氨酸代谢是巨噬细胞极化过程中一个关键的分解代谢和合成代谢过程。m1巨噬细胞被认为具有较低的arg1并可通过一氧化氮合成酶代谢精氨酸产生一氧化氮以杀死病原体,而m2巨噬细胞具有较高的arg1,其可产生鸟氨酸促进伤口愈合。arg1蛋白水平和活性与它们的rna动态一致,并且在m1极化24
‑
48小时后显著增加,而nos2蛋白水平和功能在m1极化12小时后达到峰值,并在随后的时间点内下降(图3k)。总的来说,这些发现表明,在晚期,m1激活过程中诱导乳酸可能产生一个更稳定的表型,这与与m2类表型有一些相似之处。事实上,以前的研究表明,用肿瘤细胞源性乳酸治疗bmdms可以驱动肿瘤相关巨噬细胞(tams)的m2类表型特征。在小鼠肿瘤模型中,研究人员观察到在从b16f10黑色素瘤和llc1肺癌分离的tams中,arg1表达与组蛋白kla水平呈正相关,而与组蛋白kac水平无关。
[0092]
m1极化过程中基因表达的变化是由lps/ifnγ诱导的复杂信号传递引起的,这包括乳酸和组蛋白kla的诱导。为了证实乳酸和组蛋白kla在基因表达调控中的作用,研究人员在m1极化期间操纵了乳酸水平,并检测其对arg1(一种m2类基因)表达的影响。研究人员首先通过删除ldha(lysm
‑
cre
/
‑
ldha
fl/fl
)来降低乳酸水平。缺乏ldha的巨噬细胞在m1极化过程中,其乳酸生成和全局组蛋白kla水平均有降低(图4a,b)。虽然在巨噬细胞中删除ldha不会改变促炎细胞因子的表达,但它减弱了arg1并减少了arg1启动子处的组蛋白kla标记(图4c,d)。当巨噬细胞在糖酵解抑制剂(2
‑
dg、dca和gne
‑
140)存在下被m1极化时,也获得了类似的结果。接下来,研究人员通过外源性乳酸处理m1巨噬细胞来提高乳酸水平。外源性乳酸可增加细胞内乳酸(图4e)和组蛋白kla水平(图4f),并诱导arg1启动子的arg1表达(图4g)和kla水平(图4h)。相反,外源性乳酸不影响早期促炎基因的表达。此外,外源乳酸在m1极化过程中增强了其他m2类基因的表达,如vegfa。因此,这一数据证实了乳酸和组蛋白kla在m1巨噬细胞极化过程中有着驱动m2类基因表达的积极作用。
[0093]
研究人员观察到的乳酸、h3k18la和m2类基因表达之间的相关性并不一定意味着组蛋白kla标记是一个致病因素。先前的研究表明外源性乳酸可以通过hif1a改变未受刺激(m0)巨噬细胞中arg1和vegfa的表达。然而,在m1极化过程中,由于hif1a蛋白在早期时间点被诱导,导致hif1a与糖酵解基因的启动子结合而非arg1和vegfa,所以hif1a对arg1和
vegfa的调节并不重要,。
[0094]
为检测组蛋白kla是否在转录调控中起直接作用,研究人员使用了一种无细胞重组染色质模板组蛋白修饰和转录分析方法,该方法之前曾被用于证明p53和p300依赖性组蛋白kac的直接转录激活。在该试验中,乙酰辅酶a被l
‑
乳酸辅酶a取代(通过hplc和ms验证),其证明了p53依赖性、p300介导的h3和h4乳酸酰化以及相应的转录效应的活性。这种效应与乙酰辅酶a依赖性组蛋白乙酰化和转录的效应相似。为证实转录直接由组蛋白的乳酸酰化而不是核提取物中的其他蛋白质介导,重组染色质与组蛋白尾部具有赖氨酸(k)到精氨酸(r)突变的核心组蛋白被进行了重组。与野生型组蛋白相比,h3和h4突变消除了p300和p53依赖的转录,而h2a或h2b突变无法做到。综上所述,这些发现表明组蛋白乳酸酰化和组蛋白乙酰化一样,可以在所描述的条件下可直接促进基因转录。为了检测p300在细胞中作为组蛋白kla写入蛋白的潜在活性,研究人员在hek293t细胞中过度表达了p300,并观察到组蛋白kla水平稍有增加。相反,hct116和hek293t细胞中p300的缺失会降低组蛋白kla水平。尽管研究人员不能排除p300在这些细胞中的间接作用,但结合体外酶促结果,这些数据表明p300是一种潜在的组蛋白kla写入蛋白。
[0095]
为应对细菌感染,巨噬细胞必须迅速作出反应,产生大量促炎性细胞因子,以帮助杀死细菌,并将更多的免疫细胞招至感染部位。在这一过程中,巨噬细胞转化为有氧糖酵解以支持促炎性细胞因子在m1激活期间的表达,并产生瓦伯格效应。随着时间的推移,这种代谢转化还会增加细胞内的乳酸。研究人员发现,在暴露于m1极化刺激16
‑
24小时后,其也会刺激组蛋白赖氨酸乳酸酰化。促炎基因不需要组蛋白乳糖化的诱导或抑制。相反,它可以作为一种机制来启动传统上与m2类巨噬细胞相关的稳态基因的表达。该研究结果支持的模型为:在m1极化期间发生的有氧糖酵解的转化启动了一个“乳酸计时器”,它利用表观遗传机制在后期诱导m2类特征,这也许是为了帮助修复宿主在感染期间产生的附带损伤。
[0096]
高水平的乳酸(例如,在某些类型的肿瘤组织中为40mm)也与癌症和其他疾病的主要特征有关。鉴于kla修饰可被乳酸刺激并有助于基因表达,kla修饰将有可能填补研究人员在对乳酸密切相关的各种生理病理学(如感染、癌症)的理解中,产生的重要知识空缺。
[0097]
方法
[0098]
材料。
[0099]
泛抗kac(ptm
‑
101)、泛抗kla(ptm
‑
1401)、抗h3k18la(ptm
‑
1406)、抗h4k5la(ptm
‑
1407)和抗h4k8la(ptm
‑
1405)抗体由ptmbio公司(chicago,il)制备;抗组蛋白h3(ab12079)、抗h3k18ac(ab1191)和抗h3k27ac(ab4729)抗体购自abcam(cambridge,ma);从activemotif(carlsbad,ca)处获得的果蝇spike
‑
in抗体(61686)和spike
‑
in染色质(53083);抗ldha(2012s)抗体来自cellsignalingtechnology公司(danvers,ma);反
‑□‑
微管蛋白(05
‑
829)和抗ldhb(abc927)抗体来自milliporesigma(burlington,ma);抗hif
‑
1a(nb100
‑
105)抗体来自novusbiologicals(littleton,co);抗inos(gtx130246)和抗arg1(gtx109242)抗体购自genetex(irvine,ca);抗p300(sc
‑
584)来自santacruzbiotechnology公司(dallas,tx);抗cd11b单克隆抗体(m1/70)、pe
‑
氰基7(25
‑
0112
‑
82)和抗f4/80单克隆抗体(bm8)、apc(17
‑
4801
‑
82)来自thermofisherscientific(waltham,ma);大肠杆菌o111的脂多糖:b4(l4391)、l
‑
乳酸钠(71718)、l
‑
( )
‑
乳酸(l6402)、二氯乙酸钠(347795)、六水氯化钴(c8661)、鱼藤酮(r8875)和乙酰辅酶a(a2056)
购自sigma
‑
aldrich(st.louis,mo);l
‑
乳酸钠(13c3,98%)(clm
‑
1579
‑
pk)和d
‑
葡萄糖(u
‑
13c6,99%)(clm
‑
1396
‑
1)购自剑桥同位素实验室(andover,ma)。重组小鼠ifn
‑
γ蛋白质(485
‑
mi
‑
100)来自r&dsystems(bergischgladbach,德国);小鼠白细胞介素
‑
4(130
‑
097
‑
760)来自miltenyibiotec(bergisch
‑
gladbach,德国);改良测序级胰蛋白酶来自promega(madison,wi);乳酸比色测定试剂盒ii(k627
‑
100)、精氨酸酶活性比色测定试剂盒(k755
‑
100)和一氧化氮合酶(nos)活性测定试剂盒(k205
‑
100)购自biovision,inc(milpitas,ca)。
[0100]
细胞培养。
[0101]
mcf
‑
7、mda
‑
mb
‑
231、hela、a549、hepg2、mef和raw 264.7细胞从美国标准菌库中获得,并在添加10%fbs和1%谷氨酰胺的dulbecco改良eagle培养基中培养(gibco,gaithersburg,md)。细胞会进行例行支原体污染检测(mp0035,sigma
‑
aldrich,st.louis,mo),并且在实验中只使用阴性细胞。未进行特异细胞系验证。对于缺氧条件下细胞的生长,其会在一个专门的、湿润的小室中进行,并在指定的时间内与1%氧气/94%氮气/5%二氧化碳平衡。
[0102]
小鼠实验。
[0103]
所有动物的使用和实验都得到了芝加哥大学动物保护和使用委员会(acup#72209)的批准。ldha
fl/fl
小鼠(jackson实验室,030112)和lysmcre小鼠(jackson实验室,004781)被用于繁衍lysmcre
/
‑
ldha
fl/fl
和同窝对照lysmcre
‑
/
‑
ldhafl/fl小鼠。以下引物用于基因分型:ldha正向:ctgagcacccatgtgaga(序列号:88)和ldha反向:agcaactccaagtgga(序列号:89)。lysmcre:cccagaaaatgccagattacg(序列号:90),lysm普通:cttgggctgccagaatttcc(序列号:91)和lysmwt:ttacagtcggccagctgac(序列号:92)。巨噬细胞来源于8周龄雄性c57bl/6小鼠的骨髓。用5ng/ml的lps和12ng/ml的ifnγ或20ng/ml白细胞介素4刺激bmdm细胞产生m1或m2表型,持续24小时或指定时间。用细菌感染bmdm细胞,隔夜培养大肠杆菌、鲍曼不动杆菌或铜绿假单胞杆菌,并在rpmi
‑
1640中稀释,且在2倍和20倍感染率下加入6孔板中的bmdm细胞。控制板中用多聚甲醛灭活细菌进行感染或在无细菌的情况下用5ng/ml脂多糖(lps)处理。在2170转/分转速下的离心培养板中培养30分钟,以促进感染,然后在5%二氧化碳下,温度为37摄氏度的加湿培养箱中培养30分钟。为了杀灭细胞外细菌,用包含100μg/ml庆大霉素的新鲜培养基取代融合细胞单层上的培养基,继续培养1h。培养后,从感染细胞中取出培养基,用含25μg/ml庆大霉素的新鲜培养基将其替换。为保持一致性,lps处理的细胞和感染死细菌的细胞也用庆大霉素处理。细胞在裂解前培养24h。将bmdm细胞随机但非盲目地分配到不同的治疗组。
[0104]
肿瘤接种和肿瘤相关巨噬细胞的分离。
[0105]
将llc1细胞(0.5
×
106)或b16f10细胞(1
×
106)注射到7周龄c57bl/6小鼠(jackson实验室)中。当肿瘤达到约600mm3时,处死小鼠以进行肿瘤分离。肿瘤用4型胶原酶(worthington,3mg/ml)和透明质酸酶(sigma,1.5mg/ml)在1%bsa/pbs、37℃温度下以200转/分的转速摇动30分钟。然后通过70μm细胞过滤器过滤消化的肿瘤,随后进行rbc溶解步骤并通过另一个40μm过滤器。将细胞重新悬浮到分离缓冲液(0.1%bsa/pbs,2mmedta)中,分层到ficollpaquetmplus(gehealthcare)上,并在450g下离心30分钟而不使其破裂。取中间白细胞层获得单核免疫细胞。然后按照公司指示使用cd11b微球(mitenyibiotec)分离
tam。用cd11b和f4/80抗体流式细胞仪检测tams的纯度。数据通过flowjov.10.4.1进行量化。
[0106]
肽免疫沉淀。
[0107]
使用标准酸提取方案从人mcf
‑
7或小鼠bmdm细胞中提取组蛋白(shechteretal,natprotoc 2,1445
‑
1457,doi:10.1038/nprot.2007.202(2007),并按照制造商的说明进行胰蛋白酶消化。泛抗kla或泛抗kac抗体首先与n蛋白asepharose珠(gehealthcarebiosciences,pittsburgh,pa)结合,然后与胰蛋白酶消化的组蛋白肽在温度为4℃下温和搅拌并过夜。然后用netn缓冲液(50mmtris
‑
clph 8.0、100mmnacl、1mmedta、0.5%np
‑
40)清洗珠子三次,用etn缓冲液(50mmtris
‑
clph 8.0、100mmnacl、1mmedta)清洗两次,用水清洗一次。用0.1%tfa从珠中洗脱肽,并在speedvac系统中干燥(thermofisherscientific,waltham,ma)。
[0108]
hplc/ms/ms分析。
[0109]
将肽样品装载到自制的毛细管柱上(10cm长x 75mmid,3μm粒径,dr.maischgmbh,ammerbuch,germany),该毛细管柱已连接到easy
‑
nlc 1000系统上(thermofisherscientific,waltham,ma)。在缓冲液a(0.1%甲酸水溶液,v/v)中,以2%至90%hplc缓冲液b(0.1%甲酸乙腈溶液,v/v)的梯度分离和洗脱肽,流速为200nl/min,时间为60min(共溶研究为34min)。然后将洗脱的肽离子化并通过q
‑
exactive质谱仪(thermofisherscientific,waltham,ma)进行分析。在m/z 300
‑
1400范围内的orbitrap质量分析仪中获得了完整的质谱,其在一级谱在m/z 200处的分辨率为70000。12个最强烈的带电离子≥2碎裂,其归一化碰撞能量设置为27,并获得了m/z200处分辨率为17500的二级谱。
[0110]
同位素标记实验。
[0111]
mcf
‑
7细胞在dmem高糖培养基和10%fbs中培养。用同位素乳酸标记细胞,用10mm的
13
c3l
‑
乳酸钠将细胞处理24小时。为用同位素葡萄糖标记细胞,需将细胞切换到dmem无葡萄糖培养基(gibco)中24小时,然后补充25mmu
‑
13c6 d
‑
葡萄糖并继续培养三代。提取组蛋白,用胰蛋白酶消化,用泛抗kla抗体免疫沉淀,并如上所述通过hplc/ms/ms分析。
[0112]
基于silac的量化。
[0113]
mcf
‑
7细胞需在“重同位素”(l
‑
赖氨酸
‑
13
c6,
15
n2)或“轻同位素”(l
‑
赖氨酸
‑
12
c6,
14
n2)dmem中培养6代以上,并添加10%透析fbs(serumsourceinternational公司,charlotte,northcarolina),以达到99%以上的标记效率。“重同位素”标记细胞和“轻同位素”标记细胞按1:1的比例混合。提取组蛋白,用胰蛋白酶消化,用泛抗kla抗体免疫沉淀,并如上所述通过hplc/ms/ms分析。定量分析采用maxquant20。从maxquant得到的h/l比值用蛋白质丰度进行标准化。
[0114]
l
‑
乳酸
‑
coa的合成。
[0115]
将l
‑
乳酸(90mg,1mmol)溶解于5ml新鲜蒸馏的ch2cl2中。向该溶液中添加n
‑
羟基琥珀酰亚胺(115mg,1mmol),对反应混合物进行超声处理以获得澄清溶液。然后在一份中添加n,n
’‑
二环己基碳二亚胺(dcc,227mg,1.1mmol)。加入时形成的白色沉淀。反应混合物在室温下搅拌并过夜。然后过滤白色沉淀并用ch3cn进行洗涤。所得有机溶剂通过真空蒸发得到粗产物l
‑
乳酸
‑
nhs(170mg,91%产率),其可直接在下一步中使用而无需进一步纯化。将
0.0065mmol水合辅酶a(5mg)溶解于1.5ml 0.5mnahco3(ph 8.0)中并在冰浴下冷却。然后将0.5mlch3cn/丙酮(1:1v/v)中的l
‑
乳酸
‑
nhs(2.5mg,0.013mmol)逐滴添加到coa溶液中。将反应溶液在4℃下搅拌并过夜,然后用1.0mhcl将ph值调节至4.0使其猝灭。反应混合物用5
‑
45%缓冲液a在缓冲液b中以5ml/分钟的流速梯度纯化30分钟;紫外检测波长分别固定在214和254nm(水中,hplc缓冲液a:0.05%tfa;乙腈中hplc缓冲液b:0.05%tfa)。收集各组分,用液氮速冻后冻干。m=2mg,产率38%1hnmr(400mhz,氧化氘)δ8.57(s,1h),8.33(s,1h),6.12(d,j=5.7hz,1h),4.49(s,1h),4.29
–
4.24(m,1h),4.14(s,2h),3.93(s,1h),3.75(d,j=8.6hz,1h),3.48(d,j=7.6hz,1h),3.35(t,j=6.4hz,2h),3.22(d,j=5.2hz,3h),2.89(q,j=6.2hz,2h),2.32(t,j=6.4hz,2h),1.23(d,j=6.9hz,3h),0.83(s,3h),0.70(s,3h)。计算maldim/z。对于c24h41n7o18p3s [m h] :840.1,发现839.6。
[0116]
基于体外染色质模板的组蛋白修饰和转录分析。
[0117]
重组蛋白的纯化和染色质组装按上述说明实施(tangetal.,细胞154297
‑
310,doi:10.1016/j.cell.2013.06.027(2013)).染色质模板组蛋白修饰和转录分析如前所述(tangetal.,细胞154297
‑
310,doi:10.1016/j.cell.2013.06.027(2013年)),除了使用乳酸
‑
coa代替乙酰l
‑
coa,同时用[α
‑
32p]ctp代替[α
‑
32p]
‑
utp。h3kr、h4kr、h2akr和h2bkr组蛋白突变体与先前描述的相同(tang etal.,细胞154297
‑
310,doi:10.1016/j.cell.2013.06.027(2013))。组蛋白修饰通过免疫印迹法监测,转录产物通过放射自显影法监测(tang etal.,细胞154297
‑
310,doi:10.1016/j.cell.2013.06.027(2013))。
[0118]
rna序列。
[0119]
使用rneasyplus微型试剂盒(74134,qiagen,hilden,germany)从激活的bmdm细胞中提取总rna。以2
‑
4微克总rna为起始材料制备库,并使用illuminatruseqstrandedmrna库制备试剂盒seta(rs
‑
122
‑
2101,illumina,sandiego,ca)。这些库的大小是使用agencourt ampure xp珠(a63882,beckmancoulter,brea,ca)来选择的,平均大小为400bp。使用illuminahiseq4000(双端测序50bp)对库进行测序。
[0120]
rna
‑
seq数据的生物信息学分析:用版本为0.11.4的fastqc评估测序质量。所有的片段都使用版本为2.1.0的hisat2映射到illuminaigenomesucscmm10的参考基因组上。在仅保留百万分之一(cpm)大于四分之一样本的基因,并使用edger软件包的tmm方法对样本库大小进行标准化后,使用版本为3.16.5的edger进行差异表达分析。使用版本为1.6.1.1的perseus进行层次聚类并生成热图(http://www.coxdocs.org/doku.php?id=perseus:start)。log2转化的基因表达值(每千碱基转录的片段,每百万测序片段(rpkm))通过减去每行的平均数进行归一化,并用pearson相关算法进行分层聚类。利用david bioinformaticsresources6.8进行基因本体分析。
[0121]
以下引物用于rt
‑
qpcr分析:arg1:ctccaagcaaggttagag(序列号:93),aggctgtcattaggacatc(序列号:94);vegfa:ccacgagaggagagagagtcc(序列号:95),cgttacagagcctgcacgg(序列号:96);il6:gttctgggaaatcgtgga(序列号:97),tttctgcaagtggcatcg(序列号:98);il1b:tttgagagagagaatgacc(序列号:99),ctcttgttgatgtgctgctg(序列号:100);ifnb1:cagctccagaaaggacgaac(序列号:101),ggcagtgttaactcttctgcat(序列号:102);cxcl10:ccaagtgccgtcatttc(序列号:103),ggctcgcagggatgatttcaa(序列号:104);tnfa:ccctcacactcagatcttct(序列号:105),
gctacgacgtggctacag(序列号:106)。
[0122]
chip
‑
seq。
[0123]
无交联免疫共沉淀是按照公开的协议进行的(cuddapahetal.,coldspringharbprotoc 2009,pdbprot5237,doi:10.1101/pdb.prot5237(2009年),并为了规范化目的加入了spiked
‑
in。根据供应商协议(#61686,activemotif,carlsbad,ca)进行spike
‑
in。简单地说,将50ng spike
‑
in染色质(#53083,活性基序,carlsbad,ca)添加到25μgbmdm染色质与2μg spike
‑
in抗体(#61686,活性基序,carlsbad,ca)与4μg抗h3k18la或抗h3k18ac抗体中。在4℃下培养4小时后,添加蛋白asepharose(17
‑
5280
‑
01,gehealthcarelifesciences,pittsburgh,pa)并再培养2小时,然后用缓冲液tsei(0.1%sds,1%tritonx
‑
100,2mmedta,20mmtris
‑
hclph 8.0,150mmnacl)、tseii(0.1%sds,1%tritonx
‑
100,2mmedta,20mmtris
‑
hclph 8.0,500mmnacl)、缓冲液iii(0.25mlicl,1%np
‑
40,1%脱氧胆酸盐,1mmedta,10mmtris
‑
hclph 8.0)和te缓冲液(1mmedta,10mmtris
‑
hclph 8.0)按顺序进行洗涤。最后用含1%sds和0.1mnahco3的缓冲液洗脱染色质dna。洗脱液用rnasea(12091021,thermofisherscientific,waltham,ma)和蛋白酶k(am2546,thermofisherscientific,waltham,ma)进行消化。根据制造商说明,使用qiaquickpcr纯化试剂盒(#28106,qiagen,hilden,germany)回收dna。
[0124]
chip
‑
seq库是根据制造商的说明书,用accelngs 2splusdna库试剂盒(swiftbiosciences,annarbor,mi)构建的。然后使用tapestation(agilent,santaclara,ca)对库进行扩增和片段大小评估,并使用qubitdsdnahs分析试剂盒(thermofisherscientific,waltham,ma)进行定量。在hiseq4000测序仪(illumina,sandiego,ca)上使用50
‑
nt单端测序配置对索引库进行合并和测序。
[0125]
chip
‑
seq数据的生物信息学分析:用版本为0.11.4的fastqc评估测序质量。使用bowtie版本2.2.6,将所有的片段都映射到illuminaigenomesucscmm10的参考基因组,并且只保留唯一的测序片段。然后使用版本为0.1.19的samtools将文件转换为bam格式,排序并删除重复的pcr。使用版本为2.2.1的macs在q值=0.01下调用峰值。为了量化和直接比较不同样本(m0和m1巨噬细胞)中的h3k18la或h3k18ac,每个基因的启动子区域(转录起始点周围2kb)中唯一映射的h3k18la或h3k18ac片段通过版本为1.5.0
‑
p1的featurecounts进行计数,然后通过相应条件(m0或m1巨噬细胞)的spike
‑
inchip片段计数进行标准化。chip
‑
seq和rna
‑
seq数据中的重叠基因用于所有后续分析。利用david bioinformatics resources 6.8进行基因本体分析。
[0126]
以下引物用于人类细胞中基因启动子区域的qpcr分析:
[0127]
foxo3a
‑
启动子:cagtgaggttg(序列号:107),aaagcctctttgctt(序列号:108);foxo3a
‑
downstream:tgcacagagccagaag(序列号:109),gctcccacagagacgtaa(序列号:110);ldha启动子:taaggggggatacctct(序列号:111),cccaagagaaaaatgcaagc(序列号:112)。以下引物用于小鼠细胞中基因启动子区域的qpcr分析:arg1/arg1 ptm:aagctggcctcagacat(序列号:113),ggtaacccgctggaaaggat(序列号:114);arg1
‑
hre
‑
1kb:cccgaggtttgacccgaagaagaa(序列号:115),ctttacacaggggaccggacc(序列号:116);arg1
‑
hre
‑
2kb:tgtctcagttcca(序列号:117),agcaattggcatctgatgga(序列号:118);vegfa/vegfaptm:cgagctagcactctcccag(序列号:119),aacttctgggcttcgc(序列号:120);vegfa
‑
hre
‑
1kb:ggcacaatttgtgcact(序列号:121),ctgccagactacagtgca(序列号:122);vegfa
‑
hre
‑
2kb:acctgatctctgct(序列号:123)、cagcctctgtatgcga(序列号:124);vegfa
‑
hre
‑
3kb:gcagaacctaggcttcacgt(序列号:125),ttgaagggctgacatggct(序列号:126);eno1:aaggtcagcaagggtcgt(序列号:127),cgtactccgagtccacag(序列号:128);glut1(slc2a1):tagatccctccttgct(序列号:129),gaacacgtagctgctcaca(序列号:130);genedesert:ctgccaggttgtagagagaggg(序列号:131),gccagatcatggcttgg(序列号:132)。
[0128]
数据分析。
[0129]
没有使用数据方法来预先确定样本量。使用graphpadprism 7.0软件确定实验数据差异的显著性。所有涉及统计的数值均以平均值及其标准误呈现。对于无统计数据的数据,除非另有说明,否则至少重复实验三次以确保其的重现性。本文引用的所有文件、书籍、手册、论文、专利、已发表的专利申请、指南、摘要和其他参考文献均以引用方式并入本文。虽然本发明的规范与实践已在本技术中显示和描述,对本领域技术人员显而易见的是提供这些实施方案的意图仅仅是作为示例,且所附权利要求旨在限定本发明的真正范围和精神。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。