1.本发明属于无人机智能控制决策与计算机技术交叉领域,特别涉及了一种基于模仿学习与强化学习的无人机智能决策系统。
背景技术:
2.无人机由于造价相对低廉、机动性好、安全系数高,在各领域的应用愈来愈普遍。然而,传统无人机控制技术依然需要大量人为参与,自主决策生成技术依然是限制无人机自主能力的瓶颈问题。当前,无人机自主决策面临的挑战主要有:1)决策模型求解计算量大,且对实时获得决策结果要求高;2)在实际应用中难以建立精确的无人机数学模型;3)实际飞行过程中环境复杂、存在大量缺失和错误信息,增加了决策难度。
3.当前已有的智能决策方法有专家系统、微分对策、动态规划等。专家系统可根据态势信息与专家规则进行匹配输出决策信息,但其过度依赖规则,使得决策过程缺乏灵活性,对复杂环境适应性不足;微分对策法从数值优化计算角度求解决策问题,但其以精确的无人机数学模型为基础,在实际应用中难以获得;利用近似值函数动态规划方法求解决策问题,在建立统一的标准决策模型时存在困难,且利用数值方法求解时容易造成维数灾难。与传统决策方法不同,强化学习是智能体以“试错”方式进行学习,通过与环境进行交互获得的奖赏指导动作,目标是使智能体获得最大的奖励。相较传统决策方法,强化学习系统需主要依靠自身的经历进行学习,由环境提供的强化信号对产生动作的好坏作出评价,通过有限次地执行能够获得最大奖励的动作,来确定最佳模型,这种决策机制在无人机控制领域展现了巨大潜力。然而,强化学习本质上属于数据驱动的优化算法,对外部环境提供的信息有较强依赖,如何获取高质量的控制决策数据,已成为限制其在无人机测控领域应用的主要瓶颈问题。
技术实现要素:
4.为了克服在无人机自主决策控制过程中,传统决策方法适应性弱、强化学习方法受限于数据获取问题难以发挥效用等问题,本发明提供了一种基于模仿学习与强化学习的无人机智能决策系统,将人为操控知识的模仿学习与复杂环境的自适应强化学习相结合,分步实现无人机决策模型训练,具有较强泛化能力,在应对复杂动态场景时具有较高鲁棒性。
5.本发明采用改的技术方案为:
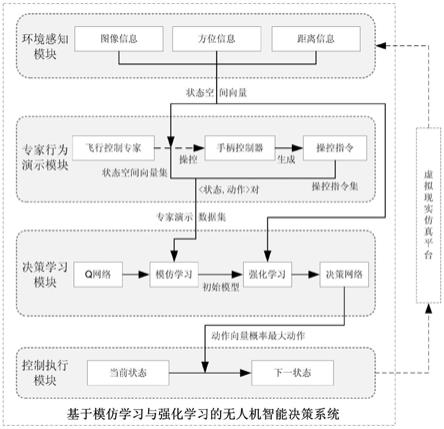
6.一种基于模仿学习与强化学习的无人机智能决策系统,包括环境感知模块、专家行为演示模块、决策学习模块和控制执行模块;
7.环境感知模块:将无人机飞行过程中多种传感器采集到的环境信息提取特征并进行融合,形成状态空间向量输出至演示模块及决策学习模块;其中,环境信息包括图像、方位和距离;
8.专家行为演示模块:收集专家在各种环境和事件下,根据领域知识和操作经验做
出的无人机操控指令,无人机操控指令与环境感知模块提供的数据共同形成专家演示数据集,输出至决策学习模块;
9.决策学习模块:将状态空间向量作为网络结构的输入,根据专家演示数据集对网络结构进行预学习,得到预学习模型,在预学习模型基础上进行训练,学习在不同场景和不同事件下应当采取的决策控制动作,得到最终的决策学习模型,并输出动作向量及其概率至控制执行模块;
10.控制执行模块:得到决策学习模块输出的各动作及其概率后,选择概率最大的动作指令由无人机执行,得到执行动作后无人机所处新的环境状态。
11.其中,环境感知模块的具体处理过程为:输入为无人机飞行过程中多种传感器采集到的环境数据,将图像数据采用resnet18网络进行提取得到高维特征,然后融合无人机所处方位信息和距离信息,形成融合后的状态空间向量作为输出,状态空间向量s
t
=(l
t
,d
t
,x
t,1
,x
t,2
,...,x
t,m
),其中s
t
为无人机t时刻的状态空间向量,l
t
为自身方位,d
t
为当前位置距离目标位置的距离,(x
t,1
,x
t,2
,...,x
t,m
)为当前视野中图像的高维信息。
12.其中,专家行为演示模块的具体处理过程为:输入为环境感知模块输出的状态空间向量,利用专家知识,在虚拟现实仿真平台中进行不同场景和不同时间下的无人机操控,输出操控指令序列,输入的状态空间向量与输出的操控指令序列共同构成专家演示数据集。
13.其中,决策学习模块包括模仿学习模块和强化学习模块;
14.模仿学习模块和强化学习模块具有相同的网络结构,由网络结构q实现,网络结构的输入为环境感知模块得到的状态空间向量,输入层与隐层之间全连接,隐层与输出层之间全连接,最终输出得到动作空间及其概率,动作空间为t时间下采取的动作向量a
t
=(a
t,f
,a
t,b
,a
t,w
,a
t,e
,a
t,u
,a
t,d
);
15.模仿学习模块根据专家演示数据集进行预学习,由专家演示数据集中作为输入的环境图像、方位、距离信息以及专家输出的无人机操控指令进行训练,得到决策学习模块的预学习模型;强化学习模块在预学习模型初始化参数的基础上进行强化训练,学习在不同场景和不同事件下应当采取的决策控制动作,得到最终的决策学习模型。
16.其中,控制执行模块的具体处理过程为:
17.将决策学习模块输出的动作向量a
t
=(a
t,f
,a
t,b
,a
t,w
,a
t,e
,a
t,u
,a
t,d
),选取其中动作概率最大的动作指令执行,得到执行动作后无人机所处的新的环境状态,然后循环迭代环境感知至控制执行整个过程,实现无人机的自主控制决策。
18.本发明的有益效果为:
19.本发明可以对复杂的实时场景作出准确的决策,使无人机从起始点飞行至设定终止点:1)整个飞行过程完全自主决策,可根据环境信息、实时事件等选择无人机控制策略,规避建筑、行人等障碍物;2)无需设计专家规则,而是由模仿学习对专家行为进行行为克隆,得到决策控制网络的粗略初始值,完成决策网络初始化;3)采用深度强化学习方法,通过对飞行过程中的事件、状态设置奖励函数,使决策生成更加准确、泛化性更高。
附图说明
20.图1为本发明系统的决策网络架构设计图。
21.图2是本发明系统组成及信息交互示意图。
22.图3是本发明系统的决策网络训练流程图。
具体实施方式
23.下面结合附图对本发明进一步详细说明。
24.一种基于模仿学习与强化学习的无人机智能决策系统,包括环境感知模块、专家行为演示模块、决策学习模块(包括模仿学习模块和强化学习模块)以及控制执行模块,需要说明的是,该系统一般需要一个虚拟现实仿真平台提供模拟环境数据采集、无人机虚拟模型运行的典型场景,本方案采用微软的airsim平台,该平台仅为系统提供飞行场景及虚拟无人机模型,亦不影响决策系统的独立性,故不作为本决策系统的构成部分。本系统各模块的构建及实现途径如下:
25.1、环境感知模块:将无人机飞行过程中多种传感器采集到的环境信息,包括图像、方位和距离等,提取特征并进行融合,形成状态空间向量为后续专家行为演示模块及决策学习模块提供输入数据。
26.多种传感器得到的环境信息的提取主要是使用resnet18网络对图像信息进行提取得到高维特征,该网络由输入层经过卷积层、池化层和全连接层,提取环境图像中的高维信息;而后,再通过一个全连接层将图像特征、方位特征和距离特征融合为一个环境状态向量s
t
=(l
t
,d
t
,x
t,1
,x
t,2
,...,x
t,m
),其中,s
t
为无人机t时刻的状态,该状态向量包含自身方位l
t
,当前位置距离目标位置的距离d
t
,以及当前视野中图像的高维信息(x
t,1
,x
t,2
,
…
,x
t,m
)。
27.整个网络结构及参数设计参考图1,网络的输入层采用resnet18网络,包含256个神经元,输入图像为64*64像素3通道格式;隐层有两层,分别有128和64个神经元,输出层有6个神经元。输入层与隐层之间全连接,隐层与输出层之间全连接,所有的神经元激活函数均使用relu函数,学习率α设置为0.01。
28.2、专家行为演示模块:通过收集专家在各种环境和各种事件下,根据其领域知识和操作经验做出的无人机操控指令,无人机操控指令与环境感知模块提供的数据共同构成专家演示数据集,为后续决策学习模块的模仿学习部分提供指令学习样本。
29.该模块输入为环境感知模块输出的状态空间向量s
t
=(l
t
,d
t
,x
t,1
,x
t,2
,...,x
t,m
),由无人机操作员(即飞行控制专家)利用专家知识,操控手柄控制器(本方案采用xbox控制器),在虚拟现实仿真平台(本方案采用airsim)中进行大量不同场景、时间下的无人机操控,输出操控指令序列,输入的状态空间向量与输出的操控指令序列构成专家演示数据集,专家演示数据集的数据是所有专家演示的<状态,动作>匹配对,供后续模仿学习使用。
30.3、决策学习模块:包括模仿学习模块和强化学习模块,两个模块具有相同的网络结构,由网络结构q实现,网络结构的输入层为环境感知模块得到的状态空间向量,输入层与隐层之间全连接,隐层与输出层之间全连接,最终输出得到动作空间。模仿学习模块根据专家演示数据集进行预学习,得到决策学习模块的预学习模型;强化学习在预学习模型基础上进行训练,学习在不同场景、事件下应当采取的决策控制动作,得到最终的决策学习模型。
31.3.1模仿学习模块主要根据专家演示数据集进行预学习,即通过行为克隆进行模
仿学习,得到决策学习模块的初始学习模型,作为q网络的初始化参数。模仿学习的训练的过程为:由领域专家提供决策数据{τ1,τ2,...,τ
m
},每个决策数据包括状态和动作序列,即接着将所有的<状态,动作>对抽取出来得到新的数据集:
32.d={(s1,a1),(s2,a2),(s3,a3),...}
33.把状态作为特征,动作作为标记进行分类或回归,从而得到最优决策策略模型。通过收集大量人类专家的操作飞行数据,飞行数据的状态s为飞行时环境场景,动作a为在此场景下的动作。将这些数据输入到神经网络q网络中,使网络的输出尽可能地接近人类实际做出的动作,完成任务。即根据人类专家提供的状态动作对来学习决策控制策略,这一过程即为行为克隆。利用模仿学习,可减小强化学习自由探索的搜索空间,为深度强化学习提供预训练模型。
34.3.2强化学习模块主要在预学习得到的q网络初始化参数的基础上进行强化训练,达到缩小搜索空间,加快收敛的作用。实现途径为在模仿学习模块完成q网络初始化后,通过深度强化学习进一步学习,具体采用dqn算法,dqn算法为基于值函数的算法,dqn更新当前状态s
t
下某动作a的q值q(s
t
,a),首先执行动作a,更新一步到达状态s
t 1
;再把s
t 1
输入q网络,计算s
t 1
下所有动作的q值,取最大的q值加上奖励r作为更新目标;最后计算q(s
t
,a)和max(q(s
t 1
,a)) r之间的差值作为损失loss,并用损失loss更新q网络,即dqn更新按如下公式进行:
[0035][0036]
其中,q(s
t
,a)表示智能体在状态s
t
选择动作a后,一直到最终状态的奖励总和的期望,奖励函数设置为与到达目的地距离有关的奖励r
d
和与飞行时间有关的奖励r
t
之和。
[0037]
r=r
d
r
t
[0038]
与目的地有关的奖励r
d
为:到达目的地获得较大的奖励,离目的地距离d越近获得的奖励越大,碰到障碍物得到一个负奖励。即为:
[0039][0040]
与时间有关的负奖励(惩罚)r
t
随飞行时间的增大而增大,以使飞行任务在更短时间内执行完成。到达最终状态的终止条件设置为到达目的地、飞行到地图边界,或已执行完设定的探索次数,满足其中任意一个即为到达最终状态。经过不断的迭代训练,即可得到一个准确的q网络,作为无人机智能决策系统决策学习模块的核心网络。
[0041]
3.3决策学习模块的q网络模型训练流程参照图3,在训练开始时,决策学习网络的权值由模仿学习得到的参数初进行始化。步骤3
‑
1,参数设置,包括循环训练次数初始值n,设置的飞行目标点,以及地图的边界设置。步骤3
‑
2,设置一次训练中的最大探索次数n。步骤3
‑
3,获取当前的环境信息,输入到环境感知模块。步骤3
‑
4,对环境信息进行特征提取,得到环境的状态空间向量。步骤3
‑
5,将状态空间向量输入到q网络中,得到当前状态下各动作的概率。步骤3
‑
6,计算网络实际值与更新目标之间的误差δ。步骤3
‑
7,利用误差δ,按照反向
传播算法更新网络中的权值。步骤3
‑
8,根据输出的动作概率,选择概率最大的动作执行,得到下一状态。步骤3
‑
9,判断当前状态是否为最终状态,根据是否达到一次训练的最大探索次数n、是否到达了目标点以及是否超出了地图边界来判断,若未到达最终状态,则重复以上步骤继续探索,若达到了最终状态则执行步骤3
‑
10,训练次数加1。步骤3
‑
11,判断训练次数是否达到设定的循环训练次数,若未达到则继续进行新的一次训练,若达到则训练过程结束。
[0042]
4、控制执行模块:负责决策学习模块的具体执行,得到决策学习模块输出的动作空间各动作的概率后,选择概率最大的动作指令由无人机执行,从而得到执行该动作后无人机所处新的环境状态。
[0043]
将决策学习模块输出的动作向量a
t
=(a
t,f
,a
t,b
,a
t,w
,a
t,e
,a
t,u
,a
t,d
)各动作的概率,选取其中概率最大的动作指令执行,从而得到执行该动作后无人机所处的新的环境状态,然后循环迭代环境感知至控制执行整个过程,实现无人机的自主控制决策。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。