一种用于乳腺癌luminal b分型的dna甲基化标记组合物及其应用
技术领域
1.本发明属于生物技术领域,具体涉及一种用于乳腺癌luminal b分型的dna甲基化标记组合物及其应用。
背景技术:
2.乳腺癌是一种异质性疾病,影响着人们的健康,尽管目前的治疗已使乳腺癌的死亡率有所降低,但预计全世界每年因乳腺癌导致的估计死亡人数显著增加,因此,对于乳腺癌的诊断与治疗是十分重要的。由于乳腺癌异质性高的特点,所以乳腺癌的分型对于乳腺癌的诊断与治疗变得尤为重要。乳腺癌分为五个亚型:管腔上皮a型(luminal a),管腔上皮b型(luminal b),her2过表达型,基底样型(blbc),normal like型(perou cm,sorlie t,eisen mb,van de rijn m,jeffrey ss,rees ca,pollack jr,ross dt,johnsen h,akslen la et al:molecular portraits of human breast tumours.nature 2000,406(6797):747
‑
752)。其中,luminal b亚型具有侵略性的临床和生物学特征,与通常接受内分泌治疗的管腔上皮a型肿瘤相反,对于管腔上皮b型肿瘤患者应采用更具攻击性的治疗方法来治疗。由于管腔上皮b型乳腺癌亚型的分子和临床异质性,采用更具攻击性的治疗方法也并不总是有效的,因此,对管腔上皮b型肿瘤患者再分型阐释差异性是十分必要的。
3.最近,有研究对乳腺癌的亚型做了进一步研究,例如针对luminal a患者设计不同的治疗方案,腔a型亚型患者的预后可能更好,这提出了在某些情况下是否需要降低治疗水平并省略化疗的问题(kroemer g,senovilla l,galluzzi l,andre f,zitvogel l:natural and therapy
‑
induced immunosurveillance in breast cancer.nat med 2015,21(10):1128
‑
1138.)。dvir netanely等人将luminal a使用rna
‑
seq和dna甲基化数据分别对1148和679个乳腺癌样本进行无监督聚类分为不同的预后亚组(netanely d,avraham a,ben
‑
baruch a,evron e,shamir r:expression and methylation patterns partition luminal
‑
a breast tumors into distinct prognostic subgroups.breast cancer res 2016,18(1):74.)。2011年,范德比尔特大学的研究人员进行了一项开创性研究,从pathology services of the hospital universitario araba
‑
txagorritxu(vitoria
‑
gasteiz),oncologikoa(donostia)and hospital universitario donostia(donostia)总共28个管腔bc型亚型样本以及八个组织样本的相邻组织样本应用无监督聚类的方法确定了两个重要的肿瘤组,将整个腔a样品与腔b
‑
her2分开,并将腔b肿瘤分为两组,分别与腔a和腔b
‑
her2聚在一起(bediaga ng,acha
‑
sagredo a,guerra i,viguri a,albaina c,ruiz diaz i,rezola r,alberdi mj,dopazo j,montaner d et al:dna methylation epigenotypes in breast cancer molecular subtypes.breast cancer res 2010,12(5):r77.)。因此我们发现,乳腺癌的同一亚型内部之间确实存在着不同的亚组,这些亚组之间在预后治疗等方面都有所不同。
4.dna甲基化和组蛋白修饰的表观遗传转录调控与人类基因组中相应的基因表达密
切相关。dna甲基化谱已显示出在包括癌症在内的许多人类疾病中受到干扰。许多研究表明,表观遗传学变化参与了肿瘤发生的最早阶段,导致癌基因的过表达和肿瘤抑制基因的下调。另外hinshelwood的研究也表明表观遗传学对乳腺癌的影响,乳腺癌的每一类亚型都有其特定的dna甲基化模式(hinshelwood ra,clark sj:breast cancer epigenetics:normal human mammary epithelial cells as a model system.j mol med(berl)2008,86(12):1315
‑
1328.)。但是,这些研究技术也很少应用dna甲基化作为生物标志物对乳腺癌单一亚型进行再分型。
5.近年来大多数对乳腺癌某一亚型的研究关注在预后更差的三阴性乳腺癌的研究,如lehmann bd等人使用来自386个肿瘤的基因表达分析,鉴定出六种不同的tnbc亚型,每种亚型均表现出独特的生物学特性(lehmann bd,pietenpol ja,tan ar:triple
‑
negative breast cancer:molecular subtypes and new targets for therapy.am soc clin oncol educ book2015:e31
‑
39.)。但是很少关注在乳腺癌luminal b这同样在临床上有着预后差异的亚型进行精确分组并且探求内部差异的。对于乳腺癌luminalb的内部保守分型缺少精确定义并且也缺少稳定的dna甲基化标记物。因此,亟需一种能够精确划分乳腺癌luminal b的检测方法。
技术实现要素:
6.本发明为解决现有技术中没有一种能够精确划分乳腺癌luminal b的检测方法的问题,提供了一种用于乳腺癌luminal b分型的dna甲基化标记组合物及其应用。
7.本发明的第一个目的是提供一种用于乳腺癌luminal b分型的dna甲基化标记组合物,所述dna甲基化组合物包括下述甲基化位点:
8.(1)位于tmem132b基因上的甲基化位点cg10520543、cg20624941、cg06826870、cg10319331和cg26716753;
9.(2)位于htr2a基因上的甲基化位点cg01620540和cg15692052;
10.(3)位于or10j1基因上的甲基化位点cg23689219、cg15700197和cg19402335;
11.(4)位于tslp基因上的甲基化位点cg15089387、cg18049164和cg15739437;
12.(5)位于tenm2基因上的甲基化位点cg12659981、cg01227558、cg09171112、cg16658460和cg18679069;
13.(6)位于slc2a9基因上的甲基化位点cg16785938、cg25117600和cg23642392;
14.(7)位于lpa基因上的甲基化位点cg07177174、cg16960593和cg17189167;
15.(8)位于or2t11基因上的甲基化位点cg18315861、cg04836492、cg17514168和cg19367176;
16.(9)位于spp2基因上的甲基化位点cg19099213、cg13611432和cg21137417;
17.(10)位于linc00710基因上的甲基化位点cg17106572、cg26901096、cg17261125和cg23610154;
18.(11)位于tcn1基因上的甲基化位点cg20018806、cg23741006、cg00187686和cg03928812。
19.进一步地限定,所述tmem132b基因的gene id为114795;htr2a基因的gene id为3356;or10j1基因的gene id为26476;tslp基因的gene id为85480;tenm2基因的gene id为
57451;slc2a9基因的gene id为56606;lpa基因的gene id为4018;or2t11基因的gene id为127077;spp2基因的gene id为6694;linc00710基因的gene id为254312;tcn1基因的gene id为6947。
20.本发明的第二个目的是提供了一种上述dna甲基化标记组合物在制备用于诊断乳腺癌luminal b分子分型或评估乳腺癌luminal b患病风险或评估乳腺癌luminal b治疗效果及预后或筛选乳腺癌luminal b治疗药物的试剂或试剂盒中的应用。
21.本发明的第三个目的是提供一种用于诊断乳腺癌luminal b分子分型或评估乳腺癌luminal b患病风险或评估乳腺癌luminal b治疗效果及预后或筛选乳腺癌luminal b治疗药物的试剂盒,其特征在于,所述试剂盒中包含用于扩增所述各甲基化位点的引物对:
22.(1)cg10520543对应引物对:seq id no.1和seq id no.2;
23.cg20624941和cg06826870对应引物对:seq id no.3和seq id no.4;
24.cg10319331和cg26716753对应引物对:seq id no.5和seq id no.6;
25.(2)cg01620540和cg15692052对应引物对:seq id no.7和seq id no.8;
26.(3)cg23689219对应引物对:seq id no.9和seq id no.10;
27.cg15700197对应引物对:seq id no.11和seq id no.12;
28.cg19402335对应引物对:seq id no.13和seq id no.14;
29.(4)cg15089387对应引物对:seq id no.15和seq id no.16;
30.cg18049164对应引物对:seq id no.17和seq id no.18;
31.cg15739437对应引物对:seq id no.19和seq id no.20;
32.(5)cg12659981和cg01227558对应引物对:seq id no.21和seq id no.22;
33.cg09171112和cg16658460对应引物对:seq id no.23和seq id no.24;
34.cg18679069对应引物对:seq id no.25和seq id no.26;
35.(6)cg16785938和cg25117600对应引物对:seq id no.27和seq id no.28;
36.cg23642392对应引物对:seq id no.29和seq id no.30;
37.(7)cg07177174和cg16960593对应引物对:seq id no.31和seq id no.32;
38.cg17189167对应引物对:seq id no.33和seq id no.34;
39.(8)cg18315861对应引物对:seq id no.35和seq id no.36;
40.cg04836492和cg17514168对应引物对:seq id no.37和seq id no.38;
41.cg19367176对应引物对:seq id no.39和seq id no.40;
42.(9)cg19099213和cg13611432对应引物对:seq id no.41和seq id no.42;
43.cg21137417对应引物对seq id no.43和seq id no.44;
44.(10)cg17106572和cg26901096对应引物对seq id no.45和seq id no.46;
45.cg17261125对应引物对seq id no.47和seq id no.48;
46.cg23610154对应引物对seq id no.49和seq id no.50;
47.(11)cg20018806、cg23741006、cg00187686和cg03928812对应引物对:seq id no.51和seq id no.52。
48.本发明的第四个目的是提供一种筛选上述的dna甲基化标记组合物的方法,其特征在于,包括以下步骤:
49.s1、将全部乳腺癌luminal b患者的肿瘤组织样本随机划分训练集、验证集和测试
集,基于训练集中样本肿瘤组织和正常组织样本获得差异甲基化位点;
50.s2、应用boruta算法,从s1得到的差异甲基化位点筛选出特征甲基化位点,作为用于构建分类器的有效特征,并通过分类结果的准确率在训练集和测试集以及验证集分析分类器效能;
51.s3、应用wgcna工具做网络模块化分析,得到共甲基化基因模块;
52.s4、利用kobas数据库对挖掘到的所有共甲基化模块进行通路富集注释,并将模块基因的数目与在功能通路的基因集合的比例数值作为模块的打分,提取出显著与癌症进程进展相关的模块,作为有关乳腺癌luminal b的关键模块;
53.s5、将s3获得的共甲基化基因模块和s4获得的关键模块作为乳腺癌luminal b的关键基因,应用无监督层次聚类的方法,根据层次结构分支对类别进行定义。
54.进一步地限定,s5所述无监督层次聚类的方法能够将乳腺癌luminal b分为cluster1、cluster2和cluster3三个亚型。
55.本发明的第五个目的是提供利用上述dna甲基化标记组合物进行乳腺癌luminal b分型的方法,其特征在于,所述方法的具体步骤如下:
56.(1)取待分型乳腺癌luminal b患者的肿瘤组织作为样本;
57.(2)对待分型样本的dna进行提取,得到待分型样本dna;
58.(3)对待分型样本dna进行亚硫酸氢钠处理,然后利用上述引物对分别对待分型样本dna中11个基因上的各甲基化位点进行pcr扩增,并对扩增后的产物进行测序;
59.(4)获得各甲基化位点对应的甲基化值;
60.(5)获得11个关键基因上各甲基化位点的甲基化均值;
61.(6)将待分型样本11个基因各自对应的甲基化均值与上述训练集中肿瘤组织样本的11个基因各自对应的甲基化均值分别进行切比雪夫距离计算,根据计算结果,获得的距离值与哪个亚型距离最近,最终将待分型样本归为哪个亚型。
62.进一步地限定,步骤(5)所述的获得11个关键基因上各甲基化位点的甲基化均值的方法为若关键基因上仅有一个甲基化位点,那么该甲基化位点对应的甲基化值即为该基因的甲基化均值;若关键基因上有多个甲基化位点,那么这多个甲基化位点分别对应的甲基化值的平均值即为该基因的甲基化均值。
63.进一步地限定,步骤(6)中所述训练集中肿瘤组织样本的11个基因各自对应的甲基化均值的获得方法为:利用上述引物对对训练集肿瘤组织样本的11个基因的各甲基化位点进行测序,获得各甲基化位点对应的甲基化值,若关键基因上仅有一个甲基化位点,那么该甲基化位点对应的甲基化值即为该基因的甲基化均值;若关键基因上有多个甲基化位点,那么这多个甲基化位点分别对应的甲基化值的平均值即为该基因的甲基化均值。
64.进一步地限定,步骤(6)通过下式计算切比雪夫距离:
[0065][0066]
其中x
1i
表示训练集中肿瘤组织样本的数据,x
2i
表示待分型样本的数据,i表示样本数。
[0067]
本发明的有益效果:
[0068]
本发明整合tcga和cbioportal的乳腺癌luminal b患者450k平台的dna甲基化数
据和临床数据,利用功能模块计算方法以及boruta算法,揭示出与乳腺癌luminal b的分型密切相关的一组包含在11个基因上的39个甲基化位点的标记组合物,通过检测这些位点的甲基化水平可以将乳腺癌luminal b划分为保守的三个亚型,分别为cluster1、cluster2和cluster3。并且获得的乳腺癌luminal b的三个亚型在预后方面呈现显著差异,cluster2亚组预后更好,这一点在geo数据集上也得到了验证。本发明阐释了dna甲基化数据可以作为乳腺癌luminal b这一具有侵略性的临床和生物学特征的亚组的精确划分的数据资源,并且应用dna甲基化数据可以识别出乳腺癌luminal b的内部亚型并识别有关预后甲基化基因。本发明所述的dna甲基化标记组合物能提高乳腺癌luminal b诊断评估效能,有利于开展相应治疗方案,进而提高乳腺癌luminalb的治疗效果,节约成本,适于推广应用,具有较好的应用前景。
附图说明
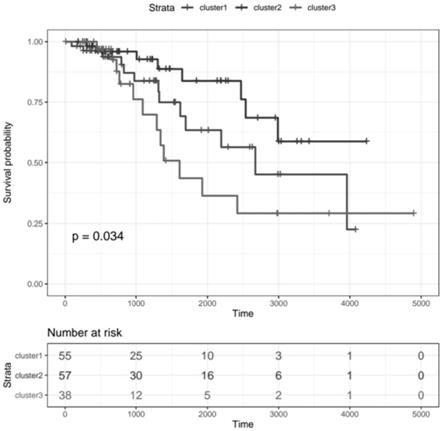
[0069]
图1为tcga数据中保守的三个亚组的生存分析的结果图;
[0070]
图2为geo数据中保守的三个亚组的生存分析的结果图。
具体实施方式
[0071]
实施例1:dna甲基化标记组合物的筛选
[0072]
将全部乳腺癌luminal b患者的肿瘤组织样本随机划分为7:3作为训练分类器分为训练集和验证集两个队列,再将验证集根据7:3分为测试集和验证集。由于考虑甲基化位点作为特征应更准确代表luminal b的特征,基于训练集样本肿瘤组织和正常组织样本的差异甲基化位点进行筛选。设置随机种子数,对所得到的差异甲基化位点应用boruta算法最终筛选出特征甲基化位点,用于构建分类器的有效特征,并通过分类结果的准确率在训练集和测试集以及验证集分析了分类器效能。
[0073]
对全部luminal b样本和正常组织样本的差异甲基化基因进行进一步挖掘,获得乳腺癌luminal b样本中关键的甲基化基因,应用wgcna做模块网络化分析,得到共甲基化基因模块,用于后续分析。将挖掘到的所有共甲基化模块利用kobas数据库做通路富集注释,依据开发的功能模块打分公式,即:模块基因的数目与在功能通路的基因集合的比例数值作为模块的打分,提取出显著与癌症进程进展高度相关的模块,作为有关乳腺癌luminal b的关键模块。
[0074]
关键模块和以上支持向量机的特征dna甲基化位点对应的dna甲基化基因的共享dna甲基化基因,被认为是乳腺癌luminal b的“关键基因”,所述“关键基因”为tmem132b(gene id为114795)、htr2a(gene id为3356)、or10j1(gene id为26476)、tslp(gene id为85480)、tenm2(gene id为57451)、slc2a9(gene id为56606)、lpa(gene id为4018)、or2t11(gene id为127077)、spp2(gene id为6694)、linc00710(gene id为254312)和tcn1(gene id为6947)。根据无监督层次聚类方法依据层次结构分支对类别进行定义,可以有力清晰地区分这一亚型中的不同亚组。tcga数据中保守的三个亚组的生存分析的结果图见图1,显示一组11个dna甲基化基因tmem132b、htr2a、or10j1、tslp、tenm2、slc2a9、lpa、or2t11、spp2、linc00710和tcn1,根据dna甲基化高中低水平将乳腺癌luminal b分为三个亚型,分别为cluster1、cluster2和cluster3。并且获得的乳腺癌luminal b的三个亚型在预后方面呈现
显著差异,cluster2亚组预后更好,这一点在geo数据集上也得到了验证(见图2)。
[0075]
通过整合tcga和cbioportal的数据(包括luminal b组和正常对照组的dna甲基化谱),揭示出一组数目为11个的dna甲基化基因用于分型乳腺癌luminal b。最终发现乳腺癌luminal b的保守的三个亚组的生存,免疫浸润,临床分期等存在显著差异。通过boruta算法对乳腺癌luminal b样本和非luminal b样本特征选择并构建支持向量机模型,表明乳腺癌luminal b的dna甲基化标记可以进行预测,并且发现它们与患者的预后相关。
[0076]
上述获得的11个dna甲基化基因包括以下甲基化位点:
[0077]
(1)位于tmem132b基因上的甲基化位点cg10520543、cg20624941、cg06826870、cg10319331和cg26716753;
[0078]
(2)位于htr2a基因上的甲基化位点cg01620540和cg15692052;
[0079]
(3)位于or10j1基因上的甲基化位点cg23689219、cg15700197和cg19402335;
[0080]
(4)位于tslp基因上的甲基化位点cg15089387、cg18049164和cg15739437;
[0081]
(5)位于tenm2基因上的甲基化位点cg12659981、cg01227558、cg09171112、cg16658460和cg18679069;
[0082]
(6)位于slc2a9基因上的甲基化位点cg16785938、cg25117600和cg23642392;
[0083]
(7)位于lpa基因上的甲基化位点cg07177174、cg16960593和cg17189167;
[0084]
(8)位于or2t11基因上的甲基化位点cg18315861、cg04836492、cg17514168和cg19367176;
[0085]
(9)位于spp2基因上的甲基化位点cg19099213、cg13611432和cg21137417;
[0086]
(10)位于linc00710基因上的甲基化位点cg17106572、cg26901096、cg17261125和cg23610154;
[0087]
(11)位于tcn1基因上的甲基化位点cg20018806、cg23741006、cg00187686和cg03928812。
[0088]
根据上述甲基化位点设计pcr引物对,获得的各甲基化位点对应的引物对如下:
[0089]
(1)cg10520543对应引物对:seq id no.1和seq id no.2;
[0090]
cg20624941和cg06826870对应引物对:seq id no.3和seq id no.4;
[0091]
cg10319331和cg26716753对应引物对:seq id no.5和seq id no.6;
[0092]
(2)cg01620540和cg15692052对应引物对:seq id no.7和seq id no.8;
[0093]
(3)cg23689219对应引物对:seq id no.9和seq id no.10;
[0094]
cg15700197对应引物对:seq id no.11和seq id no.12;
[0095]
cg19402335对应引物对:seq id no.13和seq id no.14;
[0096]
(4)cg15089387对应引物对:seq id no.15和seq id no.16;
[0097]
cg18049164对应引物对:seq id no.17和seq id no.18;
[0098]
cg15739437对应引物对:seq id no.19和seq id no.20;
[0099]
(5)cg12659981和cg01227558对应引物对:seq id no.21和seq id no.22;
[0100]
cg09171112和cg16658460对应引物对:seq id no.23和seq id no.24;
[0101]
cg18679069对应引物对:seq id no.25和seq id no.26;
[0102]
(6)cg16785938和cg25117600对应引物对:seq id no.27和seq id no.28;
[0103]
cg23642392对应引物对:seq id no.29和seq id no.30;
[0104]
(7)cg07177174和cg16960593对应引物对:seq id no.31和seq id no.32;
[0105]
cg17189167对应引物对:seq id no.33和seq id no.34;
[0106]
(8)cg18315861对应引物对:seq id no.35和seq id no.36;
[0107]
cg04836492和cg17514168对应引物对:seq id no.37和seq id no.38;
[0108]
cg19367176对应引物对:seq id no.39和seq id no.40;
[0109]
(9)cg19099213和cg13611432对应引物对:seq id no.41和seq id no.42;
[0110]
cg21137417对应引物对seq id no.43和seq id no.44;
[0111]
(10)cg17106572和cg26901096对应引物对seq id no.45和seq id no.46;
[0112]
cg17261125对应引物对seq id no.47和seq id no.48;
[0113]
cg23610154对应引物对seq id no.49和seq id no.50;
[0114]
(11)cg20018806、cg23741006、cg00187686和cg03928812对应引物对:seq id no.51和seq id no.52。
[0115]
实施例2:一种乳腺癌luminal b分型的方法
[0116]
(1)选取乳腺癌luminal b患者的新鲜肿瘤组织作为待分型样本,切成约50mg的小块,用液氮速冻后,
‑
80℃保存;
[0117]
(2)对待分型样本的基因组进行提取,得到待分型样本dna(基因组dna的量≥1ug),dna样本可溶于超纯水或te(ph8.0)中,
‑
20℃短期保存或
‑
80℃长期保存,样本保存期间避免反复冻融;
[0118]
(3)对待分型样本dna进行用亚硫酸氢钠处理,该方法应用亚硫酸氢钠修饰处理基因组dna,所有未发生甲基化的胞嘧啶(c)被转化为尿嘧啶(u)而甲基化的胞嘧啶则不变;然后利用实施例1中所述的引物对对经亚硫酸氢钠处理后的样品dna上的甲基化位点进行pcr扩增,并对扩增后的产物进行测序,;
[0119]
(4)采用亚硫酸氢盐处理后测序(bisulfite sequencing pcr,bsp)的检测基因甲基化的经典方法获取各甲基化位点的甲基化值:将步骤(3)测得的序列与原始序列比对,统计甲基化位点及数量,最终得到11个关键基因上各甲基化位点的甲基化值。
[0120]
(5)获得11个关键基因上各甲基化位点的甲基化均值:若关键基因上仅有一个甲基化位点,那么该甲基化位点对应的甲基化值即为该基因的甲基化均值;若关键基因上有多个甲基化位点,那么这多个甲基化位点分别对应的甲基化值的平均值即为该基因的甲基化均值。
[0121]
(6)将待分型样本11个基因各自对应的甲基化均值与实施例1所述训练集中肿瘤组织样本的11个基因各自对应的甲基化均值分别进行切比雪夫距离计算,计算公式为其中x
1i
表示训练集中肿瘤组织样本的数据,x
2i
表示待分型样本的数据,i表示样本数,根据计算结果,获得的距离值与哪个亚型距离最近,最终将待分型样本归为哪个亚型。
[0122]
实施例1所述训练集中肿瘤组织样本的11个基因各自对应的甲基化均值的获得方法如下:利用实施例1中所述的引物对对训练集肿瘤组织样本的11个基因的各甲基化位点进行测序,获得各甲基化位点对应的甲基化值,若关键基因上仅有一个甲基化位点,那么该甲基化位点对应的甲基化值即为该基因的甲基化值;若关键基因上有多个甲基化位点,那
么这多个甲基化位点分别对应的甲基化值的平均值即为该基因的甲基化均值。
[0123]
实施例3:一种用于诊断乳腺癌luminal b分子分型的试剂盒
[0124]
一种用于诊断乳腺癌luminal b分子分型的试剂盒中包含用于扩增实施例1所述各甲基化位点的引物对:
[0125]
(1)cg10520543对应引物对:seq id no.1和seq id no.2;
[0126]
cg20624941和cg06826870对应引物对:seq id no.3和seq id no.4;
[0127]
cg10319331和cg26716753对应引物对:seq id no.5和seq id no.6;
[0128]
(2)cg01620540和cg15692052对应引物对:seq id no.7和seq id no.8;
[0129]
(3)cg23689219对应引物对:seq id no.9和seq id no.10;
[0130]
cg15700197对应引物对:seq id no.11和seq id no.12;
[0131]
cg19402335对应引物对:seq id no.13和seq id no.14;
[0132]
(4)cg15089387对应引物对:seq id no.15和seq id no.16;
[0133]
cg18049164对应引物对:seq id no.17和seq id no.18;
[0134]
cg15739437对应引物对:seq id no.19和seq id no.20;
[0135]
(5)cg12659981和cg01227558对应引物对:seq id no.21和seq id no.22;
[0136]
cg09171112和cg16658460对应引物对:seq id no.23和seq id no.24;
[0137]
cg18679069对应引物对:seq id no.25和seq id no.26;
[0138]
(6)cg16785938和cg25117600对应引物对:seq id no.27和seq id no.28;
[0139]
cg23642392对应引物对:seq id no.29和seq id no.30;
[0140]
(7)cg07177174和cg16960593对应引物对:seq id no.31和seq id no.32;
[0141]
cg17189167对应引物对:seq id no.33和seq id no.34;
[0142]
(8)cg18315861对应引物对:seq id no.35和seq id no.36;
[0143]
cg04836492和cg17514168对应引物对:seq id no.37和seq id no.38;
[0144]
cg19367176对应引物对:seq id no.39和seq id no.40;
[0145]
(9)cg19099213和cg13611432对应引物对:seq id no.41和seq id no.42;
[0146]
cg21137417对应引物对seq id no.43和seq id no.44;
[0147]
(10)cg17106572和cg26901096对应引物对seq id no.45和seq id no.46;
[0148]
cg17261125对应引物对seq id no.47和seq id no.48;
[0149]
cg23610154对应引物对seq id no.49和seq id no.50;
[0150]
(11)cg20018806、cg23741006、cg00187686和cg03928812对应引物对:seq id no.51和seq id no.52。
[0151]
本实施例所述的试剂盒还可用于评估乳腺癌luminal b患病风险或评估乳腺癌luminal b治疗效果及预后或筛选乳腺癌luminal b治疗药物。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。