新型抗cd40抗体
1.相关申请的交叉引用
2.本技术要求2019年1月22日提交的us 62/795,027的优先权,其公开内容以引用的方式并入本文中。
3.序列表
4.在命名为“074233
‑
8001wo01
‑
sl
‑
20200121_st25”,大小为174kb(如microsoft windows中所测量)并且创建于2020年1月21日的文件中所含的序列表通过电子提交的方式与此一起提交,并且以引用的方式并入本文中。
背景技术:
1.发明领域
5.本公开大体上涉及新型抗人cd40抗体。
6.2.相关技术的描述
7.cd40为48kda i型整合膜糖蛋白和肿瘤坏死因子(tnf)受体超家族的成员。cd40在多种细胞类型上表达,所述细胞类型包括抗原呈递细胞(apc),如正常和赘生性b细胞、树突状细胞(dc)、单核细胞和巨噬细胞,和非免疫细胞,包括上皮细胞(例如,角质细胞)、成纤维细胞(例如,滑膜细胞)、平滑肌细胞和血小板。cd40还在广泛范围的肿瘤细胞上表达,所述肿瘤细胞包括所有b
‑
淋巴瘤、30%
‑
70%的实体肿瘤、黑色素瘤和癌瘤。
8.apc上的cd40信号传导引起apc的存活增强以及活化。cd40介导的apc活化涉及多种免疫反应,包括细胞因子(例如il
‑
1、il
‑
6、il
‑
8、il
‑
10、il
‑
12、tnf
‑
α和mip
‑
1α)分泌、协同刺激分子(例如icam
‑
1、lfa
‑
3、cd80和cd86)上调和apc增殖。cd40调节针对感染、肿瘤和自身抗原的免疫反应。cd40在广泛范围的恶性细胞上过度表达。cd40在肿瘤抑制和免疫系统刺激中的作用使cd40成为基于抗体的免疫疗法的有吸引力的目标(van mierlo gj,den boer at,medema jp等人《美国国家科学院院刊(proc natl acad sci u s a.)》2002;99(8):5561 5566;french rr,chan ht,tutt al,glennie mj.《自然
·
医学(nat med.)》1999;5(5):548
‑
553)。
9.迫切需要新型抗cd40抗体。
10.发明简述
11.在整个本公开中,冠词“一(a/an)”和“所述”在本文中用于指一个(种)或超过一个(种)(即,至少一个(种))所述冠词的语法对象。举例来说,“(一)抗体”意指一种抗体或多于一种抗体。
12.本公开提供新型单克隆抗cd40抗体、氨基酸和其核苷酸序列、以及其用途。
13.在一个方面,本公开提供一种分离的抗cd40抗体或其抗原结合片段,其包含:
14.a)重链cdr1序列,其选自下组:seq id no:1、7、13、19、25、31、37、43、49、55、61、67、73、79、85、91、97、103、109、115、121、127、133、139、145、151、157、163、169、175、181、187、193、199、205、211、217、223、229、235和241;
15.b)重链cdr2序列,其选自下组:seq id no:3、9、15、21、27、33、39、45、51、57、63、69、75、81、87、93、99、105、111、117、123、129、135、141、147、153、159、165、171、177、183、189、195、201、207、213、219、225、231、237和243;
16.c)重链cdr3序列,其选自下组:seq id no:5、11、17、23、29、35、41、47、53、59、65、71、77、83、89、95、101、107、113、119、125、131、137、143、149、155、161、167、173、179、185、191、197、203、209、215、221、227、233、239和245;
17.d)轻链cdr1序列,其选自下组:seq id no:2、8、14、20、26、32、38、44、50、56、62、68、74、80、86、92、98、104、110、116、122、128、134、140、146、152、158、164、170、176、182、188、194、200、206、212、218、224、230、236和242;
18.e)轻链cdr2序列,其选自下组:seq id no:4、10、16、22、28、34、40、46、52、58、64、70、76、82、88、94、100、106、112、118、124、130、136、142、148、154、160、166、172、178、184、190、196、202、208、214、220、226、232、238和244;和
19.f)轻链cdr3序列,其选自下组:seq id no:6、12、18、24、30、36、42、48、54、60、66、72、78、84、90、96、102、108、114、120、126、132、138、144、150、156、162、168、174、180、186、192、198、204、210、216、222、228、234、240和246。
20.在某些实施方式中,所述抗体或其抗原结合片段包含选自下组的重链可变区:seq id no:247、251、255、259、263、267、271、275、279、283、287、291、295、299、303、307、311、315、319、323、327、331、335、339、343、347、351、355、359、363、367、371、375、379、383、387、391、395、399、403、407、411和415,和与其具有至少80%序列同一性但保持与cd40的特异性结合亲和力的同源序列。
21.在某些实施方式中,所述抗体或其抗原结合片段包含选自下组的轻链可变区:seq id no:249、253、257、261、265、269、273、277、281、285、289、293、297、301、305、309、313、317、321、325、329、333、337、341、345、349、353、357、361、365、369、373、377、381、385、389、393、397、401、405、409、413和417,和与其具有至少80%序列同一性但保持与cd40的特异性结合亲和力的同源序列。
22.在某些实施方式中,所述抗体或其抗原结合片段包含:
23.a)包含seq id no:247的重链可变区和包含seq id no:249的轻链可变区;
24.b)包含seq id no:251的重链可变区和包含seq id no:253的轻链可变区;
25.c)包含seq id no:255的重链可变区和包含seq id no:257的轻链可变区;
26.d)包含seq id no:259的重链可变区和包含seq id no:261的轻链可变区;
27.e)包含seq id no:263的重链可变区和包含seq id no:265的轻链可变区;
28.f)包含seq id no:267的重链可变区和包含seq id no:269的轻链可变区;
29.g)包含seq id no:271的重链可变区和包含seq id no:273的轻链可变区;
30.h)包含seq id no:275的重链可变区和包含seq id no:277的轻链可变区;
31.i)包含seq id no:279的重链可变区和包含seq id no:281的轻链可变区;
32.j)包含seq id no:283的重链可变区和包含seq id no:285的轻链可变区;
33.k)包含seq id no:287的重链可变区和包含seq id no:289的轻链可变区;
34.l)包含seq id no:291的重链可变区和包含seq id no:293的轻链可变区;
35.m)包含seq id no:295的重链可变区和包含seq id no:297的轻链可变区;
36.n)包含seq id no:299的重链可变区和包含seq id no:301的轻链可变区;
37.o)包含seq id no:303的重链可变区和包含seq id no:305的轻链可变区;
38.p)包含seq id no:307的重链可变区和包含seq id no:309的轻链可变区;
39.q)包含seq id no:311的重链可变区和包含seq id no:313的轻链可变区;
40.r)包含seq id no:315的重链可变区和包含seq id no:317的轻链可变区;
41.s)包含seq id no:319的重链可变区和包含seq id no:321的轻链可变区;
42.t)包含seq id no:323的重链可变区和包含seq id no:325的轻链可变区;
43.u)包含seq id no:327的重链可变区和包含seq id no:329的轻链可变区;
44.v)包含seq id no:331的重链可变区和包含seq id no:333的轻链可变区;
45.w)包含seq id no:335的重链可变区和包含seq id no:337的轻链可变区;
46.x)包含seq id no:339的重链可变区和包含seq id no:341的轻链可变区;
47.y)包含seq id no:343的重链可变区和包含seq id no:345的轻链可变区;
48.z)包含seq id no:347的重链可变区和包含seq id no:349的轻链可变区;
49.aa)包含seq id no:351的重链可变区和包含seq id no:353的轻链可变区;
50.bb)包含seq id no:355的重链可变区和包含seq id no:357的轻链可变区;
51.cc)包含seq id no:359的重链可变区和包含seq id no:361的轻链可变区;
52.dd)包含seq id no:363的重链可变区和包含seq id no:365的轻链可变区;
53.ee)包含seq id no:367的重链可变区和包含seq id no:369的轻链可变区;
54.ff)包含seq id no:371的重链可变区和包含seq id no:373的轻链可变区;
55.gg)包含seq id no:375的重链可变区和包含seq id no:377的轻链可变区;
56.hh)包含seq id no:379的重链可变区和包含seq id no:381的轻链可变区;
57.ii)包含seq id no:383的重链可变区和包含seq id no:385的轻链可变区;
58.jj)包含seq id no:387的重链可变区和包含seq id no:389的轻链可变区;
59.kk)包含seq id no:391的重链可变区和包含seq id no:393的轻链可变区;
60.ll)包含seq id no:395的重链可变区和包含seq id no:397的轻链可变区;
61.mm)包含seq id no:399的重链可变区和包含seq id no:401的轻链可变区;
62.nn)包含seq id no:403的重链可变区和包含seq id no:405的轻链可变区;
63.oo)包含seq id no:407的重链可变区和包含seq id no:409的轻链可变区;
64.pp)包含seq id no:411的重链可变区和包含seq id no:413的轻链可变区;或
65.qq)包含seq id no:415的重链可变区和包含seq id no:417的轻链可变区。
66.在某些实施方式中,所述抗体或其抗原结合片段进一步包含一个或多个氨基酸残基取代或修饰,但仍保持与cd40的特异性结合亲和力。在某些实施方式中,至少一个所述取代或修饰在一个或多个cdr序列中,和/或在一个或多个重链或轻链可变区序列中但不在任一个cdr序列中。
67.在某些实施方式中,所述抗体或其抗原结合片段进一步包含免疫球蛋白恒定区,任选地,ig恒定区,或任选地,人igg恒定区。
68.在某些实施方式中,所述抗体或其抗原结合片段是人源化的。
69.在某些实施方式中,所述抗体或其抗原结合片段为骆驼单结构域抗体、双功能抗体、scfv、scfv二聚体、bsfv、dsfv、(dsfv)2、dsfv
‑
dsfv'、fv片段、fab、fab'、f(ab')2、双特异
性抗体、ds双功能抗体、纳米抗体、结构域抗体或二价抗体。
70.在某些实施方式中,所述抗体或其抗原结合片段能够特异性地与cd40(任选地,来源于人或兔的cd40)结合。
71.在某些实施方式中,所述抗体或其抗原结合片段如通过生物层干涉测量法所测量,能够以不超过7pm、不超过10pm、不超过50pm、不超过100pm、不超过200pm、不超过300pm或不超过400pm的k
d
值特异性地与cd40结合。
72.在某些实施方式中,所述抗体或其抗原结合片段如通过流式细胞仪分析所测量,能够以不超过0.06nm、不超过0.07nm、不超过0.08nm、不超过0.09nm或不超过0.1nm的ec
50
特异性地与在细胞表面上表达的cd40结合。
73.在某些实施方式中,所述抗体或其抗原结合片段与一个或多个缀合部分连接。在某些实施方式中,所述缀合部分包含清除调节剂、毒素、可检测标记、化学治疗剂或纯化部分。
74.在另一方面,本公开提供一种抗体或其抗原结合片段,其与本文所提供的抗体或其抗原结合片段竞争相同表位。
75.在另一方面,本公开提供一种药物组合物,其包含本文所提供的抗体或其抗原结合片段和药学上可接受的载体。
76.在另一方面,本公开提供一种分离的多核苷酸,其编码本文所提供的抗体或其抗原结合片段。在某些实施方式中,所述分离的多核苷酸包含选自下组的核苷酸序列:seq id no:248、250、252、254、256、258、260、262、264、266、268、270、272、274、276、278、280、282、284、286、288、290、292、294、296、298、300、302、304、306、308、310、312、314、316、318、320、322、324、326、328、330、332、334、336、338、340、342、344、346、348、350、352、354、356、358、360、362、364、366、368、370、372、374、376、378、380、382、384、386、388、390、392、394、396、398、400、402、404、406、408、410、412、414、416和418。
77.在另一方面,本公开提供一种载体,其包含本文所提供的分离的多核苷酸。
78.在另一方面,本公开提供一种宿主细胞,其包含本文所提供的载体。
79.在另一方面,本公开提供一种表达本文所提供的抗体或其抗原结合片段的方法,其包括在表达本文所提供的载体的条件下培养本文所提供的宿主细胞。
80.在另一方面,本公开提供一种治疗将受益于cd40活性调节的受试者的疾病或病状的方法,其包括向所述受试者施用治疗有效量的本文所提供的抗体或其抗原结合片段或本文所提供的药物组合物。在某些实施方式中,所述疾病或病状为cd40相关疾病或病状。在某些实施方式中,所述疾病或病状为癌症、自身免疫疾病、炎性疾病或传染病。在某些实施方式中,所述癌症为肾上腺癌、骨癌、脑癌、乳腺癌、结肠直肠癌、食道癌、眼癌、胃癌、头颈癌、肾癌、肝癌、肺癌、非小细胞肺癌、细支气管肺泡细胞肺癌、间皮瘤、头颈癌、鳞状细胞癌、淋巴瘤、淋巴细胞性白血病、黑色素瘤、口腔癌、卵巢癌、子宫颈癌、阴茎癌、前列腺癌、胰腺癌、皮肤癌、肉瘤、睾丸癌、甲状腺癌、子宫癌、阴道癌和霍奇金氏病(hodgkin's disease)。在某些实施方式中,所述受试者为人类。在某些实施方式中,所述施用为通过口服、经鼻、静脉内、皮下、舌下或肌肉内施用。
81.在另一方面,本公开提供一种在表达cd40的细胞中调节cd40活性的方法,其包括使所述表达cd40的细胞暴露于本文所提供的抗体或其抗原结合片段。
82.在另一方面,本公开提供一种检测样品中cd40的存在或含量的方法,其包括使所述样品与本文所提供的抗体或其抗原结合片段接触,并且测定所述样品中cd40的存在或含量。
83.在另一方面,本公开提供一种诊断受试者的cd40相关疾病或病状的方法,其包括:a)使从所述受试者获得的样品与本文所提供的抗体或其抗原结合片段接触;b)测定所述样品中cd40的存在或含量;和c)使所述cd40的存在或含量与所述受试者中所述cd40相关疾病或病状的存在或状态相关联。
84.在另一方面,本公开提供本文所提供的抗体或其抗原结合片段在制备用于治疗受试者的cd40相关疾病或病状的药物中的用途。
85.在另一方面,本公开提供本文所提供的抗体或其抗原结合片段在制备用于诊断cd40相关疾病或病状的诊断试剂中的用途。
86.在另一方面,本公开提供一种试剂盒,其包含本文所提供的抗体或其抗原结合片段,所述试剂盒可用于检测cd40。
附图说明
87.以下附图形成本说明书的一部分且被包括以进一步说明本发明的某些方面。通过参考这些附图中的一个或多个以及本文中所呈现的具体实施方式的详细描述,可更好地理解本发明。
88.图1示出了所指示的抗cd40抗体的cd40活化。
89.图2示出了冻融处理之后所指示的抗cd40抗体的cd40活化。
90.图3示出了通过流式细胞测量术测定的所指示的抗cd40抗体与细胞表面上cd40的结合。
91.图4示出了所指示的抗cd40抗体与cd40l的cd40结合竞争,呈现为抗体存在下相对于抗体不存在下,与cd40结合的cd40l百分比。
92.图5a和图5b说明如使用cd80(图5a)和cd86(图5b)表达所评估的,抗cd40抗体引起的b细胞活化。简单来说,在存在或不存在抗cd40抗体的情况下,将单核细胞耗乏的健康供体pbmc与il
‑
2和il
‑
4一起培育48小时。使用流式细胞测量术分析cd19 细胞上的cd80和cd86表达。
93.图6a
‑
6b说明如使用cd80(图6a)和cd86(图6b)所评估的,抗cd40抗体引起的树突状细胞成熟和活化。简单来说,将单核细胞从健康供体pbmc分离,用gm
‑
csf和il
‑
4诱导5天朝向树突状细胞的分化。随后将抗cd40抗体引入再持续48小时。使用流式细胞测量术分析单核细胞衍生的树突状细胞(modc)的cd80和cd86表达。
94.发明详述
95.以下对本公开的描述仅打算说明本公开的各种实施方式。因此,所论述的具体修改不应被解释为对本公开范围的限制。对所属领域的技术人员显而易见的是,可在不脱离本公开的范围的情况下做各种等效、改变和修改,且应理解所述等效实施方式将包括在本文中。本文引用的所有参考文献,包括出版物、专利和专利申请,均以全文引用的方式并入本文中。
96.i.定义
97.应理解,以上一般描述和以下详细描述都仅是示范性和解释性的,并且不限制要求保护的本发明。在本技术中,除非另外特别陈述,否则单数的使用包括复数。在本技术中,除非另有说明,否则“或”的使用意指“和/或”。此外,术语“包括(including)”以及例如“包括(includes)”和“包括(included)”的其它形式的使用不具限制性。此外,除非另外特定陈述,否则例如“要素”或“组分”的术语涵盖包含一个单元的要素和组分和包含超过一个亚单元的要素和组分。此外,术语“部分”的使用可以包括部分的一部分或整个部分。
98.当提及例如量、持续时间等的可测量的值时,如本文所用,术语“约”意味着涵盖与指定值相差至多
±
10%的变化。除非另外指明,否则本说明书和权利要求书中所用的表示成分量、特性(诸如分子量)、反应条件等的所有数字应理解为在所有情况下都由术语“约”修饰。因此,除非相反地指示,否则在以下说明书和所附权利要求书中所阐述的数值参数是可以取决于试图由所公开的主题获得的所需特性而变化的近似值。最低限度地,并且不试图限制等效物原则对权利要求书范围的应用,每一个数值参数都应至少根据所报告的有效数字的数目并且通过应用一般四舍五入技术来解释。尽管阐述本发明的广泛范围的数值范围和参数是近似值,但是在特定实例中所阐述的数值是尽可能精确地报告的。然而,任何数值固有地含有某些误差,这些误差必然由其相应测试测量中所存在的标准差造成。
99.术语“抗体”是指可以与完整抗体竞争、特异性结合于目标抗原的任何同种型的完整免疫球蛋白或其片段,并且包括例如嵌合抗体、人源化抗体、完全人抗体和双特异性抗体。“抗体”是一种抗原结合蛋白。完整抗体通常包含至少两条全长重链和两条全长轻链,但在一些情况下可以包括更少的链,例如天然存在于骆驼科动物中的抗体,其可以仅包含重链。抗体可以仅来源于单一来源,或者可以是“嵌合”的,即抗体的不同部分可以来源于两种不同的抗体,如下文进一步所描述。抗原结合蛋白、抗体或结合片段可以通过重组dna技术或通过完整抗体的酶促或化学裂解在融合瘤中产生。除非另外指明,否则术语“抗体”除了包含两条全长重链和两条全长轻链的抗体外,还包括其衍生物、变异体、片段和突变蛋白,其实例如下所述。此外,除非明确排除,否则抗体包括单克隆抗体、双特异性抗体、微型抗体、结构域抗体、合成抗体(在本文中有时被称作“抗体模拟物”)、嵌合抗体、人源化抗体、人抗体、抗体融合物(在本文中有时被称作“抗体缀合物”)和其各自的片段。在一些实施方式中,所述术语还涵盖肽体。
100.天然存在的抗体结构单元通常包含四聚体。每一所述四聚体通常由两对相同的多肽链构成,每对具有一条全长“轻”链(在某些实施方式中,约25kda)和一条全长“重”链(在某些实施方式中,约50
‑
70kda)。每条链的氨基端部分通常包括约100到110个或更多个氨基酸的可变区,其通常负责抗原识别。每条链的羧基端部分通常定义可以负责效应功能的恒定区。人轻链通常分类为κ和λ轻链。重链通常分类为μ、δ、γ、α或ε,并且分别将抗体的同种型定义为igm、igd、igg、iga和ige。igg具有几个亚类,包括但不限于igg1、igg2、igg3和igg4。igm具有亚类,包括但不限于igm1和igm2。iga类似地细分为亚类,包括但不限于iga1和iga2。在全长轻链和重链内,通常,可变区和恒定区通过约12个或更多个氨基酸的“j”区接合,其中重链还包括约10个更多氨基酸的“d”区。参见例如《基础免疫学(fundamental immunology)》,第7章(paul,w.编,第2版,纽约raven出版社(1989))(出于所有目的以全文引用的方式并入本文中)。每对轻/重链的可变区通常形成抗原结合位点。
101.术语“可变区”或“可变结构域”是指抗体的轻链和/或重链的一部分,通常重链中
包括大约氨基端120到130个氨基酸并且轻链中包括约100到110个氨基端氨基酸。在某些实施方式中,即使在相同的物种的抗体中,不同抗体的可变区的氨基酸序列仍然相差很大。抗体的可变区通常决定了特定抗体对其目标的特异性。
102.可变区通常展现与由三个高变区接合的相对保守的框架区(fr)相同的一般结构,所述三个高变区也称为互补决定区或cdr。来自每对的两条链的cdr通常通过框架区对准,这可以实现与特定表位的结合。从n端到c端,轻链和重链可变区通常包含结构域fr1、cdr1、fr2、cdr2、fr3、cdr3和fr4。每个结构域的氨基酸的分配通常符合以下中的定义:kabat《免疫学感兴趣的蛋白质的序列(sequences of proteins of immunological interest)》(马里兰州贝塞斯达的美国国立卫生研究院(national institutes of health,bethesda,md.)(1987和1991));chothia和lesk,《分子生物学杂志(j.mol.biol.)》,196:901
‑
917(1987);或chothia等人,《自然(nature)》,342:878
‑
883(1989)。
103.在某些实施方式中,在不存在抗体轻链的情况下,抗体重链与抗原结合。在某些实施方式中,在不存在抗体重链的情况下,抗体轻链与抗原结合。在某些实施方式中,在不存在抗体轻链的情况下,抗体结合区与抗原结合。在某些实施方式中,在不存在抗体重链的情况下,抗体结合区与抗原结合。在某些实施方式中,在不存在其它可变区的情况下,个别可变区与抗原特异性结合。
104.在某些实施方式中,cdr的明确描述和包含抗体的结合位点的残基的识别通过解析抗体结构和/或解析抗体
‑
配体复合物的结构来实现。在某些实施方式中,其可通过所属领域的技术人员已知的多种技术中的任一种,例如x射线晶体学实现。在某些实施方式中,可以采用各种分析方法来识别或估计cdr区。所述方法的实例包括但不限于kabat定义、chothia定义、abm定义和接触定义(contact definition)。
105.kabat定义是用于对抗体中的残基进行编号的标准,并且通常用于识别cdr区。参见例如johnson和wu,《核酸研究(nucleic acids res.)》,28:214
‑
8(2000)。chothia定义与kabat定义类似,但chothia定义考虑了某些结构环区域的位置。参见例如chothia等人,《分子生物学杂志》,196:901
‑
17(1986);chothia等人,《自然》,342:877
‑
83(1989)。abm定义使用由oxford molecular group生产的一套整合计算机程序组,其对抗体结构建模。参见例如martin等人,《美国国家科学院院刊》,86:9268
‑
9272(1989);《abm
tm
:一种用于对抗体的可变区建模的计算机程序(abm
tm
,a computer program for modeling variable regions of antibodies)》,英国牛津(oxford,uk);oxford molecular有限公司。abm定义使用知识数据库和从头算方法(ab initio method)的组合从一级序列对抗体的三级结构建模,所述从头算方法例如由samudrala等人,《使用组合层次方法进行从头算蛋白质结构预测(ab initio protein structure prediction using a combined hierarchical approach)》,《蛋白质、结构、功能和遗传学(proteins,structure,function and genetics》增刊,3:194
‑
198(1999)所述的那些。接触定义是基于可用的复杂晶体结构的分析。参见例如maccallum等人,《分子生物学杂志》,5:732
‑
45(1996)。
106.按照惯例,重链中的cdr区通常称为h1、h2和h3,并且沿着从氨基端到羧基端的方向依序编号。轻链中的cdr区通常称为l1、l2和l3,并且沿着从氨基端到羧基端的方向依序编号。
107.术语“轻链”包括全长轻链和其具有足够赋予结合特异性的可变区序列的片段。全
长轻链包括可变区结构域vl和恒定区结构域cl。轻链的可变区结构域在多肽的氨基端。轻链包括κ链和λ链。
108.术语“重链”包括全长重链和其具有足够赋予结合特异性的可变区序列的片段。全长重链包括可变区结构域vh和三个恒定区结构域ch1、ch2和ch3。vh结构域在多肽的氨基端,并且ch结构域在羧基端,其中ch3最靠近多肽的羧基端。重链可以具有任何同种型,包括igg(包括igg1、igg2、igg3和igg4亚型)、iga(包括iga1和iga2亚型)、igm和ige。
109.术语“抗原”是指能够诱导适应性免疫反应的物质。具体来说,抗原是由抗体或t淋巴细胞抗原受体特异性结合的物质。抗原通常是蛋白质和多糖,不太常见的也是脂质。适合的抗原包括但不限于细菌(外壳、荚膜、细胞壁、鞭毛、菌毛和毒素)、病毒和其它微生物的部分。抗原还包括肿瘤抗原,例如在肿瘤中通过突变产生的抗原。如本文所用,抗原还包括免疫原和半抗原。
110.如本文所用,术语“抗原结合片段”是指由抗体的一部分形成的包含一个或多个cdr的抗体片段,或与抗原结合但不包含完整天然抗体结构的任何其它抗体片段。抗原结合片段的实例包括但不限于双功能抗体、fab、fab'、f(ab')2、fv片段、二硫键稳定化的fv片段(dsfv)、(dsfv)2、双特异性dsfv(dsfv
‑
dsfv')、二硫键稳定化的双功能抗体(ds双功能抗体)、单链抗体分子(scfv)、scfv二聚体(二价双功能抗体)、双特异性抗体、多特异性抗体、骆驼单结构域抗体、纳米抗体、结构域抗体和二价结构域抗体。抗原结合片段能够与亲本抗体所结合的相同抗原结合。
[0111]“fab片段”包含一条轻链和一条重链的c
h
1和可变结构域。fab分子的重链无法与另一重链分子形成二硫键。
[0112]“fab
′
片段”包含一条轻链和一条重链的一部分,所述部分含有v
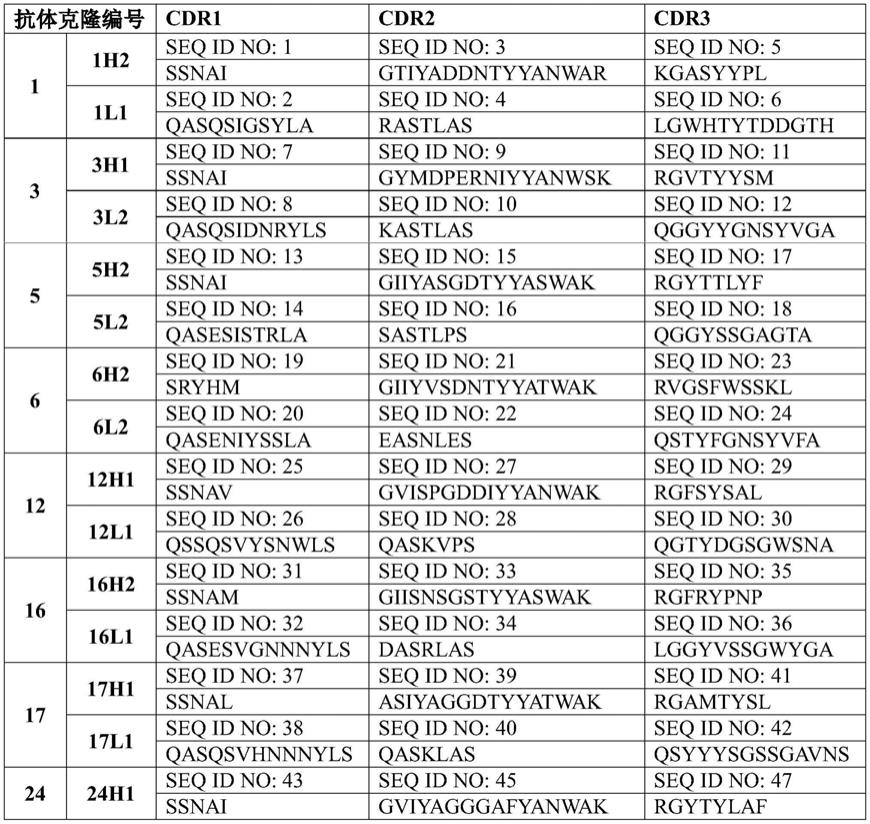
h
结构域和c
h
1结构域并且还含有介于c
h
1与c
h
2结构域之间的区域,因此可以在两个fab
′
片段的两条重链之间形成链间二硫键,以形成f(ab
′
)2分子。
[0113]“f(ab')2片段”含有两条轻链和两条重链,所述两条重链含有位于c
h
1结构域与c
h
2结构域之间的恒定区的一部分,使得在两条重链之间形成链间二硫键。f(ab
′
)2片段从而由两个fab
′
片段构成,这两个片段通过两条重链之间的二硫键保持在一起。
[0114]
关于抗体的“fv”是指最小的带有完整抗原结合位点的抗体片段。fv片段由与单个重链的可变结构域结合的单条轻链的可变结构域组成。
[0115]“dsfv”是指二硫键稳定化的fv片段,其中在单条轻链的可变结构域与单条重链的可变结构域之间的键联是二硫键。在一些实施方式中,“(dsfv)
2”或“(dsfv
‑
dsfv')”包含三条肽链:通过肽连接子(例如较长柔性连接子)连接且分别通过二硫桥键与两个v
l
部分结合的两个v
h
部分。在一些实施方式中,dsfv
‑
dsfv'具有双特异性,其中每个二硫键配对的重链和轻链具有不同抗原特异性。
[0116]“单链fv抗体”或“scfv”是指由轻链可变结构域和重链可变结构域组成的工程改造的抗体,所述轻链可变结构域和重链可变结构域直接或通过肽连接子序列彼此连接(huston js等人《美国国家科学院院刊》,85:5879(1988))。
[0117]“fc”区包含两个重链片段,其包含抗体的c
h
2和c
h
3结构域。两个重链片段由两个或更多个二硫键且通过c
h
3结构域的疏水相互作用保持在一起。抗体的fc区负责各种效应功能,如抗体依赖性细胞介导的细胞毒性(adcc)和补体依赖性细胞毒性(cdc),但不具有抗原
结合的功能。
[0118]“单链fv
‑
fc抗体”或“scfv
‑
fc”是指由与抗体fc区连接的scfv组成的工程改造的抗体。
[0119]“骆驼单结构域抗体”、“重链抗体”或“hcab”是指含有两个v
h
结构域且不含轻链的抗体(riechmann l.和muyldermans s.,《免疫学方法杂志(j immunol methods)》.12月10日;231(1
‑
2):25
‑
38(1999);muyldermans s.,《生物技术杂志(j biotechnol)》.6月;74(4):277
‑
302(2001);wo94/04678;wo94/25591;美国专利号6,005,079)。重链抗体最初来源于骆驼科(camelidae)(骆驼、单峰骆驼和羊驼)。虽然不含轻链,但骆驼化抗体具有可靠的抗原结合组库(hamers
‑
casterman c.等人,《自然》6月3日;363(6428):446
‑
8(1993);nguyen vk.等人,《骆驼科重链抗体:进化创新案例(heavy
‑
chain antibodies in camelidae;a case of evolutionary innovation)》,《免疫遗传学(immunogenetics)》.4月;54(1):39
‑
47(2002);nguyen vk.等人,《免疫学(immunology)》.5月;109(1):93
‑
101(2003))。重链抗体的可变结构域(vhh结构域)代表由后天免疫反应产生的已知最小的抗原结合单元(koch
‑
nolte f.等人,《美国实验生物学学会联合会杂志(faseb j)》11月;21(13):3490
‑
8.电子版2007年6月15日(2007))。
[0120]“纳米抗体”是指由来自重链抗体的vhh结构域和两个恒定结构域ch2和ch3组成的抗体片段。
[0121]“双功能抗体”或“dab”包括具有两个抗原结合位点的小抗体片段,其中所述片段包含同一多肽链中与v
l
结构域连接的v
h
结构域(v
h
‑
v
l
或v
l
‑
v
h
)(参见例如holliger p.等人,《美国国家科学院院刊》7月15日;90(14):6444
‑
8(1993);ep404097;wo93/11161)。通过使用过短以使得同一链上的两个结构域之间不能配对的连接子,迫使结构域与另一条链的互补结构域配对,从而产生两个抗原结合位点。所述抗原结合位点可靶向相同或不同的抗原(或表位)。在某些实施方式中,“双特异性ds双功能抗体”是靶向两个不同抗原(或表位)的双功能抗体。在某些实施方式中,“scfv二聚体”是二价双功能抗体或二价scfv(bsfv),其包含v
h
‑
v
l
(由肽连接子连接)与另一v
h
‑
v
l
部分二聚,使得一个部分的v
h
与另一部分的v
l
配位并形成可靶向同一抗原(或表位)或不同抗原(或表位)的两个结合位点。在其它实施方式中,“scfv二聚体”是双特异性双功能抗体,其包含v
h1
‑
v
l2
(由肽连接子连接)与v
l1
‑
v
h2
(也由肽连接子连接)结合,使得v
h1
与v
l1
配位且v
h2
与v
l2
配位并且每个配位对具有不同的抗原特异性。
[0122]“结构域抗体”是指仅含有重链的可变结构域或轻链的可变结构域的抗体片段。在某些情况下,两个或更多个v
h
结构域与肽连接子共价接合以产生二价或多价结构域抗体。二价结构域抗体的两个v
h
结构域可靶向相同或不同的抗原。
[0123]
如本文所用,“双特异性”抗体是指具有来源于两种不同单克隆抗体的片段且能够与两种不同的表位结合的人工抗体。两个表位可存在于同一抗原上,或其可存在于两种不同抗原上。
[0124]
如本文所用,术语“嵌合”意指一部分重链和/或轻链来源于一个物种且其余重链和/或轻链来源于不同物种的抗体或抗原结合片段。在说明性实例中,嵌合抗体可包含来源于人类的恒定区和来源于非人动物(如小鼠或兔)的可变区。在一些实施方式中,非人动物是哺乳动物,例如小鼠、大鼠、兔、山羊、绵羊、豚鼠或仓鼠。
[0125]
如本文所用,术语“人源化”意指抗体或抗原结合片段包含来源于非人动物的cdr、
来源于人类的fr区,和在适用时,来源于人类的恒定区。
[0126]
如本文所用,“cd40”是指来源于任何脊椎动物来源,包括哺乳动物,例如灵长类动物(例如人类、猴)和啮齿动物(例如小鼠和大鼠)的cd40。人cd40的示范性序列包括人cd40蛋白质(ncbi参考序列号alq33424.1)。cd40的示范性序列包括小鼠cd40蛋白质(ncbi参考序列号aab08705.1);褐家鼠(大鼠)cd40蛋白质(ncbi参考序列号aah97949.1)。如本文所用,术语“cd40”打算涵盖cd40的任何形式,例如,1)天然未加工的cd40分子、“全长”cd40链或cd40的天然存在的变异体,包括例如剪接变异体或等位基因变异体;2)由细胞中的加工产生的cd40的任何形式;或3)通过重组方法产生的cd40子单元的全长、片段(例如截断形式、细胞外/跨膜结构域)或经修饰形式(例如突变形式、糖基化/聚乙二醇化、his
‑
标签/免疫荧光融合形式)。
[0127]
术语“抗cd40抗体”是指能够特异性地与cd40(例如人或小鼠或兔cd40)结合的抗体。
[0128]
如本文所用,术语“特异性结合(specific binding/specifically binds)”是指两个分子之间,例如抗体和抗原之间的非随机结合反应。在某些实施方式中,本文提供的抗体或抗原结合片段与人和/或cd40特异性结合,其结合亲和力(k
d
)≤10
‑6m(例如,≤5
×
10
‑7m、≤2
×
10
‑7m、≤10
‑7m、≤5
×
10
‑8m、≤2
×
10
‑8m、≤10
‑8m、≤5
×
10
‑9m、≤4
×
10
‑9m、≤3
×
10
‑9m、≤2
×
10
‑9m或≤10
‑9m)。本文使用的k
d
是指解离速率相对于缔合速率的比率(k
off
/k
on
),其可通过使用所属领域中已知的任何常规方法来确定,所述方法包括但不限于表面等离子体共振方法、微尺度热泳方法、hplc
‑
ms方法和流式细胞测量(如facs)方法。在某些实施方式中,k
d
值可通过使用流式细胞测量术适当地确定。
[0129]
如本文所用,“阻断结合”或“竞争相同表位”的能力是指抗体或抗原结合片段以任何可检测程度抑制两个分子(例如人cd40和抗cd40抗体)之间的结合相互作用的能力。在某些实施方式中,阻断两个分子之间的结合的抗体或抗原结合片段将两个分子之间的结合相互作用抑制至少85%或至少90%。在某些实施方式中,此抑制可大于85%,或大于90%。
[0130]
如本文所用,术语“表位”是指抗体所结合的抗原上特定的一组原子或氨基酸。如果两种抗体展现针对抗原的竞争性结合,那么其可以结合所述抗原内的相同或紧密相关的表位。举例来说,如果抗体或抗原结合片段将参考抗体与抗原的结合阻断至少85%、或至少90%或至少95%,那么抗体或抗原结合片段可视为结合与参考抗体相同/紧密相关的表位。
[0131]
所属领域的技术人员将认识到,有可能在无过度实验的情况下,确定给定抗体是否与本公开的抗体相同的表位结合,其方法是确定前者是否阻止后者与cd40抗原多肽结合。如果给定抗体与本公开的抗体竞争,如通过本公开的抗体与cd40抗原多肽的结合减少所展示,那么两种抗体与相同或密切相关的表位结合。或者,如果给定抗体与cd40抗原多肽的结合由本公开的抗体抑制,那么两种抗体与相同或紧密相关的表位结合。
[0132]
关于氨基酸序列的“保守取代”是指用具有类似生理化学特性的侧链的不同氨基酸残基置换氨基酸残基。举例来说,可在具有疏水性侧链的氨基酸残基(例如met、ala、val、leu和ile)间、具有中性亲水性侧链的残基(例如cys、ser、thr、asn和gln)间、具有酸性侧链的残基(例如asp、glu)间、具有碱性侧链的氨基酸(例如his、lys和arg)间或具有芳香族侧链的残基(例如trp、tyr和phe)间进行保守取代。如所属领域中已知,保守取代通常不会引起蛋白质构象结构的显著变化,并且因此可保留蛋白质的生物活性。
[0133]
如本文所用,“效应功能”是指由抗体fc区与其效应子(如c1复合物和fc受体)结合引起的生物活性。示范性效应功能包括:由抗体与c1复合物上的c1q的相互作用诱导的补体依赖性细胞毒性(cdc);由抗体fc区与效应细胞上的fc受体的结合诱导的抗体依赖性细胞介导的细胞毒性(adcc);和吞噬作用。
[0134]
如本文所用,术语“同源物”和“同源”是可互换的并且是指当最佳地比对时与另一序列具有至少80%(例如至少85%、88%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%)序列同一性的核酸序列(或其互补链)或氨基酸序列。
[0135]
术语“宿主细胞”意指已经用核酸序列转化或能够用核酸序列转化并且从而表达相关基因的细胞。所述术语包括亲本细胞的后代,无论后代与原始亲本细胞在形态上或遗传构成上是否相同,只要存在相关基因即可。
[0136]“分离”的物质已通过人工方式自天然状态改变。如果“分离”的组合物或物质存在于自然界中,则所述组合物或物质已经从其原始环境改变或从其原始环境移出,或这两种情况都有。例如,天然地存在于活动物体内的多核苷酸或多肽不是“分离”的,但如果相同多核苷酸或多肽与其天然状态的共存材料充分地分离,由此以基本上纯的状态存在,那么所述多核苷酸或多肽是“分离”的。“分离的核酸序列”是指分离核酸分子的序列。在某些实施方式中,“分离的抗体或其抗原结合片段”是指如通过电泳法(如sds
‑
page、等电聚焦、毛细管电泳)或色谱法(如离子交换色谱或反相hplc)所测定,纯度为至少60%、70%、75%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的抗体或抗原结合片段。
[0137]
关于氨基酸序列(或核酸序列)的“序列同一性百分比(%)”定义为在比对序列并在必要时引入空位以实现最大数目的相同氨基酸(或核酸)后,候选序列中与参考序列中的氨基酸(或核酸)残基相同的氨基酸(或核酸)残基的百分比。氨基酸残基的保守取代可视为或可不视为相同残基。出于确定氨基酸(或核酸)序列同一性百分比的目的进行的比对可例如使用以下实现:可公开获得的工具,如blastn、blastp(可见于美国国家生物技术信息中心(u.s.national center for biotechnology information;ncbi)的网站,另外参见altschul s.f.等人,《分子生物学杂志》,215:403
‑
410(1990);stephen f.等人,《核酸研究(nucleic acids res.)》,25:3389
‑
3402(1997))、clustalw2(可见于欧洲生物信息研究所(european bioinformatics institute)网站,另外参见higgins d.g.等人,《酶学方法(methods in enzymology)》,266:383
‑
402(1996);larkin m.a.等人,《生物信息学(bioinformatics)》(英格兰牛津(oxford,england)),23(21):2947
‑
8(2007))和align或megalign(dnastar)软件。所属领域的技术人员可使用所述工具所提供的默认参数,或可视需要例如通过选择适合算法来自定制比对的参数。
[0138]
可用于本发明的药学上可接受的载体是常规的。《雷明顿氏药物科学(remington'spharmaceutical sciences)》,e.w.martin著,mack publishing公司,宾夕法尼亚州伊斯顿(easton,pa.),第15版(1975)描述适用于本文中所公开的融合蛋白的药物递送的组合物和配制物。一般,载体的性质取决于所采用的特定施用模式。举例来说,非经肠配制物通常包含包括药学上和生理学上可接受的流体的可注射流体,如水、生理盐水、平衡盐溶液、右旋糖水溶液、甘油等来作为媒剂。对于固体组合物(例如粉末、丸剂、片剂或胶囊形式),常规的无毒固体载体可以包括例如药物级甘露糖醇、乳糖、淀粉或硬脂酸镁。除生物中性载体
外,待施用的药物组合物还可以含有少量无毒辅助物质,如润湿剂或乳化剂、防腐剂和ph缓冲剂等,例如乙酸钠或脱水山梨糖醇单月桂酸酯。
[0139]
如本文所用,术语“受试者”是指人类或任何非人动物(例如,小鼠、大鼠、兔、狗、猫、牛、猪、绵羊、马或灵长类动物)。人类包括出生前和出生后形式。在许多实施方式中,受试者是人类。受试者可以是患者,所述患者是指呈现给医疗服务提供者以进行疾病诊断或治疗的人类。术语“受试者”在本文中可与“个体”或“患者”互换使用。受试者可患有或易患疾病或病症,但可能或可能不表现出疾病或病症的症状。
[0140]
如本文所用,术语“治疗有效量”或“有效剂量”是指可有效治疗疾病或病状的药物的剂量或浓度。举例来说,关于使用本文所公开的单克隆抗体或其抗原结合片段治疗癌症,治疗有效量为能够降低肿瘤体积、根除全部或部分肿瘤、抑制或减缓肿瘤生长或癌细胞渗透到其它器官中、抑制介导癌性病状的细胞的生长或增殖、抑制或减缓肿瘤细胞转移、改善与肿瘤或癌性病状相关的任何症状或标记物、预防或延迟肿瘤或癌性病状的发展或其某一组合的单克隆抗体或其抗原结合片段的剂量或浓度。
[0141]
如本文所用,病状的“治疗(treating/treatment)”包括预防或减轻病状,减缓病状的发作或发展速率,降低罹患病状的风险,预防或延迟与病状相关的症状的发展,减少或结束与病状相关的症状,产生病状的完全或部分消退,治愈病状或其某一组合。
[0142]
如本文所用,术语“载体”是指可以将编码蛋白质的多核苷酸可操作地插入其中以产生所述蛋白质表达的运载体。载体可用于转化、转导或转染宿主细胞,以使其携带的基因元件在宿主细胞内表达。载体的实例包括质粒;噬菌粒;粘粒;人工染色体,如酵母人工染色体(yac)、细菌人工染色体(bac)或p1衍生的人工染色体(pac);噬菌体,如λ噬菌体或m13噬菌体;和动物病毒。用作载体的动物病毒的类别包括逆转录病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(例如单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒和乳多空病毒(例如sv40)。载体可以含有多种用于控制表达的元件,包括启动子序列、转录起始序列、增强子序列、可选元件和报告基因。另外,载体可以含有复制起点。载体还可以包括有助于其进入细胞的材料,包括但不限于病毒粒子、脂质体或蛋白质包衣。载体可以是表达载体或克隆载体。本公开提供了含有本文提供的编码抗体或其抗原结合片段的核酸序列、至少一个与所述核酸序列可操作地连接的启动子(例如sv40、cmv、ef
‑
1α)和至少一个选择标记物的载体(例如表达载体)。载体的实例包括但不限于逆转录病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(例如单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒、乳多空病毒(例如sv40)、λ噬菌体和m13噬菌体、质粒pcdna3.3、pmd18
‑
t、poptivec、pcmv、pegfp、pires、pqd
‑
hyg
‑
gseu、palter、pbad、pcdna、pcal、pl、pet、pgemex、pgex、pci、pegft、psv2、pfuse、pvitro、pvivo、pmal、pmono、pselect、puno、pduo、psg5l、pbabe、pwpxl、pbi、p15tv
‑
l、ppro18、ptd、prs10、plexa、pact2.2、pcmv
‑
script.rtm.、pcdm8、pcdna1.1/amp、pcdna3.1、prc/rsv、pcr 2.1、pef
‑
1、pfb、psg5、pxt1、pcdef3、psvsport、pef
‑
bos等。
[0143]
ii.抗cd40抗体
[0144]
本公开提供抗cd40抗体和其抗原结合片段。本文提供的抗cd40抗体和抗原结合片段能够与cd40特异性结合。
[0145]
本文提供的抗体和抗原结合片段的结合亲和力可以由k
d
值表示,所述k
d
值表示抗原和抗原结合分子之间的结合达到平衡时,解离速率相对于缔合速率的比率(k
off
/k
on
)。抗
原结合亲和力(例如k
d
)可以使用所属领域中已知的适合方法(包括例如生物层干涉测量法)来适当地测定。
[0146]
在一些实施方式中,如通过生物层干涉测量法所测量,本文提供的抗cd40抗体和其抗原结合片段能够以不超过7pm、不超过10pm、不超过50pm、不超过100pm、不超过200pm、不超过300pm或不超过400pm的结合亲和力(k
d
)与人cd40特异性结合。
[0147]
抗体与人cd40的结合也可由“半最大有效浓度”(ec
50
)值表示,ec
50
是指观察到其最大作用(例如结合或抑制作用等)的50%时的抗体浓度。ec
50
值可以通过所属领域中已知的方法,例如夹心分析,如elisa、蛋白质印迹(western blot)、流式细胞测量分析和其它结合分析来测量。在某些实施方式中,如通过流式细胞测量分析所测量,本文所提供的抗体和其片段以不超过0.06nm、不超过0.07nm、不超过0.08nm、不超过0.09nm或不超过0.1nm的ec
50
(即50%结合浓度)与在细胞表面上表达的cd40特异性结合。
[0148]
在某些实施方式中,本文提供的抗体和其片段对人cd40具有特异性结合亲和力,其足以提供诊断和/或治疗用途。
[0149]
在某些实施方式中,本文提供的抗体和其片段与cd40配体竞争结合cd40。
[0150]
cd40的天然存在的配体为cd40l(也称为cd154、gp39和trap),一个tnf超家族成员。cd40l为主要在活化的cd4
t细胞和较小cd8
t细胞子集上表达的跨膜蛋白质(由(van kooten c.和banchereau,2000综述)。cd40l作为三聚结构存在于所述细胞上,其在结合时诱导其受体寡聚。
[0151]
cd40与cd40l的相互作用诱导体液和细胞介导的免疫反应。cd40调节此配体
‑
受体对以活化b细胞和其它包括树突状细胞(dc)的抗原呈递细胞(apc)(参见toubi和shoenfeld,2004;kiener等人,1995)。cd40在b细胞上的活化诱导增殖、免疫球蛋白类别变换、抗体分泌,并且还在生发中心的发展和记忆b细胞的存活方面具有一定作用,所有这些方面都对体液免疫反应是必不可少的(kehry mr.《免疫学杂志(j immunol)》1996;156:2345
‑
2348)。cd40l与cd40在树突状细胞上的结合诱导dc成熟,如通过协同刺激分子,如b7家族(cd80,cd86)的表达增加和产生促炎性细胞因子,如白介素12所体现。这些引起强烈的t细胞反应(stout,r.d.,j.suttles.1996.《今日免疫学(immunol.today)》17:487
‑
492;brendan o'sullivan,ranjeny thomas.《免疫学评论(critical reviews in immunology)》2003;23:83
‑
107;cella,m.,d.scheidegger,k.palmer
‑
lehmann,p.lane,a.lanzavecchia,g.alber.《实验医学杂志(j.exp.med.)》1996;184:747
‑
452)。
[0152]
cd40
‑
cd40l在驱动有效t细胞依赖性免疫反应中起关键作用。通过与cd40l竞争结合cd40,本文提供的抗体和其片段阻断cd40
‑
cd40l的结合和相互作用且阻断cd40信号传导,并且由此提供抑制病原性自身免疫反应的活性。
[0153]
在某些实施方式中,如通过协同刺激分子(如cd80、cd83、cd86)的表达增加所显现的,本文所提供的抗体和其片段与树突状细胞上cd40的结合诱导dc成熟。这些引起强烈的t细胞反应(参见stout,r.d.,j.suttles.1996.《今日免疫学》17:487
‑
492;brendan o'sullivan,ranjeny thomas.《免疫学评论》2003;23:83
‑
107;cella,m.,d.scheidegger,k.palmer
‑
lehmann,p.lane,a.lanzavecchia,g.alber.《实验医学杂志》1996;184:747
‑
452)。在某些实施方式中,如协同刺激分子(如cd80、cd83、cd86)的上调所测量到的,本文提供的抗体和其片段与cd40的结合诱导dc活化。在某些实施方式中,如协同刺激分子(如b7家
族(cd80,cd86))的上调所测量到的,本文提供的抗体和其片段与cd40的结合诱导b细胞活化。
[0154]
iii.特异性抗cd40抗体
[0155]
本公开提供抗cd40抗体和其抗原结合片段,其包含以下抗cd40抗体克隆的一个或多个(例如1、2、3、4、5或6个)cdr序列:抗cd40抗体克隆1、3、5、6、12、16、17、24、26、27、31、45、58、70、78、86、91、93、94、102、103、105、108、109、110、114、120、121、129、134、151、166、167、193、217、233、169a、176a、181a、183、184、5
‑
z或6
‑
z。
[0156]
如本文所用,抗体克隆1是指兔单克隆抗体,其具有seq id no:247的重链(1h2)可变区和seq id no:249的轻链(1l1)可变区。
[0157]
如本文所用,抗体克隆3是指兔单克隆抗体,其具有seq id no:251的重链(3h1)可变区和seq id no:253的轻链(3l2)可变区。
[0158]
如本文所用,抗体克隆5是指兔单克隆抗体,其具有seq id no:255的重链(5h2)可变区和seq id no:257的轻链(5l2)可变区。
[0159]
如本文所用,抗体克隆6是指兔单克隆抗体,其具有seq id no:259的重链(6h2)可变区和seq id no:261的轻链(6l2)可变区。
[0160]
如本文所用,抗体克隆12是指兔单克隆抗体,其具有seq id no:263的重链(12h1)可变区和seq id no:265的轻链(12l1)可变区。
[0161]
如本文所用,抗体克隆16是指兔单克隆抗体,其具有seq id no:267的重链(16h2)可变区和seq id no:269的轻链(16l1)可变区。
[0162]
如本文所用,抗体克隆17是指兔单克隆抗体,其具有seq id no:271的重链(17h1)可变区和seq id no:273的轻链(17l1)可变区。
[0163]
如本文所用,抗体克隆24是指兔单克隆抗体,其具有seq id no:275的重链(24h1)可变区和seq id no:277的轻链(24l1)可变区。
[0164]
如本文所用,抗体克隆26是指兔单克隆抗体,其具有seq id no:279的重链(26h1)可变区和seq id no:281的轻链(26l1)可变区。
[0165]
如本文所用,抗体克隆27是指兔单克隆抗体,其具有seq id no:283的重链(27h1)可变区和seq id no:285的轻链(27l2)可变区。
[0166]
如本文所用,抗体克隆31是指兔单克隆抗体,其具有seq id no:287的重链(31h2)可变区和seq id no:289的轻链(31l1)可变区。
[0167]
如本文所用,抗体克隆45是指兔单克隆抗体,其具有seq id no:291的重链(45h1)可变区和seq id no:293的轻链(45l2)可变区。
[0168]
如本文所用,抗体克隆58是指兔单克隆抗体,其具有seq id no:295的重链(58h2)可变区和seq id no:297的轻链(58l1)可变区。
[0169]
如本文所用,抗体克隆70是指兔单克隆抗体,其具有seq id no:299的重链(70h1)可变区和seq id no:301的轻链(70l2)可变区。
[0170]
如本文所用,抗体克隆78是指兔单克隆抗体,其具有seq id no:303的重链(78h2)可变区和seq id no:305的轻链(78l1)可变区。
[0171]
如本文所用,抗体克隆86是指兔单克隆抗体,其具有seq id no:307的重链(86h2)可变区和seq id no:309的轻链(86l2)可变区。
[0172]
如本文所用,抗体克隆91是指兔单克隆抗体,其具有seq id no:311的重链(91h1)可变区和seq id no:313的轻链(91l1)可变区。
[0173]
如本文所用,抗体克隆93是指兔单克隆抗体,其具有seq id no:315的重链(93h2)可变区和seq id no:317的轻链(93l2)可变区。
[0174]
如本文所用,抗体克隆94是指兔单克隆抗体,其具有seq id no:319的重链(94h1)可变区和seq id no:321的轻链(94l2)可变区。
[0175]
如本文所用,抗体克隆102是指兔单克隆抗体,其具有seq id no:323的重链(102h1)可变区和seq id no:325的轻链(102l1)可变区。
[0176]
如本文所用,抗体克隆103是指兔单克隆抗体,其具有seq id no:327的重链(103h2)可变区和seq id no:329的轻链(103l2)可变区。
[0177]
如本文所用,抗体克隆105是指兔单克隆抗体,其具有seq id no:331的重链(105h1)可变区和seq id no:333的轻链(105l4)可变区。
[0178]
如本文所用,抗体克隆108是指兔单克隆抗体,其具有seq id no:335的重链(108h1)可变区和seq id no:337的轻链(108l3)可变区。
[0179]
如本文所用,抗体克隆109是指兔单克隆抗体,其具有seq id no:339的重链(109h2)可变区和seq id no:341的轻链(109l1)可变区。
[0180]
如本文所用,抗体克隆110是指兔单克隆抗体,其具有seq id no:343的重链(110h1)可变区和seq id no:345的轻链(110l1)可变区。
[0181]
如本文所用,抗体克隆114是指兔单克隆抗体,其具有seq id no:347的重链(114h2)可变区和seq id no:349的轻链(114l1)可变区。
[0182]
如本文所用,抗体克隆120是指兔单克隆抗体,其具有seq id no:351的重链(120h1)可变区和seq id no:353的轻链(120l1)可变区。
[0183]
如本文所用,抗体克隆121是指兔单克隆抗体,其具有seq id no:355的重链(121h2)可变区和seq id no:357的轻链(121l1)可变区。
[0184]
如本文所用,抗体克隆129是指兔单克隆抗体,其具有seq id no:359的重链(129h1)可变区和seq id no:361的轻链(129l1)可变区。
[0185]
如本文所用,抗体克隆134是指兔单克隆抗体,其具有seq id no:363的重链(134h1)可变区和seq id no:365的轻链(134l2)可变区。
[0186]
如本文所用,抗体克隆151是指兔单克隆抗体,其具有seq id no:367的重链(151h1)可变区和seq id no:369的轻链(151l1)可变区。
[0187]
如本文所用,抗体克隆166是指兔单克隆抗体,其具有seq id no:371的重链(166h2)可变区和seq id no:373的轻链(166l1)可变区。
[0188]
如本文所用,抗体克隆167是指兔单克隆抗体,其具有seq id no:375的重链(167h2)可变区和seq id no:377的轻链(167l2)可变区。
[0189]
如本文所用,抗体克隆193是指兔单克隆抗体,其具有seq id no:379的重链(193h1)可变区和seq id no:381的轻链(193l2)可变区。
[0190]
如本文所用,抗体克隆217是指兔单克隆抗体,其具有seq id no:383的重链(217h2)可变区和seq id no:385的轻链(217l1)可变区。
[0191]
如本文所用,抗体克隆233是指兔单克隆抗体,其具有seq id no:387的重链
(233h1)可变区和seq id no:389的轻链(233l1)可变区。
[0192]
如本文所用,抗体克隆169a是指兔单克隆抗体,其具有seq id no:391的重链(169ah1)可变区和seq id no:393的轻链(169al1)可变区。
[0193]
如本文所用,抗体克隆176a是指兔单克隆抗体,其具有seq id no:395的重链(176ah1)可变区和seq id no:397的轻链(176al1)可变区。
[0194]
如本文所用,抗体克隆181a是指兔单克隆抗体,其具有seq id no:399的重链(181ah1)可变区和seq id no:401的轻链(181al1)可变区。
[0195]
如本文所用,抗体克隆183a是指兔单克隆抗体,其具有seq id no:403的重链(183ah2)可变区和seq id no:405的轻链(183al1)可变区。
[0196]
如本文所用,抗体克隆184a是指兔单克隆抗体,其具有seq id no:407的重链(184ah1)可变区和seq id no:409的轻链(184al1)可变区。
[0197]
如本文所用,抗体克隆5
‑
z是指基于抗体5的人源化抗体,其包含seq id no:411的重链(5h2
‑
z)可变区和seq id no:413的轻链(5l2
‑
z)可变区。抗体5
‑
z与其亲本抗体5相比具有相当的与抗原的亲和力。
[0198]
如本文所用,抗体克隆6
‑
z是指基于抗体6的人源化抗体,其包含seq id no:415的重链(6h2
‑
z)可变区和seq id no:417的轻链(6l2
‑
z)可变区。抗体6
‑
z与其亲本抗体6相比具有相当的与抗原的亲和力。
[0199]
表1展示这些43种抗cd40抗体的cdr序列。
[0200]
表1.
[0201]
[0202]
[0203]
[0204][0205][0206]
下文提供上文43种抗cd40抗体的重链和轻链可变区序列。
[0207]
1h2
[0208]
氨基酸序列(seq id no:247):
[0209]
qsleesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigtiyaddntyyanwargrftis
rtsttvdlkitspttedtatyfcakgasyyplwgpgtlvtvss
[0210]
核酸序列(seq id no:248):
[0211]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggaatggatcggaaccatttatgctgatgataacacatattacgcgaactgggcgagaggccggttcaccatctccagaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccaaaggtgcttcttattatcctttgtggggcccaggcaccctggtcaccgtctcctca
[0212]
1l1
[0213]
氨基酸序列(seq id no:249):
[0214]
vvmtqtpsstsaavegtvtincqasqsigsylawfqqkpgqppklliyrastlasgvpsrfkgsgsgtqftltisgvqredaatyyclgwhtytddgthfgggtevvvk
[0215]
核酸序列(seq id no:250):
[0216]
gtcgtgatgacccagactccatcctccacgtctgccgctgtggaaggcacagtcaccatcaattgccaggccagtcagagcattggtagctatttggcctggtttcagcagaaaccagggcagcctcccaagctcctgatctacagggcttccactctggcatctggggtcccatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagcggcgtgcagcgtgaggatgctgccacttactactgtctaggctggcatacttatactgatgatggaactcatttcggcggagggaccgaggtggtggtcaaa
[0217]
3h1
[0218]
氨基酸序列(seq id no:251):
[0219]
qsveesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigymdperniyyanwskgrftfsqtsttvdlkiasptsedtatyfcargvtyysmwgpgtlvtvss
[0220]
核酸序列(seq id no:252):
[0221]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccaggaaaggggctggagtggatcggatacatggatcctgagagaaacatatactacgcgaattggtcaaaaggccgattcaccttctcccaaacctcgaccacggtggatctgaaaatcgccagtccgacaagcgaggacacggccacctatttctgtgccagaggtgttacttattattcaatgtggggcccgggcaccctggtcaccgtctcctca
[0222]
[0223]
3l2
[0224]
氨基酸序列(seq id no:253):
[0225]
dvvmtqtpasvsepvggtvtikcqasqsidnrylswyqqkpgqppklliykastlasgvssrfkgsgsgteftltisdlecadaatyycqggyygnsyvgafgggtevvvk
[0226]
核酸序列(seq id no:254):
[0227]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtcagagtattgataataggtacttatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctacaaggcatccactctggcatctggggtctcatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggcggttattatggtaatagttatgttggcgctttcggcggagggaccgaggtggtggtcaaa
[0228]
5h2
[0229]
氨基酸序列(seq id no:255):
[0230]
qsvkesggglfkptdtltltctvsgfslssnaiswvrqapgkglewigiiyasgdtyyaswakgrftisktssttvdlkmtslttegtatyfcargyttlyfwgpgtlvtvss
[0231]
核酸序列(seq id no:256):
[0232]
cagtcagtgaaggagtccgggggaggtctcttcaagccaacggataccctgacactcacctgcaccgtctctggattctccctcagtagtaatgcaataagctgggtccgccaggctccagggaaggggctggaatggatcggaatcatttatgctagtggtgacacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgtcgaccacggtggatctgaaaatgaccagtctgacaaccgagggcacggccacctatttctgtgccagaggatatactactctttacttctggggcccaggcaccctggtcaccgtctcctca
[0233]
5l2
[0234]
氨基酸序列(seq id no:257):
[0235]
qivmtqtpasvsaavggtvtikcqasesistrlawyqqkpgqppklliysastlpsgvpsrfsgsgsgtdftltisgvqcddaatyycqggyssgagtafgggtevvvk
[0236]
核酸序列(seq id no:258):
[0237]
caaattgtgatgacccagactccagcctccgtgtctgcagctgtgggaggcacagtcaccatcaagtgccaggccagtgagagtattagtactaggttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctactctgcatccactctgccatctggggtcccatcgcggttcagtggcagtggatctgggacagacttcactctcaccatcagcggcgtgcagtgtgacgatgctgccacttactactgtcaaggcggttatagtagtggtgctggtactgctttcggcggagggaccgaggtggtggtcaaa
[0238]
6h2
[0239]
氨基酸序列(seq id no:259):
[0240]
qsleesggrlvtpgtpltltctasgfdfsryhmcwvrqapgkglewigiiyvsdntyyatwakgrftisrtsttvdlkitspttedtatyfcvrvgsfwssklwgpgtlvtvss
[0241]
核酸序列(seq id no:260):
[0242]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagcctctggattcgacttcagtaggtaccacatgtgctgggtccgccaggctccagggaaggggctggaatggatcggaatcatttatgttagtgataacacatactacgcgacctgggcaaaaggccgattcaccatctccagaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgtcagagttggtagtttttggagcagtaagttgtggggcccaggcaccctggtcaccgtctcctca
[0243]
6l2
[0244]
氨基酸序列(seq id no:261):
[0245]
dvvmtqtpasvsepvggtvtincqaseniysslawyqqkpgqppklliyeasnlesgvssrfsgsgsgteftltisdlecadaatyycqstyfgnsyvfafgggtevvvk
[0246]
核酸序列(seq id no:262):
[0247]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaattgccaggccagtgagaacatttacagctctttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctatgaagcatccaatctagaatctggggtctcatcaaggttcagcggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaatctacttatttcggtaatagttatgtttttgctttcggcggagggaccgaggtggtggtcaaa
[0248]
12h1
[0249]
氨基酸序列(seq id no:263):
[0250]
qsveesggrlvtpgtpltltctvsgfslssnavnwvrqapgeglewigvispgddiyyanwakgrftisktsttvdlkitspttedtatyfcargfsysalwgqgtlvtvss
[0251]
核酸序列(seq id no:264):
[0252]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcagtagtaatgcagtgaactgggtccgccaggctccaggggaggggctggaatggatcggagtcattagtcctggtgatgacatatactacgcgaattgggcaaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagaggtttttcctattcagccttgtggggccaaggcaccctggtcaccgtctcctca
[0253]
12l1
[0254]
氨基酸序列(seq id no:265):
[0255]
qvltqtaspvsaavggtvtincqssqsvysnwlswyqqkpgqrpklliyqaskvpsgvssrfsgsgsgtqfiltisgvqcddaatyycqgtydgsgwsnafgggtevvvk
[0256]
核酸序列(seq id no:266):
[0257]
caagtgctgacccagactgcatcgcccgtgtctgccgctgtgggaggcacagtcaccatcaactgccagtccagtcagagtgtttatagtaactggctatcctggtatcagcagaaaccagggcagcgtcccaagctcctgatctaccaggcatccaaggtgccatctggggtctcatcgcggttcagcggcagtggatctgggacacagttcattctcaccatcagcggcgtgcagtgtgacgatgctgccacttactactgtcaaggcacttatgatggtagtggttggtctaatgctttcggcggagggaccgaggtggtggtcaaa
[0258]
16h2
[0259]
氨基酸序列(seq id no:267):
[0260]
qsveesggrlvtpgtpltltctvsgidlssnamtwvrqapgeglewigiisnsgstyyaswakgrftisktssttvdlkmtslttedtatyfcargfrypnpwgpgtlvtvss
[0261]
核酸序列(seq id no:268):
[0262]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggaatcgacctcagtagcaatgcaatgacctgggtccgccaggctccaggggaggggctggaatggatcggaatcattagtaatagtggtagcacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgtcgaccacggtggatctgaaaatgaccagtctgacaaccgaggacacggccacctatttctgtgccagaggttttagatatcctaatccctggggcccaggcaccctggtcaccgtctcctca
[0263]
16l1
[0264]
氨基酸序列(seq id no:269):
[0265]
qvltqtpssvsaavggtvtincqasesvgnnnylswyqqrpgqppkvliydasrlasgvssrfkgsgsgtqftltisgvqcddaatyyclggyvssgwygafgggtevvvk
[0266]
核酸序列(seq id no:270):
[0267]
caagtgctgacccagactccatcctccgtgtctgcagctgtgggaggcacagtcaccatcaattgccaggccagtgagagtgttggtaataacaactacttatcctggtatcagcaaagaccagggcagcctcccaaggtcttgatctacgatgcatccaggctggcatctggggtctcatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagtggtgtgcaatgtgacgatgctgccacttactattgtctaggcggttatgttagtagtggttggtatggg
gctttcggcggagggaccgaggtggtggtcaaa
[0268]
17h1
[0269]
氨基酸序列(seq id no:271):
[0270]
qsleesggdlvkpgasliltctasgfdfssnalcwvrqapgkglewiasiyaggdtyyatwakgrftvsktssttvflqmtsltaadtatyfcargamtyslwgpgtlvtvss
[0271]
核酸序列(seq id no:272):
[0272]
cagtcgttggaggagtccgggggagacctggtcaagcctggggcatccctgatactcacctgcacagcctctggattcgacttcagtagcaatgcactgtgctgggtccgccaggctccagggaaggggctggagtggatcgcatccatttatgctggtggtgacacttactacgcgacctgggcgaaaggccgattcaccgtctccaaaacctcgtcgaccacggtgtttctgcagatgaccagtctgacagccgcggacacggccacctatttctgtgcgaggggtgctatgacttatagtttgtggggcccaggcaccctggtcaccgtctcctca
[0273]
17l1
[0274]
氨基酸序列(seq id no:273):
[0275]
adivmtqtpasveaamggtvtincqasqsvhnnnylswyqqkpgqppklliyqasklasggpsrfkgsgsgteftltisdlecadaatyycqsyyysgssgavnsfgggtevvvk核酸序列(seq id no:274):
[0276]
gctgacattgtgatgacccagactccagcctccgtggaggcagctatgggaggcacagtcaccatcaactgccaggccagtcagagtgttcataataataactacttatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctaccaggcatccaaactggcatctgggggcccatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaagctattattatagtggtagtagtggtgccgttaattctttcggcggagggaccgaggtggtggtcaaa
[0277]
24h1
[0278]
氨基酸序列(seq id no:275):
[0279]
qeqlkesggdlvtpgtpltltctvsgfslssnaiswvrqapgkglewigviyagggafyanwakgrftfsktsttvdlkmtslttedtasyfctrgytylafwgqgtlvtvss
[0280]
核酸序列(seq id no:276):
[0281]
caggagcagttgaaggagtccgggggagacctggtcacgcctgggacacccctgacactcacctgcacagtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggaatggatcggagtcatttatgctggtggtggcgcattctacgcgaactgggcgaaaggccgattcaccttctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacaaccgaggacacggcctcttatttctgtaccagaggctatacttatttggccttctggggccagggcaccctggtcaccgtctcctca
[0282]
24l1
[0283]
氨基酸序列(seq id no:277):
[0284]
adivmtqtpasveaavggtvtincqasqsisnliswyqqkpgqppklliykastlasgvssrfkgsgsgteytltisdlecadaatyycqgsaygtsdvcafgggtevvvk
[0285]
核酸序列(seq id no:278):
[0286]
gctgacattgtgatgacccagactccagcctccgtggaggcagctgtgggaggcacagtcaccatcaattgccaggccagtcagagcattagcaacctcatttcttggtatcagcagaaaccagggcagcctcccaaactcctgatctacaaggcatccactctggcatctggggtctcatcgcggttcaaaggcagtggatctgggacagagtacactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggctctgcttatggtactagtgatgtttgt
gctttcggcggagggaccgaggtggtggtcaaa
[0287]
26h1
[0288]
氨基酸序列(seq id no:279):
[0289]
qsveesggrlvtpgtpltltctvsgidlssnamtwvrqapgeglewigaidangspyytnwakgrftisktsttvtlkmtspttedtatyfcargytrldlwgqgtlvtvss
[0290]
核酸序列(seq id no:280):
[0291]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggaatcgacctcagtagcaatgcaatgacctgggtccgccaggctccaggggaggggctggaatggatcggagccattgatgctaatggtagcccatactacacgaactgggcgaaaggccgattcaccatctccaaaacctcgaccacggtgactctgaaaatgaccagtccgacaaccgaggacacggccacctatttctgtgccagagggtatactcggttggatctctggggccagggcaccctggtcaccgtctcctca
[0292]
26l1
[0293]
氨基酸序列(seq id no:281):
[0294]
qvltqtpssvsaavggtvtincqssqsilsdnylawyqqkpgqppklliyqasklvsgvssrfkgsgsgtgftltisgvqcddaatyycqgaydssdwygafgggtevvvk
[0295]
核酸序列(seq id no:282):
[0296]
caagtgctgacccagactccatcctccgtgtctgcagctgtgggaggcacagtcaccatcaattgccagtccagtcagagtattttgagtgacaactacttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctaccaggcatccaaattggtttctggggtctcatcgcgattcaaaggcagtggatctgggacaggattcactctcaccatcagcggcgtgcagtgtgacgatgctgccacttactactgtcaaggcgcttatgatagtagtgattggtacggtgctttcggcggagggaccgaggtggtggtcaaa
[0297]
27h1
[0298]
氨基酸序列(seq id no:283):
[0299]
qsveesggrlvtpgtpltltctvsgfslnnyamiwvrqapgegleyigfinsggsayyaswakgrftisrtsttvdlkmtsltaadtatyfcargvpkmdlwgqgtlvtvss
[0300]
核酸序列(seq id no:284):
[0301]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcaataactatgcaatgatctgggtccgccaggctccaggggaggggctggaatacatcggattcattaattctggtggtagcgcatactacgcgagctgggcaaaaggccgattcaccatctccagaacctcgaccacggtggatctgaaaatgaccagtctgacagccgcggacacggccacctatttctgtgccagaggggttcctaagatggacttgtggggccaaggcaccctggtcaccgtctcctca
[0302]
27l2
[0303]
氨基酸序列(seq id no:285):
[0304]
ivmtqtpssvsaavggtvtincqasqsvyngnelswyqqkpgqppklliyaasilasgvpsrfkgsgwgthftltisdvvcddaatyycagyqssviddigfgggtevvvk
[0305]
核酸序列(seq id no:286):
[0306]
atcgtgatgacccagactccatcctccgtgtctgcagctgtgggaggcacagtcaccatcaattgccaggccagtcaaagtgtttataatggcaacgaattatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctatgctgcatccattttggcatccggggtcccatcgcggttcaaaggcagtgggtgggggacacacttcactctca
ccatcagcgatgtggtgtgcgacgatgctgccacttactactgtgcaggatatcaaagtagcgttattgatgatattggtttcggcggagggaccgaggtggtggtcaaa
[0307]
31h2
[0308]
氨基酸序列(seq id no:287):
[0309]
qsveesggrlvtpggsltltctvsgfslnnyamiwvrqapgegleyigfintgdrayyaswakgrftisktssttvdlkmtsltaadtatyfcargvpamglwgqgtlvtvss
[0310]
核酸序列(seq id no:288):
[0311]
cagtcggtggaggagtccgggggtcgcctggtaacgcctggaggatccctgacactcacctgcacagtctctggattctccctcaataactatgcaatgatctgggtccgccaggctccaggggagggactggaatacatcggattcattaatactggtgatcgcgcatactatgcgagctgggcaaaaggccgattcaccatctccaaaacctcgtcgaccacggtggatctgaaaatgaccagtctgacagccgcggacacggccacctatttctgtgccagaggggttcctgctatgggcttgtggggccagggcaccctggtcaccgtctcctca
[0312]
31l1
[0313]
氨基酸序列(seq id no:289):
[0314]
ivmtqtpspvsaavgdpvtincqasqsvynnnelswyqqkpgqapklliyaasyvasgvpsrfkgsgsgtqftltisnvvcddaatyycagyessgiddigfgggtevvvk
[0315]
核酸序列(seq id no:290):
[0316]
atcgtgatgacccagactccatctcccgtgtctgcagctgtgggagatccagtcaccatcaattgccaggccagtcagagtgtttataataataacgaattatcctggtatcagcagaaacctgggcaggctcccaagctcctgatctatgctgcatcctatgtggcatctggggtcccatcgcggttcaaaggcagtggatctgggacgcagttcactctcaccatcagcaatgtggtgtgtgacgatgctgccacttactactgtgcaggatatgaaagtagtggtattgatgatattggtttcggcggagggaccgaggtggtggtcaaa
[0317]
45h1
[0318]
氨基酸序列(seq id no:291):
[0319]
qsveesggrlvtpgtpltltctvsgfslssnamtwvrqapgqglewigiiyasgstyyaswakgrftisktssttvdlkmtspttedtatyfcargfarlplwgqgtlvtvss
[0320]
核酸序列(seq id no:292):
[0321]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggattctccctcagtagcaatgcaatgacctgggtccgccaggctccagggcaggggctggaatggatcggaatcatttatgctagtggtagcacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgtcgaccacggtggatctgaaaatgaccagtccgacaaccgaggacacggccacctatttctgtgccagaggatttgcccggttgccgttgtggggccagggcaccctggtcaccgtctcctca
[0322]
45l2
[0323]
氨基酸序列(seq id no:293):
[0324]
qvltqtpssvsaavggtvtincqssqsvgsnylswyqqkpgqppklliydastlasgvpsrfsgsgsgtqftltisgvqcddaatyycqgsyyssdwygafgggtevvvk
[0325]
核酸序列(seq id no:294):
[0326]
caagtgctgacccagactccatcctccgtgtctgcagccgtgggaggcacagtcaccatcaattgccagtccagtcagagtgttggtagtaactacttatcctggtatcagcagaaaccagggcagcctcccaagctcttgatcta
cgatgcatccactctggcatctggggtcccatcgcggtttagcggcagtggatctgggacacagttcactctcaccatcagcggcgtgcagtgtgacgatgctgccacttactactgtcaaggcagttattatagtagtgattggtacggtgctttcggcggagggaccgaggtggtggtcaaa
[0327]
58h2
[0328]
氨基酸序列(seq id no:295):
[0329]
qsleesggdlvkpgasltltctatgfsfntnyymcwvrqapgkgleliacsyttsgstyyatwakgrftfsktssttvtlqmtsltaadtatyfcvkygagytynlwgpgtlvtvss
[0330]
核酸序列(seq id no:296):
[0331]
cagtcgttggaggagtccgggggagacctggtcaagccgggggcatccctgacactcacctgcacagccactggattctccttcaataccaactactacatgtgctgggtccgccaggctccagggaaggggctggagttgatcgcatgcagttatactactagtggtagtacttactatgcgacctgggcgaaaggccgattcaccttctccaaaacctcgtcgaccacggtgactctgcaaatgaccagtctgacagccgcggacacggccacctatttctgtgtgaaatatggtgctggttatacttataacttgtggggcccaggcaccctggtcaccgtctcctca
[0332]
58l1
[0333]
氨基酸序列(seq id no:297):
[0334]
alvmtqtpssvsaavggtvtikcqasesisnylawyqqkpgqppnlliyrastlesgvpsrfkgsgsgteftltisdlecadaatyfcqqgysntnldnifgggtevvvk
[0335]
核酸序列(seq id no:298):
[0336]
gcccttgtgatgacccagactccatcctccgtgtctgcagctgtgggaggcacagtcaccatcaagtgccaggccagtgagagcattagtaactacttagcctggtatcagcagaaaccagggcagcctcccaatctcctgatctacagggcatccactctggaatctggggtcccatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttacttctgtcagcagggttacagtaatactaatcttgataatattttcggcggagggaccgaggtggtggtcaaa
[0337]
70h1
[0338]
氨基酸序列(seq id no:299):
[0339]
qsveesggrlvtpgtpltltctvsgfslssnaiswvrqapgegleyigwidatgsayyatwakgrftisktssttvdlkmtspttedtatyfcargfrysafwgqgtlvtvss
[0340]
核酸序列(seq id no:300):
[0341]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccaggggaggggctggagtacatcggatggattgatgctactggtagcgcatactacgcgacctgggcgaaaggccgattcaccatctctaaaacctcgtcgaccacggtggatctgaagatgaccagtccgacaaccgaggacacggccacctatttctgtgccagagggtttaggtattctgcgttctggggccaaggcaccctggtcaccgtctcctca
[0342]
70l2
[0343]
氨基酸序列(seq id no:301):
[0344]
qvltqtpspvsvavggtvtincqasqsvynnnylswyqqkpgqppklliydtstlasgipsrfkgsgsgtqftltisdlecddaatyycagtystsdwsvafgggtevvv
[0345]
核酸序列(seq id no:302):
[0346]
caagtgctgacccagacaccatcgcccgtgtctgtagctgtgggaggcacagtcaccatcaattgccag
gccagtcagagtgtttataataacaactacttatcctggtatcaacagaaaccagggcagcctcccaagctcctgatctatgatacatccactctggcatctgggatcccatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagcgacctggagtgtgacgatgctgccacttattattgtgcaggcacttattctactagtgattggtctgttgctttcggcggagggaccgaggtggtggtcaaa
[0347]
78h2
[0348]
氨基酸序列(seq id no:303):
[0349]
qsveesggrlvtpgtpltltctvsgidlstyfmswvrqapgkgleyigwintndkiyyaswakgrftisttsttvdlkitspttedtatyfcgspypryasglnlwgqgtlvtvss
[0350]
核酸序列(seq id no:304):
[0351]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggaatcgacctcagtacctatttcatgagctgggtccgccaggctccagggaaggggctggaatacatcgggtggattaatactaatgataaaatatactacgcgagctgggcgaagggccgattcaccatctccacaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtggcagtccttatcctaggtatgctagtggtcttaacttgtggggccaaggcaccctggtcaccgtctcctca
[0352]
78l1
[0353]
氨基酸序列(seq id no:305):
[0354]
advvmtqtpasvsepvggtvtikcqasqsihnylawyqqkpgqppklliysasnlasgvssrfkgsgsgteytltisdlecadaatyycqctyygssyentfgggtevvvk
[0355]
核酸序列(seq id no:306):
[0356]
gccgatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtcagagcattcataattacttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctattctgcatccaatctggcatctggggtctcatcgcggttcaaaggcagtggatctgggacagaatacactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaatgtacttattatggtagtagttatgagaatactttcggcggagggaccgaggtggtggtcaaa
[0357]
86h2
[0358]
氨基酸序列(seq id no:307):
[0359]
qsleesggrlvtpggsltltctvsgidlsryhmswvrqapgkglewiatthidggvyyaiwakgrftisktsttvdlkmtsltaedtatyfcarkfdlwgqgtlvtvss
[0360]
核酸序列(seq id no:308):
[0361]
cagtcgctggaggagtccgggggtcgcctggtaacgcctggaggatccctgacactcacctgcacagtctctggaatcgacctcagtaggtaccacatgagctgggtccgccaggctccagggaaggggctggaatggatcgcaacgactcatattgatggtggcgtatactacgcgatttgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacagccgaggacacggccacctatttctgtgccagaaagtttgacttgtggggccaaggcaccctggtcaccgtctcctcag
[0362]
86l2
[0363]
氨基酸序列(seq id no:309):
[0364]
qvltqtpssvsaavggtvtiscqssesvsnnnwlswyqqksgqppklliyqasklasgvssrfkgsgsgtqftltisdlecadaatyycqggyydsgwyyafgggtevvvk
[0365]
核酸序列(seq id no:310):
[0366]
caagtgctgacccagactccatcgtccgtgtctgcagctgtgggaggcacagtcaccatcagttgccagtccagtgagagcgtttcaaataataactggttatcctggtatcagcagaaatcagggcagcctcccaagctcctgatctaccaggcatccaaactggcatctggggtctcatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggcggttattatgatagtggttggtactatgctttcggcggagggaccgaggtggtggtcaaa
[0367]
91h1
[0368]
氨基酸序列(seq id no:311):
[0369]
qsveesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigfidsegsasyaswangrftisktsntvdlkmtglttedtatyfcargfrylplwgqgtlvtvss
[0370]
核酸序列(seq id no:312):
[0371]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggagtggatcggattcattgatagtgagggtagcgcatcctacgcgagctgggcgaatggtcgattcaccatctccaaaacctcgaacacggtggatctgaaaatgaccggtctgacaaccgaggacacggccacctatttctgtgccagaggatttcggtacttgcccttgtggggccaaggcaccctggtcaccgtctcctca
[0372]
91l1
[0373]
氨基酸序列(seq id no:313):
[0374]
avltqtpspvsaavggtvtincqasqsvyynnylawyqqkpgqppklliydtsklasgvpsrfkgsgsgtqftltisgvqcddaasyfcqgtyyssgwywnafgggtevvvk
[0375]
核酸序列(seq id no:314):
[0376]
gccgtgctgacccagacaccatcccccgtgtctgcagctgtgggaggcacagtcaccatcaattgccaggccagtcagagtgtttattataacaactacttagcctggtatcagcagaaaccagggcagcctcccaaactcctgatctacgatacatccaaattggcatctggggtcccatcccggttcaaaggcagtggatctgggacacagttcactctcaccatcagcggcgtgcagtgtgacgatgctgcctcttacttctgtcaaggcacttattatagtagtggttggtactggaatgctttcggcggagggaccgaggtggtggtcaaa
[0377]
93h2
[0378]
氨基酸序列(seq id no:315):
[0379]
qeqlkesggdlvtpgtpltltctvsgfslssnaiswvrqapgkglewigviyagggafyaswakgrftfsktsttvdlkmtslttedtasyfctrgytylafwgqgtlvtvss
[0380]
核酸序列(seq id no:316):
[0381]
caggagcaactgaaggagtccgggggagacctggtcacgcctgggacacccctgacactcacctgcacagtctctgggttctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggaatggatcggagtcatttatgctggtggtggcgcattctacgcgagctgggcgaaaggccgattcaccttctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacaaccgaggacacggcctcctatttctgtaccagaggctatacttatttggccttctggggccagggcaccctggtcaccgtctcctca
[0382]
93l2
[0383]
氨基酸序列(seq id no:317):
[0384]
dvvmtqtpasvsepvggtvtircqasqsinnflswyqqkpgqppklliykastlasgvssrfkgsgsgteytltisdlecadaatyycqgsaygtsdvcafgggtevvvk
[0385]
核酸序列(seq id no:318):
[0386]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaggtgccaggccagtcagagcattaacaatttcttatcttggtatcagcagaaaccagggcagcctcccaagctcctgatctacaaggcatccactctggcatctggggtctcatcgcggttcaaaggcagtggatctgggacagagtacactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggctctgcttatggtactagtgatgtttgtgctttcggcggagggaccgaggtggtggtcaaa
[0387]
94h1
[0388]
氨基酸序列(seq id no:319):
[0389]
qsleesggdlvkpgasliltctasgfdfssnalcwvrqapgkglewiasiyaggdtyyatwakgrftvsktssttvflqmtsltaadtatyfcargamtyslwgpgtlvtvss
[0390]
核酸序列(seq id no:320):
[0391]
cagtcgttggaggagtccgggggagacctggtcaagcctggggcatccctgatactcacctgcacagcctctggattcgacttcagtagcaatgcactgtgctgggtccgccaggctccagggaaggggctggagtggatcgcatccatttatgctggtggtgacacttactacgcgacctgggcgaaaggccgattcaccgtctccaaaacctcgtcgaccacggtgtttctgcagatgaccagtctgacagccgcggacacggccacctatttctgtgcgaggggtgctatgacttatagtttgtggggcccaggcaccctggtcaccgtctcctca
[0392]
94l2
[0393]
氨基酸序列(seq id no:321):
[0394]
adivmtqtpasveaavggtvtincqasqsvhnnnylswyqqkpgqppklliyqasklasggpsrfkgsgsgteftltisdlecadaatyycqsyyysgcsgavnsfgggtevvvk核酸序列(seq id no:322):
[0395]
gctgacattgtgatgacccagactccagcctccgtggaggcagctgtgggaggcacagtcaccatcaactgccaggccagtcagagtgttcataataataactacttatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctaccaggcatccaaactggcatctgggggcccatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaagctattattatagtggttgtagtggtgccgttaattctttcggcggagggaccgaggtggtggtcaaa
[0396]
102h1
[0397]
氨基酸序列(seq id no:323):
[0398]
qsleesggrlvtpggsltltctvsgidlssnavgwvrqapgkgleyigvisvsgniyyanwargrftisktssttvdlkmtsltaadtatyfcarpwdlwgqgtlvtvss
[0399]
核酸序列(seq id no:324):
[0400]
cagtcgctggaggagtccgggggtcgcctggtaacgcctggaggatccctgacactcacctgcacagtctctggaatcgacctcagtagcaatgcagtgggctgggtccgccaggctccagggaaggggctggaatacatcggagtcattagtgttagtggtaacatatactacgcgaactgggcgagaggccgattcaccatctccaaaacctcgtcgaccacggtggatctgaaaatgaccagtctgacagccgcggacacggccacctatttctgtgccagaccctgggacttgtggggccaaggcaccctggtcaccgtctcctca
[0401]
102l1
[0402]
氨基酸序列(seq id no:325):
[0403]
dvvmtqtpasvseavggtvtikcqasesisswlawyqqkpgqppklliylastlasgvpsrfkgsgsgtqftltisdlecadaatyycqcssytsgyvaafgggtevvvk
[0404]
核酸序列(seq id no:326):
[0405]
gatgttgtgatgacccagactccagcctccgtgtctgaagctgtgggaggcacagtcaccatcaagtgccaggccagtgagagcattagcagttggttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctatctggcatctactctggcatctggggtcccatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaatgttcttcttatacgagtggttatgttgccgctttcggcggagggaccgaggtggtggtcaaa
[0406]
103h2
[0407]
氨基酸序列(seq id no:327):
[0408]
qsmeesggrlvtpgtpltltctvstfslnsfhmswvrqapgkglewigvihpndatyyaswakgrftisktsttvdlkitspttedtatyfcardlagystggsfwgqgtlvtvss
[0409]
核酸序列(seq id no:328):
[0410]
cagtcaatggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctacattctccctcaatagtttccacatgagctgggtccgccaggctccagggaaggggctggaatggatcggcgtcattcatcctaatgatgccacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagagatcttgctggttatagtactggtggtagcttctggggccaaggcaccctggtcaccgtctcctca
[0411]
103l2
[0412]
氨基酸序列(seq id no:329):
[0413]
alvltqtpspvsaavggtvtvscqasqsvynnnwlswfqqkpgqppklliyrastlasgvpsrfsgsgsgtqftltisgvqcadaatyycaaykswsnddfgfgggtevvvk
[0414]
核酸序列(seq id no:330):
[0415]
gcgcttgtgctgacccagactccatctcccgtgtctgcagctgtgggaggcacagtcaccgtcagttgccaggccagtcagagtgtttataataacaactggttatcctggtttcagcagaaaccagggcagcctcccaagctcctgatctacagggcatccactctggcatctggggtcccatcacggttcagcggcagtggatctgggacacagttcactctcaccatcagtggcgtgcagtgtgccgatgctgccacttactactgtgcagcgtataaaagttggagtaatgatgattttggtttcggcggagggaccgaggtagtagtcaaa
[0416]
105h1
[0417]
氨基酸序列(seq id no:331):
[0418]
qsleesggrlvtpgtpltitctvsgidlssvamgwvrqapgkgleyigvistsgnkyyatwakgrftisktsttvelkvtspttedtatyfcarawnlwgqgtlvtvss
[0419]
核酸序列(seq id no:332):
[0420]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacaatcacctgcacggtctctggaatcgacctcagtagcgttgcaatgggctgggtccgccaggctccagggaaggggctggaatacatcggagtcattagtactagtggtaataaatactacgcgacctgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggagctgaaggtcaccagtccgacaaccgaggacacggccacctatttctgtgccagagcctggaacttgtggggccaaggcaccctggtcaccgtctcctca
[0421]
105l4
[0422]
氨基酸序列(seq id no:333):
[0423]
dvvmtqtpasvsepvggtvtikcrasediesylawyrqkpgqppklliyrasklasgvpsrfsgsgsgt
eytltisdlecadaatyycqcttytstyvgggfgggtevvvk
[0424]
核酸序列(seq id no:334):
[0425]
gatgtagtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccgggccagtgaggacattgaaagctatttagcctggtatcggcagaaaccagggcagcctcccaagctcctgatctacagggcatccaaactggcatctggggtcccatcgcggttcagtggcagtggatctgggacagagtacactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaatgtactacttatacgagtacttatgttggtggtggtttcggcggagggaccgaggtggtggtcaaa
[0426]
108h1
[0427]
氨基酸序列(seq id no:335):
[0428]
qslegsggrlvkpdetltitctvsgfslssnamswvrqapgkglewigfidaggsayyatwvngrftisktsttvdlkmtslttedtatyfcakglswsdfwgqgtlvtvss
[0429]
核酸序列(seq id no:336):
[0430]
cagtcgctggaggggtccgggggtcgcctggtcaagcctgacgaaaccctgacaatcacctgcacagtctctggattctccctcagtagcaatgcaatgagctgggtccgccaggctccagggaaggggctggaatggatcggattcatagatgcgggtggtagcgcatactacgcgacctgggtgaatggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacaaccgaggacacggccacctatttctgtgccaaaggactaagctggtctgacttttggggccagggcaccctggtcaccgtctcctca
[0431]
108l3
[0432]
氨基酸序列(seq id no:337):
[0433]
qvltqtpssvsaavggtvtvscqssqsvvsnnrlswyqqksgqppklliylastlpsgvpsrfrgsgsgtqftltisdlgcddaatyycqgtygsssyygafgggtevvvk
[0434]
核酸序列(seq id no:338):
[0435]
caagtgctgacccagactccatcgtccgtgtctgcagctgtgggaggcacagtcaccgtcagttgccagtccagtcagagtgttgttagtaacaaccgcttatcctggtatcagcagaaatcagggcagcctcccaagctcctgatctatctggcatccactctgccatctggggtcccatcgcggttcaggggcagtggatctgggacacagttcactctcaccatcagcgacctgggctgtgacgatgctgccacttactactgtcaaggcacttatggtagtagtagttattacggagctttcggcggagggaccgaggtggtggtcaaa
[0436]
109h2
[0437]
氨基酸序列(seq id no:339):
[0438]
qsleesggrlvtpgtpltltctaseftissfhmswvrqapgkglewigvihpndityyaswakgrftisktsttvelkitspttedtatyfcvrdltggttggrlwgpgtlvtvss
[0439]
核酸序列(seq id no:340):
[0440]
cagtcgctggaggagtccgggggtcgcctagtcacgcctgggacacccctgacactcacctgcacagcctctgaatttaccattagtagcttccacatgagctgggtccgccaggctccagggaaggggctggaatggatcggagtcattcatcccaatgatatcacatattacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggagctgaagatcaccagtccgacaaccgaggacacggccacctatttctgtgtcagagatcttactggtggtactactggtggtaggttgtggggcccaggcaccctggtcaccgtctcctca
[0441]
109l1
[0442]
氨基酸序列(seq id no:341):
[0443]
alvltqtpspvsaavgdtvtvscqssksvcnndwlswfqqkpgqppklliyrastlasgvpsrfkgsgsgtqftltisgvecddaatyycagyaswnnddfgfggetevvvk
[0444]
核酸序列(seq id no:342):
[0445]
gcccttgtgctgacccagactccatcccccgtgtctgcagctgtgggagacacagtcaccgtcagttgccagtccagtaagagtgtttgtaataacgactggttatcctggtttcagcagaaaccagggcagcctcccaagctcctgatctacagggcatccactctggcatctggggtcccatctcgattcaaaggcagtggatctgggacacaattcactctcaccatcagcggcgtggaatgtgacgatgctgccacttactactgtgcaggctatgcaagttggaataatgatgattttggtttcggcggagagaccgaggtggtggtcaaa
[0446]
110h1
[0447]
氨基酸序列(seq id no:343):
[0448]
qsveesggrlvtpgtsltltctasgfslssywmgwvrqapekgleyigiistseniyyatwakgrftisktssttvdlkitspttedtatyfcarwsdlwgqgtlvtvss
[0449]
核酸序列(seq id no:344):
[0450]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacatccctgacactcacctgcacagcctccggattctccctcagtagctactggatgggctgggtccgccaggctccagagaaggggctggaatacatcggaatcattagtacgagtgagaacatatactacgcgacctgggcgaaaggccgattcaccatctccaaaacctcgtcgaccacagtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagatggagtgacttgtggggccaaggcaccctggtcaccgtctcctca
[0451]
110l1
[0452]
氨基酸序列(seq id no:345):
[0453]
qvltqtpasvsaavggtvtincqssqsvgsgnilswyqqkpgqppklliyqasklasgvssrfkgsgsgtqftliisdvqcddgasyyclgsygcssadcaafgggtevvvk
[0454]
核酸序列(seq id no:346):
[0455]
caagtgctgacccagactccagcctccgtgtctgcagctgtgggaggcacagtcaccatcaactgccagtccagtcagagtgttggtagtggcaatatcttatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctaccaggcatccaaactggcatctggggtctcatcgcggttcaaaggcagtggatctgggacacagttcactctcatcatcagcgacgtgcagtgtgacgatggtgcctcttactactgtctaggcagttatggttgtagtagtgctgattgtgctgctttcggcggagggaccgaggtggtggtcaaa
[0456]
114h2
[0457]
氨基酸序列(seq id no:347):
[0458]
qsvevsggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigiidsngstyyaswakgrftiskasttvdlkitgpttedtatyfcgrgaiypalwgqgtlvtvss
[0459]
核酸序列(seq id no:348):
[0460]
cagtcggtggaggtgtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggaatggatcggaatcattgatagtaatggtagcacatactacgcgagctgggcgaaaggccgattcaccatctccaaagcctcgaccacggtggatctgaaaatcaccggtccgacaaccgaggacacggccacctatttctgtggcagaggggcgatttatccggctttgtggggccaaggcaccctggtcaccgtctcctca
[0461]
114l1
[0462]
氨基酸序列(seq id no:349):
[0463]
afeltqtpasveaavggtvtikcqasqsisssylswyqqkpgqppklliykastlasgvpsrfkgsgsgtqftltisgvqcddaatyyclyayfggstaehtfgggtevvvk
[0464]
核酸序列(seq id no:350):
[0465]
gcattcgaattgacccagactccagcctccgtggaggcagctgtgggaggcacagttaccatcaagtgccaggccagtcagagtattagtagtagctacttatcctggtatcagcaaaaaccagggcagcctcccaagctcctgatctacaaggcttccactctggcatctggggtcccatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagtggcgtgcagtgtgacgatgctgccacttactactgtctatacgcttattttggtggtagtactgctgagcatactttcggcggagggaccgaggtggtggtcaaa
[0466]
120h1
[0467]
氨基酸序列(seq id no:351):
[0468]
qsleesggrlvtpgtpltltctvsgidlsryymswvrqapgkglewiatthidggvyyanwakgrftisktattvdlkmtsltaedtatyfcarkfdlwgqgtlvtvss
[0469]
核酸序列(seq id no:352):
[0470]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggaatcgacctcagtaggtactacatgagctgggtccgccaggctccagggaaggggctggaatggatcgcaacgactcatattgatggtggcgtatattacgcgaactgggcgaaaggccgattcaccatctccaaaaccgcgaccacggtggatctgaaaatgaccagtctgacagccgaggacacggccacctatttctgtgccagaaaatttgacttgtggggccaaggcaccctggtcaccgtctcctca
[0471]
120l1
[0472]
氨基酸序列(seq id no:353):
[0473]
qeltqtpssvsaavggtvtiscqssesvsnnnwlswyqqkpgqppklliyaasklasgvpsrftgsgsgtqftltisdlecadaatyycqggyydsgwyyafgggtevvvk
[0474]
核酸序列(seq id no:354):
[0475]
tgcagctgtgggaggcacagtcaccatcagttgccagtccagtgagagcgtttcaaataacaactggttatcctggtaccagcagaaaccagggcagcctcccaagctcctgatctatgctgcatccaagctggcaagtggggtcccatcgcggttcaccggcagtgggtctgggacacagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgccaaggcggttattatgatagtggttggtactatgctttcggcggagggaccgaggtggtggtcaaa
[0476]
121h2
[0477]
氨基酸序列(seq id no:355):
[0478]
qsaeesggrlgtpgtpltltctvsgfslssnainwvrqapgkglewigiidapgstyyaswakgrftisktsttadlkitspttedtatyfcarnyayfalwgpgtlvtvss
[0479]
核酸序列(seq id no:356):
[0480]
cagtcggcggaggagtccgggggtcgcctgggcacgcctgggacacccctgacactcacctgtacagtctctggattctccctcagtagcaatgcaataaactgggtccgccaggctccagggaaggggctggaatggatcggaatcattgatgctcctggtagcacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgaccacggcggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagaaattatgcctactttgccttatggggcccaggcaccctggtcaccgtctcctca
[0481]
121l1
[0482]
氨基酸序列(seq id no:357):
[0483]
afemtqtpssvsepvggtvtikcqasesvgsnnrlswyqqkpgqppklliyeasklpsgvpsrfrgsgsgtqftltisdiqredaatyyclgwhastddgwafgagtnvgie
[0484]
核酸序列(seq id no:358):
[0485]
gcattcgagatgacccagactccatcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtgagagtgttggtagtaacaaccgcttatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctatgaagcatccaaactgccatctggggtcccgtcgcggttcagaggcagtggatctgggacacagttcactctcaccatcagcgacattcagcgtgaggatgctgccacctactattgtctaggctggcatgctagtactgatgatggttgggcattcggagctggcaccaatgtgggaatcgaa
[0486]
129h1
[0487]
氨基酸序列(seq id no:359):
[0488]
qsvkesggglfkptdtltltctvsgfslssnaitwvrqapgkglewigiiwsggdtdyatwakgrftisktsttvdleitspttedtatyfcvkgatysalwgpgtlvtvss
[0489]
核酸序列(seq id no:360):
[0490]
cagtcagtgaaggagtccgggggaggcctcttcaagccaacggataccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataacttgggtccgccaggctccagggaaggggctggaatggatcggaatcatttggagtggtggtgacaccgactacgcgacctgggcgaaaggccgcttcaccatctccaaaacctcgaccacggtggatctggaaatcaccagtccgacaaccgaggacacggccacctatttctgtgtcaaaggggctacttatagtgccttgtggggcccaggcaccctggtcaccgtctcctca
[0491]
129l1
[0492]
氨基酸序列(seq id no:361):
[0493]
alvmtqtpssveadvggtvtikcqasqsissnyyawyqqkpgqppklliykastlasgvssrfrgsgsgteytltisdlecadaatyycqgfdygnsnvgafgggtevvvk
[0494]
核酸序列(seq id no:362):
[0495]
gcccttgtgatgacccagactccatcctccgtggaggcagatgtgggaggcacagtcaccatcaagtgccaggccagtcagagtattagtagtaactactatgcctggtatcagcagaaaccagggcagcctcccaagctcctgatctacaaggcatccactctggcatctggggtctcatcgcggttcagaggcagtggatctgggacagagtatactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggctttgattatggtaatagtaatgttggtgctttcggcggagggaccgaggtggtggtcaaa
[0496]
134h1
[0497]
氨基酸序列(seq id no:363):
[0498]
qsleesggrlvtpgtpltltctvsgidlssnamswvrqapgkglewigyiwsggntdyaswakgrftisktsttvdlkitspttedtatyfcarggsyfpfwgpgtlvtvss
[0499]
核酸序列(seq id no:364):
[0500]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggaatcgacctcagtagcaatgcaatgagctgggtccgccaggctccagggaaggggctggaatggatcggatacatttggagtggtggtaatacagactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatcaccagtccaacaaccgaggacacggccacctatttctgtgccaggggggggtcatactttccc
ttctggggcccaggcaccctggtcaccgtctcctca
[0501]
134l2
[0502]
氨基酸序列(seq id no:365):
[0503]
dpvmtqtpsstsaavggtvtincqssqsvyidrlawyqqkpgqppklliyqasklpsgvpsrfsgsgsgkqstltisgvqcddaatyycagfydsgsgtytlafgggtevvvk
[0504]
核酸序列(seq id no:366):
[0505]
gaccctgtgatgacccagactccatcttccacgtctgcggctgtgggaggcacagtcaccatcaactgccagtccagtcagagtgtttatatcgaccgcttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctaccaggcatccaaactgccatctggggtcccatcgcggttcagcggcagtggatctgggaaacagtccactctcaccatcagtggcgtgcagtgtgacgatgctgccacttactactgtgcagggttttatgatagtggtagtggcacttatacattagctttcggcggagggaccgaggtggtggtcaaa
[0506]
151h1
[0507]
氨基酸序列(seq id no:367):
[0508]
qsveesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigvidaggstyfaswakglftisktssttvdlqmtslttedtatyfcargwsrhdfwgpgtlvtvss
[0509]
核酸序列(seq id no:368):
[0510]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggaatggatcggagtcattgatgctggtgggtccacatacttcgcgagctgggcgaaaggcctattcaccatctccaaaacctcgtcgaccacggtggatctgcaaatgaccagtctgacaaccgaggacacggccacctatttctgtgccagaggttggagtagacatgacttctggggcccaggcaccctggtcaccgtctcctca
[0511]
151l1
[0512]
氨基酸序列(seq id no:369):
[0513]
dvvmtqtpasvsepvggtvtikcqasqsisnilawyqqkpgqpprlliysastlasgvssrfkasgsgteftltisdlecadaatyycqgydstvgvgafgggtevvvk
[0514]
核酸序列(seq id no:370):
[0515]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtcagagcattagcaatatattagcctggtatcagcagaaaccagggcagcctcccaggctcctgatctattctgcatccactctggcatctggggtctcatcgcggttcaaggccagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaagggtatgatagtactgttggtgtgggtgctttcggcggagggaccgaggtggtggtcaaa
[0516]
166h2
[0517]
氨基酸序列(seq id no:371):
[0518]
qsleesggrlvtpgtpltltctasgfdlsryhmnwvrqapgkglewigiiyvsddsyyaswakgrftisktstavdlkitspttedtatyfcarvgsvwssklwgpgtlvtvss
[0519]
核酸序列(seq id no:372):
[0520]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagcctctggattcgacttaagtaggtaccacatgaactgggtccgccaggctccagggaaggggctggaatggatcggaatcatttatgttagtgatgactcatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgaccgcgg
tggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagagttggtagtgtttggagcagtaagttgtggggcccaggcaccctggtcaccgtctcctca
[0521]
166l1
[0522]
氨基酸序列(seq id no:373):
[0523]
dvvmtqtpasvsepvggtvtikcqaseniynnlawyqqkpgqppklliyrastlesgvpsrfkgsgsgteftltisdlecadaatyycqstyfggsyvfafgggtevvvk
[0524]
核酸序列(seq id no:374):
[0525]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtgagaacatttacaacaatttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctacagggcatccactctggaatctggggtcccatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgcgccgatgctgccacttactactgtcaatctacttattttggtgggagttatgtttttgctttcggcggagggaccgaggtggtggtcaaa
[0526]
167h2
[0527]
氨基酸序列(seq id no:375):
[0528]
qsleesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigtiyatdstsyaswakgrftisktsttvdlkmtsltaadtatyfcalgasysalwgpgtlvtvss
[0529]
核酸序列(seq id no:376):
[0530]
cagtcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcacagtctctggattctccctcagtagcaatgcaataagttgggtccgccaggctccagggaaggggctggaatggatcggaaccatttatgctactgatagcacgtcctacgcgagctgggcaaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacagccgcggacacggccacctatttctgtgccttaggtgctagttattctgctttgtggggcccaggcaccctggtcaccgtctcctca
[0531]
167l2
[0532]
氨基酸序列(seq id no:377):
[0533]
aivmtqtpssksvavgdtvtincqasesvasndrlawyqqkpgqrpklliyqastlasgvpsrfkgsgsgteftltisnvvcddaatyycagykssstdgnafgggtevvvk
[0534]
核酸序列(seq id no:378):
[0535]
atcgtgatgacccagactccatcttccaagtctgtcgctgtgggagacacagtcaccatcaattgccaggccagtgagagtgttgctagtaacgaccgcttagcctggtatcagcagaaaccagggcagcgtcccaaactcctaatctaccaggcatccactctggcatctggggtcccatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcaatgtggtgtgtgacgatgctgccacttactactgtgcaggatataaaagtagtagtactgatggtaatgctttcggcggagggaccgaggtggtggtcaaa
[0536]
193h1
[0537]
氨基酸序列(seq id no:379):
[0538]
qsveesggglvtpggtltltctasgfslssydmswvrrapgkglewigviatggrrdyaswakgrftvsktsttvdlkmtsltaadtatyfcarysdsdgyalwgpgtlvtvss
[0539]
核酸序列(seq id no:380):
[0540]
cagtcggtggaggagtccggaggaggcctggtaacgcctggaggaaccctgacactcacctgcacagcctctggattctccctcagcagctacgacatgagctgggtccgccgggctccagggaaggggctggaatggatcggagt
cattgctactggtggtagaagggactacgcgagctgggcaaaaggctgattcaccgtctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacagccgcggacacggccacctatttctgtgccagatatagtgatagtgatggttatgccttgtggggcccaggcaccctggtcaccgtctcctca
[0541]
193l2
[0542]
氨基酸序列(seq id no:381):
[0543]
aevvmtqapasveaavggtvtikcqasesigswlawyqqkpgqppklliysastlafgvpsrfsgsgsgtqftltisdlecadaatyycqsnyystsghafgggtevvvk
[0544]
核酸序列(seq id no:382):
[0545]
gccgaagtagtgatgacccaggctccagcctccgtggaggcagctgtgggaggcacagtcaccatcaagtgccaggccagtgagagcattggcagttggttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctattctgcgtccactctggcatttggggtcccgtcgcggttcagcggcagtggatctgggacacagttcactctcaccatcagcgacctggagtgtgccgatgcggccacttactactgtcaaagtaattattatagtactagtgggcatgctttcggcggagggaccgaggtggtggtcaaa
[0546]
217h2
[0547]
氨基酸序列(seq id no:383):
[0548]
qsveesggrlvtpgtpltltckasgfslsnywmnwvrqapgkglewigtinyggstyyaswakgrftisktsttvdlkitspttedtatyfcardngaytfdswgpgtlvtvss
[0549]
核酸序列(seq id no:384):
[0550]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaaagcctctggattctccctcagtaactactggatgaactgggtccgccaggctccagggaaggggctggaatggatcggaaccattaattatggtggtagcacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagagataatggtgcttatacttttgattcctggggcccaggcaccctggtcaccgtctcctca
[0551]
217l1
[0552]
氨基酸序列(seq id no:385):
[0553]
ivmtqtpssasepvggtvtikcqasqsvynnnylswyqqkpgqspkqliyaastlasgvpsrfkgsgsgtqftltisdvqcddaasyyclgksscsyddcrafgggtevvvk
[0554]
核酸序列(seq id no:386):
[0555]
attgtgatgacccagactccatcctctgcgtctgaacctgtgggaggcacagtcaccatcaaatgccaggccagtcagagtgtttataataacaactacttatcctggtatcagcagaaaccagggcagtctcccaagcaactgatctatgctgcatccactctggcatctggggtcccatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagcgacgtgcagtgtgacgatgctgccagttactactgtctaggcaaatctagttgtagttatgatgattgtagggctttcggcggagggaccgaggtggtggtcaaa
[0556]
233h1
[0557]
氨基酸序列(seq id no:387):
[0558]
qeqlvesggglvqpegsltltctasgfsfsyyswacwvrqapgkglewiacidgggsratyyaswakgrftisttssttvtlqmtsltaadtatyfcsrsdyngyisyfdlwgpgtlvtvss
[0559]
核酸序列(seq id no:388):
[0560]
caggagcagctggtggagtccgggggaggcctggtccagcctgagggatccctgacactcacctgcaca
gcctctggattctcctttagttactattcttgggcgtgctgggtccgccaggctccagggaagggactggagtggatcgcatgcattgatggtggtggtagtcgcgccacttactacgcgagctgggcgaaaggccgattcaccatctccacaacctcgtcgaccacggtgactctgcaaatgaccagtctgacagccgcggacacggccacttatttctgttcgagatccgactataatggttatatctcctactttgacttgtggggccccggcaccctggtcaccgtctcctca
[0561]
233l1
[0562]
氨基酸序列(seq id no:389):
[0563]
afeltqtpssveaavggtvtincqasqsirsdlawyqqkpgqppklliykastlasgvpsrfrgsgsgteytltisdlecadaatyycqsyyhssstafgggtevvvk
[0564]
核酸序列(seq id no:390):
[0565]
gcattcgagttgacccagactccatcctccgtggaggcagctgtgggaggcacagtcaccatcaattgccaggccagtcagagcattcgtagcgacttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctataaggcatccactctggcatctggggtcccatcgcggttcagaggcagtggatctgggacagagtacactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaagctattatcatagtagtagtactgctttcggcggagggaccgaggtggtggtcaaa
[0566]
169ah1
[0567]
氨基酸序列(seq id no:391):
[0568]
qspeesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigyidantnayyaswakgrvtisqtsttvdlritsptsedtatyfcargvtyypmwgpgtlvtvss
[0569]
核酸序列(seq id no:392):
[0570]
cagtcgccggaggagtccgggggtcgcctggtcacgcctgggacacccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggagtggatcggatatatagatgcgaatactaacgcatactacgcgagttgggcaaaaggccgagtcaccatctcccaaacctcgaccacggtggatctgaggatcaccagtccgacaagcgaagacacggccacctatttctgtgccagaggtgttacttattatccaatgtggggcccaggcaccctggtcaccgtctcctca
[0571]
169al1
[0572]
氨基酸序列(seq id no:393):
[0573]
dvvmtqtpasvsepvggtvtikcqasqsiasrycswyqqkpgqppklliykastlasgvssrfkgsgseteftltisdlecadaatyycqggyygdsyvgafgggtevvvk
[0574]
核酸序列(seq id no:394):
[0575]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtcagagtattgctagtaggtactgctcctggtatcagcagaaaccagggcagcctcccaagctcctgatctacaaggcatccactctagcatctggggtctcatcgcggttcaaaggcagtggatctgagacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggcggttattatggtgatagttatgttggcgctttcggcggagggaccgaggtggtggtcaaa
[0576]
176ah1
[0577]
氨基酸序列(seq id no:395):
[0578]
qsveesggrlvkpdetltltctvsgfslssnaiswvrqapgkglewigaiysddntyyanwakgrftisktsttvdlkmtslttedtatyfcgrgasrfdfwgpgtlvtvss
[0579]
核酸序列(seq id no:396):
[0580]
cagtcggtggaggagtccgggggtcgcctggtcaagcctgacgaaaccctgacactcacctgcaccgtctctggattctccctcagtagcaatgcaataagttgggtccgccaggctccagggaaggggctggaatggatcggagccatttatagtgatgataacacatactacgcgaactgggcgaaaggccgattcaccatctccaaaacctcgaccacggtggatctgaaaatgaccagtctgacaaccgaggacacggccacctatttctgtggcagaggtgcttctaggtttgacttctggggcccaggcaccctggtcaccgtctcctca
[0581]
176al1
[0582]
氨基酸序列(seq id no:397):
[0583]
dvvmtqtpasvsaavggtvtikcqasqsingnylawyqqkpgqppklliykastltsgvpsrfkgsgsgtqftltisdlecadgatyycqytdygstyvgafgggtevvvk
[0584]
核酸序列(seq id no:398):
[0585]
gatgttgtgatgacccagactccagcctccgtgtctgcagctgtgggaggcacagtcaccatcaagtgccaggccagtcagagtattaatggtaactacttagcctggtatcagcagaaaccagggcagcctcccaagctcctaatctataaggcatccactctgacatctggggtcccatcgcggttcaaaggcagtggatctgggacacagttcactctcaccatcagcgacctggagtgtgccgatggtgccacttactactgtcaatatactgattatggtagtacttatgttggtgctttcggcggagggaccgaggtggtggtcaaa
[0586]
181ah1
[0587]
氨基酸序列(seq id no:399):
[0588]
qsleesggrlvtpgtpltltctvsgfslssnaiswvrqapgkglewigyidantnayyaswakgrvtisqtsttvdlritsptsedtatyfcargvtyypmwgpgtlvtvss
[0589]
核酸序列(seq id no:400):
[0590]
caatcgctggaggagtccgggggtcgcctggtcacgcctgggacacccctgacgctcacctgcaccgtctctggattctccctcagtagcaatgcaataagctgggtccgccaggctccagggaaggggctggagtggatcggatatatagatgcgaatactaacgcatactacgcgagttgggcaaaaggccgagtcaccatctcccaaacctcgaccacggtggatctgaggatcaccagtccgacaagcgaagacacggccacctatttctgtgccagaggtgttacttattatccaatgtggggcccaggcaccctggtcaccgtctcctca
[0591]
181al1
[0592]
氨基酸序列(seq id no:401):
[0593]
dvvmtqtpasvsepvggtvtikcqasqsigsrywswyqqqpgqppklliykastlasgvssrfkgsgseteftltisdlecadaatyycqggyygdsyvgafgggtevvvk
[0594]
核酸序列(seq id no:402):
[0595]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaagtgccaggccagtcagagtattggtagtaggtactggtcctggtatcagcagcaaccagggcagcctcccaagctcctgatctacaaggcatccactctggcatctggggtctcatcgcggttcaaaggcagtggatctgagacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggcggttattatggtgatagttatgttggcgctttcggcggagggaccgaggtggtggtcaaa
[0596]
183ah2
[0597]
氨基酸序列(seq id no:403):
[0598]
qsveesggrlvtpgtpltitctvsgmdlssnamtwvrqapgkglewigiiyasdstyyaswakgrftisktssttvdlkitspttedtatyfcargatyiplwgpgtlvtvss
[0599]
核酸序列(seq id no:404):
[0600]
cagtcggtggaggagtccgggggtcgcctggtcacgcctgggacacccctgacaatcacctgcacagtctctggaatggacctcagtagcaatgcaatgacctgggtccgccaggctccagggaaggggctggaatggattggaatcatttatgctagtgatagcacatactacgcgagctgggcgaaaggccgattcaccatctccaaaacctcgtcgaccacggtggatctaaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagaggtgctacttacattcccttgtggggcccaggcaccctggtcaccgtctcctca
[0601]
183al1
[0602]
氨基酸序列(seq id no:405):
[0603]
dvvmtqtpasvsepvggtvtincqasqsisssylawyqqkpgqppklliykastlasgvssrfkgsgsgteftltisdlecadaatyycqctdygssyvgtfgggtevvvk
[0604]
核酸序列(seq id no:406):
[0605]
gatgttgtgatgacccagactccagcctccgtgtctgaacctgtgggaggcacagtcaccatcaattgccaggccagtcagagtattagtagtagctacttagcctggtatcagcagaaaccagggcagcctcccaagctcctgatctacaaggcatccactctggcatctggggtctcatcgcggtttaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaatgtactgattatggtagtagttatgttggtactttcggcggagggaccgaggtggtggtcaaa
[0606]
184ah1
[0607]
氨基酸序列(seq id no:407):
[0608]
qsveesggrlvkpdetltltctvsgidlssntmswvrqapgkglewigligpvsntyyanwakgrvtisktsttvdlkitspttedtatyfcargwfqysfwgpgtlvtvss
[0609]
核酸序列(seq id no:408):
[0610]
cagtcggtggaggagtccgggggtcgcctggtcaagcctgacgaaaccctgacactcacctgcacagtgtctggaatcgacctcagtagcaatacaatgagctgggtccgccaggctccagggaaggggctggaatggatcggactgattggtcctgtcagtaacacatactacgcgaactgggcgaaaggccgggtcaccatctccaaaacctcgaccacggtggatctgaaaatcaccagtccgacaaccgaggacacggccacctatttctgtgccagaggctggttccaatatagcttctggggcccaggcaccctggtcaccgtctcctca
[0611]
184al1
[0612]
氨基酸序列(seq id no:409):
[0613]
aevlmtqtpssveapvggtvtincqasqsidsylswyqqkpgqppklliykastlasgvssrfkgsgsgteftltisdlecadaatyycqggyysssnnyitfgggtevvvk
[0614]
核酸序列(seq id no:410):
[0615]
gccgaagtactgatgacccagactccatcctccgtggaggcacctgtgggaggcacagtcaccatcaactgccaggccagtcagagcattgatagctacttatcctggtatcagcagaaaccagggcagcctcccaagctcctgatctacaaggcatccactctggcatctggggtctcatcgcggttcaaaggcagtggatctgggacagagttcactctcaccatcagcgacctggagtgtgccgatgctgccacttactactgtcaaggcggttattatagtagtagtaataattatattactttcggcggagggaccgaggtggtggtcaaa
[0616]
5h2
‑
z
[0617]
氨基酸序列(seq id no:411):
[0618]
evqlvesggglvqpggslrlscaasgfslssnaiswvrqapgkglewvgiiyasgdtyyaswakgrft
isrdnskntlylqmnslraedtavyycargyttlyfwgqgtlvtvss核酸序列(seq id no:412):
[0619]
gaggtgcagctggtggagtccggaggaggactggtgcagccaggaggcagcctgaggctgtcctgtgcagcctccggcttctctctgagctccaacgccatctcttgggtgaggcaggcacctggcaagggactggagtgggtgggcatcatctacgcctccggcgacacctactatgcctcttgggccaagggccggttcaccatctctagagataacagcaagaatacactgtatctgcagatgaattccctgagggccgaggacacagccgtgtactattgcgcccgcggctacaccacactgtatttttggggccagggcaccctggtgacagtgtctagc
[0620]
5l2
‑
z
[0621]
氨基酸序列(seq id no:413):
[0622]
diqmtqspssvsasvgdrvtitcqasesistrlawyqqkpgkapklliysastlpsgvpsrfsgsgsgtdftltisslqpedfatyycqggyssgagtafgggtkveik
[0623]
核酸序列(seq id no:414):
[0624]
gacatccagatgacacagagcccaagctccgtgagcgcctccgtgggcgatagggtgaccatcacatgtcaggcctctgagagcatctccaccaggctggcatggtaccagcagaagccaggcaaggcccctaagctgctgatctattctgccagcaccctgccatccggagtgccatctaggttctccggctctggcagcggcacagactttaccctgacaatctctagcctgcagcccgaggatttcgccacctactattgccagggaggatactcctctggagcaggaaccgcctttggcggaggcacaaaggtggagatcaag
[0625]
6h2
‑
z
[0626]
氨基酸序列(seq id no:415):
[0627]
evqlvesggglvqpggslrlscaasgfdfsryhmswvrqapgkglewvgiiyvsdntyyatwakgrftisrdnskntlylqmnslraedtavyycvrvgsfwssklwgqgtlvtvss
[0628]
核酸序列(seq id no:416):
[0629]
gaggtgcagctggtggagagcggaggaggactggtgcagccaggaggctccctgcggctgtcttgcgccgccagcggcttcgatttttccaggtaccacatgtcctgggtgcgccaggcacctggcaagggactggagtgggtgggcatcatctacgtgagcgacaacacctactatgccacatgggccaagggccggttcaccatctccagagataactctaagaatacactgtacctgcagatgaatagcctgagggcagaggacaccgccgtgtactattgcgtgcgggtgggctccttttggagctccaagctgtggggacagggcaccctggtgacagtgtctagc
[0630]
6l2
‑
z
[0631]
氨基酸序列(seq id no:417):
[0632]
diqmtqspstlsasvgdrvtitcqaseniysslawyqqkpgkapklliyeasnlesgvpsrfsgsgsgteftltisslqpddfatyycqstyfgnsyvfafgggtkveik
[0633]
核酸序列(seq id no:418):
[0634]
gacatccagatgacccagtccccatctacactgagcgcctccgtgggcgatagggtgaccatcacatgtcaggccagcgagaacatctacagctccctggcctggtatcagcagaagcccggcaaggcccctaagctgctgatctacgaggcctctaatctggagagcggagtgccatcccggttctctggaagcggatccggaaccgagtttaccctgacaatctctagcctgcagcccgacgatttcgccacctactattgccagtctacatactttggcaacagctacgtgttcgcctttggcggcggcacaaaggtggagatcaag
[0635]
已知cdr负责抗原结合,然而,已发现并非所有6个cdr都是必不可少的或不可改变的。换句话说,有可能置换或改变或修饰抗cd40抗体克隆1、3、5、6、12、16、17、24、26、27、31、45、58、70、78、86、91、93、94、102、103、105、108、109、110、114、120、121、129、134、151、166、
167、193、217、233、169a、176a、181a、183、184、5
‑
z或6
‑
z中的一个或多个cdr,但实质上仍保持与cd40的特异性结合亲和力。
[0636]
在某些实施方式中,本文提供的抗cd40抗体和抗原结合片段包含一个以下抗cd40抗体克隆的重链cdr3序列:抗cd40抗体克隆1、3、5、6、12、16、17、24、26、27、31、45、58、70、78、86、91、93、94、102、103、105、108、109、110、114、120、121、129、134、151、166、167、193、217、233、169a、176a、181a、183、184、5
‑
z或6
‑
z。在某些实施方式中,本文提供的抗cd40抗体和抗原结合片段包含选自下组的重链cdr3序列:seq id no:5、11、17、23、29、35、41、47、53、59、65、71、77、83、89、95、101、107、113、119、125、131、137、143、149、155、161、167、173、179、185、191、197、203、209、215、221、227、233、239和245。重链cdr3区位于抗原结合位点的中心,并且因此被认为与抗原接触最多,并为抗体与抗原的亲和力提供最多的自由能。另外,根据多种多样化机制,认为就长度、氨基酸组成和构象来说,重链cdr3是迄今为止抗原结合位点最多样化的cdr(tonegawa s.《自然》302:575
‑
81)。重链cdr3的多样性足以产生大多数抗体特异性(xu jl,davis mm.《免疫(immunity.)》13:37
‑
45)以及所需的抗原结合亲和力(schier r等,《分子生物学杂志》263:551
‑
67)。
[0637]
在某些实施方式中,本文提供的抗体和其抗原结合片段包含合适的框架区(fr)序列,只要抗体和其抗原结合片段可以与cd40特异性地结合即可。表1中所提供的cdr序列获自兔抗体,但其可使用所属领域中已知的适合方法(如重组技术)移植到任何适合物种(尤其如小鼠、人类、大鼠、兔)的任何适合fr序列。
[0638]
在某些实施方式中,本文提供的抗体和其抗原结合片段是人源化的。人源化抗体或抗原结合片段在其降低人类的免疫原性方面是合乎需要的。人源化抗体在其可变区中是嵌合的,因为非人cdr序列被移植到人或基本上人的fr序列。抗体或抗原结合片段的人源化基本上可以通过将非人(如鼠类)cdr基因替换人免疫球蛋白基因中相应的人cdr基因来进行(参见例如jones等人(1986)《自然》321:522
‑
525;riechmann等人(1988)《自然》332:323
‑
327;verhoeyen等人(1988)《科学(science)》239:1534
‑
1536)。
[0639]
可使用所属领域中已知的方法选择适合的人重链和轻链可变结构域以实现此目的。在一说明性实例中,可以使用“最适(best
‑
fit)”方法,其中针对已知的人可变结构域序列的数据库筛选或blast非人(例如啮齿动物)抗体可变结构域序列,并且识别最接近非人查询序列的人序列,并将其用作移植非人cdr序列的人构架(参见例如sims等人,(1993)《免疫学杂志》151:2296;chothia等人(1987)《分子生物学杂志》196:901)。或者,来源于所有人抗体的共有序列的框架可用于非人cdr的移植(参见例如carter等人(1992)《美国国家科学院院刊》,89:4285;presta等人(1993)《免疫学杂志》,151:2623)。
[0640]
在某些实施方式中,本文提供的人源化抗体或抗原结合片段除cdr序列为非人序列外,实质上全部由人序列构成。在一些实施方式中,可变区fr和恒定区(如果存在)则完全或实质上来自人免疫球蛋白序列。人fr序列和人恒定区序列可以来源于不同的人免疫球蛋白基因,例如fr序列来源于一种人抗体,且恒定区来源于另一人抗体。在一些实施方式中,人源化抗体或抗原结合片段包含人fr1
‑
4。
[0641]
在某些实施方式中,本文提供的人源化抗体和其抗原结合片段包含抗体克隆5
‑
z或6
‑
z的一个或多个fr序列。
[0642]
两种示范性人源化抗cd40抗体克隆5
‑
z和6
‑
z均保持对表达cd40的细胞的特异性
结合亲和力,并且在所述方面至少与亲本兔抗体相当或甚至更好。两种示范性人源化抗体都保持其与表达cd40细胞的功能性相互作用,其在于这两种抗体都可以诱导人b细胞活化并且诱导人树突状细胞成熟和活化。
[0643]
在一些实施方式中,来源于人类的fr区可以包含与其来源于的人免疫球蛋白相同的氨基酸序列。在一些实施方式中,人fr的一个或多个氨基酸残基经来自亲本非人抗体的相应残基取代。在某些实施方式中,可能需要使人源化抗体或其片段紧密近似非人亲本抗体结构。在某些实施方式中,本文提供的人源化抗体或抗原结合片段在每个人fr序列中包含不超过10、9、8、7、6、5、4、3、2或1个氨基酸残基取代,或者在重链或轻链可变结构域的所有fr中包含不超过10、9、8、7、6、5、4、3、2或1个氨基酸残基取代。在一些实施方式中,氨基酸残基的所述变化可以仅存在于重链fr区,仅存在于轻链fr区,或存在于两条链中。
[0644]
在某些实施方式中,本文提供的抗体和其抗原结合片段包含选自下组的重链可变结构域序列:seq id no:247、251、255、259、263、267、271、275、279、283、287、291、295、299、303、307、311、315、319、323、327、331、335、339、343、347、351、355、359、363、367、371、375、379、383、387、391、395、399、403、407、411和415。在某些实施方式中,本文提供的抗体和其抗原结合片段包含选自下组的轻链可变结构域序列:seq id no:249、253、257、261、265、269、273、277、281、285、289、293、297、301、305、309、313、317、321、325、329、333、337、341、345、349、353、357、361、365、369、373、377、381、385、389、393、397、401、405、409、413和417。
[0645]
在一些实施方式中,本文提供的抗cd40抗体和抗原结合片段包含全部或一部分重链可变结构域和/或全部或一部分轻链可变结构域。在一个实施方式中,本文提供的抗cd40抗体和抗原结合片段为由全部或一部分本文提供的重链可变结构域组成的单结构域抗体。所述单结构域抗体的更多信息可在所属领域中获得(参见例如美国专利第6,248,516号)。
[0646]
在某些实施方式中,本文提供的抗cd40抗体和其片段进一步包含免疫球蛋白恒定区。在一些实施方式中,免疫球蛋白恒定区包含重链和/或轻链恒定区。重链恒定区包含ch1、铰链和/或ch2
‑
ch3区。在某些实施方式中,重链恒定区包含fc区。在某些实施方式中,轻链恒定区包含cκ或cλ。
[0647]
本文所提供的抗体或其抗原结合片段可以是单克隆抗体、多克隆抗体、人源化抗体、嵌合抗体、重组抗体、双特异性抗体、标记抗体、二价抗体或抗个体基因型抗体。重组抗体为使用重组方法在体外而非在动物中制备的抗体。
[0648]
iv.抗体变异体
[0649]
本文所提供的抗体和其抗原结合片段还涵盖其各种变异体。在某些实施方式中,抗体和其抗原结合片段涵盖本文所提供的示范性抗体的各种类型的变异体,即,抗体克隆1、3、5、6、12、16、17、24、26、27、31、45、58、70、78、86、91、93、94、102、103、105、108、109、110、114、120、121、129、134、151、166、167、193、217、233、169a、176a、181a、183、184、5
‑
z和6
‑
z。
[0650]
在某些实施方式中,抗体变异体在如在表1中所提供的一个或多个cdr序列、本文所提供的一个或多个可变区序列(但不在任一cdr序列中)和/或恒定区(例如fc区)中包含一个或多个修饰或取代。所述变异体保持其亲本抗体的与cd40的特异性结合亲和力,但具有由一个或多个修饰或一个或多个取代赋予的一种或多种所需特性。举例来说,抗体变异体可以具有提高的抗原结合亲和力、改进的糖基化模式、减少的糖基化风险、减少的脱氨基、减少或耗乏的一种或多种效应功能、改进的fcrn受体结合、增加的药物动力学半衰期、
ph敏感性和/或对缀合(例如一个或多个引入的半胱氨酸残基)的相容性。
[0651]
可使用所属领域中已知的方法,例如“丙氨酸扫描诱变”(参见例如cunningham和wells(1989)《科学》,244:1081
‑
1085)来筛选亲本抗体序列以识别适合的或优选的残基以进行修饰或取代。简而言之,可以识别目标残基(例如带电荷的残基,如arg、asp、his、lys和glu),且用中性或带负电荷的氨基酸(例如丙氨酸或多丙氨酸)置换,且产生经修饰的抗体并针对感兴趣的特性进行筛选。如果在特定氨基酸位置的取代显示出感兴趣的功能变化,则所述位置可以被识别为进行修饰或取代的潜在残基。潜在残基可通过用不同类型的残基(例如半胱氨酸残基、带正电残基等)取代来进一步评估。
[0652]
亲和力变异体
[0653]
亲和力变异体可以在表1中所提供的一个或多个cdr序列、一个或多个fr序列或如本文所提供的重链或轻链可变区序列中含有修饰或取代。fr序列可由所属领域的技术人员基于表1中的cdr序列和本文的可变区序列容易地被识别,因为在所属领域中众所周知cdr区在可变区中由两个fr区侧接。亲和力变异体保持亲本抗体的与cd40的特异性结合亲和力,或甚至具有优于亲本抗体的提高的cd40特异性结合亲和力。在某些实施方式中,cdr序列、fr序列或可变区序列中的至少一个(或所有)取代包含保守取代。
[0654]
所属领域的技术人员将理解,在表1中所提供的cdr序列和本文所提供的可变区序列中,一个或多个氨基酸残基可以被取代,但所得抗体或抗原结合片段仍保持与cd40的结合亲和力,或甚至具有提高的结合亲和力。所属领域中已知的各种方法可用于实现此目的。举例来说,可以产生抗体变异体(如fab或scfv变异体)库并且用噬菌体呈现技术表达,且随后针对对人cd40的结合亲和力进行筛选。再例如,可以使用计算机软件虚拟模拟抗体与人cd40的结合,并识别抗体上形成结合界面的氨基酸残基。所述残基可避免进行取代以便防止结合亲和力的降低,或作为取代的目标以实现较强结合。
[0655]
在某些实施方式中,本文所提供的人源化抗体或抗原结合片段包含一个或多个cdr序列和/或一个或多个fr序列中的一个或多个氨基酸残基取代。在某些实施方式中,亲和力变异体总共在cdr序列和/或fr序列中包含不超过10、9、8、7、6、5、4、3、2或1个取代。
[0656]
在某些实施方式中,抗cd40抗体和其抗原结合片段包含与表1中列出的一个或多个序列具有至少80%(例如至少85%、88%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%)序列同一性的1、2或3个cdr序列,并且同时在类似于或甚至高于其亲本抗体的水平下保持与cd40的结合亲和力。
[0657]
在某些实施方式中,抗cd40抗体和其抗原结合片段包含与本文所提供的一个或多个序列具有至少80%(例如至少85%、88%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%)序列同一性的一个或多个可变区序列,并且同时在类似于或甚至高于其亲本抗体的水平下保持与cd40的结合亲和力。在一些实施方式中,在以下的可变区序列中总共1到10个氨基酸被取代、插入或删除:seq id no:247、249、251、253、255、257、259、261、263、265、267、269、271、273、275、277、279、281、283、285、287、289、291、293、295、297、299、301、303、305、307、309、311、313、315、317、319、321、323、325、327、329、331、333、335、339、341、343、345、347、349、351、353、355、357、359、361、363、365、367、369、371、373、375、377、379、381、383、385、387、389、391、393、395、397、399、401、403、405、407、409、411、413、415和417。在一些实施方式中,取代、插入或缺失发生于cdr外部的区域中(例如fr中)。
[0658]
糖基化变异体
[0659]
本文所提供的抗cd40抗体和抗原结合片段还涵盖糖基化变异体,可以获得其以增加或降低抗体或抗原结合片段的糖基化程度。
[0660]
抗体或其抗原结合片段可包含具有侧链的一个或多个氨基酸残基,所述侧链可连接碳水化合物部分(例如寡糖结构)。抗体的糖基化通常是n
‑
连接型或o
‑
连接型。n
‑
连接型是指碳水化合物部分与天冬酰胺残基(例如三肽序列,如天冬酰胺
‑
x
‑
丝氨酸和天冬酰胺
‑
x
‑
苏氨酸中的天冬酰胺残基,其中x是除脯氨酸外的任何氨基酸)的侧链的连接。o
‑
连接型糖基化是指糖n
‑
乙酰基半乳糖胺、半乳糖或木糖中的一种与羟基氨基酸的连接,最常见地与丝氨酸或苏氨酸的连接。天然糖基化位点的去除可方便地实现,例如通过改变氨基酸序列以使得上文所描述的三肽序列中的一个(对于n
‑
连接型糖基化位点)或序列中存在的丝氨酸或苏氨酸残基(对于o
‑
连接型糖基化位点)被取代来实现。可以类似方式,通过引入所述三肽序列或者丝氨酸或苏氨酸残基来产生新的糖基化位点。
[0661]
半胱氨酸工程改造的变异体
[0662]
本文所提供的抗cd40抗体和抗原结合片段还涵盖半胱氨酸工程改造的变异体,其包含一个或多个引入的游离半胱氨酸氨基酸残基。
[0663]
游离半胱氨酸残基为不是二硫桥键的一部分的半胱氨酸残基。半胱氨酸工程改造的变异体可用于在工程改造的半胱氨酸位点处,通过例如顺丁烯二酰亚胺或卤代乙酰基,与尤其例如细胞毒性和/或成像化合物、标记或放射性同位素缀合。用于工程改造抗体或抗原结合片段以引入游离半胱氨酸残基的方法是所属领域中已知的,例如参见wo2006/034488。
[0664]
fc变异体
[0665]
本文所提供的抗cd40抗体和抗原结合片段还涵盖fc变异体,其在其fc区和/或铰链区处包含一个或多个氨基酸残基修饰或取代。
[0666]
在某些实施方式中,抗cd40抗体或抗原结合片段包含一个或多个改进与新生fc受体(fcrn)的ph依赖性结合的氨基酸取代。所述变异体可具有延长的药物动力学半衰期,因为其在酸性ph下与fcrn结合,这使其避免在溶酶体中降解且随后转位并从细胞释放出来。对抗体和其抗原结合片段进行工程改造以提高与fcrn的结合亲和力的方法是所属领域中众所周知的,参见例如vaughn,d.等人,《结构(structure)》,6(1):63
‑
73,1998;kontermann,r.等人,《抗体工程(antibody engineering)》,第1卷,第27章:提高pk的fc区工程改造(engineering of the fc region for improved pk),springer出版,2010;yeung,y.等人,《癌症研究(cancer research)》,70:3269
‑
3277(2010);和hinton,p.等人,《免疫学杂志》,176:346
‑
356(2006)。
[0667]
在某些实施方式中,抗cd40抗体或抗原结合片段包含改变抗体依赖性细胞毒性(adcc)的一个或多个氨基酸取代。在fc区的ch2结构域处的某些氨基酸残基可经取代以提供增强的adcc活性。替代或另外地,可改变抗体上的碳水化合物结构以增强adcc活性。所属领域中已描述通过抗体工程改造改变adcc活性的方法,参见例如shields rl等人,《生物化学杂志(j biol chem.)》2001.276(9):6591
‑
604;idusogie ee等人,《免疫学杂志(j immunol.)》2000.164(8):4178
‑
84;steurer w等人,《免疫学杂志》1995,155(3):1165
‑
74;idusogie ee等人,《免疫学杂志》2001,166(4):2571
‑
5;lazar ga等人,《pnas》,2006,103
(11):4005
‑
4010;ryan mc等人,《分子癌症治疗学(mol.cancer ther.)》,2007,6:3009
‑
3018;richards jo等人,《分子癌症治疗学》2008,7(8):2517
‑
27;shields r.l等人,《生物化学杂志(j.biol.chem)》,2002,277:26733
‑
26740;shinkawa t等人,《生物化学杂志》,2003,278:3466
‑
3473。
[0668]
在某些实施方式中,抗cd40抗体或抗原结合片段包含一个或多个氨基酸取代,其例如通过提高或消减c1q结合和/或cdc来改变补体依赖性细胞毒性(cdc)(参见例如wo99/51642;duncan和winter《自然》322:738
‑
40(1988);美国专利号5,648,260;美国专利号5,624,821);和关于fe区变异体的其它实例的wo94/29351。
[0669]
在某些实施方式中,抗cd40抗体或抗原结合片段在fc区的界面中包含一个或多个氨基酸取代以有助于和/或促进杂二聚化。这些修饰包含将突起(protuberance)引入到第一fc多肽中和将空腔(cavity)引入到第二fc多肽中,其中突起可以定位在空腔中以便促进第一fc多肽和第二fc多肽的相互作用以形成杂二聚体或复合物。产生具有这些修饰的抗体的方法为所属领域中已知的,例如如美国专利号5,731,168中所描述。
[0670]
v.抗原结合片段
[0671]
本文还提供抗cd40抗原结合片段。各种类型的抗原结合片段为所属领域中已知的并且可以基于本文所提供的抗cd40抗体(包括例如cdr展示于表1中且可变序列展示于本文中的示范性抗体)和其不同变异体(如亲和力变异体、糖基化变异体、fc变异体、半胱氨酸工程改造的变异体等)产生。
[0672]
在某些实施方式中,本文所提供的抗cd40抗原结合片段是骆驼单结构域抗体、双功能抗体、单链fv片段(scfv)、scfv二聚体、bsfv、dsfv、(dsfv)2、dsfv
‑
dsfv'、fv片段、fab、fab'、f(ab')2、双特异性抗体、ds双功能抗体、纳米抗体、结构域抗体、单结构域抗体或二价结构域抗体。
[0673]
各种技术可用于产生所述抗原结合片段。说明性方法包括酶消化完整抗体(参见例如morimoto等人,《生物化学与生物物理学方法杂志(journal of biochemical and biophysical methods)》24:107
‑
117(1992);和brennan等人,《科学》,229:81(1985))、由宿主细胞如大肠杆菌重组表达(例如对于fab、fv和scfv抗体片段)、如上文所论述从噬菌体呈现库筛选(例如对于scfv),和两个fab'
‑
sh片段化学偶合形成f(ab')2片段(carter等人,《生物技术(bio/technology)》10:163
‑
167(1992))。用于产生抗体片段的其它技术对于熟练技术人员将是显而易见的。
[0674]
在某些实施方式中,抗原结合片段是scfv。scfv的产生描述于例如wo 93/16185;美国专利号5,571,894和5,587,458中。scfv可以在氨基或羧基端与效应蛋白融合以提供融合蛋白(参见例如《抗体工程(antibody engineering)》,borrebaeck编)。
[0675]
vi.缀合物
[0676]
在一些实施方式中,抗cd40抗体和其抗原结合片段进一步包含缀合部分。缀合部分可以与抗体和其抗原结合片段连接。缀合部分是可与抗体或其抗原结合片段连接的非蛋白质部分。经考虑,多种缀合部分可与本文提供的抗体或抗原结合片段连接(参见例如《“结合物疫苗”,对微生物学与免疫学的贡献(“conjugate vaccines”,contributions to microbiology and immunology)》,j.m.cruse和r.e.lewis,jr.(编),carger出版社,纽约,(1989))。这些缀合部分可通过共价结合、亲和力结合、嵌入、配位结合、复合、缔合、掺合或
添加和其它方法与抗体或抗原结合片段连接。
[0677]
在某些实施方式中,本文所公开的抗体和抗原结合片段可以经工程改造以含有可以用于与一个或多个缀合部分结合的表位缀合部分外的特定位点。举例来说,所述位点可包括一个或多个反应性氨基酸残基,如半胱氨酸或组氨酸残基,以促进与缀合部分的共价键结。
[0678]
在某些实施方式中,抗体可以间接或通过另一缀合部分与缀合部分连接。举例来说,抗体或抗原结合片段可以与生物素缀合,随后间接缀合于与亲和素缀合的第二缀合物。缀合物可以是清除调节剂、毒素(例如化学治疗剂)、可检测标记(例如放射性同位素、镧系元素、发光标记、荧光标记、或酶
‑
底物标记)或纯化部分。
[0679]“毒素”可为对细胞有害或可破坏或杀死细胞的任何试剂。毒素的实例包括但不限于紫杉醇(taxol)、细胞松弛素b(cytochalasin b)、短杆菌肽d(gramicidin d)、溴化乙锭、吐根素(emetine)、丝裂霉素(mitomycin)、依托泊苷(etoposide)、特诺波赛(tenoposide)、长春新碱(vincristine)、mmae、mmaf、dm1、长春碱(vinblastine)、秋水仙碱(colchicin)、多柔比星(doxorubicin)、道诺比星(daunorubicin)、二羟基炭疽菌素二酮(dihydroxy anthracin dione)、米托蒽醌(mitoxantrone)、光神霉素(mithramycin)、放射菌素d(actinomycin d)、1
‑
去氢睪固酮、糖皮质激素、普鲁卡因(procaine)、丁卡因(tetracaine)、利多卡因(lidocaine)、普萘洛尔(propranolol)、嘌呤霉素(puromycin)和其类似物、抗代谢物(例如甲氨喋呤、6
‑
巯基嘌呤、6
‑
硫鸟嘌呤、阿糖胞苷、5
‑
氟尿嘧啶达卡巴嗪(5
‑
fluorouracil decarbazine))、烷基化剂(例如氮芥(mechlorethamine)、噻替派苯丁酸氮芥(thioepa chlorambucil)、美法仑(melphalan)、卡莫司汀(carmustine)(bsnu)和洛莫司汀(lomustine)(ccnu)、环硫磷酰胺、白消安(busulfan)、二溴甘露醇、链佐霉素(streptozotocin)、丝裂霉素c(mitomycin c)和顺
‑
二氯二胺铂(ii)(ddp)、顺铂)、蒽环霉素(anthracyclines)(例如道诺比星(以前的柔红霉素(daunomycin))和多柔比星)、抗生素(例如更生霉素(dactinomycin)(以前的放射菌素(actinomycin))、博来霉素(bleomycin)、光神霉素(mithramycin)和安曲霉素(anthramycin)(amc))、抗有丝分裂剂(例如长春新碱和长春碱)、拓扑异构酶抑制剂和微管蛋白结合剂。
[0680]
可检测标记的实例可包括荧光标记(例如荧光素、罗丹明(rhodamine)、丹磺酰基、藻红蛋白或德克萨斯红(texas red))、酶
‑
底物标记(例如辣根过氧化酶、碱性磷酸酶、荧光素酶、葡糖淀粉酶、溶菌酶、糖氧化酶或β
‑
d
‑
半乳糖苷酶)、放射性同位素(例如
123
i、
124
i、
125
i、
131
i、
35
s、3h、
111
in、
112
in、
14
c、
64
cu、
67
cu、
86
y、
88
y、
90
y、
177
lu、
211
at、
186
re、
188
re、
153
sm、
212
bi和
32
p、其它镧系元素)、发光标记、发色部分、地高辛(digoxigenin)、生物素/亲和素、用于检测的dna分子或金。
[0681]
在某些实施方式中,缀合部分可以是有助于增加抗体半衰期的清除调节剂。说明性实例包括水溶性聚合物,如peg、羧甲基纤维素、葡聚糖、聚乙烯醇、聚乙烯吡咯烷酮、乙二醇/丙二醇的共聚物等。聚合物可以具有任何分子量,并且可以是分支或非分支的。与抗体连接的聚合物的数目可以变化,并且如果连接超过一个聚合物,那么它们可以是相同或不同的分子。
[0682]
在某些实施方式中,缀合部分可以是纯化部分,如磁珠。
[0683]
在某些实施方式中,本文提供的抗体和其抗原结合片段用于缀合物的基底。
[0684]
vii.多核苷酸和重组方法
[0685]
本公开提供编码抗cd40抗体和其抗原结合片段的分离的多核苷酸。在某些实施方式中,分离的多核苷酸包含一个或多个如seq id no:82、84、86、88、90、92、94、96、98、100、102、104、106、108、110、112、114、116、118和/或120中所示的核苷酸序列,其编码本文提供的示范性抗体的可变区。编码单克隆抗体的dna使用常规程序(例如,通过使用能够特异性地与编码抗体的重链和轻链的基因结合的寡核苷酸探针)容易地分离和测序。编码dna还可以通过合成方法获得。
[0686]
编码抗cd40抗体和其抗原结合片段的分离的多核苷酸(例如包括seq id no:248、250、252、254、256、258、260、262、264、266、268、270、272、274、276、278、280、282、284、286、288、290、292、294、296、298、300、302、304、306、308、310、312、314、316、318、320、322、324、326、328、330、332、334、336、338、340、342、344、346、348、350、352、354、356、358、360、362、364、366、368、370、372、374、376、378、380、382、384、386、388、390、392、394、396、398、400、402、404、406、408、410、412、414、416和418)可以使用所属领域中已知的重组技术插入到载体中以进行进一步克隆(扩增dna)或进行表达。许多载体可供使用。载体组件通常包括但不限于以下中的一个或多个:信号序列、复制起点、一个或多个标记基因、增强子元件、启动子(例如sv40、cmv、ef
‑
1α)和转录终止序列。
[0687]
本公开提供了含有本文提供的编码抗体或抗原结合片段的核酸序列、至少一个与所述核酸序列可操作地连接的启动子(例如sv40、cmv、ef
‑
1α)和至少一个选择标记物的载体(例如表达载体)。载体的实例包括但不限于逆转录病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(例如单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒、乳多空病毒(例如sv40)、λ噬菌体和m13噬菌体、质粒pcdna3.3、pmd18
‑
t、poptivec、pcmv、pegfp、pires、pqd
‑
hyg
‑
gseu、palter、pbad、pcdna、pcal、pl、pet、pgemex、pgex、pci、pegft、psv2、pfuse、pvitro、pvivo、pmal、pmono、pselect、puno、pduo、psg5l、pbabe、pwpxl、pbi、p15tv
‑
l、ppro18、ptd、prs10、plexa、pact2.2、pcmv
‑
script.rtm.、pcdm8、pcdna1.1/amp、pcdna3.1、prc/rsv、pcr 2.1、pef
‑
1、pfb、psg5、pxt1、pcdef3、psvsport、pef
‑
bos等。
[0688]
包含编码抗体或抗原结合片段的多核苷酸序列的载体可被引入宿主细胞中进行克隆或基因表达。用于克隆或表达本文载体中的dna的适合宿主细胞是如上所述的原核生物、酵母或更高等真核生物细胞。用于此目的的适合的原核生物包括真细菌,如革兰氏阴性(gram
‑
negative)或革兰氏阳性生物体,例如肠内菌科(enterobacteriaceae),如埃希氏菌属(escherichia),例如大肠杆菌;肠杆菌属(enterobacter);欧文氏菌属(erwinia);克雷伯氏菌属(klebsiella);变形杆菌属(proteus);沙门氏菌属(salmonella),例如鼠伤寒沙门氏菌(salmonella typhimurium);沙雷氏菌属(serratia),例如粘质沙雷氏菌(serratia marcescans);和志贺杆菌属(shigella),以及芽孢杆菌属(bacilli),如枯草芽孢杆菌(b.subtilis)和地衣芽孢杆菌(b.licheniformis);假单胞菌属(pseudomonas),如绿脓杆菌(p.aeruginosa);和链霉菌属(streptomyces)。
[0689]
除原核生物以外,真核微生物(如丝状真菌或酵母)为抗cd40抗体编码载体的适合克隆或表达宿主。酿酒酵母(saccharomyces cerevisiae)或常见的烘焙酵母是低级真核宿主微生物体中最常用的。然而,多种其它属、种和菌株是通常可获得的且本文有用的,如粟酒裂殖酵母(schizosaccharomyces pombe);克鲁维酵母属(kluyveromyces)宿主,例如乳
酸克鲁维酵母(k.lactis)、脆壁克鲁维酵母(k.fragilis)(atcc 12,424)、保加利亚克鲁维酵母(k.bulgaricus)(atcc 16,045)、威克克鲁维酵母(k.wickeramii)(atcc 24,178)、克鲁维雄酵母(k.waltii)(atcc 56,500)、果蝇克鲁维酵母(k.drosophilarum)(atcc36,906)、耐热克鲁维酵母(k.thermotolerans)和马克斯克鲁维酵母(k.marxianus);耶氏酵母属(yarrowia)(ep 402,226);毕赤酵母(pichia pastoris)(ep 183,070);假丝酵母属(candida);瑞氏木霉(trichoderma reesia)(ep 244,234);粗糙脉孢菌(neurospora crassa);许旺酵母属(schwanniomyces),如西方许旺酵母(schwanniomyces occidentalis);和丝状真菌,例如脉孢菌属(neurospora)、青霉菌属(penicillium)、弯颈霉属(tolypocladium)和曲霉属(aspergillus)宿主,如构巢曲霉(a.nidulans)和黑曲霉(a.niger)。
[0690]
适合表达本文提供的糖基化抗体或抗原片段的宿主细胞来源于多细胞生物体。无脊椎动物细胞的实例包括植物和昆虫细胞。已经识别出多种杆状病毒株和变异体和相应的来自如下宿主的容许昆虫宿主细胞:草地贪夜蛾(spodoptera frugiperda)(毛虫)、埃及伊蚊(aedes aegypti)(蚊子)、白纹伊蚊(aedes albopictus)(蚊子)、黑腹果蝇(drosophila melanogaster)(果蝇)和家蚕(bombyx mori)。多种用于转染的病毒株是可公开获得的,例如苜蓿银纹夜蛾(autographa californica)npv的l
‑
1变异体和家蚕npv的bm
‑
5病毒株,并且所述病毒可以根据本发明用作本文中的病毒,尤其是用于转染草地贪夜蛾细胞。棉、玉米、马铃薯、大豆、矮牵牛、番茄和烟草的植物细胞培养物也可以用作宿主。
[0691]
然而,对脊椎动物细胞的兴趣最大,脊椎动物细胞在培养物(组织培养物)中的繁殖已成为常规程序。有用的哺乳动物宿主细胞系的实例是由sv40转化的猴肾cv1系(cos
‑
7,atcc crl 1651);人胚肾系(亚克隆以在悬浮培养中生长的293或293细胞;graham等人,《普通病毒学杂志(j.gen virol.)》36:59(1977));幼小仓鼠肾细胞(bhk,atcc ccl10);中国仓鼠卵巢细胞/
‑
dhfr(cho,urlaub等人,《美国国家科学院院刊》77:4216(1980));小鼠支持细胞(tm4,mather,《生殖生物学(biol.reprod.)》23:243
‑
251(1980));猴肾细胞(cv1 atcc ccl 70);非洲绿猴肾细胞(vero
‑
76,atcc crl
‑
1587);人子宫颈癌细胞(hela,atcc ccl 2);犬肾细胞(mdck,atcc ccl 34);布法罗大鼠(buffalo rat)肝细胞(brl 3a,atcc crl 1442);人肺细胞(w138,atcc ccl 75);人肝细胞(hep g2,hb 8065);小鼠乳房肿瘤(mmt 060562,atcc ccl51);tri细胞(mather等人,《纽约科学院年报(annals n.y.acad.sci.)》383:44
‑
68(1982));mrc 5细胞;fs4细胞;和人肝瘤系(hep g2)。在一些优选实施方式中,宿主细胞为293f细胞。
[0692]
用上述用于产生抗cd40抗体的表达或克隆载体转染宿主细胞,并在按需要改良的常规营养培养基中培养,以诱导启动子、选择转化体或扩增编码所需序列的基因。在另一实施方式中,抗体可通过所属领域中已知的同源重组产生。
[0693]
用于产生本文提供的抗体或抗原结合片段的宿主细胞可以在各种培养基中培养。市售培养基,如ham's f10(sigma)、最小必需培养基(mem)(sigma)、rpmi
‑
1640(sigma)和杜尔贝科氏改良型伊格尔氏培养基(dulbecco's modified eagle's medium,dmem,sigma)适用于培养宿主细胞。另外,ham等人,《酶学方法》58:44(1979);barnes等人,《分析生物化学(anal.biochem.)》102:255(1980);美国专利号4,767,704、4,657,866、4,927,762、4,560,655或5,122,469;wo 90/03430;wo 87/00195;或美国专利re30,985中所述的培养基中的任
一种都可以用作宿主细胞的培养基。这些培养基中的任一种都可以视需要补充激素和/或其它生长因子(如胰岛素、转铁蛋白或表皮生长因子)、盐(如氯化钠、钙盐、镁盐和磷酸盐)、缓冲剂(如hepes)、核苷酸(如腺苷和胸苷)、抗生素(如gentamycin
tm
药物)、微量元素(定义为通常以微摩尔范围内的最终浓度存在的无机化合物)和葡萄糖或等效能量源。也可以所属领域的技术人员已知的适当浓度包括任何其它必需的补充剂。培养条件,如温度、ph等,是先前与选择用于表达的宿主细胞一起使用的条件,并且对所属领域的普通技术人员来说将是显而易见的。
[0694]
当使用重组技术时,抗体可以在细胞内、周质空间中产生,或直接分泌至培养基中。如果抗体在细胞内产生,那么作为第一步,将微粒碎片(宿主细胞或溶解片段)例如通过离心或超滤去除。carter等人,《生物技术》10:163
‑
167(1992)描述了一种用于分离分泌到大肠杆菌的周质空间的抗体的程序。简而言之,在乙酸钠(ph 3.5)、edta和苯甲基磺酰氟(pmsf)的存在下,在约30分钟内将细胞糊解冻。细胞碎片可以通过离心去除。在抗体分泌到培养基中的情况下,来自所述表达系统的上清液一般首先使用市售的蛋白质浓缩过滤器(例如amicon或millipore pellicon超滤单元)进行浓缩。可在前述任一步骤中包括蛋白酶抑制剂(如pmsf)以抑制蛋白水解,且可以包括抗生素以防止外来污染物的生长。
[0695]
由细胞制备的抗cd40抗体和其抗原结合片段可以使用例如羟基磷灰石色谱、凝胶电泳、透析、deae
‑
纤维素离子交换色谱、硫酸铵沉淀、盐析和亲和色谱进行纯化,其中亲和色谱是优选的纯化技术。
[0696]
在某些实施方式中,固定在固相上的蛋白质a用于进行抗体和其抗原结合片段的免疫亲和力纯化。蛋白质a作为亲和配体的适合性取决于抗体中存在的任何免疫球蛋白fc结构域的物种和同种型。蛋白质a可用于纯化基于人γ1、γ2或γ4重链的抗体(lindmark等人,《免疫学方法杂志》62:1
‑
13(1983))。蛋白质g被建议用于所有小鼠同种型和人γ3(guss等人,《欧洲分子生物学杂志(embo j.)》5:1567 1575(1986))。亲和配体所附接的基质最通常是琼脂糖,但也可以使用其它基质。机械上稳定的基质,如受控微孔玻璃或聚(苯乙烯二乙烯基)苯,可以实现比琼脂糖更快的流动速率和更短的加工时间。当抗体包含ch3结构域时,bakerbond abx
tm
树脂(新泽西州菲利普斯堡(phillipsburg,n.j.)j.t.baker)可用于纯化。用于蛋白质纯化的其它技术,如离子交换柱分级分离、乙醇沉淀、反相hplc、硅胶色谱、肝素sepharose
tm
色谱、阴离子或阳离子交换树脂(如聚天冬氨酸柱)色谱、色谱焦聚、sds
‑
page和硫酸铵沉淀,取决于待回收的抗体也是可用的。
[0697]
在任何一个或多个初步纯化步骤之后,可使用ph在约2.5
‑
4.5之间的洗脱缓冲液,对包含相关抗体和污染物的混合物进行低ph疏水相互作用色谱,优选在低盐浓度(例如约0
‑
0.25m盐)下进行。
[0698]
viii.药物组合物
[0699]
本公开进一步提供包含抗cd40抗体或其抗原结合片段和一种或多种药学上可接受的载体的药物组合物。
[0700]
用于本文所公开的药物组合物的药学上可接受的载体可以包括例如药学上可接受的液体、凝胶或固体载体、水性媒剂、非水性媒剂、抗微生物剂、等渗剂、缓冲剂、抗氧化剂、麻醉剂、悬浮剂/分散剂、螯合剂(sequestering/chelating agent)、稀释剂、佐剂、赋形剂或无毒辅助物质、所属领域中已知的其它组分或其各种组合。
[0701]
适合的组分可包括例如抗氧化剂、填充剂、粘合剂、崩解剂、缓冲剂、防腐剂、润滑剂、调味剂、增稠剂、着色剂、乳化剂或稳定剂,如糖和环糊精。适合抗氧化剂可包括例如甲硫氨酸、抗坏血酸、edta、硫代硫酸钠、铂、过氧化氢酶、柠檬酸、半胱氨酸、硫代甘油、硫代乙醇酸、硫代山梨糖醇、丁基化羟基苯甲醚、丁基化羟基甲苯和/或没食子酸丙酯。如本文所公开,在包含如本文所提供的抗体或抗原结合片段和缀合物的组合物中,包括一种或多种抗氧化剂(如甲硫氨酸),减少抗体或抗原结合片段的氧化。此氧化减少将防止或减少结合亲和力的损失,由此提高抗体稳定性并使储存寿命最大化。因此,在某些实施方式中,提供包含一种或多种如本文所公开的抗体或抗原结合片段和一种或多种抗氧化剂(如甲硫氨酸)的组合物。本文进一步提供通过将抗体或抗原结合片段与一种或多种抗氧化剂(例如甲硫氨酸)混合来防止如本文所提供的抗体或抗原结合片段的氧化、延长其储存寿命和/或提高其功效的方法。
[0702]
为了进一步说明,药学上可接受的载体可包括例如水性媒剂,如氯化钠注射液、林格氏注射液(ringer's injection)、等渗右旋糖注射液、无菌水注射液、或右旋糖和乳酸林格氏注射液;非水性媒剂,如植物来源的非挥发性油、棉籽油、玉米油、芝麻油或花生油;抑制细菌或抑制真菌浓度的抗微生物剂;等渗剂,如氯化钠或右旋糖;缓冲剂,如磷酸盐或柠檬酸盐缓冲剂;抗氧化剂,如硫酸氢钠;局部麻醉剂,如普鲁卡因盐酸盐(procaine hydrochloride);悬浮剂和分散剂,如羧甲基纤维素钠、羟丙基甲基纤维素或聚乙烯吡咯烷酮;乳化剂,如聚山梨醇酯80(tween
‑
80);螯合剂,如乙二胺四乙酸(edta)或乙二醇四乙酸(egta)、乙醇、聚乙二醇、丙二醇、氢氧化钠、盐酸、柠檬酸或乳酸。用作载体的抗微生物剂可添加至多剂量容器中的药物组合物中,所述抗微生物剂包括苯酚或甲酚、汞剂、苯甲醇、氯丁醇、对羟基苯甲酸甲酯和对羟基苯甲酸丙酯、硫柳汞、苯扎氯铵(benzalkonium chloride)和苄索氯铵(benzethonium chloride)。适合的赋形剂可包括例如水、生理盐水、右旋糖、甘油或乙醇。适合的无毒辅助物质可包括例如润湿剂或乳化剂、ph缓冲剂、稳定剂、溶解性增强剂或如乙酸钠、脱水山梨糖醇单月桂酸酯、三乙醇胺油酸酯或环糊精的试剂。
[0703]
药物组合物可为液体溶液、悬浮液、乳液、丸剂、胶囊、片剂、持续释放配制物或散剂。口服配制物可包括标准载体,如药物级甘露糖醇、乳糖、淀粉、硬脂酸镁、聚乙烯吡咯烷酮、糖精钠、纤维素、碳酸镁等。
[0704]
在某些实施方式中,药物组合物被配制成可注射组合物。可注射的药物组合物可以任何常规形式,例如液体溶液、悬浮液、乳液或适于产生液体溶液、悬浮液或乳液的固体形式制备。注射用制剂可包括准备好用于注射的无菌和/或无热原质溶液;准备好在临用前与溶剂组合的无菌干燥可溶性产品,如冻干粉末,包括皮下片剂;准备好用于注射的无菌悬浮液;准备好在临用前与媒剂组合的无菌干燥不溶性产品;和无菌和/或无热原质乳液。溶液可以是水性或非水性的。
[0705]
在某些实施方式中,单位剂量的肠胃外制剂被包装在安瓿、小瓶或带针头的注射器中。用于肠胃外施用的所有制剂都应是无菌且无热原质的,正如所属领域中已知和实践的那样。
[0706]
在某些实施方式中,无菌冻干粉末通过将如本文所公开的抗体或抗原结合片段溶解于适合溶剂中来制备。溶剂可含有提高稳定性的赋形剂和粉末或由粉末制备的复原溶液的其它药理学组分。可使用的赋形剂包括但不限于水、右旋糖、山梨糖醇、果糖、玉米糖浆、
木糖醇、甘油、葡萄糖、蔗糖或其它适合的试剂。溶剂可以含有缓冲剂,如柠檬酸盐、磷酸钠或磷酸钾、或所属领域的技术人员已知的其它所述缓冲剂,在一个实施方式中,缓冲剂呈约中性ph。随后对溶液进行无菌过滤,然后在所属领域的技术人员已知的标准条件下进行冻干,得到所需配制物。在一个实施方式中,将所得溶液分配到小瓶中进行冻干。每个小瓶可以含有单剂量或多剂量的抗cd40抗体或其抗原结合片段或其组合物。少量高于一个剂量或一组剂量所需(例如约10%)的过量填充小瓶是可以接受的,以便于精确地抽取样品和精确地给药。冻干粉末可在适当条件下储存,例如在约4℃到室温下。
[0707]
用注射用水复原冻干粉末提供用于肠胃外施用的配制物。在一个实施方式中,为进行复原,将无菌和/或无热原质水或其它液体适合载体添加至冻干粉末中。精确量取决于所给出的所选择的疗法,且可凭经验确定。
[0708]
ix.使用方法
[0709]
本公开还提供治疗方法,其包括:向有需要的受试者施用治疗有效量的如本文所提供的抗体或抗原结合片段,从而治疗或预防cd40相关病状或病症。在一些实施方式中,cd40相关病状或病症为癌症、自身免疫疾病、炎性疾病或传染病。
[0710]
癌症的实例包括但不限于非小细胞肺癌(鳞状/非鳞状)、小细胞肺癌、肾细胞癌、结肠直肠癌、结肠癌、卵巢癌、乳腺癌(包括基底乳腺癌、导管癌和小叶乳腺癌)、胰腺癌、胃癌、膀胱癌、食道癌、间皮瘤、黑色素瘤、头颈癌、甲状腺癌、肉瘤、前列腺癌、成胶质细胞瘤、子宫颈癌、胸腺癌、黑色素瘤、骨髓瘤、蕈样霉菌病(mycoses fungoids)、梅克尔细胞癌(merkel cell cancer)、肝细胞癌(hcc)、纤维肉瘤、粘液肉瘤、脂肪肉瘤、软骨肉瘤、骨原性肉瘤和其它肉瘤、滑膜瘤、间皮瘤、尤文氏肿瘤(ewing's tumor)、平滑肌肉瘤、横纹肌肉瘤、淋巴恶性疾病、基底细胞癌、腺癌、汗腺癌、甲状腺髓样癌、乳头状甲状腺癌、嗜铬细胞瘤皮脂腺癌、乳头状癌、乳头状腺癌、髓质癌、支气管癌、肝癌、胆管癌、绒膜癌、维尔姆斯瘤(wilms'tumor)、子宫颈癌、睾丸肿瘤、精原细胞瘤、经典霍奇金淋巴瘤(chl)、原发性纵隔大b细胞淋巴瘤、富t细胞/组织细胞b细胞淋巴瘤、急性淋巴细胞性白血病、急性骨髓细胞性白血病、急性骨髓性白血病、慢性骨髓细胞性(粒细胞性)白血病、慢性骨髓性白血病、慢性淋巴细胞性白血病、真性红细胞增多症、肥大细胞源性肿瘤、ebv阳性和阴性ptld和弥漫性大b细胞淋巴瘤(dlbcl)、浆母细胞性淋巴瘤、结外nk/t细胞淋巴瘤、鼻咽癌、hhv8相关原发性渗出性淋巴瘤、非霍奇金氏淋巴瘤、多发性骨髓瘤、瓦尔登斯特伦氏巨球蛋白血症(waldenstrom's macroglobulinemia)、重链疾病、骨髓增生异常综合征、毛状细胞白血病和骨髓增生异常、原发性cns淋巴瘤、脊髓肿瘤、脑干神经胶质瘤、星形细胞瘤、髓母细胞瘤、颅咽管瘤、室管膜瘤、松果体瘤、成血管细胞瘤、听神经瘤、少突神经胶质瘤、脑膜瘤、黑色素瘤、成神经细胞瘤和成视网膜细胞瘤。
[0711]
自身免疫疾病包括但不限于获得性免疫缺乏综合征(aids,其为具有自身免疫组分的病毒性疾病)、斑秃、强直性脊椎炎、抗磷脂综合征、自身免疫阿狄森病(autoimmune addison'sdisease)、自身免疫溶血性贫血、自身免疫肝炎、自身免疫内耳疾病(aied)、自身免疫淋巴细胞增生综合征(alps)、自身免疫血小板减少性紫癜(atp)、白塞氏病(behcet'sdisease)、心肌病、口炎性腹泻
‑
疱疹样皮炎;慢性疲乏免疫功能不全综合征(cfids)、慢性炎性脱髓鞘性多发性神经病(cipd)、瘢痕性类天疱疮、冷凝集素病、克雷斯综合征(crest syndrome)、克隆氏病(crohn's disease)、德戈斯病(degos'disease)、幼年型皮肌炎、盘状
狼疮、原发性混合型冷球蛋白血症、肌肉纤维疼痛
‑
纤维肌炎、格雷夫斯氏病(graves'disease)、吉兰
‑
巴雷综合征(guillain
‑
barre syndrome)、桥本氏甲状腺炎(hashimoto'sthyroiditis)、特发性肺纤维化、特发性血小板减少性紫癜(itp)、iga肾病、胰岛素依赖性糖尿病、幼年型慢性关节炎(斯提耳氏病(still's disease))、幼年型类风湿性关节炎、梅尼尔氏病(meniere's disease)、混合性结缔组织病、多发性硬化、重症肌无力、恶性贫血(pemacious anemia)、结节性多动脉炎、多软骨炎、多内分泌腺综合征、风湿性多肌痛、多发性肌炎和皮肌炎、原发性无γ球蛋白血症、原发性胆汁性肝硬化、牛皮癣、牛皮癣性关节炎、雷诺氏现象(raynaud's phenomena)、莱特尔氏综合征(reiter's syndrome)、风湿热、类风湿性关节炎、结节病、硬皮病(进行性全身性硬化(pss),也称为全身性硬化(ss))、舍格伦氏综合征(sjogren's syndrome)、僵人征候群、全身性红斑狼疮、高安氏动脉炎(takayasu arteritis)、颞动脉炎/巨细胞动脉炎、溃疡性结肠炎、葡萄膜炎、白斑病和韦格纳氏肉牙肿病(wegener's granulomatosis)。炎性病症包括例如慢性和急性炎性病症。炎性病症的实例包括阿尔茨海默病(alzheimer's disease)、哮喘、特应性过敏、过敏、动脉粥样硬化、支气管哮喘、湿疹、肾小球肾炎、移植物抗宿主疾病、溶血性贫血、骨关节炎、败血症、中风、组织和器官的移植、血管炎、糖尿病性视网膜病变和呼吸器诱发的肺损伤。在一些实施方式中,cd3相关病状为炎性疾病,如全身性红斑狼疮(sle)、肠道粘膜发炎、与结肠炎相关的消耗病、多发性硬化、病毒感染、类风湿性关节炎、骨关节炎、克罗恩病(cohn's disease)和发炎性肠病、牛皮癣、全身性硬皮病、自身免疫糖尿病等。
[0712]
传染病包括但不限于真菌感染、寄生虫/原虫感染或慢性病毒感染,例如疟疾(malaria)、粗球孢子菌病(coccidioidomycosis immitis)、组织胞浆菌病(histoplasmosis)、甲癣(onychomycosis)、曲霉病(aspergillosis)、芽生菌病(blastomycosis)、白色念珠菌病(candidiasis albicans)、副球孢子菌病(paracoccidioidomycosis)、微孢子虫病(microsporidiosis)、棘阿米巴角膜炎(acanthamoeba keratitis)、阿米巴症(amoebiasis)、蛔虫病(ascariasis)、焦虫病(babesiosis)、小袋虫病(balantidiasis)、浣熊蛔虫病(baylisascariasis)、恰加斯氏病(chagas disease)、支睾吸虫病(clonorchiasis)、锥蝇病(cochliomyia)、隐孢子虫病(cryptosporidiosis)、裂头绦虫病(diphyllobothriasis)、麦地那龙线虫病(dracunculiasis)、包虫病(echinococcosis)、象皮病(elephantiasis)、蛲虫病(enterobiasis)、片吸虫病(fascioliasis)、姜片虫病(fasciolopsiasis)、丝虫病(filariasis)、贾第虫病(giardiasis)、人体颚口线虫病(gnathostomiasis)、膜壳绦虫病(hymenolepiasis)、等孢子球虫(isosporiasis)、片山热(katayama fever)、利什曼体病(leishmaniasis)、莱姆病(lyme disease)、后殖吸虫病(metagonimiasis)、蛆病(myiasis)、盘尾线虫病(onchocerciasis)、虱病(pediculosis)、疥疮(scabies)、血吸虫病(schistosomiasis)、睡眠病(sleeping sickness)、杆线虫病(strongyloidiasis)、绦虫病(taeniasis)、弓蛔虫病(toxocariasis)、弓形虫病(toxoplasmosis)、旋毛虫病(trichinosis)、鞭虫病(trichuriasis)、锥虫病(trypanosomiasis)、蠕虫感染(helminth infection)、b型肝炎(hbv)感染、c型肝炎(hcv)感染、疱疹病毒(herpes virus)、埃
‑
巴二氏病毒(epstein
‑
barr virus)、hiv、巨细胞病毒(cytomegalovirus)、i型单纯疱疹病毒、ii型单纯疱疹病毒、人乳头瘤病毒、腺病毒、人免疫缺陷病毒i、人免疫缺陷病毒ii、卡波西韦斯
特肉瘤相关疱疹病毒传染(kaposi west sarcoma associated herpes virus epidemics)、细环病毒(thin ring virus/torquetenovirus)、人嗜t淋巴细胞病毒i(human tlymphotrophic viruse i)、人嗜t淋巴细胞病毒ii、水痘带状疱疹(varicella zoster)、jc病毒或bk病毒感染。
[0713]
如本文所提供的抗体或抗原结合片段的治疗有效量将取决于所属领域中已知的各种因素,例如受试者的体重、年龄、既往病史、目前的药物治疗、健康状况和交叉反应的可能性、过敏性、敏感性和不良副作用,以及施用途径和疾病发展的程度。所属领域的普通技术人员(例如医生或兽医)可如这些和其它情况或要求所指示按比例减少或增加剂量。
[0714]
在某些实施方式中,如本文所提供的抗体或抗原结合片段可以约0.01mg/kg至约100mg/kg的治疗有效剂量施用。在这些实施方式中的某些中,抗体或抗原结合片段是以约50mg/kg或更低的剂量施用,并且在这些实施方式中的某些中,剂量是10mg/kg或更低、5mg/kg或更低、3mg/kg或更低、1mg/kg或更低、0.5mg/kg或更低、或0.1mg/kg或更低。在某些实施方式中,施用剂量可在治疗过程中改变。例如,在某些实施方式中,初始施用剂量可以高于后续施用剂量。在某些实施方式中,施用剂量可依据受试者的反应在治疗过程中改变。
[0715]
可以调节给药方案以提供最优所需反应(例如治疗反应)。例如,可施用单剂量,或可随时间推移施用若干分剂量。
[0716]
本文所公开的抗体和抗原结合片段可通过所属领域中已知的任何途径施用,如肠胃外(例如皮下、腹膜内、静脉内(包括静脉内输注)、肌肉内或皮内注射)或非肠胃外(例如口服、鼻内、眼内、舌下、直肠或局部)途径。
[0717]
在一些实施方式中,本文所公开的抗体或抗原结合片段可以单独施用或与一种或多种额外治疗手段或药剂组合施用。举例来说,本文所公开的抗体或抗原结合片段可以与另一治疗剂(例如化学治疗剂或抗癌药物)组合施用。
[0718]
在这些实施方式中的某些中,如本文所公开的与一种或多种额外治疗剂组合施用的抗体或抗原结合片段可以与一种或多种额外治疗剂同时施用,并且在这些实施方式中的某些中,抗体或抗原结合片段和一种或多种额外治疗剂可以作为同一药物组合物的一部分施用。然而,与另一治疗剂“组合”施用的抗体或抗原结合片段不必与所述药剂同时施用或以同一组合物施用。如短语在本文中的使用,在另一药剂之前或之后施用的抗体或抗原结合片段被视为与所述药剂“组合”施用,即使抗体或抗原结合片段和第二药剂是通过不同途径施用的。当可能时,根据额外治疗剂的产品信息表单中列出的时间表,或根据《主治医师案头参考2003(physicians'desk reference 2003)》(《主治医师案头参考》,第57版;medical economics公司;isbn:1563634457;第57版(2002年11月))、或所属领域中众所周知的方案,施用与本文中所公开的抗体或抗原结合片段组合施用的额外治疗剂。
[0719]
本公开进一步提供使用抗cd40抗体或其抗原结合片段的方法。
[0720]
在一些实施方式中,本公开提供检测样品中cd40的存在或含量的方法,其包括使所述样品与抗体或其抗原结合片段接触,并且测定所述样品中cd40的存在或含量。
[0721]
在一些实施方式中,本公开提供诊断受试者的cd40相关疾病或病状的方法,其包括:a)使从所述受试者获得的样品与本文所提供的抗体或其抗原结合片段接触;b)测定所述样品中cd40的存在或含量;和c)使所述cd40的存在与所述受试者中所述cd40相关疾病或病状相关联。
[0722]
在一些实施方式中,本公开提供试剂盒,其包含任选地与可检测部分缀合的本文所提供的抗体或其抗原结合片段。所述试剂盒可用于检测cd40或诊断cd40相关疾病。
[0723]
在一些实施方式中,本公开还提供本文所提供的抗体或其抗原结合片段在制备用于治疗受试者的cd40相关疾病或病状的药物,在制备用于诊断cd40相关疾病或病状的诊断试剂中的用途。
[0724]
提供以下实施例是为了更好地说明要求保护的发明,而不应理解为限制本发明的范围。下述所有特定组合物、材料和方法完全或部分地落入本发明的范围内。这些特定组合物、材料和方法并不打算限制本发明,而是仅说明落入本发明范围内的特定实施方式。在不脱离本发明范围的情况下,所属领域的技术人员无需履行发明能力即可开发出等效组合物、材料和方法。应理解,可以在本文所述的程序中进行许多变化,同时仍保持在本发明的范围内。本发明人希望所述变化形式包括在本发明的范围内。
[0725]
实施例1:hekblue细胞cd40活化
[0726]
在96孔板中用抗cd40抗体以5
×
104/孔接种hekblue cd40l报告细胞(美国加利福尼亚州圣地亚哥(san diego,ca,usa)invivogen),并且在37℃下培育24小时。使用quanti
‑
blue分析(美国加利福尼亚州圣地亚哥invivogen)来分析上清液的分泌型胚胎碱性磷酸酶(seap)活性。相对于抗体浓度标绘650nm的吸光度以展现cd40活化。如图1中所示,抗体克隆5具有0.34nm的ec50,抗体克隆6具有8.0nm的ec50,而对照抗体(如zhang等人的美国专利号8778345b2中所公开的apx005m)具有10nm的ec50。
[0727]
实施例2:在冻融条件下的稳定性测试.
[0728]
为了测试抗体在冻融条件下的稳定性,将pbs中的抗cd40抗体等分试样在
‑
80℃下冷冻72小时且在4℃下完全解冻,且随后在96孔板中用hekblue cd40l报告细胞以5
×
104/孔接种且在37℃下培育24小时。使用quanti
‑
blue测定来分析上清液的分泌型胚胎碱性磷酸酶(seap)活性。相对于抗体浓度标绘650nm的吸光度以展现cd40活化。如图2中所示,抗体克隆5和6在冻融条件下稳定。ft,冻融等分试样
[0729]
实施例3:hekblue细胞上的cd40结合
[0730]
流式细胞测量术用于测定抗cd40抗体与细胞表面上呈现的cd40蛋白质的结合。收集hekblue cd40l报告细胞并且用抗cd40和荧光二级抗体染色。抗体结合以中值荧光强度展示。如图3中所示,在与cd40的结合中,抗体克隆5具有0.36nm的ec50,抗体克隆6具有0.63nm的ec50,而对照抗体具有0.82nm的ec50。
[0731]
实施例4:结合亲和力
[0732]
使用生物层干涉测量法(bli)在octet系统上测定与重组cd40 ecd
‑
fc融合蛋白的结合亲和力。简单来说,通过链霉亲和素探针捕获生物素化的cd40 ecd
‑
fc,且用实时光干涉测量法测量抗体缔合/解离。随后通过k
on
和k
off
计算kd。结果展示于下表中。
[0733]
抗体克隆k
d
(pm)56.0463771518416642023312
apx005m41
[0734]
实施例5:表位分组(binning)
[0735]
使用octet系统进行表位分组。简单来说,使第一抗体结合cd40 ecd
‑
fc并且引入第二抗体。第二抗体结合的量用于获得两个结合表位之间的关系。下文提供展示分组结果的经校正矩阵。结果指示抗体克隆5和6与不同表位结合。
[0736]
抗体克隆5克隆6对照组克隆50.00881.10510.018克隆61.53880.06840.7226对照组0.08620.13180.0241
[0737]
实施例6:cd40l结合的竞争
[0738]
使用cd40l和抗cd40抗体进行竞争elisa。简单来说,将cd40l涂布于elisa板上并且暴露于预混合的cd40 ecd
‑
fc
‑
his融合蛋白和抗cd40抗体。随后使用抗his抗体测定cd40与cd40l的结合并且呈现为不存在抗体情况下cd40与cd40l的结合百分比。如图4中所示,抗体克隆5抑制约90%的cd40l结合,而抗体克隆6抑制约50%。
[0739]
实施例7:b细胞活化
[0740]
使用cd80和cd86表达来评估抗cd40抗体引起的b细胞活化。简单来说,在存在或不存在抗cd40抗体的情况下,将单核细胞耗乏的健康供体pbmc与il
‑
2和il
‑
4一起培育48小时。使用流式细胞测量术分析cd19
细胞上的cd80和cd86表达。如图5a中所示,通过cd80表达评估的b细胞活化中,抗体克隆5具有2.7pm的ec50,抗体克隆6具有0.17nm的ec50,而对照抗体具有0.41nm的ec50。如图5b中所示,通过cd86表达评估的b细胞活化中,抗体克隆5具有1.5pm的ec50,抗体克隆6具有0.14nm的ec50,而对照抗体具有21pm的ec50。值得注意的是,如图5b中所示,与对照抗体和抗体克隆5相比,抗体克隆6可以在更高程度上活化b细胞,如由高浓度下最高的cd86表达水平所指示。
[0741]
实施例8:树突状细胞成熟和活化
[0742]
使用cd80和cd86表达来评估抗cd40抗体引起的树突状细胞成熟和活化。简单来说,单核细胞从健康供体pbmc分离,用gm
‑
csf和il
‑
4诱导5天朝向树突状细胞的分化。随后引入抗cd40抗体再持续48小时。使用流式细胞测量术分析modc cd80和cd86表达。如图6a中所示,由cd80表达评估的单核细胞衍生的树突状细胞(modc)活化中,抗体克隆5具有0.74nm的ec50,抗体克隆6具有29nm的ec50,而对照抗体apx005m具有1.6nm的ec50并且对照抗体cp
‑
870893(美国纽约社利(shirley,ny,usa)creative biolabs)具有5.0nm的ec50。如图6b中所示,由cd86表达评估的modc活化中,抗体克隆5具有1.3nm的ec50,抗体克隆6具有22nm的ec50,而对照抗体apx005m具有1.7nm的ec50并且对照抗体cp
‑
870893具有4.2nm的ec50。值得注意的是,如图6a和图6b中所示,与对照抗体和抗体克隆5相比,抗体克隆6可以在更高程度上活化modc,如由在高浓度下最高的cd80和cd86表达水平所指示。
[0743]
*************
[0744]
本文所公开或所要求保护的所有组合物和方法都可根据本公开在无过度实验的情况下制造和执行。虽然本发明的组合物和方法已结合优选实施方式描述,但是对于所属领域的技术人员显而易见的是,在不脱离本发明的概念、精神和范围的情况下,可以对方法和本文所描述的方法中的步骤或步骤顺序进行改变。更具体地说,显然,在化学上和生理学
上相关的某些试剂可以取代本文所述的试剂,同时实现相同或类似的结果。对于所属领域的技术人员显而易见的所有所述类似的替代和修改被认为是在由所附权利要求书定义的本发明的精神、范围和概念内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。