基于
γ
‑
疑似感染社区模型的疑似流行病感染人员检测方法
技术领域
1.本发明属于数据挖掘技术领域,具体为一种基于γ
‑
疑似感染社区模型的疑似流行病感染人员检测方法。
背景技术:
2.以新冠为代表的流行病防控的关键之一就是发现感染者,感染者发现的越早,越能及时控制疫情,减轻下游医疗救治工作的压力。因此,开展主动检测和流行病学摸排工作,挖出潜在的无症状感染者或疑似病例,对有效控制传染源、减少或消除病原体扩散、防止疾病在人群中的传播蔓延具有重要作用。
3.但是发现新冠的感染者存在许多困难,新冠病毒的感染能力特别强,咳嗽、打喷嚏、说话甚至站在近处都会被感染,而且感染新冠之后并不会立即发病,存在14天潜伏期,而在潜伏期内,新冠仍然具有感染性,这无疑给新冠感染者的发现增加了难度。而如今存在的算法中存在局限性,没有很好的把时间和位置信息进行统筹,而对于新冠来说,不将时间和地理位置信息同时匹配是不具有显示意义的。
技术实现要素:
4.本发明的目的在于提供了一种基于γ
‑
疑似感染社区模型的疑似流行病感染人员检测方法,并且可以查找出所有的高感染团体。
5.实现本发明目的的技术方案为:一种基于γ
‑
疑似感染社区模型的疑似流行病感染人员检测方法,具体步骤为:
6.步骤1,爬取网络上感染人员出行轨迹信息;
7.步骤2,分析感染人员出行轨迹数据,对人员出行轨迹数据进行两两匹配,获得任意两个人员接触可能性数值,存储到匹配值文件中;
8.步骤3,读取匹配值文件中的数据,生成接触概率图,其中,将人员id作为接触概率图的节点,两个人员的接触可能性数值作为连接两节点边的权值;
9.步骤4,对接触概率图进行极大团搜索,找到接触概率图中极大团,对所有找到的极大团进行单独分析,找到所有极大团上的γ
‑
疑似感染社区。
10.优选地,所述网络上感染人员出行轨迹信息包括个人的唯一表示id和轨迹数据,轨迹数据包括地点信息和时间信息。
11.优选地,分析感染人员出行轨迹数据,对人员出行轨迹数据进行两两匹配,获得任意2个人员接触可能性数值的具体方法为:
12.选取任意两个轨迹文件,读取文件中的轨迹信息;
13.判断时间匹配度:判断生成的两条轨迹数据是否属于同一天并且在设定的时间差值内,即两个轨迹文件的首尾时间是否存在交集,若不存在交集,则重新选取两个轨迹文件进行时间匹配度判断,若是存在,则进行下一步地理位置匹配度判断;
14.判断地理位置匹配度:匹配地点位置,判断生成的两条轨迹数据是否属于在距离
容差范围内的同一区域内,若不属于,则重新选取两个轨迹文件进行时间匹配度判断,若是存在,则计算接触可能性数值;
15.分段计算两个轨迹的匹配值,将最大匹配值作为接触可能性数值。
16.优选地,两个轨迹的匹配值的计算方法为:
17.设定其中一条轨迹段的区域范围,将匹配时间段内另一条轨迹段在其中一条轨迹段区域范围内的轨迹点占另一条轨迹段总轨迹点的比值作为匹配值。
18.优选地,寻找接触概率图中极大团的具体方法为:
19.构建3个集合r、p、x用以保存算法枚举过程中的状态,r集合是结果集,表示为当前已经找到的团,r中的节点都互相相连,但不一定构成极大团;p集合和x集合中的节点表示r集合中的节点的公共邻居,p集合和x集合中的点都可以加入到r集合,以此扩充r集合的团结构,x集合为禁止集,其中的节点,都是之前已经加入到r集合中过的点;p集合为备选集,表示为尚未加入r集合中的点;
20.每次从p集合中选取一个点v加入r集合中,同时更新p集合和x集合,保证p集合和x集合依然含有的是新r集合的公共邻居,具体为:将p集合和x集合分别和v点的邻接表做交集,进行递归调用,当递归调用结束后,将v点从备选集p转入禁止集x中,在p和x集合均为空的时候输出r集合作为极大团。
21.优选地,找极大团上的γ
‑
疑似感染社区的具体方法为:
22.选取极大团上内的两个相邻节点加入集合c中,集合c表示当前找到的γ
‑
团;
23.在满足选取的两个节点之间的边大于γ条件下选取新节点加入集合c,且满足新节点加入集合c之后,所有边的乘积大于等于γ;
24.遍历极大团上的所有节点,最后得到的集合c即为极大团上的γ
‑
疑似感染社区。
25.优选地,选取新节点的具体方法为:
26.以一个未被访问过的节点作为起始节点,沿当前节点的边走到未访问过的节点,当没有未访问过的节点时,则回到上一个节点,继续试探别的节点,直至所有的节点都被访问结束。
27.本发明与现有技术相比,其显著优点为:从技术手段上来说,本发明采用基于现实世界的轨迹数据进行匹配,将匹配的返回数值作为人员感染接触可能性的衡量,不仅去除了直接询问隔离人员的局限性,并且可以找全与患者有过一段近距离共处的陌生人,直观的以数字作为人员接触的程度,从而减少寻找感染人员的时间;本发明的轨迹匹配采用了适当的剪枝,表示当前判断的两条轨迹在当前的时间上无法匹配,那么空间上就不进行匹配,节省了计算地理位置匹配的计算量和地理位置的匹配时间;本发明掌握了患者在被隔离前的活动轨迹,就可以很清楚地知道他去过的地方,再通过时空范围查询就能找到跟患者有过近距离接触的人群,直接查找到一段时间内与感染人员接触的人员信息,节省了人力物力财力和医护人员的工作量;本发明可以设置不同的阈值γ可以产生不同概率下的γ
‑
疑似感染社区,以此应对不同场景下的感染匹配。
附图说明
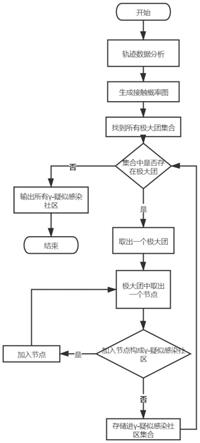
28.图1本发明的流程示意图。
29.图2是一个图的示意图。
30.图3是图2中极大团的示意图。
31.图4是一个接触概率图的示意图。
32.图5是一个仅包含位置信息的轨迹示意图。
33.图6是一个包含时间和位置信息的轨迹示意图。
34.图7是图5映射在二维平面上的轨迹示意图。
35.图8是无向图的深度遍历的示意图。
具体实施方式
36.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
37.如图1所示,一种基于γ
‑
疑似感染社区模型的疑似流行病感染人员检测方法,具体步骤如下:
38.步骤1,爬取网络上感染人员出行轨迹信息;
39.所述网络上感染人员出行轨迹信息包括个人的唯一表示id和轨迹数据,轨迹数据包括地点信息和时间信息,并存储为trace(id,location,time)形式,id指个人的唯一表示id,location表示地点信息,time表示时间信息。
40.步骤2,分析感染人员出行轨迹数据,对人员出行轨迹数据进行两两匹配,获得任意2个人员接触可能性数值,存储到匹配值文件中,具体方法如下:
41.选取任意两个轨迹文件,读取文件中的轨迹信息;
42.判断时间匹配度:判断生成的两条轨迹数据是否属于同一天并且在设定的时间差值内,即两个轨迹文件的首尾时间是否存在交集,若不存在交集,则重新选取两个轨迹文件进行时间匹配度判断,若是存在,则进行下一步地理位置匹配度判断;
43.判断地理位置匹配度:匹配地点位置,判断生成的两条轨迹数据是否属于在距离容差范围内的同一区域内,若不属于,则重新选取两个轨迹文件进行时间匹配度判断,若是存在,则计算接触可能性数值;
44.分段计算两个轨迹的匹配值,将最大匹配值作为接触可能性数值。两个轨迹的匹配值的计算方法为:
45.设定其中一条轨迹段的区域范围,将匹配时间段内另一条轨迹段在其中一条轨迹段区域范围内的轨迹点占另一条轨迹段总轨迹点的比值作为匹配值。
46.对所有轨迹文件进行进行两两匹配,计算接触可能性数值。
47.步骤3,读取匹配值文件中的数据,生成接触概率图,其中,将人员id作为接触概率图的节点,两个人员的接触可能性数值作为连接两节点边的权值;
48.在本发明中,将图表示成g(v,e),其中v是图中所有节点的集合,而e则是所有边的集合,通常使用n,m分别表示g中点数和边数,即n=|v|、m=|e|。对于图g中的任意两点u、v,使用二元组(u,v)表示连接点u和点v的一条边。对于每个节点v∈g,设n
g
(v)表示v的邻居,即n
g
(v)={u|(v,u)∈e,u,v∈v}。所有邻居点合在一起组成了点v的邻接表,表示为γ(v)。γ(v)的大小称之为点v的度数。
49.而对于给定接触概率图g'=(v,e,γ),其中v表示g中节点的集合,e表示g中边的集合,γ表示图中的不确定性,指图中边的权值。在接触概率图g'=(v,e,γ)中,不同边的存在与否是相互独立的事件,边上的概率值并不相互影响。对图g'中的节点u,用l(u)表示节点u的所有邻居节点。集合c存放当前找到的团的节点,用来表示当前找到的γ
‑
团,对于图中的节点子集c,max(c)表示c中编号最大的节点,l(c)表示c的所有邻居节点。对于图g'中的集合c,用clique(c,g')表示c的团概率,并且规定clique(c,g')=1。令n=|v|,m=|e|,n和m分别表示图g节点的数量和边的数量。
50.定义1:团在图g=(v,e)中,如果节点子集c中任意节点之间都有边相连,则节点子集c是一个团。
51.定义2:极大团对于图g=(v,e)中的节点子集m和v,如果:(1)m满足团的定义;(2)不存在一个节点v∈v\m,使得m∪v是一个团,则m是一个极大团。
52.定义3:团概率在接触概率图g'=(v,e,γ)中,对于任意的团c,团概率clique(c,g')为c中所有边的权值的乘积。
53.定义4:γ
‑
团在接触概率图g'=(v,e,γ)中,如果节点子集c和v,满足:(1)c是一个团;(2)clique(c,g')>=γ,那么c是一个γ
‑
团。
54.定义5:γ
‑
疑似感染社区在接触概率图g'=(v,e,γ)中,如果节点子集c和v,满足:(1)c是一个γ团;(2)在图g'中不存在一个节点v∈v\c,使得c∪v是一个γ
‑
团,则c是图g'中的一个γ
‑
疑似感染社区。
55.步骤4,对接触概率图进行极大团搜索,首先找到接触概率图中极大团,再对所有找到的极大团进行单独分析,找到所有极大团上的γ
‑
疑似感染社区,具体方法如下:
56.找极大团的具体方法为:
57.构建3个集合r、p、x用以保存算法枚举过程中的状态,r集合是结果集,表示为当前已经找到的团,r中的节点都互相相连,但不一定构成极大团;p集合和x集合中的节点表示r集合中的节点的公共邻居,p集合和x集合中的点都可以加入到r集合,以此扩充r集合的团结构,x集合为禁止集,其中的节点,都是之前已经加入到r集合中过的点;p集合为备选集,表示为尚未加入r集合中的点;
58.每次从p集合中选取一个点v加入r集合中,同时更新p集合和x集合,保证p集合和x集合依然含有的是新r集合的公共邻居,具体为:将p集合和x集合分别和v点的邻接表做交集,进行递归调用,当递归调用结束后,将v点从备选集p转入禁止集x中,在p和x集合均为空的时候输出r集合作为极大团。
59.找所有极大团上的γ
‑
疑似感染社区的具体方法为:
60.选取极大团上内的两个相邻节点加入集合c中,集合c表示当前找到的γ
‑
团,两节点之间的边要大于γ,γ设置为一个阈值,表示团内所有的边的乘积的最小值,当要去扩充γ
‑
团c时,只加入c的公共邻居节点中编号大于max(c)的节点。但是每次c中添加进新的节点后,c的团概率会降低,可能导致clique(c,g')<γ,此时的集合c就不再是一个γ
‑
团。
61.在满足选取的两个节点之间的边大于γ条件下再选取其他的节点,选取新节点加入c之前,且新节点加入集合c后所有边的乘积大于等于γ。
62.选取新节点的方式采取基于深度优先遍历(dfs)算法如图8所示,深度优先遍历首先以一个未被访问过的节点作为起始节点,沿当前节点的边走到未访问过的节点,当没有
未访问过的节点时,则回到上一个节点,继续试探别的节点,直至所有的节点都被访问结束。采取节点编号升序来处理接触概率图中的节点,并且通过维持集合a和集合b进行搜索,以此高效地枚举接触概率图中所有的γ
‑
疑似感染社区,其中a集合中存放(u,r)数据对,u表示的是节点编号,r表示将节点u添加进入集合c后,集合c要乘上的值,并且u>max(c),u加入集合c之后,仍保证所有边的乘积大于等于阈值γ,而集合c存放当前找到的团的节点集合表示的是接触概率图中的子集,max(c)表示的是c中编号最大的节点。b集合也是存放数据对(u,r),含义与a相同,但是b集合中存放的节点都是已经处理过的节点,当a集合为空时,结束,但是不能证明c是γ
‑
疑似感染社区,可能b集合中仍有节点可以扩充c,只有当a和b集合都为空时,c才是γ
‑
疑似感染社区。判断是否已选取了极大团中的所有节点,即极大团内所有节点是否都被遍历过,当所有节点被遍历过,获得的集合c为γ
‑
疑似感染社区。
63.如果γ
‑
疑似感染社区内检测出患病者,则疑似感染团体内其他人员都有极高的感染可能性。本发明可以设置不同的阈值γ可以产生不同概率下的γ
‑
疑似感染社区,以此应对不同场景下的感染匹配,比如针对交通工具,很小的阈值就可以进行判断相遇,那么对于普通的轨迹数据,相比于交通工具的接触,需要设置的比交通工具的阈值大一些。
64.实施例1:本实施例中,一种基于γ
‑
疑似感染社区模型的疑似流行病感染人员检测方法。首先对所有的轨迹数据进行匹配两条轨迹的接触程度,再通过接触程度的数据进行图上的极大团分析。本发明的搜索找到疑似流行病的感染团体,使之可以完成对流行病的疑似感染人员的搜索。
65.1.模型设计
66.在本发明中,一个图被表示成g(v,e)。其中v是图中所有节点的集合,而e则是所有边的集合,通常使用n,m分别表示g中点数和边数,即n=|v|、m=|e|。对于图g中的任意两点u、v,可以使用二元组(u,v)表示连接点u和点v的一条边。对于任意一个点v,所有和它相连的点都可以称为它的邻居点,所有邻居点合在一起组成了点v的邻接表,一般表示为γ(v)。γ(v)的大小称之为点v的度数。对于一个图g=(v,e),其中v表示节点集,e表示边,连接g中的节点。本发明分别用n和m表示节点的数目和边数,即n=|v|和m=|e|,对于每个节点v∈g,设n
g
(v)表示v的邻居,即n
g
(v)={u|(v,u)∈e,u,v∈v}。
67.而对于给定接触概率图g'=(v,e,γ),其中v表示g'中节点的集合,e表示g'中边的集合,γ表示图中的不确定性,指图中边的权值。在接触概率图g'=(v,e,γ)中,不同边的存在与否是相互独立的事件,边上的概率值并不相互影响。对图g'中的节点u,用l(u)表示节点u的所有邻居节点。对于图中的节点子集c,max(c)表示c中编号最大的节点,l(c)表示c的所有邻居节点。对于图g'中的团c,用clique(c,g')表示c的团概率,并且规定clique(0,g')=1。令n=|v|,m=|e|,n和m分别表示图g'节点的数量和边的数量。
68.定义1:团在图g=(v,e)中,如果节点子集c中任意节点之间都有边相连,则节点子集c是一个团。
69.定义2:极大团对于图g=(v,e)中的节点子集m和v,如果:(1)m满足团的定义;(2)不存在一个节点v∈v\m,使得m∪v是一个团,则m是一个极大团。
70.定义3:团概率在接触概率图g'=(v,e,γ)中,对于任意的团c,团概率clique(c,g')为c中所有边的权值的乘积。
71.定义4:γ
‑
团在接触概率图g'=(v,e,γ)中,如果节点子集c和v,满足:(1)c是一
个团;(2)clique(c,g')>=γ,那么c是一个γ
‑
团。
72.定义5:γ
‑
疑似感染社区在接触概率图g'=(v,e,γ)中,如果节点子集c和v,满足:(1)c是一个γ团;(2)在图g'中不存在一个节点v∈v\c,使得c∪v是一个γ
‑
团,则c是图g中的一个γ
‑
疑似感染社区。
73.如图2所示,定义在图上的极大团表示为c1={1,2,3},c2={3,5,6},c3={8,9},c4={1,4},c5={1,5},c6={5,10},c7={9,10},c8={6,7}。
74.2.接触概率图上的γ
‑
疑似感染社区搜索方法
75.2.1接触概率图上的γ
‑
疑似感染社区搜索算法
76.本发明针对图的性质,设计了一个搜索算法,用于匹配两条轨迹的匹配度。
77.2.1.1算法1
[0078][0079][0080]
根据轨迹数据包含的信息,将轨迹数据内包含的地点数据和时间进行比对,根据图示的轨迹将轨迹映射在二维平面中,在设置的单位时间内被比对的轨迹数据段,其包含的地理范围是否在比对数据一定差值的地理范围内,即在可允许的误差范围之中。对于轨迹数据trace=(id,date,time,location),在date相同的情况下,time的误差在一定范围之中,并且两者location的表示范围在误差distance内,两者轨迹区域的重合程度作为两者接触程度的指标。如果产生两条不同人的轨迹数据location_a和location_b,阴影表示的极值区域在d误差的作用下表示的区域范围,此时将location_b的轨迹点与阴影区域内进行匹配,匹配点的数量作为衡量两者接触程度指标的一个参考,若是两者存在多条轨迹
数据,即找到多条数据接触程度的最大值,作为两者之间的接触度,即图中两个节点之间边的数值,如图7所示。
[0081]
2.1.2算法2
[0082]
[0083][0084]
γ
‑
疑似感染社区搜索(maximal uncertainc lique enumeration)算法,通过在概率图上所找到的极大团为基准,遍历极大团内的节点,依次将极大团内的节点加入集合c中,γ
‑
疑似感染社区搜索算法中用集合c来表示当前找到的γ
‑
团,当要去扩充γ
‑
团c时,只加入c的公共邻居节点中编号大于max(c)的节点,如果加入节点后的c内所有的边乘积大于等于阈值γ,那么这个节点可以作为扩充c的节点加入到其中,但是每次c中添加进新的节点后,c的团概率会降低,可能导致概率<γ,此时的集合c就不再是一个γ
‑
团。当不再有节点可以加入到c中时,表示找到一个γ
‑
疑似感染社区。
[0085]
实施例2:如图4所示给定γ=0.1,那么接触概率图g'中的γ
‑
疑似感染社区分别为节点集合c1={1,2,3}、c2={2,5}、c3={3,4}、c4={3,5}、c5={4,5}、c6={5,6}、c7={6,7,8,9},共7个γ
‑
疑似感染社区。
[0086]
本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保
护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。