1.本发明涉及材料性能研究技术领域,特别涉及一种基于密度不平衡样本数据的材料性能预测方法及系统。
背景技术:
2.目前类别不平衡数据挖掘领域的研究已变得越来越重要。这是因为现实生活中的数据集基本是不平衡的,只是不平衡率不同,并且这种不平衡已经严重影响到分类算法的性能。不平衡分类的基本问题是不平衡数据造成多数机器学习算法性能降低。大多数机器学习算法是根据平衡数据集提出的,并且以总体分类准确率为分类算法的评价指标,因此对一些复杂的不平衡数据集进行处理时,这些传统分类算法不能充分地反映出数据的分布特征。因为识别少数类样本会比识别多数类样本要困难很多,很难确定少数类样本的真实决策边界,所以传统分类算法往往会出现将所有的样本划分为多数类的情况,而少数类的分类预测效果则很差。因此那些基于平衡数据提出的分类算法不适合处理不平衡数据分类任务。
3.在数据挖掘领域中集成分类是很有效的一种方法,在不平衡数据分类中,传统基于集成学习的分类方法,由于没有考虑不平衡数据分布的特点,也没有充分利用集成分类差异化学习的优势,导致在不平衡数据分类效果上不是很明显。
4.在材料领域中,缩短具有预期性能的新材料开发周期是现今材料工业界所迫切需要的。在大部分材料数据中,那些符合预期性能的材料数据往往会很少。现有的普遍做法是通过smote方法在数据预处理上对少数类样本进行扩充,来增加少数类样本的数量。虽然这种方法在数据层面上使数据集得到平衡,但是这种方法容易产生一些不正确的样本,干扰模型对少数类的预测。
技术实现要素:
5.本发明的目的是提供一种基于密度不平衡样本数据的材料性能预测方法及系统,以实现边界样本的定位,并通过基于边界样本的训练,提升对少数类样本预测的准确性。
6.为实现上述目的,本发明提供了如下方案:
7.一种基于密度不平衡样本数据的材料性能预测方法,所述预测方法包括如下步骤:
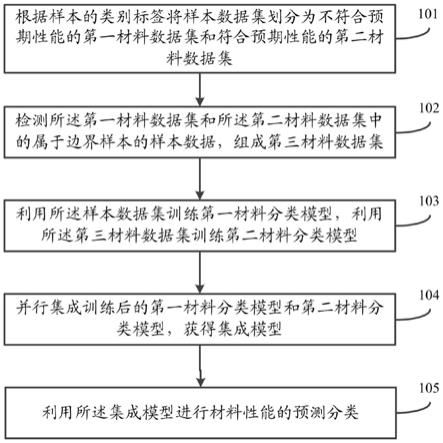
8.根据样本的类别标签将样本数据集划分为不符合预期性能的第一材料数据集和符合预期性能的第二材料数据集;所述第一材料数据集中样本数据的数量大于第二材料数据集中样本数据的数量;
9.检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集;
10.利用所述样本数据集训练第一材料分类模型,利用所述第三材料数据集训练第二材料分类模型;
11.并行集成训练后的第一材料分类模型和第二材料分类模型,获得集成模型;
12.利用所述集成模型进行材料性能的预测分类。
13.可选的,所述检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集,具体包括:
14.基于近邻计算方法确定所述第二材料数据集中的属于边界样本的样本数据,组成边界域;
15.将所述边界域和所述第一材料数据集合并获得融合样本集;
16.根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集。
17.可选的,所述基于近邻计算方法确定所述第二材料数据集中的属于边界样本的样本数据,组成边界域,具体包括:
18.基于近邻计算方法,计算第二材料数据集中每个样本数据在所述样本数据集中近邻的样本数据,获得第二材料数据集中每个样本数据的近邻的样本数据;
19.统计第二材料数据集中每个样本数据的近邻的样本数据中属于第一材料数据集的个数,获得第二材料数据集中每个样本数据的近邻统计个数;
20.将第二材料数据集中近邻统计个数在预设范围内的样本数据作为边界样本,添加至所述边界域。
21.可选的,所述根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集,具体包括:
22.获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除;
23.获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除;
24.基于近邻计算方法,获取待计算样本数据在融合样本集中的近邻的样本数据,添加至统计集合中;
25.判断所述统计集合中近邻的样本数据的个数是否小于预设阈值,获得第一判断结果;
26.若所述第一判断结果表示否,则将统计集合中的所有近邻的样本数据添加至计算队列和所述第三材料数据集,并将所述统计集合中的所有近邻的样本数据从所述融合样本集中删除;
27.判断所述计算队列是否为空,获得第二判断结果;
28.若所述第二判断结果为否,则返回步骤“获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除”;
29.若所述第二判断结果为是,则判断所述边界域是否为空,获得第三判断结果;
30.若所述第三判断结果表示否,则返回步骤“获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除”;
31.若所述第三判断结果表示是,输出所述第三材料数据集。
32.一种基于密度不平衡样本数据的材料性能预测系统,所述预测系统包括:
33.样本数据集划分模块,用于根据样本的类别标签将样本数据集划分为不符合预期
性能的第一材料数据集和符合预期性能的第二材料数据集;所述第一材料数据集中样本数据的数量大于第二材料数据集中样本数据的数量;
34.边界样本检测模块,用于检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集;
35.模型训练模块,用于利用所述样本数据集训练第一材料分类模型,利用所述第三材料数据集训练第二材料分类模型;
36.模型集成模块,用于并行集成训练后的第一材料分类模型和第二材料分类模型,获得集成模型;
37.性能预测模块,用于利用所述集成模型进行材料性能的预测分类。
38.可选的,所述边界样本检测模块,具体包括:
39.第一边界样本检测子模块,用于基于近邻计算方法确定所述第二材料数据集中的属于边界样本的样本数据,组成边界域;
40.数据集融合子模块,用于将所述边界域和所述第一材料数据集合并获得融合样本集;
41.第二边界样本检测子模块,用于根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集。
42.可选的,所述第一边界样本检测子模块,具体包括:
43.第一近邻的样本数据确定单元,用于基于近邻计算方法,计算第二材料数据集中每个样本数据在所述样本数据集中近邻的样本数据,获得第二材料数据集中每个样本数据的近邻的样本数据;
44.近邻统计个数获取单元,用于统计第二材料数据集中每个样本数据的近邻的样本数据中属于第一材料数据集的个数,获得第二材料数据集中每个样本数据的近邻统计个数;
45.第一边界样本检测单元,用于将第二材料数据集中近邻统计个数在预设范围内的样本数据作为边界样本,添加至所述边界域。
46.可选的,所述第二边界样本检测子模块,具体包括:
47.计算队列初始化单元,用于获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除;
48.待计算样本数据获取单元,用于获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除;
49.第二近邻的样本数据,用于确定单元基于近邻计算方法,获取待计算样本数据在融合样本集中的近邻的样本数据,添加至统计集合中;
50.第一判断单元,用于判断所述统计集合中近邻的样本数据的个数是否小于预设阈值,获得第一判断结果;
51.第二边界样本检测单元,用于若所述第一判断结果表示否,则将统计集合中的所有近邻的样本数据添加至计算队列和所述第三材料数据集,并将所述统计集合中的所有近邻的样本数据从所述融合样本集中删除;
52.第二判断单元,用于判断所述计算队列是否为空,获得第二判断结果;
53.第一返回单元,用于若所述第二判断结果为否,则返回步骤“获取所述计算队列中
的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除”;
54.第三判断单元,用于若所述第二判断结果为是,则判断所述边界域是否为空,获得第三判断结果;
55.第二返回单元,用于若所述第三判断结果表示否,则返回步骤“获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除”;
56.第三材料数据集输出单元,用于若所述第三判断结果表示是,输出所述第三材料数据集。
57.一种边界样本确定方法,所述确定方法包括如下步骤:
58.基于近邻计算方法确定第二材料数据集中的属于边界样本的样本数据,组成边界域;
59.将所述边界域和第一材料数据集合并获得融合样本集;
60.根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集。
61.可选的,所述基于近邻计算方法确定第二材料数据集中的属于边界样本的样本数据,组成边界域,具体包括:
62.基于近邻计算方法,计算第二材料数据集中每个样本数据在所述样本数据集中近邻的样本数据,获得第二材料数据集中每个样本数据的近邻的样本数据;
63.统计第二材料数据集中每个样本数据的近邻的样本数据中属于第一材料数据集的个数,获得第二材料数据集中每个样本数据的近邻统计个数;
64.将第二材料数据集中近邻统计个数在预设范围内的样本数据作为边界样本,添加至所述边界域。
65.可选的,所述根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集,具体包括:
66.获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除;
67.获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除;
68.基于近邻计算方法,获取待计算样本数据在融合样本集中的近邻的样本数据,添加至统计集合中;
69.判断所述统计集合中近邻的样本数据的个数是否小于预设阈值,获得第一判断结果;
70.若所述第一判断结果表示否,则将统计集合中的所有近邻的样本数据添加至计算队列和所述第三材料数据集,并将所述统计集合中的所有近邻的样本数据从所述融合样本集中删除;
71.判断所述计算队列是否为空,获得第二判断结果;
72.若所述第二判断结果为否,则返回步骤“获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除”;
73.若所述第二判断结果为是,则判断所述边界域是否为空,获得第三判断结果;
74.若所述第三判断结果表示否,则返回步骤“获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除”;
75.若所述第三判断结果表示是,输出所述第三材料数据集。
76.根据本发明提供的具体实施例,本发明公开了以下技术效果:
77.本发明公开了一种基于密度不平衡样本数据的材料性能预测方法,所述预测方法包括如下步骤:根据样本的类别标签将样本数据集划分为不符合预期性能的第一材料数据集和符合预期性能的第二材料数据集;检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集;利用所述样本数据集训练第一材料分类模型,利用所述第三材料数据集训练第二材料分类模型;并行集成训练后的第一材料分类模型和第二材料分类模型,获得集成模型;利用所述集成模型进行材料性能的预测分类。本发明首先定位边界样本,然后利用原始的样本数据集训练第一材料分类模型,利用边界样本训练第二材料分类模型,进而将第一材料分类模型和第二材料分类模型进行融合,利用融合后的集成模型进行材料性能的预测分类,实现了边界样本的定位,并通过基于边界样本的单独训练,提升了对少数类样本预测的准确性。
附图说明
78.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
79.图1为本发明提供的一种基于密度不平衡样本数据的材料性能预测方法的流程图;
80.图2为本发明提供的一种基于密度不平衡样本数据的材料性能预测方法的原理图;
81.图3为本发明提供的边界域确定的流程图;
82.图4为本发明提供的密度域(第三材料数据集)构建的流程图;
83.图5为本发明提供的材料分类模型训练与预测的原理图。
具体实施方式
84.本发明的目的是提供一种基于密度不平衡样本数据的材料性能预测方法及系统,以实现边界样本的定位,并通过基于边界样本的训练,提升对少数类样本预测的准确性。
85.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对发明作进一步详细的说明。
86.实施例1
87.如图1和2所示,本发明提供一种基于密度不平衡样本数据的材料性能预测方法,本发明以大块非晶合金材料数据集为例进行说明,所述预测方法包括如下步骤:
88.步骤101,根据样本的类别标签将样本数据集划分为不符合预期性能的第一材料数据集d
″
(即多数类样本集)和符合预期性能的第二材料数据集d
′
(即少数类样本);所述第
一材料数据集中样本数据的数量大于第二材料数据集中样本数据的数量。
89.数据集介绍:数据集t{(x1,y1),(x2,y2),
…
,(x
5936
,y
5936
)}共有16个特征分别为nt(normalizing temperature):归一化温度;tht(through hardening temperature):穿透硬化温度;tht(through hardening time):穿透硬化时间;thqcr(cooling rate for through hardening):穿透硬化冷却速度;ct(carburization temperature):渗碳温度;ct(carburization time):渗碳时间;dt(diffusion temperature):扩散温度;dt(diffusion time):扩散时间;qmt(quenching media temperature):淬火介质温度;tt(tempering temperature):回火温度;tt(temperingtime):回火时间;tcr(cooling rate fortempering):回火冷却速度、c:碳含量;ni:镍含量;cr:铬含量;mo:钼含量。其中温度的单位均用摄氏度表示,时间的单位为分钟,含量均被表示为百分比;和一个样本标签c(c∈(大块金属玻璃bmg,带状金属玻璃rmg,晶合金cra))。数据集t有5936个样本,大块金属玻璃bmg样本有675个,带状金属玻璃rmg样本有3708个,晶合金cra样本有1552个。随机地从数据集t中取4452个样本为训练集d,即样本数据集。根据样本标签将样本数据集分为不符合预期性能的第一材料数据集d
″
(c=rmg和cra)和符合预期性能的第二材料数据集d
′
(c=bmg)。
90.步骤102,检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集。
91.步骤102基于如下原理实现:
92.a.边界域构建:如图3所示,对每个少数类样本集d
′
中的材料样本x
i
进行近邻计算、近邻统计和边界判断等三种操作:
93.(1)近邻计算:从原数据集d中计算x
i
的m个近邻。从训练集d中计算材料样本x
i
(i∈[1,|d
′
|])的10个近邻。m表示距离该少数类样本最近的样本数。其取值需要根据数据集提前确定,一般m取10。其中的距离计算采用欧式距离计算。
[0094]
(2)近邻统计:在m个近邻中统计多数类样本个数m
′
,即,在10个近邻中统计多数类样本个数m
′
。
[0095]
(3)边界判断:如果m
′
介于和m之间(即,m
′
∈[5,10)),则将该少数类样本放入边界域b中。否则不做任何操作,这一步是根据大块金属玻璃bmg附近的m个样本中多数类样本的个数是否超过总近邻的半数,来判断该样本是否为边界样本。
[0096]
对下一个少数类样本同样进行上述(1)(2)(3)步操作。
[0097]
b.密度域构建过程包括以下步骤(如图4所示):
[0098]
步骤一、样本合并:将多数类样本集d
″
与边界域进行合并,得到样本集mergeset。
[0099]
步骤二、初始化队列:随机从边界域b中选择一个样本x放入队列queue中,并从边界域b中删去此样本。由于本发明是利用密度的方法来确定边界样本,而算法刚开始不知道从哪个样本开始,这里选择从边界域b中随机选择一个样本开始。其中边界域b的样本均为大块金属玻璃bmg样本。选一个样本删除一个样本的原因是为了让边界域b中的所有样本都被选到。
[0100]
步骤三、取样本:取出队列queue中队首样本x
i
,并做出队列操作。
[0101]
步骤四、计算近邻:计算在集合mergeset中与样本x
i
的欧氏距离不大于邻域参数η
的样本并放入集合d
η
(x
i
)中。即,计算在集合mergeset中与样本x
i
的欧氏距离不大于领域参数η=40的样本并放入集合d
40
(x
i
)中。这里的η表示欧式距离,作用是得到在η=40范围内(即以该样本为中心,η=40的一个圆的范围)的近邻样本。其取值需要根据具体数据集来确定,一般是通过网格搜索的方法来确定最佳参数。在大块非晶合金材料数据集中,η=40集成分类算法取得最好效果。
[0102]
步骤五、近邻统计:统计集合d
η
(x
i
)(d
40
(x
i
))中样本个数n。
[0103]
步骤六、数量判断:如果n小于预定义的参数ω(其中ω表示在η=40范围内最少样本个数。η和ω的作用就是根据边界域的分布来找到其附近多数类,使得所选的多数类样本分布与边界域分布一致。其中ω的设定需要根据数据集来确定,一般ω∈[5,10]),则执行步骤七,否则进行下面步骤:
[0104]
步骤1、放入队列和集合:将集合d
η
(x
i
)中所有样本放入队列queue和tempset集合中。
[0105]
步骤2、删除集合:从集合mergeset删去集合d
η
(x
i
)的所有样本。
[0106]
步骤七、判断队列queue是否为空:如果不为空,则执行步骤三,否则执行步骤八。
[0107]
步骤八、判断边界域b是否为空:如果不为空,则执行步骤二,否则执行步骤九。
[0108]
步骤九、合并集合获得密度域m:将tempset集合中的多数类样本跟少数类样本集d
′
进行合并,得到最终的密度域m。
[0109]
具体的,步骤102所述检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集,具体包括:基于近邻计算方法确定所述第二材料数据集中的属于边界样本的样本数据,组成边界域;将所述边界域和所述第一材料数据集合并获得融合样本集;根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集。
[0110]
其中,所述基于近邻计算方法确定所述第二材料数据集中的属于边界样本的样本数据,组成边界域,具体包括:基于近邻计算方法,计算第二材料数据集中每个样本数据在所述样本数据集中近邻的样本数据,获得第二材料数据集中每个样本数据的近邻的样本数据(边界域构建中的(1));统计第二材料数据集中每个样本数据的近邻的样本数据中属于第一材料数据集的个数,获得第二材料数据集中每个样本数据的近邻统计个数(边界域构建中的(2));将第二材料数据集中近邻统计个数在预设范围内的样本数据作为边界样本,添加至所述边界域(边界域构建中的(2),预设范围为和m之间)。
[0111]
所述根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集,具体包括:获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除(b.密度域构建过程中的步骤二);获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除(b.密度域构建过程中的步骤三);基于近邻计算方法,获取待计算样本数据在融合样本集中的近邻的样本数据,添加至统计集合中(b.密度域构建过程中的步骤四);判断所述统计集合中近邻的样本数据的个数是否小于预设阈值,获得第一判断结果(b.密度域构建过程中的步骤五和六,所述预设阈值为ω);若所述第一判断结果表示否,则将统计集合中的所有近邻的样本数据添加至计算队列和所
述第三材料数据集,并将所述统计集合中的所有近邻的样本数据从所述融合样本集中删除(b.密度域构建过程中的步骤1和2);判断所述计算队列是否为空,获得第二判断结果;若所述第二判断结果为否,则返回步骤“获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除”;若所述第二判断结果为是,则判断所述边界域是否为空,获得第三判断结果(b.密度域构建过程中的步骤七);若所述第三判断结果表示否,则返回步骤“获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除”;若所述第三判断结果表示是,输出所述第三材料数据集(b.密度域构建过程中的步骤八和九)。
[0112]
步骤103,利用所述样本数据集训练第一材料分类模型,利用所述第三材料数据集训练第二材料分类模型。
[0113]
选择随机森林为集成学习模型,随机森林中总树量size=100,分配率p=0.5。size的设定没有固定要求,可以根据实际需求设定。分配率p根据实际需求选定,一般分配率p∈[0.4,0.6]。本发明中可将随机森林中的树分为两大块:用原始的样本数据集训练的树和用密度域训练的树。而p的作用就是分配这两大块中树的个数。
[0114]
用样本数据集d构建集成模型rf1,其中随机森林rf1的总树量为size
×
(1
‑
p)。
[0115]
用密度域m(第三材料数据集)构建集成模型rf2,其中随机森林rf2的总树量为size
×
p。
[0116]
步骤104,并行集成训练后的第一材料分类模型和第二材料分类模型,获得集成模型。将集成模型rf1和集成模型rf2进行合并,得到最终的集成学习模型rf。
[0117]
步骤105,利用所述集成模型进行材料性能的预测分类。
[0118]
输入待预测数据p,使用简单投票法(即每个弱分类器投票的权重相等),统计随机森林rf中各个弱分类器(即树)做出预测的类别,将统计数量最多的类别作为随机森林rf最终预测的结果。
[0119]
步骤103
‑
105,如图5所示。
[0120]
实施例2
[0121]
本发明还提供一种基于密度不平衡样本数据的材料性能预测系统,所述预测系统包括:
[0122]
样本数据集划分模块,用于根据样本的类别标签将样本数据集划分为不符合预期性能的第一材料数据集和符合预期性能的第二材料数据集;所述第一材料数据集中样本数据的数量大于第二材料数据集中样本数据的数量。
[0123]
边界样本检测模块,用于检测所述第一材料数据集和所述第二材料数据集中的属于边界样本的样本数据,组成第三材料数据集。
[0124]
所述边界样本检测模块,具体包括:第一边界样本检测子模块,用于基于近邻计算方法确定所述第二材料数据集中的属于边界样本的样本数据,组成边界域;数据集融合子模块,用于将所述边界域和所述第一材料数据集合并获得融合样本集;第二边界样本检测子模块,用于根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集。
[0125]
其中,所述第一边界样本检测子模块,具体包括:第一近邻的样本数据确定单元,用于基于近邻计算方法,计算第二材料数据集中每个样本数据在所述样本数据集中近邻的
样本数据,获得第二材料数据集中每个样本数据的近邻的样本数据;近邻统计个数获取单元,用于统计第二材料数据集中每个样本数据的近邻的样本数据中属于第一材料数据集的个数,获得第二材料数据集中每个样本数据的近邻统计个数;第一边界样本检测单元,用于将第二材料数据集中近邻统计个数在预设范围内的样本数据作为边界样本,添加至所述边界域。
[0126]
所述第二边界样本检测子模块,具体包括:计算队列初始化单元,用于获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除;待计算样本数据获取单元,用于获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除;第二近邻的样本数据,用于确定单元基于近邻计算方法,获取待计算样本数据在融合样本集中的近邻的样本数据,添加至统计集合中;第一判断单元,用于判断所述统计集合中近邻的样本数据的个数是否小于预设阈值,获得第一判断结果;第二边界样本检测单元,用于若所述第一判断结果表示否,则将统计集合中的所有近邻的样本数据添加至计算队列和所述第三材料数据集,并将所述统计集合中的所有近邻的样本数据从所述融合样本集中删除;第二判断单元,用于判断所述计算队列是否为空,获得第二判断结果;第一返回单元,用于若所述第二判断结果为否,则返回步骤“获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除”;第三判断单元,用于若所述第二判断结果为是,则判断所述边界域是否为空,获得第三判断结果;第二返回单元,用于若所述第三判断结果表示否,则返回步骤“获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除”;第三材料数据集输出单元,用于若所述第三判断结果表示是,输出所述第三材料数据集。
[0127]
模型训练模块,用于利用所述样本数据集训练第一材料分类模型,利用所述第三材料数据集训练第二材料分类模型。
[0128]
模型集成模块,用于并行集成训练后的第一材料分类模型和第二材料分类模型,获得集成模型。
[0129]
性能预测模块,用于利用所述集成模型进行材料性能的预测分类。
[0130]
实施例3
[0131]
本发明还提供一种边界样本确定方法,所述确定方法包括如下步骤:
[0132]
基于近邻计算方法确定第二材料数据集中的属于边界样本的样本数据,组成边界域。
[0133]
所述基于近邻计算方法确定第二材料数据集中的属于边界样本的样本数据,组成边界域,具体包括:基于近邻计算方法,计算第二材料数据集中每个样本数据在所述样本数据集中近邻的样本数据,获得第二材料数据集中每个样本数据的近邻的样本数据;统计第二材料数据集中每个样本数据的近邻的样本数据中属于第一材料数据集的个数,获得第二材料数据集中每个样本数据的近邻统计个数;将第二材料数据集中近邻统计个数在预设范围内的样本数据作为边界样本,添加至所述边界域。
[0134]
将所述边界域和第一材料数据集合并获得融合样本集;
[0135]
根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集。
[0136]
所述根据所述边界域,基于欧式距离计算方法确定所述融合样本集中的属于边界样本的样本数据,组成第三材料数据集,具体包括:获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除;获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除;基于近邻计算方法,获取待计算样本数据在融合样本集中的近邻的样本数据,添加至统计集合中;判断所述统计集合中近邻的样本数据的个数是否小于预设阈值,获得第一判断结果;若所述第一判断结果表示否,则将统计集合中的所有近邻的样本数据添加至计算队列和所述第三材料数据集,并将所述统计集合中的所有近邻的样本数据从所述融合样本集中删除;判断所述计算队列是否为空,获得第二判断结果;若所述第二判断结果为否,则返回步骤“获取所述计算队列中的第一个样本数据,作为待计算样本数据,并将所述待计算样本数据从所述计算队列中删除”;若所述第二判断结果为是,则判断所述边界域是否为空,获得第三判断结果;若所述第三判断结果表示否,则返回步骤“获取所述边界域中的最靠前的样本数据添加至计算队列中,并将已添加至计算队列中的所述样本数据从所述边界域中删除”;若所述第三判断结果表示是,输出所述第三材料数据集。
[0137]
根据本发明提供的具体实施例,本发明公开了以下技术效果:
[0138]
本发明公开了一种基于密度不平衡样本数据的材料性能预测方法,能够精准地定位到决策边界不清晰的样本(即边界样本),然后利用集成模型的特点,在原来模型的基础上集成根据边界样本构建的模型,提升了模型对少数类样本的分类预测准确率。
[0139]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
[0140]
本文中应用了具体个例对发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。