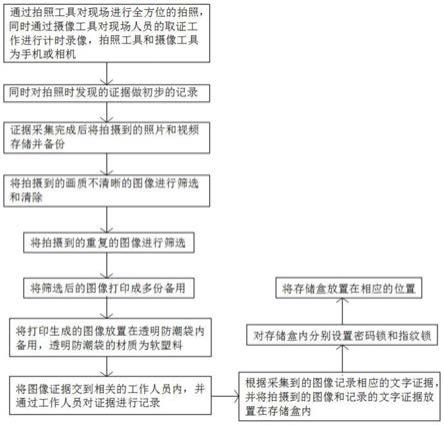
1.本发明属于脑电信号处理领域和人机交互领域,具体涉及一种考虑个体差异的跨模式脑电信号识别方法。
背景技术:
2.随着脑科学研究的发展,越来越多的脑机接口(brain computer interface,bci)应用得到了关注和研究。脑机接口是硬件和软件的组合,通过使用脑电波来控制外部设备,例如脑控机械臂。bci技术涉及到神经科学、人机交互、信息处理、模式识别等多个学科,通过对采集自人脑的生理信号进行特征提取与分类,识别出被试的真实想法,再将这些想法转换成不同的命令,从而实现人脑与外部环境的交互与控制。
3.捕获人脑的生理信号的最常见且高效的方法是采集头皮脑电信号(eeg),这是一种非侵入性方法,还具有许多优点,例如可移植性、客观可靠和高时间分辨率。尽管基于脑电信号的任务识别已取得丰富的研究成果,但在实际场景下的bci应用仍存在着问题。目前的研究大多着眼于单一被试内的脑电识别,但这种实验范式存在着较大的局限性,由于脑电信号模式在不同被试之间有所不同,当存在多个被试的情况时,已有的分类模型无法保证在其他新的被试上达到与已有被试相近的识别准确率。使用eeg进行bci应用主要面临的就是eeg个体差异问题,因此需要训练特定被试的分类器模型同时频繁地校准模型以保持令人满意的识别精度。
4.近年来,随着深度学习的发展,越来越多的研究中使用了深度神经网络模型,神经网络能够自动地学习有用的特征并构建非线性的复杂关系的模型,适用于脑电信号的建模。目前有两类深度学习算法被广泛地应用于解决个体差异性问题,一是基于深度特征分布相似化的方法:将深层特征的分布距离最小化以达到域迁移的效果;二是基于对抗网络的方法:通过加入一个对抗网络来调整特征提取网络提取到一些特征分布相似的任务特征。然而,上述的方法在训练模型的过程中均需要使用大量的未标记的新被试数据,导致在实际使用中耗费了大量时间以采集新被试的数据。
5.在bci应用中,不仅需要考虑个体差异性所带来的影响,同时需要考虑算法本身在实际场景下的实用性。因此,使用深度学习来开发一种高实用性的去除eeg个体差异的方法极具现实意义。
技术实现要素:
6.本发明的目的在于克服现有技术存在的不足,提供一种高实用性的去除eeg个体差异的方法。本发明通过对跨被试的脑电信号进行分析和特征提取,在模型训练过程中分离出背景特征以及任务特征,并在后续的网络模型中输入多种特征以增强模型的学习能力。同时通过计算被试间的背景特征的欧几里得距离,来获取不同被试之间的相似度,使用相似度更高的数据来训练模型,使得模型能够在新被试上达到更高的识别准确率。本发明所提供的方法只需要采集少量的新被试数据,提升了在bci应用中的实用性。
7.为达到上述目的,本发明所采用的技术方案如下:
8.一种考虑个体差异的跨模式脑电信号识别方法,具体包括步骤如下:
9.步骤(1)、脑电信号预处理:
[0010]1‑
1数据格式的统一
[0011]
根据采集信号时的电极位置,将通道维度的特征向量格式转化为2d矩阵格式,同时将每个通道的脑电信号划分为5个频段,最终得到大小为h
×
w
×
5的3d张量数据的脑电数据;其中h为2d矩阵的高,w为2d矩阵的宽。
[0012]
所述的5个频段为delta(1
‑
4hz)、theta(4
‑
8hz)、alpha(8
‑
14hz)、beta(14
‑
31hz)、gamma(31
‑
50hz)。
[0013]1‑
2数据分割及整理
[0014]
对步骤1
‑
1获得的脑电信号进行切片,以t为时间窗口进行滑窗操作,得到一系列大小为l
×
h
×
w
×
5的脑电信号片段,其中l为数据长度,l=t
×
w,w为采样频率;然后将上述切片后的脑电信号片段打上被试id标签以及任务类别标签,最终构建数据集;
[0015]
步骤2、搭建多分支网络(mbn),用以实现消除脑电信号的个体差异性。
[0016]
所述多分支网络模型包括主干网络,分别用于提取背景特征和任务特征的两个分支网络b1、b2;以预处理后的脑电信号作为输入,以任务类别标签作为输出;
[0017]
所述主干网络包括依次级联的四个串联的卷积层、最大池化层、第一全连接层、第一dropout层、第二全连接层、第二dropout层、第三全连接层;所述分支网络b1、b2采用相同结构,均包括四个串联的卷积层;主干网络和分支网络的前三层卷积层均采用将主干网络和分支网络的同一层卷积层输出的特征向量进行拼接后输入到主干网络的下一层卷积层,主干网络和分支网络的最后一层卷积层采用将主干网络和分支网络的同一层卷积层输出的特征向量进行拼接后输入到主干网络的最大池化层中。
[0018]
作为优选,主干网络和分支网络的四个串联的卷积层中均采用线性整流函数(relu)作为激活函数以及在卷积前对数据进行边缘填充,卷积核的移动步长为1,卷积核的参数分别为:64个5
×
5卷积核;128个4
×
4卷积核;256个4
×
4卷积核;64个1
×
1卷积核。
[0019]
作为优选,主干网络中最大池化层的核大小为2
×
2,移动步长为2。dropout层的参数均设置为0.5,以提升模型的泛化能力并增强模型的抗噪声能力。第一至第三全连接层的神经元个数分别为1024,512和n,其中n为特定任务的分类类别数。
[0020]
分支网络b1、b2训练阶段具体如下:
[0021]
1)构建两个分别用于分类被试id以及任务类别的分类器c1、c2,两个分类器结构相同;并利用数据集进行训练。
[0022]
每个分类器包括两路分支和相似度计算结果模块,每路分支包括依次级联的四个串联的卷积层,一个最大池化层以及一个全连接层,其中最大池化层的核大小为2
×
2,移动步长为2,全连接层的神经元个数为1024;两路分支输入分别为数据集中的脑电信号对,输出均输入至相似度计算结果模块;相似度计算结果模块通过公式(3)计算两路分支输出向量的特征距离,并根据公式(4)输出分类结果。
[0023]
在分类器c1中利用被试一致性检验进行训练,输入为数据集中的脑电信号对,输出为脑电信号对是否来自同一位被试。在分类器c1的训练阶段中,计算两个脑电信号样本输出向量的欧几里得距离,当该距离小于阈值时,则判断为来自同一被试的样本数据,反
之,则判断为来自不同被试的样本数据。
[0024]
在分类器c2中利用任务一致性检验进行训练,输入为数据集中的脑电信号对,输出为脑电信号对是否进行着同一类任务。在分类器c2的训练阶段中,计算两个脑电信号样本输出向量的欧几里得距离,当该距离小于阈值时,则判断为同一类任务,反之则判断为不同类任务。
[0025]
用于分类被试id的分类器c1中卷积层用于提取与被试相关的背景特征,用于分类任务类别的分类器c2中卷积层用于提取与识别任务相关的任务特征。训练分类器的相关函数如下所示:
[0026]
x
′1=b(x1)
ꢀꢀ
(1)
[0027]
x
′2=b(x2)
ꢀꢀ
(2)
[0028][0029][0030]
其中b(
·
)为分类器模型的卷积层部分,在被试一致性检验中,b为b1,在任务一致性检验中,b为b2。其中x1和x2代表脑电信号对,输入对应的分支提取特征后,输出特征向量x'1和x'2。其中d(
·
)为欧几里得距离计算公式,当所述的两个特征向量的欧几里得距离小于阈值时,则判断两个样本具有数据一致性,即label为1。
[0031]
2)将训练好的两个分类器中的分支部分去除最大池化层、全连接层,保留四个串联的卷积层,分别作为多分支网络模型中的两个分支网络,即分类器c1中四个串联的卷积层为分支网络b1,分类器c2中四个串联的卷积层为分支网络b2。
[0032]
3)在对跨被试数据的处理中,当部分被试与新被试之间的差异性过大并使用该部分被试数据训练模型后,很难再通过调整模型使其在新被试上有着良好的性能。因此在训练模型之前对训练样本进行筛选是重要的。本发明利用不同被试之间的背景特征对训练集中的数据进行筛选。由于提取背景特征的分支网络b1的训练模式和脑电信号的任务内容信息无关,本发明只需要采集少量的不带标签的新被试数据样本,从而尽可能地缩短了数据采集时间。具体操作如下:
[0033]
a)采集一位新被试的r个样本,与另一位已有被试的r个样本组成r个脑电信号对,并均输入至分类器c1中。
[0034]
b)分类器c1模型将每个脑电信号对映射到同一特征空间,并计算两个特征向量之间的欧几里得距离,最终将r个脑电信号对的输出结果取平均值作为两位被试之间的相似度。计算所有被试之间的相似度后获得被试间相似度矩阵其中k为被试个数。
[0035][0036]
其中i,j=1,2,
…
,k,代表被试id;表示第i位被试以及第j位被试的第r个脑电信号对的特征向量。
[0037]
c)根据被试相似度矩阵,删除与新被试差异性过大的被试数据样本(即第i位被试
作为测试集时,根据m
i*
删除前q个最大值所对应的被试数据样本),剩余数据样本作为训练集,输入至多分支网络模型进行训练。
[0038]
4)对多分支网络模型进行训练,以进行最终的脑电识别任务。将主干网络与分支网络的卷积层输出向量拼接,能够更好地结合背景特征以及任务特征,进一步提取性能更加优秀的特征以进行最终的识别任务。多分支网络的定义如下所示:
[0039]
y=f(x&x
′
&x
″
)=f(x&b1(x)&b2(x))
ꢀꢀ
(6)
[0040]
其中x和y分别代表主干网络模型f(
·
)的输入和输出,输入为脑电信号,输出为脑电信号所对应的任务,x'和x”分别代表脑电信号x输入到分支网络b1以及分支网络b2后所得到的背景特征以及任务特征,&代表向量拼接操作。相较于传统的单分支网络模型,在多分支网络模型中,卷积操作由原先的y=f(x)变为了y=f(x&b1(x)&b2(x)),在输入更多的特征的情况下,模型能够得到更好的训练。
[0041]
步骤3、利用训练好的多分支网络模型,实现跨模式脑电信号识别。
[0042]
本发明的另一个目的是提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述的方法。
[0043]
本发明的又一个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述的方法。
[0044]
本发明的有益效果是:
[0045]
1.本发明方法在多分支网络模型的训练阶段不需要收集新被试的数据来调整模型,提高了算法在实际bci应用中的实用性。
[0046]
2.本发明方法使用少量新被试数据对训练集样本进行了筛选,避免了部分差异性过大的被试样本对模型训练产生的负面提升。
[0047]
3.相较于已有方法,本发明所需要采集的新被试样本更少,减少了数据采集时间。
[0048]
4.在seed数据集的跨被试任务中,加入样本选择策略以及使用多分支网络模型给模型带来了性能提升。
附图说明
[0049]
图1为本发明统一脑电信号数据格式的示意图;
[0050]
图2为本发明中分类器c1、c2模型训练框架图;
[0051]
图3为本发明中样本选择的相关示意图,其中(a)为在同一特征空间中的被试样本分布示意图,虚线框中的圆圈代表新被试样本,实线表示距离最短(相似度最高)的样本对,虚线表示距离最大(相似度最低)的样本对;(b)为被试间相似度矩阵热力图。
[0052]
图4为本发明中多分支网络模型训练框架图;
[0053]
图5为本发明使用多分支网络以及进行样本选择后的准确率柱状图。
具体实施方式
[0054]
下面结合附图,对本发明基于个体脑电差异的跨模式脑电信号识别的方法做详细描述。
[0055]
针对跨模式脑电信号的特点,本发明提出一种多分支网络模型算法,并在模型训练前对训练集进行筛选。在本实施例中,包括以下步骤:
[0056]
步骤1、脑电信号预处理。
[0057]
本发明基于seed数据集进行了情感三分类的跨被试实验以验证算法的有效性。在seed数据集中共有15名被试参与实验,同时在每次实验中,播放15个电影片段以激发对应的情绪,并采用62通道的esi neuroscan system对脑电信号进行记录,采样频率为1000hz。为了减少存储空间以及计算量,去除了一些基本噪声后,将脑电信号数据降采样至200hz。
[0058]1‑
1数据格式的统一:在图1中展示了统一脑电信号的数据格式的过程,首先对62个通道的eeg数据进行带通滤波,将每个通道的信号划分为delta(1
‑
4hz)、theta(4
‑
8hz)、alpha(8
‑
14hz)、beta(14
‑
31hz)、gamma(31
‑
50hz),接着将通道维度的数据根据实际采集脑电信号的电极分布组织成一个大小为17
×
19的2d矩阵。最终在通道维度以及频段维度上,脑电数据被组织为一个大小为17
×
19
×
5的3d张量的数据格式。
[0059]1‑
2数据分割及整理:将步骤1
‑
1获得的脑电信号数据进行切片处理,使用1秒作为时间窗口进行滑窗操作,最终得到一系列大小为200
×
17
×
19
×
5的样本。完成数据分割后,将15名被试中的13名被试的数据作为训练集,将剩余2名被试的数据作为测试集。
[0060]
步骤2、搭建多分支网络(mbn)模型架构:多分支网络模型包括一个主干网络,两个相同结构的分支网络b1、b2:两个分支网络的网络架构相同,通过不同的约束来分别提取背景特征和任务特征;分支网络提取到的特征与主干网络的特征进行拼接,用于最终的任务识别。
[0061]2‑
1分类器c1、c2模型的网络架构如图2所示,通过不同的任务约束两个分类器模型进行训练。在训练集中存在着同一脑电信号对在不同分类器中的标签相反的情况,以保证两个分类器模型能够学习到不同的特征:在训练分类器c1的训练集中,样本对存在着来自同一电影片段的不同被试数据,其标签为0;以及来自不同电影片段的同一被试数据,其标签为1。在训练分类器c2的训练集中,样本对存在着来自同一电影片段的不同被试数据,其标签为1;以及来自不同电影片段的同一被试数据,其标签为0。在分类器模型中,输入脑电信号对,并在全连接层输出两个1024维的特征向量。最终计算两个特征向量的欧几里得距离作为脑电信号对的被试/任务相似程度,当该距离小于阈值时,则判断标签为1,反之则判断标签为0。
[0062]2‑
2当上述的两个分类器的损失函数收敛时,分类器c1中的分支网络b1模型在卷积层提取到的特征更多的是与个人有关的背景特征;分类器c2中的分支网络b2模型在卷积层提取到的特征更多的是与情感有关的任务特征。训练结束后,保存两个分支网络b1、b2模型的参数以供后续的多分支网络训练调用。
[0063]2‑
3训练样本选择:为了避免部分与新被试差异性过大的数据对模型训练造成的负提升,在多分支网络模型训练之前,对训练样本进行筛选。
[0064]2‑3‑
1采集少量的新被试数据。在数据采集的过程中,不需要要求被试进行多种任务,同时该部分数据不需要带有任务标签。将新被试样本与已有被试样本组成脑电信号对输入至分类器c1中。在seed数据集中,选取每段电影片段的前60秒的脑电信号数据作为上述采集所需的数据,经过数据预处理后,新被试与一位已有被试之间共有60个脑电信号对。
[0065]2‑3‑
2计算脑电信号对在同一特征空间中的欧几里得距离,并计算所有脑电信号对的平均值作为两个被试间的相似度,最终获得15名被试之间的相似度矩阵。图3.a为样本在同一特征空间中的示意图,图3.b为被试间相似度矩阵热力图,其中每位被试(对应图3.b
中的每一行)与其他被试的相似度由对应的分类器c1模型得出,15个被试由15个不同的模型计算与他人的相似度。
[0066]2‑3‑
3根据被试间相似度矩阵对训练集中的数据进行筛选,删除3名与新被试差异性最大的被试数据,将剩余的10名被试的数据作为训练集,输入至多分支网络模型进行训练。
[0067]2‑
4在多分支网络模型中,将主干网络和分支网络在同一层卷积输出的特征向量进行拼接,并输入到主干网络的下一层卷积中进行运算。相较于单分支网络模型,多分支网络模型的卷积操作由y=f(x)变为了y=f(x&b1(x)&b2(x))。样本x同时输入到三个网络中进行运算,分别从分支网络b1中提取背景特征以及从分支网络b2提取任务特征,最终与主干网络输出的特征值拼接,进行情感脑电信号识别的模型训练。多分支网络架构如图4所示。
[0068]
步骤3、在seed数据集上对本发明进行性能评估的结果:使用训练好的多分支网络模型对测试集中的样本预测标签,计算15位被试在情感脑电信号识别上的三分类准确率。
[0069]
本实施例图5对比了单分支网络模型、多分支网络模型以及经过样本选择后的多分支网络模型在跨被试情感脑电识别上的三分类准确率。其中多分支网络模型的平均准确率达到了79.57%,相较于单分支网络模型提升了20.89%,说明加入背景特征以及任务特征对模型共同进行训练后,能够更有效地捕获到不同被试之间的差异性并提升模型性能。在原有的13名被试数据上去除了3名与新被试数据差异过大的数据并使用剩余10名被试的数据对模型进行训练时,在大多数被试上,模型有着更高的分类准确率,其平均准确率达到82.47%,相较于没有进行样本选择的模型提升了2.90%。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。