1.本发明属于数据仓库领域,特别涉及教育行业数据整合方法、数据仓库系统、设备及介质。
背景技术:
2.当下很多学校业务系统繁多,由不同厂商开发,造成字段和数据定义的不统一,互相之间很难关联,存在数据孤岛的现象,因此需要发明一种教育行业数据整合方法,建立数据仓库系统,从而打破数据孤岛的现象。
技术实现要素:
3.本发明的第一个目的是针对现有技术中存在的上述问题,提供了一种教育行业数据整合方法;本发明的第二个目的是提供一种数据仓库系统;本发明的第三个目的是提供一种电子设备,本发明的第四个目的是提供一种计算机可读存储介质。
4.本发明的第一个目的可通过下列技术方案来实现:一种教育行业数据整合方法,其特征在于,包括如下步骤:
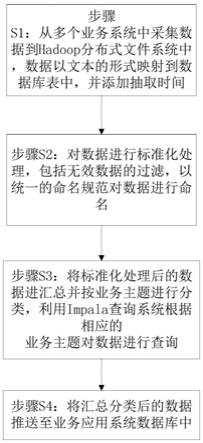
5.步骤s1:从多个业务系统中采集数据到hadoop分布式文件系统中,数据以文本的形式映射到数据库表中,并添加抽取时间;
6.步骤s2:对数据进行标准化处理,包括无效数据的过滤,以统一的命名规范对数据进行命名;
7.步骤s3:将标准化处理后的数据进汇总并按业务主题进行分类,利用impala查询系统根据相应的业务主题对数据进行查询;
8.步骤s4:将汇总分类后的数据推送至业务应用系统数据库中。
9.在上述教育行业数据整合方法中,步骤s1中,利用sqoop从多个业务系统中采集异构数据源到hadoop分布式文件系统中。
10.在上述教育行业数据整合方法中,步骤s1中,利用hive将数据以文本的形式映射到数据库表中,并添加抽取时间。
11.在上述教育行业数据整合方法中,步骤s2中,利用mapreduce计算引擎对数据进行标准化处理。
12.本发明的第二个目的可通过下列技术方案来实现:一种数据仓库系统,其特征在于,包括数据仓库、hadoop分布式文件系统、hive离线数据仓库工具、mapreduce计算引擎、etl流程、impala查询系统、sqoop数据传递工具。
13.在上述一种数据仓库系统中,所述数据仓库包括:
14.数据操作层:对接业务系统抽取数据,数据以文本的形式映射到数据库表中,并添加抽取时间;
15.数据明细层:对数据操作层的数据、字段进行标准化处理;
16.数据汇总层:将标准化处理后的数据进汇总并按业务主题进行分类;
17.数据应用层:将汇总分类后的数据推送至业务应用系统数据库中。
18.本发明第三个目的可通过下列技术方案来实现:一种电子设备,其特征在于,包括:
19.显示器;
20.一个或多个处理器;
21.存储器;以及
22.一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述程序包括用于执行上述教育行业数据整合方法。
23.本发明的第三个目的可通过下列技术方案来实现:一种计算机可读存储介质,其特征在于,存储有与具有显示器的电子装置结合使用的计算机程序,所述计算机程序可被处理器执行上述教育行业数据整合方法。
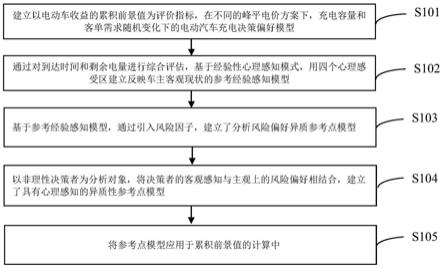
24.与现有技术相比,本发明具有以下优点:
25.1、本发明通过数据仓库系统对学校业务系统中的数据进行整合,从而打破数据孤岛现象,便于第三方利用impala查询系统进行数据查询。
附图说明
26.图1是本发明的流程示意图。
具体实施方式
27.以下是本发明的具体实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
28.如图1所示,本发明第一个实施例提供一种教育行业数据整合方法,包括如下步骤:
29.步骤s1:从多个业务系统中采集数据到hadoop分布式文件系统中,数据以文本的形式映射到数据库表中,并添加抽取时间;
30.学校的业务系统有多个,包括学工系统、超星系统、通卡系统、收费系统等,这些业务系统可以采用关系型数据库管理系统,通过接口对接这些系统,然后利用sqoop数据传递工具将业务系统中的数据导入hadoop分布式文件系统中。sqoop采集异构数据源,sqoop专为大数据批量传输设计。
31.然后利用hive离线数据仓库工具将数据以文本的形式映射为一张数据库表,并且添加抽取时间,目的是为了便于后续的按照抽取时间进行数据的查询,从而便于人员查询、分析数据,若出现故障,则该时间的数据可能缺失,人员根据数据库表能够发现具体是哪一个时间段的数据有缺失。
32.步骤s2:对数据进行标准化处理,包括无效数据的过滤,以统一的命名规范对数据进行命名;
33.利用mapreduce计算引擎对数据进行标准化处理。包括无效数据的过滤和以统一的命名规范对数据进行命名等。
34.将无效数据进行过滤,从而进行数据优化,然后数据的命名方式按照同一的命名规则,从而对数据进行标准化处理。
35.步骤s3:将标准化处理后的数据进汇总并按业务主题进行分类,利用impala查询系统根据相应的业务主题对数据进行查询。
36.对标准化处理后的数据进汇总分类,存储在数据仓库中,按照业务主题进行分类,业务主题可以为“收费业务”、“学工管理业务”等,第三方利用impala查询系统能根据相应的业务主题对数据进行查询。第三方可以是管理人员等,例如管理人员需要对学校的多个业务系统进行数据的查询,可以使用impala查询系统,选择相应的业务主题,然后在数据仓库系统中进行查询。
37.步骤s4:将汇总分类后的数据推送至业务应用系统数据库中。
38.例如将汇总的数据推送到app上等,做一些数据的推送。
39.本发明第二个实施例提供一种数据仓库系统,包括数据仓库、hadoop分布式文件系统、hive离线数据仓库工具、mapreduce计算引擎、etl流程、impala查询系统、sqoop数据传递工具。所述数据仓库包括:
40.数据操作层:对接业务系统抽取数据,数据以文本的形式映射到数据库表中,并添加抽取时间;
41.数据明细层:对数据操作层的数据、字段进行标准化处理;
42.数据汇总层:将标准化处理后的数据进汇总并按业务主题进行分类;
43.数据应用层:将汇总分类后的数据推送至业务应用系统数据库中。
44.在数据操作层中,对接业务系统,然后利用sqoop数据传递工具从业务系统中抽取数据到hadoop分布式文件系统中,hive离线数据仓库工具将数据以文本的形式映射到数据库表中,同时添加抽取时间。
45.在数据明细层中,利用mapreduce计算引擎对数据操作层的数据、字段进行标准化处理,包括无效数据的过滤和以统一的命名规范对数据进行命名等。
46.在数据汇总层中,将标准化处理后的数据进汇总并按业务主题进行分类,第三方可以利用impala查询系统根据相应的业务主题对数据进行查询。
47.在数据应用层中,将汇总分类后的数据推送至业务应用系统数据库中。
48.数据仓库从各数据源(即业务系统)获取数据及在数据仓库内的数据转换和流动都可以认为是etl(抽取extra,转化transfer,装载load)的过程,etl是数据仓库的流水线。
49.对数据仓库进行分层管理,将复杂逻辑简单化。
50.本发明第三个实施例提供一种电子设备,包括:
51.显示器;
52.一个或多个处理器;
53.存储器;以及
54.一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述程序包括用于执行上述教育行业数据整合方法。
55.本发明的第四个实施例提供一种计算机可读存储介质,存储有与具有显示器的电子装置结合使用的计算机程序,所述计算机程序可被处理器执行上述教育行业数据整合方法。
56.本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替
代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
57.尽管本文较多地使用了大量术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。