基于分段线性拟合hi及lstm的滚动轴承rul预测方法
技术领域
1.本发明属于滚动轴承寿命预测技术领域,更为具体地讲,涉及一种基于分段线性拟合hi及lstm的滚动轴承rul预测方法。
背景技术:
2.在目前旋转机械的所有关键组件中,滚动轴承一直是研究的重要对象之一。一方面由于滚动轴承使用广泛,在旋转机械设备应用中有着不可替代的作用;另一方面是由于滚动轴承相较于其他的零部件更易失效。由于滚动轴承的服役环境和工作条件的复杂性和不确定性、疲劳损伤发展的随机性和失效模式的多样性,导致滚动轴承的最大使用寿命有较大的离散性,并且滚动轴承的定期维护经常导致“维护不足”和“过度维护”的问题。而滚动轴承的rul(remaining useful life,剩余使用寿命)预测可以最大限度的延长轴承的使用寿命并降低维护成本,因此对滚动轴承的rul预测的研究一直是该领域研究的重点。
3.目前已有的关于旋转机械的rul预测的研究方法大致可以分为基于模型和基于数据驱动的预测方法两大类。基于模型的预测方法通过建立物理或数学模型来描述系统或设备的退化趋势,此方法要求大量的物理机理或经验知识,但是面对现代结构复杂的机械设备系统和多变的服役环境很难建立有效的失效模型,因此基于模型的预测方法的应用有限。基于数据驱动的rul预测方法没有上述方面的要求,对设备的退化过程建模一般只需要设备运行过程中的采集和监测的数据。在数据驱动的方法主要分为统计模型和人工智能两大类。神经网络等人工智能方法是近年来针对各种序列分类和预测问题的最先进的模型之一,神经网络方法以其建模优势和极强的非线性处理能力,逐渐成为主流研究方法。同时,在当今大数据时代下,在工程实际应用中,现有的基于神经网络的寿命预测技术存在模型输入样本量太大、对退化期的样本定位模糊以及在多工况和多失效模式下的寿命预测的精度较低等问题,需要研究解决。
技术实现要素:
4.本发明的目的在于克服现有技术的不足,提供一种基于分段线性拟合hi及lstm的滚动轴承rul预测方法,对hi曲线采用bup时间序列分割算法进行分段得到退化期hi曲线,采用lstm作为rul预测模型,将退化期hi曲线作为预测模型的输入,实现对滚动轴承的rul预测,提高rul的预测准确率和稳健性。
5.为实现上述发明目的,本发明基于分段线性拟合hi及lstm的滚动轴承rul预测方法包括以下步骤:
6.s1:根据实际需要获取预设工况下若干滚动轴承的特征数据序列,根据特征数据序列绘制各个滚动轴承对应的hi曲线,同时获取该hi曲线对应的滚动轴承剩余寿命序列,其中每个值即为对应时刻该滚动轴承的rul值;
7.s2:对于每个滚动轴承的hi曲线,分别确定该hi曲线使用bup时间序列分割算法进行健康状态划分的最优分段数,具体方法为:
8.s2.1:根据实际情况设置k个备选分段数m
k
,其中k=1,2,
…
,k,分别以每个备选分段数作为bup时间序列分割算法的循环迭代停止条件,使用bup时间序列分割算法对hi曲线对应的特征数据序列进行健康状态划分,得到m
k
个分段特征数据序列;
9.s2.2:将备选分段数m
k
对应的每个分段特征数据序列分别作为一个数据类别,计算得到聚类评价指标ch
k
;对于m
k
个分段特征数据序列,计算每个分段特征数据序列的均方根rms
k,m
,m=1,2,
…
,m
k
,然后采用以下公式计算得到拟合评价指标cost
k
:
[0010][0011]
s2.3:从k个备选分段数m
k
中筛选出聚类评价指标ch
k
最大的备选分段数
[0012]
s2.4:判断备选分段数对应的拟合评价指标是否最小,如果是,进入步骤s2.7,否则进入步骤s2.5;
[0013]
s2.5:从k个备选分段数m
k
中筛选出聚类评价指标ch
k
次最大的备选分段数m
k
′
;
[0014]
s2.6:判断是否如果是,进入步骤s2.7,否则进入步骤s2.8;
[0015]
s2.7:将分段数作为最优分段数;
[0016]
s2.8:将分段数m
k
′
作为最优分段数;
[0017]
s3:将步骤s2得到的最优分段数作为bup时间序列分割算法的循环迭代停止条件,使用bup分割算法对hi曲线进行健康状态划分,得到分段线性拟合后的hi曲线;
[0018]
s4:对于每个滚动轴承分段线性拟合后的hi曲线,将每两个健康状态之间的分界点作为健康状态转折点,并将第一个健康状态转折点作为初始故障发生点,以初始故障发生点区分滚动轴承的健康期与退化期,初始故障发生点之前为健康期,之后为退化期;
[0019]
s5:对于每个滚动轴承分段线性拟合后的hi曲线分别提取出退化期hi曲线,并从该hi曲线对应的滚动轴承剩余寿命序列提取出退化期hi曲线对应的退化期剩余寿命序列,分别对退化期hi曲线和退化期剩余寿命序列进行归一化处理,得到归一化退化期hi曲线和归一化退化期剩余寿命序列;
[0020]
s6:采用长短时记忆网络作为滚动轴承的rul预测模型,将步骤s5中的归一化退化期hi曲线作为输入,将归一化退化期剩余寿命序列作为标签,对rul预测模型进行训练;
[0021]
s7:对于预设工况下的某个滚动轴承,获取其到当前时刻的特征数据序列,绘制对应的hi曲线,采用步骤s2中的相同方法确定其最优分段数,采用步骤s3中的相同方法得到分段线性拟合后的hi曲线,采用步骤s4中的相同方法确定退化期,然后从该滚动轴承分段线性拟合后的hi曲线分别提取出退化期hi曲线并进行归一化,得到归一化退化期hi曲线,将该归一化退化期hi曲线输入步骤s6训练好的rul预测模型中,得到预测的剩余寿命序列。
[0022]
本发明基于分段线性拟合hi及lstm的滚动轴承rul预测方法,获取预设工况下若干滚动轴承的特征数据序列,绘制对应的hi曲线并获取剩余寿命序列,基于聚类评价指标和拟合评价指标筛选出每个滚动轴承采用bup时间序列分割算法进行分段的最优分段数,对hi曲线进行分段并提取出退化期hi曲线以及退化期剩余寿命序列,进行归一化得到归一化退化期hi曲线和归一化退化期剩余寿命序列,采用长短时记忆网络作为rul预测模型,将
归一化退化期hi曲线作为输入,将归一化退化期剩余寿命序列作为标签,对rul预测模型进行训练,对于预设工况下的某个滚动轴承绘制hi曲线,采用相同方法得到归一化退化期hi曲线,将其输入rul预测模型得到预测的剩余寿命序列。
[0023]
本发明具有以下有益效果:
[0024]
1)本发明利用bup时间序列分割算法对全寿命周期的hi曲线进行了健康状态划分,识别出了初始故障发生点,仅将初始故障发生点之后的退化期hi曲线用来预测rul,一方面避免了rul预测模型的过大输入样本量带来的较高的硬件要求和训练负担,另一方面还优化了rul预测模型的输入,提高了预测结果的准确度和稳健性
[0025]
2)本发明提出的基于分段线性拟合hi及lstm的滚动轴承rul预测方法具有预测模型的结构简单、对硬件资源的要求低,并且经实验证明本发明可以有效提高在多工况和多失效模型下的滚动轴承的rul预测的准确度和稳健度。
附图说明
[0026]
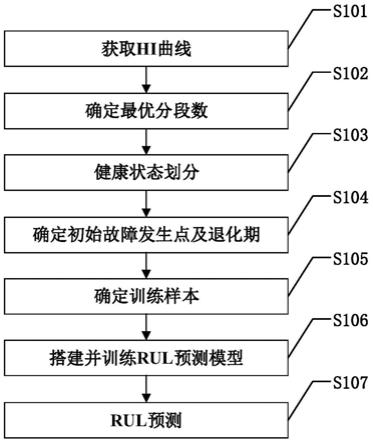
图1是本发明基于分段线性拟合hi及lstm的滚动轴承rul预测方法的具体实施方式流程图;
[0027]
图2是本发明中确定最优分段数的流程图;
[0028]
图3是本实施例中滚动轴承的hi曲线图;
[0029]
图4是本实施例中每个滚动轴承的健康状态的划分结果图;
[0030]
图5是本实施例中测试集轴承bearing1_5的预测标签和真实标签之间的对比图;
[0031]
图6是本实施例中测试集轴承bearing2_5的预测标签和真实标签之间的对比图;
[0032]
图7是本实施例中测试集轴承bearing3_5的预测标签和真实标签之间的对比图;
[0033]
图8是本实施例中本发明与对比方法的20次预测结果的rmse对比图;
[0034]
图9是本实施例中本发明与对比方法的20次预测结果的score对比图。
具体实施方式
[0035]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0036]
实施例
[0037]
图1是本发明基于分段线性拟合hi及lstm的滚动轴承rul预测方法的具体实施方式流程图。如图1所示,本发明基于分段线性拟合hi及lstm的滚动轴承rul预测方法的具体步骤包括:
[0038]
s101:获取hi曲线:
[0039]
根据实际需要获取预设工况下若干滚动轴承的特征数据序列,根据特征数据序列绘制各个滚动轴承对应的hi(健康指标)曲线,同时获取该hi曲线对应的滚动轴承剩余寿命序列,其中每个值即为对应时刻该滚动轴承的rul值。
[0040]
s102:确定最优分段数:
[0041]
对于每个滚动轴承的hi曲线,分别确定该hi曲线使用bup时间序列分割算法进行健康状态划分的最优分段数。图2是本发明中确定最优分段数的流程图。如图2所示,本发明
中确定最优分段数的具体步骤包括:
[0042]
s201:获取备选分段数的分段结果:
[0043]
根据实际情况设置k个备选分段数m
k
,其中k=1,2,
…
,k,分别以每个备选分段数作为bup时间序列分割算法的循环迭代停止条件,使用bup时间序列分割算法对hi曲线对应的特征数据序列进行健康状态划分,得到m
k
个分段特征数据序列。bup时间序列分割算法的具体原理的步骤可以参见文献“e.keogh,s.chu,d.hart,et al.segmenting time series:a survey and novel approach[m].singapore:data mining in time series databases,2004,1
‑
21”,本实施例中对其具体算法简述如下:
[0044]
记用于绘制hi曲线的特征数据序列为s,序列长度为n,首先创建序列s的n/2个分段(seg0,seg1,
…
seg
n/2
‑1)来近似该长度为n的特征数据序列s,将此n/2个分段作为时间序列s的初始最佳近似,对每个相邻分段对(seg
i
,seg
i 1
)使用最小二乘方法进行拟合合并,i=0,1,
…
,n/2
‑
2,并计算对应的合并代价,合并代价为合并前的相邻段对与合并后的拟合曲线之间的均方误差(mean square error,mse);
[0045]
在迭代过程中,当一对合并代价最小的相邻分段(seg
minind
,seg
minind 1
)合并时,需要进行以下几步操作:
[0046]
步骤一:记录保存临时合并代价cost(minind);
[0047]
步骤二:将合并代价最小的相邻分段对(seg
minind
,seg
minind 1
)合并到新的段snew中;
[0048]
步骤三:从分段集合中删除相邻合并段(seg
minind
‑1,seg
minind
)、(seg
minind 1
,seg
minind 2
)的合并代价merge_cost(minind)、merge_cost(minind 1),将步骤一中保存的临时合并代价cost(minind)添加至合并代价merge_cost(minind)中;
[0049]
步骤四:重新计算snew与其左邻居s
minind
‑1的合并成本;
[0050]
步骤五:重新计算snew与其右邻居s
minind 2
的合并成本;
[0051]
当分段数达到预设的备选分段数时,循环迭代停止之后,得到分段结果。
[0052]
结合一些学者的研究和大多数滚动轴承的实际退化过程,本实施例中将滚动轴承的退化过程中经历的健康状态的阶段个数限定在2
‑
4范围内,即每个滚动轴承的备选分段数为2、3、4;。
[0053]
s202:计算分段结果评价指标:
[0054]
对于备选分段数m
k
的分段特征数据序列,计算其聚类评价指标ch
k
和拟合评价指标cost
k
。
[0055]
聚类评价指标ch的全称为calinski
‑
harabaz,是一种无监督聚类评价指标。类别内部数据的协方差越小且类别之间的协方差越大ch越高,即ch分数越高说明聚类质量越好。本发明中,将备选分段数m
k
对应的每个分段特征数据序列作为一个数据类别,计算得到聚类评价指标ch
k
,本实施例中聚类评价指标的计算公式如下:
[0056][0057]
其中,tr()表示求取矩阵的迹,b
k
表示类别之间的协方差矩阵,w
k
表示类别内部数据的协方差矩阵。
[0058]
拟合评价指标cost
k
的计算方法如下:对于m
k
个分段特征数据序列,计算每个分段
特征数据序列的均方根rms
k,m
,m=1,2,
…
,m
k
,然后采用以下公式计算得到拟合评价指标cost
k
:
[0059][0060]
s203:筛选最大聚类评价指标的备选分段数:
[0061]
从k个备选分段数m
k
中筛选出聚类评价指标ch
k
最大的备选分段数
[0062]
s204:判断备选分段数对应的拟合评价指标是否最小,如果是,进入步骤s207,否则进入步骤s205。
[0063]
s205:筛选次最大聚类评价指标的备选分段数:
[0064]
从k个备选分段数m
k
中筛选出聚类评价指标ch
k
次最大的备选分段数m
k
′
。
[0065]
s206:判断是否如果是,进入步骤s207,否则进入步骤s208。
[0066]
s207:将分段数作为最优分段数。
[0067]
s208:将分段数m
k
′
作为最优分段数。
[0068]
s103:健康状态划分:
[0069]
将步骤s102得到的最优分段数作为bup时间序列分割算法的循环迭代停止条件,使用bup分割算法对hi曲线进行健康状态划分,得到分段线性拟合后的hi曲线。
[0070]
s104:确定初始故障发生点及退化期:
[0071]
对于每个滚动轴承分段线性拟合后的hi曲线,将每两个健康状态之间的分界点作为健康状态转折点,并将第一个健康状态转折点作为初始故障发生点,以初始故障发生点区分滚动轴承的健康期与退化期,初始故障发生点之前为健康期,之后为退化期。
[0072]
s105:确定训练样本:
[0073]
对于每个滚动轴承分段线性拟合后的hi曲线分别提取出退化期hi曲线,并从该hi曲线对应的滚动轴承剩余寿命序列提取出退化期hi曲线对应的退化期剩余寿命序列,分别对退化期hi曲线和退化期剩余寿命序列进行归一化处理,得到归一化退化期hi曲线和归一化退化期剩余寿命序列。
[0074]
退化期hi曲线的归一化采用最大最小归一化,退化期剩余寿命序列归一化采用每个时刻的rul值除以该滚动轴承的最大寿命。
[0075]
s106:搭建并训练rul预测模型:
[0076]
采用长短时记忆网络(lstm)作为滚动轴承的rul预测模型,将步骤s105中的归一化退化期hi曲线作为输入,将归一化退化期剩余寿命序列作为标签,对rul预测模型进行训练。
[0077]
s107:rul预测:
[0078]
对于预设工况下的某个滚动轴承,获取其到当前时刻的特征数据序列,绘制对应的hi曲线,采用步骤s102中的相同方法确定其最优分段数,采用步骤s103中的相同方法得到分段线性拟合后的hi曲线,采用步骤s104中的相同方法确定退化期,然后从该滚动轴承分段线性拟合后的hi曲线分别提取出退化期hi曲线并进行归一化,得到归一化退化期hi曲
线,将该归一化退化期hi曲线输入步骤s106训练好的rul预测模型中,得到预测的剩余寿命序列。
[0079]
为了更好地说明本发明的技术方案和技术效果,采用一个具体实例对本发明的工作流程和技术效果进行分析说明。轴承故障是旋转机械中的一种典型故障,因此本实施例采用西安交通大学轴承数据集xjtu
‑
sy的轴承加速全寿命振动信号数据进行实验测试。
[0080]
本实施例中使用的西安交通大学的轴承加速寿命试验共设计了3类工况,在每一种工况下对5个滚动轴承进行加速寿命测试,表1是本实施列中基于西安交通大学的轴承数据的具体试验工况。
[0081]
工况编号工况一工况二工况三转速(r/min)210022502400径向力(kn)121110
[0082]
表1
[0083]
本实施例中振动加速度信号数据集通过单向加速度传感器进行采集,采样频率为25.6khz,采样间隔为1min,每次的采样时长为1.28s。包含了3种工况下的15个滚动轴承的全周期寿命振动信号,且明确标注了各失效轴承的样本总数、基本额定寿命、实际寿命以及故障位置等信息。
[0084]
将15个滚动轴承的水平振动加速度数据进行特征提取、特征优选后得到的优选特征进行特征融合,根据融合后的特征数据序列得到各自的hi曲线。图3是本实施例中滚动轴承的hi曲线图。
[0085]
对每个滚动轴承的hi曲线经过最优分段数的选择算法确定健康状态的最佳划分个数。表2是每个滚动轴承的健康状态最佳的划分个数。
[0086][0087]
表2
[0088]
将表2中每个滚动轴承的健康状态的最佳划分个数作为bup时间序列分割算法的停止条件,对各个滚动轴承的hi曲线进行健康状态划分,并保存每条hi曲线的分段线性拟合数据。图4是本实施例中每个滚动轴承的健康状态的划分结果图。
[0089]
将第一个健康状态转折点作为初始故障发生点,则可以确定本实施例中每个滚动轴承的初始故障发生点。表3是每个滚动轴承的初始故障发生点。初始故障发生点之后的hi曲线即为退化期hi曲线。
[0090][0091]
表3
[0092]
将处于退化期所有hi曲线的分段线性拟合数据作为rul预测模型的输入样本,分为训练样本集和测试样本集。本实施例选取每种工况下的前4个滚动轴承作为rul预测模型的训练集样本,选取每种工况下的最后一个滚动轴承作为rul预测模型的测试集样本。表4是本实施例划分后的训练集和测试集的具体情况。
[0093][0094]
表4
[0095]
由于lstm在处理长时间序列方面的优越性,利用lstm搭建滚动轴承的rul预测模型。考虑到本实施例中处于退化期的hi曲线的训练样本量较少,为了避免过拟合,本实施例搭建了一个结构较为简单的lstm预测模型,即隐藏层的层数和各隐藏层的节点数都较少的lstm预测模型。表5是lstm预测模型的超参数。本实施例采用的lstm预测模型结构共三层,其中包括一个lstm层,两个dense层,每一层的节点数分别为32
‑8‑
1,迭代次数取300,损失函数为mse,优化器为adam。
[0096]
参数编号参数名称参数值1输入节点数32隐藏单元节点数32
‑
83激活函数
‘
relu
’‑‘
relu
’‑‘
linear’4输出节点数15批尺寸646迭代次数3007优化器adam8损失函数mse
[0097]
表5
[0098]
利用构建好lstm预测模型对表4中训练集的12个滚动轴承的样本特征及标签完成迭代训练。然后将表4中测试集的3个滚动轴承的hi曲线的分段线性拟合数据送入训练好的lstm预测模型进行前向传播,得到各个测试集轴承的rul预测结果。最后与各测试集轴承真实的rul标签进行对比以评估搭建的lstm预测模型的能力的强弱。图5是本实施例中测试集轴承bearing1_5的预测标签和真实标签之间的对比图。图6是本实施例中测试集轴承bearing2_5的预测标签和真实标签之间的对比图。图7是本实施例中测试集轴承bearing3_5的预测标签和真实标签之间的对比图。从图5、图6和图7可以看到,用来测试的3个滚动轴承的预测趋势均能描述并跟随轴承真实变化的退化趋势,预测的rul曲线与真实rul曲线具有较高的吻合程度,说明lstm预测模型对滚动轴承的rul预测效果较好。由此说明本发明基于lstm和分段线性拟合hi的rul预测模型能够适用于不同工况、不同退化趋势和不同失效模式下的滚动轴承的rul预测。
[0099]
为了验证本发明提出的将hi曲线的分段线性拟合数据作为lstm预测模型的输入的优越性,将其预测结果与原始的hi曲线、振动信号提取的均方根(rms)特征曲线作为输入的预测结果进行对比。为了避免单次实验结果的偶然性和探究不同输入在多次实验表现出的准确度和稳定度,本实施例共重复了20次相同的实验。然后分别计算了三种不同输入下的20次预测结果的评估指标:均方根误差rmse和打分函数score。
[0100]
图8是本实施例中本发明与对比方法的20次预测结果的rmse对比图。图9是本实施例中本发明与对比方法的20次预测结果的score对比图。rmse值和score值均为3个滚动轴承的rmse和score之和。图8和图9的结果表明,就预测稳定度而言,hi曲线的分段线性拟合数据在20次重复实验中表现出来的预测稳定度较好,同时rmse和score评估指标也比其他两种输入更小,说明预测误差更小,即预测准确度更好。因此,综合预测准确度和预测稳健性考虑,本发明采用的hi曲线的分段线性拟合数据作为输入时预测得到的rul的准确度和稳定度均更高。
[0101]
表6是三种不同输入下的20次平均预测评估指标对比表。分别对比了3个滚动轴承的20次实验的平均rmse指标和平均score指标的得分,并计算了3个轴承rmse指标和score得分的总和。
[0102][0103]
表6
[0104]
表6结果表明,采用原始hi数据和分段线性拟合数据作为预测模型的输入,均比直
接使用单个特征rms作为输入所获得的预测误差更低,说明通过特征融合构建的hi相对于单个特征可以提升rul的预测效果。另外也可以看到,采用分段线性拟合的hi数据作为输入相比于原始hi数据作为输入,所获得的rmse和score评估指标的总计得分都更小,说明本发明采用的分段线性拟合数据作为输入获得的rul预测误差更低,验证了本发明采用分段线性拟合数据提升了rul预测模型的预测精度。
[0105]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。