1.本发明涉及深度学习图像识别分析领域,具体涉及一种基于深度学习面部识别的轻量级走神判别方法。
背景技术:
2.信息技术的发展给人们的生活带来极大的便利,特别是对在线教育行业而言,视频直播的形式让学生得以在家完成课堂学习,这在疫情下的社会显得更为重要。为了提高学生的听课质量、让老师得到及时反馈,需要在直播过程中对学生听课是否走神进行智能识别,并将结果汇总,以供老师参考处理。对于捕获的学生听课设备摄像头的视频流,需要在关键帧检测到学生的人脸定位,再根据学生人脸区域进行走神识别,最后得到识别结果。
3.得益于硬件性能的提升,基于深度学习的人脸检测技术飞速发展,其速度和精度均远远超过基于传统方法的人脸检测模型,在工业界也得到了广泛应用。从densebox开始,人们从通用目标检测模型向人脸检测迁移,使用全卷积网络直接预测人脸目标矩形框和置信度,取得了不错的效果。之后face rcnn和retinaface等网络的性能不断提升,但网络规模也逐渐增大,在大多数硬件性能受限的场合不适用于实时性应用。目前人脸检测技术的效果已经能基本满足业务需求,为了方便应用和迁移,同时兼顾网络复杂度和运行速度,采用opencv提供的基于resnet10
‑
ssd网络的人脸识别预训练模型,作为人脸检测模块。
4.人脸检测技术的成熟使得人脸识别技术高速发展,目前人脸识别精度已经超过人眼,已经广泛应用到实际产品中。人脸表情识别作为人脸识别技术中的一个组成部分,今年来也得到了广泛的研究和应用。deepemotion在fer2013和ck 等经典面部表情识别数据集中都取得了不错的性能,各种基于vgg、resnet的网络变体也不断刷新各大数据集的性能指标。然而现有的数据集和模型都局限于处理反映愤怒、高性、悲伤、惊讶等基本情感的表情识别任务,印度学者提出的daisee走神识别数据集由于人种差异和视频质量问题,也不适用于国内的业务场景,同时也并没有模型在daisee数据集上表现出良好的性能。因此,在面部走神识别领域,不管是数据集还是网络模型都十分稀缺,带来了一定的困难和挑战。
技术实现要素:
5.本发明要解决的技术问题是克服现有的缺陷,提供一种基于深度学习面部识别的轻量级走神判别方法,可以有效解决背景技术中的问题。
6.为实现上述目的,本发明提出:一种基于深度学习面部识别的轻量级走神判别方法,该方法主要包括两个模块:基于resnet10
‑
ssd的人脸检测算法、基于mobilenet gru的走神识别算法;该轻量级面部走神识别方法兼顾了精度和速度,在实际应用场景中具有较高的实用价值。
7.作为本发明的一种优选技术方案:
8.一种基于深度学习面部识别的轻量级走神判别方法,包括以下步骤:
9.s1:采用基于resnet10
‑
ssd的人脸检测算法对视频流中的关键帧进行人脸检测。
人脸检测模块选择resnet10作为骨架,提取输入图片的深度特征,再送入一系列连续堆叠的卷积模块;根据网络不同阶段提取到的不同尺度的特征,分别送入ssd[10]检测头,同时预测图片中人脸框的定位信息和置信度;
[0010]
s2:对步骤s1中获得的人脸框信息,设置一个置信度阈值,将置信度大于阈值、距离图片画面中心最近的人脸框作为要识别的目标;将框内人脸区域裁下,送入后续模块进行走神识别;
[0011]
s3:对于步骤s2中获得的人脸区域,采用基于mobilenet gru的走神识别算法进行面部走神识别;走神识别模块借鉴yolo结构搭建网络骨架,并添加一个借用人脸关键点信息进行额外监督的注意力模块,通过全局池化后得到当前帧的人脸特征向量,一方面直接添加一个辅助分支,用头部姿态估计俯仰角pitch、偏航角yaw、滚动角roll,作为辅助信息进行额外监督;另一方面通过gru融合时序信息,在主分支进行走神识别分类,得到最后识别结果;
[0012]
s4:对于步骤s3中的注意力模块,对网络骨架提取的特征图,依次施加通道注意力和空间注意力,并借助人脸关键点信息对空间注意力图进行额外监督,达到增强位置特征信息、抑制冗余噪声的作用;注意力模块计算过程如下公式所述:
[0013]
z
c
=f
e
(u)
⊙
u
[0014]
z
cbam
=f
p
(z
c
)
⊙
z
c
[0015]
u表示注意力模块的输入特征图;
[0016]
f
e
表示获取通道注意力的函数;
[0017]
⊙
表示按元素相乘操作;
[0018]
z
c
表示施加通道注意力之后的特征图;
[0019]
f
p
表示获取空间注意力的函数;
[0020]
z
cbam
表示施加空间注意力之后的特征图;
[0021]
使用眼、口等51个面部关键点,使用高斯核生成热力图,对空间注意力进行额外监督,如下公式所述:
[0022][0023]
(x,y)表示热力图中的点的横、纵坐标;
[0024]
(x0,y0)表示面部关键点的横、纵坐标;
[0025]
σ表示高斯核标准差;
[0026]
若关键点生成的类高斯分布之间存在重叠区域,则按元素取最大值作为热力图的对应值;
[0027]
s5:对于步骤s3中的gru模块,将当前帧人脸特征向量与历史帧的隐藏向量相融合,达到提取时序、空间特征的效果。gru模块计算过程如下公式所述:
[0028]
r=σ(w
r
*[h
t
‑1,x
t
])
[0029]
z=σ(w
z
*[h
t
‑1,x
t
])
[0030][0031]
[0032]
x
t
表示模块输入的当前帧特征向量;
[0033]
h
t
‑1表示历史帧记忆内容;
[0034]
r表示重置门,控制记忆内容遗忘程度;
[0035]
h
′
表示当前帧融合记忆内容后的混合状态;
[0036]
z表示更新门,选择历史帧记忆内容和当前帧混合状态中的有效信息;
[0037]
h
t
表示当前帧输出的特征向量;
[0038]
模块输出的时空向量h
t
经过一个全连接层后,使用softmax函数即可得到走神状况的识别得分;
[0039]
s6:对于步骤s3中的注意力模块、头部姿态估计辅助分支、走神识别主分支这三个任务,需要同时进行监督;
[0040]
对注意力模块,损失函数取二元交叉熵:
[0041][0042]
其中y
i
,p
i
分别为对应位置的热力图真值与空间注意力图预测值;
[0043]
对头部姿态估计辅助分支,采取均方误差函数作为损失函数。同时为了加快收敛,可对网络输出值进行缩放:
[0044][0045]
其中y
i
,p
i
分别为头部姿态角的真值与预测值,ε为缩放系数;
[0046]
对走神识别主分支,对定义的几个走神状态进行多分类,采用交叉熵损失函数:
[0047][0048]
其中y
ij
,p
ij
分别为第i个样本的第j个走神状态的真值与预测值;
[0049]
对三个子任务损失进行加权,即可得到网络总损失:
[0050]
l=λ
att
l
att
λ
pose
l
pose
λ
cls
l
cls
[0051]
其中λ
att
,λ
pose
,λ
cls
为子任务损失的权重;
[0052]
s7对于步骤s3中头部姿态估计分支的输出结果生成初始角,方便结合后续帧的头部姿态角对网络输出结果进行矫正;再加上对网络预测得分的平滑操作,即可得到走神识别算法的最终结果。
[0053]
与现有技术相比,本发明的有益效果是:本发明提出了一种基于深度学习的轻量级的面部走神识别方法,兼顾了实时性和准确性,具有较强的实用效果。
附图说明
[0054]
图1为人脸检测网络总体结构图;
[0055]
图2为人脸检测网络核心模块结构图;
[0056]
图3为走神识别网络总体结构图;
[0057]
图4为走神识别网络bottleneckcsp模块结构图;
[0058]
图5为走神识别网络人脸关键点生成辅助热力图;
[0059]
图6为走神识别网络cbam模块结构图;
[0060]
图7为走神识别网络头部姿态角示意图;
[0061]
图8为走神识别网络gru网络结构图。
具体实施方式
[0062]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0063]
请参阅图1
‑
8,本发明提供以下技术方案:
[0064]
一种基于深度学习面部识别的轻量级走神判别方法,包括以下步骤:
[0065]
s1:采用基于resnet10
‑
ssd的人脸检测算法对视频流中的关键帧进行人脸检测。人脸检测模块选择resnet10作为骨架,提取输入图片的深度特征,再送入一系列连续堆叠的卷积模块;根据网络不同阶段提取到的不同尺度的特征,分别送入ssd检测头,同时预测图片中人脸框的定位信息和置信度。
[0066]
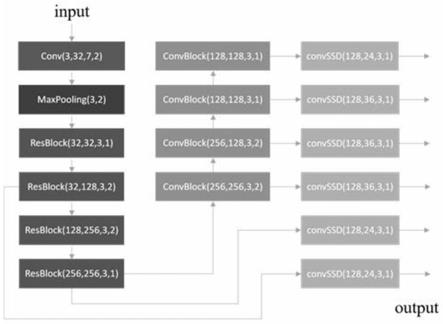
网络结构如图1所示,图中括号内四个数字代表:输入通道、输出通道、卷积核大小、步长;两个数字代表:卷积核大小、步长;该网络以单幅图像作为输入,图像归一化后首先通过卷积核为7、步长为2的卷积层 bn层 relu层,即图中conv模块,将图像映射为32维的张量,同时分辨率减半;通过池化核为3、步长为2的最大池化层后,张量分辨率再次减半;之后依次通过连续堆叠的残差模块,即图中resblock模块、卷积模块,即图中convblock模块提取第4、6、7、8、9、10层特征,分别送入ssd检测头,即图中convssd模块,再分别使用一个卷积层来预测人脸框的位置信息、置信度;网络的核心模块结构如图2所示。
[0067]
s2:对步骤s1中获得的人脸框,每个ssd检测头需要预测(x
c
,y
c
,w,h,o,c)这6个值,其中(x
c
,y
c
)表示框的中心坐标,(w,h)表示框的宽高,o表示框中内容为背景的置信度,c表示框中内容为人脸的置信度;同时为了改善人脸框位置信息的预测性能,添加(x
c
,y
c
,w,h)缩放系数:
[0068][0069][0070]
b
w
=d
w
·
exp(var
w
·
l
w
)
[0071]
b
h
=d
h
·
exp(var
h
·
l
h
)
[0072]
其中分别为网络预测值、人脸框绝对值。(d
w
,d
h
)为先验框的宽、高,为目标框中心点所在的单元格相对于左上角的坐标,offset=0.5为中心坐标偏置,为缩放系数。在不同特征层选取不同的先验框(d
w
,d
h
)。一般地,为每层分配一对尺寸(s
min
,s
max
),首先得到两个正方形先验框,其边长分别为s
min
、其次分配若干个长宽比值r,每分配一个r,得到长宽分
别为别为的两个矩形先验框。具体地,以输入图片分辨率为300
×
300,人脸检测网络一共有m=6个输出层,每个输出层分辨率分别为[(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)],分配的先验尺寸(s
min
,s
max
)分别为[(30,60),(60,111),(111,162),(162,213),(213,264),(264,315)],分配的先验长宽比r分别为[(2,),(2,3),(2,3),(2,3),(2,),(2,)],因此每个层分配的先验框的个数分别为[4,6,6,6,4,4];将每个输出层得到的人脸预测框整合到一起,需要应用nms算法去重,得到最后的人脸检测结果。
[0073]
s3:对于步骤s2中获得的人脸框信息,设置一个置信度阈值,将置信度大于阈值、距离图片画面中心最近的人脸框作为要识别的目标;将框内人脸区域裁下,使用基于mobilenet gru的走神识别算法进行走神识别;
[0074]
神识别模块借鉴yolo结构搭建网络骨架,并添加一个借用人脸关键点信息进行额外监督的cbam注意力模块,通过全局池化后得到当前帧的人脸特征向量,一方面直接添加一个辅助分支,用头部姿态估计作为辅助信息进行额外监督;另一方面通过gru融合时序信息,在主分支进行走神识别分类,得到最后识别结果;其网络结构如图3所示,图中括号内的四个数字代表:输入通道、输出通道、卷积核大小、步长;两个数字代表:输入通道、输出通道;一个数字代表:隐藏单元数;网络以当前关键帧图像、上一关键帧提取的特征向量作为输入,同时输出当前帧头部姿态估计、当前帧走神识别结果。
[0075]
s4:对于步骤s3中的网络骨架部分,除了第一层用普通卷积模块,即图中conv模块,提取原始输入图像的像素特征外,均采用深度可分离卷积替代传统卷积,降低网络参数量和计算量;网络采用连读堆叠的bottleneckcsp模块和步长为2的深度可分离卷积模块,即图中dwconv模块,提取图片深度特征,后者还起到下采样的作用;每个卷积模块由一个卷积层 bn层 relu层组成,深度可分离卷积模块即采用深度可分离卷积层代替卷积层,其余不变;
[0076]
bottleneckcsp模块采用了跨阶段局部连接和残差思想,在降低计算量的同时保留残差网络的强大特征提取能力,其结构如图4所示;模块将输入张量分为两路,其中一路通过一个卷积模块降低通道数,再经过n个残差模块提取特征,再通过一个独立卷积层调整维度空间;另一路直接通过一个额外的卷积层,将两路张量在通道维度拼接,共同通过bn层 relu激活层,最后再用一个独立的卷积层调整输出维度。
[0077]
s5:在步骤s3中的网络骨架尾部添加一个注意力模块并保留恒等映射,用人脸关键点生成热力图进行额外监督,如附图5所示;
[0078]
一方面,针对走神识别任务,网络应该更关注眼睛、嘴巴等关键位置,对脸颊等不重要的位置应该进行适度忽略,因此需要添加cbam注意力模块进行特征增强和噪声抑制;另一方面,经计算可知在网络骨架最终输出的特征图中,每个单元格的感受野已达117个像素,若取走神识别任务图像输入分辨率为112
×
112,则特征图上每个单元格的感受野已经覆盖整个图像区域,此时传统的cbam模块可能会将某些特征向量压缩到0左右,使其无法对最后的分类输出作出贡献,这显然是不合理的,所以需要保留恒等映射;cbam计算过程如下所示:
[0079]
z
c
=f
e
(u)
⊙
u
[0080]
z
cbam
=f
p
(z
c
)
⊙
z
c
[0081]
其中u为注意力模块的输入特征图,f
e
代表获取通道注意力的函数,
⊙
为点乘操作,z
c
为施加通道注意力之后的特征图;f
p
代表获取空间注意力的函数,z
cbam
为施加空间注意力之后的特征图;
[0082]
注意力模块网络结构如图6所示;f
e
通过最大池化和平均池化将输入特征图u分两路压缩到一维向量,后续的两层核为1、步长为1的卷积层时期上起到全连接层的作用,并且最大池化和平均池化两路的卷积层共享参数,最后通过sigmoid激活函数即得到了取值范围为[0~1]的通道注意力,再与u进行点乘操作,即得到z
c
;f
p
则在通道维度对z
c
进行最大池化和平均池化,将得到的两张通道数为1的注意力图在通道维度进行拼接,通过一层卷积层后进行sigmoid激活,得到取值范围为[0~1]的空间注意力,再与z
c
进行点乘操作得到z
cbam
,即注意力模块的最终输出;
[0083]
将施加注意力机制后的特征图进行全局平均池化,得到该帧人脸特征向量;
[0084]
s6:对于步骤s3中的头部姿态估计辅助分支,利用步骤s5中得到的该帧人脸特征向量,通过一层全连接层,直接拟合头部姿态,俯仰角pitch、偏航角yaw、滚动角roll,如附图7所示。
[0085]
s7:对于步骤s3中的面部走神识别主分支,利用步骤s5中得到的该帧人脸特征向量,历史帧的历史信息,通过gru单元提取时序特征,得到融合特征向量,通过一层全连接层后,对本帧人脸走神状态进行分类预测,通过softmax激活函数即可得到走神状态的得分;gru计算公式如下:
[0086]
r=σ(w
r
*[h
t
‑1,x
t
])
[0087]
z=σ(w
z
*[h
t
‑1,x
t
])
[0088][0089][0090]
对当前帧输入的特征向量x
t
、历史帧记忆内容h
t
‑1,首先计算得到重置门r,用来控制记忆内容h
t
‑1在当前帧的输出预测贡献占比,得到当前帧的混合状态h
′
;然后计算更新门z,对记忆内容h
t
‑1和当前状态h
′
,同时起到选择记忆有效信息、遗忘无效信息的作用,最终得到输出特征向量h
t
;gru模块网络结构如附图8所示,各种门的求取都由全连接层完成;
[0091]
s8:对于步骤s3中的cbam注意力模块、头部姿态估计辅助分支、走神识别主分支这三个任务同时进行监督;对cbam注意力模块,使用眼、鼻、口共51个面部关键点,使用高斯核生成热力图:
[0092][0093]
其中(x,y)为热力图中的点的横、纵坐标,(x0,y0)为面部关键点的横、纵坐标,σ=10为高斯核标准差;若关键点生成的类高斯分布之间存在重叠区域,则按元素取最大值作为热力图的对应值;损失函数取二元交叉熵:
[0094]
[0095]
其中y
i
,p
i
分别为对应位置的热力图真值与cbam注意力图预测值;
[0096]
对头部姿态估计辅助分支,由于三个姿态角取值均为连续值,故可采取均方误差函数作为损失函数;同时为了加快收敛,可对网络输出值进行缩放:
[0097][0098]
其中y
i
,p
i
分别为头部姿态角的真值与预测值,ε=5为缩放系数;
[0099]
对走神识别主分支,对定义的几个走神状态进行多分类,采用交叉熵损失函数即可:
[0100][0101]
其中y
ij
,p
ij
分别为第i个样本的第j个走神状态的真值与预测值;
[0102]
对三个子任务损失进行加权,即可得到网络总损失:
[0103]
l=λ
att
l
att
λ
pose
l
pose
λ
cls
l
cls
[0104]
本发明取λ
att
=λ
pose
=λ
cls
=1.0;
[0105]
s9:根据步骤s3中头部姿态估计分支的输出结果生成初始角,方便结合后续帧的头部姿态角对网络输出结果进行矫正;再加上对网络预测得分的平滑操作,即可得到走神识别算法的最终结果。
[0106]
本发明将基于深度学习的人脸检测结合表情识别的范式应用到了面部走神识别领域,并且通过基于轻量级网络设计的算法有效提取空间特征和时序特征生成走神状态得分,兼顾速度与精度,具有良好的实用效果。
[0107]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。