变体致病性评分和分类及其用途
1.相关申请的交叉引用
2.本技术要求2020年7月23日提交的美国临时专利申请63/055,724的优先权,该临时专利申请出于所有目的全文以引用方式并入本文。
技术领域
3.所公开的技术涉及机器学习技术的使用,这些机器学习技术可以被称为人工智能,该人工智能在计算机和数字数据处理系统上实施,用于评估生物序列变体的致病性以及使用致病性评估得出其他致病性相关数据的目的。这些方法可以包括或利用相应的数据处理方法和产品来模拟智能(即基于知识的系统、推理系统和知识获取系统)和/或用于推理不确定性的系统(例如模糊逻辑系统)、自适应系统、机器学习系统和人工神经网络。特别地,所公开的技术涉及使用基于深度学习的技术来训练深度卷积神经网络以用于致病性评估以及此类致病性信息的使用或精化。
背景技术:
4.本部分中讨论的主题不应仅因为在本部分中有提及就被认为是现有技术。类似地,在本部分中提及的或与作为背景技术提供的主题相关联的问题不应被认为先前在现有技术中已被认识到。本部分中的主题仅表示不同的方法,这些方法本身也可对应于受权利要求书保护的技术的具体实施。
5.遗传变异可以帮助解释许多疾病。每个人具有独特的遗传密码,并且在一组个体内存在许多遗传变体。已通过自然选择从基因组损耗了许多或大多数有害遗传变体。然而,仍然难以识别哪些遗传变异可能是临床感兴趣的。
6.此外,对变体的属性和功能效果(例如,致病性)进行建模是基因组学领域中具有挑战性的任务。尽管功能基因组测序技术的快速进展,但由于细胞类型特异性转录调节系统的复杂性,对变体的功能后果的解释仍存在巨大挑战。
技术实现要素:
7.描述了用于构建变体致病性分类器并且用于使用或精化此类致病性分类器信息的系统、方法和制品。此类具体实施可以包括或利用存储指令的非暂态计算机可读存储介质,这些指令可由处理器执行以执行本文所述系统和方法中的动作。即使未明确列出或描述,具体实施的一个或多个特征也可以与基础具体实施或其他具体实施组合。此外,不相互排斥的具体实施被教导为可以组合,使得具体实施的一个或多个特征可以与其他具体实施组合。本公开可周期性地提醒用户这些选项。然而,从一些具体实施中省略重复这些选项的叙述,不应视为限制以下各部分中教导的潜在组合。相反,这些叙述据此以引用方式向前并入以下具体实施中的每一者中。
8.所公开的这种系统具体实施和其他系统任选地包括本文所讨论的特征中的一些或全部特征。系统还可以包括结合所公开的方法中描述的特征。为了简洁起见,没有单独枚
举系统特征的替代组合。此外,适用于系统、方法和制品的特征对于每组法定分类的基本特征并不重复。读者将理解所识别的特征可如何容易地与在其他法定分类中的基本特征组合。
9.在所讨论主题的一个方面,描述了训练基于卷积神经网络的变体致病性分类器的方法和系统,该分类器在与存储器耦合的许多处理器上运行。可替代地,在其他系统具体实施中,除了基于神经网络的分类器之外或在基于神经网络的分类器的替代方案中,可以采用训练或适当参数化的统计模型或技术和/或其他机器学习方法。系统使用了由良性变体和致病性变体生成的蛋白质序列对的良性训练示例和致病性训练示例。良性变体包括常见的人类错义变体和非人类灵长类动物错义变体,这些非人类灵长类动物错义变体出现在与人类共享匹配的参考密码子序列的替代性非人类灵长类动物密码子序列上。所采样的人类可以属于不同的人类亚群,其可以包括或表征为:非洲/非洲裔美国人(缩写为afr)、美国人(缩写为amr)、德系犹太人(缩写为asj)、东亚人(缩写为eas)、芬兰人(缩写为fin)、非芬兰欧洲人(缩写为nfe)、南亚人(缩写为sas)和其他人(缩写为oth)。非人类灵长类动物错义变体包括来自多种非人类灵长类动物物种的错义变体,包括但不必限于黑猩猩、倭黑猩猩、大猩猩、婆罗洲猩猩(b.orangutan)、苏门答腊猩猩(s.orangutan)、恒河猴和狨猴。
10.如本文所讨论的,在多个处理器上运行的深度卷积神经网络可以被训练成将变体氨基酸序列分类为良性或致病性的变体氨基酸序列。因此,此类深度卷积神经网络的输出可以包括但不限于变体氨基酸序列的致病性评分或分类。如可以理解的,在某些具体实施中,除了基于神经网络的方法之外或在基于神经网络的方法的替代方案中,可以采用适当参数化的统计模型或技术和/或其他机器学习方法。
11.在本文所讨论的某些实施方案中,致病性处理和/或评分操作可以包括另外的特征或方面。举例来说,可以将各种致病性评分阈值用作评价或评估过程的一部分,诸如用于将变体评估或评分为良性或致病性的变体。举例来说,在某些具体实施中,用作可能致病性变体的阈值的每个基因的致病性评分的合适百分位数范围可以为51%至99%,诸如但不限于第51个、第55个、第65个、第70个、第75个、第80个、第85个、第90个、第95个或第99个百分位数。相反,用作可能良性变体的阈值的每个基因的致病性评分的合适百分位数范围可以为1%至49%,诸如但不限于第1个、第5个、第10个、第15个、第20个、第25个、第30个、第35个、第40个或第45个百分位数。
12.在其他实施方案中,致病性处理和/或评分操作还可以包括允许估计选择效应的特征或方面。在此类实施方案中,使用表征突变率和/或选择的合适输入对给定群体内的等位基因频率进行的前向时间模拟可以用于在目的基因处生成等位基因频谱。然后可以计算目的变体的损耗度量,诸如通过比较具有和不具有选择的等位基因频谱并且拟合或表征的对应选择-损耗功能来计算。基于给定致病性评分和该选择-损耗功能,可以基于针对变体生成的致病性评分来确定给定变体的选择系数。
13.在另外的方面,致病性处理和/或评分操作还可以包括允许使用致病性评分估计遗传疾病患病率的特征或方面。关于计算每个基因的遗传疾病患病率度量,在第一方法中,最初获得一组有害变体的三核苷酸背景配置。对于该组中的每个三核苷酸背景,执行假设某些选择系数(例如0.01)的前向时间模拟以生成该三核苷酸背景的预期等位基因频谱(afs)。将整个三核苷酸的afs相加,按基因中三核苷酸的频率加权,产生该基因的预期afs。
根据该方法的遗传疾病患病率度量可以定义为具有超过该基因的阈值的致病性评分的变体的预期累积等位基因频率。
14.在另外的方面,致病性处理和/或评分操作可以包括重新校准致病性评分的特征或方法。关于诸如重新校准,在一个示例性实施方案中,重新校准方法可以集中于变体的致病性评分的百分位数,因为这些可能更稳健并且较少受到施加在整个基因上的选择压力的影响。根据一个具体实施,计算出致病性评分的每个百分位数的存活概率,该存活概率构成存活概率校正因子,这意味着致病性评分的百分位数越高,变体在纯化选择中存活的机会就越小。可以采用存活概率校正因子来执行重新校准,以便帮助减轻噪声对错义变体中选择系数的估计的影响。
15.呈现前述描述以使得能够制造和使用所公开的技术。对所公开的具体实施的各种修改将是显而易见的,并且在不脱离所公开的技术的实质和范围的情况下,本文所定义的一般原理可应用于其他具体实施和应用。因此,所公开的技术并非旨在限于所示的具体实施,而是要符合与本文所公开的原理和特征一致的最广范围。所公开的技术的范围由所附权利要求限定。
附图说明
16.当参考附图阅读以下详细描述时将更好地理解本发明的这些和其他特征、方面和优点,其中在整个附图中相同的字符表示相同的部件,其中:
17.图1描绘了根据所公开技术的一个具体实施的训练卷积神经网络的各方面的框图;
18.图2示出了根据所公开技术的一个具体实施的用于预测蛋白质的二级结构和溶剂可及性的深度学习网络架构;
19.图3示出了根据所公开技术的一个具体实施的用于致病性预测的深度残差网络的示例性架构;
20.图4描绘了根据所公开技术的一个具体实施的致病性评分分布;
21.图5描绘了根据所公开技术的一个具体实施的clinvar致病性变体的平均致病性评分与该基因中所有错义变体的第75个百分位数处的致病性评分的相关性的图;
22.图6描绘了根据所公开技术的一个具体实施的clinvar良性变体的平均致病性评分与该基因中所有错义变体的第25个百分位数处的致病性评分的相关性的图;
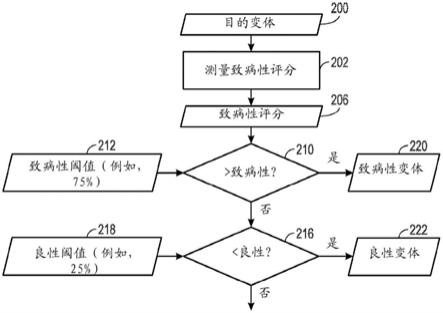
23.图7描绘了根据所公开技术的一个具体实施的可以使用阈值来基于变体致病性评分将变体表征为良性或致病性类别的样本工艺流程;
24.图8描绘了根据所公开技术的一个具体实施的可以得出最佳前向时间模型参数的样本工艺流程;
25.图9描绘了根据所公开技术的一个具体实施的简化为具有不同增长率的四个指数扩张阶段的人类群体的进化历史;
26.图10描绘了根据本方法得出的突变率估计值与其他文献得出的突变率之间的相关性;
27.图11描绘了根据本公开的各方面的观察到的与预期的cpg突变数量的比率与甲基化水平;
28.图12a、图12b、图12c、图12d、图12e描绘了根据本公开的各方面的皮尔逊卡方统计量的热图,这些热图示出了用于实施前向时间模拟模型的最佳参数组合;
29.图13示出了在一个示例中,使用根据本方法确定的最佳模型参数得出的模拟等位基因频谱与观察到的等位基因频谱相吻合;
30.图14描绘了根据所公开技术的一个具体实施的在前向时间模拟背景中掺入选择效应的样本工艺流程;
31.图15描绘了根据本公开的各方面的选择-损耗曲线的示例;
32.图16描绘了根据所公开技术的一个具体实施的可以得出目的变体的选择系数的样本工艺流程;
33.图17描绘了根据所公开技术的一个具体实施的可以得出致病性-损耗关系的样本工艺流程;
34.图18描绘了根据本公开的各方面的brca1基因的致病性评分与损耗的图;
35.图19描绘了根据本公开的各方面的ldlr基因的致病性评分与损耗的图;
36.图20描绘了根据所公开技术的一个具体实施的可以得出累积等位基因频率的样本工艺流程;
37.图21描绘了根据所公开技术的一个具体实施的可以得出预期累积等位基因频率的广义样本工艺流程;
38.图22描绘了根据本公开的各方面的预期累积等位基因频率与观察到的累积等位基因频率的图;
39.图23描绘了根据本公开的各方面的预期累积等位基因频率与疾病患病率的图;
40.图24描绘了根据所公开技术的一个具体实施的可以得出预期累积等位基因频率的第一样本工艺流程;
41.图25描绘了根据所公开技术的一个具体实施的可以得出预期累积等位基因频率的第二样本工艺流程;
42.图26描绘了根据本公开的各方面的预期累积等位基因频率与观察到的累积等位基因频率的图;
43.图27描绘了根据本公开的各方面的预期累积等位基因频率与疾病患病率的图;
44.图28描绘了根据所公开技术的一个具体实施的将重新校准方法的各方面与致病性评分过程相关联的样本工艺流程;
45.图29描绘了根据本公开的各方面的致病性评分百分位数与概率的分布;
46.图30描绘了根据本公开的各方面的观察到的致病性评分百分位数叠加高斯噪声的离散均匀分布的密度图;
47.图31描绘了根据本公开的各方面的观察到的致病性评分百分位数叠加高斯噪声的离散均匀分布的累积分布函数;
48.图32经由热图描绘了根据本公开的各方面的具有真实致病性评分百分位数的变体(x轴)落入观察到的致病性评分百分位数区间(y轴)中的概率;
49.图33描绘了根据所公开技术的一个具体实施的确定校正因子的步骤的样本工艺流程;
50.图34描绘了根据本公开的各方面的用于scn2a基因的错义变体的10个区段的百分
位数的损耗概率;
51.图35描绘了根据本公开的各方面的用于scn2a基因的错义变体的10个区段的百分位数的存活概率;
52.图36描绘了根据所公开技术的一个具体实施的确定校正损耗度量的步骤的样本工艺流程;
53.图37描绘了根据本公开的各方面的已校正或重新校准的热图,该热图表达了具有真实致病性评分百分位数的变体(x轴)落入观察到的致病性评分百分位数区间(y轴)中的概率;
54.图38描绘了根据本公开的各方面的每个致病性评分百分位数区段的校正损耗度量的图;
55.图39描绘了根据本公开的各方面的具有多层的前馈神经网络的一个具体实施;
56.图40描绘了根据本公开的各方面的卷积神经网络的一个具体实施的示例;
57.图41描绘了根据本公开的各方面的经由特征映射添加在下游重新注入先前信息的残差连接;
58.图42示出了可以操作所公开的技术的示例性计算环境;并且
59.图43是可用于实施所公开的技术的计算机系统的简化框图。
具体实施方式
60.呈现以下讨论以使得本领域的任何技术人员能够实现和使用所公开的技术,并且在特定应用及其要求的背景中提供以下讨论。对所公开的具体实施的各种修改对于本领域的技术人员而言将是显而易见的,并且在不脱离所公开的技术的实质和范围的情况下,本文所定义的一般原理可应用于其他具体实施和应用。因此,所公开的技术并非旨在限于所示的具体实施,而是要符合与本文所公开的原理和特征一致的最广范围。
61.i.引言
62.以下讨论包括与神经网络的训练和使用有关的方面,包括卷积神经网络,这些卷积神经网络可以用于实施下文所讨论的某些分析,诸如变体致病性评分或分类的生成以及基于此类致病性评分或分类的有用临床分析或度量的得出。考虑到这一点,可以在描述本技术时提及或参考此类神经网络的某些方面和特征。为了简化讨论,假定在描述本技术时,对此类神经网络有基本的了解。然而,对于那些想要对相关神经网络概念进行额外解释的人来说,相关神经网络概念的额外信息和描述将在描述接近结束时提供。此外,还应当理解,尽管本文主要讨论了神经网络以提供有用的示例并且有助于解释,但是可以采用其他具体实施代替或补充神经网络方法,包括但不限于训练或适当参数化的统计模型或技术和/或其他机器学习方法。
63.特别地,以下讨论可以利用在用于分析某些目的基因组数据的具体实施中的与神经网络(例如,卷积神经网络)相关的某些概念。考虑到这一点,此处概述了目的潜在生物和遗传问题的某些方面来为本文所解决的问题提供有用的背景,对于该问题,可以利用本文所讨论的神经网络技术。
64.遗传变异可以帮助解释许多疾病。每个人具有独特的遗传密码,并且在一组个体内存在许多遗传变体。已通过自然选择从基因组损耗了许多或大多数有害遗传变体。然而,
仍然希望鉴定哪些遗传学变化可能是致病的或有害的。特别地,此类知识可以帮助研究人员关注可能的致病性遗传变体并加快许多疾病的诊断和治愈的速度。
65.建模变体的属性和功能效果(例如,致病性)是基因组学领域的重要但具有挑战性的任务。尽管功能基因组测序技术的快速进展,但由于细胞类型特异性转录调节系统的复杂性,对变体的功能后果的解释仍存在巨大挑战。因此,用于预测变体的致病性的强大计算模型对于基础科学和转化研究两者都可以具有巨大的益处。
66.此外,过去几十年生物化学技术的进展已产生下一代测序(ngs)平台,这些平台以比以往低得多的成本快速产生基因组数据,从而导致生成的基因组数据量不断增加。此类压倒性大量测序dna仍然难以注释。当大量标记数据可用时,监督机器学习算法通常很好地执行。然而,在生物信息学和许多其他富含数据的学科中,标记实例的过程是昂贵的。相反,未标记示例是廉价的并且易于获得。对于其中标记数据的量相对较小并且未标记数据的量基本上较大的情况,半监督学习表示手动标记的成本有效的替代形式。因此,这提供了使用半监督算法来构建基于深度学习的致病性分类器的机会,这些分类器准确地预测变体的致病性。以可产生不含人类确定偏差的致病性变体的数据库。
67.关于基于机器学习的致病性分类器,深度神经网络是一种人工神经网络,其使用多个非线性且复杂的变换层来对高级特征进行连续建模。深度神经网络经由反向传播提供反馈,该反向传播携带观察输出和预测输出之间的差异以调整参数。深度神经网络随着大型训练数据集的可用性、并行与分布式计算的能力以及复杂的训练算法而演进。
68.卷积神经网络(cnn)和递归神经网络(rnn)是深度神经网络的组成部分。卷积神经网络可以具有包括卷积层、非线性层和池化层的架构。递归神经网络被设计成利用输入数据的顺序信息,并且具有在构建模块如感知子、长短期记忆单元和门控递归单元之间循环连接。此外,已提出了针对有限情境的许多其他新兴深度神经网络,诸如深度时空神经网络、多维递归神经网络和卷积自编码器。
69.鉴于序列数据是多维和高维的,深度神经网络由于其广泛的适用性和增强的预测能力而在生物信息学研究方面具有前景。卷积神经网络已被用于解决基因组学中基于序列的问题,诸如基序发现、致病性变体鉴定和基因表达推断。卷积神经网络使用权重共享策略,该策略可用于研究dna,因为其可捕获序列基序,该序列基序是dna中被假定具有显著生物学功能的短且反复出现的局部模式。卷积神经网络的标志是卷积滤波器的使用。与基于精密设计的特征和手工制作的特征的传统分类方法不同,卷积滤波器执行特征的自适应学习,类似于将原始输入数据映射到知识的信息表示的过程。在这个意义上,卷积滤波器用作一系列基序扫描器,因为一组此类滤波器能够在训练过程期间识别输入中的相关模式并更新其自身。递归神经网络可捕获具有不同长度的序列数据(诸如,蛋白质或dna序列)中的长程依赖。
70.如图1所示例性描绘的,训练深度神经网络涉及优化每层中的权重参数,这将较简单的特征逐渐组合成复杂的特征,使得可以从数据中学习到最合适的分层表示。优化过程的单个循环按以下步骤来进行。首先,在给定训练数据集(例如,在该示例中的输入数据100)的情况下,前向传递顺序地计算每层中的输出并将函数信号通过神经网络102向前传播。在最终输出层中,目标损失函数(比较步骤106)测量推断的输出110与给定标记112之间的误差104。为了尽量减少训练误差,后向传递使用链规则来反向传播(步骤114)误差信号
并计算相对于整个神经网络102中的所有权重的梯度。最后,基于随机梯度下降或其他适当方法使用优化算法来更新权重参数(步骤120)。虽然批量梯度下降针对每个完整的数据集执行参数更新,但随机梯度下降通过针对每个小数据示例集执行更新来提供随机逼近。若干优化算法源自随机梯度下降。例如,adagrad和adam训练算法执行随机梯度下降,同时分别基于每个参数的梯度的更新频率和动量自适应地修改学习速率。
71.深度神经网络训练中的另一个元素是正则化,该正则化是指旨在避免过度拟合并因此实现良好泛化性能的策略。例如,权重衰减将惩罚因子添加到目标损失函数,使得权重参数收敛到较小绝对值。丢弃在训练期间从神经网络随机移除隐藏单元,并且可被认为是可能子网络的集成。此外,批量归一化通过归一化微型批量内每次激活的标量特征并学习每个平均值和方差作为参数来提供新的正则化方法。
72.考虑到前面关于目前所描述的技术的高级概述,目前所描述的技术与先前的致病性分类模型不同,后者采用了大量的人类设计的特征和元分类器。相比之下,在本文所述的技术的某些实施方案中,可以采用简单的深度学习残差网络,其仅采取侧接目的变体的氨基酸序列和其他物种中的直系同源序列比对作为输入。在某些具体实施中,为了向网络提供关于蛋白质结构的信息,可以分别训练两个单独的网络以仅从序列学习二级结构和溶剂可及性。这些可以在较大深度学习网络中作为子网络掺入以预测对蛋白质结构的影响。使用序列作为起始点避免了蛋白质结构和功能结构域注释中的潜在偏差,这些偏差可以是不完全确定的或不一致地应用的。
73.深度学习分类器的准确度与训练数据集的大小成正比,并且来自六个灵长类动物物种中的每一者的变异数据独立地有助于增强分类器的准确度。现存非人类灵长类动物物种的巨大数量和多样性以及表明对改变蛋白质的变体的选择压力在灵长类动物血统内基本一致的证据表明系统的灵长类动物群体测序是对目前限制临床基因组解释的数百万意义不明的人类变体进行分类的有效策略。
74.此外,常见的灵长类动物变异也为评价完全独立于以前使用的训练数据(因元分类器的激增而难以客观评价)的现有方法,提供了干净的验证数据集。使用了10,000个留存的灵长类动物常见变体来评价本文所述的本模型以及其他四种流行的分类算法(sift、polyphen2、cadd、m-cap)的性能。由于大致50%的所有人类错义突变将按常见等位基因频率通过自然选择去除,因此在一组随机挑选的错义变体(按照突变率与10000个留存的灵长类动物常见变体匹配)上计算每个分类器的第50个百分位数评分,并用阈值评价留存的灵长类动物常见变体。使用仅训练人类常见变体的深度学习网络或使用人类常见变体和灵长类动物变体二者的目前公开的深度学习模型的准确度显著优于对独立验证数据集中的其他分类器。
75.考虑到前述内容,并且作为总结,本文所述的方法与预测变体致病性的现有方法在多种方面均不同。首先,目前描述的方法采用半监督深度卷积神经网络的新颖架构。第二,可靠的良性变体是从人类常见变体(例如,来自gnomad)和灵长类动物变体获得的,而高置信度致病性训练集是通过迭代平衡采样和训练生成的,以避免使用相同的人类精选的变体数据库来对模型进行循环训练和测试。第三,将二级结构和溶剂可及性的深度学习模型整合到致病性模型的架构中。从结构和溶剂模型获得的信息不限于对特定氨基酸残基的标记预测。而且,从结构和溶剂模型中去除了读出层,并将预训练的模型与致病性模型合并。
在训练致病性模型时,结构和溶剂预训练层也会反向传播,以尽量减少误差。这有助于使预训练的结构和溶剂模型集中于致病性预测问题。
76.还如本文所讨论的,如本文所述训练和使用的模型的输出(例如,致病性评分和/或分类)可用于生成额外的数据或有价值的诊断,诸如针对一系列具有临床意义的变体的选择效应的估计和对遗传疾病患病率的估计。还描述了其他相关概念,诸如模型输出的重新校准以及用于表征致病性和良性变体的阈值的生成和使用。
77.ii.术语/定义
78.如本文所用:
79.碱基是指如下核苷酸碱基或核苷酸,a(腺嘌呤)、c(胞嘧啶)、t(胸腺嘧啶)或g(鸟嘌呤)。
80.术语“蛋白质”和“翻译序列”可以互换使用。
81.术语“密码子”和“碱基三联体”可以互换使用。
82.术语“氨基酸”和“翻译单元”可以互换使用。
83.短语“变体致病性分类器”、“用于变体分类的基于卷积神经网络的分类器”和“用于变体分类的基于深度卷积神经网络的分类器”可以互换使用。
84.iii.致病性分类神经网络
85.a.训练和输入
86.谈到示例性具体实施,本文描述了深度学习网络,该深度学习网络可以用于变体致病性分类(例如,致病性或良性)和/或生成以数值表征致病性或缺乏致病性的定量度量(例如,致病性评分)。在一个仅使用具有良性标记的变体对分类器进行训练的背景下,拟定了关于可能观察到的给定突变是否为群体中常见突变的预测问题。多个因素影响在高等位基因频率处观察变体的概率,尽管毒害性是本讨论和描述的主要重点。其他因素包括但不限于突变率、技术误差诸如测序范围,以及影响中性遗传漂变(诸如基因转换)的因素。
87.关于训练深度学习网络,变体分类对临床应用的重要性激发了多次尝试使用监督的机器学习来解决问题,但这些努力因为缺乏足够大小的真实数据集而受到阻碍,该数据集含有用于训练的可靠标记的良性和致病性变体。
88.现有人类专家精选的变体的数据库并不代表完整基因组,clinvar数据库中约50%的变体仅来自于200个基因(占人类蛋白编码基因的约1%)。此外,系统研究发现多数人类专家注释的支持证据存在疑问,低估了解释可以仅在单个患者中观察到的罕见变体的难度。尽管人类专家解释变得越来越严格,围绕共识实践制定了大量分类指导方针,但是这些分类指导方针对加强现有趋势是有风险的。为降低人类解释偏差,最近的分类器对常见人类多态性或固定的人类-黑猩猩替代物进行训练,但这些分类器也使用对人类精选数据库进行训练的早期分类器的预测评分作为它们的输入。在不存在独立的、无偏差的真实数据集的情况下,这些不同方法的性能的客观基准是难懂的。
89.为了解决这个问题,目前描述的技术利用来自非人类灵长类动物(例如,黑猩猩、倭黑猩猩、大猩猩、红毛猩猩、恒河猴和狨猴)的变异,该变异提供了超过300,000个独特的错义变体,这些变体与常见人类变异不重叠并且很大程度上代表了已通过纯化选择筛选的良性结果的常见变体。这大大扩大了可用于机器学习方法的训练数据集。平均而言,每个灵长类动物物种提供比整个clinvar数据库(截止2017年11月,在排除具有不确定意义的变体
和注释冲突的变体后,约42000个错义变体)更多的变体。另外,该内容不含人类解释偏差。
90.关于生成根据本技术使用的良性训练数据集,一个此类数据集由用于机器学习的人类和非人类灵长类动物的大部分常见良性错义变体构成。数据集包含常见人类变体(》0.1%等位基因频率;83,546个变体),以及来自黑猩猩、倭黑猩猩、大猩猩和红毛猩猩、恒河猴和狨猴的变体(301,690个独特灵长类动物变体)。
91.使用包含常见人类变体(等位基因频率(af)》0.1%)和灵长类动物变异的一个此类数据集来训练深度残差网络(在本文中称为灵长类动物ai或pai)。训练网络以接收侧接目的变体的氨基酸序列和其他物种中的直系同源序列比对来作为输入。与采用人类设计特征的现有分类器不同,训练目前描述的深度学习网络以直接从一级序列中提取特征。在某些具体实施中,为了掺入关于蛋白质结构的信息,并且如下文更详细地描述的,训练单独的网络以仅从序列预测二级结构和溶剂可及性,并且这些被包括为全模型中的子网络。鉴于已经成功结晶的人类蛋白质的数量有限,从一级序列推断结构具有避免由于蛋白质结构和功能结构域注释不完整而引起偏差的优点。具有所包括的蛋白质结构的网络的一个具体实施的总深度为36层卷积,包含大致400,000个可训练参数。
92.b.蛋白质二级结构和溶剂可及性子网络
93.在具体实施的一个示例中,用于致病性预测的深度学习网络包含36个总卷积层,这些卷积层包括用于二级结构和溶剂可及性预测子网络的19个卷积层,以及用于主要致病性预测网络的17个卷积层,该主要致病性预测网络采取二级结构和溶剂可及性子网络的结果作为输入。特别地,由于大多数人类蛋白质的晶体结构是未知的,因此训练二级结构网络和溶剂可及性预测网络以使网络能够从一级序列学习蛋白质结构。
94.一个此类具体实施中的二级结构和溶剂可及性预测网络具有相同的架构和输入数据,但在预测状态上有所不同。例如,在一个此类具体实施中,对二级结构和溶剂可及性网络的输入是编码来自人类与99种其他脊椎动物的多序列比对的保守信息的合适维度(例如,51长度
×
20个氨基酸pfm)的氨基酸位置频率矩阵(pfm)。
95.在一个实施方案中,并且参考图2,用于致病性预测的深度学习网络以及用于预测二级结构和溶剂可及性的深度学习网络采用残差块140的架构。残差块140包括重复卷积单元,散布有跳跃连接142,这些跳跃连接允许来自较早层的信息跳过残差块140。在每个残差块140中,首先对输入层进行批量归一化,之后进行使用修正线性单元(relu)的激活层。然后,使激活通过1d卷积层。对来自1d卷积层的此中间输出再次进行批量归一化以及relu激活,之后进行另一1d卷积层。在第二1d卷积结束时,将该第二1d卷积的输出与原始输入相加到残差块中(步骤146),这通过允许原始输入信息绕过残差块140来充当跳跃连接142。在此类架构(可以称为深度残差学习网络)中,输入被保留处于其原始状态,并且残差连接保持不含来自模型的非线性激活,从而允许有效训练更深度的网络。图2以及表1和表2中提供了二级结构网络130和溶剂可及性网络132两者的背景中的详细架构(下文讨论),其中pwm保守数据150被示出为初始输入。在所描绘的示例中,模型的输入150可以是使用由raptorx软件(用于对蛋白数据库序列进行训练)生成的保守位置加权矩阵(pwm)或99个脊椎动物比对(用于对人类蛋白序列进行训练和干扰)。
96.在残差块140之后,softmax层154计算每个氨基酸的三个状态的概率,其中最大softmax概率确定氨基酸的状态。使用adam优化器利用整个蛋白质序列的累积类别互熵损
失函数来训练一个此类具体实施中的模型。在示出的一个具体实施中,一旦网络对二级结构和溶剂可及性进行了预训练,而不是直接将网络的输出作为致病性预测网络160的输入,就采取softmax层154之前的层代替,以便更多信息传递给致病性预测网络160。在一个示例中,softmax层154之前的层的输出是合适长度的氨基酸序列(例如,长度为51个氨基酸)并且变成用于致病性分类的深度学习网络的输入。
97.考虑到前述内容,训练二级结构网络以预测3态二级结构:(1)α螺旋(h)、(2)β折叠(b)或(3)卷曲(c)。训练溶剂可及性网络以预测3态溶剂可及性:(1)掩埋态(b)、(2)过渡态(i)或(3)暴露态(e)。如上所述,两个网络仅采用一级序列作为它们的输入150,并且使用来自protein databank中已知晶体结构的标记进行训练。每个模型对预测每个氨基酸残基的一个相应状态进行建模。
98.考虑到前述内容,并且借助于示例性具体实施的进一步说明,对于输入数据集150中的每个氨基酸位置,从位置频率矩阵中获取对应于侧接氨基酸(例如侧接51个氨基酸)的窗口,并且使用该窗口来预测用于该长度氨基酸序列中心处的氨基酸的二级结构或溶剂可及性的标记。用于二级结构和相对溶剂可及性的标记使用dssp软件直接从蛋白质的已知3d晶体结构获得,并且不需要从一级序列进行预测。为了将二级结构网络和溶剂可及性网络作为致病性预测网络160的一部分掺入,从基于人类的99个脊椎动物多序列比对中计算出位置频率矩阵。尽管从这两种方法生成的保守矩阵通常相似,但在训练致病性预测期间通过二级结构和溶剂可及性模型进行了反向传播,从而允许对参数权重进行微调。
99.举例来说,表1示出了3态二级结构预测深度学习(dl)模型的示例性模型架构细节。形状指定了模型每层的输出张量的形状,并且激活为给予该层神经元的激活。模型的输入是变体周围侧接氨基酸序列的合适维度(例如,51个氨基酸长度,深度为20)的位置特异性频率矩阵。
100.类似地,表2中示出的模型架构示出了3态溶剂可及性预测深度学习模型的示例性模型架构细节,如本文所述,这些细节在架构方面可以与二级结构预测dl模型相同。形状指定了模型每层的输出张量的形状,并且激活为给予该层神经元的激活。模型的输入是变体周围侧接氨基酸序列的合适维度(例如,51个氨基酸长度,深度为20)的位置特异性频率矩阵。
101.3态二级结构预测模型的最佳测试准确度为80.32%,类似于由deepcnf模型在类似训练数据集上预测的现有技术准确度。3态溶剂可及性预测模型的最佳测试准确度为64.83%,类似于由raptorx在类似训练数据集上预测的当前最佳准确度。
102.示例性具体实施—模型架构和训练
103.参考表1和表2(下面再现)以及图2,并且借助于提供具体实施的示例,训练两个端对端深度卷积神经网络模型以分别预测蛋白质的3态二级结构和3态溶剂可及性。这两个模型具有类似的配置,包括两个输入通道,一个用于蛋白质序列,并且另一个用于蛋白质保守概况。每个输入通道具有维度l
×
20,其中l表示蛋白质的长度。
104.输入通道中的每一个输入通道通过具有40个内核和线性激活值的1d卷积层(第1a层和第1b层)。该层用于将输入维度从20上采样至40。在整个模型中的所有其他层都使用40个内核。通过对40个维度中的每个维度进行求和(即,合并模式=
‘
求和’)来将两个层(1a与1b)激活值合并在一起。合并节点的输出通过1d卷积的单个层(第2层),然后进行线性激活。
105.来自第2层的激活值通过一系列9个残差块(第3层至第11层)。第3层的激活值被反馈到第4层,并且第4层的激活值被反馈到第5层,以此类推。还存在直接将每第3个残差块(第5层、第8层和第11层)的输出相加的跳跃连接。然后将合并的激活值反馈到具有relu激活值的两个1d卷积(第12层和第13层)中。将来自第13层的激活值给予softmax读出层。softmax计算出给定输入的三个类别输出的概率。
106.还应当注意,在二级结构模型的一个具体实施中,1d卷积的空洞率为1。在溶剂可及性模型的具体实施中,最后的3个残差块(第9层、第10层和第11层)的空洞率为2,以增加内核的覆盖率。就这些方面而言,空洞/扩张卷积是其中通过以特定步长(也称为空洞卷积速率或扩张因子)跳过输入值来在比内核长度大的区域上应用该内核的卷积。空洞/扩张卷积在卷积滤波器/内核的元素之间添加间距,使得在执行卷积运算时,考虑较大间隔的邻近输入条目(例如,核苷酸、氨基酸)。这使得能够在输入中结合长程情境依赖性。空洞卷积节省了部分卷积计算以在处理相邻核苷酸时重新使用。空洞/扩张卷积允许具有很少可训练参数的大感受场。蛋白质的二级结构强烈取决于非常接近的氨基酸的相互作用。因此,具有较高内核覆盖率的模型会稍微改善性能。相反,溶剂可及性受到氨基酸之间的长程相互作用的影响。因此,对于使用空洞卷积的具有高内核覆盖度率的模型,其准确度比短覆盖率模型高2%以上。
107.表1—3态二级结构预测模型的示例
108.[0109][0110]
表2-3态溶剂可及性模型的示例
[0111]
[0112][0113]
c.致病性预测网络架构
[0114]
关于致病性预测模型,开发了半监督深度卷积神经网络(cnn)模型以预测变体的致病性。这些模型的输入特征包括侧接变体的蛋白质序列和保守概况,以及特定基因区域中错义变体的损耗。还通过深度学习模型预测了变体导致的二级结构和溶剂可及性的变化,并将这些变化整合到致病性预测模型中。在一个此类具体实施中预测的致病性规模是0(良性)到1(致病性)。
[0115]
用于一种此类致病性分类神经网络(例如,灵长类动物ai)的架构示意性地描述于图3中,并且以更详细的示例描述于表3(下文)中。在图3中所示的示例中,1d是指1维卷积层。在其他具体实施中,模型可以使用不同类型的卷积,诸如2d卷积、3d卷积、扩张或空洞卷积、转置卷积、可分离卷积、深度可分离卷积等等。此外,如上所述,用于致病性预测(例如,灵长类动物ai或pai)的深度学习网络以及用于预测二级结构和溶剂可及性的深度学习网络二者的某些具体实施采用残差块的架构。
[0116]
在某些实施方案中,深度残差网络的一些或所有层还使用relu激活函数,该激活函数与饱和非线性(诸如s形或双曲线正切)相比大大加速了随机梯度下降的收敛。所公开的技术可以使用的激活函数的其他示例包括参数relu、泄漏relu和指数线性单元(elu)。
[0117]
如本文所述,一些或所有层还可以采用批量归一化,通过该批量归一化改变训练期间卷积神经网络(cnn)中每层的分布,并且该分布从一层到另一层有所不同。这降低了优化算法的收敛速度。
[0118]
表3-根据一个具体实施的致病性预测模型
[0119]
[0120][0121]
示例性具体实施—模型架构
[0122]
考虑到前述内容,并且参考图3和表3,在一个具体实施中,致病性预测网络接收五个直接输入和四个间接输入。此类示例中的五个直接输入可以包括合适维度的氨基酸序列(例如,51个氨基酸序列长度
×
深度为20)(编码20个不同氨基酸),并且包括没有变体的参考人类氨基酸序列(1a),具有取代变体的替代人类氨基酸序列(1b),来自灵长类动物物种多序列比对的位置特异性频率矩阵(pfm)(1c),来自哺乳动物物种多序列比对的pfm(1d)和来自更远古的脊椎动物物种多序列比对的pfm(1e)。间接输入包括基于参考序列的二级结构(1f)、基于替代序列的二级结构(1g)、基于参考序列的溶剂可及性(1h)和基于替代序列的溶剂可及性(1i)。
[0123]
对于间接输入1f和1g,将二级结构预测模型的预训练层加载,排除softmax层。对于输入1f,预训练层基于变体的人类参考序列以及由psi-blast针对变体生成的pssm。同样,对于输入1g,二级结构预测模型的预训练层基于人类替代序列作为输入以及pssm矩阵。
输入1h和1i分别对应于含有用于变体的参考序列和替代序列的溶剂可及性信息的类似预训练通道。
[0124]
在该示例中,五个直接输入通道通过具有线性激活值的40个内核的上采样卷积层。将第1a层、第1c层、第1d层和第1e层与40个特征维度相加的值合并以产生第2a层。换句话说,将参考序列的特征映射与三种类型的保守特征映射合并。类似地,将1b、1c、1d和1e与40个特征维度相加的值合并以生成第2b层,即,将替代序列的特征与三种类型的保守特征合并。
[0125]
使用relu激活值对第2a层和第2b层进行批量归一化,并且每层都通过滤波器大小为40的1d卷积层(3a和3b)。将第3a层和第3b层的输出与1f、1g、1h和1i合并,其中特征映射彼此连接。换句话说,将具有保守概况的参考序列和具有保守概况的替代序列的特征映射与参考序列和替代序列的二级结构特征映射以及参考序列和替代序列的溶剂可及性特征映射合并(第4层)。
[0126]
第4层的输出通过六个残差块(第5层、第6层、第7层、第8层、第9层、第10层)。1d卷积的最后三个残差块的空洞率为2,以为内核提供更高的覆盖率。第10层的输出通过滤波器大小为1并且激活值为s形的1d卷积(第11层)。第11层的输出通过全局最大池化,该全局最大池化会选择变体的单一值。该值代表变体的致病性。表3中示出了致病性预测模型的一个具体实施的细节。
[0127]
d.训练(半监督)和数据分布
[0128]
关于半监督学习方法,此类技术允许利用标记数据和未标记数据二者来训练网络。选择半监督学习的动机是人类精选的变体数据库不可靠且有噪声,并且特别是缺乏可靠的致病性变体。因为半监督学习算法在训练过程中使用标记实例和未标记实例二者,所以它们可以产生分类器,这些分类器实现比仅具有少量的可用于训练的标记数据的完全监督的学习算法更好的性能。半监督学习的原理是可利用未标记数据内的固有知识来增强仅使用标记实例的监督模型的预测能力,从而提供用于半监督学习的潜在优势。由监督分类器从少量标记数据中学习到的模型参数可能会被未标记数据引导到更现实的分布(更接近类似于测试数据的分布)。
[0129]
生物信息学中普遍存在的另一个挑战是数据不平衡问题。当要预测的类别中的一类在数据中的代表性数量不足时,就会出现数据不平衡现象,这是因为属于该类别的实例很少(值得注意的情况)或难以获取。这些少数类别通常是最重要的学习类别,因为它们可能与特殊情况相关。
[0130]
处理不平衡数据分布的算法方法基于分类器的集合。有限量的标记数据自然会导致较弱的分类器,但弱分类器的集合倾向于超过任何单个成分分类器的性能。此外,集合通常通过验证与学习多个模型相关联的努力和成本的因素来改善从单个分类器获得的预测准确度。直观而言,汇总几个分类器会导致更好的过拟合控制,因为将各个分类器的高变异性进行平均也会将分类器的过拟合进行平均。
[0131]
iv.基因特异性致病性评分阈值
[0132]
虽然前面涉及对作为神经网络实现的致病性分类器的训练和验证,但下面的部分涉及使用此类网络进一步精化和/或利用致病性分类的各种具体实施特异性场景和使用实例场景。在第一方面,描述对评分阈值的讨论和此类评分阈值的使用。
[0133]
如本文所述,目前公开的致病性分类网络(诸如(但不限于)本文所述的本文所述的灵长类动物ai或pai分类器)可以用于生成可用于将基因内的致病性变体与良性变体区分或从这些基因内筛选致病性变体的致病性评分。因为如本文所述的致病性评分是基于在人类和非人类灵长类动物中纯化选择的程度,所以预期与致病性变体和良性变体相关的致病性评分在强纯化选择下的基因中较高。另一方面,对于中性进化或弱选择下的基因,致病性变体的致病性评分倾向于较低。这种概念在图4中直观示出,其中变体的致病性评分206在相应基因的评分分布内示出。如参考图4可以理解的,实际上,具有近似基因特异性阈值可用于鉴定可能是致病性的或良性的变体。
[0134]
为了评估可能用于评估致病性评分的可能阈值,使用84个基因研究潜在的评分阈值,这些基因含有clinvar中的至少10个良性变体/可能良性变体以及至少10个致病性和可能致病性变体。这些基因用于帮助评价每个基因的合适的致病性评分阈值。对于这些基因中的每一者,测量clinvar中的良性变体和致病性变体的平均致病性评分。
[0135]
在一个具体实施中,观察到每个基因中致病性clinvar变体和良性clinvar变体的平均致病性评分与该基因中的致病性评分的第75个百分位数和第25个百分位数(此处为灵长类动物ai或pai评分)完全一致,如图5和图6以图形示出的,图5示出了致病性变体的基因特异性灵长类动物ai阈值,图6示出了良性变体的基因特异性灵长类动物ai阈值。在这两个图中,每个基因由带有上述基因符号标记的点表示。在这些示例中,clinvar致病性变体的平均灵长类动物ai评分与该基因中所有错义变体的第75个百分位数处的灵长类动物ai评分紧密相关(斯皮尔曼相关性=0.8521,图5)。同样,clinvar良性变体的平均灵长类动物ai评分与该基因的所有错义变体的第25个百分位数处的灵长类动物ai评分紧密相关(斯皮尔曼相关性=0.8703,图6)。
[0136]
鉴于本方法,用作可能致病性变体的截止值的每个基因的致病性评分的合适百分位数可以处于由第51个百分位数至第99个百分位数限定的范围内并且处于包括第51个百分位数至第99个百分位数的范围内(例如,第65个、第70个、第75个、第80个或第85个百分比)。相反,用作可能良性变体的截止值的每个基因的致病性评分的合适百分位数可以处于由第1个百分位数至第49个百分位数限定的范围内并且处于包括第1个百分位数至第49个百分位数的范围内(例如,第15个、第20个、第25个、第30个或第35个百分比)。
[0137]
关于这些阈值的使用,图7示出了可以使用此类阈值来基于变体的致病性评分206将这些变体分选成良性或致病性类别的样本工艺流程。在该示例中,可以使用如本文所述的致病性评分神经网络来处理目的变体200(步骤202)以得出目的变体200的致病性评分206。在所描绘的示例中,将致病性评分与基因特异性致病性阈值212(例如,75%)比较(决策框210),并且如果未确定为致病性的,则与基因特异性良性阈值218比较(决策框216)。尽管为简单起见,该示例中的比较过程被示出为连续发生的,但是在实践中,可以同时在单一步骤中执行这些比较,或者可替代地,可以仅执行这些比较中的一者(例如,确定变体是否是致病性的)。如果超过致病性阈值212,则目的变体200可以被视为致病性变体220,而相反,如果致病性评分206低于良性阈值212,则目的变体200可以被视为良性变体222。如果未满足阈值标准,则可以将目的变体处理为既非致病性的也非良性的。在一项研究中,得出基因特异性阈值和度量并且使用本文所述的方法对clinvar数据库内的17,948个独特基因进行评价。
[0138]
v.使用前向时间模拟基于致病性评分来估计针对所有人类变体的选择效应
[0139]
临床研究和患者护理是示例性的使用实例场景,其中可以采用致病性分类网络(诸如灵长类动物ai)将基因内的致病性变体与良性变体分类和/或分离。特别地,临床基因组测序已成为患有罕见遗传疾病的患者的护理标准。罕见遗传疾病通常(如果不是主要)由高度有害的罕见突变引起,这些罕见突变通常由于它们的严重程度而更容易检测到。然而,导致常见遗传病的那些罕见突变,由于它们影响微弱且数量众多,在很大程度上仍未被表征。
[0140]
考虑到这一点,可能期望理解罕见突变与常见疾病之间的机制,并且研究人类突变的进化动力学,特别是在如本文所讨论的变体的致病性评分的背景下。在人类群体的进化期间,新变体不断地通过新生突变生成,而其中一些变体也由于自然选择而被去除。如果人类群体大小不变,受这两种力量影响的变体的等位基因频率最终会达到平衡。考虑到这一点,可能期望使用观察到的等位基因频率来确定自然选择在任何变体上的严重程度。
[0141]
然而,人类群体在任何时候都不是处于稳定状态,相反,自农业出现以来,人类群体一直在指数式地扩张。因此,根据本文所讨论的某些方法,前向时间模拟可以用作研究两种力量对变体的等位基因频率分布的影响的工具。这种方法的各方面是关于图8中示出的步骤来描述的,在讨论得出最佳的前向时间模型参数时,可以参考和返回到该步骤。
[0142]
考虑到这一点,使用新生突变率280的中性进化的前向时间模拟可以用作使变体的等位基因频率随时间的分布而进行建模(步骤282)的一部分。作为基线,假设中性进化可以模拟前向时间群体模型。模型参数300通过将模拟的等位基因频谱(afs)304与人类基因组中观察到的同义突变的afs(同义afs 308)进行拟合(步骤302)得出。然后,使用一组最佳模型参数300(即,对应于最佳拟合的那些参数)生成的模拟afs 304可以与如本文所讨论的其他概念诸如变体致病性评分结合使用,以得出有用的临床信息。
[0143]
由于罕见变体的分布是最感兴趣的,因此在该示例性具体实施中,人类群体的进化史在该模拟中被简化为四个具有不同增长率的指数扩张阶段,如图9中所示,该图是简化的人类群体扩张模型(即简化的进化史278)的示意性图示。在该示例中,统计群体大小与有效群体大小之间的比率可以表示为r,并且初始有效群体大小表示为ne0=10,000。可以假设每一代花费约30年。
[0144]
在该示例中,在第一阶段采用了长预烧期(约3,500代),有效群体大小的变化小。群体大小变化可以表示为n。由于预烧后的时间未知,因此这个时间可以表示为t1,并且在t1的有效群体大小表示为10,000*n。在预烧期间的增长率284是g1=n^(1/3,500)。
[0145]
在公元1400年,世界各地的统计群体大小估计已经为约3.6亿。在公元1700年,统计群体大小增加到约6.2亿,并且在公元2000年,统计群体大小为62亿。基于这些估计,可以得出每个阶段的增长率284,如表4中所示:
[0146]
表4:模拟方案
[0147][0148]
对于第j代286,从上一代随机采样nj个染色体以形成新一代群体,其中nj=gj*n
j-1
,其中gj是第j代的增长率284。大部分的突变在染色体采样期间从上一代继承。然后根据新生突变率(μ)280,将新生突变应用于这些染色体。
[0149]
关于新生突变率280,根据某些具体实施,可以根据以下方法或等效方法得出这些新生突变率。特别地,在一个此类具体实施中,利用文献来源的全基因组测序,获得了三个大型的亲子三联体数据集,共计8,071个三联体(halldorsson集(2976个三联体)、goldmann集(1291个三联体)和sanders集(3804个三联体))。合并这8,071个三联体,获得映射到基因间区域的新生突变,并得出192个三核苷酸背景配置中每一者的新生突变率280。
[0150]
将这些突变率估计与其他文献中的突变率(kaitlin从1,000个基因组计划的基因间区域得出的突变率)进行比较,如图10中所示。相关性为0.9991,其中目前的估计值通常低于kaitlin的突变率,如表5所示(其中cpgti=cpg位点处的转换突变,非cpgti=非cpg位点处的转换突变,tv=颠换突变)。
[0151]
表5-突变率比较
[0152][0153]
关于cpg岛的突变率,cpg位点处的甲基化水平基本上会影响突变率。为了精确地
计算cpgti突变率,应考虑那些位点处的甲基化水平。考虑到这一点,在示例性具体实施中,可以根据以下方法计算突变率和cpg岛。
[0154]
首先,通过使用全基因组亚硫酸氢盐测序数据(从roadmap epigenomics项目获得)来评价甲基化水平对cpg突变率的影响。提取每个cpg岛的甲基化数据,并对10个胚胎干细胞(esc)样本进行平均。然后基于10个定义的甲基化水平将那些cpg岛分成10个区段,如图11中所示。分别计算落入基因间区域和外显子区域两者中的每个甲基化区段中的cpg位点的数量以及观察到的cpg转换变体的数量。每个甲基化区段中的cpg位点处的预期转换变体数量计算为cpgti变体的总数乘以该甲基化区段中的cpg位点的比例。如图11中所示,观察到了观察到的cpg突变数量与预期的cpg突变数量的比率随着甲基化水平的增加而增加,并且在高甲基化水平与低甲基化水平之间,观察到的cpgti突变数量/预期的cpgti突变数量的比率的变化约为五倍。
[0155]
cpg位点被分为两种类型:(1)高甲基化(如果平均甲基化水平》0.5);和(2)低甲基化(如果平均甲基化水平≤0.5)。分别针对高甲基化水平和低甲基化水平计算了8个cpgti三核苷酸背景中的每一者的新生突变率。对8个cpgti三核苷酸背景进行平均,获得cpgti突变率:高甲基化为1.01e-07,并且低甲基化为2.264e-08,如表6所示。
[0156]
然后拟合外显子组测序数据的等位基因频谱(afs)。在一个此类样本具体实施中,假设100,000个独立位点并使用参数t1、r和n的各种组合来执行模拟,其中考虑t1∈(330、350、370、400、430、450、470、500、530、550),r∈(20、25、30、...、100、105、110),和n∈(1.0、2.0、3.0、4.0、5.0)。
[0157]
使用不同的新生突变率,即cpgti、非cpgti和tv(如表6所示),分别对三大类突变中的每一者进行模拟。对于cpgti,分别模拟高甲基化水平和低甲基化水平,并通过应用高甲基化位点或低甲基化位点的比例作为权重来合并两个afs。
[0158]
对于参数的每个组合以及每个突变率,模拟人类群体直到今天。然后随机采样一千个约246,000条染色体的集(步骤288)(例如,从靶或最后一代290),对应于gnomad外显子组的样本大小。然后,通过对一千个相应的采样集294进行平均(步骤292)来生成模拟的afs 304。
[0159]
在验证方面,从基因组聚集数据库(gnomad)v2.1.1获取人类外显子组多态性数据,该基因组聚集数据库收集了来自全世界八个亚群的123,136个个体的全外显子组测序(wes)数据(http://gnomad.broadinstitute.org/)。排除没有通过滤波器、中位覆盖率《15或落入低复杂性区域或节段性重复区域内的变体,其中区域的边界在从https://storage.googleapis.com/gnomad-public/release/2.0.2/readme.txt下载的文件中定义。保留映射到由ucsc基因组浏览器针对hg19构建定义的规范编码序列的变体。
[0160]
gnomad的同义等位基因频谱308通过计算七个等位基因频率类别中的同义变体的数量(步骤306)生成,这些类别包括单子、双子、3≤等位基因数(ac)≤4、...和33≤ac≤64。由于重点是罕见变体,所以移除了ac》64的变体。
[0161]
应用似然比检验来评价(步骤302)罕见同义变体的模拟afs 304与gnomad afs(即同义afs 308)在三个突变类别中的拟合。如图12a至图12e中所示,皮尔逊卡方统计量的热图(对应于-2*log似然比)示出该示例中的最佳参数组合(即最佳模型参数300)发生在t1=530,r=30和n=2.0处。图13示出用对参数组合模拟的afs 304模仿了观察到的gnomad afs
(即同义afs 308)。估计的t1=530代与考古学一致,考古学确定农业的广泛采用时期是在约12,000年前(即新石器时代的开始)。普查群体大小和有效群体大小之间的比率低于预期,这意味着人类群体的多样性实际上相当高。
[0162]
在一个示例性具体实施中,并且参考图14,为了解决前向时间模拟背景中的选择效应,在前面的模拟结果中检索人类扩张史中最可能的人口统计模型。基于这些模型,选择被掺入模拟,其具有选自{0,0.0001,0.0002,...,0.8,0.9}的不同的选择系数值(s)320。对于每一代286,在继承了亲本群体的突变和应用新生突变后,根据选择系数320随机清除一小部分突变。
[0163]
为了改善模拟的精确性,对192个三核苷酸背景中的每一者使用从8071个三联体(即亲子三联体)得到的它们的特定新生突变率230来应用单独的模拟(步骤282)。在选择系数320的每个值和每个突变率280下,模拟初始大小为约20,000条染色体的人类群体,扩展到今天。从所得群体(即目标或最终一代290)随机采样一千个集294(步骤288)。每个集含有约500,000条染色体,对应于gnomad topmed uk生物库的样本大小。对于8个cpgti三核苷酸背景中的每一者,分别模拟高甲基化水平和低甲基化水平。通过应用高甲基化位点或低甲基化位点的比例作为权重来合并两个afs。
[0164]
在获得192个三核苷酸背景的afs后,这些afs被外显子组中的192个三核苷酸背景的频率加权以生成外显子组的afs。对36个选择系数中的每一者重复该程序(步骤306)。
[0165]
然后得出选择-损耗曲线312。特别地,随着对突变的选择压力(s)的上升,预计变体将被逐渐损耗。利用在各自选择水平下的模拟afs(304),限定表征为“损耗”的度量,以测量与中性进化(即没有选择)下的场景相比,通过纯化选择消灭的变体比例。在该示例中,损耗可以表征为:
[0166]
(1)
[0167]
生成36个选择系数中的每一者的损耗值316(步骤314),以绘制图15中所示的选择-损耗曲线312。对该曲线可以应用内插以获得与任何损耗值相关联的估计选择系数。
[0168]
考虑到前面关于使用前向时间模拟的选择和损耗表征的讨论,这些因素可以用于估计基于致病性(例如,灵长类动物ai或pai)评分的错义变体的选择系数。
[0169]
举例来说,并且参考图16,在一项研究中,通过从近似约200,000个个体获取变体等位基因频率数据来生成数据(步骤350),该变体等位基因频率数据包括122,439个gnomad外显子组和13,304个gnomad全基因组测序(wgs)样本(去除topmed样本之后)、约65k topmed wgs样本和约50k uk生物库wgs样本。重点是每个数据集中的罕见变体(af《0.1%)。根据gnomad外显子组覆盖率,所有变体都需要通过滤波器并且中值深度≥1。排除示出杂合子过多的变异体,由《-0.3的近交系数限定。对于全外显子组测序,如果随机森林模型生成的概率≥0.1,则排除变体。对于wgs样本,如果随机森林模型生成的概率≥0.4,则排除变体。对于蛋白截断变体(ptv)(其包括无义突变)、剪接变体(即那些发生在剪接供体或受体位点处的变体)和移码,应用额外的滤波器,即基于由功能缺失转录物效应估计器(loftee)算法估计的低置信度进行过滤。
[0170]
合并三个数据集中的变体以形成最终数据集352以计算损耗度量。根据以下重新计算等位基因频率以对三个数据集进行平均:
[0171]
(2)其中i表示数据集索引。如果变体没有出现在一个数据集中,则该数据集的ac就被分配为零(0)。
[0172]
关于无义突变和剪接变体的损耗,可以计算与每个基因中的预期数量相比,通过纯化选择损耗的ptv的比例。由于在计算基因中预期的移码数量方面有困难,所以重点反而放在无义突变和剪接变体上,表示为功能缺失突变(lof)。
[0173]
计算合并数据集中的每个基因的无义突变和剪接变体的数量(步骤356),以得到观察到的lof数量360(以下公式的分子)。为了计算预期的lof数量364(步骤362),从gnomad数据库网站下载含有约束度量的文件(https://storage.googleapis.com/gnomad-public/release/
[0174]
2.1.1/constraint/gnomad.v2.1.1.lof_metrics.by_gene.txt.bgz)。将合并数据集中观察到的同义变体用作基线,并且通过乘以预期的lof数量和来自gnomad的预期的同义变体数量的比率来转换为预期的lof数量364。然后计算损耗度量380(步骤378)并验证在[0,1]内。如果小于0,则分配0,反之亦然。以上可以表示为:
[0175]
(3)其中
[0176]
基于lof的损耗度量380,可以使用相应的选择-损耗曲线312得出每个基因的lof的选择系数的估计值390(步骤388)。
[0177]
关于损耗380在错义变体中的计算(步骤378),在具体实施的一个示例中(图17中示出),针对基因数据集418得出的预测致病性评分(例如,灵长类动物ai或pai评分)的百分位数420用于表示每个基因内的所有可能错义变体。由于本文所述的致病性评分测量变体的相对适合度,因此可以预期,在强负选择下的基因中,错义变体的致病性评分往往更高。相反,在中等选择的基因中,预期评分可能会更低。因此,使用致病性评分(例如pai评分)的百分位数420来避免对基因的整体影响是合适的。
[0178]
对于每个基因,将致病性评分百分位数420(本示例中的pai百分位数)分为(步骤424)10个区段(例如(0.0,0.1]、(0.1,0.2]、...、(0.9,1.0]),并计算落在每个区段中的观察到的错义变异的数量428(步骤426)。损耗度量380的计算430与lof的计算类似,除了针对10个区段中的每个区段计算相应的损耗度量380以外。来自gnomad的错义/同义变体的校正因子被应用于每个区段中预期的错义变体数量,与用于本文所述的lof损耗的计算方式类似。以上可以表示为:
[0179]
(4)其中
[0180]
基于每个基因内10个区段的损耗,可以得出致病性评分的百分位数420与损耗度量380之间的关系436(步骤434)。在一个示例中,每个区段的百分位数中值被确定并且平滑样条拟合至10个区段的中间点。图18和图19中分别相对于基因brca1和ldlr的两个示例示
出了这种示例,这示出了损耗度量随着致病性评分百分位数的增加以基本上线性方式增加。
[0181]
基于该方法,对于每一个可能的错义变体,可以基于其致病性百分位数评分420,使用基因特异性拟合样条来预测其损耗度量380。然后可以使用选择-损耗关系(例如,选择-损耗曲线312或其他拟合函数)来估计该错义变体的选择系数320。
[0182]
另外,可以分别估计有害罕见错义变体和ptv的预期数量。例如,可能感兴趣的是估计正常个体可能在它们的编码基因组中可能携带的有害罕见变体的平均数量。对于具体实施的该示例,重点是af《0.01%的罕见变体。为了计算每个个体的有害罕见ptv的预期数量,其等于是对选择系数320超过某个阈值的ptv的等位基因频率求和,如下所示:
[0183]
(5)e[#ptv|s》k]=∑af|s》k
[0184]
由于ptv包括无义突变、剪接变体和移码,所以针对每个类别分别进行计算。从下表6中所示的结果可以观察到,每个个体具有约1.9个罕见ptv,其中s》0.01(等于或差于brca1突变)。
[0185]
表6.不同选择系数截止值下的有害罕见ptv的预期数量
[0186] s》0.2s》0.1s》0.05s》0.02s》0.01s》0.001e[无义变体数量]0.00370.02090.07540.30780.64590.9959e[剪接变体数量]0.00320.01530.04710.16390.33610.5100e[移码数量]0.02340.06350.15740.49440.93381.3745e[ptv数量]0.03030.09960.27990.96621.91592.8804
[0187]
另外,通过对选择系数320超过不同阈值的罕见错义的等位基因频率求和来计算有害罕见错义变体的预期数量:
[0188]
(6)e[#missense|s》k]=∑af|s》k
[0189]
从下表7中所示的结果可以看出,在s》0.01的情况下,错义变异是ptv的约4倍。
[0190]
表7.在不同选择系数截止值下的有害罕见错义变体的预期数量
[0191][0192]
vi.使用致病性评分来估计遗传疾病患病率
[0193]
为了促进错义变体的致病性评分在临床环境中的采用和使用,研究了在那些临床目的基因中致病性评分与临床疾病患病率之间的关系。特别地,开发了使用基于致病性评分的各种度量来估计遗传疾病患病率的方法。本文描述了基于致病性评分来预测遗传疾病患病率的两种此类方法的非限制性示例。
[0194]
关于本研究采用的数据的初步背景,本文提到的discovehr数据是regeneron遗传学中心与geisinger卫生系统之间的合作,该合作旨在通过整合全外显子组测序和来自
geisinger的mycode社区健康计划中50,726名成人参与者的纵向电子健康记录(ehr)的临床表型来促进精准医疗。考虑到这一点,并且参考图20,定义了76个基因(g76)(即基因数据集450),其包括美国医学遗传学和基因组学学院(acmg)建议中确定的56个基因和25种医学病况,用于识别和报告临床可操作的遗传学发现。评价g76基因内这些潜在的致病性变体456的患病率,这些潜在的致病性变体包括具有clinvar“致病性”分类的变体以及已知和预测的功能缺失变体。如本文所讨论的,得出每个基因中那些clinvar致病性变体456的累积等位基因频率(caf)466(步骤460)。从文献来源获得76个基因中大多数基因的近似遗传疾病患病率。
[0195]
考虑到该背景,开发了两个基于致病性评分206(例如灵长类动物ai或pai评分)用于预测遗传疾病患病率的方法的示例。在这些方法中,并且参考图21,采用基因特异性致病性评分阈值212(决策框210)来确定基因的错义变体200是致病性的(即,致病性变体220)还是非致病性的(即,非致病性变体476)。在一个示例中,如果致病性评分206大于特定基因中致病性评分的75个百分位数,则定义预测有害变体的截止值,但是可以根据需要采用其他截止值。遗传疾病患病率度量被定义为那些预测的有害错义变体的预期累积等位基因频率(caf)480,如步骤478处得出的。如图22中所示,该度量与clinvar致病性变体的discovehr累积af的斯皮尔曼相关性为0.5272。类似地,图23示出了该度量与疾病患病率的斯皮尔曼相关性为0.5954,这意味着良好的相关性。因此,遗传疾病患病率度量(即,那些预测的有害错义变体的预期累积等位基因频率(caf))可以用作遗传疾病患病率的预测因子。
[0196]
关于计算每个基因的这种遗传疾病患病率度量,描绘为图21的步骤478,评价了两种不同的方法。在第一方法中,并且参考图24,最初获得有害错义变体220列表的三核苷酸背景配置500(步骤502)。在本背景下,这可以对应于获得所有可能的错义变体,其中这些致病性变体220是致病性评分206超过该基因中的第75个百分位数阈值(或其他合适的截止值)的那些。
[0197]
对于每个三核苷酸背景500,执行如本文所述的前向时间模拟(步骤502),以生成预期(即,模拟)等位基因频谱(afs)304,其中假设选择系数320等于0.01并使用该三核苷酸背景的新生突变率280。在该方法的一个具体实施中,该模拟模拟了约400k染色体中(约200k样本)的100,000个独立位点。因此,在此类背景下,特定三核苷酸背景500的预期afs 304是模拟的afs/100,000*,该三核苷酸在有害变体列表中的出现率。对192个三核苷酸求和产生该基因的预期afs 304。根据该方法,特定基因的遗传疾病患病率度量(即预期caf 480)被定义为该基因的预期afs 304中模拟的罕见等位基因频率(即af≤0.001)的总和(步骤506)。
[0198]
根据第二方法得出的遗传疾病患病率度量与使用第一方法得出的遗传疾病患病率度量相似,但在有害错义变体列表的定义方面有所不同。根据第二方法,并且参考图25,如果致病性变体220的估计损耗≥该基因中蛋白截断变体(ptv)损耗的75%,则将这些致病性变体定义为每个基因的预测有害变体,如本文所讨论的。举例来说,并且如图25中所示,在该背景下,可以测量目的变体200的致病性评分206(步骤202)。如本文所讨论的,致病性评分206可以用于使用预先确定的致病性百分位数-损耗关系436来估计(步骤520)消耗522。然后可以将估计的损耗522与损耗阈值或截止值524进行比较(决策框526),以将非致病性变体476与被认为是致病性变体220的那些分离。一旦确定了致病性变体220,处理就可
以如上面在步骤478处所讨论的进行以得出预期caf 480。
[0199]
关于使用该第二方法得出的遗传疾病患病率度量,图26示出根据第二方法计算的遗传疾病患病率与clinvar致病性变体的discovehr累积af的斯皮尔曼相关性为0.5208。类似地,图27示出了根据第二方法计算的遗传疾病患病率度量与疾病患病率的斯皮尔曼相关性为0.4102,这意味着良好的相关性。因此,使用第二方法计算的度量也可以用作遗传疾病患病率的预测因子。
[0200]
vii.重新校准致病性评分
[0201]
如本文所述,根据本教导生成的致病性评分是使用主要基于变体周围的dna侧翼序列、物种间的保守和蛋白质二级结构训练的神经网络得出的。然而,与致病性评分(例如,灵长类动物ai评分)相关的变异可以很大(例如,约0.15)。另外,本文所讨论的用于计算致病性评分的通用模型的某些具体实施不利用训练期间在人类群体中观察到的等位基因频率的信息。在某些情况下,一些具有高致病性评分的变体可能会出现等位基因数》1的情况,这意味着需要根据等位基因数对这些致病性评分进行罚分。考虑到这一点,可能有用的是重新校准致病性评分以解决此类情况。在本文所讨论的一个示例性实施方案中,重新校准方法的重点可以是变体的致病性评分的百分位数,因为这些可能更稳健并且受到施加在整个基因上的选择压力的影响较少。
[0202]
考虑到这一点,并且参考图28,在重新校准方法的一个示例中,建模真实的致病性百分位数以便允许评估和考虑观察到的致病性评分百分位数550中的噪声。在该建模过程中,可以假设真实的致病性百分位数是在(0,1]内离散均匀分布的(例如,它们有100个值,[0.01,0.02,...,0.99,1.00])。观察到的致病性评分百分位数550可以假定为以真实的致病性评分百分位数为中心,加上一些噪声项,遵循以下正态分布,具有标准偏差为0.15:
[0203]
(7)obsai~trueai e,e~n(0,sd=0.15)
[0204]
在该背景下观察到的致病性评分百分位数550的分布554是真实致病性评分百分位数叠加高斯噪声的离散均匀分布,如图29中所示,其中每条线表示以真实致病性评分百分位数的每个值为中心的正态分布。该观察到的致病性评分百分位数叠加高斯噪声的离散均匀分布556的密度图如图30中所示,并且其在步骤562处确定的累积分布函数(cdf)558如图31所示。从该cdf 558中,将累积概率分为100个区间,并生成观察到的致病性评分百分位数550的分位数568(步骤566)。
[0205]
为了使具有真实致病性评分百分位数的变体(图32中的x轴)落入观察到的致病性评分百分位数区间(y轴)的概率可视化,该100
×
100概率矩阵的每一行可被归一化为总计一,并将结果绘制为热图572(图32)(步骤570)。热图572上的每个点测量观察到的致病性评分百分位数550区间内的变体实际来自真实致病性评分百分位数的概率(即具有真实致病性评分百分位数(x轴)的变体落入观察到的致病性评分百分位数区间(y轴)的概率)。
[0206]
转到图33,对于错义变体,使用本文所述的方法来确定每个基因中10个区段中的每个区段的损耗度量522。在该示例中,并且如本文其他地方所讨论的,作为分区段过程的一部分,可以计算出目的变体200的致病性评分206(步骤202)。相应的致病性评分206继而可以用于基于预先确定的致病性评分百分位数评分-损耗关系436来估计损耗522(步骤520)。
[0207]
该损耗度量522测量可以通过纯化选择来去除落入每个区段内的变体的概率。图
34和图35中示出了相对于基因scn2a的这种示例。特别地,图34描绘了scn2a基因的错义变体在10个区段的百分位数上的损耗概率。变体在选择中存活的概率可以定义为(1-损耗),表示为存活概率580,并在步骤582处确定。如果该概率小于0.05,则可以设置为0.05。图35描绘了scn2a基因错义变体在10个区段的百分位数上的存活概率580。在两个附图中,在x轴上1.0处所描绘的菱形表示ptv。
[0208]
根据一个具体实施,对存活概率与区段(例如10个区段)中每个区段的致病性评分百分位数中值进行平滑样条拟合(步骤584),并产生致病性评分的每个百分位数的存活概率。根据该方法,这就构成了存活概率校正因子590,意味着致病性评分206的百分位数越高,变体在纯化选择中存活的机会就越小。在其他具体实施中,可以采用其它技术,诸如内插来代替拟合平滑样条。然后可以根据该校正因子590对那些观察到的变体的高致病性评分206进行罚分或校正。
[0209]
考虑到前述情况,并且转到图36,可以采用存活概率校正因子590来执行重新校准。举例来说,并且在概率矩阵的背景下,该概率矩阵可以可视化为如前所示的热图572,对于特定的基因,使热图572的每一行(例如,具有50
×
50、100
×
100等维度的概率矩阵)乘以相应的存活概率校正因子590(例如,100个值的向量)(步骤600),以通过该基因的预期损耗减少热图572的值。然后将热图的每行重新校准为总计1。然后可以绘制和显示重新校准的热图596,如图37中所示。在该示例中重新校准的热图596在x轴上显示真实致病性评分百分位数,并且重新校准的观察到的致病性评分百分位数在y轴上。
[0210]
真实致病性评分百分位数被分为区段(步骤604)(即1%至10%(重新校准的热图596的前10列)合并为第一区段)、11%至20%(重新校准的热图596的下一个10列)合并为第二区段、...、等等),这表示变体可能来自真实致病性评分百分位数区段中的每个真实致病性评分百分位数区段的概率。对于具有观察到的致病性评分百分位数(例如,x%,对应于重新校准的热图596的第x行)的该基因的变体,可以获得该变体可能落入真实致病性评分百分位数区段(例如,10个区段)中的每个区段内的概率(步骤608)。这可以表示为对每个区段的变体贡献612。
[0211]
在该示例中,这些区段(例如,10个区段)中的每个区段内的错义变体620的预期数量(在步骤624得出)是在相应基因中所有观察到的错义变体对该区段的变体贡献之和。基于基因的落入每个区段内的错义变体620的对预期数量,本文所讨论的错义变体的损耗公式可以用于计算每个错义区段的校正损耗度量634(步骤630)。这在图38中示出,其中绘制了每个百分位数区段的校正损耗度量的示例。特别地,图38描绘了基因scn2a中重新校准的损耗度量与原始损耗度量的比较。在x轴上1.0处绘制的菱形指示ptv的损耗。
[0212]
在这种重新校准致病性评分206的方式中,对致病性评分206的百分位数的噪声分布进行建模,并且降低预测的损耗度量522的噪声。这可以帮助减轻噪声对如本文所讨论的错义变体中选择系数320的估计的影响。
[0213]
viii.神经网络入门知识
[0214]
神经网络
[0215]
在前述讨论中,在致病性分类或评分网络的背景下参考神经网络架构和使用的各个方面。虽然对于那些希望了解和使用本文所讨论的致病性分类网络的人来说,对这些神经网络设计和使用的各个方面的广泛知识被认为是没有必要的,但为了那些希望获得更多
细节的人的利益,以下神经网络入门知识被提供作为额外的参考。
[0216]
考虑到这一点,术语“神经网络”在一般意义上可以理解为计算结构,它被训练用于接收相应的输出,并基于其训练生成输出,诸如致病性评分,其中输入被修改、分类或以其他方式处理。此类结构可以被称为神经网络,因为它是以生物大脑为模型,结构的不同节点等同于“神经元”,该节点可以与广泛的其他节点相互连接以允许节点之间复杂的潜在相互连接。一般来讲,神经网络可以被认为是机器学习的一种形式,因为通路和相关节点通常是通过示例来训练的(例如,使用输入和输出是已知的或成本函数可以被优化的样本数据),并且在使用神经网络和其性能或输出被修改或重新训练时,可以随着时间的推移学习或进化。
[0217]
考虑到这一点并作为进一步说明,图39描绘了神经网络700的示例的简化视图,这里是具有多层702的全连接神经网络700。如本文所述和图39中所示,神经网络700是在彼此之间交换消息的互连人工神经元704(例如,a1、a2、a3)的系统。所示出的神经网络700具有三个输入、隐藏层中的两个神经元和输出层中的两个神经元。隐藏层具有激活函数f(
●
),并且输出层具有激活函数g(
●
)。连接具有相关联的数字权重(例如,w
11
、w
21
、w
12
、w
31
、w
22
、w
32
、v
11
、v
22
),这些数字权重在训练过程期间被调整,使得当输入经过训练处理的输入时,适当训练的网络会做出正确的反应。输入层处理原始输入,隐藏层基于输入层与隐藏层之间的连接的权重来处理来自该输入层的输出。输出层获得来自隐藏层的输出,并且基于隐藏层与输出层之间的连接的权重对该输出进行处理。在一种背景下,网络700包括多层的特征检测神经元。每层具有许多神经元,该神经元对来自先前层的输入的不同组合做出响应。这些层可以被构造成使得第一层检测输入图像数据中的一组基元模式,第二层检测模式中的模式,第三层检测那些模式中的模式。
[0218]
卷积神经网络
[0219]
神经网络700可以基于其操作模式分类为不同类型。举例来说,卷积神经网络是神经网络的一种类型,其采用或掺入一个或多个卷积层,而不是密集或密集连接层。特别地,密集连接层在其输入特征空间中学习全局模式。相反,卷积层学习局部模式。举例来说,在图像的情况下,卷积层可以学习在小窗口或输入子集中发现的模式。这种对局部模式或特征的关注给予了卷积神经网络两个有用的特性:(1)它们学习的模式是平移不变的,以及(2)它们可以学习模式的空间层次结构。
[0220]
关于对第一特性,在数据集的一部分或子集中学习某种模式后,卷积层可以在相同或不同数据集的其他部分中识别该模式。相比之下,如果该模式出现在其他地方(例如,在新的位置处),则密集连接网络将不得不重新学习该模式。对特性使得卷积神经网络数据是有效率的,因为它们需要更少的训练样本来学习表示,然后该表示可以被泛化,以便在其他背景和地点中识别。
[0221]
关于第二特性,第一卷积层可以学习小的局部模式,而第二卷积层则学习由第一层的特征构成的更大模式,以此类推。这允许卷积神经网络有效地学习日益复杂和抽象的视觉概念。
[0222]
考虑到这一点,卷积神经网络能够通过将布置在许多不同层702中的人工神经元704层与激活函数相互连接(使各层相互依赖)来学习高度非线性映射。其包括一个或多个散布有一个或多个子采样层和非线性层的卷积层,该卷积层后面通常有一个或多个全连接
层。卷积神经网络的每个元素都从前一层的一组特征接收输入。卷积神经网络的学习是同步进行的,因为同一特征映射中的神经元具有相同的权重。这些局部共享的权重降低了网络的复杂性,使得当多维输入数据进入网络时,卷积神经网络避免了特征提取和回归或分类过程中的数据重建的复杂性。
[0223]
卷积在称为特征映射的3d张量上操作,该张量具有两个空间轴(高度和宽度)以及深度轴(也称为通道轴)。卷积操作从其输入特征映射提取斑块,并对所有这些斑块进行相同的转换,从而产生输出特征映射。对输出特征映射仍然是3d张量:其具有宽度和高度。其深度可以是任意的,因为输出深度是层的参数,并且该深度轴中的不同通道代表滤波器。滤波器编码输入数据的特定方面。
[0224]
例如,在其中第一卷积层接收给定大小(28、28、1)的特征映射,并输出一定大小(26、26、32)的特征映射的示例中:该特征映射在其输入上计算32个滤波器。这32个输出通道中的每一个都含有26
×
26的数值网格,这是滤波器在输入上的响应映射,指示该滤波器模式在输入中不同位置处的响应。这就是术语特征映射在对背景下的含义:深度轴上的每一个维度都是特征(或滤波器),并且2d张量输出[:,:,n]是这个滤波器在输入上的响应的2d空间映射。
[0225]
考虑到前述情况,卷积由两个关键参数限定:(1)从输入提取的斑块的大小,和(2)输出特征映射的深度(即通过卷积计算的滤波器的数量)。在典型的具体实施中,这些以深度32开始,继续至深度64,并且终止于深度128或256,但是某些具体实施可以与此进展不同。
[0226]
转到图40,描绘了卷积过程的视觉概述。如对示例所示,卷积的工作方式是在3d输入特征映射720上滑动(例如,增量移动)这些窗口(诸如大小为3
×
3或5
×
5的窗口),在每个位置处停止,并提取周围特征的3d斑块722(形状(窗口_高度、窗口_宽度、输入_深度))。然后,每个此类3d斑块722被转化(经由与相同的学习权重矩阵的张量乘积,称为卷积内核)为形状(输出_深度)的1d向量724(即变换斑块)。然后,这些矢量724在空间上重新组装成形状(高度、宽度、输出_深度)的3d输出特征映射726。输出特征映射726中的每个空间位置都对应于输入特征映射720中的相同位置。例如,在3
×
3窗口的情况下,向量输出[i,j,:]来自3d斑块输入[i-1:i 1,j-1:j 1,:]。
[0227]
考虑到前述情况,卷积神经网络包括卷积层,这些卷积层在输入值与卷积滤波器(权重矩阵)之间执行卷积操作,这些滤波器在训练过程期间通过多次梯度更新迭代学习。其中(m、n)是滤波器的大小,并且w是权重矩阵,卷积层通过计算点积wπx b来执行w与输入x的卷积,其中x是x的实例,b是偏差。卷积滤波器在输入上滑动的步长大小称为步幅,并且滤波器区域(m
×
n)称为感受场。相同的卷积滤波器应用于输入的不同位置,这减少了所学习的权重的数量。它还允许位置不变学习,即,如果输入中存在重要模式,则无论该模式在序列中的何处,卷积滤波器都可以学习它。
[0228]
训练卷积神经网络
[0229]
从前述讨论中可以理解,卷积神经网络的训练是执行给定目的任务的网络的重要方面。对卷积神经网络进行调整或训练,使得输入数据导致特定的输出估计。使用基于输出估计与基准真值的比较的反向传播来调整卷积神经网络,直到输出估计渐进地匹配或接近基准真值为止。
[0230]
通过基于基准真值与实际输出之间的差异(即,误差,δ)调整神经元之间的权重来训练卷积神经网络。如本文所述,训练过程中的中间步骤包括使用卷积层从输入数据生成特征向量。计算关于每层中的权重(在输出处开始)的梯度。这称为后向传递或后退。使用负梯度和先前权重的组合来更新网络中的权重。
[0231]
在一个具体实施中,卷积神经网络150使用随机梯度来更新算法(诸如adam),该算法通过梯度下降来执行误差的后向传播。该算法包括计算网络中所有神经元的激活,从而产生用于前向传递的输出。然后,计算每层的误差和正确权重。在一个具体实施中,卷积神经网络使用梯度下降优化来计算跨所有层的误差。
[0232]
在一个具体实施中,卷积神经网络使用随机梯度下降(sgd)来计算成本函数。sgd通过仅从一个随机数据对计算出损失函数中的权重来近似关于其的梯度。在其他具体实施中,卷积神经网络使用不同的损失函数,诸如euclidean损失和softmax损失。在其他具体实施中,卷积神经网络使用adam随机优化器。
[0233]
卷积层
[0234]
卷积神经网络的卷积层用作特征提取器。特别地,卷积层充当能够学习并将输入数据分解为分层特征的自适应特征提取器。卷积操作通常涉及“内核”,该内核用作输入数据上的滤波器,从而产生输出数据。
[0235]
卷积操作包括在输入数据上滑动(例如,增量移动)内核。对于内核的每个位置,将内核和输入数据的重叠值相乘,并添加结果。乘积之和是输入数据中内核居中的点处的输出数据的值。从许多内核产生的不同输出称为特征映射。
[0236]
一旦对卷积层进行了训练,就可以将它们应用于对新的推理数据执行识别任务。由于卷积层从训练数据学习,因此它们避免了显式特征提取并且隐式地从训练数据中学习。卷积层使用卷积滤波器内核权重,这些卷积滤波器内核权重被确定并更新为训练过程的一部分。卷积层提取输入的不同特征,这些不同特征在较高层处进行组合。卷积神经网络使用不同数量的卷积层,其中每个卷积层具有不同的卷积参数,诸如内核大小、步幅、填充、特征映射的数量和权重。
[0237]
子采样层
[0238]
卷积神经网络的具体实施的其他方面可以涉及层的子采样。在对背景下,子采样层减少了通过卷积层提取的特征分辨率,使提取特征或特征映射对噪声和变形稳健。在一个具体实施中,子采样层采用两类池化操作:平均池化和最大池化。池化操作将输入分成不重叠的空间或区域。对于平均池化,计算该区域中数值的平均值。对于最大池化,选择数值中的最大值。
[0239]
在一个具体实施中,子采样层包括上一层中一组神经元的池化操作:在最大池化中将其输出映射到仅一个输入,并且在平均池化中将其输出映射到输入的平均值。在最大池化中,池化神经元的输出是输入内驻留的最大值。在平均池化中,池化神经元的输出是与输入神经元集一起驻留的输入值的平均值。
[0240]
非线性层
[0241]
与本概念相关的神经网络具体实施的另一方面是使用非线性层。非线性层使用不同的非线性触发函数来对每个隐藏层上可能的特征发出不同的识别信号。非线性层使用各种具体函数来实现非线性触发,该触发包括但不限于修正线性单元(relu)、双曲正切、双曲
正切的绝对值、s形和连续触发(非线性)函数。在一个具体实施中,relu激活实现函数y=max(x,0)并且保持层的输入和输出大小相同。使用relu的一个潜在优点是卷积神经网络的训练速度可能快了很多倍。relu是非连续的、非饱和的激活函数,如果输入值大于零,则该函数相对于输入是线性的,否则为零。
[0242]
在其他具体实施中,卷积神经网络可以使用功率单元激活函数,该函数是连续的、非饱和函数。如果c为奇数,则功率激活函数能够产生x和y-反对称激活,如果c为偶数,则功率激活函数能够产生y-对称激活。在一些具体实施中,该单元产生非修正线性激活。
[0243]
在其他具体实施中,卷积神经网络可以使用s形单位激活函数,该函数是连续的饱和函数。s形单元激活函数不产生负激活,并且仅相对于y-轴反对称。
[0244]
残差连接
[0245]
卷积神经网络的另一特征是使用经由特征映射添加在下游重新注入先前信息的残差连接,如图41所示。如对示例所示,残差连接730包括通过将过去的输出张量添加到稍后输出张量来将先前表示再注入到下游数据流中,这有助于防止沿着数据处理流的信息损失。残差连接730包括将较早层的输出作为输入用于较后层,从而在顺序网络中有效地创建快捷方式。较早输出与稍后激活相加,而不是连接到稍后激活,这假设两个激活的尺寸相同。如果它们具有不同的尺寸,那么可以使用线性变换以将较早激活重塑为目标形状。残差连接解决了任何大规模深度学习模型中可能存在的两个问题:(1)消失梯度和(2)表示瓶颈。一般来讲,向具有超过十层的任何模型添加残差连接730可能是有益的。
[0246]
残差学习和跳跃连接
[0247]
在与本技术和方法相关的卷积神经网络中存在的另一个概念是使用跳跃连接。残差学习的原理是残差映射比原始映射更容易学习。残差网络堆叠多个残差单元,以缓解训练准确度的劣化。残差块利用特殊加性跳跃连接来减轻深度神经网络中的消失梯度。在残差块开始时,数据流被分成两个流:(1)第一流携带块的不变输入,(2)第二流应用权重和非线性。在块结束时,使用逐元素求和来合并两个流。此类构造的一个优点是允许梯度更容易地流过网络。
[0248]
受益于此类残差网络,可以容易地训练深度卷积神经网络(cnn),并且可以实现了用于数据分类、对象检测等的改善的准确度。卷积前馈网络将第l层的输出作为输入连接到第(l 1)层。残差块添加跳跃连接,该跳跃连接利用恒等函数绕过非线性变换。残差块的优点是梯度可以直接通过恒等函数从稍后层流到较早层。
[0249]
批量归一化
[0250]
与可以适用于本致病性分类方法的卷积神经网络的具体实施有关的另一方面是批量归一化,其是用于通过使数据标准化成为网络架构的组成部分来加速深度网络训练的方法。即使在训练期间平均值和方差随时间变化,批量归一化也可以自适应地归一化数据,并且通过在内部维持在训练期间看到的数据的分批均值和方差的指数移动平均值来工作。批量归一化的一种作用是其有助于梯度传播(很像残差连接)并且因此有助于使用深度网络。
[0251]
因此,批量归一化可以被看作可以插入到模型架构中的另一层,就像全连接或卷积层一样。通常在卷积或密集连接层之后使用批量归一化层,虽然也可以在卷积或密集连接层之前使用批量归一化层。
[0252]
批量归一化经由后向传递提供了关于前馈输入并且计算相对于参数的梯度的定义以及其自身输入。实际上,通常在卷积或全连接层之后,但在输出被馈送到激活函数中之前,插入批量归一化层。对于卷积层,在不同位置处的相同特征映射的不同元素(即,激活)以相同方式进行归一化以便遵循卷积属性。因此,在所有位置上,而不是每次激活,对微型批量中的所有激活进行归一化。
[0253]
1d卷积
[0254]
在可以适用于本方法的卷积神经网络的具体实施中使用的其他技术涉及使用1d卷积来提取局部1d斑块或来自序列的子序列。1d卷积方法从输入序列中的窗口或斑块获得每个输出步长。1d卷积层识别序列中的局部模式。因为对每个斑块执行相同的输入变换,所以可以稍后在不同的位置处识别在输入序列中的特定位置处学习的模式,从而使得1d卷积层平移对于平移不变。例如,使用尺寸为5的卷积窗处理碱基序列的1d卷积层应能够学习长度为5或更小的碱基或碱基序列,并且它应能够识别输入序列中任何上下文中的碱基基序。因此,碱基水平的1d卷积能够了解碱基形态。
[0255]
全局平均池化
[0256]
在本背景下可能有用或利用的卷积神经网络的另一方面涉及全局平均池化。特别地,可通过获取最后层中的特征的空间平均值以用于进行评分,来使用全局平均池化来替换全连接(fc)层以用于分类。全局平均池化减少训练负荷并避开过拟合问题。全局平均池化在模型之前应用结构,并且其等同于具有预定义权重的线性变换。全局平均池化减少了参数的数量并且消除了全连接层。全连接层通常是参数和连接最密集层,而全局平均池化提供了成本低得多的方法来实现类似的结果。全局平均池化的主要概念是从每个最后层特征图生成平均值作为直接馈送到softmax层中的用于评分的置信因子。
[0257]
全局平均池化可以提供某些益处,包括但不限于:(1)在全局平均池化层中不存在额外参数,因此在全局平均池化层处避免了过拟合;(2)由于全局平均池化的输出是整个特征映射的平均值,因此全局平均池化对空间平移是稳健的;以及(3)由于在整个网络的所有参数中通常占据超过50%的全连接层中的大量参数,因此通过全局平均池化层更换它们可以显著降低模型的大小,并且这使得全局平均池化在模型压缩中非常有用。
[0258]
全局平均池化有意义,因为最后层中的更强特征预期具有更高的平均值。在一些具体实施中,全局平均池化可以用作分类评分的代理。全局平均池化下的特征图可以被解释为置信图,并且促成特征图与类别之间的对应关系。如果最后层特征处于足够抽象以进行直接分类,那么全局平均池化可能特别有效;然而,如果应当将多级特征组合成组,如部件模型(这更适当地通过在全局平均池化之后添加简单的全连接层或其他分类器来解决),那么单独的全局平均池化可能不是足够的或适当的。
[0259]
ix.计算机系统
[0260]
如可以理解的,本讨论的神经网络方面以及对由所描述的神经网络对致病性分类器输出执行的分析和处理可以在计算机系统或系统上实施。考虑到这一点,并且通过另外的背景,图42示出了可以操作当前公开的技术的示例性计算环境800。具有致病性分类器160、二级结构子网络130和溶剂可及性子网络132的深度卷积神经网络102在一个或多个训练服务器802(其数量可以基于要处理的数据量或计算负荷进行调节)上训练。可由训练服务器访问、生成和/或利用的该方法的其他方面包括但不限于在训练过程中使用的训练数
platform)、英伟达(nvidia)公司的volta、英伟达公司的drive px、英伟达公司的jetson tx1/tx2module、intel公司的nirvana、movidius vpu、fujitsu dpi、arm公司的dynamiciq、ibm truenorth等。
[0266]
在计算机系统850的背景下,用户界面输入设备882可以包括键盘;指向设备,诸如鼠标、轨迹球、触摸板或图形输入板;扫描仪;结合到显示器中的触摸屏;音频输入设备,诸如语音识别系统和麦克风;以及其他类型的输入设备。一般来讲,使用术语“输入设备”可以解释为涵盖将信息输入到计算机系统850中的所有可能类型的设备和方式。
[0267]
用户界面输出设备886可以包括显示子系统、打印机、传真机或非视觉显示器(诸如音频输出设备)。显示子系统可包括阴极射线管(crt)、平板设备诸如液晶显示器(lcd)、投影设备或用于产生可见图像的一些其他机构。显示子系统还可提供非视觉显示器,诸如音频输出设备。一般来讲,使用术语“输出设备”可以解释为涵盖将信息从计算机系统850输出到用户或者输出到另一机器或计算机系统的所有可能类型的设备和方式。
[0268]
存储子系统862存储提供本文所述的一些或全部模块和方法的功能的编程结构和数据结构。这些软件模块通常由处理器854单独或与其他处理器854组合执行。
[0269]
在存储子系统862中使用的存储器866可以包括多个存储器,包括用于在程序执行期间存储指令和数据的主随机存取存储器(ram)878和其中存储固定指令的只读存储器(rom)874。文件存储子系统870可以为程序文件和数据文件提供持久性存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、cd-rom驱动器、光盘驱动器或可移动介质磁盘盒。实现某些实施方式的功能的模块可以由文件存储子系统870存储在存储子系统862中,或者存储在处理器854可访问的其他机器中。
[0270]
总线子系统858提供用于使计算机系统850的各种部件和子系统按照预期彼此通信的机构。尽管总线子系统858被示意性地示出为单条总线,但是总线子系统858的替代具体实施可以使用多条总线。
[0271]
计算机系统850本身可以具有不同类型,包括个人计算机、便携式计算机、工作站、计算机终端、网络计算机、电视机、主机、独立服务器、服务器群、一组广泛分布的松散联网的计算机,或者任何其他数据处理系统或用户设备。由于计算机和网络的不断变化的性质,对图43中描绘的计算机系统850的描述仅旨在作为用于示出所公开的技术的具体示例。计算机系统850的许多其他配置是可能的,其具有比图43中描绘的计算机系统850更多或更少的部件。
[0272]
该书面描述使用示例以公开本发明,包括最佳模式,并且还使得本领域的任何技术人员能够实践本发明,包括制造和使用任何装置或系统以及执行任何结合的方法。本发明的可取得专利的范围由权利要求限定,并且可以包括本领域的技术人员想到的其他示例。如果此类其他示例具有与权利要求的字面语言无差异的结构元件,或者如果它们包括与权利要求的字面语言无实质差异的等同结构元件,则这些其他示例旨在落入权利要求的范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。