1.本技术总体上涉及牙齿三维数字模型的局部坐标系的设定方法。
背景技术:
2.随着计算机科学的不断发展,牙科专业人员越来越多地借助计算机技术来提高牙科诊疗的效率。
3.在借助计算机的牙科诊疗中,常用到经分割的牙列的三维数字模型(各牙齿之间相互独立,因此可以单独移动各牙齿)。为了便于处理和计算,可以建立一个世界坐标系并且为每一颗牙齿建立一个局部坐标系,对于每一颗牙齿,可以结合所述世界坐标系以及该牙齿的局部坐标系来表示该牙齿的位姿。在一些借助计算机的牙科诊疗中,例如,借助计算机的牙科正畸方案的制定,局部坐标系的设定非常关键。
4.当前,较常见的局部坐标系的设定方法要求较多人工介入,包括对牙齿表面的特征点进行手动标注,以及对产生的局部坐标系进行人工调整。
5.但这种方法存在以下几点不足之处:第一,每个技术人员对局部坐标系的理解可能不同,难以保证局部坐标系设定的一致性;第二,大量的特征点手动标注以及局部坐标系的手动调整需要消耗大量时间和人力,不利于提升效率和降低成本。
6.鉴于以上,有必要提供一种新的牙齿三维数字模型的局部坐标系设定方法。
技术实现要素:
7.本技术的一方面提供了一种计算机执行的牙齿三维数字模型的局部坐标系的设定方法,其包括:获取世界坐标系下的表示第一牙齿的第一三维数字模型;对所述第一三维数字模型的进行特征提取;利用经训练的深度学习图神经网络,基于所述提取的特征,产生总变换矩阵;以及基于所述世界坐标系和所述总变换矩阵建立所述局部坐标系。
8.在一些实施方式中,所述的计算机执行的牙齿三维数字模型的局部坐标系的设定方法还可以包括:产生预变换矩阵,并将其应用于所述世界坐标系下的第一三维数字模型,得到经预变换的第一三维数字模型,其中,所述特征提取是对所述经预变换的第一三维数字模型进行;所述经训练的深度学习图神经网络,基于所述提取的特征,产生最终变换矩阵;以及将所述预变换矩阵和所述最终变换矩阵结合得到所述总变换矩阵,其中,所述最终变换矩阵所对应的变换小于所述总变换矩阵。
9.在一些实施方式中,所述预变换矩阵可以基于以下至少之一产生:(一)所述第一三维数字模型局部坐标系的原点;以及(二)多个用于训练所述深度学习图神经网络的样本的总变换矩阵的平均值。
10.在一些实施方式中,所述第一三维数字模型局部坐标系的原点可以是以下之一:所述第一三维数字模型的几何中心,以及所述第一三维数字模型的牙洞线中心。
11.在一些实施方式中,所述深度学习图神经网络的输出包括9维向量,其中,6维表示旋转向量,3维表示平移向量。
12.在一些实施方式中,所述特征包括:面片中心点、面片法向量以及面片各顶点到中心点的向量。
13.在一些实施方式中,训练所述深度学习图神经网络所采用的损失函数包括以下之一:预测的总变换矩阵与真值总变换矩阵之差;预测的总变换矩阵的旋转分量与真值总变换矩阵的旋转分量之差;预测的总变换矩阵的平移分量与真值总变换矩阵的平移分量之差;以及经预测的总变换矩阵和真值总变换矩阵变换的所述第一三维数字模型之差。
14.在一些实施方式中,所述的计算机执行的牙齿三维数字模型的局部坐标系的设定方法还可以包括:通过引入扰动,基于所述第一三维数字模型产生多个输入;对比所述多个输入对应的局部坐标系设定结果;以及若所述对比的结果大于预定值,则发出警报。
15.在一些实施方式中,所述的计算机执行的牙齿三维数字模型的局部坐标系的设定方法还可以包括:所述深度学习图神经网络包括dropout层,所述深度学习图神经网络对于所述第一三维数字模型产生多个局部坐标系设定结果;对比所述多个局部坐标系设定结果;以及若所述对比的结果大于预定值,则发出警报。
16.在一些实施方式中,所述深度学习图神经网络是针对牙列中一颗预定的牙齿。
17.在一些实施方式中,所述深度学习图神经网络是动态图卷积神经网络。
附图说明
18.以下将结合附图及其详细描述对本技术的上述及其他特征作进一步说明。应当理解的是,这些附图仅示出了根据本技术的若干示例性的实施方式,因此不应被视为是对本技术保护范围的限制。除非特别指出,附图不必是成比例的,并且其中类似的标号表示类似的部件。
19.图1为本技术一个实施例中计算机实施的牙齿三维数字模型的局部坐标系的设定方法的示意性流程图。
具体实施方式
20.以下的详细描述引用了构成本说明书一部分的附图。说明书和附图所提及的示意性实施方式仅仅是出于说明性之目的,并非意图限制本技术的保护范围。在本技术的启示下,本领域技术人员能够理解,可以采用许多其他实施方式,并且可以对所描述实施方式做出各种改变,而不背离本技术的主旨和保护范围。应当理解的是,在此说明并图示的本技术的各个方面可以按照很多不同的配置来布置、替换、组合、分离和设计,这些不同配置都在本技术的保护范围之内。
21.本技术的一方面提供了一种计算机执行的利用深度学习图神经网络设定牙齿三维数字模型的局部坐标系的方法。
22.图神经网络包括基于频谱的图神经网络和基于空间的图神经网络,其中,基于频谱的图神经网络有spectral cnn、chebyshev spectral cnn(chebnet)、adaptive graph convolutional network(agcn)等,基于空间的图神经网络有graphsage、graph attention network(gat)等。
23.利用深度学习图神经网络预测局部坐标系,可以看成预测一个变换矩阵,通过将该变换矩阵应用于世界坐标系,得到局部坐标系。对于三维空间,这样的变换矩阵可以是一
个4x4的矩阵,它包括一个3x3的旋转矩阵和一个3x1的平移矩阵。
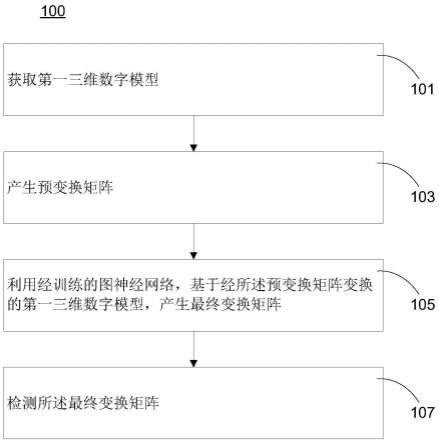
24.请参图1,为本技术一个实施例中的计算机执行的利用深度学习图神经网络设定牙齿三维数字模型的局部坐标系的方法100的示意性流程图。
25.在101中,获取第一三维数字模型。
26.第一三维数字模型是表示第一牙齿的三维数字模型,是单颗牙齿的三维数字模型。在一个实施例中,它可以是世界坐标系下的三维数字模型,即其各顶点的位置是以所述世界坐标系下的坐标值来表示。
27.在一个实施例中,可以如此定义世界坐标系,将垂直于咬合面的向量作为世界坐标系的z轴,将两颗6号牙的牙尖连线作为世界坐标系x轴,然后,基于所述z轴和x轴确定y轴。可以理解,世界坐标系的定义方式并不限于以上例子,不同系统所产生的牙列三维数字模型的世界坐标系的定义方式可能不同,或者说不同系统所产生的牙列三维数字模型在世界坐标系下的位姿(包括位置和方向)可能不同。
28.获取患者牙齿的数字三维模型的方法有多种。在一个实施例中,可以直接扫描患者的牙颌(上颌和/或下颌),获得表示患者牙列的三维数字模型。在又一实施例中,可以扫描患者牙颌的实体模型,例如石膏模型,获得表示患者牙列的三维数字模型。在又一实施例中,可以扫描患者牙颌的印模,获得表示患者牙列的三维数字模型。
29.将表示患者牙列的三维数字模型进行分割即可获得表示各牙齿的三维数字模型。
30.在103中,产生预变换矩阵。
31.考虑到不同系统所产生的同一牙齿的三维数字模型在世界坐标系下可能处于不同位姿,以及同一系统所产生的不同患者的同一牙齿的三维数字模型在世界坐标系下可能处于不同位姿,如果直接从世界坐标系变换得到局部坐标系,该变换相对较为复杂。因此可以先产生一个预变换矩阵,基于世界坐标系和该预变换矩阵可以产生一个比较接近目标局部坐标系的坐标系。利用该预变换矩阵调整牙齿三维数字模型的位姿,基于变换后的牙齿三维数字模型,后续深度学习图神经网络只需预测一个较小的变换即可。通过所述变换,可以把牙齿三维数字模型调整到一个比较统一的初始位置,这样利于模型学习和预测。
32.可以把这个过程看成将原始的变换矩阵拆解成两个变换矩阵,预变换矩阵m1和后续深度学习图神经网络预测的变换矩阵m2。
33.m=m1×
m2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
等式(1)
34.可以采用多个手段产生预变换矩阵m1,下面对这些手段进行详细说明。
35.在一个实施例中,可以在训练集中提取一定数量(例如100个)的变换矩阵m,对这些变换矩阵取平均值,可以将这样得到的变换矩阵作为预变换矩阵m1。
36.在又一实施例中,可以根据局部坐标系的原点的定义,调整牙齿的位置,使得目标局部坐标系的原点和世界坐标系的原点重合,可以将这个变换矩阵作为预变换矩阵m1。这样后续深度学习图神经网络只需预测对应的旋转即可。例如,若局部坐标系的原点为牙齿的中心(重心),那么,可以求出该牙齿在世界坐标系下的坐标,将世界坐标系的原点坐标减去所述中心坐标得到的矩阵作为预变换矩阵m1。
37.在又一实施例中,针对每一牙齿,可以设置多个模板(包括三维数字模型和局部坐标系)(例如,可以根据牙齿的大小设置大、中、小三个模板),然后,将所述第一三维数字模型与这些模板进行点云配准,选择匹配度最高的一个的变换矩阵m作为第一三维数字模型
的预变换矩阵m1。
38.在本技术的启示下,可以理解,产生预变换矩阵的手段并不限于以上,可以包括任何适用的其他手段。另外,这些手段可以组合使用,将预变换矩阵拆分为两个甚至更多变换矩阵。例如,可以先通过对训练集中若干变换矩阵取平均值获得第一变换矩阵,再通过计算经所述第一变换矩阵变换后的牙齿的三维数字模型的中心得到第二变换矩阵,将所述第一和第二变换矩阵组合得到预变换矩阵m1。
39.在一个实施例中,在训练所述深度学习图神经网络以及利用它预测变换矩阵时,先使用预变换矩阵对牙齿三维数字模型进行预调整,再将经调整的牙齿三维数字模型输入深度学习图神经网络。
40.在105中,利用经训练的深度学习图神经网络,基于经所述预变换矩阵变换的第一三维数字模型,产生最终变换矩阵。
41.在一个实施例中,所述经训练的深度学习图神经网络可以对经所述预变换的第一三维数字模型均匀非重复采样第一预定数量的面片(例如,800个面片,该第一预定数量足够多,能够充分保留所述第一三维数字模型的几何特征,使得后续能够比较精确地预测变换矩阵即可)。若一颗牙齿的三维数字模型的面片数量少于所述第一预定数量,可以重复采样以凑齐所述第一预定数量的采样面片。然后,对每个采样面片进行特征提取。在一个实施例中,可以对每一采样面片提取以下特征:面片中心点的坐标、面片的法向量以及面片每个顶点到中心点的向量。在本技术的启示下,可以理解,除了上述特征之外,还可以对面片提取其他特征。完成特征提取之后,将提取到的特征编码形成特征向量。
42.在一个实施例中,对于不同类型的牙齿,面片采样的数量可以不同。
43.在一个实施例中,所述深度学习图神经网络可以采用动态图神经网络(dynamic graph cnn,以下称为dgcnn)。
44.在一个实施例中,可以将传统的dgcnn进行修改,使得网络最后为全连接层,预测一个9维向量,其中,前3维对应平移向量t,后6维对应旋转向量r。可以理解,除了以上的形式,所述9维向量的顺序也可以定义为其它形式,例如,前6维为r,后3维为t。为了便于表达,平移向量和平移矩阵均以t表示,旋转向量和旋转矩阵均以r表示。
45.r只有6维是因为旋转矩阵需要满足正交矩阵的性质(orthogonal matrice),即需满足矩阵的转置等于矩阵的逆:
46.r
t
=r-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
等式(2)
47.请参在cvpr 2019上发表的《on the continuity of rotation representations in neural networks》,可以将6维旋转向量转换成3x3旋转矩阵r,并且该过程可以求导以进行反向传播。因此,该转换过程可以放在dgcnn的最后,将其预测得到的9维向量转化成转换矩阵m2。
48.在一个实施例中,训练所述dgcnn时,训练的损失可以采用以下几种:
49.(1)预测的m2和真值(ground truth)m2之差。
50.(2)预测的r和真值r之差。
51.(3)预测的t和真值t之差。
52.(4)将预测的m2和真值m2分别应用于输入的牙齿三维数字模型,该两变换后的牙齿三维数字模型之差。
53.损失函数可以采用l1或l2或其他适用的损失函数。
54.可以理解,若所述深度学习图神经网络用于预测直接从世界坐标系到局部坐标系的转换矩阵,那么,其输出的矩阵就是m。
55.在107中,检测所述最终变换矩阵。
56.在个别情况下,所述深度学习图神经网络预测得到的最终变换矩阵可能不准确,因此,可以对预测得到的最终变换矩阵进行检测,若检测结果显示最终变换矩阵不合格,那么,系统可以发出警报,提醒人工介入调整。
57.在一个实施例中,可以引入随机扰动,以基于所述经预变换的第一三维数字模型产生至少一个不同的输入,如果所述深度学习图神经网络基于这些输入预测得到的结果之间存在较大差异,那么,系统可以发出警报,提醒人工介入调整。
58.在一个实施例中,可以随机生成至少一个小的扰动变换矩阵,应用于所述经预变换的第一三维数字模型,以产生多个不同的输入。然后,对与这些输入相对应的预测结果计算方差(variance)或变异系数(coefficient of variation),若计算结果大于预定值,则发出警报。
59.在又一实施例中,可以在所述深度学习图神经网络中引入dropout层,在预测时开启dropout层,以对同一输入产生多个不同的输出。然后,对这些输出计算方差(variance)或变异系数(coefficient of variation),若计算结果大于预定值,则发出警报。
60.需要说明的是,有多种定义牙齿三维数字模型局部坐标系的方式(即如何定义局部坐标系的原点以及各坐标轴的方向),例如,对于局部坐标系的原点,在一个实施例中,可以将牙洞线中心作为第一三维数字模型局部坐标系原点;在又一实施例中,可以计算得到第一三维数字模型的几何中心,将其作为第一三维数字模型局部坐标系原点。对于牙齿三维数字模型局部坐标系的不同定义方式,所对应的变换矩阵也会不同。本技术的方法适用于各种牙齿三维数字模型局部坐标系的定义方式。
61.由于不同的牙齿的几何形态差异较大,在一个实施例中,可以为每一牙齿分别设立一个深度学习图神经网络,分别用于为相应牙齿设定局部坐标系。
62.尽管在此公开了本技术的多个方面和实施例,但在本技术的启发下,本技术的其他方面和实施例对于本领域技术人员而言也是显而易见的。在此公开的各个方面和实施例仅用于说明目的,而非限制目的。本技术的保护范围和主旨仅通过后附的权利要求书来确定。
63.同样,各个图表可以示出所公开的方法和系统的示例性架构或其他配置,其有助于理解可包含在所公开的方法和系统中的特征和功能。要求保护的内容并不限于所示的示例性架构或配置,而所希望的特征可以用各种替代架构和配置来实现。除此之外,对于流程图、功能性描述和方法权利要求,这里所给出的方框顺序不应限于以同样的顺序实施以执行所述功能的各种实施例,除非在上下文中明确指出。
64.除非另外明确指出,本文中所使用的术语和短语及其变体均应解释为开放式的,而不是限制性的。在一些实例中,诸如“一个或多个”、“至少”、“但不限于”这样的扩展性词汇和短语或者其他类似用语的出现不应理解为在可能没有这种扩展性用语的示例中意图或者需要表示缩窄的情况。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。