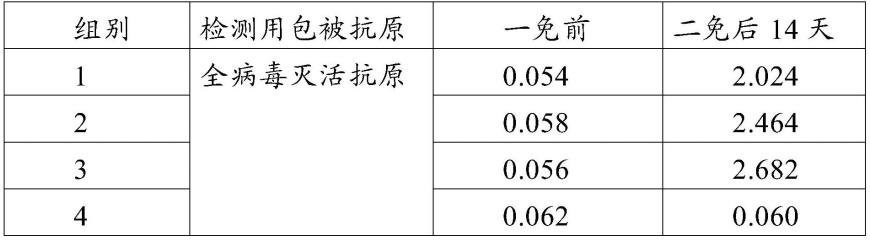
基于细胞增殖标志物的tc患病风险预测建模方法
技术领域
1.本技术涉及患病风险预测建模领域,尤其是涉及一种基于细胞增殖标志物的tc患病风险预测建模方法。
背景技术:
2.甲状腺癌症(thyroid carcinoma,tc)是十大常见癌种之一,其成因复杂,早期多无明显自觉症状。据2021年统计结果,2015年我国甲状腺癌患者共计20.1万人;预计2020年我国甲状腺癌男性患者53389人,女性患者167704人,分别占世界甲状腺癌患者的38.89%和37.36%,2020年发病人数较2015年增加约2万人,逐渐呈现年轻化和偏女性化特征,且同期发病率均高于甲状腺癌世界人口均化发病率。从1980-2015年间,我国甲状腺癌发病率持续升高,一方面是由于现代生活节奏和压力增大,环境因素影响增强,另一方面也因为医学检测技术的不断升级。
3.为实现对乳头状tc、滤泡状tc、源于滤泡上皮细胞的未分化tc以及主要来源于滤泡旁细胞的髓样tc的早期筛选,在普通外科检查之外,还需要血液检查甲状腺激素、甲状腺自身免疫抗体以及肿瘤标志物作为辅助,对高风险人群需进一步进行细针穿刺抽吸细胞学检查(fna检查),以确诊肿瘤类型和分化进展分期。由于甲状腺外科触摸检查高度依赖医师经验,主观性影响较大,超声检测仅从外部探测组织结构,血液检查标志物的敏感性和特异性不足以实现早筛目的,而fna检测的过度应用,更会造成较多患者不必要的痛苦。开发一种基于循环系统肿瘤风险因子、无损且可持续监测的甲状腺癌肿瘤风险评估方法,以减少非必需病理学检测的实施,具有重要的现实意义。
4.近年来甲状腺癌患病风险预测模型,可归纳为三种主要模式:1)基于“医学影像学检测(特别是超声技术)的征象结果”,如组成成分、回声、形态、边界、钙化情况等信息,构建受试者工作特征曲线(receiver operating characteristic curve,roc)对甲状腺癌风险进行预测评估,可参考文献如“陈俊慧,张曼,刘水澎,et al.基于超声征象多因素logistic回归β值积分法的甲状腺癌风险预测研究[j].中国癌症杂志,2019,29(004):289-293.”;2)基于“桥本氏甲状腺炎症、甲状腺功能以及血清甲状腺自身免疫抗体”,对甲状腺癌风险进行评估,可参考文献如“kadam s,ghadhban b,abduljabbarsalehm.hashimoto's thyroiditis increases risk for differentiated thyroid carcinoma[j].annals of the romanian society for cell biology,2021,25:5952-5961.”;3)基于“tgga等癌症基因组图谱数据库的rnaseq数据、kegg通路富集分析”,构建基于变异路径的风险评估及甲状腺癌人工神经网络模型,可参考文献如“zhao y,zhao l,mao t,et al.assessment of risk based on variant pathways and establishment of an artificial neural network model of thyroid cancer[j].bmc medical genetics,2019,20.”。
[0005]
针对上述中的相关技术,发明人认为存在以下缺陷:超声检查易受主观因素影响,对早期病灶不够敏感;甲状腺激素与肿瘤标志物afp、cea等绝大多数对早期tc的敏感性和特异性效果不佳;肿瘤特征核酸特征鉴定方法由于出现时间较晚,临床转化进展尚早,需积
累更多数据对方法有效性进行验证支持。现有的tc风险评估体系的样本获取成本高、难度大、样本积累效率偏低,导致现有tc风险评估模型的迭代升级难度较高。
技术实现要素:
[0006]
为了解决现有的tc风险评估体系不能适用于健康群体进行甲状腺癌的患病风险监测,且样本获取成本高、难度大、样本积累效率低,导致风险评估模型的迭代升级难度大的问题,本技术提供一种基于细胞增殖标志物的tc患病风险预测建模方法。
[0007]
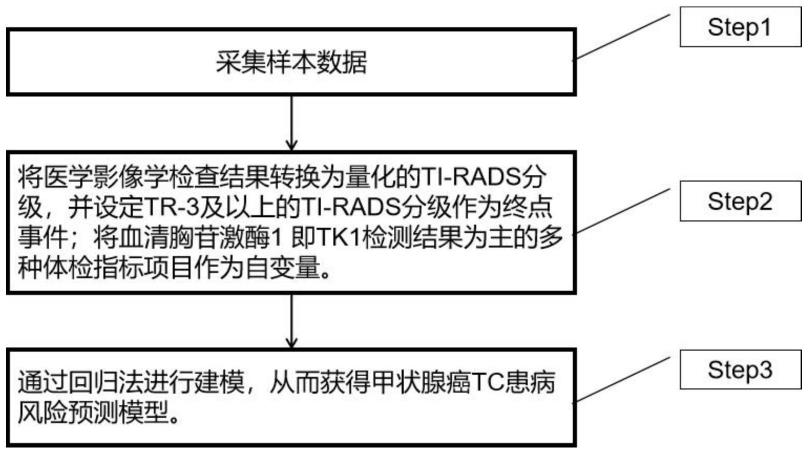
本技术提供的一种基于细胞增殖标志物的tc患病风险预测建模方法,采用如下技术方案:一种基于细胞增殖标志物的tc患病风险预测建模方法,包括:采集样本数据;将医学影像学检查结果转换为量化的ti-rads分级,并设定tr-3及以上的ti-rads分级作为终点事件;将细胞增殖标志物血清胸苷激酶1即tk1检测结果为主的多种体检指标项目作为自变量;通过回归法进行建模,从而获得甲状腺癌tc患病风险预测模型。
[0008]
本技术通过设定在体检样本中即可获取的tc中间状态(该tc中间状态作为tc病理进程中必然经过的中间状态,具有确定级别的恶化风险特征)作为终点事件(即将具有确定tc风险的影像学检查结果集合设定为风险预测终点事件(设定tr-3、tr-4和tr-5作为阳性结果)),多种体检指标项目作为自变量,由于自变量和因变量都设定在体检阶段,仅需提供体检结果就可进行风险预测模型的开发,无需为了收集临床结果进行大量低效的回访工作,从而降低了阳性结果样本的获取成本和难度,阳性样本的稳定积累成为可能,在相同时间段内,该系统获得的风险预测模型的迭代升级可行性更高。另外,通过结合将细胞增殖标志物血清胸苷激酶1即tk1检测结果为主的多种体检指标项目作为自变量,从而建模获得的预测模型可以更好的适用于tc患病风险的预测;而且本技术中以多种体检指标项目作为自变量,因而所建立的tc患病风险预测模型可以普遍适用于一般的健康人群,比如用于体检机构中用于对普通的体检人群进行tc患病风险预测,可以适应普遍筛查的高频度和高通量需求。
[0009]
优选的,所述的通过回归法进行建模,从而获得甲状腺癌tc患病风险预测模型,具体包括以下步骤:s1,使用三折交叉验证法随机抽样将原始样本数据拆分为训练集与验证集;s2,针对不同的训练集,通过重复使用不平衡回归ilkl算法进行建模,获得多个预测模型;对应同一个训练集所获得的多个预测模型形成一个预测模型库;s3,对各个预测模型库中的预测模型进行筛选,若预测模型公式中含有tk1项目自变量,则将该所述的预测模型纳入初筛预测模型组中;s4,对于初筛预测模型组中的预测模型,使用对应的验证集样本进行受试者工作特征曲线(即roc曲线)验证并计算曲线下面积auc值;s5,若auc值大于等于0.7,则将对应的初筛预测模型组中的预测模型纳入最终的预测模型组中;s6,对最终的预测模型组中的各个预测模型,按照参数综合方式进行模型优化,从而得到tc风险预测模型。
[0010]
通过采用以上方案,尤其是通过利用tk1项目自变量及受试者工作特征曲线对预
测模型进行筛选,tk1检测结果可指示细胞增殖水平,可反映多类型肿瘤细胞的早期异常增殖变化;auc值大于等于0.7,证明该预测模型具备一定的准确性;另外,通过重复使用不平衡回归ilkl算法进行建模,从而可以在高度不平衡的样本组之间配齐数目,同时保持其样本的高度代表性,从而最终获得更有实用价值的、更准确的tc早期风险预测模型。
[0011]
优选的,步骤s2所述的使用不平衡回归ilkl算法进行建模具体包括以下步骤:s21,将样本根据终点事件状态分为两组,其中,终点事件为“一般风险”(即tr-1和tr-2)的样本为“多数组”,阳性样本(即tr-3及以上的ti-rads分级)组为少数组;s22,将作为自变量的体检指标项目设为聚类指标变量,将终点事件设为样本标签,将k(大于2小于等于10的自然数)设定为类别组数;s23,从多数组样本中随机选择k个样本作为质心,对多数组样本中的每一个点,基于聚类指标变量计算其与每一个质心样本的欧几里德距离,并将其划分到距离最短的质心所属的集合中;s24,所有数据归入k个集合后,重新计算每个集合的质心点;s25,若新计算出来的质心样本和原质心样本之间的欧几里德距离小于设置的阈值(即达到收敛状态),则将获得的k个集合作为k-means聚类分组;否则继续进行迭代,直至最终获得k-means聚类分组;s26,按照少数组比多数组的比例对k-means聚类分组进行随机抽样;s27,合并所有的抽样样本与少数组样本,通过二分类逻辑回归获得预测模型。
[0012]
通过采用以上方案,使用不平衡回归ilkl算法进行建模,从而可以有效解决真实体检数据中阳性样本与健康样本之间的样本不平衡性问题。选择终点事件为“一般风险”的样本为“多数组”,阳性样本(即tr-3及以上的ti-rads分级)组为少数组,此时只要按照终点事件不同状态的比值(阳性组/多数组)在k个类别中随机抽样,即可获得与阳性组样本数持平的“一般风险”样本集;在样本对等的情况下进行二分类逻辑回归,可有效规避因样本不平衡导致的预测模型偏向满足多数组结果的问题,另一方面也通过阳性人群的真实占比率拓展了预测模型的多样性。
[0013]
优选的,步骤s6中所述的按照参数综合方式进行模型优化具体包括以下步骤:s61,使用最终的预测模型组中的各个预测模型,分别对全部的训练集加验证集的数据进行受试者工作特征曲线(即roc曲线)验证并计算曲线下面积auc值;s62,根据验证结果中对阳性样本的预测正确率大小对所述的各个预测模型进行排序;s63,选择预测正确率最高的2-10个模型,进行预测模型的参数优化:预测模型中包含三种参数——项目自变量、项目自变量的系数以及常数;优化时,将所有模型中的所有项目自变量合并作为最终的tc风险预测模型的项目自变量;将所有模型中的各个项目自变量的系数相加再求平均后作为tc风险预测模型的相应项目自变量的系数;将所有模型中的常数相加再求平均后作为tc风险预测模型的常数。
[0014]
通过采用以上技术方案,从而可以进一步提高tc模型预测的准确性。
[0015]
优选的,通过以下方法对作为自变量的其他体检指标项目进行筛选:首先,(可通过显著性分析、相关性分析和秩和分析)验证已量化转化项目与终点事件之间的紧密相关性程度;若相关性的显著度p《0.1,则将该项目纳入待选项目;否则不
纳入待选项目;其次,对筛选获得的待选项目,(可通过box-tidwell法、项目间相关性分析法和多重共线性检验法)对项目之间的相关性进行排查,选择满足自变量三项假设的项目纳入回归项目中,最终与血清细胞质胸苷激酶1检测结果一起作为自变量;其中,所述的满足自变量三项假设,即项目与终点事件logit转换值之间存在线性关系、项目间无多重共线性与显著相关性。
[0016]
通过采用以上技术方案,(尤其是比如进行显著性分析、相关性分析和秩和分析)从而可以保证检测项目与终点事件发生存在显著或较为显著的相关性、(比如通过比如box-tidwell法验证),连续自变量与因变量的logit转换值之间存在线性关系、以及(比如通过项目间相关性分析法和多重共线性检验法)保证入选自变量项目之间具有独立性。将满足以上这些条件的自变量纳入“回归项目”,保证了自变量的单因素分析差异具有统计学意义、连续自变量与因变量logit转换值之间存在线性关系假说、同时也避免因放入相关性较高的自变量项目,造成某方面因素的影响权重被放大失真。
[0017]
优选的,通过提取医学影像学检查文字结果中的ti-rads分级量化结果,来实现将医学影像学检查结果转换为量化的ti-rads分级;将医学影像学检查结果转换为量化的ti-rads分级后,还包括:将分类选项结果进行自然数赋值处理,从而实现将初始不同格式的检测调查结果数据转换为一致性的量化数据。
[0018]
通过采用以上技术方案,将医学影像学检查结果以及初始不同格式的检测调查结果数据转换为一致性的量化数据,从而便于进行建模时使用。
[0019]
进一步优选的,利用终点事件提取工具提取医学影像学检查文字结果中的ti-rads分级量化结果,具体包括以下步骤:a,通过len和substitute命令,输出影像学文字结果中“ti”的出现次数;b,使用find命令获得“ti”在文字中首次出现的定位值n1,并使用mid命令抓取n1位置ti-rads后的分级字符串;c,将首次出现定位值n1 1作为起始位置,继续使用find命令,获得“ti”第二次出现的定位值n2,并抓取n2位置的ti-rads分级字符串;d,将第二次出现的定位值n2 1作为起始位置,继续使用find命令进行定位,以此类推,得到所有位置对应的ti-rads后的分级字符串;e,使用value和iferror命令将所有位置得到的字符串均转换为数字(如无数字则赋值“0”);f,使用max命令输出转换后的数字中的最大值l;g,使用if命令,将获得的t值转换为风险分级数1或2。
[0020]
通过采用以上技术方案,通过终点事件提取工具在海量的医学影像学描述性文字中,针对性发现ti-rads分类信息,并按照其分级结果的最大值进行转化输出,从而可以提高转换效率,降低出错率。
[0021]
优选的,所述的将分类选项结果进行自然数赋值处理,即利用逻辑值转换工具将项目按照二分类、有序和无序的不同,分别转换为量化值(比如二分类项目阴性结果赋值为1,阳性结果赋值为2;多分类项目按照顺序转换为自然数数列(如1,2,至n))。
[0022]
采用以上技术方案,将项目按照二分类、有序和无序的不同进行量化,从而有利于
将所述的体检指标数据用于建模使用。
[0023]
前述的基于细胞增殖标志物的tc患病风险预测建模方法中,通过对风险概率结果的区段识别(如根据cutoff=0.500分段,小于0.5的为低风险人群,大于等于0.5的为高风险人群),输出受检者的tc风险分群信息。
[0024]
通过采用以上方法,将受检者划分为高风险人群和低风险人群,从而有利于实现将多数的医疗资源倾向于高风险人群。
[0025]
综上所述,本技术包括以下至少一种有益技术效果:1.本技术通过设定在体检样本中即可获取的tc中间状态(该tc中间状态作为tc病理进程中必然经过的中间状态,具有确定级别的恶化风险特征)作为终点事件(即将具有确定tc风险的影像学检查结果综合分级设定为风险预测终点事件(设定tr-3、tr-4和tr-5作为阳性结果)),多种体检指标项目作为自变量,由于自变量和因变量都设定在体检阶段,仅需提供体检结果就可进行风险预测模型的开发,无需为了收集临床结果进行大量低效的回访工作,从而降低了阳性结果样本的获取成本和难度,阳性样本的稳定积累成为可能,在相同时间段内,该系统获得的风险预测模型的迭代升级可行性更高。另外,通过结合将血清胸苷激酶1即tk1检测结果为主的多种体检指标项目作为自变量,从而建模获得的预测模型可以更好的适用于tc患病风险的预测;而且本技术中以多种体检指标项目作为自变量,因而所建立的tc患病风险预测模型可以普遍适用于一般的健康人群,比如用于体检机构中用于对普通的体检人群进行tc患病风险预测,可以适应普遍筛查的高频度和高通量需求。
[0026]
2.本技术通过使用不平衡回归ilkl算法进行建模,从而可以有效解决真实体检数据中阳性样本与健康样本之间的样本不平衡性问题。选择终点事件为“一般风险”的样本为“多数组”,阳性样本(即tr-3及以上的ti-rads分级)组为少数组,此时只要按照终点事件不同状态的比值(阳性组/多数组)在k个类别中随机抽样,即可获得与阳性组样本数持平的“一般风险”样本集;在样本对等的情况下进行二分类逻辑回归,可有效规避因样本不平衡导致的预测模型偏向满足多数组结果的问题,另一方面也通过阳性人群的真实占比率拓展了预测模型的多样性。
附图说明
[0027]
图1是本技术的一种实施例的方法流程图。
[0028]
图2是本技术中tc风险预测模型的具体建模方法流程图。
[0029]
图3是本技术中项目筛选及应用ilkl算法进行建模的方法流程图。
[0030]
图4为利用终点事件提取工具提取医学影像学检查文字结果中的ti-rads分级量化结果的方法流程图。
[0031]
图5为采用本技术所建模型进行tc患病风险评估的方框示意图。
[0032]
图6为实验例中对所建立的预测模型进行验证的roc曲线示意图。
具体实施方式
[0033]
以下结合附图1-6对本技术作进一步详细说明。
[0034]
现有技术中,比如2019年王晓亮等提出的桥本氏甲状腺炎合并分化型甲状腺癌的风险预测模型,针对桥本氏甲状腺炎合并分化型甲状腺癌患者评估其tc风险,该tc风险评
估体系以患者最终确诊甲状腺癌为终点事件,因而需要将甲状腺癌患者作为样本采集目标,由于甲状腺癌确证患者实际仅占筛查人群的0.021%,样本获取成本高、难度大、样本积累效率偏低,导致现有tc风险评估模型的迭代升级难度非常大。而作为风险评估系统的核心,临床预测模型的迭代升级,是风险评估系统提升评估有效性的关键途径。但因体检数据与临床数据各自普遍隔绝成“信息孤岛”,体检数据完整性、临床结果一致性、体检结果与临床结果的相关性(时间间隔太大导致缺乏对应关系)都会对阳性样本的有效性造成干扰,其结果便是可利用阳性样本数量远低于实际发生情况。这加大了预测模型研究难度,不易获得有应用价值的tc风险预测模型,风险预测算法迭代的可行性也不高。发明人基于此问题进行研究发现,根据最新版本的acr ti-rads v2017白皮书中将影像学发现的甲状腺结节分为五类:良性(tr-1)、良性可能性大(tr-2)、怀疑tc(tr-3)、中度疑似tc(tr-4)、高度疑似tc(tr-5)。根据wildman-tobriner b等2019年报道,tr-1时tc阳性预测率(ppv)为0%;tr-2时tc阳性预测率(ppv)为1.5%;tr-3时tc阳性的ppv为11.8%,tr-4和tr-5中tc阳性ppv值分别为29.4%和57.4%,故可将tr-1和tr-2结果作为tc一般风险状态,tr-3、tr-4和tr-5结果作为tc高风险状态。
[0035]
因此,发明人创造性的想到通过设定在体检样本中即可获取的tc中间状态(该tc中间状态作为tc病理进程中必然经过的中间状态,具有确定级别的恶化风险特征)作为终点事件(即将医学影像学检查结果转换为量化的终点事件状态,设定tr-3及以上的ti-rads分级作为终点事件(也即设定tr-3、tr-4和tr-5作为阳性结果)),多种体检指标项目作为自变量,由于自变量和因变量都设定在体检阶段,仅需提供体检结果就可进行风险预测模型的开发,无需为了收集临床结果进行大量低效的回访工作,降低了阳性结果样本的获取成本和难度,阳性样本的稳定积累成为可能,在相同时间段内,该系统获得的风险预测模型的迭代升级可行性更高。另外,通过结合将血清胸苷激酶1即tk1检测结果为主的多种体检指标项目作为自变量,从而建模获得的预测模型可以更好的适用于tc患病风险的预测;而且本技术中以多种体检指标项目作为自变量,因而所建立的tc患病风险预测模型可以普遍适用于一般的健康人群,比如用于体检机构中用于对普通的体检人群进行tc患病风险预测,可以适应普遍筛查的高频度和高通量需求。也即,本技术通过改变数据获取模式,降低阳性样本的获取成本,可有效提高tc风险预测模型的开发效率。在长期稳定的阳性样本积累基础之上,tc风险预测模型可进行更充分的算法迭代,从而获得更稳定和更有预测效率的tc风险评估系统,最终达到医疗资源对tc高危人群的高效能分配。
[0036]
本技术实施例公开一种基于细胞增殖标志物的tc患病风险预测建模方法。参照图1,一种基于细胞增殖标志物的tc患病风险预测建模方法,包括:step1,采集样本数据;step2,将医学影像学检查结果转换为量化的ti-rads分级,并设定tr-3及以上的ti-rads分级作为终点事件;将血清胸苷激酶1即tk1检测结果为主的多种体检指标项目作为自变量;step3,通过回归法(如二分类逻辑回归风险模型的普遍公式)进行建模,从而获得甲状腺癌tc患病风险预测模型。
[0037]
具体实施时,首先可基于对体检结果的整体观察,选择同一机构同一检测体系下的检测结果,然后可通过终点事件提取工具、逻辑值转换工具等将原有项目的不同形式转
换为统一量化形式;再通过数据清洗步骤,将存在数据完整性和规范性缺陷的样本进行清除(如清除tk1值或ti-rads结果无记录的样本,同时去除转换后量化结果明显超出测量范围的样本,如检测获得的负数或离群值样本(离群值的判定依据《gbt 4883-2008数据的统计处理和解释——正态样本离群值的判断和处理》中6.2.1“上侧情形”的方法))。最后可借助非结构化数据库来存储原始状态和数值转化的项目结果,并按照分析需求输出为可分析的数据文件形式。
[0038]
一般将体检结果项目按照项目结果形式分为三大类,1)医学影像学检查结果,包括超声/超声造影(ceus)项目;2)连续值项目;3)分类结果项目,包括二分类项目、有序多分类项目和无序多分类项目。
[0039]
可选的,所述的通过回归法进行建模,从而获得甲状腺癌tc患病风险预测模型,如图2所示,具体包括以下步骤:s1,使用三折交叉验证法随机抽样将原始样本数据拆分为训练集与验证集;s2,针对不同的训练集,通过重复使用不平衡回归ilkl算法进行建模,获得多个预测模型;对应同一个训练集所获得的多个预测模型形成一个预测模型库;s3,对各个预测模型库中的预测模型进行筛选,若预测模型公式中含有tk1项目自变量,则将该所述的预测模型纳入初筛预测模型组中;s4,对于初筛预测模型组中的预测模型,使用对应的验证集样本进行受试者工作特征曲线(即roc曲线)验证并计算曲线下面积auc值;s5,若auc值大于等于0.7,则将对应的初筛预测模型组中的预测模型纳入最终的预测模型组中;s6,对最终的预测模型组中的各个预测模型,按照参数综合方式进行模型优化,从而得到tc风险预测模型。
[0040]
具体实施时,比如用于模型开发的样本数量为5259例,通过三折法抽样,分别分为三组样本:组1为1753个样本,组2为1753个样本,组3为1753个样本。模型开发中使用ilkl算法进行样本匹配,使用roc曲线验证方法进行模型的筛选工作。三折法组合一使用组1作为验证集,组2与组3合并形成训练集。如图3,通过对训练集的项目筛选和ilkl算法的循环处理,获得预测模型库1(内含预测模型100个)。然后分别在三折法抽样的组合二和组合三中重复以上步骤,形成不同的预测模型库。
[0041]
可选的,如图3所示,步骤s2所述的使用不平衡回归ilkl算法进行建模具体包括以下步骤:s21,将样本根据终点事件状态分为两组,其中,终点事件为“一般风险”(即tr-1和tr-2)的样本为“多数组”,阳性样本(即tr-3及以上的ti-rads分级)组为少数组;s22,将作为自变量的体检指标项目设为聚类指标变量,将终点事件设为样本标签,将k(大于2小于等于10的自然数)设定为类别组数;s23,从多数组样本中随机选择k个样本作为质心,对多数组样本中的每一个点,基于聚类指标变量计算其与每一个质心样本的欧几里德距离,并将其划分到距离最短的质心所属的集合中;s24,所有数据归入k个集合后,重新计算每个集合的质心点;s25,若新计算出来的质心样本和原质心样本之间的欧几里德距离小于设置的阈
值(即达到收敛状态),则将获得的k个集合作为k-means聚类分组;否则继续进行迭代,直至最终获得k-means聚类分组;s26,按照少数组比多数组的比例对k-means聚类分组进行随机抽样;s27,合并所有的抽样样本与少数组样本,通过二分类逻辑回归获得预测模型。
[0042]
如阳性样本为120例,在健康组抽样的环节,按照阳性组/健康组比例对k-means聚类分组进行随机抽样,从而使健康组抽样后的样本数目接近120,从而达到降低预测偏倚性的目的。
[0043]
可选的,步骤s6中所述的按照参数综合方式进行模型优化具体包括以下步骤:s61,使用最终的预测模型组中的各个预测模型,分别对全部的训练集加验证集的数据进行受试者工作特征曲线(即roc曲线)验证并计算曲线下面积auc值;s62,根据验证结果中对阳性样本的预测正确率大小对所述的各个预测模型进行排序;s63,选择预测正确率最高的2-10个模型,进行预测模型的参数优化:预测模型中包含三种参数——项目自变量、项目自变量的系数以及常数;优化时,将所有模型中的所有项目自变量合并作为最终的tc风险预测模型的项目自变量;将所有模型中的各个项目自变量的系数相加再求平均后作为tc风险预测模型的相应项目自变量的系数;将所有模型中的常数相加再求平均后作为tc风险预测模型的常数。
[0044]
比如进行参数优化时,预测模型中包含三种参数,an为模型中所有自变量项目的固定编号,实际编号为a1至an;b
m-n
为项目系数,指模型m(比如m=1~5)中an项目的参数,实际编号为b
1-1
至b
5-n
,若任一模型未含有某an项目自变量,其项目参数b值设定为0;cm为模型m的常数,实际编号为c
1-c5。优化后模型中包含5个合并模型中所有的an项,参数b和c的优化依照如下公式:c
op
=(c1 c2 c3 c4 c5)/5b
op(m-n)
=(b
1-n
b
2-n
b
3-n
b
4-n
b
5-n
)/5。
[0045]
可选的,如图3所示,通过以下方法对作为自变量的其他体检指标项目进行筛选:首先,(可通过显著性分析、相关性分析和秩和分析)验证已量化转化项目与终点事件之间的紧密相关性程度;若相关性的显著度p《0.1,则将该项目纳入待选项目;否则不纳入待选项目;其次,对筛选获得的待选项目,(可通过box-tidwell法、项目间相关性分析法和多重共线性检验法)对项目之间的相关性进行排查,选择满足自变量三项假设的项目纳入回归项目中,最终与血清细胞质胸苷激酶1检测结果一起作为自变量;其中,所述的满足自变量三项假设,即项目与终点事件(logit)转换值之间存在线性关系、项目间无多重共线性与显著相关性。
[0046]
在进行样本采集时,采集受检者的以下信息:1)受检者基本信息(去除敏感信息);2)家族病史/个人病史;3)生活方式调查结果;4)生化检测结果;5)医学影像学检查结果。然后将体检项目与转换后量化项目共同导入形成的数据库存储系统中。按照记录内容的逻辑关系分为受检者基本信息、家族病史/个人病史、生活方式调查结果、单项检测结果和医学影像学检查结果,其中单项检测结果又由血液检验、生化检验、感染免疫检验和体液检验组成。
[0047]
可选的,通过提取医学影像学检查文字结果中的ti-rads分级量化结果,来实现将医学影像学检查结果转换为量化的ti-rads分级;将医学影像学检查结果转换为量化的ti-rads分级后,还包括:将分类选项结果进行自然数赋值处理,从而实现将初始不同格式的检测调查结果数据转换为一致性的量化数据。
[0048]
可选的,利用终点事件提取工具提取医学影像学检查文字结果中的ti-rads分级量化结果,如图4所示,具体包括以下步骤:a,通过len和substitute命令,输出影像学文字结果中“ti”的出现次数;b,使用find命令获得“ti”在文字中首次出现的定位值n1,并使用mid命令抓取n1位置ti-rads后的分级字符串;c,将首次出现定位值n1 1作为起始位置,继续使用find命令,获得“ti”第二次出现的定位值n2,并抓取n2位置的ti-rads分级字符串;d,将第二次出现的定位值n2 1作为起始位置,继续使用find命令进行定位,以此类推,得到所有位置对应的ti-rads后的分级字符串;e,使用value和iferror命令将所有位置得到的字符串均转换为数字(如无数字则赋值“0”);f,使用max命令输出转换后的数字中的最大值l;g,使用if命令,将获得的t值转换为风险分级数1或2。
[0049]
具体实施时,比如利用excel 2013中的命令行实现提取医学影像学检查文字结果中的ti-rads分级量化结果:步骤1):fx=0.5*(len(初始文字)-len(substitute(初始文字,"ti","")));步骤2):fx=mid(a3,find("ti",初始文字) 8,1);步骤3):fx=mid(a3,find("ti",初始文字,n1 1) 8,1);步骤4):fx=mid(a3,find("ti",初始文字,n2 1) 8,1);步骤5):fx=mid(a3,find("ti",文字表格,n3 1) 8,1);步骤6):fx=iferror(value(抓取ti-rads分级字符串),0);步骤7):fx=max(步骤2提取分级值:步骤5提取分级值);步骤8):fx==if(l》2,2,1)。
[0050]
可选的,所述的将分类选项结果进行自然数赋值处理,即利用逻辑值转换工具将项目按照二分类、有序和无序的不同,分别转换为量化值(比如二分类项目按照阳/阴性结果转换0/1或1/2,如男/女可分别转换为1/2;tr-1和tr-2转换为1,tr-3、tr-4和tr-5统一转换为2;多分类项目按照顺序转换为自然数数列(如1,2,至n))。
[0051]
本技术中,可通过对风险概率结果的区段识别(如根据cutoff=0.500分段,小于0.5的为低风险人群,大于等于0.5的为高风险人群),输出受检者的tc风险分群信息。
[0052]
具体实施时,可收集同一地点同一机构长期的体检数据,其中包括了tk1检测和其它常规健康体检项目(包括但不限于血常规、肿瘤标志物等)。如图5所示,按照本技术所建立的tc风险预测模型,选定体检报告中特定项目;联合tk1试剂盒检测结果导入预测模型;通过模型进行风险概率计算和判断;根据计算结果,进行预测结果的文本输出。本技术所建立的tc患病风险预测模型,可适用于普通的健康人群,具体可以被用于体检机构中进行tc患病风险预测。
[0053]
实验例:采用某医院2009-2014年体检数据(样本总数20679),其中tc一般风险(tr-1与tr-2)组16480人,阴性组4199人(符合真实比例,提高了本技术的回归模型的拓展性和风险评测方法实用意义),基于本技术的建模方法进行建模。最终的预测模型中使用了包括年龄分级性别以及8种生物标志物或体检项目指标作为自变量:血清胸苷激酶1浓度(tk1)、α羟丁酸脱氢酶、高密度脂蛋白、尿酸、谷丙转氨酶、血小板计数、癌胚抗原(cea)及谷草转氨酶。
[0054]
其中,年龄以年为单位;性别中男性赋值为1,女性赋值为0;tk1值(pm)检测采用深圳华瑞同康生物技术有限公司生产的cis系列化学发光数字成像分析仪及胸苷激酶1诊断试剂盒;尿酸、血小板计数、高密度脂蛋白可采用xfa6100全自动血液细胞分析仪检测;α羟丁酸脱氢酶、谷草转氨酶、谷丙转氨酶可采用md-100型半自动生化分析仪检测;癌胚抗原(cea)可采用elisa检测试剂盒(供应商:上海冠导生物工程有限公司)与全自动生化检测仪进行测定。
[0055]
对应获得的患病甲状腺癌tc风险预测模型的函数公式为:风险概率p=expx/(1 expx),其中,x=-1.972 (0.0285
×
年龄(岁)) (-0.472
×
性别赋值) (0.23
×
tk1(pm)) (0.004
×
血小板计数(109/l)) (-1.0485
×
高密度脂蛋白(mmol/l)) (-0.002
×
尿酸(μmol/l)) (0.021
×
α羟丁酸脱氢酶(u/l)) (-0.003
×
谷丙转氨酶(u/l)) (-0.011
×
谷草转氨酶(u/l)) (0.1745
×
cea(μg/l))。
[0056]
风险概率p为医学影像学出现ti-rads 3类结果的可能性,即使用甲状腺影像报告及数据系统中的ti-rads 3类分级结果作为预测模型的终点事件,锚定了确定的tc风险概率;当风险概率p《0.5时,可判定为一般风险;而当风险概率p≥0.5时,可判定为高风险。
[0057]
另外,采用某医院2009-2017体检数据(样本总数4552)对该预测模型进行验证,如图6所示,获得auc值为0.749,95%ci 0.736-0.761.采用自助抽样法置信区间(1000迭代;随机数种子:978)检验获得的youden指数为0.3873,敏感性为55.53.特异性为84.20(阈值0.5)。
[0058]
此外,发明人还进行了该预测模型与联合检测方法的价值比较,结果显示,本实验例中采用10个项目同时检测,相较于细胞增殖标志物tk1或肿瘤标志物cea单独使用或tk1、cea联合使用,最终建立的tc风险预测模型的预测准确率更高。
[0059]
以上均为本技术的较佳实施例,并非依此限制本技术的保护范围,故:凡依本技术的方法、原理所做的等效变化,均应涵盖于本技术的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。