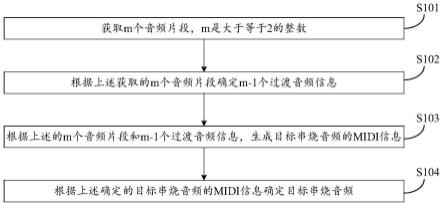
通过动态响应打断内容改进会话ai的双工通信
技术领域
1.本公开总体上涉及用于呈现由用户使用人工智能引擎提供的听觉输入的反馈的自动化系统和方法,并且具体地涉及被配置为在基于声音的交互期间实时智能地打断用户以便确保及时反馈和/或主持指导的系统和方法。
背景技术:
2.近几十年来,计算机辅助语言学习领域发展迅速,特别是对计算机辅助发音训练的兴趣也随着最近基于网络和移动应用程序和资源的激增而增长。其中一些在技术上变得越来越复杂,在某些情况下合并了诸如自动语音识别(asr)和人工智能(ai)技术,进一步为语言产出和个性化反馈提供了机会。当前的人工智能服务能够产生对话,但与这种对话相关的人工音调一直存在。例如,学生或其他用户与面对面的老师或其他“真实”评论者与使用此类技术的学生或其他用户与面对面的老师或其他“真实”评论者的体验之间仍然存在鸿沟。例如,ai继续提供相对于正常人类对话的发生方式而言感觉是人造的或不自然的对话体验。为了更接近整合技术与发音教与学的目标,虚拟反馈平台必须提供更真实、更自然的对话体验。此外,在许多其他情况下,人工智能呈现的打断内容可以改善两个或更多人之间的对话。
3.本领域中需要解决上述缺点的系统和方法。
技术实现要素:
4.在一个方面,公开了一种在语音期间呈现打断内容的计算机实现的方法。该方法包括在第一时间并且由经由计算设备访问的应用程序接收第一用户讲话的第一音频数据的第一步骤,以及通过应用程序检测在第一音频数据中的第一类型的语音异常的至少第一指示符的第二步骤。第三步骤包括经由应用程序并基于第一指示符确定触发事件已经发生。该方法还包括第四步骤:经由应用程序使得呈现第一打断内容,其中第一打断内容包括关于检测到的语音异常的反馈,并且无论第一用户是否仍在讲话,都在随后的第二时间呈现。
5.在另一方面,公开了一种在会话期间呈现打断内容的计算机实现的方法,所述会话包括至少第一参与者和第二参与者。该方法包括在第一时间并且由经由计算设备访问的应用程序接收至少第一参与者讲话的第一音频数据的第一步骤,以及由应用程序检测在第一音频数据中的第一类型的会话异常的第一指示符的第二步骤。该方法还包括由应用程序基于第一指示符确定触发事件已经发生的第三步骤,以及经由应用程序使得呈现第一打断内容的第四步骤。此外,第一打断内容包括与检测到的会话异常相关联的主持指导,并且在第一参与者和第二参与者中的一个或两个正在讲话时在第二时间呈现。
6.在另一方面,公开了一种确定语音异常是否已经发生的计算机实现的方法。该方法包括在第一时间并且由经由计算设备访问的应用程序接收第一用户讲话的第一音频数据的第一步骤,以及经由用于应用程序的基于语音的机器学习模型基于第一音频数据对与
第一用户相关联的一个或更多个语音特性进行分类的第二步骤。此外,第三步骤包括在第二时间并且经由应用程序接收第一用户讲话的第二音频数据,以及经由应用程序确定在第二音频数据中语音异常已经反生的第四步骤,该确定至少部分基于第二音频数据与分类的语音特性的比较。此外,该方法包括响应于确定语音异常已经发生,经由应用程序使得由计算设备呈现第一打断内容的第五步骤。在这种情况下,第一打断内容包括关于检测到的语音异常的反馈,并且无论第一用户是否还在讲话,都在随后的第三时间呈现。
7.本公开的其他系统、方法、特征和优点对于本领域的普通技术人员在检查以下附图和详细描述时将是或将变得显而易见。旨在将所有这些附加的系统、方法、特征和优点包括在本描述和本概述中,在本公开的范围内,并受所附权利要求的保护。
附图说明
8.参考以下附图和描述可以更好地理解本发明。图中的组件不一定按比例绘制,而是强调说明本发明的原理。此外,在附图中,相同的附图标记在不同视图中表示对应的部分。
9.图1a和图1b提供了示出根据一个实施例的第一用户参与智能反馈助手的服务的示例的序列;
10.图2a-2c共同描绘了根据一个实施例的用于向用户提供实时反馈的系统的示意图;
11.图3是根据一个实施例的可能导致系统打断用户的触发事件的一些示例的示意图;
12.图4a-4e提供了根据一个实施例的示出第二用户参与智能反馈助手的服务的示例序列;
13.图5a和图5b呈现了根据一个实施例的智能反馈助手打断讨论以在会话期间提供主持的示例;
14.图6是示出根据一个实施例的用于确定用户是否应该被打断的过程的一个示例的流程图;
15.图7a和图7b呈现了根据一个实施例的智能反馈助手打断其中两个人正在互相交谈的会话以在会话期间提供主持的示例;
16.图8a和图8b呈现了根据一个实施例的智能反馈助手向说话者呈现私人打断消息的示例;
17.图9a-9c呈现了根据一个实施例的智能反馈助手打断讨论以澄清话题来源的示例;
18.图10a和图10b呈现了根据一个实施例的智能反馈助手基于语音内容打断讨论的示例;
19.图10c和图10d呈现了根据一个实施例的智能反馈助手基于语音内容呈现私人打断消息的示例;
20.图11a-11c呈现了根据一个实施例的智能反馈助手基于姓名错误发音呈现私人打断消息的示例;以及
21.图12是根据一个实施例的用于在基于语音的交互期间提供实时反馈的计算机实
现方法的过程的流程图。
具体实施方式
22.实施例提供了用于在与智能反馈助手(“助手”)的基于语音的交互期间生成和呈现适当的响应或信息的系统和方法。响应是由人类用户实时打断对话提供的。换句话说,并非是延迟信息的呈现直到用户完成他们的口头表达,助手可以打断正在进行的用户演讲并“在当下”提供反馈。这种及时响应使助手能够更好地模拟人类听众,并显著提高用户将反馈纳入其对话的能力。在一些情况下,助手可以附加地或替代地被配置为在两个或更多个人之间的会话期间在适当的时间进行调解,以便提供主持指导和/或其他及时的反馈,从而丰富人类参与者之间的对话的质量。
23.如以下将更详细讨论的,所提出的实施例描述了一种计算机实现的服务,该服务被配置为主动收听用户的语音内容并基于默认设置和/或用户偏好确定何时需要打断。如本文所用,术语“语音内容”或更简单地“语音”是指由人类用户说出或以其他方式产生的可听声音。此外,包括或大于单个辅音的由人类产生的词或词的一部分将被称为话语或“音素片段”。通常,服务接收用户的语音作为音频数据,进而确定音频数据是否包括触发事件的指示。出于本技术的目的,触发事件是指与预定条件匹配并且将导致系统生成并呈现适当消息的听觉事件或听觉事件序列,而不管用户是否仍在说话。如果有触发事件的指示,则系统启动处理操作以确认触发事件并确定已经发生的触发事件的类型。确认后,服务可以识别对事件类型和事件内容的适当响应,并在用户语音期间近乎实时地呈现响应。
24.此外,实施例可以利用可用的智能自动化助手的特征和组件,智能自动化助手在此也称为虚拟助手,其可以提供人与计算机之间的改进的接口。这样的助手允许用户使用自然语言以口头和/或文本形式与设备或系统进行交互。例如,可以将虚拟助手配置为易于使用的接口,接收和解释用户输入,将用户的意图操作化为任务和这些任务的参数,执行服务以支持这些任务,并产生用户易于理解的输出。
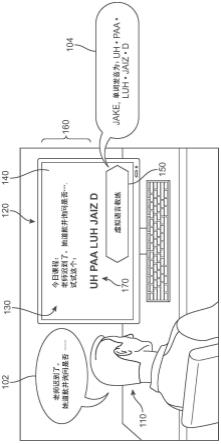
25.为了介绍的目的,参考图1a和图1b示出了所提出的系统和方法的一个实施例的概述。在图1a和图1b中,描绘了通过计算设备实现的智能反馈辅助系统(“系统”)的实施例。在图1a中,第一用户110坐在桌边,参与由第一用户设备120提供的活动。在这种情况下,该活动正在经由显示在第一用户设备120的监视器140上的虚拟语言教练应用程序(“第一应用程序”)130来执行。例如,第一应用程序130正在向第一用户110显示文本样本160,并且当第一用户110试图朗诵文本样本160中显示的单词(例如,“老师迟到了。她道歉并询问是否...(the teacher was late.she apologized and asked if
…
)”)时,经由第一应用程序130访问的虚拟语言教练150正在积极聆听。当第一用户110开始讲话时,教练150经由连接到第一用户设备120的麦克风接收语音作为音频数据,并且近乎实时地连续处理和分析音频数据。在图1a中,第一用户110的第一语音102包括“老师迟到了。她道歉并询问是否
‑‑‑
(the teacher was late.she aplowged and asked if
‑‑‑
)”。在此以及在本公开全文中应当理解,诸如
“‑‑‑”
之类的虚线的使用表示某人正在讲话并且已被另一个源(例如,教练150)打断的情况。
26.当系统接收到包括作为“aplowged”的“道歉(apologized)”的错误发音的音频数据时,系统可以检测到错误发音并识别正确的或适当的表达应该是什么。作为响应,系统立
即使教练150在讲话中打断第一用户110以纠正他。换言之,不是等待第一用户110完成讲话,而是系统被配置为“跳入”并打断以提供近乎即时的反馈(即,在时间上尽可能接近检测到的错误发音事件)。如图1a所示,作为教练150的第一应用程序130生成第一听觉反馈响应104“单词发音为:uh
·
paa
·
luh
·
jaizd(the word is pronounced:uh
·
paa
·
luh
·
jaizd)”。在一些实施例中,第一应用程序130可以附加地或替代地通过显示器140生成打扰性较小的消息170(“试试这个:uh
·
paa
·
luh
·
jaizd(try this:uh
·
paa
·
luh
·
jaizd)”)。
27.在图1b中,接收到反馈的第一用户110再次以第二语音106开始(“我将再试一次。她uh paa luh jaizd并问
–
(i will try again.she uh paa luh jaizd and asked
–
)”)。在某些情况下,系统可以进一步配置为允许用户包括这样的会话响应(例如,“我将再试一次”)并认识到这些陈述虽然与显示的朗诵内容无关,但不需要更正。此外,在一些实施例中,系统可以可选地根据用户选择的偏好进行调解,以提供流动鼓励。在这种情况下,系统再次使得教练150打断第一用户110,这一次带有第二听觉反馈响应108(“好多了!(much better!)”),而显示的反馈包括“你做到了!(you did it!)”。因此,类似于可能在第一用户110和人类教师之间发生的自然的给予和接受会话流,系统可以“讨论”或以其他方式产生重叠或作为双工通信交换的一部分的响应。与在朗诵或其他语音结束时提供的反馈相比,这种类型的来回交流已被证明在学习新语言或其他主题方面提供了更大的好处。
28.现在参考图2a-2c,描绘了用于实现本文公开的系统和方法的环境200a、200b和200c(统称为200)的实施例的概览。该环境表示用于捕获和处理实时音频数据的过程和系统,例如以提高用户的语言能力,并响应于在音频数据中检测到的触发事件而生成近乎即时的反馈。在不同的实施例中,一些步骤可以由基于云的一个或更多个计算系统的组件执行,并且一些步骤可以由本地一个或更多个计算系统的组件执行。
29.此外,虽然未在附图中示出,但所提出的系统可以包括或可以访问能够与人类用户进行智能交互的组件,例如在智能虚拟助手技术中使用的组件(例如,amazon echo、google home、apple iphone等),能够在服务和用户之间提供基本实时的同步通信会话。其他示例包括基于的技术(例如)和基于会话ai的驾驶舱,例如mbux ai
tm
,以及trt、amp和triton。
30.虚拟助手可以包括用于以自然方式与最终用户进行会话并利用会话ai系统和算法的规定。例如,虚拟助手可以包括对话管理系统、响应接口系统和语言生成系统。从这些单元接收到的信息可以转换为最终用户的最终输出。响应接口系统因此可以能够将来自其他系统的输入转换成文本、语音和/或其他种类的表达(例如调制的语音、表情符号、文本、图像等)。因此,用户设备可以是用户使用的能够与虚拟助手进行通信的计算设备。用户设备可以包括为用户提供输入和/或查看信息的接口的显示器,和/或用于产生合成语音的扬声器(或扬声器连接)。例如,用户可以使用在膝上型计算机上运行的程序与虚拟助手交互,例如基于文本的聊天程序、基于声音的通信程序和/或基于视频的通信程序。虚拟助手的一个或更多个资源可以在一个或更多个服务器上运行。每个服务器可以是单台计算机、单台计算机的部分计算资源、相互通信的多台计算机或远程服务器网络(例如,云)。一个或更多个服务器可以容纳本地数据库和/或与一个或更多个外部数据库通信。
31.为了清楚起见,环境200在三个单独的附图中被描绘。在图2a中,示出了环境200的
第一方面200a。在该示例中,可以看出各种用户可以参与智能反馈助手的服务,包括:群组204(包括第一参与者206(用户a)、第二参与者208(用户b)和第三参与者210(用户c)),先前使用过该服务的个体第四参与者212(用户d),以及第一次使用该服务并且因此具有“空”偏好模块的个体第五参与者214(用户e)。关于群组204,可以理解三个参与者正在开会并且经由可以是共享资源或属于参与者之一的单个计算设备(第一计算设备216)访问服务。在其他实施例中,三个参与者中的两个或更多个可以具有他们自己的设备来在会议期间运行服务的各个实例。在一些实施例中,第四参与者212和/或第五参与者214可以是正在亲自开会的群组204的远程成员。在其他实施例中,第四参与者212(经由第二计算设备218)和/或第五参与者214(经由第三计算设备220)可以使用该服务来帮助实现他们自己的个体目标。下面在图4a-5b和图7a-11d中呈现了可通过图2a所示的布置实现的所提出的实施例相关的这种群组动态和个体动态的示例。
32.在不同的实施例中,计算设备216、218和220可以指各种计算设备类型,例如但不限于台式计算机、膝上型计算机、笔记本电脑、平板电脑、智能手机、智能手表等。每个设备可以包括电子单元,电子单元包括多个不同组件,例如用户接口组件(例如,触摸屏显示器、键盘、鼠标、麦克风、扬声器等)、用户接口模块、处理器和/或通信模块。如在本说明书中所使用的,术语“模块”旨在包括但不限于被配置为执行一个或更多个软件程序的一台或更多台计算机、处理单元或设备,该软件程序包括导致计算机的一个或更多个处理设备或单元来执行一项或更多项功能的程序代码。该设备可以包括系统,该系统包括一个或更多个处理器和存储器。存储器可以包括非暂态计算机可读介质。存储在存储器中的指令可以由一个或更多个处理器执行。该设备可以被配置为接收和分析来自与该设备相关联的各种输入传感器的数据或从连接到该设备的外部组件或设备传送的数据。
33.通信模块可以允许设备进行无线通信。在这种情况下,通信模块被示为能够访问无线网络202;但是,也可以使用有线连接。例如,通信模块可以包括有线串行总线,例如通用串行总线或并行总线,以及其他连接。通信模块还可以包括使用蓝牙无线电技术、ieee 802.11(包括任何ieee802.11修订版)中描述的通信协议、蜂窝技术(例如gsm、cdma、umts、ev-do、wimax或lte)的无线连接,或技术,以及其他可能性。在一个实施例中,服务被配置为完全离线可用,从而为应用程序描述的所有特征和组件本地地驻留在用户的计算设备上。
34.api(应用程序编程接口)的用户接口可用于促进最终用户与例如分布式计算环境(例如,基于网络的应用程序)或完全驻留在单个计算机系统上的应用程序(例如,独立的应用程序)的交互。在不同的实施例中,一个或更多个计算设备可以包括设备显示器(“显示器”),其可以例如为软件应用程序(“应用程序”)呈现信息和媒体。在一些实施例中,应用与提供智能反馈助手服务的平台相关联或者是所述平台。在一些情况下,用户设备可以通过网络浏览器运行客户端软件,在这种情况下,客户端软件可以托管在与计算机系统相关联的服务器上。在其他情况下,用户设备可以运行已通过集中式市场(即“应用商店”)下载的本地软件应用程序的形式的客户端软件。在一些实施例中,可以以其他方式下载应用程序以在设备上本地访问。在一些情况下,虽然允许用户执行各种任务的客户端软件可以在用户设备上运行,但是一些软件数据可以从与远程服务器相关联的数据库中检索和存储。
35.在一些实施例中,参与者可以通过可以呈现在设备显示器上的用户接口来接收和
发送信息。在一些实施例中,显示器可以是触摸屏,允许客户通过触摸直接与用户接口交互。用户接口可以指操作系统用户接口或者可以在设备上运行的一个或更多个软件应用程序的接口。在一些实施例中,用户接口可以包括消息传递窗口或其他聊天空间,助手可以通过其呈现消息或其他数字内容或者用户可以提供输入。此外,该应用程序被配置为通过麦克风等音频输入设备接收用户语音输入。在一些实施例中,应用程序可以提供用于访问和修改设置以及查看应用程序活动的用户设置和配置文件接口。从配置文件接口做出的选择可以包括与应用程序相关的用户特定信息,例如用户设置、用户选择的触发事件偏好、每个用户设备的用户期望的警报偏好(例如,sms消息、应用程序内消息、音频警报、视觉警报、警报频率等)和/或触发事件的类型,以及可选的应用活动历史存储库,该存储库可以存储并向用户呈现反映过去基于应用的反馈或其他响应的各种数据。在一些实施例中,应用程序可以被配置为连接到云(例如,通过wi-fi或蜂窝连接)以添加或修改也可以或替代地存储在云中(例如在用户账户数据库中)的用户账户的信息。
36.一般来说,“接口”可以被理解为是指用于通过客户端应用程序向应用程序用户传送内容的机制。在一些示例中,接口可以包括可以通过本机应用程序用户接口(ui)呈现给用户的弹出窗口、控件、可致动接口、交互按钮或可以通过本机应用程序ui显示给用户的其他对象,如以及特定应用程序用于呈现与这些本机控件相关的内容的本机机制。此外,术语“致动”或“致动事件”是指与通过接口对应用程序的特定输入或使用相关联的事件(或特定事件序列),其可以触发应用程序的显示变化。
37.此外,“本机控制”指的是用于通过客户端应用程序将内容传送给应用程序用户的机制。例如,本机控件可包括可通过本机应用程序ui、触摸屏访问点、菜单项或可通过本机应用程序ui、更大接口的片段,以及用于呈现与这些本机控件相关的内容的特定应用程序的本机机制向用户显示的其他对象呈现给用户的可致动或可选择选项或“按钮”。语音控件也可用于致动选项。术语“资产”指的是可以与本机应用程序中的本机控件相关联地呈现的内容。作为一些非限制性示例,资产可以包括可致动弹出窗口中的文本、与按钮或其他本地应用对象的交互式点击相关联的音频、与教学用户接口相关联的视频或其他此类信息呈现。
38.在图2a中,第一智能虚拟助手(sfa)服务292,包括:第一sfa应用程序(“应用程序a”)224的实例,正被第一计算设备216访问,第二sfa服务294,包括第二sfa应用程序(“应用程序b”)228的实例,正被第二计算设备218访问,以及第三sfa服务296,包括第三sfa应用程序(“应用程序c”)232的实例,正被第三计算设备220访问。另外,如将在图2b和图2c中更详细地讨论的那样,每个单独访问的sfa服务包括或可以访问偏好模块。为了参考的目的,第一sfa服务292可以访问第一偏好模块(“模块a”)226,第二sfa服务294可以访问第二偏好模块(“模块b”)230,并且第三sfa服务296可以访问到第三偏好模块(“模块c”)234。
39.在不同的实施例中,sfa服务中的一个或更多个可以本地存储在用户计算设备上,可以完全存储在云计算环境中并且在本地计算设备上运行,或者可以包括驻留在本地设备上的组件以及驻留在云环境中的组件。图2a和图2c中的虚线表示服务具有可以被配置为驻留在本地计算设备和/或云网络环境中的一个或更多个组件的潜力。换言之,下文关于图2b和图2c描述的各种组件可以包括在计算设备上本地存储的sfa服务中。因此,虽然为了说明的目的,服务组件被示为通过图2a-2c中的网络202被访问,在其他实施例中,可能不需要网
络连接。因此,计算设备216、218和220中的一个或更多个可以在本地或通过网络202访问sfa服务。
40.在不同的实施例中,用于计算设备216、218和220的输入设备(例如麦克风、触摸屏、鼠标、触控板、键盘等)可用于收集用户数据。用户数据被传送到用户正在与之交互的sfa应用(例如,应用a、应用b、应用c)。出于该示例的目的,用户数据主要包括用户说话的音频数据,尽管在其他实施例中,用户数据可以包括视觉和/或基于文本的内容或其他用户选择/输入。
41.在图2b中,示出了环境200的第二方面200b。图2b包括sfa服务的实施例的一些组件的表示。在服务至少部分地驻留在本地计算设备之外的一些实施例中,应用可以将音频数据传送到可选的远程用户账户数据库248以进行处理、分析和存储。在一个实施例中,用户账户数据库248是存储与一个或更多个用户相关的账户数据的内容库。对于多个用户,数据可以包括姓名、个人和专业详细信息、偏好、用户当前和过去的历史、支付信息以及其他详细信息,这部分取决于sfa提供的服务的类型。在一个实施例中,用户账户数据库248包括订阅sfa服务的每个最终用户的计算设备的注册表。例如,用户可能拥有或使用从其访问sfa的多个计算设备。注册表识别与用户关联的一个或更多个设备。最终用户还同意系统在每个注册设备之间适当地共享数据。在一些实施例中,从客户端收集的部分或全部数据将被加密以确保隐私。
42.在服务驻留在本地的实施例中,音频数据可以由本地版本的sfa机器学习模型接收,该模型最初将由大型数据语料库进行预训练,然后适应该设备的特定用户和应用程序的需求。替代地或附加地,在一些实施例中,应用可以访问中央sfa机器学习模型(“中央模型”)250,该模型最初由大量数据语料库训练,然后随着从单个应用实例收集附加的用户数据而不断更新和重新训练,然后提供给应用程序的用户。在一些实施例中,初始或更新的中央模型250将生成设置和配置,这些设置和配置最初将用作应用程序体验的默认偏好和操作配置文件。用户可以手动更改其设备上运行的sfa实例的配置,和/或应用程序将继续以持续的方式收集用户数据,以自动修改和定制模型以满足用户的需求.
43.在一个实施例中,如果在用户登录时没有或没有足够的用户活动用于系统确定用户的偏好,可以理解,系统可以被配置为参考默认模型或默认模型的一个版本,该默认模型是根据与设备用户的人口统计特征匹配的同一应用程序的用户子集的模型使用情况选择的,并且其偏好在使用时是已知的。在某些情况下,这可以作为更量身定制的初始或默认用户体验,从中可以进行智能系统的训练。例如,对于图2a中的用户e,就是这种方法,用户e第一次使用该服务。例如,当客户端设备第一次通过网络下载应用程序时,或者现有的视频会议应用程序共享包含该应用程序作为插件的更新时,就会发生这种情况。在不同的实施例中,中央模型可以接收更新的训练数据(例如,随着更多音频数据或用户与应用程序交互,将额外的去标识化特征上传到服务器)以继续改进模型。在一个示例中,如果改进的通用模型可用,则应用被配置为触发将更新的模型自动下载到客户端。
44.在一些其他实施例中,可以在云环境中维护集中式知识库238,并用作关于可能的触发事件242(参见图3)、响应选项244和集体用户交互历史246的信息的中央存储库。在一些其他实施例中,特征化器可以最初对数据进行去识别化并处理和转换数据以对可消耗特征进行建模。在一些实施例中,sfa的每个本地实例可替代地或附加地包括或有权访问个性
化打断ai知识库(“知识库”),该知识库存储和管理用户的偏好240和适用于触发事件、响应选项和/或交互历史的选择。在不同的实施例中,知识库附加地或替代地与将在下面参考图2c讨论的偏好生成系统298通信。
45.一般来说,响应选项244包括大范围的配置,通过这些配置可以指示sfa与用户交互。将在下面参考图4a-5b和图7a-11c讨论这些响应选项的一些示例。在一些实施例中,知识库238还可以包括关于一旦中央模型250认为有必要打断就可以由sfa生成和呈现的可能响应的指令。在其他实施例中,各种响应(例如,特定于需要打断的场合的自动反馈)可以存储在一个单独的模块中供sfa使用。交互历史可以理解为指代任何已收集的用户数据,包括用户体验和训练事件,通常去除任何标识符信息。
46.如前所述,在一些实施例中,中央模型250可以为sfa的操作生成默认模式,例如为新用户在sfa的操作中提供默认偏好。如果用户不希望提交任何附加数据以获得更个性化的体验,则可以继续应用默认模式(参见图2c)。为了提供这里描述的特征,可以根据从多个来源获得的数据训练中央模型250。在不同的实施例中,中央模型250可以指深度神经网络(dnn)模型,包括具有多个连接节点的多层(例如,感知器、玻尔兹曼机、径向基函数、卷积层等)的深度学习模型,该深度学习模型可以使用大量输入数据进行训练,以快速地以高准确度解决复杂问题。在一个示例中,感知器可以接收一个或更多个输入,这些输入表示感知器正在被训练以识别和分类的数据对象的各种特征,并且基于该特征在定义数据对象中的重要性,这些特征中的每一个都被分配一定的权重。一旦dnn被训练好,dnn就可以被部署并用于通过推理技术来对模式进行识别和分类。
47.如上所述,需要训练深度学习或神经学习系统以从输入数据生成推论。在至少一个实施例中,推理和/或训练逻辑可以包括但不限于用于存储前向/后向和/或输入/输出权重和/或与在一个或更多个实施例的方面进行训练和/或用于推理的神经网络的神经元或层对应的输入/输出数据的数据存储装置。在至少一个实施例中,数据存储装置存储在使用一个或更多个实施例的方面进行训练和/或推理期间输入/输出数据和/或权重参数的前向传播期间结合一个或更多个实施例训练或使用的神经网络的每一层的权重参数和/或输入/输出数据。在至少一个实施例中,数据存储装置的任何部分可以与其他片上或片外数据存储一起包括,包括处理器的高速缓存或系统存储器。
48.在一些实施例中,使用包括语音样本266和区域样本274中的一个或更多个的训练数据集来训练未经训练的神经网络——例如,中央模型250的初始版本,这将在下面详细讨论。在至少一个实施例中,训练框架是pytorch框架,而在其他实施例中,训练框架是tensorflow、boost、caffe、microsoft cognitive toolkit/cntk、mxnet、chainer、keras、deeplearning4j或其他训练框架。在至少一个实施例中,训练框架训练未经训练的神经网络并使其能够使用本文所述的处理资源来训练以生成经训练的神经网络。在至少一个实施例中,可以随机选择权重或通过使用深度置信网络进行预训练来选择权重。在至少一个实施例中,可以以监督、部分监督或无监督的方式执行训练。
49.在至少一个实施例中,使用监督学习来训练未经训练的神经网络,其中训练数据集包括与输入的期望输出配对的输入,或者其中训练数据集包括具有已知输出的输入,神经网络的输出手动分级以教模型什么类型的情况应该触发sfa对用户语音的打断。在至少一个实施例中,未经训练的神经网络以受监督的方式进行训练,处理来自训练数据集的输
入,并将得到的输出与一组预期或期望的输出进行比较。在至少一个实施例中,误差然后通过未经训练的神经网络传播回来。在至少一个实施例中,训练框架调整控制未经训练的神经网络的权重。在至少一个实施例中,训练框架包括用于监控未经训练的神经网络如何向模型收敛的工具,模型例如为经训练的神经网络,该模型适合于基于已知的输入数据确定需要打断的场合。在至少一个实施例中,训练框架重复训练未经训练的神经网络,同时使用损失函数和调整算法(例如随机梯度下降)调整权重以细化未经训练的神经网络的输出。在至少一个实施例中,训练框架训练未经训练的神经网络,直到未经训练的神经网络达到期望的准确度。在至少一个实施例中,然后可以部署经过训练的神经网络以实现任意数量的机器学习操作。
50.类似地,在至少一个实施例中,未经训练的神经网络也或替代地使用无监督学习来训练,其中未经训练的神经网络尝试使用未标记的数据来进行自我训练。在至少一个实施例中,无监督学习训练数据集将包括没有任何关联输出数据或“基础事实”数据的输入数据。在至少一个实施例中,未经训练的神经网络可以学习训练数据集中的分组,并且可以确定各个输入如何与未经训练的数据集相关。在至少一个实施例中,可以使用无监督训练来生成自组织图,这是一种经过训练的神经网络,能够执行对减少新数据的维数有用的操作。在至少一个实施例中,还可以使用无监督训练来执行异常检测,这允许识别新数据集中偏离新数据集的正常模式的数据点。
51.在其他实施例中,可以附加地或替代地使用半监督学习,指的是在训练数据集中包括标记数据和未标记数据的混合的技术。在至少一个实施例中,训练框架可以用于执行增量学习,例如通过转移学习技术。在至少一个实施例中,增量学习使经过训练的神经网络能够适应新数据,而不会忘记在初始训练期间灌输在网络中的知识。
52.如图2b所示,服务的两个主要训练数据源包括语音样本266和区域样本274。语音样本266指的是标准语音语料库,用于训练标准声学模型,可以在模式开发过程中收集的其他语音数据,以及具有专家详细注释的学习者的非标准语音语料库,用于训练和评估语音模型252,其输出将由中央模式250在确定触发事件是否已经发生时使用。为了将未标记的语音样本266(即,没有伴随文本的语音)用作语音模型252的训练数据,可以应用自然语言处理器(nlp)268以生成自动标记的数据270,例如语音到文本处理器。随着收集到更多样本,该数据的大小可能会增加,然后将该数据提供给训练数据模块272以供中央模型250使用。
53.一般来说,nlp技术可用于处理样本语音数据以及解释语言,例如通过解析句子和确定单词的基本含义。实施例可以利用自然语言处理(nlp)领域中已知的任何技术。这些包括语音识别和自然语言理解中的任何技术。作为一个非限制性示例,系统可以包括用于对接收到的语音音频文件进行自然语言处理(nlp)的计算资源。例如,系统应用的nlp可以包括接收到的语音音频文件的机器翻译,以获得将接收到的语音音频文件捕获的语音翻译成书面文本。然后可以根据诸如文本摘要和/或情感分析的一种或多种nlp分析来分析机器翻译的文本。nlp分析可以包括对机器翻译的文本实施断句规则,以将文本分解成更小的文本块,例如段落和单独的句子。nlp分析还可以包括将词性标识符(例如,名词、动词、冠词、形容词)的部分标记到构成文本块的词。nlp分析还可以包括解析文本以创建一个或更多个解析树,该解析树概述了文本块的不同的可能解释。nlp分析还可以包括从文本块中提取一个
或更多个关键术语以更好地理解文本上下文的术语提取。nlp分析还可以包括将文本从一种语言翻译成另一种语言的语言翻译能力。
54.在不同的实施例中,区域样本274可以包括诸如本地新闻广播节目的音频片段之类的数据,以及用户位于和/或已选择作为他或她的偏好的区域的其他媒体源。在某些情况下,可包括来自语言技能标准化评估(例如ielts
tm
)的语音数据或由移动辅助语言学习(mall)应用程序(例如duolingo)记录的语音,其中学生大声朗读书面文本。类似地,隐藏字幕可用的源(电视节目、电影、广播媒体、在线视频或播客等)也可用于训练语言模型254。该数据可随着更多样本可用而随时间的推移更新,也提供给训练数据模块272以供中央模型250使用。
55.就本技术而言,语音异常指的是偏离标准规则、表达或对语言的期望。可能会出现几种类型的语言异常,包括错误发音、词汇语法不准确、韵律错误、语义错误、不正确的用语和言语不流畅。词汇语法(lexico-grammar)可以理解为是指单词(或词汇项或块)与其语法结构之间的关系,包括适用于特定语法上下文或环境的词汇,以及适用于特定词汇上下文或环境的语法。韵律是指语调、重音模式、响度变化、停顿和节奏,通常通过改变音高、响度、速度和持续时间以及发音力的变化来强调单词或短语来表达。因此,韵律错误通常是指对音调、响度、持续时间、速度或发音力度的不当使用,包括但不限于听起来不韵律、韵律不齐、缓慢或断断续续或太快的语音。语义错误包括误用介词、动词短语或其他词混淆(当一个人使用与另一个词(如灯和光)具有相似含义的词并在说话时混淆两者时)。此外,用语是指单词的公式化序列,包括惯用短语和谚语表达。言语不流畅包括用户使用填充词或声音(例如,嗯、啊、呃、唔等)和错误的开始、重新开始的短语或重复的音节等。
56.在图2b中,可以看出语音模型252可以包括语言能力识别模型(“语言模型”)254、情感识别模型(“情感模型”)256和内容评估模型(“内容评估器”)298中的一个或更多个,其中的每一个都可以产生将由中央模型250在确定是否应该发生打断时使用的输出。语言模型254可以被理解为包括声学模型、语言模型和评分模型中的一种或更多种。这三个模型的包含使得准确的自动语音评分成为可能。一般来说,声学模型是语音识别器的组件。通常,语音识别软件应用隐藏马尔可夫模型(hmm)来表示每个电话或声音。识别基于一系列概率,该模型从许多可能性中估计最可能的音素或单词。为语音的每一帧提取频谱特征,并且模型将每个可能的音素的概率关联起来。输出是对说出的单词的最佳统计估计。声学模型必须在一组语音数据上进行“训练”或优化。训练过程涉及将音频语音与该语音的转录配对,以便模型将声音与正字法表示相关联。声学模型应该针对与要识别的语音相匹配的语音进行训练,例如每个语音样本和区域样本274。因此,说话者的口音是关键因素,因为每个潜在的用户人口统计可能具有不同的发音曲目。因此,所提出的系统被配置为获取语音数据并在与用户目标语言的目标人群匹配的样本上训练声学模型。
57.此外,语言模型包括可能在响应中说出的词。该模型通常由n连词(n-gram)的频率组成。因此,如果语言任务是描述一个女孩吃苹果的图片,那么二连词“一个苹果(an apple)”和三连词“吃一个苹果(eating an apple)”很可能会频繁出现在用户响应中。语言模型有助于在单词识别过程中概率的分配。
58.评分模型是指用于从语音识别过程中选择特征并将它们应用于预测人类评级的方法。在语言评估中,测试开发人员不仅应该考虑作为人类分数的最佳预测因子的输出特
征,还应该考虑哪些预测因子与人类分数相关。例如,诸如语速之类的持续时间度量可以是人类对语法能力判断的强大统计预测因子。精通(versant)测试提供了几种评分模型。发音模型可以从识别过程中提取的频谱特性开发。例如,表演的节奏和片段方面被定义为参考一组母语人士话语的可能性,然后这些度量被用于非线性模型来预测人类对发音的判断。流畅度模型类似地从事件的持续时间发展而来,例如响应延迟、每个时间的单词、每个发音时间的片段和单词间时间。句子掌握主要来自响应中给出的单词错误数量,并使用部分信用rasch模型进行缩放。引出单个单词或短语的词汇项目使用识别的输出来确定响应是正确还是不正确,并将结果输入到二分法rasch模型中。在构建的响应中,例如复述故事,识别的输出被用于潜在语义分析方法(latent semantic analysis approach)中,以预测人类对词汇覆盖范围的判断。因此,versant测试试图通过在模型中使用不同的、相关的特征来分别预测每个特征,然后结合子分数来创建总体分数,从而保持结构有效性。在其他示例中,例如speechrater
sm
,与发音、流畅度和词汇相关的许多特征被输入到回归模型中,以预测口语任务的整体分数,而不是个人特质。
59.此外,在不同的实施例中,语言模型254可以包括但不限于自动发音错误检测(aped)模型。一般来说,aped系统的目标是找到有效的置信度度量和组合特征,这样可以为标准发音产生更高的分数,但对非标准发音产生较低的分数。如果这些分数低于某些阈值,则可以将它们检测为发音错误,或者将这些分数馈给到经过训练的分类器中以确定发音是否正确。基于声学语音学的方法通常将aped问题视为比较或分类问题。因此,在语音学统计分析的基础上,首先提取该片段的各种特征,包括声学特征、感知特征和结构特征,然后从中找到判别特征或组合特征。最后,使用这些特征,可以为特定一组手机上的特定aped任务构建高级分类器或比较器。基于声学-语音学的方法已与基于自动语音识别(asr)的方法深度集成,并且它们已被证明可以相互补充。借助最先进的asr技术,实现了大规模语料库上多级片段的准确分割和鲁棒的置信度度量。判别特征是通过使用声学-语音学知识和改进的声学模型来构建的。这些多类型互补特征馈入结构良好的分类器,从而全面提高aped的准确性。
60.此外,语言模型254可以包括自动语音评分系统,由此计算机系统将口语能力分数指派给语音。该任务通常涉及生成从语音信号到口语能力分数的映射函数,由此通常由人工评分者生成的分数被用作训练系统的黄金标准。大多数自动语音评分系统包含三个主要组件:自动语音识别(asr)系统,它为给定语音样本生成单词假设以及其他信息,例如单词之间的停顿的持续时间;一组基于数字信号处理和自然语言处理(nlp)技术的模块,这些模块计算了一些特征,测量语言评估专家认为相关的语音的各个方面(例如,流利度、发音、语法准确性);以及使用监督机器学习范式将特征映射到分数的评分模型。在一些实施例中,中央模型250可以使用自动语音评分系统的输出来确定触发事件是否已经发生。
61.更一般地,语言模型254还可以包括计算机辅助语言学习(call)系统的特征,更具体地,专注于语音和发音的call系统,也称为计算机辅助发音训练(capt)系统。capt系统可以有效地处理和分析语言学习者发出的语音,然后将发音质量或能力的定量或定性评估作为反馈提供给他们。此过程也称为自动发音(质量/熟练程度)评估(评价/评分)。capt系统准确地检测语言学习者话语中的发音错误,诊断出发音错误的类型和位置,然后提供纠正反馈和操作指导以进行改进。中央模型250可以使用这种系统的输出来确定一旦触发事件
已经发生,什么反馈响应是合适的。此类系统的一些非限制性示例包括speechrater
sm
、carnegie speech assessment和nativeaccent、eduspeak sdk、arizona english language learner assessment、的duolingo english test、pocketsphinx.js等。
62.在不同的实施例中,中央模型250还可以被配置为基于预测的说话者的情绪-认知状态来识别触发事件。例如,在一些实施例中,服务可以包括或有权访问一个或更多个情绪模型256的输出。在不同的实施例中,情绪模型256可以解释人类的情绪状态并通知模型以便基于发出语音的用户的确定的性情确定触发事件。一般来说,情感语音处理技术使用语音特征的计算分析来识别用户的情绪状态。可以通过模式识别技术分析发声参数和韵律特征,例如音高变量和语速。通常,基于语音的情感识别有两个组分:同时分析语音内容和语音特征。这种分析的语义组分对具有情感和认知内涵的词的出现率进行计数。
63.例如,当一个人开始谈话时,他们在两个不同的通道中生成信息:主要通道和次要通道。主要通道与谈话的句法语义部分(按照字面上该人要表达的意思)相关联,而次要通道与说话者的副语言信息(音调、情绪状态等)相关联。基本分类包括“积极”与“消极”的心理状态(即,包括快乐和高兴的积极情绪,包括悲伤、恐惧、愤怒、厌恶、蔑视的消极情绪,以及惊讶或中性(没有情绪))。认知状态同样可以被评估,例如注意力程度、记忆问题、痴呆、语言障碍等。如果没有经过合适的数据库训练,情绪识别系统的性能和鲁棒性很容易受到影响。因此,数据库中有足够的和合适的短语来训练情感识别系统并随后评估其性能是必不可少的。通常,可以使用三种主要类型的数据库来训练情感模型:行为情绪、自然自发情绪和诱发情绪。作为一些非限制性示例,情感模型256可以包括来自一个或更多个可用情感模型的特征,例如beyond verbal
tm
、vokaturi
tm
、emovoice
tm
,good vibrations
tm
等。该服务还可以使用合并整体说话人建模和架构、半监督学习、合成训练材料和数据学习特征的其他技术。
64.在不同的实施例中,中央模型250还可以被配置为基于语音的内容来识别触发事件。例如,在一些实施例中,服务可以包括或有权访问一个或更多个内容评估器298的输出。在不同的实施例中,内容评估器298可以审查口述词的准确性并确定是否存在错误信息的高可能性。例如,可以通过提取相关特征(例如,词袋、n连词(n-gram)、心理语言因素、句法和语义特征等)来近实时地分析内容。在一些非限制性示例中,内容评估器298可以结合基于依赖于朴素贝叶斯(bayes)(具有n-gram)、深度学习(例如,cnn、lstm、bi-lstm、c-lstm、han和卷积han)、bert等的技术的模型。在另一个示例中,内容评估器298可以审查口语的词并且将内容与之前在会话期间呈现的内容进行比较以确定内容是否包括之前已经讨论或提出的信息。在另一个实施例中,内容评估器298可以基于当前用户偏好来审查所说的词是否有离题或不合需要的内容。中央模型250然后可以基于内容评估器298的输出来确定触发事件(也参见图5a、图5b和图7a-10d)。
65.在不同的实施例中,随着获得由运行服务的各个设备生成的训练数据,中央模型250可以随着时间得到改进。在这种情况下,将在一段时间内收集来自每个用户设备的数据。一旦收集到足够数量的数据集,就可以将数据共享为中央模型250的训练数据。例如,可以将联合学习模块258配置为生成分布在多个设备上的数据集,同时防止中央模型250的数据泄露。因此,在模型被训练之后,基于服务器的应用将等待来自客户端的聚合“建立”,以
便采用联合学习,这将随着时间的推移提高训练模型的质量。在数据积累并通过各个客户端设备将特征传送给服务器之后,服务器可以训练初始模型的改进迭代。新模型代表了可以为新用户或不希望创建个性化简档的用户实施的改进且更有效的模型。
66.在一个示例中,第一计算设备216、第二计算设备218和第三计算设备220(参见图2a)可以实现由sfa服务提供的一个或更多个特征。每个设备将在数天、数周或数月或更长时间内累积数据,并且该数据(原始或处理过的)将被发送到联合学习模块258。在一些实施例中,该方法涉及从存储在数十到可能数千或数百万远程设备(本文称为节点260)上的数据学习单个全局统计模型(中央模型250)。实施例可以应用实施水平联合学习、垂直联合学习、联合转移学习(ftl)、多参与者多类垂直联合学习框架(mmvfl)、fedf、perfit、fadl和blockchain-fl、pysyft、tensor flow federated(tff)、federated ai technology enabler(fate)、tensor/io、functional federated learning in erlang(ffl-erl)、crypten、leaf或其他可用的联合学习技术中的一项或更多项的架构。这些技术用于准备数据,然后作为训练数据模块272的附加或替代训练数据提供给中央模型250,从而提高模型的有效性和准确性。
67.一旦中央模型250如本文所述确定触发事件已经发生,它可以向反馈生成器262发出指令,该反馈生成器262被配置为审查语音模型252的音频数据和输出以生成针对与语言或会话异常相关的音频数据方面的适当的响应。反馈生成器264然后将响应传送到输出模块236,输出模块236被配置为经由在用户设备上运行的应用程序,例如经由诸如语音合成器或视觉内容渲染器的呈现组件262,将消息呈现为打断内容。
68.现在参考图2c,示出了环境200的第三方面200c。图2c包括sfa服务的实施例的一些组件的表示。在不同的实施例中,个性化模型模块(“个性化模块”)276的组件可以位于本地计算设备或云平台中的任一个或两者中。个性化模块276被配置为与正在其上访问sfa应用程序的用户的计算设备284通信,以便获得用户活动记录和选择。用户记录将用作可驻留在用户设备和/或云平台上的个性化ml模型(“个人模型”)280的用户特定训练数据278。
69.在不同的实施例中,个人模型280被配置为确定特质和语音/话音特征(“输出”)282,以及可以提高sfa的性能的其他用户特定模式,包括用户通常使用sfa所针对的任务、用户口头表示他或她不希望被打断的场合或特定的语音交互,以及其他语言特征。语音特征的一些非限制性示例包括语言、口音、语音流、响度、语调和泛音强度,以及各种语音性状,例如清晰度和/或可理解性、发音、语音停顿、语音音调和语音节奏。用户的音频数据可以通过语音机器学习模型进行分类,以识别/分类语音特征或其他可能对用户来说是“正常”或基线的性状和模式,并且可以改进服务的操作。
70.然后可以将输出282传送到用户简档模块288,用户简档模块288也可以驻留在用户的本地设备上和/或与应用程序相关联的远程服务器中。在一些实施例中,个人模型280包括或有权访问一个或更多个用户特定的语音模型(例如,参见语音模型252),以便生成更细微和准确的输出。此外,该应用程序可以被配置为呈现接口(例如,在显示器上或通过话音命令),该接口提供了用于修改sfa操作的多个可选选项,如下所述。换言之,用户可以手动选择或更新影响应用程序配置的一个或更多个用户设置/模式(“选择”)286。在一个示例中,用户可以为第一设备(例如,膝上型电脑)选择一组偏好,并为第二不同设备(例如,他们的智能手表)选择第二组偏好。在不同的实施例中,用户可以指示应用程序应该在什么时候
主动收听和/或打断,以及它应该在什么时候脱离。例如,应用程序可能会因专有、ip或任何其他机密会议而关闭或禁用。此外,该应用程序可以被配置为针对第一类组织(例如,技术初创公司)的成员使用一组偏好执行,并针对不同类型的第二组织(例如,银行或其他金融机构)的成员应用不同的第二组全局偏好。在不同的实施例中,本地或个人模型可以被配置为在新的音频数据和用户与服务交互时更新其特征储存库。新数据将允许模型继续微调原始模型并为用户开发改进的个性化模型。
71.出于说明的目的,一些非限制性的用户特定偏好可以包括用户偏好,例如(a)“不要因[特定错误]而打断”,例如“不要因字母b的错误发音而打断”、“不要因为口吃而打断我”、“不要再因为同样的错误而打断我”、“不要在我说话的时候打断我”、“如果我使用俚语不要打断”或“如果我说比如唔、啊、呃、嗯等填充词不要打断我,以及“只为发音错误打断”和“只为语法和口音更正打断”;(b)“不要因[特定持续时间内]而打断”,例如“在接下来的五分钟内不要打断”、“今天不要打断我”和“今晚不要打断我”;(c)“不要打断[人]”,例如“不要打断我”、“不要打断joe”、“如果我说话超过5分钟就打断我”或“不要打断除了我以外的任何其他人”(例如,基于已知的语音识别技术,如声纹和声音认证);(d)“不要打断[频率]”,例如“不要在每10分钟间隔内打断超过3次”、“不要在每个句子中打断超过一次”或“不要为今天的发音纠正打断超过4次”;(e)“只有当我在[位置/活动/设备]时才打断”,例如“只有在家时才打断”、“只有在阅读日语时才打断”、“只有在使用平板设备时才打断”、“要/不要将我在此设备上所做的选择和/或历史记录应用到我使用的其他设备”,或“我在学校时不要打断”;(f)“只为[任务]打断”,例如“只在我练习南方口音时打断”、“我的年龄17岁,只为一般青少年不会犯的错误打断”或“我是医生,只有在我说错医疗状况时才打断我”。无论用户是单独说话还是在群组对话中,这些类型的偏好都可以应用。
[0072]
此外,可能存在更具体地针对其中存在不止一个人的会话的用户偏好。例如,此类偏好可能包括(a)“当有人重复别人已经说过或已经被提及的内容时打断”;(b)“当有人说别人时打断”;(c)“当有人说话不尊重或生气时打断”;(d)“当主要发言者(例如,教师)发言时间超过[持续时间]时打断”;(e)“当有人在高中以上水平发言时打断”;(f)“当有参加者或[人名]超过10分钟未发言时打断”;(g)“当有人在小组会议上发言超过3分钟时打断”。
[0073]
可以参考知识库238中的响应选项244来提供或修改其他选项(见图2b)。用户偏好可以通过在应用程序中提供的选项进行,并且可以根据后续用户活动或选择,或者响应于对中央模型的更新,随时间改变,并且在一些实施例中,可以跨设备共享和/或通过网络202存储在用户账户数据库中。
[0074]
这些选择286与用户简档模块288共享。个人模型280的输出282和选择286一起与用户特定偏好模块290共享,用户特定偏好模块290被配置为在用户的计算设备284处维护和应用适当的应用程序配置。在一些实施例中,应用程序被配置为引导用户通过可定制的“偏好模块”的设置(例如,他们的母语是什么,用户想要软件打断多少次,什么样的打断是可以的,等等)。在一些实施例中,每个客户端的单独偏好模块可以与其他客户端的偏好模块交互。在这种情况下,系统可以配置为通过get和post协议发送通知。客户端可以控制他们是否希望偏好模块具有交互性(例如,从任何其他客户端的模块发送和接收信息)。
[0075]
因此,在不同的实施例中,客户端使用具有基于偏好模块的修改的初始模型。随着时间的推移,用户可以建立应用程序收集的他们的个性化数据,一旦收集到一定数量的数
据,模型就会被微调以针对用户个性化。微调训练可以在用户的本地机器上进行。新微调的模型能够更好地迎合每个用户的偏好。
[0076]
应当理解,偏好模块290可以被配置为驻留在用户的本地计算设备和/或云网络环境中。例如,可以在本地设备处生成语音文件,并且基于本地的偏好模块接收语音文件并在用户设备处生成并随着新语音文件的生成而不断更新用户简档和偏好。因此,用户声音数据可以在本地被包含和保护,而不是被传输到远程位置。在一些实施例中,仅将去识别化的音频数据或处理的去识别化的数据传送到外部设备或系统以存储在账户数据库中。
[0077]
一般来说,默认模型或中央模型可以评估来自语音模型的输出以确定一个或更多个触发事件是否已经发生以呈现打断内容。就本技术而言,打断内容是指通过sfa生成的内容,包括音频和视觉内容,在触发事件的几分钟内(即,接近即时)呈现,并且不考虑说话者是否还在讲话而呈现。在大多数情况下,通常会在有人说话时呈现打断内容,除非该人在语言或会话异常后立即突然停止说话。
[0078]
如图2b所示,可能存在当被系统检测到时被配置为导致打断的特定事件。在图3中示出可能的触发事件242的一些非限制性示例,在被检测到时可以触发sfa以打断用户,描绘为三个一般类别。第一类是语言指示符310。如前所述,所提出的系统可以应用于人们正在学习新语言、不同口音或提高他们的语言能力的情况。因此,错误发音、语法、韵律和词汇的实例可能是打断的触发因素。此外,情绪状态可能会影响sfa与用户的交互方式。此外,在一些实施例中,对话异常可能是打断的触发因素(参见下面的图6a、图6b和图7a-11d)。
[0079]
如将在下文描述的实施例中讨论的,所提出的系统还可以适用于其他环境,例如两个或更多人之间的协作对话或会议。在这种情况下,情绪指示符320在确定何时可以保证打断时可能特别重要。在第二类中,检测到特定的消极情绪或特定的积极情绪会触发打断。例如,sfa可以在会议期间充当主持人,在讲话变得激烈或以其他方式通过检测到愤怒而具有不受欢迎的语气时“介入”。
[0080]
类似地,在一些实施例中,可以使用第三类别来训练模型,使得诸如持续时间、复杂性、对话、歧义、会话流和重复性的参与指示符330可以导致由sfa呈现的打断。与参与指示符330相关的触发事件也可以称为会话异常。例如,可以打断说话时间过长、过于复杂或含糊不清的人,以便为其他参与者提供说话的机会。此外,如果对话包括重复的方面,人们正在说话或打断对方,或者会话没有按照提议的议程进行,系统可以触发打断。可以理解,认知障碍340可以基于这三个类别的一个或更多个指示符来检测。此外,为了本技术的目的,发生语音异常的确定通常将基于语言指示符310和/或情绪指示符320的检测,而会话异常发生的确定通常将基于检测到参与指示符330和/或情绪指示符320。然而,可能存在两者之间存在重叠的情况,使得也可以或替代地基于参与指示符330来确定语音异常,并且还可以或替代地基于语言指示符确定会话异常。
[0081]
在一些实施例中,可以理解的是,该模型可以被配置为确定仅当在会话期间和/或在一段时间(例如,模型可能不会在一个人跑题一次时打断,但如果同一个人第二次跑题就会打断)内出现指示符的多个实例时才发生诸如打断、消极情绪等触发事件。此外,在一些实施例中,触发事件可以基于这些指示符的组合。换句话说,如果在与第二人的会话期间第一人打断的第一实例可能其本身不足以保证模型打断,并且第一人提高声音的第一实例可能其本身不足以保证模型打断,这两个指示符的组合(第一人以提高的声音打断第二人)可
以组合表示导致模型打断会话的触发事件。
[0082]
现在参考图4a-4e,其中慢跑者410采用sfa服务的实现的示例场景在五个图的序列上被描绘。在图4a中,慢跑者410被示为在她的手腕上佩戴配备有sfa的智能手表设备430,并且在她的耳朵中佩戴耳机420。当她锻炼时,慢跑者410正在练习她的英语语言技能。在这个例子中,她从第一话语412开始(“所以当我要去risterwan时
–
(so when i am going to a risterwant to
–
)”),她在其中错误发音了一个单词。sfa检测到这种错误发音并确定应该呈现的打断内容,在这种情况下作为第一反馈432(“梅格,不是risterwant,尝试restaurant(meg,rather than risterwant,try restaurant)”)。在图4b中,慢跑者410继续尝试在第二话语414中重复该陈述(“restuhant,好的。所以当
–
(restuhant,ok.so when
–
)”)。sfa立即打断她以提供纠正性的第二反馈434(“让我们再试一次。restaurant。(let’s try it again.restaurant.)”)。作为响应,如图4c所示,慢跑者410再次以第三话语416(“所以当我去餐厅时
–
(so when i am going to a restaurant
–
)”)开始。在一些实施例中,sfa还可以被配置为以类似于人类导师的方式提供正面反馈。在这种情况下,sfa以第三反馈436(“干得好(great job)”)打断,允许慢跑者410立即感受到她的努力得到了回报。在图4d中,慢跑者410继续第四话语418(“谢谢!在餐厅我喜欢点薯条和
–
(thanks!at the restaurant i like to order chips and
–
)”)。在一些实施例中,sfa可以被配置为提供区域特定的指导。在这种情况下,sfa以第四反馈438打断(“在美国,薯条被称为炸薯条。你是说炸薯条还是脆脆的薯片?(in the us,chips are called french fries.did you mean french fries,or crunchy potato chips?)”)。如图4e所示,慢跑者410对这种指导表示赞赏,用第五话语450确认(“哎呀!是的,我想我是说炸薯条(oops!yeah i guess i meant french fries)”),并且sfa用确认440(“没问题。请继续(no problem.go on please)”)进行响应。因此,可以理解,个性化语言学习可以作为移动中的独立移动系统来提供。在其他实施例中,反馈也可以或替代地呈现在显示器上,例如,作为用户语音和目标语音之间的音频波形比较,或一个或更多个单词的语音拼写。
[0083]
第二示例显示在图5a和图5b中,其中包括几个人的群组500围坐在桌子周围进行会议,例如公司或其他组织会议。第一说话者510在表达第一陈述512(还有一件事!每当我收到一份长篇报告时
–
(“and another thing!whenever i receive one of those long reports
–
)”)时站立并提高他的声音和/或变得更加活跃。配备sfa的第一计算设备550,在此表示为在诸如智能设备的通用计算设备上运行,检测第一说话者的情绪状态以及该主题与他们所描述的被朗诵或以其他方式在会议开始之前或开始时输入到sfa的议程无关的事实。响应这些触发事件中的一个或任何一个,第一sfa 500呈现包括第一音频响应552(“也许这个问题以后再讨论更好(perhaps this is a concern that is better discussed at a later time)”)的打断内容,可以温和地引导群组回到他们的预期的讨论。例如,在图5b中,第一说话者510已经回到他的座位,并且在第二陈述514(“好的,我想samantha现在应该谈谈议程项目3(ok,i guess samantha should speak about agenda item 3now)”)中更深思熟虑地将会话从他自己身上移开。
[0084]
为了清楚起见,图6中示出了呈现打断内容的过程的一个实施例的流程图600。在该示例中,在第一阶段610中,用户语音输入612由被配置为在特定任务期间主动倾听614用户的sfa接收。在第二阶段620,系统确定与当前任务相关的任何用户偏好是否可用于该用
户。如果偏好可用,则系统在第三阶段624访问这些用户偏好,例如,通过偏好模块626。可选地,可以在第四阶段630检测当前用户的附加用户设备。如果有附加设备,系统可以可选地确保已经接收到最近的设置和/或用户活动,以便在第五阶段690更新偏好模块626。如果没有附加设备,则流程移动到第七阶段642,在该阶段中,基于来自默认配置模式或用户配置设置640的指令,审查语音输入以获取触发事件条件的指示。如果模型确定触发事件已经发生,则可以可选地在第八阶段650中识别事件类型。该信息可以在第九阶段652中使用,由此系统确定将生成的适当响应作为即将发生的打断的内容。一旦创建响应,系统在第十阶段660呈现打断内容。然后系统在第十一阶段670继续收听。在一些实施例中,用户交互历史和反馈可以被存储以供系统在第十一阶段662使用或参考作为会话历史680,也可以在后续会话中共享以供其他设备使用。
[0085]
为了说明的目的,现在在图7a-11c中描绘一些提出的实施例的几个附加示例。在图7a和7b中给出第三示例,其包括坐在咖啡店700中交谈的小组。在图7a中,第一参与者710可以被理解为正在打断第二参与者720的讲话,而第三参与者730坐在他们之间,不确定如何改进讨论但意识到此时讨论无效。在确定触发事件已经发生时(在这种情况下,两个人互相打断说话),配备sfa的第二计算设备750以高于两个说话者的音量生成打断内容752,以便被听到:“也许玛丽想在别人插话之前完成她的想法。玛丽?(perhaps mary wanted to complete her idea before others chime in.mary?)”。在图7b中,第一参与者710以道歉声明714(“哦,对不起玛丽,请继续(oh sorry mary,go ahead)”)进行响应,而第二参与者720(玛丽)继续她的观点724(“没关系。正如我所说,...(no problem.as i was saying,the
…
)”)。因此,客观的非个人来源可以提供主持指导或反馈,而不是将主持的负担强加给第三参与者730,从而由于反馈后面没有人脸而导致第一参与者720在校正时的敌意减少,以及减轻第二参与者720感到的挫败感,并在第三参与者730不需要“选边站”时减轻他或她的压力。
[0086]
在图8a和8b中示出教室设置800中的第四示例。一组学生890被示为正在听由站在房间前面的老师840提供的讲座842。教师840继续他的讲课没有停顿,持续时间太长,超过他在他的sfa偏好中建立的持续时间,以便训练自己多休息并与他的学生一起讨论。作为对这个用户请求的触发事件的响应,所选择的响应类型不那么突兀地呈现为消息852(“自从你开始讲话以来没有人问过任何问题。也许可以与学生一起讨论?(no one has asked any questions since you started speaking.perhaps check in with the students?)”)通过在其中运行的sfa显示在配备sfa的第三计算设备850(在这种情况下,他的智能手表显示器)上。在一些实施例中,消息852可以伴随不显眼的音频提示,例如哔哔声或振动,以提醒教师840正在显示打断内容。在注意到这个相对微妙的打断内容时,教师840能够记住需要在他的讲座中暂停,并询问是否有任何问题844,第一学生892立即向其举手。
[0087]
因此,在这种情况下,教师840能够通过让sfa监控他的讲话的持续时间并检测是否有足够的停顿或打断来帮助他自己更好地帮助他的学生。这可以让学生更多地参与,因为他们不觉得自己打断了老师。在一些其他实施例中,应用程序可以提供使用户能够识别他/她的听众的年级水平或其他标准理解水平的选项,并且如果他或她超过该语音的水平则请求sfa打断,以便与学生核对或将语言水平重新设置为适当的水平。在另一个示例中,应用程序可以提供使用户能够选择说话速度的选项,并在他或她以比所选速度更快的速度
说话时请求sfa打断。在一些实施例中,应用程序可以提供,如果一个或更多个听众在选定的时间段内没有说话,使用户能够请求打断的选项。在一个实施例中,用户可能能够选择一个特定的听者,从一段时间内该听者没有语音会导致打断,以帮助说话者确保所选择的听者正在听讲座或对话(例如,选择的听者之前遇到过问题或表明主题对他/她来说是困难的)。
[0088]
第五示例显示在图9a-9c中,其中与几个参加者902正在开商务会议900,而房间中的配备sfa的第四计算设备950主动收听出席者902生成的语音内容。在图9a中,第一出席者910提出想法912(“如果我们尝试方法b和c怎么办?(what if we tried approach b and c?)”)但没有收到任何其他人正在听的指示,如图9b所示,出席者902继续彼此交谈而不承认第一出席者的话。在图9c中,第二出席者920通过提高他的声音并重复“如果我们尝试方法b和c怎么办?(what if we tried approach b and c?)”922来插话,而第一出席者910显得沮丧。经常在这样的场景中,特别是在最初的讲话者在组织中具有较低或较小级别的角色或被忽视的情况下,和/或在第二出席者920更直言不讳或专横的情况下,该想法将被承认为已由第二出席者920,而第一出席者910静静地坐着,无法纠正这种情况。然而,如图9c所示,sfa能够确定触发事件已经发生——在这种情况下,之前已经提出了一个想法和/或内容,作为观察952(“詹妮弗几分钟前提出了同样的想法。也许她可以详细说明?(jennifer raised this same idea a few minutes ago.perhaps she could elaborate instead?)”)从而中性地将对话带回到更平等的基础上,并且可以承认通常不被注意的出席者。
[0089]
第六示例参照图10a-10d进行描述。在第一种情况下,如图10a和图10b所示,与几个群组成员发生不同的会议1000,而房间中的配备sfa的第五计算设备1050主动收听由成员生成的语音内容。第一成员1010做出第一报告1012(“我听说道琼斯昨天下跌了888点(i heard the dow jones fell by 888points yesterday)”),第二成员1020(可能是该群组的负责人)对此做出第一响应1022(“所以也许我们应该持有-(so maybe we should hold
–
)”),一旦sfa识别出虚假内容触发事件就会打断,导致sfa打断并发出纠正声明1052(“看今天的新闻,它实际上只下跌了88点(looking at today’s news,it actually only fell by 88points)”)。在这种情况下,会议以正确的信息继续,使得第二成员1020添加第二响应1024(“哦,好的,所以我们可以继续(oh,ok,so we can proceed)”),强调错误信息检测智能设备“参与”会议的好处。然而,可以理解的是,第一成员1010可能会感到受到惩罚或尴尬。
[0090]
在一个替代实施例中,如图10c和图10d所示,当第一成员1010做出相同的报告1012(“我听说道琼斯昨天下跌888点(i heard the dow jones fell by 888points yesterday)”)时,类似的场景正在展开,第二成员1020对此做出第三响应1026(“所以也许我们应该抛售吗?(so maybe we should hold off on that?)”)。在这种情况下,第一成员1010已经做出了包括虚假信息的报告,这可能直到很久以后当已经做出进一步决定时才被意识到。然而,个人平板电脑形式的配备有sfa的第六计算设备1060正在运行并主动收听会议。与之前的情况相反,当sfa打断成员以产生基于音频的更正时,在这种情况下,sfa由第一成员1010配置为将更正呈现为基于显示的文本更正1062(“看今天的新闻,实际上只下降了88点(looking at today’s news,it actually only fell by 88points)”),因此只是
在看着他的平板电脑时被动地打断了第一成员1010。然后第一成员1010能够自己主动提出更正的陈述1016,看起来只是说错了话,从而减少了错误对群组和他自己的影响,从而允许会议在那个时候继续进行更新的信息。
[0091]
参考图11a-11c示出了第八示例,其中正在进行虚拟电话会议1100。会议领导者1100被示为坐在配备sfa的第七计算设备1150处,同时通过设备显示器上显示的视频与参与者1190交互。在这种情况下,sfa被配置为与会议领导者1110交互,作为可以在其上显示消息的聊天机器人接口1152。在图11a中,会议领导者1110提出第一请求1112(“让sara从这里接听(let’s have sara take it from here)”),以指示第一呼叫者1120开始讲话。然而,如图11b所示,sfa可以访问一个或更多个呼叫者的偏好模块,并且基于该数据能够检测到第一呼叫者姓名的错误发音,在该实施例中(基于会议领导者的设置)对应于触发事件。作为响应,sfa使聊天机器人接口1152呈现纠正消息1154(“saira已表明她的名字将被发音为“sigh-rah”而不是sara(saira has indicated her name is to be pronounced“sigh-rah”rather than sara)”)。该信息在saira讲话时出现,并且可以理解为仅打断了会议领导者1110。在图11c中,一旦第一呼叫者1120结束讲话,会议领导者1110就提供道歉1114(“谢谢你,sigh-rah。很抱歉之前误读了你的名字(thanks for that,sigh-rah.sorry for mispronouncing your name earlier)”),从而恢复了对第一呼叫者的包容感和个性化的信心,而无需她纠正她的主管。
[0092]
图12是示出了在语音期间呈现打断内容的计算机实现的方法1200的实施例的流程图。该方法包括在第一时间并且由通过计算设备访问的应用程序接收第一用户说话的第一音频数据的第一步骤1210,以及通过应用程序检测至少第一音频数据中的第一类语音异常的第一指示符的第二步骤1220。第三步骤1230包括由应用程序基于第一指示符确定触发事件已经发生。方法1200还包括第四步骤1240,通过应用程序使第一打断内容被呈现,其中第一打断内容包括关于检测到的语音异常的反馈,并且无论第一用户是否还在讲话,都在第二时间呈现。
[0093]
在其他实施例中,该方法可以包括额外的步骤或方面。在一个实施例中,第一类型的语音异常是错误发音、词汇语法不准确、韵律错误、语义错误、语音不流畅和不正确的用语中的一个。在一些实施例中,该方法还包括以下步骤:通过应用程序接收第一用户讲话的第二音频数据,由应用程序检测第二音频数据中的内容异常的第二指示符,以及通过应用程序引起呈现的第二打断内容,包括识别在第二音频数据中识别的错误信息的反馈。在这种情况下,第二打断内容还可以包括纠正错误信息的反馈。
[0094]
在一些实施例中,反馈包括关于纠正检测到的语音异常的指导。在另一示例中,第一打断内容被呈现为在第一用户说话时打断第一用户的音频输出。在一些其他示例中,第一打断内容被呈现为在第一用户说话时打断第二用户的视觉输出。在一个实施例中,第二时间在第一时间之后不到十秒。
[0095]
在本公开的范围内也可以考虑其他方法。例如,公开了一种在包括至少第一参与者和第二参与者的会话期间呈现打断内容的计算机实现的方法。该方法包括在第一时间并且由经由计算设备访问的应用程序接收至少第一参与者讲话的第一音频数据的第一步骤,以及由应用程序检测第一音频数据中的第一类型的会话异常的第一指示符的第二步骤。该方法还包括由应用程序基于第一指示符确定触发事件已经发生的第三步骤,以及经由应用
程序使得呈现第一打断内容的第四步骤。此外,第一打断内容包括与检测到的会话异常相关联的主持指导,并且在第一参与者和第二参与者中的一个或两个正在讲话时在第二时间呈现。
[0096]
在其他实施例中,该方法可以包括额外的步骤或方面。在一些实施例中,第一类型的会话异常是以下情况之一:第一参与者在讲话中切断第二参与者,第一参与者和第二参与者相互说话,第一参与者提高他们的声音,以及第一参与者正在重复第二参与者在对话中早些时候所说的话。在一个实施例中,主持指导包括允许第二参与者继续讲话的建议。在另一个实施例中,主持指导包括识别第二参与者先前提出了现在正在第一音频数据中提出的想法。在一些实施例中,该方法还包括由应用程序在第一时间之前接收描述会话议程的第一输入的步骤,并且主持指导包括第一音频数据中的内容关于议程偏离主题的提醒。在又一个示例中,该方法还可以包括以下步骤:在第一时间之前并且通过应用程序接收与持续时间的选择相对应的第一数据输入,将第一数据输入存储在第一参与者的偏好模块中,由应用程序确定第一音频数据包括由第一参与者发出的超过所选持续时间的基本上连续的语音,并经由应用程序使得第二打断内容被呈现,其中第二打断内容包括通知第一用户已超过选定的持续时间。
[0097]
在一些其他实施例中,可以实现额外的特征或方面。例如,公开了一种提供交互式语音指导内容、会话输入、对话、聊天或其他交互的计算机实现方法。该方法包括获得由第一人说出的第一语音样本,以及获得第一样本的第一转录。此外,该方法包括使用第一样本和第一转录来训练第一机器学习模型以识别第一人的语音特征的第二步骤。该方法包括在第二人说出时实时或近实时地接收第一语音流(即,主动聆听)的第三步骤,并通过机器学习模型确定第一异常语音发生在第一流中。第四步骤包括通过虚拟助手几乎立即打断第一语音流,以便将第一异常通知第二人。
[0098]
在本公开的范围内也可以考虑其他方法。例如,公开了一种确定语音异常是否已经发生的计算机实现方法。该方法包括在第一时间并且由通过计算设备访问的应用程序接收第一用户讲话的第一音频数据的第一步骤,以及通过用于应用程序的基于语音的机器学习模型基于第一音频数据对与第一用户相关联的一个或更多个语音特性进行分类的第二步骤。此外,第三步骤包括在第二时间经由应用程序接收第一用户讲话的第二音频数据,以及第四步骤经由应用程序确定第二音频数据中出现语音异常,该确定至少部分基于第二音频数据与分类的语音特性的比较。此外,该方法包括响应于语音异常已经发生的确定,经由应用程序使得由计算设备呈现第一打断内容的第五步骤。在这种情况下,第一打断内容包括关于检测到的语音异常的反馈,并且无论第一用户是否还在讲话,都在随后的第三时间呈现。
[0099]
在其他实施例中,该方法可以包括额外的步骤或方面。在一些实施例中,基于语音的机器学习模型驻留在与第一用户相关联的第一计算机设备上。在另一个实施例中,该方法还包括基于分类的语音特性生成第一用户的用户简档的步骤,该用户简档包括(至少)第一用户的语言和口音的识别(例如,参见图2a)。其他语音特性可以包括在音频数据中检测到的音频特征和模式,如上文关于区域、年龄、可能的性别、代词的使用、可能的种族和/或文化遗产等所描述的。在一些实施例中,该方法可以进一步包括以下步骤:在第三时间并且由应用程序从第一用户接收应该引起来自应用程序的打断内容的呈现的第一类型的语音
异常的第一选择,由应用程序将第一选择存储在用户简档中,并在确定语音异常是否已经发生时参考用户简档。在另一个示例中,该方法可以另外包括以下步骤:在第三时间并且由应用程序从第一用户接收被排除在触发来自应用程序的打断内容的呈现之外的第一类型的语音异常的第一选择,由应用程序将第一选择存储在用户简档中,并在确定语音异常是否已经发生时参考用户简档。
[0100]
因此,如本文所述,所公开的实施例可以向说话者提供关于他们的语音的有价值的见解,并提供个性化和可定制的反馈。有据可查的是,准确和及时的反馈对于帮助语言学习者注意到他们的语言产出和目标语言之间的差异至关重要。此外,打断内容增加了与智能助手计算机进行有意义、真实交互的感觉。
[0101]
应用本文公开的一种或更多种技术生成的图像可以显示在监视器或其他显示设备上。在一些实施例中,显示设备可以直接耦接到生成或渲染图像的系统或处理器。在其他实施例中,显示设备可以例如经由网络间接耦接到系统或处理器。这种网络的示例包括互联网、移动电信网络、wifi网络以及任何其他有线和/或无线网络系统。当显示设备被间接耦接时,系统或处理器生成的图像可以通过网络流式传输到显示设备。例如,这种流式传输允许渲染图像的视频游戏或其他应用程序在服务器或数据中心中执行,并且渲染的图像被传输并显示在物理上与服务器或数据中心分开的一个或更多个用户设备(例如计算机、视频游戏机、智能手机、其他移动设备等)上。因此,本文公开的技术可用于增强被流式传输的图像并增强流式传输图像的服务,例如geforce now(gfn)、stadia等。
[0102]
此外,应用在此公开的一种或更多种技术生成的声音或其他音频可以由扬声器或其他音频输出设备产生。在一些实施例中,音频设备可以直接耦接到产生声音的系统或处理器。在其他实施例中,音频设备可以例如经由网络间接耦接到系统或处理器。这种网络的示例包括互联网、移动电信网络、wifi网络以及任何其他有线和/或无线网络系统。当音频设备被间接耦接时,系统或处理器生成的声音可以通过网络流式传输到显示设备。这种流式传输允许在服务器或数据中心中执行包括音频的应用程序和其他软件以及允许由在物理上与服务器或数据中心分开的一个或更多个用户设备(例如计算机、智能手表、智能手机、其他移动设备、等)传输和产生的生成声音。因此,本文公开的技术可应用于增强流式传输的声音并增强提供音频的服务。
[0103]
在本详细描述中描述并在图中示出的实施例的过程和方法可以使用具有一个或更多个中央处理单元(cpu)和/或图形处理单元(gpu)的任何类型的计算系统来实现。实施例的过程和方法也可以使用诸如专用集成电路(asic)之类的专用电路来实现。实施例的过程和方法也可以在包括只读存储器(rom)和/或随机存取存储器(ram)的计算系统上实现,其可以连接到一个或更多个处理单元。计算系统和设备的示例包括但不限于:服务器、蜂窝电话、智能手机、平板电脑、笔记本电脑、智能手表、智能眼镜、电子书阅读器、笔记本电脑或台式电脑、一体机,以及各种数字媒体播放器。
[0104]
实施例的过程和方法可以作为指令和/或数据存储在非暂态计算机可读介质上。非暂态计算机可读介质可以包括任何合适的计算机可读介质,例如存储器,例如ram、rom、闪存或本领域已知的任何其他类型的存储器。在一些实施例中,非暂态计算机可读介质可以包括例如电子存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或这
些设备的任何合适的组合。非暂态计算机可读介质的更具体示例可以包括便携式计算机软盘、软盘、硬盘、磁盘或磁带、只读存储器(rom)、随机存取存储器(ram)、静态随机存取存储器(sram)、便携式光盘只读存储器(cd-rom)、可擦除可编程只读存储器(eprom或闪存)、电可擦除可编程只读存储器(eeprom)、数字多功能盘(dvd和dvd-rom)、记忆棒、其他种类的固态驱动器以及这些示例性介质的任何合适的组合。如本文所用,非暂态计算机可读介质不应被解释为瞬态信号,例如无线电波或其他自由传播的电磁波、传播通过波导或其他传输介质的电磁波(例如,光脉冲通过光纤电缆)或通过电线传输的电信号。
[0105]
存储在非暂态计算机可读介质上用于执行本发明的操作的指令可以是指令集架构(isa)指令、汇编指令、机器指令、机器相关指令、微代码、固件指令、集成电路的配置数据、状态设置数据或以一种或多种编程语言中的任何一种编写的源代码或目标代码,包括面向对象的编程语言,例如smalltalk、c 或合适的语言,以及过程编程语言,例如“c”编程语言或类似的编程语言。
[0106]
结合图示方法、装置(系统)和计算产品的流程图和/或框图的附图来描述本公开的各方面。应当理解,流程图和/或框图的每个块可以由计算机可读指令实现。图中的流程图和框图说明了各种公开实施例的可能实现方式的架构、功能和操作。因此,流程图或框图中的每个块可以表示模块、段或指令的一部分。在一些实施方式中,附图和权利要求中阐述的功能可以以不同于列出和/或图示的顺序出现。
[0107]
实施例可以利用任何类型的网络来在单独的计算系统之间进行通信。网络可以包括使用有线和无线通信系统的局域网(lan)和/或广域网(wan)的任意组合。网络可以使用各种已知的通信技术和/或协议。通信技术可以包括但不限于:以太网、802.11、全球微波接入互操作性(wimax)、移动宽带(例如cdma和lte)、数字用户线路(dsl)、有线互联网接入、卫星宽带、无线isp、光纤互联网以及其他有线和无线技术。网络上使用的网络协议可能包括传输控制协议/互联网协议(tcp/ip)、多协议标签交换(mpls)、用户数据报协议(udp)、超文本传输协议(http)、安全超文本传输协议(https)和文件传输协议(ftp)以及其他协议。
[0108]
通过网络交换的数据可以使用包括超文本标记语言(html)、可扩展标记语言(xml)、atom、javascript对象表示法(json)、yaml以及其他数据交换格式的技术和/或格式来表示。此外,通过网络传输的信息可以使用传统的加密技术进行加密,例如安全套接字层(ssl)、传输层安全性(tls)和互联网协议安全性(ipsec)。
[0109]
本公开的其他系统、方法、特征和优点对于本领域的普通技术人员在检查以下附图和详细描述后将是或将变得显而易见。旨在将所有这些额外的系统、方法、特征和优点包括在本描述和本概述中,在本公开的范围内,并受所附权利要求的保护。
[0110]
尽管描述了各种实施例,但该描述旨在是示例性的,而不是限制性的,并且对于本领域的普通技术人员来说显而易见的是,在实施例的范围内的更多实施例和实现方式是可能的。尽管在附图中示出了许多可能的特征组合并且在该详细描述中进行了讨论,但是所公开的特征的许多其他组合也是可能的。任何实施例的任何特征或元件可以与任何其他实施例中的任何其他特征或元件组合使用或替代任何其他实施例中的任何其他特征或元件,除非特别限制。
[0111]
本公开包括并考虑与本领域普通技术人员已知的特征和元件的组合。已经公开的实施例、特征和元件也可以与任何常规特征或元件组合以形成如权利要求限定的不同发
明。任何实施例的任何特征或元素也可以与来自其他发明的特征或元素组合以形成由权利要求限定的另一个不同的发明。因此,应当理解,本公开中所示和/或讨论的任何特征可以单独或以任何合适的组合来实施。因此,除了根据所附权利要求及其等同物之外,实施例不受限制。此外,可以在所附权利要求的范围内进行各种修改和改变。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。