技术特征:
1.一种在语音期间呈现打断内容的计算机实现的方法,所述方法包括:在第一时间由经由计算设备访问的应用程序接收第一用户讲话的第一音频数据;经由所述应用程序检测所述第一音频数据中的第一类型的语音异常的至少第一指示符;由所述应用程序基于所述第一指示符确定触发事件已经发生;以及经由所述应用程序使得所述计算设备呈现第一打断内容,其中所述第一打断内容:包括关于检测到的语音异常的反馈,以及无论所述第一用户是否还在讲话,都会在随后的第二时间呈现。2.根据权利要求1所述的方法,其中,所述第一类型的语音异常是错误发音、词汇语法不准确、韵律错误、语义错误、语音不流畅和不正确用语中的一个。3.根据权利要求1所述的方法,还包括:经由所述应用程序接收所述第一用户讲话的第二音频数据;由所述应用程序检测所述第二音频数据中的内容异常的第二指示符;以及经由所述应用程序使得呈现第二打断内容,所述第二打断内容包括识别在所述第二音频数据中识别的错误信息的反馈。4.根据权利要求3所述的方法,其中,所述第二打断内容还包括纠正所述错误信息的反馈。5.根据权利要求1所述的方法,其中,所述反馈包括关于纠正检测到的语音异常的指导。6.根据权利要求1所述的方法,其中,所述第一打断内容被呈现为在所述第一用户讲话时打断所述第一用户的音频输出。7.根据权利要求1所述的方法,其中,所述第一打断内容被呈现为在所述第一用户讲话时打断第二用户的视觉输出。8.根据权利要求1所述的方法,其中,所述第二时间在所述第一时间之后不到十秒。9.一种在会话期间呈现打断内容的计算机实现的方法,所述会话包括至少第一参与者和第二参与者,所述方法包括:在第一时间由经由计算设备访问的应用程序接收至少所述第一参与者讲话的第一音频数据;由所述应用程序检测所述第一音频数据中的第一类型的会话异常的第一指示符;由所述应用程序基于所述第一指示符确定触发事件已经发生;以及经由所述应用程序使得呈现第一打断内容,其中所述第一打断内容:包括与检测到的会话异常相关的主持指导,以及在所述第一参与者和所述第二参与者中的一个或两个正在讲话时,在随后的第二时间呈现。10.根据权利要求9所述的方法,其中,所述第一类型的会话异常是其中所述第一参与者打断所述第二参与者的中间讲话、所述第一参与者和所述第二参与者彼此说话、所述第一参与者正在提高他们的声音、以及所述第一参与者正在重复所述第二参与者在所述会话中早些时候所说的话的实例中的一个。11.根据权利要求9所述的方法,其中,所述主持指导包括允许所述第二参与者继续讲
话的建议。12.根据权利要求9所述的方法,其中,所述主持指导包括对所述第二参与者先前提出的现在正在第一音频数据中提出的想法的识别。13.根据权利要求9所述的方法,还包括:由所述应用程序在所述第一时间之前接收描述会话的议程的第一输入;以及其中,所述主持指导包括在所述第一音频数据中的内容相对于所述议程偏离主题的提醒。14.根据权利要求9所述的方法,还包括:由所述应用程序在所述第一时间之前接收与持续时间的选择相对应的第一数据输入;将所述第一数据输入存储在所述第一参与者的偏好模块中;由所述应用程序确定所述第一音频数据包括由所述第一参与者发出的超过所选持续时间的基本上连续的语音;以及经由所述应用程序使得呈现第二打断内容,其中所述第二打断内容包括所述第一用户已经超过所选持续时间的通知。15.根据权利要求9所述的方法,还包括:其中所述第一打断内容被呈现为要么在所述第一参与者正在讲话时打断所述第一参与者的音频输出,要么在所述第一参与者或第二参与者正在讲话时打断所述第一参与者的视觉输出。16.一种确定是否已经发生语音异常的计算机实现的方法,所述方法包括:在第一时间由经由计算设备访问的应用程序接收第一用户讲话的第一音频数据;经由用于所述应用程序的基于语音的机器学习模型,基于所述第一音频数据对与所述第一用户相关联的一个或更多个语音特性进行分类;在第二时间由所述应用程序接收所述第一用户讲话的第二音频数据;经由所述应用程序确定在所述第二音频数据中已经发生语音异常,所述确定至少部分基于所述第二音频数据与分类的语音特性的比较;以及响应于确定已经发生语音异常,经由所述应用程序使得由所述计算设备呈现第一打断内容,其中所述第一打断内容:包括关于检测到的语音异常的反馈,以及无论所述第一用户是否还在讲话,都会在随后的第三时间呈现。17.根据权利要求16所述的方法,其中,所述基于语音的机器学习模型位于与所述第一用户相关联的第一计算机设备上。18.根据权利要求16所述的方法,还包括基于所述语音特性生成所述第一用户的用户简档,所述用户简档包括识别语言和所述第一用户的口音。19.根据权利要求18所述的方法,还包括:在第三时间由所述应用程序从所述第一用户接收第一类型的语音异常的第一选择,所述第一选择应该得出呈现来自所述应用程序的打断内容;由所述应用程序将所述第一选择存储在所述用户简档中;以及在确定是否已经发生语音异常时参考所述用户简档。20.根据权利要求18所述的方法,还包括:在第三时间由所述应用程序从所述第一用户接收第一类型的语音异常的第一选择,所
述第一选择应该排除触发呈现来自所述应用程序的打断内容;由所述应用程序将所述第一选择存储在所述用户简档中;以及在确定是否已经发生语音异常时参考所述用户简档。
技术总结
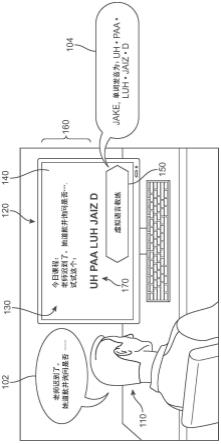
公开了在人类语音期间呈现打断内容的系统和方法。提出的系统在会话AI平台中提供改进的双工通信。在一些实施例中,系统接收语音数据并使用语言模型评估数据。如果语言模型检测到语言不规则的指示,例如错误发音,智能反馈助手可以确定系统应该近乎实时地打断说话者并提供有关其发音的反馈。此外,还可能检测到会话异常,导致智能反馈助手打断并呈现主持指导。在某些情况下,情绪模型也可用于基于说话者的声音检测情绪状态,以提供近乎即时的反馈。用户还可以定制他们被打断的方式和场合。馈。用户还可以定制他们被打断的方式和场合。馈。用户还可以定制他们被打断的方式和场合。
技术研发人员:S
受保护的技术使用者:辉达公司
技术研发日:2022.04.21
技术公布日:2023/2/6
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。