1.本技术涉及多媒体技术领域,尤其涉及一种音频数据的处理方法及装置。
背景技术:
2.随着数字流媒体音乐的广泛传播和应用,以及随着手机、平板、耳机等无线终端设备的普及和发展,聆听音乐成为大多数人在不同环境下的生活必需品,并且人们对音乐的多样化需求也日趋增长。例如,除了从音频开头至结尾全部聆听的听歌体验之外,人们对于由多个音频片段组合而成的音频,即串烧音频的需求也日益增多。
3.目前在实现音频串烧时,通常仅能实现对相似度较高的至少两个音频片段进行拼接串烧。然而这种方式实现的串烧音频的风格往往都比较单一。
4.因此,如何获得更丰富、更具多样性的串烧音频,是现有技术中亟待解决的技术问题。
技术实现要素:
5.本技术提供了一种音频数据的处理方法及装置,基于该方法可以获得更丰富、更具多样性的串烧音频。
6.为达上述目的,本技术提供如下技术方案:
7.第一方面,本技术提供一种音频数据的处理方法,该方法包括:获取m个音频片段,m是大于等于2的整数。根据该m个音频片段确定m-1个过渡音频信息。根据该m个音频片段和该m-1个过渡音频信息,生成目标串烧音频。其中,该m-1个过渡音频信息用于衔接该m个音频片段。其中,对于该m-1个过渡音频信息中的第一过渡音频信息而言,该第一过渡音频信息用于衔接m个音频片段中排序连续的第一音频片段和第二音频片段。这里,m个音频片段的排序为该m个音频片段的串烧顺序。
8.可以看出,基于本技术提供的方法对多个音频片段进行串烧时,可以生成全新的用于衔接该多个音频片段的过渡音频信息。因此本技术提供的方法无需考虑用于串烧得到目标串烧音频的多个音频片段的相似度。也就是说,通过本技术实施例提供的方法能够获得更丰富、更具多样性的串烧音频。
9.在一种可能的设计方式中,上述根据该m个音频片段确定m-1个过渡音频信息包括:根据上述第一音频片段的第一信息和上述第二音频片段的第二信息,确定第一过渡音频信息。其中,该第一信息包括第一音频片段的乐器数字接口(musical instrument digital interface,midi)信息和音频特征信息,该第二信息包括第二音频片段的midi信息和音频特征信息,该第一过渡音频信息包括第一过渡音频信息对应的第一过渡音频的乐器数字接口midi信息。
10.在另一种可能的设计方式中,上述的音频特征信息包括音频片段的主旋律轨位置信息、风格标签、情感标签、节奏信息、节拍信息、或调号信息中的至少一种。
11.基于该两种可能的设计,本技术所提供方法生成的用于衔接多个音频片段的过渡
音频信息是在midi域进行的。由于音频的midi信息是音频最原始的表现形式,其记录有音频的音符音高、音符力度、音符时长等信息。因此,相比在时域上直接对多个音频片段进行串烧,本技术所提供的方法在midi域中对音频片段的midi信息进行处理后所生成的用于衔接两个音频片段的过渡音频信息是基于音频乐理生成的。这样的话,基于该过渡音频信息获得的串烧音频在听觉上更加流畅自然。并且,在midi域处理数据也更有利于串烧音频在后期渲染时的灵活性和一致性。
12.在另一种可能的设计方式中,上述根据上述第一音频片段的第一信息和上述第二音频片段的第二信息,确定第一过渡音频信息包括:根据第一音频片段的第一信息、第二音频片段的第二信息以及预设神经网络模型,确定第一过渡音频信息。
13.在另一种可能的设计方式中,当在目标串烧音频中,第一音频片段位于第二音频片段之前,则:上述第一过渡音频信息是基于用于表征第一过渡音频信息的特征向量确定的,该第一过渡音频信息的特征向量是基于第一向量和第二向量确定的。其中,第一向量是根据第一信息在第一音频片段的时序末端生成的特征向量,第二向量是根据第二信息在第二音频片段的时序始端生成的特征向量。
14.基于该两种可能的设计,本技术所提供方法在midi域通过神经网络模型对多个音频片段的midi信息进行处理,从而得到了用于衔接多个音频片段的过渡音频的midi信息。这样的话,基于神经网络极强的学习能力,本技术在midi域基于对音频乐理的学习而得到的用于衔接多个音频片段的过渡音频信息,能够更自然流畅的衔接多个音频片段。
15.在另一种可能的设计方式中,上述获取m个音频片段包括:响应于用户的第一操作,确定k个目标音频。从该k个目标音频中提取m个音频片段。其中,2≤k≤m,且k是整数。
16.基于该可能的设计,本技术可以基于用户的意愿对用户选择的多个目标音频中的音频片段进行串烧,从而提高了用户的体验。
17.在另一种可能的设计方式中,在上述根据该m个音频片段确定m-1个过渡音频信息之前,上述方法还包括:确定该m个音频片段的串烧顺序。
18.在另一种可能的设计方式中,上述方法还包括:响应于用户的第二操作,重新确定上述m个音频片段的串烧顺序。根据重新确定的串烧顺序和m个音频片段,重新确定m-1个过渡音频信息。根据重新确定的m-1个过渡音频信息和m个音频片段,重新生成目标串烧音频。
19.根据该可能的设计,通过本技术所提供方法生成目标串烧音频后,当用户对该目标串烧音频不满意时,可以向终端设备输入第二操作,以使终端设备响应该第二操作,对生成该目标串烧音频的m个音频片段的串烧顺序进行调整,并重新生成新的目标串烧音频。这样的话,通过设备和用户之间的反复交互,可以令用户获得满意的目标串烧音频,从而提高了用户的体验。
20.在另一种可能的设计方式中,上述方法还包括:响应于用户的第三操作,对上述目标串烧音频进行渲染。
21.在另一种可能的设计方式中,上述方法还包括:输出上述目标串烧音频。
22.第二方面,本技术提供了一种音频数据的处理装置。
23.在一种可能的设计方式中,该处理装置用于执行上述第一方面提供的任一种方法。本技术可以根据上述第一方面提供的任一种方法,对该处理装置进行功能模块的划分。例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个
处理模块中。示例性的,本技术可以按照功能将该处理装置划分为获取单元、确定单元和生成单元等。上述划分的各个功能模块执行的可能的技术方案和有益效果的描述均可以参考上述第一方面或其相应的可能的设计提供的技术方案,此处不再赘述。
24.在另一种可能的设计中,该处理装置包括:一个或多个处理器和传输接口,该一个或多个处理器通过该传输接口接收或发送数据,该一个或多个处理器被配置为调用存储在存储器中的程序指令,以使得该处理装置执行如第一方面及其任一种可能的设计方式提供的任一种方法。
25.第三方面,本技术提供了一种计算机可读存储介质,该计算机可读存储介质包括程序指令,当程序指令在计算机或处理器上运行时,使得计算机或处理器执行第一方面中的任一种可能的实现方式提供的任一种方法。
26.第四方面,本技术提供了一种计算机程序产品,当其在音频数据的处理装置上运行时,使得第一方面中的任一种可能的实现方式提供的任一种方法被执行。
27.第五方面,本技术提供给了一种音频数据的处理系统,该系统包括终端设备和服务器。其中,该终端设备用于执行第一方面中的任一种可能的实现方式提供的任一种方法中与用户进行交互的方法部分,该服务器用于执行第一方面中的任一种可能的实现方式提供的任一种方法中生成目标串烧音频的方法部分。
28.可以理解的是,上述提供的任一种装置、计算机存储介质、计算机程序产品或系统等均可以应用于上文所提供的对应的方法,因此,其所能达到的有益效果可参考对应的方法中的有益效果,此处不再赘述。
29.在本技术中,上述音频数据的处理装置的名字对设备或功能模块本身不构成限定,在实际实现中,这些设备或功能模块可以以其他名称出现。只要各个设备或功能模块的功能和本技术类似,属于本技术权利要求及其等同技术的范围之内。
附图说明
30.图1为本技术实施例提供的一种手机硬件结构示意图;
31.图2为本技术实施例提供的一种音频数据的处理系统的示意图;
32.图3为本技术实施例提供的一种音频数据的处理方法的流程示意图;
33.图4为本技术实施例提供的一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图;
34.图5为本技术实施例提供的另一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图;
35.图6为本技术实施例提供的又一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图;
36.图7为本技术实施例提供的又一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图;
37.图8为本技术实施例提供的一种预设神经网络模型的结构示意图;
38.图9为本技术实施例提供的另一种预设神经网络模型的结构示意图;
39.图10为本技术实施例提供的第二操作的示意图;
40.图11为本技术实施例提供的一种对目标串烧音频的midi信息进行渲染以及输出
的示意图;
41.图12为本技术实施例提供的一种音频数据的处理装置的结构示意图;
42.图13为本技术实施例提供的用于承载计算机程序产品的信号承载介质的结构示意图。
具体实施方式
43.为了更清楚的理解本技术实施例,下面对本技术实施例中涉及的部分术语或技术进行说明:
44.1)、乐器数字接口(musical instrument digital interface,midi)
45.midi是编曲界应用最广泛的音乐标准格式,可以称为“计算机能理解的乐谱”。
46.midi用音符的数字控制信号来记录音乐。即,midi传输的不是声音信号本身,而是音符及控制参数等指令。这些指令可以指示midi设备演奏音乐,例如指示midi设备以指令中所指示的音量大小来演奏某个音符等。midi所传输的指令可以被统一表示成midi消息或midi信息。
47.通常,midi信息可以以图谱形式呈现,也可以以数据流的形式呈现。当midi信息以图谱形式呈现时,可以简称为midi谱。
48.对于一首以波形音频文件格式(waveform audio file format,wav)存储的时域上的音乐波形信号,当该音乐波形信号被转录为midi信息时,即可以将该midi信息理解为该音乐波形信号在midi域的表达形式。其中,时域是指时间域。
49.可以理解,midi信息一般可以包含多个声轨,且每一个声轨均标注有音符的起始位置、结束位置、音符的音高以及音符的力度信息等。其中,一个声轨用于表征一种乐器声音/人声。可以理解,一首完整的通过midi信息表达的音乐的大小往往只有几十千字节(kilobyte,kb),但是却可以包含数十条声轨。
50.当前,几乎所有的现代音乐都是通过midi信息加上音色库来制作合成。其中,音色库(或称为采样库)包括人类所能听到和创造出来的各种声音,例如包括各种乐器的演奏、各种人声的演唱、念白,以及各种自然、人造声音的录音等。
51.2)、隐空间
52.对于神经网络的某个中间层输出的特征,该特征所表示的原始数据经过若干神经网络层变换后的空间即可称为隐空间。通常,隐空间的维度一般小于原始数据的空间维度。
53.隐空间也可以被理解为原始数据特征的某种抽象的提取和表示。
54.3)、序列模型网络、双向序列模型网络
55.通常,输入或者输出中包含有序列数据的模型可以叫做序列模型。序列模型通常用于处理具有某种顺序关系数据。用于构建序列模型的神经网络可以称为序列模型网络。
56.其中,常见的序列模型网络包括循环神经网络(recurrent neural network,rnn)、长短期记忆网络(long short-term memory,lstm)、门控循环单元(gated recurrent unit,gru)、转换器(transformer)等。
57.应理解,序列模型网络在时间t预测得到的预测结果,通常是基于对输入数据在时间t之前的数据进行学习后得到的。
58.而在一些情况中,当序列模型网络在时间t预测得到的预测结果,是基于对输入数
据在时间t之前的数据进行学习,以及对输入数据在时间t之后的数据进行学习后得到的,这种情况下,该序列网络模型称为双向序列模型网络。可以看出,双向序列网络模型在对输入数据进行预测时,结合了输入数据中时刻t的上下文信息来进行结果预测。
59.应理解,双向序列模型可以在输入数据的任意时刻预测得到预测结果。
60.其中,常见的双向序列模型网络包括(双向)循环神经网络((bidirectional)recurrent neural networks,(bi-)rnn)、(双向)长短时记忆网络((bidirectional)long short-term memory,(bi-)lstm)、(双向)门控循环单元((bidirectional)gate recurrent unit,(bi-)gru)、转换器(transformer)等。
61.4)、其他术语
62.在本技术实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本技术实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
63.在本技术的实施例中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。本技术中的术语“至少一个”的含义是指一个或多个。在本技术的描述中,除非另有说明,术语“多个”的含义是两个或两个以上。
64.还应理解,本文中所使用的术语“和/或”是指并且涵盖相关联的所列出的项目中的一个或多个项目的任何和全部可能的组合。术语“和/或”,是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本技术中的字符“/”,一般表示前后关联对象是一种“或”的关系。
65.还应理解,在本技术的各个实施例中,各个过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本技术实施例的实施过程构成任何限定。
66.应理解,根据a确定b并不意味着仅仅根据a确定b,还可以根据a和/或其它信息确定b。
67.还应理解,术语“包括”(也称“includes”、“including”、“comprises”和/或“comprising”)当在本说明书中使用时指定存在所陈述的特征、整数、步骤、操作、元素、和/或部件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元素、部件、和/或其分组。
68.应理解,本技术实施例下文中所述的串烧,是指从不同音频中提取出多段音频段,并将该多个音频段按照预设顺序串联组合在一起的过程,该预设顺序即为该多段音频段的串烧顺序。
69.本技术实施例提供一种音频数据的处理方法,该方法先根据预先获取的m个音频片段确定出m-1个过渡音频信息,然后基于该m-1个过渡音频信息对该m个音频片段进行衔接,从而生成了m个音频片段被串烧后的目标串烧音频。其中,一个过渡音频信息用于衔接串烧顺序相邻的两个音频片段。
70.由于通过该方法对多个音频片段进行串烧时,无需考虑该多个音频片段之间的特征相似度。因此,通过本技术实施例方法可以获得丰富的、风格多样的串烧音频。
71.本技术实施例还提供一种音频数据的处理装置,该处理装置可以是终端设备。其中,该终端设备可以是手机、平板电脑、笔记本电脑、个人数字助理(personal digital assistant,pda)、上网本、可穿戴电子设备(例如智能手表、智能眼镜)等便携式设备,也可以是台式计算机、智能电视、车载等设备,还可以是其他任一能够实现本技术实施例的终端设备,本技术对此不作限定。
72.以上述处理装置是手机为例,参考图1,图1示出了本技术实施例提供的一种手机10硬件结构示意图。如图1所示,手机10可以包括处理器110,内部存储器120,外部存储器接口130,摄像头140,触摸屏150,音频模块160以及通信模块170等。
73.处理器110可以包括一个或多个处理单元,例如:处理器110可以包括应用处理器(application processor,ap),调制解调处理器,图形处理器(graphics processing unit,gpu),图像信号处理器(image signal processor,isp),控制器,存储器,视频编解码器,数字信号处理器(digital signal processor,dsp),基带处理器,和/或神经网络处理器(neural-network processing unit,npu)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
74.其中,控制器可以是手机10的神经中枢和指挥中心。控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
75.npu为神经网络(neural-network,nn)计算处理器,通过借鉴生物神经网络结构,例如借鉴人脑神经元之间传递模式,对输入信息快速处理,还可以不断的自学习。通过npu可以实现手机10的智能认知等应用,例如:文字识别、图像识别、人脸识别等。
76.处理器110中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器110中的存储器为高速缓冲存储器。该存储器可以保存处理器110刚用过或循环使用的指令或数据。如果处理器110需要再次使用该指令或数据,可从所述存储器中直接调用。避免了重复存取,减少了处理器110的等待时间,因而提高了系统的效率。
77.在一些实施例中,处理器110可以包括一个或多个接口。接口可以包括集成电路(inter-integrated circuit,i2c)接口,集成电路内置音频(inter-integrated circuit sound,i2s)接口,脉冲编码调制(pulse code modulation,pcm)接口,通用异步收发传输器(universal asynchronous receiver/transmitter,uart)接口,移动产业处理器接口(mobile industry processor interface,mipi),通用输入输出(general-purpose input/output,gpio)接口,用户标识模块(subscriber identity module,sim)接口,和/或通用串行总线(universal serial bus,usb)接口等。
78.i2c接口是一种双向同步串行总线,包括一根串行数据线(serial data line,sda)和一根串行时钟线(derail clock line,scl)。i2s接口可以用于音频通信。pcm接口也可以用于音频通信,将模拟信号抽样,量化和编码。uart接口是一种通用串行数据总线,用于异步通信。该总线可以为双向通信总线。它将要传输的数据在串行通信与并行通信之间转换。mipi接口可以被用于连接处理器110与摄像头140、触摸屏150等外围器件。mipi接口包括摄像头串行接口(camera serial interface,csi),触摸屏串行接口(display serial interface,dsi)等。gpio接口可以通过软件配置。gpio接口可以被配置为控制信号,也可被配置为数据信号。
79.内部存储器120,可以用于存储计算机可执行程序代码,所述可执行程序代码包括
指令。处理器110通过运行存储在内部存储器120的指令,从而执行手机10的各种功能应用以及数据处理,例如执行本技术实施例提供的音频数据的处理方法。
80.外部存储器接口130可以用于连接外部存储卡,例如micro sd卡,实现扩展手机10的存储能力。外部存储卡通过外部存储器接口130与处理器110通信,实现数据存储功能。例如将音乐,视频、图片等文件保存在外部存储卡中。
81.摄像头140,用于获取静态图像或视频。物体通过镜头生成光学图像投射到感光元件。数字信号处理器用于处理数字信号,除了可以处理数字图像信号,还可以处理其他数字信号。应理解,手机10可以包括n个摄像头140,n是正整数。
82.触摸屏150,用于手机10和用户之间的交互。触摸屏150包括显示面板151和触摸板152。其中,显示面板151用于显示文字、图像、视频等。触摸板152用于输入用户的指令。
83.音频模块160用于将数字音频信息转换成模拟音频信号输出,也用于将模拟音频输入转换为数字音频信号。音频模块160可以包括扬声器161、受话器162、麦克风163以及耳机接口164中的至少一个。
84.其中,扬声器161,也称“喇叭”,用于将音频电信号转换为声音信号。受话器162,也称“听筒”,用于将音频电信号转换成声音信号。麦克风163,也称“话筒”,“传声器”,用于将声音信号转换为电信号。耳机接口164用于连接有线耳机。耳机接口164可以是usb接口,也可以是3.2mm的开放移动电子设备平台(open mobile terminal platform,omtp)标准接口,美国蜂窝电信工业协会(cellular telecommunications industry association of the usa,ctia)标准接口。
85.这样,手机10即可以通过音频模块160中的扬声器161,受话器162,麦克风163,耳机接口164,以及应用处理器等实现音频功能。例如用户的语音输入、语音/音乐的播放等。
86.通信模块170,用于实现手机10的通信功能。具体的,通信模块170可以通过天线、移动通信模块,无线通信模块,调制解调处理器以及基带处理器等实现。
87.天线用于发射和接收电磁波信号。手机10中的每个天线可用于覆盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。例如:可以将用于移动通信模块的天线1可以复用为无线局域网的分集天线。在另外一些实施例中,天线可以和调谐开关结合使用。
88.移动通信模块可以提供应用在手机10上的包括2g/3g/4g/5g等无线通信的解决方案。移动通信模块可以包括至少一个滤波器,开关,功率放大器,低噪声放大器(low noise amplifier,lna)等。移动通信模块可以由天线接收电磁波,并对接收的电磁波进行滤波,放大等处理,传送至调制解调处理器进行解调。移动通信模块还可以对经调制解调处理器调制后的信号放大,经天线转为电磁波辐射出去。在一些实施例中,移动通信模块的至少部分功能模块可以被设置于处理器110中。在一些实施例中,移动通信模块的至少部分功能模块可以与处理器110的至少部分模块被设置在同一个器件中。调制解调处理器可以包括调制器和解调器。
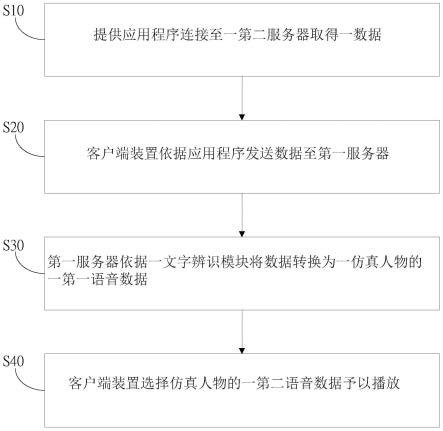
89.无线通信模块可以提供应用在手机10上的包括无线局域网(wireless local area networks,wlan)(如无线保真(wireless fidelity,wi-fi)网络),蓝牙(bluetooth,bt),gnss,调频(frequency modulation,fm),近距离无线通信技术(near field communication,nfc),红外技术(infrared,ir)等无线通信的解决方案。无线通信模块可以
是集成至少一个通信处理模块的一个或多个器件。无线通信模块经由天线接收电磁波,将电磁波信号调频以及滤波处理,将处理后的信号发送到处理器110。无线通信模块还可以从处理器110接收待发送的信号,对其进行调频,放大,经天线转为电磁波辐射出去。
90.示例性的,本技术实施例中的gnss可以包括:全球卫星定位系统(global positioning system,gps),全球导航卫星系统(global navigation satellite system,glonass),北斗卫星导航系统(beidou navigation satellite system,bds),准天顶卫星系统(quasi-zenith satellite system,qzss)和/或星基增强系统(satellite based augmentation systems,sbas)等。
91.可以理解的是,本技术实施例示意的结构并不构成对手机10的具体限定。在本技术另一些实施例中,手机10可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
92.需要说明的是,当上述的处理装置为终端设备,上述音频数据的处理方法可以通过安装在终端设备上的应用程序(application,app)实现。其中,该app具有剪辑音频的功能。作为示例,该app可以是音乐剪辑app等。
93.其中,该app可以是具有人工介入功能的app。这里,人工介入是指app可以接收用户输入的指令,并能够响应用户输入的指令。也就是说,该app可以和用户进行交互。该app可以包括用于与用户进行交互的交互界面,该交互界面通过终端设备的显示屏(例如图1所示的显示面板151)显示。
94.应理解,如果终端设备包括有触摸屏(例如图1所示的触摸屏150),则用户可以通过操作终端设备的触摸屏(例如操作图1所示的触摸板152)实现和app的交互。如果终端设备不包括触摸屏(例如终端设备是普通的台式计算机),则用户可以通过终端设备的鼠标、键盘等输入输出器件和app进行交互。
95.还应理解,上述的app可以是安装在终端设备中的嵌入式应用程序(即终端设备的系统应用),也可以是可下载应用程序。
96.其中,嵌入式应用程序是设备(如手机)的操作系统提供的应用程序。例如,该嵌入式应用程序可以时手机出厂是提供的音乐应用程序等。可下载应用程序是一个可以提供自己的通信连接的应用程序,该可下载应用程序是可以预先安装在设备中的app,或者可以是由用户下载并安装在设备中的第三方app,例如,该该可下载应用程序可以是音乐剪辑app,本技术实施例对此不作具体限定。
97.还需说明的是,上述的处理装置也可以是服务器。这种情况下,本技术实施例还提供一种音频数据的处理系统。其中,该处理系统包括服务器和终端设备,该服务器和终端设备之间可以通过有线或无线的方式连接通信。
98.如图2所示,图2示出了本技术实施例提供的一种处理系统20的示意图。处理系统20包括终端设备21和服务器22。其中,终端设备21可以通过客户端app(例如音频剪辑的客户端app)与用户进行交互,例如接收用户输入的指令,并将接收到的指令传输至服务器22。然后,服务器22用于基于从终端设备21接收到的指令执行本技术实施例提供的音频数据的处理方法,并将生成的目标串烧音频的midi信息和/或目标串烧音频发送至终端设备21。这样,终端设备21即可接收到服务器22发送的目标串烧音频的midi信息和/或目标串烧音频,
并通过音频模块向用户播放该目标串烧音频,和/或,通过显示屏向用户显示该目标串烧音频的midi谱。对此不作限定。
99.下面结合附图,对本技术实施例提供的音频数据的处理方法进行详细描述。
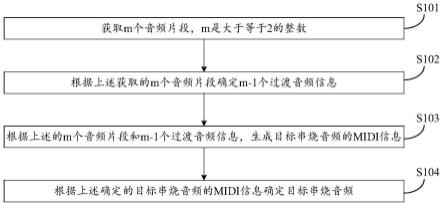
100.参考图3,图3示出了本技术实施例提供的一种音频数据的处理方法的流程示意图。该方法由上文所述的音频数据的处理装置执行。下面,以上文所述的音频数据的处理装置是终端设备为例,该方法可以包括以下步骤:
101.s101、获取m个音频片段,m是大于等于2的整数。
102.其中,该m个音频片段包括不同音频中的片段。
103.具体的,终端设备可以先确定出k个目标音频,然后再从k个目标音频中提取m个音频片段。其中,2≤k≤m,且k是整数。
104.也就是说,终端设备可以从一个目标音频中提取至少一个音频片段。
105.s102、根据上述获取的m个音频片段确定m-1个过渡音频信息。
106.其中,该m-1个过渡音频信息用于衔接该m个音频片段。对于该m-1个过渡音频信息中的第一过渡音频信息,该第一过渡音频信息是用于衔接终端设备所获取的m个音频片段中排序连续的第一音频片段和第二音频片段的过渡音频信息。应理解,这里所述排序是m个音频片段的串烧顺序的排序。应理解,该串烧顺序是终端设备预先确定的。
107.具体的,终端设备可以根据预设神经网络模型和在s101获取的m个音频片段的信息,确定出m-1个过渡音频信息。这里,该过渡音频信息即为过渡音频段的midi信息。
108.s103、根据上述的m个音频片段和m-1个过渡音频信息,生成目标串烧音频的midi信息。
109.终端设备通过上述的m-1个过渡音频信息(即过渡音频段的midi信息)将m个音频片段的midi信息连接起来,即生成了目标串烧音频的midi信息。
110.s104、根据上述确定的目标串烧音频的midi信息确定目标串烧音频。
111.可选的,终端设备还可以基于目标串烧音频的midi信息确定出目标串烧音频后,输出该目标串烧音频。
112.通过上述本技术实施例提供的方法,终端设备可以基于m个音频片段,生成用于衔接该m个音频片段的m-1个过渡音频信息。这样,通过该m-1个过渡音频信息即可将m个音频片段的midi信息衔接起来,从而得到m个音频片段被串烧后的目标串烧音频的midi信息。这样的话,当终端设备将目标串烧音频的midi信息转换为音频格式,即得到了目标串烧音频。可以看出,通过这种方式对多个音频片段进行串烧时,终端可以生成全新的用于衔接该多个音频片段的过渡音频段,因此本技术实施例提供的方法无需考虑用于得到目标串烧音频的音频片段的相似度。也就是说,通过本技术实施例提供的方法能够获得更丰富、更具多样性的串烧音频。
113.并且,本技术实施例提供的方法生成过渡音频信息的过程是在midi域中进行的,由于音频的midi信息是音频最原始的表现形式,其记录有音频的音符音高、音符力度、音符时长等信息。因此,相比在时域上直接对多个音频片段进行串烧,本技术实施例提供的方法能够基于音频乐理生成用于衔接两个音频片段的过渡音频信息,且基于该过渡音频信息获得的串烧音频在听觉上更加流畅自然。并且,在midi域处理数据更有利于串烧音频在后期渲染时的灵活性和一致性。
114.下面对s101-s104进行详细描述:
115.在s101,可以理解,s101所述的一个音频可以是一首完整/不完整的歌曲/音乐,一个音频片段则是从一个音频中截取的一段音频。还应理解,音频或音频片段均具有时序性。
116.可选的,终端设备可以随机的将媒体数据库或本地存储的音乐数据库中的k个音频确定为k个目标音频。
117.可选的,终端设备可以先接收用户输入的第一操作,并响应该第一操作,从而确定出k个目标音频。可以理解,该终端设备中安装有具有音频剪辑功能的应用程序,该第一操作即为用户在该应用程序中的音频剪辑界面上的操作。
118.一种可能的实现方式,上述的第一操作可以包括用户在音频剪辑界面上的目标音频的选择操作。可选的,选择操作可以包括音乐数据库的选择操作,以及在选中的音乐数据库中选择目标音频的操作。
119.其中,音乐数据库可以是存储在本地的音乐数据库,也可以是基于系统根据音频的场景标签、情感标签、风格标签等对音频进行分类后的音乐数据库,也可以是系统自动推荐的音乐数据库,还可以是用户对基于系统推荐或分类的音乐数据库中的音频进行删除或增加后配置得到的自定义的音乐数据库等,本技术实施例对此不作限定。这里,系统可以是与终端设备上安装的具有音频剪辑功能的应用程序连接通信的任意媒体系统,本技术实施例对此不作限定。
120.作为示例,系统推荐的音乐数据库可以是系统根据终端设备的传感器检测的当前用户所处场景/状态推荐的音乐数据库。例如,当终端设备传感器检测到当前用户的状态为跑步状态,则系统可以向用户推荐包括动感音乐的音乐数据库。或者,系统推荐的音乐数据库也可以是随机展示的流媒体的音乐数据库,例如各大音乐榜单,或者包括流行经典音乐的音乐数据库。等等。
121.这里需要说明的是,每个音频在制作时,都可以标注有包括但不限于场景、风格、情感等标签。其中,场景是指适合聆听该音频的场景,例如可以是工作场景、学习场景、跑步场景等。风格是指音频的音乐风格,例如可以是摇滚、电子、轻音乐等。情感是指该音频表达的情感,例如可以是伤感、思恋、孤独等。对此不做详述。
122.以终端设备设备是手机10,手机10中安装有音频剪辑应用程序为例,在一个示例中,参考图4,图4示出了本技术实施例提供的一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图。
123.如图4中的(a)所示,手机10的触摸屏上显示有音频剪辑应用程序的音频剪辑界面401。可以看出,音频剪辑界面401为“分类曲库”标签下的音乐数据库选择界面。这样,用户即可在音频剪辑界面401上进行音乐数据库的选择操作。
124.如图4中的(a)所示,在音频剪辑界面401上,显示有系统基于音频的不同分类标准对音频进行分类时的类型标签。如图所示,音频剪辑界面401上显示有基于适于聆听音频的场景对音频进行分类时的类型标签,如“工作”标签、“跑步”标签等。音频剪辑界面401上还显示有基于音频所表达情感对音频进行分类时的类型标签,例如“快乐”标签、“兴奋”标签等。音频剪辑界面401上还显示有基于音频的音乐风格对音频进行分类时的类型标签,例如“流行”标签、“节奏蓝调”标签等。容易理解,图4中的(a)所示出的音频的类型标签及其显示格式仅为示例性说明,并不作为对本技术实施例保护范围的限定。
125.这样,用户可以基于自身的需求/喜好,操作(例如用手指/触摸笔点击)音频剪辑界面401上显示的类型标签,例如用户可以用手指分别点击“跑步”标签、“快乐”标签、“兴奋”标签、以及“节奏蓝调”标签,并在操作(例如用手指/触摸笔点击)音频剪辑界面401上的“确定”按钮后,作为响应,手机10即可显示系统基于用户选择的类型标签推荐的所有具有“跑步”标签、“快乐”标签、“兴奋”标签、以及“节奏蓝调”标签的音频的界面,例如图4中的(b)所示的目标音频选择界面402。可以理解,目标音频选择界面402上显示的所有音频,即构成了用户所选择的音乐数据库。
126.可以理解,当用户在音频剪辑界面401上选择的类型标签为“自动”标签,则手机10在目标音频选择界面402上所显示的音频,即为手机10根据该手机10配置的传感器(例如陀螺仪传感器、噪声传感器等)检测到的当前操作手机10的用户所处的环境/状态,为用户自动推荐的适合用户在当前环境聆听的音频。对此不作赘述。
127.进一步的,用户可以在目标音频选择界面402上进行目标音频的选择操作,例如用户可以基于自身的需求/喜好,在目标音频选择界面402选中k个目标音频。作为响应,手机10即确定出k个目标音频。
128.在另一个示例中,参考图5,图5示出了本技术实施例提供的另一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图。
129.如图5中的(a)所示,手机10的触摸屏上显示有音频剪辑应用程序的音频剪辑界面501。可以看出,音频剪辑界面501为用户在音频剪辑界面401上选中“推荐曲库”标签后显示的音乐数据库选择界面。这样,用户即可在音频剪辑界面501上进行音乐数据库的选择操作。
130.如图5中的(a)所示,在音频剪辑界面501上,显示有系统展示的多个音乐数据库的标识。例如“流行经典”音乐库标识、“网络甜歌”音乐库标识、“轻音乐集”音乐库标识、“金曲榜”音乐库标识等。容易理解,图5中的(a)所示出的音乐数据库及其标识的显示格式仅为示例性说明,并不作为对本技术实施例保护范围的限定。例如,手机10还可以分多个界面来显示不同类型的音乐数据库的标识,对此不作限定。
131.这样,用户即可基于自身需求或喜好,操作(例如用手指/触摸笔点击)音频剪辑界面501上所显示的一个音乐数据库(例如“流行经典”音乐库),并在操作(例如用手指/触摸笔点击)音频剪辑界面501上的“确定”按钮后,作为响应,手机10即可显示“流行经典”音乐库中音频的界面,例如图5中的(b)所示的目标音频选择界面502。
132.进一步的,用户可以在目标音频选择界面502上进行目标音频的选择操作,例如用户可以基于自身的需求/喜好,在目标音频选择界面502选中k个目标音频。作为响应,手机10即确定出k个目标音频。
133.在又一个示例中,参考图6,图6示出了本技术实施例提供的又一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图。
134.如图6所示,手机10的触摸屏上显示有音频剪辑应用程序的音频剪辑界面601。可以看出,音频剪辑界面601为用户在音频剪辑界面401或音频剪辑界面501上选中“本地曲库”标签后显示的目标音频选择界面。这样,用户即可在音频剪辑界面501上进行目标音频的选择操作。
135.可以理解,用户在音频剪辑界面401或音频剪辑界面501上选中“本地曲库”标签后
显示音频剪辑界面601的操作,相当于是用户在音频剪辑界面401或音频剪辑界面501选择本地音乐数据库的操作。
136.如图6所示,在音频剪辑界面601上显示有本地存储的多个音频,例如以列表的形式显示多个音频。这样,用户可以在音频剪辑界面601上进行目标音频的选择操作,例如用户可以基于自身的需求/喜好,在音频剪辑界面601选中k个目标音频。作为响应,手机10即确定出k个目标音频。
137.容易理解,图6中所示出的本地存储的多个音频的显示的格式仅为示例性说明,并不作为对本技术实施例的限定。例如,手机10还可以将本地存储的多个音频划分为多个组,并以多个层级界面来显示不同组别中的音频列表,对此不作限定。
138.另一种可能的实现方式,上述的第一操作可以包括用户在音频剪辑界面上输入目标音频的数量的输入操作,以及音乐数据库的选择操作。
139.作为示例,参考图7,图7示出了本技术实施例提供的又一种用户在音频剪辑应用程序的音频剪辑界面上输入的第一操作的示意图。
140.如图7所示,图7所示的音频剪辑界面701上包括用于输入串烧音频数目的接口(即输入框702),这样,用户即可通过输入框702输入串烧音频的数量,以k的取值是3为例,即用户可以在输入框702输入数值“3”。
141.此外,用户可以通过操作音频剪辑界面701上的“曲库”按钮,并根据自身的需求/喜好选择音乐数据库。这里,用户操作音频剪辑界面701上的“曲库”按钮后所显示的选择音乐数据库的过程,可以参考上文中图4中的(a)、图5中的(b)以及图6选择音乐数据库的描述,这里不作赘述。
142.当用户通过操作音频剪辑界面701上的“曲库”按钮选定音乐数据库后,手机10即可以根据用户在输入框702输入的k值,在用户选定的音乐数据库中选择k个音频作为目标音频。
143.可选的,手机10可以基于预设规则,并根据用户在输入框702输入的k值,在用户选定的音乐数据库中选择k个音频作为目标音频。例如,手机10可以在音乐数据库中随机选择k个音频作为目标音频,或者,手机10可以将音乐数据库中的前k个音频作为目标音频,等等,本技术实施例对此不作限定。
144.这样,当终端设备确定出k个目标音频后,终端设备可以通过预设算法从k个目标音频中提取m个音频片段。作为示例,该预设算法可以是用于提取歌曲中副歌/高潮部分的算法,本技术实施例对此不作限定。
145.可选的,终端设备预置有m个音频的串烧顺序,或者,终端设备可以进一步通过与用户进行交互,以确定出该m个音频片段在串烧时的串烧顺序。
146.一个示例,结合图4、图5以及图6,当用户在图4中的(b)所示的目标音频选择界面402上选中k个目标音频后,并对目标音频选择界面402上的“确定”按钮进行操作(例如用手指/触摸笔点击)后,或者,当用户在图5中的(b)所示的目标音频选择界面502上选中k个目标音频后,并对目标音频选择界面502上的“确定”按钮进行操作(例如用手指/触摸笔点击)后,或者,当用户在图6所示的音频剪辑界面601选中k个目标音频后,并对音频剪辑界面601上的“确定”按钮进行操作(例如用手指/触摸笔点击)后,终端设备(即手机10)即可显示如图4中的(c)所示的串烧顺序选择界面403。如图4中的(c)所示,串烧顺序选择界面403可以
包括“顺序”、“随机”、以及“自定义”三个选项。
147.其中,当用户选择“顺序”选项时,作为响应,手机10可以按照k个目标音频在所属音乐数据库中的顺序,对从k个目标音频中提取的m个音频片段进行串烧。可选的,k个目标音频在所属音乐数据库中的顺序,可以以该k个目标音频在该音乐数据库中的编号体现。
148.当用户选择“随机”选项时,作为响应,手机10可以随机的对从k个目标音频中提取的m个音频片段进行串烧。
149.当用户选择“自定义”选项时,用户可以进一步的在“自定义”的选项框4031中以预设顺序依次输入k个目标音频的标识(例如编号)。这样,作为响应,手机10即可以该预设顺序对从k个目标音频中提取的m个音频片段进行串烧。其中,该预设顺序即为用户自定义的顺序。
150.另一个示例,在图7所示的音频剪辑界面701上,还可以包括三个用于输入串烧歌曲顺序的选项,其具体说明可以参考上文对图4中的(c)的说明,这里不再赘述。
151.在s102,终端设备在确定出m个音频片段后,可以确定该m个音频片段的音频特征信息。
152.其中,音频片段的音频特征信息可以包括音频片段的主旋律轨位置信息、风格标签、情感标签、节奏信息、节拍信息、或调号信息等信息中的至少一种。可以理解,这里所述的节拍即为音乐的节拍,调号即为音调号。其中,本技术实施例对终端设备获得音频片段的音频特征信息的具体实现方式不作具体限定。本技术实施例对终端设备确定该m个音频片段的音频特征信息的过程不作详述。
153.对于终端设备确定出的m个音频片段中的每个音频片段而言,终端设备还可以通过音乐人声检测技术,对每个音频片段进行音乐和人声分离处理。
154.以m个音频片段中的第一音频片段为例,终端设备可以通过音乐人声检测技术,将第一音频片段中的人声和各种乐器(例如钢琴、贝斯、鼓、小提琴等)声音分离,并将分离得到的多轨乐器和人声转换为midi格式的数据,该midi格式的数据即为第一音频片段的midi信息。这里,本技术实施例对音乐人声检测技术不作详述。
155.需要说明的是,音频片段中也可以不包括人声。这种情况下,终端设备可以通过音乐人声检测技术,分离出第一音频片段中的多轨乐器声音,并将该多轨乐器声音转换为midi格式的数据。
156.进一步的,终端设备可以根据m个音频片段的音频特征信息和midi信息,以及预设神经网络模型,确定出m-1个过渡音频信息。其中,m-1个过渡音频信息中的一个过渡音频信息,是用于衔接终端设备所获取的m个音频片段中排序连续的两个音频片段的过渡音频信息,其中,该m个音频片段的排序是指该m个音频片段的串烧顺序,过渡音频信息为过渡音频段的midi信息。这里,终端设备确定m个音频片段的串烧顺序的详细描述可以参考s101中的相关描述,这里不再赘述。
157.其中,预设神经网络模型可以预置在终端设备中,也可以预置在与终端设备具有通信连接的服务器上,本技术实施例对此不作限定。
158.其中,该预设神经网络模型包括编码器、信息提取模块、信息生成模块以及解码器。这里,编码器、信息提取模块、信息生成模块、以及解码器均为序列模型网络结构,信息提取模块是双向序列模型网络结构。
159.作为示例,其中,编码器、信息生成模块、以及解码器可以是rnn、lstm、gru、transformer等网络。信息提取模块可以是bi-rnn、bi-lstm、bi-gru、transformer等网络。
160.应理解,该预设神经网络模型包括至少两个编码器、至少两个信息提取模块、至少一个信息生成模块以及至少一个解码器。其中,该至少两个编码器的网络结构相同,该至少两个信息提取模块的网络结构相同,该至少一个信息生成模块的网络结构相同,该至少一个解码器的网络结构相同。此外,在一个预设神经网络模型中,编码器和解码器的网络结构也可以是相同的。需要说明的是,编码器和解码器的数据流向是相反的。作为示例,编码器的输入可以作为解码器的输出,编码器的输出可以作为解码器的输入。
161.应理解,上述至少两个编码器、至少两个信息提取模块、至少一个信息生成模块以及至少一个解码器的网络参数均是在训练该预设神经网络模型时确定的。这里,训练预设神经网络模型的详细说明可以参考下文中训练图8所示预设神经网络模型80的描述,这里不作赘述。
162.在一种可能的实现方式中,当需要该预设神经网络模型处理的音频片段的数量为m,则该预设神经网络模型包括m个输入和m-1个输出。这样的话,该预设神经网络模型中编码器的数量为m,信息提取模块的数量为2
×
(m-1),信息生成模块和解码器的数量均为m-1。
163.这种情况下,该预设神经网络模型可以对输入的m个音频片段的信息同时进行处理,并输出m-1个过渡音频的midi信息。
164.一个示例,以m的取值是2为例,参考图8,图8示出了本技术实施例提供的一种预设神经网络模型的结构示意图。
165.如图8所示,预设神经网络模型80包括用于接收2个输入的2个编码器,分别为编码器811和编码器812。预设神经网络模型80包括2个(即2
×
(2-1)个)信息提取模块,分别为信息提取模块821和信息提取模块822。预设神经网络模型80还包括1个(即(2-1)个)信息生成模块(即信息生成模块83)和1个(即(2-1)个)解码器(即解码器84)。
166.另一个示例,以m的取值是4为例,参考图9,图9示出了本技术实施例提供的另一种预设神经网络模型的结构示意图。
167.如图9所示,预设神经网络模型90包括用于接收4个输入的4个编码器,分别为编码器911、编码器912、编码器913、以及编码器914。预设神经网络模型90包括6个(即2
×
(4-1)个)信息提取模块,分别为信息提取模块921、信息提取模块922、信息提取模块923、信息提取模块924、信息提取模块925、以及信息提取模块926。预设神经网络模型90包括3个(即(4-1)个)信息生成模块,分别为信息生成模块931、信息生成模块932、以及信息生成模块933。预设神经网络模型90还包括3个(即(4-1)个)解码器,分别为解码器941、解码器942、以及解码器943。
168.在另一种可能的实现方式中,预设神经网络模型中编码器和信息提取模块的数量均为2,信息生成模块和解码器的数量均为1(例如图8所示的预设神经网络模型)。也就是说,该预设神经网络模型包括2个输入、1个输出。
169.这种情况下,该预设神经网络模型一次可以对2个输入(即2个音频片段的信息)同时进行处理,并输出1个过渡音频信息。当需要该预设神经网络模型处理的音频片段的数量为m,且m大于2时,则该预设神经网络模型可以对m个音频片段的信息串行的进行m-1次处理,即可得到m-1个过渡音频信息。应理解,该预设神经网络模型每次处理的两个音频片段
是串烧顺序相邻的两个音频片段。
170.作为示例,当需要该预设神经网络模型处理的音频片段包括音频片段1、音频片段2、音频片段3以及音频片段4,即m的取值为4时,假设该4个音频片段的串烧顺序为:音频片段1
→
音频片段4
→
音频片段3
→
音频片段2,则终端设备可以对该4个音频片段的信息串行的进行3(即(4-1))次处理,即可得到3个过渡音频信息。具体的,终端设备可以将音频片段1和音频片段4的信息作为该预设神经网络的两个输入信息,这样即可得到用于衔接音频片段1和音频片段4的过渡音频信息1。终端设备可以将音频片段4和音频片段3的信息作为该预设神经网络的两个输入信息,这样即可得到用于衔接音频片段4和音频片段3的过渡音频信息2。终端设备还可以将音频片段3和音频片段2的信息作为该预设神经网络的两个输入信息,这样即可得到用于衔接音频片段3和音频片段2的过渡音频信息3。
171.下面以m的取值是2,即以终端设备获取到2个音频片段(例如该2个音频片段包括第一音频片段和第二音频片段),且串烧顺序为第一音频片段
→
第二音频片段为例,结合图8对本技术实施例提供的预设神经网络模型中的各个模块及其对音频片段的信息进行处理的过程予以详细说明。从串烧顺序可以看出,第一音频片段是目标串烧音频中在前的乐段(简称前乐段),第二音频片段是目标串烧音频中在后的乐段(简称后乐段)。
172.这里,第一音频片段作为前乐段,其音频特征信息和midi信息可以被称为第一信息。第二音频片段作为后乐段,其音频特征信息和midi信息可以被称为第二信息。其中,第一信息即可作为预设神经网络模型80的一个输入,第二信息即可作为预设神经网络模型80的另一个输入。
173.需要说明的是,第一信息中的midi信息(即第一音频片段的midi信息)中的多个声轨,和第二信息中的midi信息(即第二音频片段的midi信息)中的多个声轨是相同的。具体的,第一信息中的midi信息所包括的声轨数量及其类型,与第二信息中的midi信息所包括的声轨数量及其类型均相同。
174.例如,第一信息中的midi信息包括3个声轨,分别为人声声轨、钢琴声轨以及小提琴声轨。那么,第二信息中的midi信息也包括这3个声轨。
175.应理解,假设第一信息中的midi信息所包括的声轨数量和第二信息中的midi信息所包括的声轨数量不同时,例如第一信息中的midi信息所包括的声轨数量,大于第二信息中的midi信息所包括的声轨数量,且第一信息中的midi信息包括第二信息中的midi信息所包括的所有声轨类型,则终端设备可以为第二信息中的midi信息增加空轨,以使第一信息中的midi信息所包括的声轨数量和第二信息中的midi信息所包括的声轨数量相同。
176.这样,终端设备可以将第一信息作为预设神经网络模型80的一个输入(例如输入1)输入到编码器811中。编码器811即可对接收到的第一信息进行处理后输出第一音频片段对应的第一序列。这里,第一序列是编码器811对第一信息中的midi信息和音频特征信息进行特征提取后得到的序列。这里,第一序列可以被理解为编码器811对第一信息进行降维后得到的序列,或者,第一序列可以被理解为编码器811将第一信息压缩至隐空间后得到的序列。
177.应理解,第一序列是时序上的一维序列,且第一序列的长度由第一音频片段的长度确定。可以理解,第一音频片段越长,第一序列越长;第一音频片段越短,第一序列越短。
178.作为示例,第一序列可以表示为“{p1,p2,
…
,ps}”,其中,p表示特征向量,s表示特
征向量的个数。应理解,由于音频片段本身具有时序性,因此第一序列也具有时序性。这样的话,p1可以是音频片段始端时刻对应的特征向量,ps可以是音频片段末端时刻对应的特征向量。
179.类似的,终端设备可以将第二信息作为预设神经网络模型80的另一个输入(例如输入2)输入到编码器812中,这样,编码器812即可对接收到的第二信息进行处理后输出第二音频片段对应的第二序列。这里,第二序列的描述可以参考第一序列,不再赘述。
180.作为示例,第二序列可以表示为“{f1,f2,
…
,f
t
}”,其中,f表示特征向量,t表示特征向量的个数。其中,f1可以是音频片段始端时刻对应的特征向量,f
t
可以是音频片段末端时刻对应的特征向量。
181.接着,信息提取模块821接收编码器811输出的第一序列。由于音频片段本身具有时序性,且第一音频片段是前乐段,因此信息提取模块821对第一序列进行学习后,可以输出与第一音频片段的末端时刻对应的第一向量。该过程也可以理解为信息提取模块821对第一序列进一步进行了降维。需要说明,第一向量携带有第一序列的特征,且与第一序列的末端时刻对应。
182.类似的,信息提取模块822接收编码器812输出的第二序列。信息提取模块821对第二序列进行学习后,可以输出与第二音频片段的始端时刻对应的第二向量。该过程也可以理解为信息提取模块822对第二序列进一步进行了降维。需要说明,第二向量携带有第二序列的特征,且与第二序列的始端时刻对应。
183.然后,预设神经网络模型80对第一向量和第二向量求和,得到第三向量。即第三向量=第一向量 第二向量。这里,第一音频片段末端时刻对应的隐空间向量(即第一向量)和第二音频片段始端时刻对应的隐空间向量(即第二向量)的和(即第三向量),可以作为衔接第一音频片段和第二音频片段的过渡音频段对应的隐空间向量。
184.这样,基于该过渡向量,预设神经网络模型80可以确定出用于衔接第一音频片段和第二音频片段的过渡音频段。具体的,预设神经网络模型80将第三向量输入到信息生成网络模块83,信息生成网络模块83即可对接收到的第三向量进行学习,并输出第三序列。应理解,第三序列即为用于衔接第一音频片段和第二音频片段的过渡音频段的特征向量所构成的序列。
185.作为示例,第三序列可以表示为“{m1,m2,
…
mj}”,其中,m表示特征向量,j表示特征向量的个数。其中,m1可以是用于衔接第一音频片段和第二音频片段的过渡音频段的始端时刻对应的特征向量,mj可以是该过渡音频段的末端时刻对应的特征向量。
186.然后,解码器84接收到信息生成模块83输出的第三序列,并对第三序列进行学习,并输出用于衔接第一音频片段和第二音频片段的过渡音频信息,即过渡音频段的midi信息。
187.应理解,上述图8所示的预设神经网络模型80可以是预先基于多个训练样本训练得到的神经网络模型。其中,一个训练样本包括两个音频片段的midi信息和音频特征信息,该训练样本的标签值为领域专家根据该两个音频片段构建的过渡音频段的midi信息。这样,基于多个训练样本对神经网络进行反复的迭代训练,即可得到本技术实施例中图8所示的预设神经网络模型。
188.在s103,终端设备将在s102步骤生成的m-1个过渡音频信息(即过渡音频段的midi
信息)分别插入m个音频片段的midi信息中,以实现通过该m-1个过渡音频信息来衔接该m个音频片段的midi信息的目的,也即生成了该m个目标音频片段串烧后得到的目标串烧音频。
189.作为示例,假设m取值为3,m个音频片段包括音频片段1、音频片段2以及音频片段3,m-1个过渡音频信息包括过渡音频信息1和过渡音频信息2。则当该3个音频片段的串烧顺序为音频片段1
→
音频片段3
→
音频片段2,且过渡音频信息1是用于衔接音频片段1和音频片段3过渡音频信息,过渡音频信息2是用于衔接音频片段3和音频片段2过渡音频信息时,则终端设备可以将过渡音频信息1插入音频片段1和音频片段3的midi信息之间,以及可以将过渡音频信息2插入音频片段3和音频片段2的midi信息之间。这样,终端设备即生成了音频片段1、音频片段2以及音频片段3串烧后目标串烧音频的midi信息。
190.在实际应用中,终端设备在生成目标串烧音频的midi信息后,可以向用户播放该目标串烧音频。当用户认为该目标串烧音频不是自己想要的串烧音频时,用户可以向终端设备输入第二操作。这样,终端设备响应该第二操作,对用于串烧得到该目标串烧音频的m个音频片段的串烧顺序进行调整,并基于调整后的串烧顺序和m个音频片段,重新生成m-1个过渡音频信息,并重新生成目标串烧音频的midi信息。
191.然后,终端设备可以向用户播放重新生成的目标串烧音频。当用户对该目标串烧音频满意,则可以执行s104;当用户对该目标串烧音频不满意,则可以再次向终端设备输入第二操作,以使终端设备对m个音频片段的串烧顺序进行再次调整,并再次重新生成目标串烧音频的midi信息。可以看出,通过终端设备和用户之间的反复交互,可以获得令用户满意的目标串烧音频,提高了用户的体验。
192.在一种可能的实现方式中,终端设备在生成目标串烧音频的midi信息后,通过图谱的形式在显示面板上显示目标串烧音频的midi谱。这样,用户的第二操作即可以是对该midi谱的拖拽操作。这样,终端设备在接收到用户的第二操作后,可以响应该第二操作,以重新确定出用于串烧得到前述目标串烧音频的m个音频片段的串烧顺序。
193.这样的话,终端设备基于重新确定出的m个音频片段的串烧顺序,以及该m个音频片段,并通过执行s102,即可重新确定出m-1个过渡音频信息。进一步的,终端设备根据重新确定出的m-1个过渡音频信息和该m个音频片段,即可重新生成目标串烧音频。这里,终端设备重新生成目标串烧音频的过程,可以参考是上文中终端设备生成目标串烧音频的过程的详细描述,这里不作赘述。
194.作为示例,以终端设备是手机10,且手机10生成的目标串烧音频的midi信息中包括3个声轨,且目标串烧音频是对音频片段1、音频片段2以及音频片段3,以音频片段1
→
音频片段3
→
音频片段2的串烧顺序进行串烧后得到的串烧音频,参考图10中的(a),图10中的(a)示出了本技术实施例提供的一种第二操作的示意图。
195.如图10中的(a)所示,当手机10第一次生成目标串烧音频的midi信息后,可以在显示面板上显示该目标串烧音频的midi谱,例如图10中的(a)中所示的串烧音频剪辑界面1001上所显示的midi谱。
196.其中,串烧音频剪辑界面1001上显示的midi谱包括三个声轨,分别为黑色条带所示的声轨1、白色条带所示的声轨2、以及条纹条带所示的声轨3。
197.其中,串烧音频剪辑界面1001上显示的midi谱上的起始线用于标记目标串烧音频的起始。串烧音频剪辑界面1001上显示的midi谱上还包括多个分割线,该多个分割线用于
区分目标串烧音频中的不同音频片段以及过渡音频段。
198.例如,基于目标串烧音频中音频片段的串烧顺序,位于起始线和分割线1之间的音频段为音频片段1,位于分割线1和分割线2之间的音频段为衔接音频片段1和音频片段3的过渡音频段1,位于分割线2和分割线3之间的音频段为音频片段3,位于分割线3和分割线4之间的音频段为衔接音频片段3和音频片段2的过渡音频段2,位于分割4右侧的音频段为音频片段2(图10中的(a)中midi谱未示出用于标记目标串烧音频结束的终止线)。可以理解,在串烧音频剪辑界面1001上显示的midi谱上也可以显示各个音频段的名称,本技术实施例对此不作限定。
199.当用户可以对串烧音频剪辑界面1001上的播放图标1002进行操作(例如用手指或触摸笔点击)后,作为响应,手机10向用户播放目标串烧音频。当用户对该目标串烧音频不满意时,可以向手机10输入第二操作。这里,第二操作可以是用户对串烧音频剪辑界面1001上显示的midi谱进行拖拽的操作(例如通过手指或触摸笔在显示面板上滑动的操作),例如用户通过手指按住音频片段1的midi谱(即图10中的(a)所示midi谱中起始线和分割线1之间的区域),并沿着图10中的(a)中箭头所示方向滑动至音频片段2的midi谱(即图10中的(a)所示midi谱中分割线4右侧的区域)位置处。作为响应,手机10交换音频片段1和音频片段2的串烧顺序,即手机10重新确定出音频片段1、音频片段2以及音频片段3的串烧顺序为音频片段2
→
音频片段3
→
音频片段1。
200.进一步的,手机10可以根据音频片段1、音频片段2、音频片段3以及重新确定的串烧顺序,重新生成目标串烧音频。
201.在另一种实现方式中,第二操作可以是用户在终端设备生成目标串烧音频的midi信息后所显示的音频剪辑界面上,输入目标串烧顺序的操作。作为响应,终端设备即接收到用户输入的目标串烧顺序。也就是说,终端设备重新确定出m个音频片段的目标串烧顺序。
202.这样的话,终端设备基于接收到的m个音频片段的目标串烧顺序,以及该m个音频片段,并通过执行s102,即可重新确定出m-1个过渡音频信息。进一步的,终端设备根据重新确定出的m-1个过渡音频信息和该m个音频片段,即可重新生成目标串烧音频。
203.作为示例,以终端设备是手机10,且目标串烧音频是手机10对音频片段1、音频片段2以及音频片段3,以音频片段1
→
音频片段3
→
音频片段2的串烧顺序进行串烧后得到的串烧音频为例,参考图10中的(b),图10中的(b)示出了本技术实施例提供的另一种第二操作的示意图。
204.如图10中的(b)所示,当手机10第一次生成目标串烧音频的midi信息后,可以在显示面板上显示如图10中的(b)所示的串烧音频剪辑界面1001。当用户可以对串烧音频剪辑界面1001上的播放图标1002进行操作(例如用手指或触摸笔点击)后,作为响应,手机10可以播放该目标串烧音频。当用户对该目标串烧音频不满意时,可以向手机10输入第二操作。
205.具体的,用户可以在串烧音频剪辑界面1001上的目标串烧顺序的输入框1003内输入期望的目标串烧顺序,例如用户在输入框1003输入“2,3,1”,其中,“2”可以用于表示音频片段2的标识,“3”可以用于表示音频片段3的标识,“1”可以用于表示音频片段1的标识,“2,3,1”可以用于表示音频片段1、音频片段2以及音频片段3的串烧顺序为音频片段2
→
音频片段3
→
音频片段1。作为响应,手机10即接收到用户输入的目标串烧顺序。这样,手机10即确定出音频片段1、音频片段2以及音频片段3的目标串烧顺序。
group audio layer iii,mp3)格式的音频文件、音频压缩格式(oggvobis,ogg)的音频文件等,当然不限于此。
217.可选的,终端设备还可以保存生成目标串烧音频的工程。这样的话,终端可以根据所保存的工程文件重新设置用于串烧得到该目标串烧音频的m个音频片段的串烧顺序,并重新进行串烧处理,这样可以提高未来对该m个音频片段再次进行串烧时的效率。
218.作为示例,以终端设备是手机10为例,参考图11,图11示出了本技术实施例提供的一种对目标串烧音频的midi信息进行渲染以及输出的示意图。
219.如图11中的(a)所示,在手机10最终确定目标串烧音频的midi信息后,手机10可以显示音频渲染界面1101。用户可以在音频渲染界面1101上输入第三操作,该第三操作可以包括:用户在“音源分离”选项下选择开启“去除人声”(图11中的(a)“去除人声”标签的黑色方块表示开启,白色方框表示关闭)的选择操作,用户在“音频波形合成”选项下选择“加载音色库”的选择操作,用户在“混音”选项下选择“录制人声”的选择操作,以及用户在“人声风格迁移”选项下选择“歌星a”作为迁移目标的选择操作。
220.作为响应,手机10接收到用户的第三操作,以及接收到用户对音频渲染界面1101上的“确定”按钮的操作(例如点击)后,手机10可以将目标串烧音频的midi信息中的人声声轨删除或置为无效,并对目标串烧音频的midi信息加载音色库以合成目标串烧音频的时域波形,然后开启录音界面为目标串烧音频录制人声,以及将目标串烧音频中的人声迁移为歌星a的声音。
221.进一步的,手机10可以在接收到用户的第三操作,并接收到用户对音频渲染界面1101上的“确定”按钮的操作(例如点击)后,显示如图10中的(b)所显示的音频发布界面1102。这样,终端设备10可以通过音频发布界面1102与用户进行交互,并按照用户输入的指示导出目标串烧音频。
222.如图11中的(b)所示,手机10可以在音频发布界面1102的“导出格式”选项下接收用户输入的选择导出音频格式的选择操作,例如选择“音频格式1”的操作。手机10可以在音频发布界面1102的“导出路径”选项下接收用户输入的目标串烧音频的名称(如名称a)以及路径的操作。手机10还可以在音频发布界面1102的“保存工程”选项下接收用户输入的开启“保存工程”功能的操作。
223.这样,当用户对音频发布界面1102的“导出”按钮进行操作后(例如点击),作为响应,手机10即将目标串烧音频按照用户的指示进行保存。
224.在一些实施例中,本技术实施例所提供方法中确定过渡音频信息和生成目标音频的方法部分(即步骤s102-s104),也可以在终端设备向用户实时播放音频的过程中进行。这种情况下,本技术实施例所提供方法中确定过渡音频信息和生成目标音频的方法部分,可以通过能够提供音频聆听的app的一个功能模块实现。
225.作为示例,能够提供音频聆听的app例如可以是云音乐app。为简单叙述,下文中以能够提供音频聆听的app是云音乐app为例进行说明。
226.具体的,云音乐app在向用户提供音乐的聆听模式时,可以提供串烧模式。该串烧模式即可通过运行该云音乐app的终端设备、或者该云音乐app连接通信的服务器执行本技术实施例所提供方法中的步骤s102-s104来实现。为简单描述,下文中以通过运行该云音乐app的终端设备执行本技术实施例所提供方法中的步骤s102-s104来实现该串烧模式为例
进行说明。
227.这样的话,可选的,当终端设备向用户通过该终端设备中运行的云音乐app播放音乐时,终端设备所播放的音乐可以是云音乐媒体库自动推荐的音乐,也可以是本地媒体库中的音乐,本技术实施例对此不作限定。
228.这样,当终端设备通过与用户的交互,确定通过上述串烧模式向用户播放音乐时,终端设备可以将正在向用户播放的当前音乐和将要向用户播放的下一首音乐作为2个目标音频。并基于该2个目标音频和预设串烧顺序,并执行上文所述的s102-s104,以生成对该2个目标音频进行串烧后得到的第一目标串烧音频。其中,该预设串烧顺序为:终端设备正在向用户播放的当前音乐
→
终端设备将要向用户播放的下一首音乐。
229.这里应注意,当终端设备当前播放的音乐是云音乐媒体库自动推荐的音乐,则终端设备在向用户播放当前音乐的过程中,可以确定出为用户自动推荐的下一首音乐,该下一首音乐即为终端将要向用户播放的下一首音乐。
230.需要说明的是,在终端设备向用户播放完当前音乐之前,终端设备可以完成对确定出的2个目标音频的串烧并获得第一目标串烧音频。
231.可选的,终端设备可以在向用户播放完当前音乐后,为用户播放第一目标串烧音频。进一步的,终端设备在向用户播放完第一目标串烧音乐后,为用户播放原先的下一首音乐。
232.作为示例,如果终端设备正在向用户播放的当前音乐是音乐1,原先将要播放的下一首音乐为音乐2,则终端设备可以在向用户播放完音乐1后,向用户播放第一目标串烧音频。然后,终端设备在向用户播放完第一目标串烧音乐后,为用户播放音乐2。
233.类似的,当终端设备为用户播放原先的下一首音乐时,该原先的下一首音乐即变为终端设备正在向用户播放的新的当前音乐。这样,终端设备即可重复上述过程,生成对该新的当前音乐和该新的当前音乐的下一首音乐进行串烧后得到的第二目标串烧音频。并且,终端设备可以在向用户播放完该新的当前音乐后,为用户播放该第二串烧音频。
234.可以看出,在终端设备通过串烧模式向用户播放音乐时,终端设备可以动态的生成当前音乐和下一首音乐的串烧音频,并为用户播放该串烧音频,从而提高了用户体验。
235.还可以理解的是,在终端设备通过串烧模式向用户播放音乐时,终端设备为用户播放当前音乐和下一首音乐时,可以仅播放当前音乐和下一首音乐中用于生成串烧音频的音频片段,例如仅播放当前音乐和下一首音乐中的副歌/高潮部分,本技术实施例对此不作限定。
236.其中,还需说明的是,当终端设备基于确定出的2个目标音频和预设串烧顺序,执行上文所述步骤s102-s104以生成目标串烧音频(例如第一目标串烧音频、第二目标串烧音频、..、第q个目标串烧音频等,q是正整数)的过程中,在s103,终端设备只需执行一次生成过渡音频信息的过程,而无需接收用户输入的第二操作。
237.另外,云音乐app的串烧模式中预置有目标串烧音频的预设渲染模式和预设导出模式,该预设渲染模式中包括音源分离处理方式、混音处理方式,声音迁移方式等中的至少一种。该预设导出模式包括串烧音频的导出格式,以及指示是否保存目标串烧音频的工程等。因此,在s104,终端设备无需通过与用户进行交互来获取对目标串烧音频的渲染模式和导出模式。
238.应理解,云音乐app的串烧模式中所预置的目标串烧音频的预设渲染模式和预设导出模式,可以通过终端设备和用户的交互预先配置得到,也可以在终端设备向用户播放音乐的过程中,通过与用户的交互配置得到,这里不作限定。还应理解,在对目标串烧音频的预设渲染模式和预设导出模式配置完成后,终端设备还可以在向用户播放音乐的过程中,通过与用户的交互来更新该预先配置的预设渲染模式和预设导出模式,本技术实施例对此不作限定。
239.当然,上述预设导出模式中也可以不包括指示是否保存目标串烧音频的工程。这种情况下,终端设备可以在通过与用户进行交互后停止为用户播放音乐时,通过与用户进行交互,接收用户输入的是否保存目标串烧音频的工程的指示,并基于用户输入的指示执行对目标串烧音频的工程的保存。可以理解,在此之前,终端设备可以将动态生成的所有目标串烧音频的工程进行缓存。
240.还应理解,上述“串烧模式”的名称仅为示例性说明,并不作为对本技术实施例的限定。
241.综上,本技术实施例提供了一种音频数据的处理方法,通过该方法,本技术实施例可以在midi域基于m个音频片段,生成用于衔接该m个音频片段的m-1个过渡音频信息。这样,通过该m-1个过渡音频信息即可将m个音频片段的midi信息衔接起来,从而得到该m个音频片段被串烧后的目标串烧音频。可以看出,通过本技术方法对多个音频片段进行串烧时,终端设备可以生成全新的用于衔接该多个音频片段的过渡音频段,因此本技术实施例提供的方法无需考虑用于得到目标串烧音频的音频片段的相似度。也就是说,通过本技术实施例提供的方法能够获得更丰富、更具多样性的串烧音频。
242.并且,由于音频的midi信息是音频最原始的表现形式,其记录有音频的音符音高、音符力度、音符时长等信息。因此,相比在时域上直接对多个音频片段进行串烧,本技术实施例提供的方法中所生成的用于衔接两个音频片段的过渡音频信息是基于音频乐理生成的,这样的话,基于该过渡音频信息获得的串烧音频在听觉上更加流畅自然。并且,在midi域处理数据也更有利于串烧音频在后期渲染时的灵活性和一致性。
243.此外,通过本技术实施例提供的方法对m个音频片段进行串烧时,用户可以参与度高,这样即可以获得令用户满意的串烧音频,即用户体验度高。
244.上述主要从方法的角度对本技术实施例提供的方案进行了介绍。为了实现上述功能,其包含了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本技术能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
245.本技术实施例可以根据上述方法示例对音频数据的处理装置进行功能模块的划分,例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本技术实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
246.如图12所示,图12示出了本技术实施例提供的一种音频数据的处理装置120的结
构示意图。处理装置120可以用于执行上述的音频数据的处理方法,例如用于执行图3所示的方法。其中,处理装置120可以包括获取单元121、确定单元122以及生成单元123。
247.获取单元121,用于获取m个音频片段。确定单元122,用于根据该m个音频片段确定m-1个过渡音频信息。生成单元123,用于根据该m个音频片段和该m-1个过渡音频信息,生成目标串烧音频。其中,该m-1个过渡音频信息用于衔接该m个音频片段。对于该m-1个过渡音频信息中的第一过渡音频信息而言,该第一过渡音频信息用于衔接m个音频片段中排序连续的第一音频片段和第二音频片段。这里,m个音频片段的排序是指m个音频片段的串烧顺序。
248.作为示例,结合图3,获取单元121可以用于执行s101,确定单元122以用于执行s102,生成单元123可以用于执行s103-s104。
249.可选的,确定单元122,具体用于根据第一音频片段的第一信息和第二音频片段的第二信息,确定第一过渡音频信息。其中,该第一信息包括第一音频片段的midi信息和音频特征信息,该第二信息包括第二音频片段的midi信息和音频特征信息,该第一过渡音频信息包括第一过渡音频信息对应的第一过渡音频的midi信息。
250.作为示例,结合图3,确定单元122可以用于执行s102。
251.可选的,上述的音频特征信息包括音频片段的主旋律轨位置信息、风格标签、情感标签、节奏信息、节拍信息、或调号信息中的至少一种。
252.可选的,确定单元122,具体用于根据第一音频片段的第一信息、第二音频片段的第二信息以及预设神经网络模型,确定第一过渡音频信息。
253.作为示例,结合图3,确定单元122可以用于执行s102。
254.可选的,当在目标串烧音频中,第一音频片段位于第二音频片段之前,则:上述第一过渡音频信息是基于用于表征第一过渡音频信息的特征向量确定的,该第一过渡音频信息的特征向量是基于第一向量和第二向量确定的。其中,该第一向量是根据第一信息在第一音频片段的时序末端生成的特征向量,该第二向量是根据第二信息在第二音频片段的时序始端生成的特征向量。
255.可选的,确定单元122,还用于响应于用户的第一操作,确定k个目标音频。获取单元121,具体用于从该k个目标音频中提取m个音频片段。其中,2≤k≤m,且k是整数。
256.作为示例,结合图3,确定单元122和获取单元121可以用于执行s101,
257.可选的,确定单元122,还用于在根据m个音频片段确定m-1个过渡音频信息之前,确定该m个音频片段的串烧顺序。
258.可选的,确定单元122还用于响应于用户的第二操作,重新确定m个音频片段的串烧顺序。确定单元122还用于根据重新确定的串烧顺序和m个音频片段,重新确定m-1个过渡音频信息.生成单元123,还用于根据重新确定的m-1个过渡音频信息和m个音频片段,重新生成目标串烧音频。
259.可选的,处理装置120还包括:渲染单元124,用于响应于用户的第三操作,对上述的目标串烧音频进行渲染。
260.作为示例,结合图3,渲染单元124可以用于执行s104。
261.可选的,处理装置120还包括:输出单元125,用于输出上述的目标串烧音频。
262.关于上述可选方式的具体描述可以参见前述的方法实施例,此处不再赘述。此外,
上述提供的任一种处理装置120的解释以及有益效果的描述均可参考上述对应的方法实施例,不再赘述。
263.作为示例,结合图1,处理装置120中的获取单元121和输出单元125,可以通过图1中的触摸屏150和处理器110实现其功能。确定单元122、生成单元123、渲染单元124可以通过图1中的处理110执行图1中的内部存储器120中的程序代码实现。
264.图13示出本技术实施例提供的用于承载计算机程序产品的信号承载介质的结构示意图,该信号承载介质用于存储计算机程序产品或用于存储计算设备上执行计算机进程的计算机程序。
265.如图13所示,信号承载介质130可以包括一个或多个程序指令,其当被一个或多个处理器运行时可以提供以上针对图3描述的功能或者部分功能。因此,例如,参考图3中s101~s104的一个或多个特征可以由与信号承载介质130相关联的一个或多个指令来承担。此外,图13中的程序指令也描述示例指令。
266.在一些示例中,信号承载介质130可以包含计算机可读介质131,诸如但不限于,硬盘驱动器、紧密盘(cd)、数字视频光盘(dvd)、数字磁带、存储器、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random access memory,ram)等等。
267.在一些实施方式中,信号承载介质130可以包含计算机可记录介质132,诸如但不限于,存储器、读/写(r/w)cd、r/w dvd、等等。
268.在一些实施方式中,信号承载介质130可以包含通信介质133,诸如但不限于,数字和/或模拟通信介质(例如,光纤电缆、波导、有线通信链路、无线通信链路、等等)。
269.信号承载介质130可以由无线形式的通信介质133(例如,遵守ieee 1902.11标准或者其它传输协议的无线通信介质)来传达。一个或多个程序指令可以是,例如,计算机可执行指令或者逻辑实施指令。
270.在一些示例中,诸如针对图3描述的音频数据的处理装置可以被配置为,响应于通过计算机可读介质131、计算机可记录介质132、和/或通信介质133中的一个或多个程序指令,提供各种操作、功能、或者动作。
271.应该理解,这里描述的布置仅仅是用于示例的目的。因而,本领域技术人员将理解,其它布置和其它元素(例如,机器、接口、功能、顺序、和功能组等等)能够被取而代之地使用,并且一些元素可以根据所期望的结果而一并省略。另外,所描述的元素中的许多是可以被实现为离散的或者分布式的组件的、或者以任何适当的组合和位置来结合其它组件实施的功能实体。
272.在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件程序实现时,可以全部或部分地以计算机程序产品的形式来实现。该计算机程序产品包括一个或多个计算机指令。在计算机上和执行计算机执行指令时,全部或部分地产生按照本技术实施例的流程或功能。计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,计算机指令可以从一个网站站点、计算机、服务器或者数据中心通过有线(例如同轴电缆、光纤、数字用户线(digital subscriber line,dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。计算机可读存储介质可以是计算机能够存取的任何可用介质
或者是包含一个或多个可以用介质集成的服务器、数据中心等数据存储设备。可用介质可以是磁性介质(例如,软盘、硬盘、磁带),光介质(例如,dvd)、或者半导体介质(例如固态硬盘(solid state disk,ssd))等。
273.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。