1.本技术涉及监测技术领域,尤其涉及一种行为监测方法、装置、电子设备及存储介质。
背景技术:
2.在养殖业中,猪只的健康状况、繁殖效率等是衡量养殖场养殖技术的重要指标,尤其是猪只的健康状况,一旦猪群中爆发流行性疾病,养殖场的收益会被严重影响,甚至会造成不可估量的经济损失。随着科技的发展,利用远程监控监听猪只的发声行为,进而实现对猪只健康状况的监测成为目前研究的难点与重点。
3.相关技术中,对猪只进行健康监测的方式主要有以下三种:
4.1、人工巡查。观察人员在猪栏进行猪只健康状况的巡查,关注猪只的异常发声行为,如果发现存在异常发声行为的猪只,标记该猪只并记录该猪只的信息。这种方式虽然检查全面完整并且可靠,但弊端在于耗费时间人力,且依赖观察人员的经验,仅适用于小规模的养殖场景,对大规模高效化管理的养殖场景并不适用。
5.2、利用包络模板与猪只的声音进行匹配,识别出异常发声行为的猪只。具体地,预先采集各种猪只的异常声音,建立各种异常声音的包络模板,再采集待监测的猪只的声音数据,将猪只的声音数据与包络模板进行匹配判断猪只是否存在异常发声行为。这种方式的弊端是,一些近似异常声音但实则不是的声音也会与包络模板进行匹配,使得监测准确率低,并且无法同时针对多个猪只进行异常发声行为的监测。
6.3、利用音频设备采集猪只音频数据,采用机器学习、深度学习的方式对猪群异常声音进行监测与分类。具体地,采集猪群的音频数据,人工区分咳嗽与非咳嗽的音频数据,将从猪群音频数据中提取出的梅尔频率倒谱(mfcc,mel frequency cepstral coefficients)或语谱图等音频特征作为异常声音分类模型的数据输入,利用机器学习或深度学习的方式,如动态时间规整(dtw)、矢量量化(vq)、模糊c均值聚类(fcm)、隐马尔科夫算法(hmm)、人工神经网络(ann)算法、卷积神经网络这些方式训练异常声音分类模型,通过异常声音分类模型实现对猪群的异常声音的分类。将采集的猪群的音频数据输入异常声音分类模型中,若异常声音分类模型判定该音频数据中存在异常声音,结合异常猪群位置通过人工找出猪群中的存在异常发声行为的猪只。这种方式通常是采集猪群的音频数据,最终只能判断出猪群中存在异常发声行为的猪只,并不能精确定位至存在异常发声行为的目标猪只,所以往往需要利用人力找出目标猪只,使得确定目标猪只的效率低下。其次,一般采用mfcc、功率谱密度(psd,power spectral density)、线性预测倒谱系数(lpcc,linear predictive cepstral coefficient)等音频特征作为异常声音分类模型的输入数据,这样训练出的模型对猪只咳嗽、尖叫、啃咬金属等异常声音区分度不高,导致分类精度差。并且,仅利用猪只的音频数据进行异常声音分类模型的训练,难以准确判断出猪只的异常发声行为。
7.也就是说,相关技术中,对存在异常发声行为的猪只的确定还存在确定准确率低、
确定效率低的技术问题。
技术实现要素:
8.有鉴于此,本技术实施例的主要目的在于提供一种行为监测方法、装置、电子设备及存储介质,以解决相关技术中对存在异常行为的猪只的确定准确率低和确定效率低的问题。
9.为达到上述目的,本技术实施例的技术方案是这样实现的:
10.本技术实施例提供了一种行为监测方法,所述方法包括:
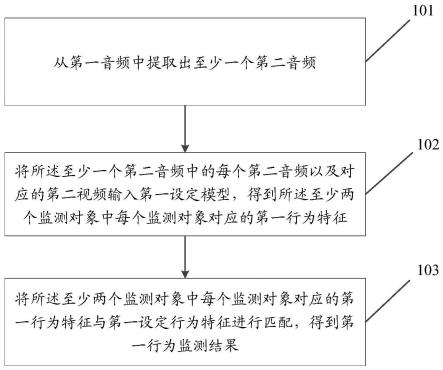
11.从第一音频中提取出至少一个第二音频;所述第一音频表征由至少两个监测对象发出的声音;所述至少一个第二音频中的每个第二音频对应表征所述至少两个监测对象中的一个监测对象发出的声音;
12.将所述至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到所述至少两个监测对象中每个监测对象对应的第一行为特征;
13.将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,
14.所述第二视频表征拍摄有对应的监测对象的视频。
15.上述方案中,所述将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,包括:
16.在第一行为特征满足以下条件至少之一的情况下,确定第一行为特征与第一设定行为特征匹配:
17.第一语谱图中存在幅值大于设定阈值的语音信号;其中,第一语谱图为第一行为特征对应的监测对象对应的第二音频的语谱图;
18.基于第一行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生设定行为。
19.上述方案中,所述方法还包括:
20.在所述第一行为监测结果表征存在监测对象对应的第一行为特征与所述第一设定行为特征匹配的情况下,将对应的第二音频以及对应的第二视频输入第二设定模型,得到对应的监测对象对应的第二行为特征;
21.将得到的第二行为特征与第二设定行为特征进行匹配,得到关于对应的监测对象的第二行为监测结果;其中,
22.所述第二设定行为特征表征对应的监测对象行为异常。
23.上述方案中,所述将得到的第二行为特征与第二设定行为特征进行匹配,包括:
24.在得到的第二行为特征满足以下至少一个条件的情况下,确定第二行为特征与第二设定行为特征匹配:
25.第二语谱图中幅值大于设定阈值的语音信号出现的时间间隔小于设定时间间隔;其中,第二语谱图为第二行为特征对应的监测对象对应的第二音频的语谱图;
26.第二语谱图中幅值大于设定阈值的语音信号持续的时长大于设定时长。
27.上述方案中,所述方法还包括:
28.在第二行为监测结果表征第二行为特征与所述第二设定行为特征匹配的情况下,
基于第二行为特征对应的监测对象的第二音频的音频编码,确定所述第二行为特征对应的监测对象。
29.上述方案中,在从第一音频中提取出至少一个第二音频之后,所述方法还包括:
30.基于第二音频的音频编码确定出所述第二音频对应的监测对象;
31.获取所述监测对象对应的第二视频。
32.上述方案中,在所述从第一音频中提取出至少一个第二音频之前,所述方法还包括:
33.将每个监测对象发出的声音分别输入设定语音编码器,得到每个监测对象发出的声音的音频编码;
34.存储所述每个监测对象与发出的声音的音频编码之间的对应关系。
35.本技术实施例还提供了一种模型训练方法,所述方法用于训练上述任意一项行为监测方法中的第一设定模型,所述方法包括:
36.获取监测对象的音频样本和视频样本;所述音频样本表征所述监测对象发出的声音;所述视频样本表征与所述音频样本同时采集的拍摄有所述监测对象的视频;
37.将所述音频样本对应的音频特征以及所述视频样本输入第一设定模型,得到第一输出结果;所述第一输出结果表征所述监测对象对应的第一行为特征;
38.基于所述第一输出结果计算损失值,并基于所述损失值更新第一设定模型的权重参数;其中,
39.所述音频样本对应的音频特征包括互相关系数矩阵特征,所述互相关系数矩阵特征表征所述音频样本对应的语谱图中相邻两帧之间的相关系数。
40.上述方案中,所述音频样本对应的音频特征还包括以下至少之一:
41.所述音频样本对应的语谱图;
42.所述音频样本对应的梅尔频率倒谱特征;
43.所述音频样本对应的一阶差分特征;
44.所述音频样本对应的二阶差分特征。
45.本技术实施例还提供了一种行为监测装置,所述装置包括:
46.提取单元,用于从第一音频中提取出至少一个第二音频;所述第一音频表征由至少两个监测对象发出的声音;所述至少一个第二音频中的每个第二音频对应表征所述至少两个监测对象中的一个监测对象发出的声音;
47.输入单元,用于将所述至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到所述至少两个监测对象中每个监测对象对应的第一行为特征;
48.匹配单元,用于将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,
49.所述第二视频表征拍摄有对应的监测对象的视频。
50.本技术实施例还提供了一种模型训练装置,所述装置包括:
51.获取单元,用于获取监测对象的音频样本和视频样本;所述音频样本表征所述监测对象发出的声音;所述视频样本表征与所述音频样本同时采集的拍摄有所述监测对象的视频;
52.输入单元,用于将所述音频样本对应的音频特征以及所述视频样本输入第一设定
模型,得到第一输出结果;所述第一输出结果表征所述监测对象对应的第一行为特征;
53.计算单元,用于基于所述第一输出结果计算损失值,并基于所述损失值更新第一设定模型的权重参数;其中,
54.所述音频样本对应的音频特征包括互相关系数矩阵特征,所述互相关系数矩阵特征表征所述音频样本对应的语谱图中相邻两帧之间的相关系数。
55.本技术实施例还提供了一种电子设备,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,其中,
56.所述处理器用于运行所述计算机程序时,执行上述任一方法的步骤。
57.本技术实施例还提供了一种存储介质,其上存有计算机程序,所述计算机程序被处理器执行时实现上述任一方法的步骤。
58.在本技术实施例中,从第一音频中提取出至少一个第二音频,其中,第一音频表征由至少两个监测对象发出的声音,至少一个第二音频中的每个第二音频表征所述至少两个监测对象中的一个监测对象发出的声音;将至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到至少两个监测对象中每个监测对象对应的第一行为特征;将至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,第二视频表征拍摄有对应的监测对象的视频,如此,可以从多个监测对象的声音组成的混合音频中提取出每个监测对象的单独音频,并结合每个监测对象对应的视频共同进行行为监测,通过这种多模态的方式提高了行为监测的准确性,并且由于可以从混合音频中提取出单个监测对象的音频进行行为监测,在监测到监测对象存在异常行为时,可以精准快速地定位出存在异常行为的监测对象,从而提高了对行为监测对象进行定位的效率。
附图说明
59.图1为本技术实施例提供的行为监测方法的实现流程示意图;
60.图2为本技术实施例提供的语音分离模型的训练过程示意图;
61.图3为本技术实施例提供的语谱图的示意图;
62.图4为本技术实施例提供的第二设定模型进行行为监测的示意图;
63.图5为本技术应用实施例提供的行为监测方法的实现流程示意图;
64.图6为本技术实施例提供的模型训练方法的实现流程示意图;
65.图7为本技术实施例提供的音频数据处理的示意图;
66.图8为本技术实施例提供的提取视频样本特征进行训练的示意图;
67.图9为本技术实施例提供的提取音频样本的音频特征进行训练的示意图;
68.图10为本技术实施例提供的行为监测装置的示意图;
69.图11为本技术实施例提供的模型训练装置的示意图;
70.图12为本技术实施例电子设备的硬件组成结构示意图。
具体实施方式
71.相关技术中,对存在异常发声行为的猪只的确定还存在确定准确率低、确定效率低的技术问题。
72.基于此,本技术实施例提供了一种行为监测方法、装置、电子设备及存储介质,从第一音频中提取出至少一个第二音频,其中,第一音频表征由至少两个监测对象发出的声音,至少一个第二音频中的每个第二音频表征所述至少两个监测对象中的一个监测对象发出的声音;将至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到至少两个监测对象中每个监测对象对应的第一行为特征;将至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,第二视频表征拍摄有对应的监测对象的视频,如此,可以从多个监测对象的声音组成的混合音频中提取出每个监测对象的单独音频,并结合每个监测对象对应的视频共同进行行为监测,通过这种多模态的方式提高了行为监测的准确性,并且由于可以从混合音频中提取出单个监测对象的音频进行行为监测,在监测到监测对象存在异常行为时,可以精准快速地定位出存在异常行为的监测对象,从而提高了对行为监测对象进行定位的效率。
73.下面结合附图及实施例对本技术再作进一步详细的描述。为了方便理解,本技术实施例以监测对象为猪只为例对本技术提供的行为监测方法进行详细阐述。
74.图1为本技术实施例提供的行为监测方法的实现流程示意图。如图1所示,所述方法包括:
75.步骤101:从第一音频中提取出至少一个第二音频;所述第一音频表征由至少两个监测对象发出的声音;所述至少一个第二音频中的每个第二音频对应表征所述至少两个监测对象中的一个监测对象发出的声音。
76.这里,为了进行更准确的行为监测,首先从第一音频中提取出至少一个第二音频,其中,第一音频表征由至少两个监测对象发出的声音,每个第二音频表征一个监测对象发出的声音。在监测对象为猪只时,第一音频表征由多个猪只发出的声音构成的混合音频,第二音频表征由多个猪只中的任意一个猪只发出的声音。通过从混合音频中提取出单个猪只的音频,可以排除其他猪只的音频造成的干扰,便于对每个单个猪只进行行为监测。
77.实际应用中,可以通过语音分离模型从第一音频中提取出至少一个第二音频。语音分离模型包括音频编码器和音频过滤器两部分。
78.针对音频编码器,在数据采集阶段,为了提高模型训练的精度,会分别采集每个猪只的音频,具体是将猪只单独置于猪栏中,分别采集每个猪只的音频。提取采集到的每个猪只的音频的对数梅尔倒谱能量特征,将每个猪只的音频对应的对数梅尔倒谱能量特征输入到三层长短期记忆模型(lstm,long short term memory)中,得到每个猪只对应的音频向量pig-vector,维度为256维。其中,音频向量表征每个猪只的音色,可以唯一标识猪只。
79.针对音频过滤器,将采集到的多个猪只发出的声音构成的混合音频作为语音分离模型的输入,结合每个猪只对应的pig-vector,以pig-vector对应的猪只的音频作为标签,训练一个时域频域的过滤网络,即:输入的是单个猪只的pig-vector以及多个猪只发出的声音构成的混合音频,在训练结束后,该过滤网络会剔除其余猪只的干扰音频,输出pig-vector对应的单个猪只的音频。
80.为了便于理解,将语音分离模型分离出的音频作为目标猪只的音频。
81.图2为本技术实施例提供的语音分离模型的训练过程示意图,如图2所示:
82.首先,将目标猪只的音频输入三层lstm模型中,得到目标猪只对应的pig-vector。
83.对多个猪只发出的声音构成的带噪混合音频进行短时傅里叶变换(sift,short-time fourier transform),得到该带噪混合音频对应的语谱图。将该语谱图的幅值频谱以及目标猪只的pig-vector输入过滤网络,过滤网络输出软遮罩(soft mask)特征。
84.将soft mask特征与带噪混合音频对应的语谱图相乘,得到增强过的幅值频谱。将带噪混合音频对应的语谱图的原始的幅值频谱与增强过的幅值频谱进行合并,得到频谱图掩码。
85.对频谱图掩码进行逆sift变换,得到增强过的音频。
86.对采集到的目标猪只的音频进行去噪处理,得到目标猪只去噪后的纯净音频,对该目标猪只的纯净音频进行sift变换,得到对应的语谱图,通过计算频谱图掩码和目标猪只的纯净音频对应的语谱图的幅值频谱之间的差值计算损失值,基于损失值实现对语音分离模型参数的更新。
87.示例性地,过滤网络由8个卷积层(cnn)、1个lstm层、2个全连接层(fc)组成,除了最后一层,其余层的激活函数均为线性整流函数(relu,rectified linear unit),最后一层的激活函数为sigmoid函数。在每一层,重复地将目标猪只的pig-vector和上一层卷积层的输出拼接起来,将拼接得到的值再作为后面一层的输入。其中,各层的详细参数如表1所示:
[0088][0089]
表1
[0090]
其中,width表示宽度函数,dilation表示膨胀函数,time表示时域方面的取值,freq表示频域方面的取值,filters/nodes表示过滤器。
[0091]
步骤102:将所述至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到所述至少两个监测对象中每个监测对象对应的第一行为特征;其中,所述第二视频表征拍摄有对应的监测对象的视频。
[0092]
这里,从第一音频中提取出至少一个第二音频后,将每个第二音频以及对应的第二视频输入第一设定模型,第二视频表征拍摄有对应的检测对象的视频。示例性地,第二音频表征是猪只1发出的声音,那么第二视频表征拍摄有猪只1的视频。
[0093]
需要说明的是,第二音频的采集时间点与第二视频的采集时间点相同。在实际应
用中,可以通过终端拍摄视频的方式获取多个猪只的视频流信息,从该视频流信息中提取出多个猪只对应的音频和对应的视频。
[0094]
将第二音频与对应的第二视频输入第一设定模型后,得到对应的监测对象对应的第一行为特征。
[0095]
在监测对象为猪只时,第一设定模型可用于识别猪只是否存在咳嗽行为特征。
[0096]
步骤103:将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果。
[0097]
这里,获得每个监测对象的第一行为特征后,将每个监测对象的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果。
[0098]
实际应用中,第一设定行为特征表征猪只的咳嗽行为特征。第一行为监测结果可表征第一行为特征对应的猪只是否出现咳嗽行为特征。
[0099]
在一实施例中,所述将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,包括:
[0100]
在第一行为特征满足以下条件至少之一的情况下,确定第一行为特征与第一设定行为特征匹配:
[0101]
第一语谱图中存在幅值大于设定阈值的语音信号;其中,第一语谱图为第一行为特征对应的监测对象对应的第二音频的语谱图;
[0102]
基于第一行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生设定行为。
[0103]
这里,第一设定行为特征表征监测对象的咳嗽行为特征,咳嗽是由于腹肌收缩以产生声门下压力,通过声门多次突然开启实现声道中强烈的气流冲击并伴有典型的声音的过程。猪只咳嗽时对应的音频的语谱图中语音信号的变化幅值与正常发声时对应的音频的语谱图中的语音信号的变化幅值之间差异较大,猪只正常发声时,音频对应的语谱图中的语音信号的幅值较小,猪只咳嗽时,音频对应的语谱图中的语音信号的幅值较大,因此,可以通过语谱图中语音信号的幅值来判断是否出现咳嗽行为。具体地,如果语谱图中存在幅值大于设定阈值的语音信号,则认为第二音频对应的猪只出现了咳嗽行为特征。其中,设定阈值表征正常发声时的音频对应的语音信号的幅值。
[0104]
图3为本技术实施例提供的语谱图的示意图,如图3所示:
[0105]
在图a中,时间段i的语音信号的幅值显著大于时间段ii的语音信号的幅值,如果将设定阈值设置为0.05,则时间段i内语音信号的幅值在0.1附近,大于设定阈值的0.05,因此,说明时间段i内出现了咳嗽行为,即:在时间段i内第一行为特征与第一设定行为特征匹配。而时间段ii内语音信号的幅值小于0.05,说明时间段ii内并没有出现咳嗽行为,在时间段ii内第一行为特征与第一设定行为特征不匹配。
[0106]
在图b中,如果将设定阈值设置为0.1,则时间段i与时间段iii内的语音信号的幅值都显著大于设定阈值0.1,因此,说明时间段i与时间段iii内出现了咳嗽行为,也就是在时间段i与时间段iii内,第一行为特征与第一设定行为特征匹配。而时间段ii内语音信号的幅值小于0.1,说明时间段ii内并没有出现咳嗽行为,在时间段ii内第一行为特征与第一设定行为特征不匹配。
[0107]
猪只在咳嗽时,通常会伴随着典型的咳嗽行为,如身体抖动、背部拱起、后肢抖动,
因此,可以基于第一行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生设定行为来判断第一行为特征与第一设定行为特征匹配。所述设定行为可以为身体抖动、背部拱起、后肢抖动。如果基于第一行为特征对应的监测对象的第二视频,判断出对应的监测对象发生了设定行为,则第一行为特征与第一设定行为特征匹配。
[0108]
实际应用中,获取第二音频对应的第二视频后,首先将第二视频进行分帧处理,提取有效图片。通常采用opencv算法对第二视频逐帧提取特征。对第二视频分离出的每帧图片采用cnn提取表观特征之后,采用lstm学习时序特征,从而实现第二视频的向量输出。在提取有效图片时,主要提取出现猪只咳嗽时伴随的身体抖动、背部拱起、后肢抖动等行为的图片作为有效图片。
[0109]
通过进行这两种方式的判断,可以结合音频特征与视频特征判断出对应的监测对象的第一行为特征是否与第一设定行为特征匹配,提高了判断结果的准确性。
[0110]
在一实施例中,所述方法还包括:
[0111]
在所述第一行为监测结果表征存在监测对象对应的第一行为特征与所述第一设定行为特征匹配的情况下,将对应的第二音频以及对应的第二视频输入第二设定模型,得到对应的监测对象对应的第二行为特征;
[0112]
将得到的第二行为特征与第二设定行为特征进行匹配,得到关于对应的监测对象的第二行为监测结果;其中,
[0113]
所述第二设定行为特征表征对应的监测对象行为异常。
[0114]
这里,如果第一行为监测结果表征存在监测对象对应的第一行为特征与第一设定行为特征匹配,说明经过第一设定模型的判断,得出对应的猪只存在咳嗽的行为,而猪只的咳嗽可能是由于喝水呛到或者戏耍时呛到等行为引起,不一定是由于患病引起的咳嗽行为,所以为了进一步判断猪只的咳嗽行为是否由于患病引起的,将对应的第二音频以及对应的第二视频输入第二设定模型,得到对应的监测对象的第二行为特征。第二设定模型用于基于监测对象的语音特征与视频特征来判断监测对象是否存在第二设定行为特征。第二设定行为特征表征对应的监测对象行为异常。实际应用中,第二设定行为特征表征监测对象的患病行为特征。
[0115]
第二设定模型的输出结果为监测对象对应的第二行为特征,得到第二行为特征后,将第二行为特征与第二设定行为特征进行匹配,得到对应的监测对象的第二行为监测结果。
[0116]
通过在第一行为监测结果表征匹配的情况下,将第二音频与对应的第二视频输入第二设定模型中,将第二行为特征与第二设定行为特征进行匹配得到第二行为监测结果,可以更进一步地判断对应的监测对象是否存在第二设定行为特征,从而提高了对监测对象的行为监测的准确性。
[0117]
在一实施例中,所述将得到的第二行为特征与第二设定行为特征进行匹配,包括:
[0118]
在得到的第二行为特征满足以下至少一个条件的情况下,确定第二行为特征与第二设定行为特征匹配:
[0119]
第二语谱图中幅值大于设定阈值的语音信号出现的时间间隔小于设定时间间隔;其中,第二语谱图为第二行为特征对应的监测对象对应的第二音频的语谱图;
[0120]
第二语谱图中幅值大于设定阈值的语音信号持续的时长大于设定时长。
[0121]
这里,如果得到的第二行为特征满足以下至少一个条件,则确定第二行为特征与第二设定行为特征匹配,具体地,第二语谱图中幅值大于设定阈值的语音信号出现的时间间隔小于设定时间间隔;和/或,第二语谱图中幅值大于设定阈值的语音信号持续的时长大于设定时长。其中,第二语谱图为第二行为特征对应的监测对象对应的第二音频的语谱图。
[0122]
由于猪只正常发声时的音频对应的语谱图中语音信号的幅值变化幅度较小,而猪只咳嗽时的音频对应的语谱图中语音信号的幅值变化幅度较大,因此,通过语谱图中幅值大于设定阈值的语音信号可认为猪只出现了咳嗽行为特征。存在患病行为特征的猪只一般会在短时间内连续咳嗽,单次咳嗽的时长也较长,因此,如果第二语谱图中幅值大于设定阈值的语音信号出现的时间间隔小于设定的时间间隔,说明猪只的咳嗽行为特征出现得较为频繁,说明猪只存在患病行为特征,因此在这种情况下,第二行为特征与第二设定行为特征匹配。如果第二语谱图中幅值大于设定阈值的语音信号持续的时长大于设定时长,说明猪只的单次咳嗽时间较长,说明猪只存在患病行为特征,因此在这种情况下,第二行为特征与第二设定行为特征匹配。
[0123]
通过对幅值大于设定阈值的语音信号出现的时间间隔与出现时长的判断,来判断第二行为特征是否与第二设定行为特征匹配,可以提高得出的判断结果的准确性。
[0124]
在一实施例中,所述将得到的第二行为特征与第二设定行为特征进行匹配,还包括:
[0125]
基于第二行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生第一设定行为,确定所述第二行为特征与第二设定行为特征匹配。
[0126]
这里,存在患病行为特征的猪只在咳嗽时,会伴随着典型的行为,如张口喘气、口鼻流沫、犬坐式、腹式呼吸等特定行为,因此,可以基于第二行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生第一设定行为来判断第二行为特征与第二设定行为特征匹配。所述第一设定行为可以为张口喘气、口鼻流沫、犬坐式、腹式呼吸中的一种或多种。如果基于第二行为特征对应的监测对象的第二视频,判断出对应的监测对象发生了第一设定行为,则第二行为特征与第二设定行为特征匹配。
[0127]
需要说明的是,本技术实施例中第二设定模型中对第二视频的特征提取与前文中第一设定模型中对第二视频的特征提取的过程是相同的,区别在于两者提取的图像特征不同。
[0128]
由于在正常的生活场景中存在喝水、戏耍呛到从而咳嗽的情况,因此在利用opencv进行视频中分帧图片的特征提取时,也提取由于喝水、戏耍呛到从而咳嗽的行为,如此,可以更好地与患病行为特征引起的咳嗽行为进行区分。
[0129]
通过利用第二视频中是否发生第一设定行为来确定第二行为特征是否与第二设定行为特征匹配,可以从视频角度进一步精确确定监测对象的行为监测结果。
[0130]
图4为本技术实施例提供的第二设定模型进行行为监测的示意图,如图4所示:
[0131]
将猪只的视频进行分帧处理,通过cnn和lstm提取每一帧图像中的特征,得出视频输出结果。提取音频中的咳嗽时间间隔特征和单次咳嗽时长特征,通过两层fc层得出语音输出结果。将视频输出结果与语音输出结果拼接起来,通过两层fc层,一层softmax层,得出最终的行为监测结果,判断出猪只是否存在患病行为特征。
[0132]
在一实施例中,所述方法还包括:
[0133]
在第二行为监测结果表征第二行为特征与所述第二设定行为特征匹配的情况下,基于第二行为特征对应的监测对象的第二音频的音频编码,确定所述第二行为特征对应的监测对象。
[0134]
这里,如果第二行为特征与第二设定行为特征匹配,由于第二设定行为表征异常行为特征,说明第二行为特征对应的监测对象存在异常行为特征,此时,需要确定存在异常行为特征的监测对象。具体地,基于第二行为特征对应的监测对象的第二音频的音频编码,确定所述监测对象。由于每个监测对象都对应着一个唯一的音频编码,音频编码可以唯一标识监测对象,即,音频编码与监测对象之间是一一对应的关系,那么在确定第二音频的音频编码时,根据音频编码与监测对象之间的对应关系,可以确定出所述音频编码对应的监测对象。
[0135]
通过在第二行为监测结果表征存在异常行为特征的情况下,基于第二行为特征对应的监测对象对应的第二音频的音频编码,确定出对应的监测对象,可以基于第二音频的音频编码准确确定出存在异常行为特征的监测对象,从而实现对存在异常行为特征的监测对象的准确定位,提高了找出存在异常行为特征的监测对象的效率。
[0136]
在一实施例中,在从第一音频中提取出至少一个第二音频之后,所述方法还包括:
[0137]
基于第二音频的音频编码确定出所述第二音频对应的监测对象;
[0138]
获取所述监测对象对应的第二视频。
[0139]
这里,在从第一音频中提取出至少一个第二音频之后,所述行为监测方法还包括基于第二音频的音频编码确定出第二音频对应的监测对象,由于第二音频的音频编码可以唯一标识对应的监测对象,因此,基于第二音频的音频编码可以确定出第二音频对应的监测对象。确定出监测对象之后,获取该监测对象对应的第二视频。其中,第二视频与第二音频的采集时间点相同。
[0140]
通过在提取出第二音频之后,基于第二音频的音频编码确定出对应的第二视频,便于基于同一个监测对象的音频和视频对所述监测对象的行为进行监测,提高了行为监测的准确性。
[0141]
在一实施例中,在所述从第一音频中提取出至少一个第二音频之前,所述方法还包括:
[0142]
将每个监测对象发出的声音分别输入设定语音编码器,得到每个监测对象发出的声音的音频编码;
[0143]
存储所述每个监测对象与发出的声音的音频编码之间的对应关系。
[0144]
这里,为了提高语音分离模型训练的精度,会单独采集每个监测对象的发出的声音,为了更好地基于监测对象发出的声音定位到具体的监测对象,将每个监测对象发出的声音分别输入设定语音编码器,得到每个监测对象发出的声音的音频编码。实际应用中,所述设定语音编码器可以是三层的lstm模型。
[0145]
获得每个监测对象发出的声音的音频编码后,存储每个监测对象与发出的声音的音频编码之间的对应关系。实际应用中,会对每个监测对象进行编号,因此,可以存储监测对象对应的编号与发出的声音的音频编码之间的对应关系。
[0146]
通过获得每个监测对象发出的声音的音频编码,并存储监测对象与音频编码之间的对应关系,便于基于音频编码准确确定出对应的监测对象,提高了对监测对象进行确定
的效率和准确性。
[0147]
图5为本技术应用实施例提供的行为监测方法的实现流程示意图,如图5所示:
[0148]
将目标猪只对应的音频向量pig-vector与多个猪只发出的声音构成的混合音频输入语音分离模型,通过语音分离模型从该混合音频中提取出目标猪只的音频,将目标猪只的音频以及目标猪只视频输入第一设定模型中,得到音频部分的输出结果和视频部分的输出结果,将这两个输出结果拼接起来通过一层fc层和一层softmax层得到目标猪只是否存在咳嗽行为的判断结果,在判断结果表征目标猪只存在咳嗽行为的情况下,提取出目标猪只的音频中的咳嗽时间间隔以及单次咳嗽时长作为音频部分模型的输入,将目标猪只的行为视频作为视频部分模型的输入,将音频部分模型的输出结果以及视频部分模型的输出结果拼接起来,通过fc层和softmax层进行连接,得出最终的判断结果,在最终判断结果表征猪只存在患病行为的情况下,基于目标猪只的音频对应的音频编号准确定位出存在患病行为的猪只。
[0149]
在本技术实施例中,从第一音频中提取出至少一个第二音频,其中,第一音频表征由至少两个监测对象发出的声音,至少一个第二音频中的每个第二音频表征所述至少两个监测对象中的一个监测对象发出的声音;将至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到至少两个监测对象中每个监测对象对应的第一行为特征;将至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,第二视频表征拍摄有对应的监测对象的视频,如此,可以从多个监测对象的声音组成的混合音频中提取出每个监测对象的单独音频,并结合每个监测对象对应的视频共同进行行为监测,通过这种多模态的方式提高了行为监测的准确性,并且由于可以从混合音频中提取出单个监测对象的音频进行行为监测,在监测到监测对象存在异常行为时,可以精准快速地定位出存在异常行为的监测对象,从而提高了对行为监测对象进行定位的效率。
[0150]
本技术实施例还提供了一种模型训练方法,图6为本技术实施例提供的模型训练方法的实现流程示意图。如图6所示,所述方法包括:
[0151]
步骤601,获取监测对象的音频样本和视频样本;所述音频样本表征所述监测对象发出的声音;所述视频样本表征与所述音频样本同时采集的拍摄有所述监测对象的视频。
[0152]
这里,首先获取监测对象的音频样本和视频样本,其中,音频样本表征监测对象发出的声音,视频样本表征拍摄有所述监测对象的视频,且采集时间点与音频样本的采集时间点相同。
[0153]
本技术实施例以监测对象为猪只为例对所述模型训练方法进行阐述。
[0154]
示例性地,监测对象可以采用月龄五个半月的猪只,其中包含存在患病行为的猪只,每只猪只平均体重为60kg。以30只猪只为监测对象,其中,每只猪只都有唯一对应的编号。
[0155]
音频样本和视频样本的采集时间可以为冬末、夏初等换季时节,因为换季时节通常为猪只出现患病行为的多发季。
[0156]
猪只所在的猪舍的尺寸为27.5m长、13.7m宽、3.2m高。猪舍内包括30个围栏,平均每栏1只猪,共30只猪。每个围栏由1.1m高的铁栅栏围起来。
[0157]
录音设备为麦克风,在猪舍内不同的猪栏内放置一个频率为100hz-16khz的麦克
风,该麦克风连接笔记本电脑声卡,通过笔记本电脑上的录音软件进行录音。麦克风固定在距离地面1.4m的位置,距离猪只背部大概0.8m。笔记本电脑声卡采样率为44.1khz,分辨率为16bits。
[0158]
视频拍摄设备为枪击摄像头。多个猪只的混合音频数据与视频数据是针对多栏猪舍里的猪只进行采集得到的,如选定5只猪只作为同一栏,将30只猪只分为6栏猪舍,对这6栏猪舍里的猪只采集混合音频数据与视频数据。采集时间可以是3天。
[0159]
为了进行第一设定模型的训练,需要单独获取每个猪只的音频数据,具体可以是将30只猪只分别单独置于猪舍,针对单个猪只采集音频数据,采集时间同样可以是3天。采集到每个猪只的音频数据后,基于每个猪只的音频数据生成数据集s1,将不同的猪只的音频数据进行去噪处理,获取纯净的音频数据,基于纯净的音频数据生成数据集s
11
。具体的去噪方法为:采用谱减法进行降噪处理。噪声一般来自于两方面,环境噪音和录音设备自身产生的噪音。谱减法认为猪舍环境下的语音信号是纯净声音信号和噪声信号的叠加,因此可以通过整体信号的静音部分去估算声音信号的平均噪声能量,然后将声音信号中的稳定噪声部分剔除,得到的就是纯净的声音信号。
[0160]
为了更好地进行第一设定模型的训练,从数据集s1中选择同一猪栏中的5只猪只的音频数据进行融合,由于一共是6栏猪,采集了3天的音频数据,所以得到6段72h的音频数据,对这6段72h的音频数据按照15s进行分段处理,从中挑选出有声音的音频段,基于这些有声音的音频段生成混合音频数据集s2。s2中的每一段数据在s
11
中均有对应的数据集作为训练的标签。针对数据集s
11
,采用人工的方式分离出咳嗽部分和非咳嗽部分,同样分别按照15s进行分段,保存为咳嗽数据集s
12
和非咳嗽数据集s
13
,需要说明的是,s
12
和s
13
中包含有其他的异常声音,这里只针对咳嗽声音进行区分。所有的数据集都对应有猪只的编号、采集的时间。根据音频采集的时间提取出对应时长的视频作为视频样本。
[0161]
图7为本技术实施例提供的音频数据处理的示意图,如图7所示:
[0162]
将目标猪只的音频输入设定的语音编码器,生成对应的pig-vector,对目标猪只的音频进行去噪处理获得目标猪只的纯净的音频,将该纯净的音频作为语音分离模型的训练标签,将目标猪只的纯净音频以及其他猪只的带有噪声的音频混合在一起构成混合音频数据集,将混合音频数据集输入语音分离模型,进行训练。
[0163]
步骤602,将所述音频样本对应的音频特征以及所述视频样本输入第一设定模型,得到第一输出结果;所述第一输出结果表征所述监测对象对应的第一行为特征。其中,所述音频样本对应的音频特征包括互相关系数矩阵特征,所述互相关系数矩阵特征表征所述音频样本对应的语谱图中相邻两帧之间的相关系数。
[0164]
这里,将音频样本对应的音频特征以及视频样本输入第一设定模型,得到第一输出结果,第一输出结果表征监测对象对应的第一行为特征。
[0165]
具体地,分别提取咳嗽数据集s
12
和非咳嗽数据集s
13
的语音特征,将s
12
对应的语音特征和咳嗽数据集对应的视频输入第一设定模型,以咳嗽时对应的语音特征作为标签进行训练,得到第一输出结果;将s
13
对应的语音特征和非咳嗽数据集对应的视频输入第一设定模型,以非咳嗽时对应的语音特征作为标签进行训练,得到第一输出结果。其中,所述音频特征还包括互相关系数矩阵特征,互相关系数矩阵表征音频样本对应的语谱图中相邻两帧之间的相关系数。由于猪只咳嗽时的音频对应的语谱图中语音信号变化幅值与正常发声时
的音频对应的语谱图中语音信号的变化幅值间的差异较大,因此,提取音频样本对应的语谱图的相邻帧之间的相似性特征进行分析。
[0166]
在得到音频样本对应的频谱能量之后,在梅尔刻度下将整个频域范围等分为m个频段,频段间存在重叠,具体地,上一个频段的中心频率为下一个频段的起始频率。对语谱图中的相邻两帧的对应频段分别求互相关系数,将得到的m个频段的互相关系数作为一帧输入信号的动态特征。
[0167]
假设s(n,k)表示第n帧语谱图经过快速傅里叶变换(fft)后的第k个点对应的频谱能量,则第n帧第m个频段的互相关系数cc(n,m)的计算公式为:
[0168][0169]
其中,k
mi
和k
mh
分别为第n帧语谱图经过fft后的第m个频段的起始频率点和结束频率点,n为总帧数,m为总频段数。通过计算可以得到一个n*m的互相关系数矩阵。
[0170]
针对视频样本部分,利用opencv对视频样本进行分帧处理,提取有效图片,针对每张图片采用cnn提取表观特征,再利用lstm学习时序特征,从而实现视频样的本向量输出。
[0171]
图8为本技术实施例提供的提取视频样本特征进行训练的示意图,如图8所示:
[0172]
将猪只的视频样本输入第一设定模型,基于视频样本获取猪只的多帧图像,针对每一帧图像,利用cnn提取表观特征,然后再将cnn提取出的结果输入lstm中学习时序特征,最后将结果作为图像向量输出。
[0173]
步骤603,基于所述第一输出结果计算损失值,并基于所述损失值更新第一设定模型的权重参数。
[0174]
这里,基于第一输出结果计算损失值,基于损失值更新第一设定模型的权重参数,计算第一输出结果和对应的标签之间的损失值,如果损失值过大,说明第一设定模型的拟合度比较差,第一设定模型输出的结果还存在较大的误差,因此,需要基于损失值更新第一模型的权重参数,使得第一输出结果尽可能地接近标签值,这样训练出的模型才具有良好的区分能力。
[0175]
在一实施例中,所述音频样本对应的音频特征还包括以下至少之一:
[0176]
所述音频样本对应的语谱图;
[0177]
所述音频样本对应的梅尔频率倒谱特征;
[0178]
所述音频样本对应的一阶差分特征;
[0179]
所述音频样本对应的二阶差分特征。
[0180]
这里,音频样本的音频特征除了互相关系数矩阵特征之外,还包括以下至少一项:音频样本对应的语谱图、音频样本对应的梅尔频率倒谱特征、音频样本对应的一阶差分特征、音频样本对应的二阶差分特征。
[0181]
语谱图是通过对原始的音频信号进行分帧加窗后得到多帧、对每一帧进行快速傅里叶变换将时域信号转换为频域信号,再把每一帧fft后的频域信号在时间上堆叠起来得到的。语谱图充分提取了音频样本的时域以及频域特征,将音频样本以图像形式进行展示。
获得音频样本的二维语谱图后,将语谱图保存为227*227*3的rgb彩色图片。
[0182]
梅尔频率倒谱特征表示的是语音信号的短时功率谱,由语音信号的对数功率谱在频率的一个非线性梅尔刻度上进行线性余弦转换得到,主要用于提取音频样本的静态特征和降低运算维度。mfcc一般经过以下步骤得出,分别是预加重、分帧、加窗、fft、梅尔滤波器组、离散余弦变换(dct),最后保留计算结果的第2个到第13个系数,得到的这12个系数就是mfcc。
[0183]
一阶差分(deltas)特征也称为微分系数,用于描述音频样本的动态特征。
[0184]
二阶差分(deltas-deltas)特征也称为加速度系数,用于描述音频样本的动态特征。
[0185]
图9为本技术实施例提供的提取音频样本的音频特征进行训练的示意图,如图9所示:
[0186]
提取音频样本的语音特征,如语谱图、mfcc、一阶差分、二阶差分、互相关系数矩阵,将这些语音特征输入第一设定模型。
[0187]
针对语谱图,采用crnn算法进行训练,并结合fc层获取语音向量。将互相关系数矩阵以及mfcc、一阶差分和二阶差分特征结合得到hfss特征,将该hfss特征输入三层的fc中进行训练生成静态和动态特征向量,最后将语音向量和静态及动态特征向量拼接得到语音部分的输出。
[0188]
为实现本技术实施例的方法,本技术实施例还提供了一种行为监测装置,图10为本技术实施例提供的行为监测装置的示意图,请参见图10,该装置包括:
[0189]
提取单元1001,用于从第一音频中提取出至少一个第二音频;所述第一音频表征由至少两个监测对象发出的声音;所述至少一个第二音频中的每个第二音频对应表征所述至少两个监测对象中的一个监测对象发出的声音;
[0190]
输入单元1002,用于将所述至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到所述至少两个监测对象中每个监测对象对应的第一行为特征;
[0191]
匹配单元1003,用于将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,
[0192]
所述第二视频表征拍摄有对应的监测对象的视频。
[0193]
在一实施例中,所述匹配单元1003,还用于在第一行为特征满足以下条件至少之一的情况下,确定第一行为特征与第一设定行为特征匹配:
[0194]
第一语谱图中存在幅值大于设定阈值的语音信号;其中,第一语谱图为第一行为特征对应的监测对象对应的第二音频的语谱图;
[0195]
基于第一行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生设定行为。
[0196]
在一实施例中,所述装置还包括:第二匹配单元,用于在所述第一行为监测结果表征存在监测对象对应的第一行为特征与所述第一设定行为特征匹配的情况下,将对应的第二音频以及对应的第二视频输入第二设定模型,得到对应的监测对象对应的第二行为特征;
[0197]
将得到的第二行为特征与第二设定行为特征进行匹配,得到关于对应的监测对象
的第二行为监测结果;其中,
[0198]
所述第二设定行为特征表征对应的监测对象行为异常。
[0199]
在一实施例中,所述第二匹配单元,还用于在得到的第二行为特征满足以下至少一个条件的情况下,确定第二行为特征与第二设定行为特征匹配:
[0200]
第二语谱图中幅值大于设定阈值的语音信号出现的时间间隔小于设定时间间隔;其中,第二语谱图为第二行为特征对应的监测对象对应的第二音频的语谱图;
[0201]
第二语谱图中幅值大于设定阈值的语音信号持续的时长大于设定时长。
[0202]
在一实施例中,所述装置还包括:第二确定单元,用于在第二行为监测结果表征第二行为特征与所述第二设定行为特征匹配的情况下,基于第二行为特征对应的监测对象的第二音频的音频编码,确定所述第二行为特征对应的监测对象。
[0203]
在一实施例中,所述装置还包括:获取单元,用于基于第二音频的音频编码确定出所述第二音频对应的监测对象;
[0204]
获取所述监测对象对应的第二视频。
[0205]
在一实施例中,所述装置还包括:存储单元,用于将每个监测对象发出的声音分别输入设定语音编码器,得到每个监测对象发出的声音的音频编码;
[0206]
存储所述每个监测对象与发出的声音的音频编码之间的对应关系。
[0207]
实际应用时,所述提取单元1001、所述输入单元1002、所述匹配单元1005、所述第二匹配单元、所述第二确定单元、所述获取单元、所述存储单元可通过终端中的处理器,比如中央处理器(cpu,central processing unit)、数字信号处理器(dsp,digital signal processor)、微控制单元(mcu,microcontroller unit)或可编程门阵列(fpga,field-programmable gate array)等实现。
[0208]
需要说明的是:上述实施例提供的行为监测装置在进行信息显示时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将装置的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的行为监测装置与行为监测方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
[0209]
为实现本技术实施例的方法,本技术实施例还提供了一种模型训练装置,图11为本技术实施例提供的模型训练装置的示意图,请参见图11,该装置包括:
[0210]
获取单元1101,用于获取监测对象的音频样本和视频样本;所述音频样本表征所述监测对象发出的声音;所述视频样本表征与所述音频样本同时采集的拍摄有所述监测对象的视频;
[0211]
输入单元1102,用于将所述音频样本对应的音频特征以及所述视频样本输入第一设定模型,得到第一输出结果;所述第一输出结果表征所述监测对象对应的第一行为特征;
[0212]
计算单元1103,用于基于所述第一输出结果计算损失值,并基于所述损失值更新第一设定模型的权重参数;其中,
[0213]
所述音频样本对应的音频特征包括互相关系数矩阵特征,所述互相关系数矩阵特征表征所述音频样本对应的语谱图中相邻两帧之间的相关系数。
[0214]
在一实施例中,所述音频样本对应的音频特征还包括以下至少之一:
[0215]
所述音频样本对应的语谱图;
[0216]
所述音频样本对应的梅尔频率倒谱特征;
[0217]
所述音频样本对应的一阶差分特征;
[0218]
所述音频样本对应的二阶差分特征。
[0219]
基于上述程序模块的硬件实现,且为了实现本技术实施例的方法,本技术实施例还提供了一种电子设备。图12为本技术实施例提供的电子设备的硬件组成结构示意图,如图12所示,电子设备包括:
[0220]
通信接口1201,能够与其它设备比如网络设备等进行信息交互;
[0221]
处理器1202,与所述通信接口1201连接,以实现与其它设备进行信息交互,用于运行计算机程序时,执行上述终端侧一个或多个技术方案提供的方法。而所述计算机程序存储在存储器1203上。
[0222]
具体地,所述处理器1202,用于从第一音频中提取出至少一个第二音频;所述第一音频表征由至少两个监测对象发出的声音;所述至少一个第二音频中的每个第二音频对应表征所述至少两个监测对象中的一个监测对象发出的声音;将所述至少一个第二音频中的每个第二音频以及对应的第二视频输入第一设定模型,得到所述至少两个监测对象中每个监测对象对应的第一行为特征;将所述至少两个监测对象中每个监测对象对应的第一行为特征与第一设定行为特征进行匹配,得到第一行为监测结果;其中,所述第二视频表征拍摄有对应的监测对象的视频。
[0223]
在一实施例中,所述处理器1202还用于在第一行为特征满足以下条件至少之一的情况下,确定第一行为特征与第一设定行为特征匹配:
[0224]
第一语谱图中存在幅值大于设定阈值的语音信号;其中,第一语谱图为第一行为特征对应的监测对象对应的第二音频的语谱图;
[0225]
基于第一行为特征对应的监测对象对应的第二视频,判断出对应的监测对象发生设定行为。
[0226]
在一实施例中,所述处理器1202还用于在所述第一行为监测结果表征存在监测对象对应的第一行为特征与所述第一设定行为特征匹配的情况下,将对应的第二音频以及对应的第二视频输入第二设定模型,得到对应的监测对象对应的第二行为特征;
[0227]
将得到的第二行为特征与第二设定行为特征进行匹配,得到关于对应的监测对象的第二行为监测结果;其中,
[0228]
所述第二设定行为特征表征对应的监测对象行为异常。
[0229]
在一实施例中,所述处理器1202还用于在得到的第二行为特征满足以下至少一个条件的情况下,确定第二行为特征与第二设定行为特征匹配:
[0230]
第二语谱图中幅值大于设定阈值的语音信号出现的时间间隔小于设定时间间隔;其中,第二语谱图为第二行为特征对应的监测对象对应的第二音频的语谱图;
[0231]
第二语谱图中幅值大于设定阈值的语音信号持续的时长大于设定时长。
[0232]
在一实施例中,所述处理器1202还用于在第二行为监测结果表征第二行为特征与所述第二设定行为特征匹配的情况下,基于第二行为特征对应的监测对象的第二音频的音频编码,确定所述第二行为特征对应的监测对象。
[0233]
在一实施例中,在从第一音频中提取出至少一个第二音频之后,所述处理器1202还用于基于第二音频的音频编码确定出所述第二音频对应的监测对象;
[0234]
获取所述监测对象对应的第二视频。
[0235]
在一实施例中,在所述从第一音频中提取出至少一个第二音频之前,所述处理器1202还用于将每个监测对象发出的声音分别输入设定语音编码器,得到每个监测对象发出的声音的音频编码;
[0236]
存储所述每个监测对象与发出的声音的音频编码之间的对应关系。
[0237]
在一实施例中,所述处理器1202还用于获取监测对象的音频样本和视频样本;所述音频样本表征所述监测对象发出的声音;所述视频样本表征与所述音频样本同时采集的拍摄有所述监测对象的视频;
[0238]
将所述音频样本对应的音频特征以及所述视频样本输入第一设定模型,得到第一输出结果;所述第一输出结果表征所述监测对象对应的第一行为特征;
[0239]
基于所述第一输出结果计算损失值,并基于所述损失值更新第一设定模型的权重参数;其中,
[0240]
所述音频样本对应的音频特征包括互相关系数矩阵特征,所述互相关系数矩阵特征表征所述音频样本对应的语谱图中相邻两帧之间的相关系数。
[0241]
在一实施例中,所述音频样本对应的音频特征还包括以下至少之一:
[0242]
所述音频样本对应的语谱图;
[0243]
所述音频样本对应的梅尔频率倒谱特征;
[0244]
所述音频样本对应的一阶差分特征;
[0245]
所述音频样本对应的二阶差分特征。
[0246]
当然,实际应用时,电子设备中的各个组件通过总线系统1204耦合在一起。可理解,总线系统1204用于实现这些组件之间的连接通信。总线系统1204除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图12中将各种总线都标为总线系统1204。
[0247]
本技术实施例中的存储器1203用于存储各种类型的数据以支持电子设备的操作。这些数据的示例包括:用于在电子设备上操作的任何计算机程序。
[0248]
可以理解,存储器1203可以是易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(rom,read only memory)、可编程只读存储器(prom,programmable read-only memory)、可擦除可编程只读存储器(eprom,erasable programmable read-only memory)、电可擦除可编程只读存储器(eeprom,electrically erasable programmable read-only memory)、磁性随机存取存储器(fram,ferromagnetic random access memory)、快闪存储器(flash memory)、磁表面存储器、光盘、或只读光盘(cd-rom,compact disc read-only memory);磁表面存储器可以是磁盘存储器或磁带存储器。易失性存储器可以是随机存取存储器(ram,random access memory),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的ram可用,例如静态随机存取存储器(sram,static random access memory)、同步静态随机存取存储器(ssram,synchronous static random access memory)、动态随机存取存储器(dram,dynamic random access memory)、同步动态随机存取存储器(sdram,synchronous dynamic random access memory)、双倍数据速率同步动态随机存取存储器(ddrsdram,double data rate synchronous dynamic random access memory)、增强型同步动态随机
存取存储器(esdram,enhanced synchronous dynamic random access memory)、同步连接动态随机存取存储器(sldram,synclink dynamic random access memory)、直接内存总线随机存取存储器(drram,direct rambus random access memory)。本技术实施例描述的存储器1203旨在包括但不限于这些和任意其它适合类型的存储器。
[0249]
上述本技术实施例揭示的方法可以应用于处理器1202中,或者由处理器1202实现。处理器1202可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器1202中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器1202可以是通用处理器、dsp,或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。处理器1202可以实现或者执行本技术实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者任何常规的处理器等。结合本技术实施例所公开的方法的步骤,可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于存储介质中,该存储介质位于存储器1203,处理器1202读取存储器1203中的程序,结合其硬件完成前述方法的步骤。
[0250]
处理器1202执行所述程序时实现本技术实施例的各个方法中的相应流程。
[0251]
在示例性实施例中,本技术实施例还提供了一种存储介质,即计算机存储介质,具体为计算机可读存储介质,例如包括存储计算机程序的存储器1203,上述计算机程序可由处理器1202执行,以完成前述方法所述步骤。计算机可读存储介质可以是fram、rom、prom、eprom、eeprom、flash memory、磁表面存储器、光盘、或cd-rom等存储器。
[0252]
在本技术所提供的几个实施例中,应该理解到,所揭露的装置、终端和方法,可以通过其它的方式实现。以上所描述的设备实施例仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
[0253]
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元,即可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。
[0254]
另外,在本技术各实施例中的各功能单元可以全部集成在一个处理单元中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
[0255]
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0256]
或者,本技术上述集成的单元如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台电子设备(可以是个人计算机、服务器、或者网络设备等)执行本技术各个实施例所述方法的全部或部分。而
前述的存储介质包括:移动存储设备、rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0257]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。