1.本发明是关于一种产生语音的方法,尤其是一种产生客制化语音服务的方法,其以应用程序取得数据,传送至伺服器进行文字辨识产生仿真人物的第一语音数据,再依据客制化语音参数播放为仿真人物的第二语音数据,而对数据提供客制化语音服务,进行播报、配音。
背景技术:
2.当前技术已有将文字转换成语音的技术,如:google翻译所提供的语音朗读功能。
3.google翻译中使用较广泛的语言都有「朗读」功能,对多中心语言而言,朗读采用的口音取决于所在地区,例如:英语:美洲、亚太(中国香港、马、新除外)及西亚大多使用美国英语(女声),其余均用英国英语(女声),但澳洲、新西兰和诺福克岛使用一种特殊的大洋洲口音(女声),印度使用印度口音(女声)。法语:除加拿大使用魁北克口音(女声)外,其余大部分地区使用标准欧陆口音(女声)。西班牙语:美洲(除美国)使用美洲西班牙语(女声),其余大部分地区使用卡斯蒂利亚西班牙语(男声)。标准汉语:繁体使用国语 (女声),简体使用普通话(女声)。葡萄牙语:除葡萄牙使用本国口音(女声)外,其余大部分地区使用圣保罗口音(女声)。
4.其中,文字转换成语音的技术称为文字转语音text to speech,简称 tts。text-to-speech(tts)的目标是将给定的文字(text)合成出对人类来说自然的语音(speech)。
5.传统上有两种方法来实现tts,分别是拼接式合成(concatenativespeech synthesis)和参数式合成(parametric speech synthesis)。
6.拼接式(concatenative speech synthesis)合成:拼接式合成将预录好的语句、文字语音组成一个数据库。当欲生成语音的文字进来时,在数据库里挑选适当的example拼接成新的语音。
7.然而该如何挑选语句来合成语音是一个大问题。若使用长的语句,合成出来的声音可能比较自然,但会要求很多的example储存在数据库里,因此会有记忆空间的问题以及该如何取得这么多example的人力问题,因此弹性较低;若使用短的语句,弹性较高,但文字的标注、声音的挑选会变得较困难、合成出来的声音会较不自然。
8.参数式合成(parametric speech synthesis):参数式合成是利用训练好的模型来合成声音的波形,好处是他不需要像拼接式合成那样有一个庞大的数据库,比起拼接式合成来得更有弹性、节省人力。但是过去的实验结果显示,参数式方法合成出来的语音比较平淡、质量较差且不自然。
9.参数式合成会从语音讯号x={x1,
…
,xt}抽取vocoder参数o ={o1,
…
,on}和从文字w抽取语言特征(linguistic features)l。
10.训练时使用一个生成模型(generative model),可以是hmm、类神经网络等,希望根据语言特征l产生适当的vocoder参数o,最后让vocoder 根据这个参数o产生声音波形。
11.training阶段,更新模型参数λ:
[0012][0013]
synthesis阶段,从linguistic features l和模型λ得到vocoder 参数o:
[0014][0015]
最后vocoder再使用这个o来合成声音波形。
[0016]
随着人工智能、深度学习的发展,google deepmind于2016年提出 wavenet,让合成出来的语音更自然、更像人声。
[0017]
deep learning(深度学习):近年来,随着deep learning技术的发展,对tts这个领域产生了重大的影响。2016年google deepmind率先提出wavenet的深度学习架构,取得了很大的成功,并且投入商业应用,包含google 助理、google翻译等等。
[0018]
然而,目前关于语音播报服务技术,多专注于产生语音的正确性,或让语音产生语句时更自然、更像人声,并无针对用户想要的声音产生客制化语音有所著墨,因此如何针对于语音播报,提升其使用体验,服务社会大众,为相关领域的技术人员有待克服的课题。
[0019]
基于上述问题,本发明提供一种产生客制化语音服务的方法,其由执行应用程序,依据语音数据库产生符合自定义参数的客制化语音,供用户能以喜爱的客制化语音以播报特定事件,如此一来即可大幅提升其使用体验。
技术实现要素:
[0020]
本发明的一目的,在于提供一种产生客制化语音服务的方法,其藉由文字辨识模块根据应用程序取得的数据产生仿真人物的语音数据,再变更为符合客制化的语音参数的客制化语音,从而对数据以客制化语音进行配音,为自定义语音为数据配音的服务,对比先前技术的语音播报数据的技术,增加了用户于播报服务中对语音选择的自由度。
[0021]
针对上述的目的,本发明提供了一种产生客制化语音服务的方法,其应用于一客户端装置执行一应用程序并链接一第一伺服器,并同时执行一事件,其先由应用程序连接至一第二伺服器取得欲进行客制化语音服务的一数据;再由客户端装置依据应用程序发送数据至第一伺服器;再,第一伺服器依据一文字辨识模块将数据转换为一仿真人物的一第一语音数据;及,最后由客户端装置选择仿真人物的一第二语音数据予以播放。本发明可以透过伺服器产生符合自定义的语音参数的客制化语音服务以播报输入数据,提升给予用户关于语音播报服务的使用体验。
[0022]
本发明提供一实施例,数据包含一文本。
[0023]
本发明提供一实施例,其中于第一伺服器依据一文字辨识模块将数据转换为一仿真人物的一第一语音数据的步骤中,第一伺服器依据文字辨识模块利用文字转换成语音技术(tts)将文本转换为仿真人物的第一语音数据。
[0024]
本发明提供一实施例,其中于客户端装置选择仿真人物的一第二语音数据予以播放的步骤中,以默认的第一语音数据的一语音参数予以播放,或选择仿真人物的第二语音数据予以播放,其中第二语音数据的语音参数与第一语音数据的语音参数不同。
[0025]
本发明提供一实施例,其中语音参数可利用应用程序设定。
[0026]
本发明提供一实施例,其中语音参数可以是一音色或包含音色及一音调。
[0027]
本发明另揭示了一种产生客制化语音服务的方法,其应用于一客户端装置执行一应用程序并链接一第一伺服器,并同时执行一事件,其先由应用程序取得用户提供的一数据;再,客户端装置依据应用程序发送数据至第一伺服器;再,第一伺服器依据一语音识别模块将数据转换为一仿真人物的一第一语音数据;及,最后由客户端装置选择仿真人物的一第二语音数据予以播放。由上可知,本发明可以透过伺服器调整调整输入的语音,产生符合自定义的语音参数的客制化语音以播放,提升给予用户关于语音播报服务的使用体验。
[0028]
本发明提供另一实施例,其中于提供应用程序取得一数据的步骤中,提供应用程序取得一用户语音。
[0029]
本发明提供另一实施例,其中于第一伺服器依据一语音识别模块将数据转换为一仿真人物的一第一语音数据的步骤中,第一伺服器依据语音识别模块利用语音转文字识别(stt)将用户语音转换为仿真人物的第一语音数据。
[0030]
本发明提供另一实施例,其中于客户端装置选择仿真人物的一第二语音数据予以播放的步骤中,以默认的第一语音数据的语音参数予以播放,或选择仿真人物的第二语音数据予以播放,其中第二语音数据的语音参数与第一语音数据的语音参数不同。
[0031]
本发明提供另一实施例,其中语音参数可利用应用程序设定。
[0032]
本发明提供另一实施例,其中语音参数可以是一音色或包含音色及一音调。
附图说明
图1:其为本发明的一实施例的步骤s10-s40的方法流程图。图2:其为本发明的一实施例的方块图;图3:其为本发明的另一实施例的步骤s110-s140的方法流程图;及图4:其为本发明的另一实施例的方块图。【图号对照说明】10
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
客户端装置12
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
事件20
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第一伺服器202
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
文字辨识模块204
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
语音识别模块22
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
语音数据库24
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
模拟人物242
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第一语音数据244
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第二语音数据26
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
语音参数262
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
音色264
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
音调30
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
第二伺服器32
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
数据322
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
文本324
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用户语音
app
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
应用程序s10-s140
ꢀꢀꢀꢀꢀ
步骤
具体实施方式
[0033]
为了使本发明的结构特征及所达成的功效有更进一步的了解与认识,特用较佳的实施例及配合详细的说明,说明如下:
[0034]
习知语音播报数据的方法,是将语音与文字进行链接,而产生语音数据从而实现语音对数据进行播报,而本发明所提供的产生客制化语音服务的方法,更可提供一种用户能自定义的客制化语音服务,从而实现使用客制化语音对数据进行播报,以提供更具使用体验的语音播报服务。
[0035]
在下文中,将藉由图式来说明本发明的各种实施例来详细描述本发明。然而本发明的概念可能以许多不同型式来体现,且不应解释为限于本文中所阐述的例式性实施例。
[0036]
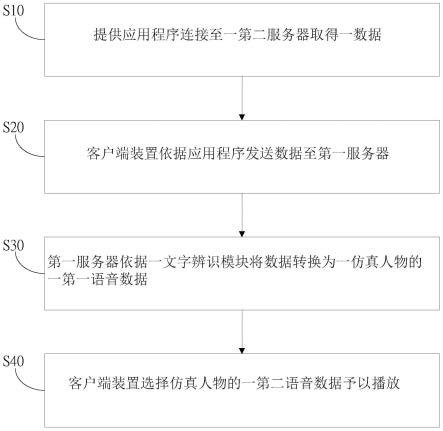
首先,请参阅图1,其为本发明的一实施例的方法流程图。如图所示,本发明的产生客制化语音服务的方法,其应用于一客户端装置执行一应用程序,并链接一第一伺服器,并同时执行一事件,其步骤包含:
[0037]
步骤s10:提供应用程序连接至一第二伺服器取得一数据;
[0038]
步骤s20:客户端装置依据应用程序发送数据至第一伺服器;
[0039]
步骤s30:第一伺服器依据一文字辨识模块将数据转换为一仿真人物的一第一语音数据;及
[0040]
步骤s40:客户端装置选择仿真人物的一第二语音数据予以播放。
[0041]
请参阅图1、图2,本发明的产生客制化语音服务的方法所采用的客制化语音服务系统1,包含客户端装置10,用户能于客户端装置10执行应用程序,例如:app,应用程序app可以透过网络链接第一伺服器20,并同时执行事件12即执行客制化语音服务,第一伺服器20有文字辨识模块202能利用文字转换成语音技术(tts)将文字变换为语音,文字转换成语音技术(tts)乃是习知技术,能将有声学特征的语音材料合成为符合文字或字句的语音或语句,实施方法于先前技术部分已有介绍,此处不再赘述。
[0042]
如步骤s10所示,本实施例为用户提供应用程序app透过网络连接至第二伺服器30取得数据32,数据32是欲进行客制化语音服务的目标,本发明是应用文字转换成语音技术(tts)的应用,故,数据32应包含一文本322,文本322为进行客制化语音服务的材料,举例来说,数据32可以是多媒体档案或网页,这里是用户以第二伺服器30上的新闻网页(例:.html文件)为数据32进行客制化语音服务,数据32须包含文字内容(例:.txt文件或一段文字)即文本322,但不限于此。
[0043]
上述文本(text),是书面语言的表现形式,或一种文档类型,或指任何文字材料。文本,是指书面语言的表现形式,从文学的角度说,通常是具有完整、系统含义(message)的一个句子或多个句子的组合。一个文本可以是一个句子(sentence)、一个段落(paragraph)或者一个篇章(discourse)。
[0044]
如步骤s20所示,客户端装置10依据应用程序app透过网络发送前述数据 32至第一伺服器20。
[0045]
如步骤s30所示,当第一伺服器20接收到数据32后,第一伺服器20上文字辨识模块
202将数据32应用文字转换成语音技术(tts)转换为模拟人物24的第一语音数据242,其是根据数据32所包含的文本322透过文字转换成语音技术 (tts),透过语音元素或拼音的组合能产生对应文字322的仿真人物24的第一语音数据242。而如何产生语音元素或拼音的方法则是习知技术,于先前技术已有提及,此处不赘述。本例可以有多个仿真人物24供用户挑选,但不限于此。
[0046]
如步骤s40所示,客户端装置10以默认的第一语音数据242的语音参数26 予以播放,语音参数26为一音色262或包含音色262及一音调264,音色(timbre) 为声音的波型(waveform),音调(tone)为声音的频率(frequency),也可以选择模拟人物24的第二语音数据244予以播放,第二语音数据的语音参数与第一语音数据的语音参数不同,并且用户可以透过应用程序app设定语音参数26。
[0047]
请参阅图3,本发明产生客制化语音服务的方法,亦应用于客户端装置执行应用程序,并链接第一伺服器,并同时执行事件,其步骤尚包含:
[0048]
步骤s110:提供应用程序取得数据;
[0049]
步骤s120:客户端装置依据应用程序发送数据至第一伺服器;
[0050]
步骤s130:第一伺服器依据一语音识别模块将数据转换为仿真人物的第一语音数据;及
[0051]
步骤s140:客户端装置选择仿真人物的第二语音数据予以播放。
[0052]
请参阅第3、4图,本发明尚提供一种产生客制化语音服务的方法,其应用于变更输入的语音而为客制化语音,亦采用客制化语音服务系统1,用户能于客户端装置10执行应用程序app,应用程序app可以透过网络链接第一伺服器20,并同时执行事件12即执行变更输入的语音的客制化语音服务,第一伺服器20有语音识别模块204能利用语音转文字识别(speech to text,stt)将语音变换为文字,语音转文字识别(stt),其相关于文字转换成语音技术(tts),语音转文字识别(sst)是以算法将语音内容转换为相对应的文字,其实施方式为将人类发出的语音输入计算机系统后,首先由数字信号处理器(digital signalprocessor)将声音分解成不同的声音频带(frequency bands),这些频带必须经过计算机内专家系统程序的解析,以判断每个声音的片断,称的为音位 (phonemes),然后在配合其他程序的判断将音位组合成单字,再利用语法的知识库(knowlege base)判断每个单字的语法关系是否符合人类的用法,最后将整个结果于计算机屏幕上输出,简单描述即透过将声音特征比对语音数据库,并将语音内容转换为可能的文字。
[0053]
如步骤s110所示,本实施例为用户提供应用程序app取得数据32,数据 32是欲进行客制化语音服务的目标,本发明系应用语音转文字识别(speech to text,stt)透过声音特征比对为文字,故,数据32可以是语音文件或多媒体档案,但应包含能转化为文字的用户语音324,用户语音324为进行客制化语音服务的材料,举例来说,这里可以是用户输入一段话,或输入影片文件为数据32 进行客制化语音服务,数据32中须包含用户语音324,但不限于此。
[0054]
如步骤s120所示,客户端装置10依据应用程序app透过网络发送前述数据32至第一伺服器20。
[0055]
如步骤s130所示,当第一伺服器20接收到数据32后,第一伺服器20上语音识别模块204将数据32应用语音转文字识别(stt)转换为模拟人物24的第一语音数据242,其是根
据数据32所包含的用户语音324透过语音转文字识别 (stt),将用户语音324辨识为文本322,再将用户语音324透过声音特征比对产生文本322的模拟人物24的第一语音数据242,此处将用户语音324重制的目的为后续能以语音参数26调整语句中的每一个声音特征而非直接调整语句,使调整后的语音更加自然,仿真人物24则对应用户语音324。
[0056]
如步骤s140所示,客户端装置10以默认的第一语音数据242的语音参数 26予以播放,语音参数26为音色262或包含音色262及音调264,音色(timbre)为声音的波型(waveform),音调(tone)为声音的频率(frequency),也可以选择模拟人物24的第二语音数据244予以播放,第二语音数据的语音参数与第一语音数据的语音参数不同,并且用户可以透过应用程序app设定语音参数26。本例的第一语音数据242、第二语音数据244即前述用户念出内容经变声前、后的结果,但不在此限。
[0057]
本发明尚提供一具体实施例,参阅图2,本例的客户端装置10可以是手机或个人计算机,但不在此限;今于客户端装置10启用应用程序app并链接应用程序app的服务供货商的第一伺服器20,此处第一伺服器20可以透过网络连接或第一伺服器20被设置于客户端装置10的本地端,但不在此限;并执行事件12,事件12是客制化语音播报服务,本例的客制化语音播报服务以用户手动启用应用程序app并启动导读功能为例,也可以是用户声控应用程序app启用代读功能,但不在此限;本例以对新闻页面执行客制化语音播报服务为例,也可以是对文章执行客制化语音播报服务或用户于游戏中要求应用程序app读出游戏攻略,但不在此限;首先,应用程序app连接至第二伺服器30取得数据32,数据32并包含文本322,本例的数据32以新闻网页(例:.html档案)为例,而文本322为新闻网页上的文字内容(text或.txt档案),但不在此限;客户端装置10将数据32传送至第一伺服器20,第一伺服器20上有文字辨识模块202透过文字转换成语音技术(tts)将文本322以对应模拟人物24的声音产生的第一语音数据242,本例可以有多个仿真人物24供用户挑选;再以默认的第一语音数据242的语音参数26予以播放,语音参数26包含音色262或包含音色262及音调264,客户端装置10可以选择仿真人物24的第二语音数据244予以播放,第二语音数据的语音参数与第一语音数据的语音参数不同。
[0058]
本发明尚提供一具体实施例,本例的客户端装置10可以是手机或个人计算机,但不在此限,亦可以是其他应用程序于客户端装置10启用应用程序app并链接提供服务的第一伺服器20,本例以某游戏程序启用应用程序app提供游戏角色的配音;并执行事件12,事件12是客制化语音播报服务,本例以程序执行该服务对不同场景(例:游戏角色)提供不同对话内容为例,但不在此限;其他步骤如上述不再赘述,该具体实施例的特征在于对不同场景的不同对话内容,有不同的语音参数26设定,本例的语音参数26由其他应用程序提供,数据32为角色配音台词亦由其他应用程序提供,但不在此限;通过执行客制化语音播报服务,其他应用程序并不需要具有语音数据库22便能对不同场景提供不同对话内容,能优化其他应用程序所占用的档案容量。
[0059]
本发明另提供一具体实施例,参阅图4,本例的客户端装置10可以是手机或个人计算机,但不在此限,今于客户端装置10启用应用程序app并链接应用程序app的服务供货商的第一伺服器20,此处第一伺服器20可以透过网络连接或第一伺服器20被设置于客户端装置10的本地端,但不在此限;并执行事件12,事件12是客制化语音服务,本例以用户念出自己要发送的内容进行变声为例说明客制化语音服务,但不在此限。应用程序app取得输入的
数据32,数据32包含用户语音324,本例以用户念出内容的档案(例:.mp3或.aac档案、应用程序app 亦能提供实时录音的功能)为数据32为例,档案须包含用户语音324即用户念出的语句(speech),但不限于此;客户端装置10将数据32传送至第一伺服器20,第一伺服器20上有语音识别模块204利用语音转文字识别(stt)产生对应用户语音324的文本322,并将用户语音324根据声学特征拆解,最后产生第一语音数据242,其对应仿真人物24,本例的前述念出内容者对应模拟人物24,但不在此限;再以默认的第一语音数据242的语音参数26予以播放,语音参数26包含音色 262或包含音色262及音调264,客户端装置10可以选择仿真人物24的第二语音数据244予以播放,第二语音数据的语音参数与第一语音数据的语音参数不同。本例的第一语音数据242、第二语音数据244即前述用户念出内容经变声后的结果,但不在此限。
[0060]
综上所述,本发明的产生客制化语音服务,其供用户自定义语音参数并据此调整语音为客制化语音,对特定事件进行客制化语音配音,提供用户一种能使用喜爱的声音来进行语音播报服务的可能,提高了使用体验。
[0061]
上文仅为本发明的较佳实施例而已,并非用来限定本发明实施的范围,凡依本发明权利要求范围所述的形状、构造、特征及精神所为的均等变化与修饰,均应包括于本发明的权利要求范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。