一种瞳孔追踪方法及其应用于bppv与vm分类诊断的方法
技术领域
1.本发明涉及医学图像处理技术领域,更具体地说,本发明涉及一种瞳孔追踪方法及其应用于bppv与vm分类诊断的方法。
背景技术:
2.良性阵发性位置性眩晕(benign paroxysmal positional vertigo,bppv),又称为“耳石症”,是最常见的外周性眩晕疾病,终生患病率为2.4%,复发率9.5%~52.5%,且好发于老年人群。bppv与多种高发的眩晕疾病如梅尼埃病、前庭神经炎和前庭性偏头痛(vestibular migraine,vm)具有相似的临床症状。
3.眼震是一种有节奏的、振荡的眼球运动,常因前庭功能障碍引起,包括外周前庭功能障碍和中枢前庭神经功能障碍。通过观察眼震有助临床医生区分不同的前庭功能疾病。基于视频眼震的辅助诊断技术可以有效运用于vm与bppv的鉴别,在2019年,yoon s等通过视频眼震描记法检查并分析了不同患者的眼震方向和峰值慢相速度(slow phase velocity,spv),成功分析出bppv和vm的spv特征。
4.虽然通过监测眼震的眼动特性和分析眼震的spv可以实现对bppv和vm的分类诊断,但传统的视频眼震记录仪仍存在以下问题:(1)对于旋转型、微弱型眼震,准确率仍太低,且当前的诊断算法,都依赖于使用2d瞳孔追踪来记录眼震的眼动特性和spv特征,瞳孔的计算稳定性不够,容易受到外界环境影响,缺乏鲁棒性,无法充分挖掘vm与bppv的眼震特征;(2)忽略了半规管空间位置、头部空间位置和耳石空间运动的观测;(3)缺乏对vm与bppv眼震反应的智能分类,医生仅通过主观判断眼震的速度、幅度、旋转方向以及眼震时间,实现疾病类型的诊断,主观性和经验性过强。研究更为精确且稳定的眼震特征提取方法,建立更为特异的分类诊断模型,是实现bppv和vm的智能化诊断的关键。
技术实现要素:
5.针对上述技术中存在的不足之处,本发明提供一种瞳孔追踪方法及其应用于bppv与vm分类诊断的方法,通过unet网络训练一个实时卷积神经网络,实现三维精确瞳孔位置追踪,提高bppv与vm分类诊断的精确性。
6.为了实现根据本发明的这些目的和其它优点,本发明通过以下技术方案实现:
7.本发明实施例提供一种瞳孔追踪方法,其包括步骤:
8.瞳孔分割:获取实时瞳孔原始输入图像,对其相邻的图像层之间应用最大池化层后调整通道数;
9.将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器;将通道数已调整的图像依次经过若干级别的所述编码器的下采样处理,输出每一级别的下采样特征图像;
10.将最后一级别的下采样特征图像使用2
×
2上卷积处理后与上一级别的下采样特征图像连起来进行上采样处理;该上采样处理结果继续使用2
×
2上卷积处理后与上二级别
的下采样特征图像连起来进行上采样处理,依次类推,直至第一级别完成上采样处理后,输出与所述原始输入图像相同分辨率的二维瞳孔分割结果;
11.瞳孔追踪定位:根据所述二维瞳孔边界图像的边界点坐标,获取瞳孔三维坐标,搭建三维瞳孔追踪器,获得瞳孔中心三维定位。
12.优选的是,获取瞳孔三维坐标,包括以下步骤:
13.根据二维瞳孔边界图像的边界点坐标,计算瞳孔中心坐标和虹膜半径,标注包括虹膜像素、瞳孔罩像素、虹膜边缘像素的特征;
14.提取标注的所述特征,通过所述特征进行瞳孔跟踪,得到每帧瞳孔坐标;
15.根据瞳孔视觉轴的三维特征和时间之间的框架,结合每帧瞳孔坐标,采用基于抽样的算法获取瞳孔三维坐标。
16.优选的是,搭建三维瞳孔追踪器,获得瞳孔中心三维定位,包括以下步骤:
17.对连续多帧二维瞳孔边界图像利用最小二乘法拟合出一个球面并选任一帧进行标定,获得瞳孔三维模型;
18.利用多线性表达模型将二维掩模的均值偏移中心和边缘像素反向投影到所述瞳孔三维模型中,在最大后验框架中建立三维瞳孔追踪器,获得瞳孔中心的三维位置。
19.一种应用瞳孔追踪方法进行bppv与vm分类诊断的方法,其包括以下步骤:
20.获取实时瞳孔视频;
21.对所述实时瞳孔视频进行瞳孔分割和追踪定位,获得瞳孔中心三维定位,记录实时眼震视频;
22.对所述实时眼震视频进行信号处理、提取实时三维眼震特征;
23.使用支持向量机对bppv眼震视频和vm眼震视频分别提取的眼震特征进行训练,搭建分类诊断模型;
24.将提取的所述实时三维眼震特征送入所述分类诊断模型,获得bppv和vm的分类诊断结果。
25.优选的是,所述眼震特征至少包括:发作频率、眼球震颤持续时间、眼球震颤发作原因、眼球震颤方向、慢相速度和慢相持续时间以及三维瞳孔的视觉轴特征。
26.优选的是,所述信号处理至少包括:滤波、快慢相识别、眼震方向匹配、提取眼震特征参数。
27.优选的是,所述快慢相识别包括步骤:
28.对滤波后的眼震信号进行极值点检测,利用最小二乘法分段拟合眼震信号,实现快慢相识别。
29.优选的是,所述眼震方向匹配包括步骤:
30.将慢相记为-1,快相记为 1,不满足快慢相的条件记为0,以[-1, 1,-1, 1,-1, 1]和[ 1,-1, 1,-1, 1,-1]分别作为慢相匹配模板和快相匹配模板;
[0031]
将眼震信号曲线快慢相判断结果分别与所述慢相匹配模板和快相匹配模板进行模板匹配,模板匹配获得最大值的模板方向即为眼震方向。
[0032]
优选的是,获取实时瞳孔视频,包括以下步骤:
[0033]
搭建基于耳石运动的虚拟仿真:
[0034]
通过结合刚体动力学和碰撞检测模块,在动力学世界上执行blender模型的步进
模拟,实现耳石依赖重力作用进行刚体碰撞运动;
[0035]
借助opengl的可视化渲染以及bullet物理引擎实现耳石空间运动模拟;
[0036]
基于所述耳石空间运动模拟,通过膜迷路模型、空间姿态传感器实现半规管空间位置、头部空间位置和耳石空间的三维导航;
[0037]
基于耳石运动虚拟仿真的三维导航,诱发眼震,获取实时瞳孔视频。
[0038]
优选的是,还包括步骤:
[0039]
在所述bullet物理引擎中选择碰撞图形:耳石模型由btconvexhullshape构造并传入顶点数组,创建一个凸三角网格;半规管模型由btbvhtrianglemeshshape构造并传入三角网格访问接口,创建一个凹三角网格。
[0040]
本发明至少包括以下有益效果:
[0041]
1.本发明提供的瞳孔追踪方法,将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器训练的实时卷积神经网络,对实时瞳孔视频进行二维分割,可以减少网络的参数数量和运行时间,有利于提高瞳孔分割的速度与准确性;
[0042]
2.本发明通过计算瞳孔中心坐标和虹膜半径,标注和提取包括虹膜像素、瞳孔罩像素、虹膜边缘像素的特征,通过特征进行瞳孔跟踪,得到每帧瞳孔坐标,再根据瞳孔视觉轴的三维特征和时间之间的框架,结合每帧瞳孔坐标,采用基于抽样的算法获取瞳孔三维坐标,为后续三维可视化提供数据支撑。
[0043]
3.本发明提供的基于瞳孔追踪方法进行bppv与vm分类诊断方法中,一方面,将深度卷积神经网络应用于瞳孔分割,将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器,训练出一个实时卷积神经网络,来对实时瞳孔视频进行二维分割,可以减少网络的参数数量和运行时间,有利于提高瞳孔分割的速度与准确性;另一方面,将机器学习应用于bppv和vm的分类诊断,基于眼震特征建立支持向量机的分类诊断模型,有利于提升bppv和vm鉴别诊断的准确性。
[0044]
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
[0045]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0046]
图1为本发明提供的瞳孔追踪方法的流程图;
[0047]
图2为本发明提供的获取瞳孔三维坐标的流程图;
[0048]
图3为本发明提供的搭建三维瞳孔追踪器获得瞳孔中心三维定位的流程图;
[0049]
图4为本发明提供的通过unet网络训练的实时卷积神经网络对实时瞳孔视频进行二维分割过程的示意图;
[0050]
图5为本发明提供的应用瞳孔追踪方法进行bppv与vm分类诊断方法的流程图;
[0051]
图6为本发明提供的眼震拟合对比示意图;
[0052]
图7为本发明提供的眼震方向匹配方法流程图;
[0053]
图8为本发明提供的获取实时瞳孔视频方法流程图。
具体实施方式
[0054]
下面将结合附图对本发明实施例的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0055]
下面所述的本发明不同实施方式中使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加;所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
[0056]
《实施方式1》
[0057]
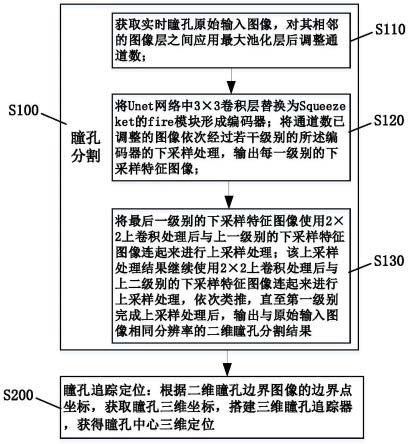
如图1所示,本发明实施方式提供一种瞳孔追踪方法其包括s100瞳孔分割和s200瞳孔追踪定位两个步骤。具体地,s100瞳孔分割包括步骤:
[0058]
s110,获取实时瞳孔原始输入图像,对其相邻的图像层之间应用最大池化层后调整通道数;
[0059]
s120,将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器;将通道数已调整的图像依次经过若干级别的所述编码器的下采样处理,输出每一级别的下采样特征图像;
[0060]
s130,将最后一级别的下采样特征图像使用2
×
2上卷积处理后与上一级别的下采样特征图像连起来进行上采样处理;该上采样处理结果继续使用2
×
2上卷积处理后与上二级别的下采样特征图像连起来进行上采样处理,依次类推,直至第一级别完成上采样处理后,输出与原始输入图像相同分辨率的二维瞳孔分割结果;
[0061]
s200瞳孔追踪定位包括步骤:根据二维瞳孔边界图像的边界点坐标,获取瞳孔三维坐标,搭建三维瞳孔追踪器,获得瞳孔中心三维定位。
[0062]
上述实施方式中,步骤s120中将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器,可以减少网络的参数数量和运行时间,fire模块将参数数从500k减少到50k,浮点运算从132.53m减少到5.81m,但仍然可以得到相同的分割结果;fire模块形成的编码器的级别数量与步骤s10中调整通道数的设置应该与图像大小和通道相匹配,是为了保证二维瞳孔分割结果与所述原始输入图像相同分辨率。步骤s130中二维瞳孔分割结果包括中心定位和边缘检测。步骤s200获得瞳孔中心三维定位,有利于瞳孔追踪与定位的可视化处理。
[0063]
该实施方式通过unet网络训练的实时卷积神经网络,对实时瞳孔视频进行二维分割,提取虹膜的外部轮廓(即边缘),有利于提高瞳孔分割的速度与准确性,提高后续三维跟踪器的鲁棒性和准确性。
[0064]
作为上述实施方式的进一步优选,获取瞳孔三维坐标,如图2所示,包括以下步骤:
[0065]
s210,根据二维瞳孔边界图像的边界点坐标,计算瞳孔中心坐标和虹膜半径,标注包括虹膜像素、瞳孔罩像素、虹膜边缘像素的特征;
[0066]
s220,提取标注的特征,通过特征进行瞳孔跟踪,得到每帧瞳孔坐标;
[0067]
s230,根据瞳孔视觉轴的三维特征和时间之间的框架,结合每帧瞳孔坐标,采用基
于抽样的算法获取瞳孔三维坐标。
[0068]
该实施方式中,步骤s210中自动标注虹膜像素、瞳孔罩像素、虹膜边缘像素等特征,是为了后续可以实现瞳孔中心定位和虹膜边缘检测。步骤s230获取瞳孔三维坐标,为后续瞳孔三维定位和可视化提供坐标数据支撑。
[0069]
作为上述实施方式的进一步优选,搭建三维瞳孔追踪器,获得瞳孔中心三维定位,如图3所示,包括以下步骤:
[0070]
s240,对连续多帧二维瞳孔边界图像利用最小二乘法拟合出一个球面并选任一帧进行标定,获得瞳孔三维模型;
[0071]
s250,利用多线性表达模型将二维掩模的均值偏移中心和边缘像素反向投影到瞳孔三维模型中,在最大后验框架中建立三维瞳孔追踪器,获得瞳孔中心的三维位置。
[0072]
该实施方式中,通过最小二乘法拟合出一个球面后再选任一帧进行标定,即可构建一个三维坐标模型,再利用多线性表达模型将二维掩模的均值偏移中心和边缘像素反向投影到瞳孔三维模型中,在最大后验框架中建立三维瞳孔追踪器,获得瞳孔中心的三维位置。最后使用每个瞳孔中心的坐标来表示三维瞳孔状态,并通过提取的二维虹膜和瞳孔像素、虹膜的外轮廓和三维瞳孔状态跟踪瞳孔的视觉轴的三维特征。
[0073]
为了更好地说明s100中通过unet网络训练的实时卷积神经网络对实时瞳孔视频进行二维分割的过程,如图4所示,下面做进一步示例说明。
[0074]
将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器。获取实时瞳孔的原始输入图像的大小为48
×
96,有3个通道,然后在相邻的图像层之间应用最大池化层,在每层后将通道数乘以2,再经过4个级别的fire模块编码器依次的下采样处理,可以得到具有32个频道且尺寸为6
×
12的下采样特征图。使用2
×
2上卷积在每个级别上对下采样特征图进行上采样。每次上采样后,将上采样的特征图像与相应的编码器下采样特征图像连接起来,将来自高层的更明确的信息与来自编码器下层的位置信息结合起来。对应于编码器中的池化层,两次使用2
×
2上卷积以获得具有与输入图像相同分辨率的二维瞳孔分割结果。
[0075]
《实施方式2》
[0076]
本实施方式提供一种应用实施方式1的瞳孔追踪方法进行bppv与vm分类诊断方法,如图5所示,其包括以下步骤:
[0077]
s310,获取实时瞳孔视频;
[0078]
s320,对实时瞳孔视频进行瞳孔分割和追踪定位,获得瞳孔中心三维定位,记录实时眼震视频;
[0079]
s330,对实时眼震视频进行信号处理、提取实时三维眼震特征;
[0080]
s340,使用支持向量机对bppv眼震视频和vm眼震视频分别提取的眼震特征进行训练,搭建分类诊断模型;
[0081]
s350,将提取的实时三维眼震特征送入分类诊断模型,获得bppv和vm的分类诊断结果。
[0082]
该实施方式中,一方面,将深度卷积神经网络应用于瞳孔分割,步骤s320中的瞳孔分割和追踪定位采用实施方式1中的方法,将unet网络中3
×
3卷积层替换为squeezeket的fire模块形成编码器,训练出一个实时卷积神经网络,来对实时瞳孔视频进行二维分割,可
以减少网络的参数数量和运行时间,有利于提高瞳孔分割的速度与准确性;另一方面,将机器学习应用于bppv和vm的分类诊断,支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其基于结构风险最小化原理,能够克服模型训练过程中的过拟合问题,有很强的泛化能力;支持向量机使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。基于眼震特征建立支持向量机的分类诊断模型,有利于提升bppv和vm鉴别诊断的准确性。
[0083]
作为上述实施方式的进一步优选,眼震特征至少包括:发作频率、眼球震颤持续时间、眼球震颤发作原因、眼球震颤方向、慢相速度和慢相持续时间以及三维瞳孔的视觉轴特征。该实施方式中,优选发作频率、眼球震颤持续时间、眼球震颤发作原因、眼球震颤方向、慢相速度和慢相持续时间等参数作为眼震特征,提高眼震识别精度,尤其是加入三维瞳孔的视觉轴特征后,利于后续三维瞳孔可视化操作。
[0084]
作为上述实施方式的进一步优选,信号处理至少包括:滤波、快慢相识别、眼震方向匹配、提取眼震特征参数。该实施方式中,滤波采用5点平滑滤波,滤除由跟踪引擎的小扰动误差和由受试者引起的干扰。
[0085]
作为上述实施方式的进一步优选,快慢相识别包括步骤:对滤波后的眼震信号进行极值点检测,利用最小二乘法分段拟合眼震信号,实现快慢相识别。眼震拟合对比图如图6所示,通过最小二乘法分段拟合眼震信号,可以较好地实现快慢识别。
[0086]
作为上述实施方式的进一步优选,如图7所示,眼震方向匹配包括步骤:
[0087]
s410,将慢相记为-1,快相记为 1,不满足快慢相的条件记为0,以[-1, 1,-1, 1,-1, 1]和[ 1,-1, 1,-1, 1,-1]分别作为慢相匹配模板和快相匹配模板;
[0088]
s420,将眼震信号曲线快慢相判断结果分别与慢相匹配模板和快相匹配模板进行模板匹配,模板匹配获得最大值的模板方向即为眼震方向。
[0089]
该实施方式是通过自定义慢相匹配模板和快相匹配模板来实现眼震方向匹配,具有较好的匹配效果。
[0090]
作为上述实施方式的进一步优选,如图8所示,获取实时瞳孔视频,包括以下步骤:
[0091]
s510,搭建基于耳石运动的虚拟仿真;
[0092]
s520,通过结合刚体动力学和碰撞检测模块,在动力学世界上执行blender模型的步进模拟,实现耳石依赖重力作用进行刚体碰撞运动;
[0093]
s530,借助opengl的可视化渲染以及bullet物理引擎实现耳石空间运动模拟;
[0094]
s540,基于耳石空间运动模拟,通过膜迷路模型、空间姿态传感器实现半规管空间位置、头部空间位置和耳石空间的三维导航;
[0095]
s550,基于耳石运动虚拟仿真的三维导航,诱发眼震,获取实时瞳孔视频。
[0096]
该实施方式中,步骤s510中仿真运算前,设置耳石的物理参数,包括重力系数、摩擦系数、反弹系数,以便获得更加真实的仿真效果。通过传输由病人头部运动而改变的欧拉角,实现半规管模型在仿真世界的运动;
[0097]
步骤s530中,bullet物理引擎可以构造仿真世界,渲染病人治疗场景、半规管和耳石,分析半规管和耳石的物理特性从而对场景的每一帧进行物理模拟。再根据耳石的运动状态、受力方向进行碰撞检测,模拟耳石在重力影响下遵循牛顿力学原理应进行的位移转换。更具体地,bullet物理引擎将创建解算器,用于求解约束方程,对场景中的每一个物体
进行仿真运算,计算出各个耳石所受到的合力和合力矩以进行碰撞检测,得到耳石在重力等作用下的最终位置。在大多数情况下仿真循环会在每一帧排序之前遍历所有的对象,对于每一个对象将会使用motionstate来更新呈现对象的位置,如果发生碰撞,将响应碰撞并进行碰撞处理。opengl将读取btconvexhullshape中的顶点数据,以三角面的形式绘制三维模型并通过矩阵变换以正交投影显示,由时间定时器实时监测,不断的重新绘制耳石的位置以实现模型的动态化。
[0098]
上述实施方式通过结合刚体动力学和碰撞检测模块,在动力学世界上执行blender模型的步进模拟,实现耳石依赖重力作用进行刚体碰撞运动,然后借助opengl的可视化渲染以及bullet物理引擎实现耳石空间运动模拟,最终通过膜迷路模型、空间姿态传感器以及耳石运动虚拟仿真技术实现半规管空间位置、头部空间位置和耳石空间的高精度三维导航,提高运动空间一致性,辅助医生诱发眼震反应,获取实时瞳孔视频。
[0099]
作为上述实施方式的进一步优选,应用bullet物理引擎还包括选择碰撞图形:耳石模型由btconvexhullshape构造并传入顶点数组,创建一个凸三角网格;半规管模型由btbvhtrianglemeshshape构造并传入通用高性能三角网格访问接口,创建一个凹三角网格。
[0100]
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申的显而易见的变化或变动仍处于本发明创造的保护范围之中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。