基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法
技术领域
1.本发明涉及粉体粒度控制技术领域,尤其涉及一种基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法。
背景技术:
2.实际工业过程中,变量的pdf形状控制问题一直极具挑战性,例如:造纸过程中纸张的纤维长度分布形状控制、燃烧过程中火焰温度场分布的形状控制等都可看作是典型的随机系统分布控制问题。具体的,以食品加工行业的粮食生产过程为例,加工后粮食的粉体粒度大小需要满足一定的要求,否则会影响后面工序的进行;因此对粉体粒度大小的精确控制,既可以为后续食品加工工序提供更高质量的原材料,而且能降低生产过程的能耗。但是目前实际生产过程中,常规的做法是将粉体粒度的均值和方差作为判断粉体质量的依据,然而对于一个实际的随机系统来说,均值和方差并不能准确反映输出变量的全部随机分布特性。因此,使用粉体粒度概率密度函数(probability density function,pdf)形状取代传统的均值和方差作为粉体质量的指标至关重要,在实际生产过程中势必表现出更广泛的应用。
3.在使用盘磨系统生产粉体的过程中,喂料量、磨盘压力、磨盘转速、磨盘间隙等多个变量都会影响粉体粒度pdf形状,考虑到变量的可测量性以及对于实际粉体粒度pdf的影响程度,可以确定磨盘间隙和喂料量作为系统的控制量输入去改变盘磨系统的动作。所以,建立以磨盘间隙和喂料量为控制量输入,以粉体粒度pdf形状为输出的盘磨系统的随机分布模型对提升粉体质量、降低生产能耗具有重要意义。
4.专利公开号cn109695174a公开了“磨浆过程纤维长度分布的pdf形状预测方法及系统”,该方法聚焦造纸磨浆过程中纤维长度分布的pdf形状预测,采用rbf神经网络近似纤维长度分布的pdf数据,再采用随机权神经网络建立权值的非线性动态模型,进而得到纤维长度分布的pdf形状预测模型。
5.专利公开号cn108846178a公开了“一种盘磨系统的粉体粒度分布形状估计方法及其系统”,该方法采用rbf神经网络对权值进行解耦计算,再采用bp神经网络构建权值的非线性动态模型,由此获得权值向量的估计值,并在此基础上对粉体粒度分布形状的概率密度函数进行估计。
6.然而,在上述专利所提的pdf形状建模方法中,普遍采用高斯型径向基函数神经网络(radial basis function neural network,rbf-nn)对输出随机变量的pdf形状进行近似,因此近似的效果强烈依赖于所选定的高斯基函数的中心和宽度,如果基函数的选择不够准确会极大影响后续的建模精度;而现有方法对于基函数的选择往往依赖于人工经验,存在参数选择困难、建模效果差等缺点。另一方面,现有方法大多选择采用各种结构的神经网络建立权值的非线性动态模型,存在模型结构复杂、建模数据要求高、参数选择困难等问题,考虑到模型的实际应用效果,应当使用更加简单高效的权值的线性动态模型加以替代。
技术实现要素:
7.针对现有技术的不足,本发明提供一种基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法。
8.一种基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法,具体包括以下步骤:
9.步骤1,采集盘磨系统运行过程中的磨盘间隙和喂料量的控制量数据,以及粉体粒度pdf形状数据;
10.步骤2、采用高斯型径向基函数神经网络rbf-nn,对粉体粒度pdf形状所对应的权值向量进行解耦计算,从而将粉体粒度pdf表示为一组基函数和所对应权值的乘积;
11.步骤2.1、将磨盘间隙、喂料量作为系统的输入变量,粉体粒度pdf形状作为系统的输出变量。
12.步骤2.2、采用高斯型径向基函数神经网络rbf-nn逼近所述粉体粒度pdf形状。
13.所述逼近的方法具体是:
14.对于非高斯随机分布的动态系统,将粉体粒度表示为一致有界的随机变量y∈[a,ζ],其中a和ξ表示y的取值范围;
[0015]
令u(k)∈rm为控制粉体粒度pdf形状的控制量输入,rm表示m维列向量;
[0016]
盘磨过程的粉体粒度pdf形状由其在每个采样时刻k的概率密度函数γ(y,u(k))来表示:
[0017][0018]
式中,p(a≤y《ξ,u(k))表示当对盘磨系统施加控制输入u(k)时输出粉体粒度落在区间[a,ξ]内的概率;
[0019]
假设区间[a,b]是预先给定的,其中a、b分别表示随机变量y取值的左右端点,且pdf是连续有界的,则粉体粒度pdf形状用如下的高斯型径向基函数神经网络rbf-nn来逼近:
[0020][0021]
式中,w
l
(u(k))是由控制输入u(k)控制的基函数r
l
(y)的相应权重,l表示高斯型径向基函数神经网络rbf-nn的第l个网络节点,n为网络节点数;
[0022]
在区间[a,b]内定义的基函数r
l
(y)如下:
[0023][0024]
式中,μ
l
和σ
l
分别表示第l个基函数的中心和宽度;
[0025]
则此时所述粉体粒度pdf形状表示为基函数和对应权值的乘积
[0026][0027]
式中,c(y)为n个基函数组成的行向量,v(k)为对应的权值向量,rn(y)和wn(u(k))分别表示第n个基函数和对应的权值。
[0028]
步骤2.3、对粉体粒度pdf形状所对应的权值向量进行解耦计算;
[0029]
所述解耦计算为,利用矩阵逆运算求解权值向量,如下:
[0030]
v(k)=(c
t
(y)c(y))-1ct
(y)γ(y,u(k))
[0031]
步骤3、采用迭代学习的方法选择一组最优的高斯基函数,使得其对于粉体粒度pdf形状的逼近误差最小;
[0032]
所述迭代学习为,在每次迭代中不断的调整rbf-nn基函数的中心和宽度值,最小化粉体粒度实际测量pdf与粉体粒度近似pdf之间的误差,从而选出一组最优的高斯基函数。
[0033]
首先,令m个粉体粒度实际测量pdf的向量形式如下:
[0034]
g(y)=[g1(y),g2(y),...,gm(y)]
[0035]
式中,m表示采样点的总数,gm(y)表示第m个采样点处的实际测量pdf;
[0036]
假设第i次迭代后获得的粉体粒度近似pdf为:
[0037]
γi(y)=[γ
i,1
(y),γ
i,2
(y),...,γ
i,m
(y)]
[0038]
式中,γ
i,m
(y)表示第i次迭代后第m个采样点处的近似pdf;
[0039]
为了评价粉体粒度pdf形状近似的效果,定义如下性能指标函数:
[0040][0041]
式中,j
i,m
表示第i次迭代后第m个采样点的粉体粒度近似pdf与实际pdf之间的逼近误差。
[0042]
写成向量形式如下:
[0043]ei
=[j
i,1
,j
i,2
,...,j
i,m
]
t
[0044]
式中,j
i,m
表示第i次迭代后第m个采样点的近似pdf与实际pdf之间的逼近误差,ei表示第i次迭代后所有采样点的逼近误差构成的误差向量,且ei所有分量都是非负的。
[0045]
采用一种基于迭代学习规则的中心和宽度值更新算法来调整基函数参数:
[0046][0047]
式中,μ
l,i
和σ
l,i
分别表示第i次迭代后第l个基函数的中心和宽度值,学习参数αu和β
σ
分别定义如下:
[0048][0049]
式中,λi和λi′
是权重系数,ζu和ζ
σ
是学习率。
[0050]
步骤4、采用子空间辨识,建立权值的线性动态模型。
[0051]
所述权值的线性动态模型的构建方法为:
[0052]
不考虑过程和测量噪声,用如下确定性系统的状态空间模型描述权值的线性动态模型:
[0053][0054]
式中,uk∈rm、vk∈r
l
和xk∈rn分别表示第k个采样时刻的输入向量、输出向量和状
态向量,rm、r
l
和rn分别表示m维、l维和n维列向量,a,b,c,d为相应维数的系统矩阵。
[0055]
步骤4.1、确定子空间建模的输入和输出变量;其中所述输入变量为磨盘间隙和喂料量的控制量数据,所述输出数据为粉体粒度pdf形状对应的权值向量数据;
[0056]
步骤4.2、构造hankel数据矩阵:
[0057][0058][0059][0060][0061]
式中,hankel矩阵包含i块行和j块列,即上述矩阵中的每个元素均为列向量;
[0062]
其中,uk∈rm表示第k个采样时刻的输入向量,vk∈r
l
表示第k个采样时刻的输出向量,k的取值范围是[0,2i j-2]。
[0063]
步骤4.3、利用斜投影公式计算斜投影oi和o
i-1
:
[0064][0065][0066]
式中,w
p
=[u
p v
p
]
t
,w
p
=[u
p v
p
]
t
,矩阵u
p
、u
f-、v
p
和v
f-的定义方式如下:
[0067][0068]
[0069][0070][0071]
式中,上标 和-分别表示相应矩阵行块数增加一行和减少一行。
[0072]
步骤4.4、对斜投影oi进行奇异值分解,得到广义能观矩阵γi和状态向量序列的估计值同时确定系统的阶次n:
[0073][0074]
式中,u1、u2、s1、s2、v1、v2均为矩阵oi分解得到的子矩阵。
[0075]
步骤4.5、对斜投影o
i-1
进行奇异值分解,计算得到γ
i-1
和下一时刻状态向量序列的估计值
[0076][0077]
式中,u
a1
、u
a2
、s
a1
、s
a2
、v
a1
、v
a2
均为矩阵o
i-1
分解得到的子矩阵;γ
i-1
表示γi去掉最后l行得到的子矩阵。
[0078]
步骤4.6、通过求解如下最小二乘问题,提取系统矩阵a,b,c,d
[0079][0080]
式中,ui=[u
i u
i 1 ... u
i j-1
],vi=[v
i v
i 1 ... v
i j-1
]。
[0081]
步骤5、利用步骤4建立的权值的线性动态模型,结合步骤2、步骤3中所述rbf-nn对粉体粒度pdf形状的近似,得到盘磨系统的随机分布模型,即粉体粒度pdf形状的动态模型;
[0082]
所述粉体粒度pdf形状的动态模型为:
[0083]
[0084]
采用上述技术方案所产生的有益效果在于:
[0085]
本发明提供一种基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法,在rbf-nn基函数选择方面,抛弃以往依据经验人工选择参数的方式,转而采用迭代学习算法选择一组具有最优中心值和宽度的高斯基函数,使得其对于粉体粒度pdf形状的逼近误差最小,极大改善了建模效果。另一方面,在权值的动态建模方面,针对目前普遍采用神经网络建立权值的非线性动态模型所造成的模型结构复杂、参数选择困难、难以实际应用等问题,采用子空间辨识建立控制量输入和权值向量之间的线性动态模型,子空间辨识在不需要任何先验知识的基础上,直接基于历史数据建立模型,模型的系统矩阵直接从特定矩阵的行和列中提取出来,既可以保证良好的建模精度,又可以降低模型复杂度,特别符合实际应用时对于模型简单易用的要求。在保证良好的粉体粒度pdf形状建模效果的同时,为后续粉体粒度pdf形状的跟踪控制奠定了良好的模型基础。本发明设计合理,易于实现,具有很好的实用价值。
附图说明
[0086]
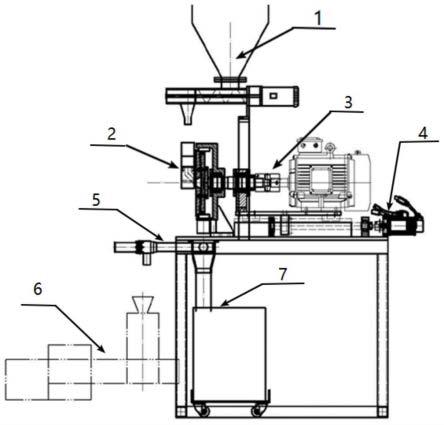
图1为本发明具体实施方式中所述盘磨系统结构示意图;
[0087]
图中:1-喂料装置;2-磨盘研磨装置;3-磨盘转速调节装置;4-磨盘间隙伺服控制装置;5-取样装置;6-激光粒度仪;7-粉体回收装置;
[0088]
图2是本发明具体实施方式中所述盘磨系统的粉体粒度pdf形状建模方法流程图;
[0089]
图3为本发明具体实施方式中所述粉体粒度pdf形状实际测量值示意图;
[0090]
图4是本发明具体实施方式中不采用迭代学习时所述粉体粒度pdf形状建模效果示意图;
[0091]
图5是本发明具体实施方式中不采用迭代学习时所述粉体粒度pdf形状建模误差示意图;
[0092]
图6是本发明具体实施方式中采用迭代学习时所述粉体粒度pdf形状建模效果示意图;
[0093]
图7是本发明具体实施方式中采用迭代学习时所述粉体粒度pdf形状建模误差示意图。
具体实施方式
[0094]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0095]
本实施方式提供一种盘磨系统,如图1所示,包括喂料装置1、磨盘研磨装置2、磨盘转速调节装置3、磨盘间隙伺服控制装置4、取样装置5、激光粒度仪6、粉体回收装置7;
[0096]
所述盘磨系统运行过程为:首先,通过喂料装置1使物料(如小麦、大米等)均匀的进入磨盘研磨装置2;然后,磨盘研磨装置2在磨盘转速调节装置3和磨盘间隙伺服控制装置4的控制之下,以一定的转速和间隙将物料研磨成粉体;将得到的粉体通过取样装置5进行间歇式取样之后送入激光粒度仪6中进行检测并得到粉体粒度分布pdf形状数据;多余的粉体通过粉体回收装置7进行回收;
[0097]
本实施方式通过盘磨系统实际运行时采集到的现场输入输出数据,建立盘磨系统
的随机分布模型。所述输入数据为磨盘间隙和喂料量的控制量数据,所述输出数据为粉体粒度pdf形状数据。
[0098]
一种基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法,如图2所示,具体包括以下步骤:
[0099]
步骤1,采集盘磨系统运行过程中的磨盘间隙和喂料量的控制量数据,以及粉体粒度pdf形状数据;
[0100]
步骤2、采用高斯型径向基函数神经网络rbf-nn,对粉体粒度pdf形状所对应的权值向量进行解耦计算,从而将粉体粒度pdf表示为一组基函数和所对应权值的乘积;
[0101]
步骤2.1、将磨盘间隙、喂料量作为系统的输入变量,粉体粒度pdf形状作为系统的输出变量。
[0102]
步骤2.2、采用高斯型径向基函数神经网络rbf-nn逼近所述粉体粒度pdf形状。
[0103]
所述逼近的方法具体是:
[0104]
对于盘磨系统这种非高斯随机分布的动态系统,将粉体粒度表示为一致有界的随机变量y∈[a,ζ],其中a和ξ表示y的取值范围;
[0105]
令u(k)∈rm为控制粉体粒度pdf形状的控制量输入,rm表示m维列向量;
[0106]
盘磨过程的粉体粒度pdf形状由其在每个采样时刻k的概率密度函数γ(y,u(k))来表示:
[0107][0108]
式中,p(a≤y《ξ,u(k))表示当对盘磨系统施加控制输入u(k)时输出粉体粒度落在区间[a,ξ]内的概率;
[0109]
假设区间[a,b]是预先给定的,其中a、b分别表示随机变量y取值的左右端点,且pdf是连续有界的,则粉体粒度pdf形状用如下的高斯型径向基函数神经网络rbf-nn来逼近:
[0110][0111]
式中,w
l
(u(k))是由控制输入u(k)控制的基函数r
l
(y)的相应权重,l表示高斯型径向基函数神经网络rbf-nn的第l个网络节点,n为网络节点数;
[0112]
在区间[a,b]内定义的基函数r
l
(y)如下:
[0113][0114]
式中,μ
l
和σ
l
分别表示第l个基函数的中心和宽度;
[0115]
则此时所述粉体粒度pdf形状表示为基函数和对应权值的乘积
[0116][0117]
式中,c(y)为n个基函数组成的行向量,v(k)为对应的权值向量,rn(y)和wn(u(k))分别表示第n个基函数和对应的权值。
[0118]
步骤2.3、对粉体粒度pdf形状所对应的权值向量进行解耦计算;
[0119]
所述解耦计算为,利用矩阵逆运算求解权值向量,如下:
[0120]
v(k)=(c
t
(y)c(y))-1ct
(y)γ(y,u(k))
[0121]
可以看出,当粉体粒度pdf形状数据是可测的,且rbf-nn基函数的中心和宽度确定时,由矩阵逆运算可以方便的求得对应的权值向量。
[0122]
步骤3、采用迭代学习的方法选择一组最优的高斯基函数,使得其对于粉体粒度pdf形状的逼近误差最小;
[0123]
所述迭代学习为,在每次迭代中不断的调整rbf-nn基函数的中心和宽度值,最小化粉体粒度实际测量pdf与粉体粒度近似pdf之间的误差,从而选出一组最优的高斯基函数。
[0124]
首先,令m个粉体粒度实际测量pdf的向量形式如下:
[0125]
g(y)=[g1(y),g2(y),...,gm(y)]
[0126]
式中,m表示采样点的总数,gm(y)表示第m个采样点处的实际测量pdf;
[0127]
假设第i次迭代后获得的粉体粒度近似pdf为:
[0128]
γi(y)=[γ
i,1
(y),γ
i,2
(y),...,γ
i,m
(y)]
[0129]
式中,γ
i,m
(y)表示第i次迭代后第m个采样点处的近似pdf;
[0130]
为了评价粉体粒度pdf形状近似的效果,定义如下性能指标函数:
[0131][0132]
式中,j
i,m
表示第i次迭代后第m个采样点的粉体粒度近似pdf与实际pdf之间的逼近误差。
[0133]
写成向量形式如下:
[0134]ei
=[j
i,1
,j
i,2
,...,j
i,m
]
t
[0135]
式中,j
i,m
表示第i次迭代后第m个采样点的近似pdf与实际pdf之间的逼近误差,ei表示第i次迭代后所有采样点的逼近误差构成的误差向量,且ei所有分量都是非负的。
[0136]
采用一种基于迭代学习规则的中心和宽度值更新算法来调整基函数参数:
[0137][0138]
式中,μ
l,i
和σ
l,i
分别表示第i次迭代后第l个基函数的中心和宽度值,学习参数αu和β
σ
分别定义如下:
[0139][0140]
式中,λi和λi′
是权重系数,ζu和ζ
σ
是学习率。
[0141]
步骤4、采用子空间辨识,建立权值的线性动态模型。
[0142]
所述权值的线性动态模型的构建方法为:
[0143]
不考虑过程和测量噪声,用如下确定性系统的状态空间模型描述权值的线性动态模型:
[0144]
[0145]
式中,uk∈rm、vk∈r
l
和xk∈rn分别表示第k个采样时刻的输入向量、输出向量和状态向量,rm、r
l
和rn分别表示m维、l维和n维列向量,a,b,c,d为相应维数的系统矩阵。
[0146]
步骤4.1、确定子空间建模的输入和输出变量;其中所述输入变量为磨盘间隙和喂料量的控制量数据,所述输出数据为粉体粒度pdf形状对应的权值向量数据;
[0147]
步骤4.2、构造hankel数据矩阵:
[0148][0149][0150][0151][0152]
式中,hankel矩阵包含i块行和j块列,即上述矩阵中的每个元素均为列向量;
[0153]
其中,uk∈rm表示第k个采样时刻的输入向量,vk∈r
l
表示第k个采样时刻的输出向量,k的取值范围是[0,2i j-2]。
[0154]
步骤4.3、利用斜投影公式计算斜投影oi和o
i-1
:
[0155][0156][0157]
式中,w
p
=[u
p v
p
]
t
,w
p
=[u
p v
p
]
t
,矩阵u
p
、u
f-、v
p
和v
f-的定义方式如下:
[0158][0159]
[0160][0161][0162]
式中,上标 和-分别表示相应矩阵行块数增加一行和减少一行。
[0163]
步骤4.4、对斜投影oi进行奇异值分解,得到广义能观矩阵γi和状态向量序列的估计值同时确定系统的阶次n:
[0164][0165]
式中,u1、u2、s1、s2、v1、v2均为矩阵oi分解得到的子矩阵。
[0166]
步骤4.5、对斜投影o
i-1
进行奇异值分解,计算得到γ
i-1
和下一时刻状态向量序列的估计值
[0167][0168]
式中,u
a1
、u
a2
、s
a1
、s
a2
、v
a1
、v
a2
均为矩阵o
i-1
分解得到的子矩阵;γ
i-1
表示γi去掉最后l行得到的子矩阵。
[0169]
步骤4.6、通过求解如下最小二乘问题,提取系统矩阵a,b,c,d
[0170][0171]
式中,ui=[u
i u
i 1 ... u
i j-1
],vi=[v
i v
i 1 ... v
i j-1
]。
[0172]
步骤5、利用步骤4建立的权值的线性动态模型,结合步骤2、步骤3中所述rbf-nn对粉体粒度pdf形状的近似,得到盘磨系统的随机分布模型,即粉体粒度pdf形状的动态模型;
[0173]
所述粉体粒度pdf形状的动态模型为:
[0174]
[0175]
至此,便可建立以磨盘间隙和喂料量为控制量输入,以粉体粒度pdf形状为输出的盘磨系统的随机分布模型。
[0176]
为了验证所提出的基于迭代学习和子空间辨识的粉体粒度pdf形状建模方法的有效性,以盘磨系统平稳运行时采集到的55组现场输入输出数据为例,进行了试验。
[0177]
所述输入数据为磨盘间隙和喂料量的控制量数据,通过下位机plc采集得到。
[0178]
所述输出数据为粉体粒度pdf形状数据,通过激光粒度仪检测得到。
[0179]
所述激光粒度仪选择德国新帕泰克激光粒度仪,可将得到的粉体通过取样装置进行间歇式取样之后送入激光粒度仪中进行检测即可得到粉体粒度pdf形状数据。
[0180]
图3为粉体粒度pdf形状实际测量值,可以看出具有明显的非高斯特性,结合粉体粒度pdf形状的特点,本发明选取具有3个高斯型基函数的rbf-nn进行建模效果的验证。
[0181]
其中,不采用所述迭代学习方法时基函数的初始中心和宽度值为:
[0182]
μ1=0.3,μ2=0.5,μ3=0.8,
[0183]
采用所述迭代学习方法后最终得到基函数的中心和宽度值为:
[0184]
μ1=0.302,μ2=0.5002,μ3=0.784,
[0185]
之后采用所述粉体粒度pdf形状建模方法建立盘磨系统的随机分布模型,其中,图4为不采用迭代学习时粉体粒度pdf形状建模效果,图5为不采用迭代学习时粉体粒度pdf形状建模误差,图6为采用迭代学习时粉体粒度pdf形状建模效果,图7为采用迭代学习时粉体粒度pdf形状建模误差。
[0186]
可以看出相比较于不采用迭代学习时的建模效果,采用迭代学习之后选择出了一组参数更优的高斯基函数,极大改善了粉体粒度pdf形状建模效果;且粉体粒度pdf形状建模误差整体呈现出扁平的特征,表明采用所述子空间辨识建立权值的线性动态模型,在保证模型简单易用的同时还具有较高的精度,可以很好的逼近粉体粒度pdf形状实际测量值。
[0187]
以上描述仅为本公开的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本公开的实施例中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本公开的实施例中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。