基于竞争合作机制的emarl的无人机集群方法和装置
技术领域
1.本技术涉及无人机集群技术领域,特别是涉及一种基于竞争合作机制的emarl的无人机集群方法和装置。
背景技术:
2.群体智能中的群集是指许多动物倾向于成群结队有序移动的行为,如候鸟和黄蜂。群中的每个个体都与其他个体保持一定距离,保持相同的速度方向,并吸引周围不在群中的个体加入,遇到障碍时,他们会尽量保持队形。
3.群集任务被认为是一个完全合作的随机博弈任务,每个智能体都有一个评判器和几个智能体,采用分散的策略来训练智能体,但采用集中的方法来训练评判器,称为“集中式训练,分布式执行”(ctde),如coma、qmix和maddpg等方法。最直接的方法是使用独立的q学习作为智能体,称为iol方法。然而,上述面临着信用分配困难的问题,在团队奖励下,iql中每个智能体的贡献没有得到很好的区分。
技术实现要素:
4.基于此,有必要针对上述技术问题,提供一种基于竞争合作机制的emarl的无人机集群方法和装置,能够实现很好的无人机集群。
5.基于竞争合作机制的emarl的无人机集群方法,包括:
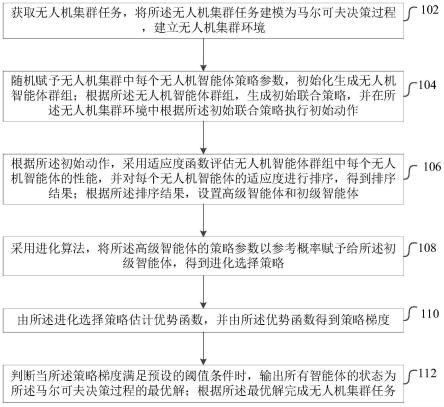
6.获取无人机集群任务,将所述无人机集群任务建模为马尔可夫决策过程,建立无人机集群环境;
7.随机赋予无人机集群中每个无人机智能体策略参数,初始化生成智能体群组;根据所述无人机智能体群组,生成初始联合策略,并在所述无人机集群环境中根据所述初始联合策略执行初始动作;
8.根据所述初始动作,采用适应度函数评估智能体群组中每个无人机智能体的性能,并对每个无人机智能体的适应度进行排序,得到排序结果;根据所述排序结果,设置高级智能体和初级智能体;
9.采用进化算法,将所述高级智能体的策略参数以参考概率赋予给所述初级智能体,得到进化选择策略;
10.由所述进化选择策略估计优势函数,并由所述优势函数得到策略梯度;
11.判断当所述策略梯度满足预设的阈值条件时,输出所有智能体的状态为所述马尔可夫决策过程的最优解;根据所述最优解完成无人机集群任务。
12.在一个实施例中,判断当所述策略梯度不满足预设的阈值条件时:
13.由所述策略梯度更新所有无人机智能体的当前策略参数;根据所有无人机智能体的当前策略参数,采用强化学习算法更新所有无人机智能体的当前联合策略;根据当前联合策略执行当前动作;
14.根据所述当前动作,采用适应度函数评估每个无人机智能体的当前性能,并对每
个无人机智能体的当前适应度进行排序,得到当前排序结果;根据当前排序结果,设置当前高级智能体和当前初级智能体;采用进化算法,将当前高级智能体的当前策略参数以参考概率赋予给当前初级智能体,得到当前进化选择策略;由当前进化选择策略估计当前优势函数,并由当前优势函数得到当前策略梯度,直至当前策略梯度满足预设的阈值条件。
15.在一个实施例中,由所述进化选择策略估计优势函数包括,
16.由所述进化选择策略得到回报函数:
[0017][0018]
式中,r
t
表示回报函数,r
t
表示t时刻的具体回报,γi表示折扣率,γ∈[0,1],r
t i
的权重小于r
t
;
[0019]rt,i
=r
sep,i
(t) r
ali,i
(t) r
coh,i
(t) r
obs,i
(t)
[0020]
式中,r
t
表示回报函数,t表示当前时刻,r
sep,i
(t)表示t时刻第i个无人机智能体所获得的基于分离规则的回报函数,r
ali,i
(t)表示t时刻第i个无人机智能体所获得的基于对齐规则得到的回报函数,r
coh,i
(t)表示t时刻第i个无人机智能体所获得的基于内聚规则得到的回报函数,r
obs,i
(t)表示t时刻第i个无人机智能体所获得的满足躲避障碍的回报函数;
[0021][0022]
式中,π(u|s,θ)表示估计的n个无人机智能体的联合策略,πi表示第i个无人机智能体的策略分布,ui表示第i个无人机智能体动作,τi表示第i个无人机智能体观察到的迹,θi表示第i个无人机智能体的策略参数;
[0023]
由所述回报函数估计优势函数:
[0024]aπ
(s
t
,u
t
)=q
π
(s
t
,u
t
)-v
π
(s
t
)
[0025][0026][0027]
式中,a
π
(s
t
,u
t
)表示优势函数,q
π
(s
t
,u
t
)表示状态作用值函数,v
π
(s
t
)表示状态值函数,t表示当前时刻,s
t
表示时间t时无人机集群环境的真实状态,u
t
表示时间t时无人机智能体动作,r
t
表示回报函数。
[0028]
在一个实施例中,由所述估计策略得到回报函数包括:
[0029][0030]
式中,r
sep,i
(t)表示t时刻第i个无人机智能体所获得的基于分离规则的回报函数,n表示智能体个数,i、j表示具体的某智能体,表示智能体i、j所在位置,ds为事先设定的距离最大值,β
sep
表示分离规则的回报系数。
[0031]
在一个实施例中,由所述估计策略得到回报函数还包括:
[0032][0033]
式中,r
ali,i
(t)表示第i个无人机智能体所获得的基于对齐规则的回报函数,n表示智能体个数,i、j表示具体的某智能体,θi、θj表示智能体i、j的方向,β
ali
表示对齐规则的回报系数。
[0034]
在一个实施例中,由所述估计策略得到回报函数还包括:
[0035][0036]
式中,r
coh,i
(t)表示第i个无人机智能体所获得的基于内聚规则的回报函数,n表示智能体个数,i、j表示具体的某智能体,r表示智能体所在位置,dc表示事先设定的距离最大值,β
coh
表示内聚规则的回报系数。
[0037]
在一个实施例中,由所述估计策略得到回报函数还包括:
[0038][0039]
式中,r
obs,i
(t)表示躲避障碍的回报函数,β
obs
表示满足躲避障碍的回报系数。
[0040]
在一个实施例中,由所述优势函数得到策略梯度包括:
[0041][0042]
式中,表示第i个无人机智能体进化选择下的策略更新梯度,表示基于策略下的期望,πi表示进化算法下的第i个智能体的策略,表示梯度算子,表示其优势函数。
[0043]
在一个实施例中,获取无人机集群任务,将所述无人机集群任务建模为马尔可夫决策过程包括:
[0044]
获取无人机集群任务,将所述无人机集群任务建模为一个部分可观测的马尔可夫决策过程,所述马尔可夫决策过程由描述了n个智能体行为的元组定义;
[0045]
其中,表示时间t时环境的真实状态,表示时间t的第k个智能体动作,映射表示智能体在状态s
t
采取联合行动u
t
然后过渡到s
t 1
的概率,表示第k个无人机智能体从环境中获得的状态,映射是将真实状态映射到观察状态的观察函数,表示在第k个无人机智能体在观察状态下采取动作后收到的回报。
[0046]
基于竞争合作机制的emarl的无人机集群装置,包括:
[0047]
获取模块,用于获取无人机集群任务,将所述无人机集群任务建模为马尔可夫决策过程,建立无人机集群环境;
[0048]
初始模块,用于随机赋予无人机集群中每个无人机智能体策略参数,初始化生成无人机智能体群组;根据所述无人机智能体群组,生成初始联合策略,并在所述无人机集群环境中根据所述初始联合策略执行初始动作;
[0049]
设置模块,用于根据所述初始动作,采用适应度函数评估无人机智能体群组中每个无人机智能体的性能,并对每个无人机智能体的适应度进行排序,得到排序结果;根据所述排序结果,设置高级智能体和初级智能体;
[0050]
赋予模块,用于采用进化算法,将所述高级智能体的策略参数以参考概率赋予给所述初级智能体,得到进化选择策略;
[0051]
估计模块,用于由所述进化选择策略估计优势函数,并由所述优势函数得到策略梯度;
[0052]
输出模块,用于判断当所述策略梯度满足预设的阈值条件时,输出所有智能体的状态为所述马尔可夫决策过程的最优解;根据所述最优解完成无人机集群任务。
[0053]
上述基于竞争合作机制的emarl的无人机集群方法,提出了一种结合竞争和合作的混合模型,在获取任务并建模后,生成一定规模的无人机智能体群组,并通过多智能体强化学习对环境下每个无人机智能体进行训练,训练后采用适应度函数评估所有无人机智能体的性能,通过对其适应度值排序来选择几个高级智能体;然后,引入设计的进化选择机制来生成下一代智能体,并不断选择智能体直到停止条件;在此过程中,将保留最佳智能体。相较于传统的进化强化学习选取部分适应度较高的智能体作为精英智能体,随后利用精英智能体对整个种群进行变异、进行更新换代的算法,本技术将部分适应度较高的无人机智能体设计为高级智能体,适应度较低的设计为初级智能体,剩余智能体为普通智能体,局部上采用轮盘赌策略,让初级智能体继承高级智能体的参数,并且可以证明,这样的设计在引入竞争的条件下,策略梯度具有强收敛。而且,针对多智能体强化学习算法采用团队回报难以信用分配的问题,引入的进化选择机制对表现较差的智能体起筛选作用,从而用进化筛选的方法在一定程度上改善了多智能体强化学习信用难分配问题。
附图说明
[0054]
图1为一个实施例中基于竞争合作机制的emarl的无人机集群方法的流程图;
[0055]
图2为一个实施例中进化多智能体强化学习算法的框架图;
[0056]
图3为一个实施例中进化选择的流程图;
[0057]
图4为一个实施例中基于竞争合作机制的emarl的无人机集群装置的结构框图。
具体实施方式
[0058]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
[0059]
如图1所示,本技术提供的一种基于竞争合作机制的emarl的无人机集群方法,在一个实施例中,包括以下步骤:
[0060]
步骤102:获取无人机集群任务,将无人机集群任务建模为马尔可夫决策过程,建立无人机集群环境。
[0061]
具体的:
[0062]
获取无人机集群任务,作为群体单位(即集群)的无人机具有更强的群体意识,而不太关心个体利益,也就是说,群体中的每个个体都与其他个体合作,追求更高的群体回报。
[0063]
因此,集群任务可以被视为一个完全合作的随机博弈,通常被建模为一个部分可观测的马尔可夫决策过程(pomdp),也就是说,将无人机集群任务建模为一个部分可观测的马尔可夫决策过程,该过程由描述了n个智能体行为的元组定义。
[0064]
其中,表示时间t时环境的真实状态,表示时间t的第k个智能体动作,表示所有无人机智能体的联合动作,映射表示智能体在状态s
t
采取联合行动u
t
然后过渡到s
t 1
的概率,表示第k个无人机智能体从环境中获得的状态,映射是将真实状态映射到观察状态的观察函数,无人机智能体所观察到的迹记录了第k个智能体从时间0到t的状态和动作,表示在第k个无人机智能体在观察状态下采取动作后收到的回报。
[0065]
步骤104:随机赋予无人机集群中每个无人机智能体策略参数,初始化生成无人机智能体群组;根据所述无人机智能体群组,生成初始联合策略,并在无人机集群环境中根据初始联合策略执行初始动作。
[0066]
在本步骤中,通过随机赋予策略参数来初始化无人机智能体群组。
[0067]
将无人机智能体群组中所有无人机智能体的策略参数累乘得到初始联合策略。
[0068]
步骤106:根据初始动作,采用适应度函数评估无人机智能体群组中每个无人机智能体的性能,并对每个无人机智能体的适应度进行排序,得到排序结果;根据排序结果,设置高级智能体以及初级智能体。
[0069]
在本步骤中,适应度函数是根据初始动作得到的,具体的适应度函数以及如何根据初始动作得到适应度函数为现有技术。
[0070]
一般的,根据适应度函数得到适应度值,并按照由高到低的顺序对各个智能体进行排序,得到排序结果。
[0071]
根据排序结果设置高级智能体和初级智能体,其余为普通智能体。其中,高级智能体是指适应度好也就是适应度值高的智能体,初级智能体是指适应度最差也就是适应度值异常低的智能体,普通智能体是处于上述两种智能体之间的智能体。具体的,可以根据实际情况进行设置。例如:将排序结果中前ns个智能体为高级智能体,后nj个智能体为初级智能体,中间部分为普通智能体。
[0072]
步骤108:采用进化算法,将高级智能体的策略参数以参考概率赋予给初级智能体,得到进化选择策略。
[0073]
在本步骤中,以参考概率赋予是指:将高级智能体的策略参数以轮盘赌的形式赋予给初级智能体,其余智能体的策略参数保持不变。
[0074]
步骤110:由进化选择策略估计优势函数,并由优势函数得到策略梯度。
[0075]
在本步骤中,为了解决pomdp,通过学习由全部n个无人机智能体的策略参数(即高级智能体的策略参数)的联合策略(即估计策略)将回报函数最大化,在联合策略中引入了状态值函数和状态作用值函数。
[0076]
具体的:
[0077]
由进化选择策略得到回报函数:(进化选择策略影响了智能体的动作,进而影响回报函数)
[0078][0079]
式中,r
t
表示回报函数,r
t
表示t时刻的具体回报,γi表示折扣率,γ∈[0,1],一般认为未来的回报不如现在等值的回报好,所以r
t i
的权重小于r
t
;智能体的目标就是让r
t
最大化;
[0080]rt,i
=r
sep,i
(t) r
ali,i
(t) r
coh,i
(t) r
obs,i
(t)
[0081]
式中,r
t
表示回报函数,t表示当前时刻,r
sep,i
(t)表示t时刻第i个无人机智能体所获得的基于分离规则的回报函数,r
ali,i
(t)表示t时刻第i个无人机智能体所获得的基于对齐规则得到的回报函数,r
coh,i
(t)表示t时刻第i个无人机智能体所获得的基于内聚规则得到的回报函数,r
obs,i
(t)表示t时刻第i个无人机智能体所获得的满足躲避障碍的回报函数;
[0082][0083]
式中,π(u|s,θ)表示估计的n个无人机智能体的联合策略,πi表示第i个无人机智能体的策略分布,ui表示第i个无人机智能体动作,τi表示第i个无人机智能体观察到的迹,θi表示第i个无人机智能体的策略参数。
[0084]
在设计无人机智能体在群集任务中的回报时,考虑由无人机智能体和障碍物组成的一般群集环境,每个无人机智能体都有相同的速度||v||,并且只观察最近的k个无人机智能体的状态,每个无人机智能体的状态包括其位置和速度(都是向量),设置无人机智能体的动作是顺时针方向增加角速度,然后,给定单个无人机智能体的角速度大小ω和动作空间大小|a|,动作空间为:
[0085][0086]
为了引导智能体高效聚集,智能体的可观察空间中有三个基本规则:
[0087]
(1)分离:为了避免群集过程中无人机智能体发生碰撞,要求无人机智能体与观察到的其他无人机智能体保持距离。
[0088]
(2)对齐:驱动无人机智能体以相同的速度方向移动,某个无人机智能体可以获得加速度以跟随其他无人机智能体。
[0089]
(3)内聚:为了逐步扩大规模,会吸引附近的无人机智能体加入。某个无人机智能体可以获得加速度,以靠近其他无人机智能体。
[0090]
本技术的集群模型根据这些规律添加了自然种群属性,将这三条规则引入到多智能体强化学习方法的回报函数估计过程中,对环境中无人机智能体的行为给予奖励(即回
报)。
[0091]
对于分离规则,第i个无人机智能体距离所有观察到的智能体越远,回报越高。因此,利用第i个无人机智能体与所有ni个观测到的无人机智能体之间位置向量差的平均模作为单个无人机智能体的奖励;同时,为了避免直接使用向量的差模作为奖励,使无人机智能体之间的距离无限增大,给出了惩罚阈值ds来惩罚无人机智能体;同时,该无人机智能体因距离其他无人机智能体太近(小于ds)会受到负面奖励,但该奖励不会随着距离大于ds而增加。如下式:
[0092][0093]
式中,r
sep,i
(t)表示t时刻第i个无人机智能体所获得的基于分离规则的回报函数,n表示智能体个数,i、j表示具体的某智能体,表示智能体i、j所在位置,ds为事先设定的距离最大值,β
sep
表示分离规则的回报系数。
[0094]
对于对齐规则,规范化所有智能体的速度向量:u
→
i=v
→
i,并使用向量之间的差,如下式:
[0095][0096]
式中,r
ali,i
(t)表示第i个无人机智能体所获得的基于对齐规则的回报函数,n表示智能体个数,i、j表示具体的某智能体,θi、θj表示智能体i、j的方向,β
ali
表示对齐规则的回报系数;
[0097]
如果知道每个无人机智能体与坐标系之间的角度:θ1,...,θn,其中对齐奖励可以重新表示如下:
[0098][0099]
式中,r
ali
(t)表示第i个无人机智能体所获得的基于对齐规则的回报函数。
[0100]
对于内聚规则,可以建模为无人机智能体i和所有ni个无人机智能体之间的距离,由于不希望所有无人机智能体都离得太近,因此引入了一个惩罚阈值dc,如下等式:
[0101][0102]
式中,r
coh,i
(t)表示第i个无人机智能体所获得的基于内聚规则的回报函数,n表示智能体个数,i、j表示具体的某智能体,r表示智能体所在位置,dc表示事先设定的距离最大值,β
coh
表示内聚规则的回报系数。
[0103]
另外,除了满足上述三个规则,为了让无人机智能体避开环境中的障碍物,将障碍物奖励构建为一个由智能体是否撞到障碍物决定的常数函数:
[0104][0105]
式中,r
obs,i
(t)表示第i个无人机智能体所获得的躲避障碍的回报函数,β
obs
表示满足躲避障碍的回报系数。
[0106]
最后,我们获得一个无人机智能体在时间t的累积奖励。对于多智能体系统,总奖励(躲避障碍并遵守上述规则)表示为所有无人机智能体的奖励之和:
[0107]rt,i
=r
sep,i
(t) r
ali,i
(t) r
coh,i
(t) r
obs,i
(t)
[0108]
需要说明,分离规则的回报系数、对齐规则的回报系数、内聚规则的回报系数、满足躲避障碍的回报系数以及如何判断无人机与障碍相撞均为现有技术。
[0109]
作为一个完全合作的博弈,希望群集系统的总体回报尽可能大,目标是最大化上式中的总回报,而不是每个无人机智能体的回报。因此,追求帕累托最优解(全局最优解),而不是纳什均衡(局部最优解)。
[0110]
由回报函数估计优势函数:
[0111]aπ
(s
t
,u
t
)=q
π
(s
t
,u
t
)-v
π
(s
t
)
[0112][0113][0114]
式中,a
π
(s
t
,u
t
)表示优势函数,q
π
(s
t
,u
t
)表示状态作用值函数,v
π
(s
t
)表示状态值函数,t表示当前时刻,s
t
表示时间t时无人机集群环境的真实状态,u
t
表示时间t时无人机智能体动作,r
t
表示回报函数。
[0115]
为了最大化优势函数和群体回报,常用的方法是采用ctde范式,如maddpg和coma。这些方法在目标函数上应用随机梯度上升来最大化奖励。maddpg中的每个无人机智能体都有一个用于全局信息训练的评判器和几个本地信息训练智能体,而coma告诉代理所选操作对当前奖励的贡献程度,并排除本地操作值。并且,引入了进化算法,将时间差分误差(coma全局奖励中,如果r0估计失败会引入的时间差分误差)应用于处理信用分配问题。
[0116]
带有进化选择机制的优势函数得到策略梯度为:
[0117][0118]
式中,表示第i个无人机智能体进化选择下的策略更新梯度,表示基于策略下的期望,πi表示进化算法下的第i个智能体的策略,表示梯度算子,表示其优势函数。
[0119]
步骤112:判断当策略梯度满足预设的阈值条件时,输出所有智能体的状态为马尔可夫决策过程的最优解;根据最优解完成无人机集群任务。
[0120]
在本步骤中,预设的阈值条件包括出现明显收敛。
[0121]
判断当策略梯度不满足预设的阈值条件时:
[0122]
由策略梯度更新所有无人机智能体的当前策略参数;根据所有无人机智能体的当前策略参数,采用强化学习算法更新所有无人机智能体的当前联合策略;根据当前联合策略执行当前动作;根据当前动作,采用适应度函数评估每个无人机智能体的当前性能,并对每个无人机智能体的当前适应度进行排序,得到当前排序结果;根据当前排序结果,设置当前高级智能体以及当前初级智能体;采用进化算法,将当前高级智能体的当前策略参数以参考概率赋予给当前初级智能体,得到当前进化选择策略;由当前进化选择策略估计当前优势函数,并由当前优势函数得到当前策略梯度,直至当前策略梯度满足预设的阈值条件。
[0123]
在生物群体合作中,当个体无论做什么都能获得与群体其他成员相同的回报的时候,由于没有合理分配就没有竞争,整个协作任务的性能会受到限制。
[0124]
合作与竞争共存的机制通常会在不同领域促进整个种群的发展,达尔文进化理论也说明了这一点,即生物群体保持着最高适应度个体的基因,并逐渐消除了最低适应度个体的基因。它增加了个人之间的竞争,尽管他们也相互合作。
[0125]
在本实施例中,集群任务即“合作”,对集群任务建模的马尔科夫过程进行求解的marl算法(多智能体强化学习)即“竞争”。在多智能体强化学习算法的基础上综合了进化算法,以加强智能体之间的竞争,构成进化多智能体强化学习算法,该算法利用marl驱动智能体完全合作地完成群集任务,同时,引入了erl(进化强化学习,结合了进化算法和强化学习)技巧,以鼓励智能体进行竞争性学习。而且,对进化多智能体强化学习算法进行改进,留下高适应度的智能体,淘汰低适应度的智能体,充分合作地解决信任分配问题。算法中给出了进化多智能体强化学习的伪码,如图2中的整个框架。
[0126]
对于合作任务,群集要求智能体进行合作并最大化团队奖励,智能体必须牺牲其奖励以换取更高的团队奖励。为了实现合作,使用集中的评判器来估计团队奖励,以分散的方式训练智能体。分别随机初始化智能体和评判器的参数和所有智能体和评判器都是神经网络。智能体同时与环境交互,将各自的历史迹τi,存储到各自的缓冲区中。更新所有缓冲区后,评判器通过从总缓存中采样(o
t
,u
t
,r
t
,o
t 1
)将损失降至最低。在更新评判器时,由于训练是集中的,使用真正的全局状态s
t
来代替观测o
t
。然后,通过从各个智能体的缓冲区中采样来更新所有智能体。
[0127]
为了减少方差,引入状态值函数v(s
t
)作为基线,并计算策略梯度。
[0128]
此外,如图3所示,设计了一个替换初级智能体参数的进化选择步骤来解决信用分配问题。在第k次更新后,计算每个智能体的ξ步累积奖励作为其适应度值。然后,对适应度值进行排序,选择前ns个智能体作为高级智能体,最后nj个智能体作为初级智能体,并使用第i个初级智能体的适应度值与所有高级智能体的适应度之和的百分比作为第i个智能体参数被替换的概率,可以称之为概率继承,未包含在初级智能体中的其他智能体将被保留并继续更新。
[0129]
与传统的进化强化学习方法不同,进化选择并没有进化所有的智能体,只选择性能良好的ns代理来形成高级智能体,并替换由性能较差的nj智能体组成的初级智能体的参
数。
[0130]
上述基于竞争合作机制的emarl的无人机集群方法,提出了一种结合竞争和合作的混合模型,在获取任务并建模后,生成一定规模的无人机智能体群组,并通过多智能体强化学习对环境下每个无人机智能体进行训练,训练后采用适应度函数评估所有无人机智能体的性能,通过对其适应度值排序来选择几个高级智能体;然后,引入设计的进化选择机制来生成下一代智能体,并不断选择智能体直到停止条件;在此过程中,将保留最佳智能体。相较于传统的进化强化学习选取部分适应度较高的智能体作为精英智能体,随后利用精英智能体对整个种群进行变异、进行更新换代的算法,本技术将部分适应度较高的无人机智能体设计为高级智能体,适应度较低的设计为初级智能体,剩余智能体为普通智能体,局部上采用轮盘赌策略,让初级智能体继承高级智能体的参数,并且可以证明,这样的设计在引入竞争的条件下,策略梯度具有强收敛。而且,针对多智能体强化学习算法采用团队回报难以信用分配的问题,引入的进化选择机制对表现较差的智能体起筛选作用,从而用进化筛选的方法在一定程度上改善了多智能体强化学习信用难分配问题。
[0131]
应该理解的是,虽然图1的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
[0132]
如图4所示,本技术还提供一种基于竞争合作机制的emarl的无人机集群装置,在一个实施例中,包括:获取模块402、初始模块404、设置模块406、赋予模块408、估计模块410和输出模块412,其中:
[0133]
获取模块402,用于获取无人机集群任务,将所述无人机集群任务建模为马尔可夫决策过程,建立无人机集群环境;
[0134]
初始模块404,用于随机赋予无人机集群中每个无人机智能体策略参数,初始化生成无人机智能体群组;根据所述无人机智能体群组,生成初始联合策略,并在所述无人机集群环境中根据所述初始联合策略执行初始动作;
[0135]
设置模块406,用于根据所述初始动作,采用适应度函数评估无人机智能体群组中每个无人机智能体的性能,并对每个无人机智能体的适应度进行排序,得到排序结果;根据所述排序结果,设置高级智能体和初级智能体;
[0136]
赋予模块408,用于采用进化算法,将所述高级智能体的策略参数以参考概率赋予给所述初级智能体,得到进化选择策略;
[0137]
估计模块410,用于由所述进化选择策略估计优势函数,并由所述优势函数得到策略梯度;
[0138]
输出模块412,用于判断当所述策略梯度满足预设的阈值条件时,输出所有智能体的状态为所述马尔可夫决策过程的最优解;根据所述最优解完成无人机集群任务。
[0139]
关于一种基于竞争合作机制的emarl的无人机集群装置的具体限定可以参见上文中对于一种基于竞争合作机制的emarl的无人机集群方法的限定,在此不再赘述。上述装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内
嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0140]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0141]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。