1.本发明涉及生物信息学分析领域,具体涉及一种对肿瘤癌细胞基因序列化并给出检测结果的系统和数据处理方法,其是基于大数据技术对肿瘤基因生物信息的综合分析与应用。
背景技术:
2.由于肿瘤早期外观特征不明显,在内窥镜检查中表现不典型,容易存在漏诊;而目前最为直接、简单、有效的钡餐x射线检测方法,对于中晚期的诊断价值更大而早期诊断存在一定缺陷。肿瘤的早期表现为细胞内基因表达图谱的改变。因此,对于肿瘤的早期检测,采用基因检测与诊断的方式是非常有必要的。
3.随着测序技术的迅猛发展,通过核酸高通量测序,可以获得庞大的基因序列数据信息。但是如何在如此庞大复杂的基因数据中挖掘感兴趣的数据,是生物信息学分析领域亟待解决的问题。对于早期肿瘤基因检测与诊断来说,从测序后获得的基因簇信息中获取具有高应用价值的信息,是实现早期肿瘤诊断的技术要点。
技术实现要素:
4.本发明的主要目的在于一种对肿瘤基因检测中的高通量基因测序数据进行序列化并分析处理得出诊断结果的系统和数据处理方法,以克服现有技术的不足。
5.为实现前述发明目的,本发明采用的技术方案包括:
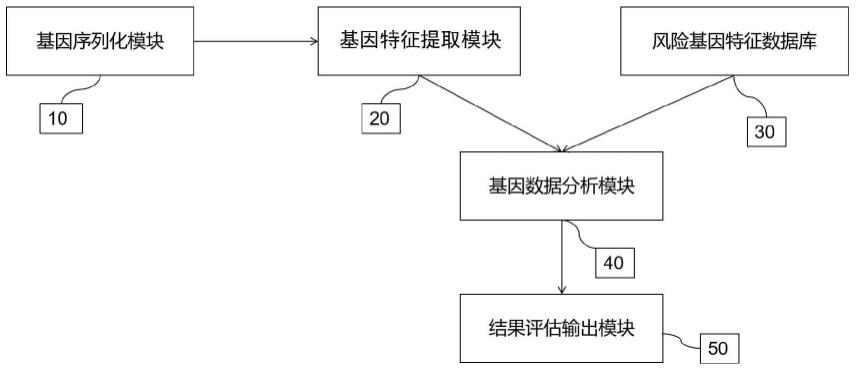
6.本发明实施例提供了一种肿瘤基因检测系统,其包括:
7.基因序列化模块,其至少用以对样本的被测基因簇数据进行序列化处理,获得被测基因序列数字化矩阵;
8.基因特征提取模块,其至少用以对所述被测基因序列数字化矩阵进行聚类降维分析,即通过特征提取算法获得被测基因系数特征向量;
9.风险基因特征数据库,其至少用以存储多个癌变基因系数特征向量以及基因协同突变单元作为结果评估参考;
10.基因数据分析模块,其至少用以将所述被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量进行相似度匹配,并提取出相似系数大于第一选定阈值的被测基因系数特征向量;
11.以及,结果评估输出模块,其至少用以将基因数据分析模块提取出的被测基因系数特征向量与风险基因特征数据库的输出结果中的基因协同突变单元进行比较,并根据基因重合程度进行评估,从而判断并输出被测基因簇数据患者患有肿瘤的风险程度。
12.在一些实施例中,所述基因序列化模块用于先对被测基因簇数据进行序列化处理,获得序列化矩阵,之后被测各基因序列分别与全基因组数据以向量的形式进行相似度计算,获得被测基因序列数字化矩阵td;
13.m代表被测基因序列数字化矩阵的行数,即被测基因簇基因个数;n代表被测基因序列数字化矩阵的列数,即全基因组数据库基因个数,每一列代表一个基因序列与全基因组序列的相似值。
14.在一些实施例中,所述基因特征提取模块采用非负矩阵算法对所述被测基因序列数字化矩阵进行特征提取,从而获得不同基因序列的组合,不同的组合形成一个不同基因组成的被测基因系数特征向量
[0015]15.表示一个特征单元向量,η1、η2......ηn分别表示不同基因序列的系数。
[0016]
进一步地,η1表示tp53基因的系数,η2表示egfr基因的系数,ηn表示ep300基因的系数。
[0017]
在一些实施例中,所述基因数据分析模块至少采用如式(1)所示的余弦相似计算公式分别计算每一个被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量的相似值,并输出相似系数大于第一选定阈值的被测基因系数特征向量;
[0018][0019]
其中代表相似系数,表示被测基因系数特征向量,表示癌变基因系数特征向量。
[0020]
本发明实施例还提供了一种肿瘤基因检测的数据处理方法,所述数据处理方法主要基于前述的肿瘤基因检测系统而实施,并且所述数据处理方法包括:
[0021]
采用基因序列化模块对细胞的被测基因簇数据进行序列化处理,获得被测基因序列数字化矩阵;
[0022]
采用基因特征提取模块对所述被测基因序列数字化矩阵进行聚类降维分析,即通过特征提取算法获得被测基因系数特征向量;
[0023]
采用风险基因特征数据库存储多个癌变基因系数特征向量以及基因协同突变单元作为结果评估参考;
[0024]
采用基因数据分析模块将所述被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量进行相似度匹配,并提取出相似系数大于第一选定阈值的被测基因系数特征向量;
[0025]
以及,采用结果评估输出模块将基因数据分析模块提取出的被测基因系数特征向量与风险基因特征数据库的输出结果中的基因协同突变单元进行比较,并根据基因重合程度进行评估,从而判断并输出被测基因簇数据患者患有肿瘤的风险程度。
[0026]
与现有技术相比,本发明的有益效果至少包括:
[0027]
本发明提供的肿瘤基因检测系统及数据处理方法可对肿瘤基因检测中的高通量基因测序数据进行序列化并分析处理得出诊断结果,可准确判断并输出被测基因数据患者患有肿瘤的风险程度。
附图说明
[0028]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,并不构成对本发明的限定。
[0029]
图1是本发明一较佳实施例中肿瘤基因检测系统的架构图。
具体实施方式
[0030]
鉴于现有技术中的不足及为解决上述问题,本案发明人经长期研究和大量实践,得以提出本发明的技术方案,其主要是提供了一种对肿瘤基因检测中的高通量基因测序数据进行序列化并分析处理得出诊断结果的方法和系统。如下将对该技术方案、其实施过程及原理等作进一步的解释说明。若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。除非特别说明,本发明采用的试剂、方法和设备为本技术领域常规试剂、方法和设备。
[0031]
本发明实施例的一个方面提供了一种肿瘤基因检测系统包括基因序列化模块、基因特征提取模块、风险基因特征数据库、基因数据分析模块及结果评估输出模块。
[0032]
进一步地,所述肿瘤基因检测系统是由基因序列化模块、基因特征提取模块、风险基因特征数据库、基因数据分析模块及结果评估输出模块组成。
[0033]
在一些具体实施例中,所述肿瘤基因检测系统包括:
[0034]
基因序列化模块,其至少用以对样本的被测基因簇数据进行序列化处理,获得被测基因序列数字化矩阵;
[0035]
基因特征提取模块,其至少用以对所述被测基因序列数字化矩阵进行聚类降维分析,即通过特征提取算法获得被测基因系数特征向量;
[0036]
风险基因特征数据库,其至少用以存储多个癌变基因系数特征向量以及基因协同突变单元作为结果评估参考;
[0037]
基因数据分析模块,其至少用以将所述被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量进行相似度匹配,并提取出相似系数大于第一选定阈值的被测基因系数特征向量;
[0038]
以及,结果评估输出模块,其至少用以将基因数据分析模块提取出的被测基因系数特征向量与风险基因特征数据库的输出结果中的基因协同突变单元进行比较,并根据基因重合程度进行评估,从而判断并输出被测基因簇数据患者患有肿瘤的风险程度。
[0039]
在一些具体实施例中,所述基因序列化模块可直接对细胞测序基因簇数据进行序列化分析,其主要包括通过被测基因簇数据与全基因组数据的相似度对基因簇序列进行数字化,建立被测细胞的基因序列数字化矩阵。
[0040]
在一些更为具体的实施例中,所述基因序列化模块用于先对被测基因簇数据进行序列化处理,获得序列化矩阵,之后被测各基因序列分别与全基因组数据以向量的形式进行相似度计算,获得被测基因序列数字化矩阵td;
[0041]
m代表被测基因序列数字化矩阵的行数,即被测基因簇基因个数;n代表被测基因序列数字化矩阵的列数,即全基因组数据库基因个数,每一列代表一个基因序列与全基因组序列的相似值。
[0042]
进一步地,所述被测基因包括肿瘤易感基因,优选包括tp53、egfr、ras、rb1、brca、notch、cdkn2a、znf750、nfe2l2、fat1、ep300等,例如,第一列代表基因tp53,第二列代表基因egfr等等,但不限于此。
[0043]
在一些具体实施例中,所述基因特征提取模块是对前述的被测细胞的基因序列数字化矩阵进行聚类降维分析,并通过特征提取算法获得被测基因系数特征向量。
[0044]
在一些更为具体的实施例中,所述基因特征提取模块采用非负矩阵算法对所述被测基因序列数字化矩阵进行特征提取,从而获得不同基因序列的组合,不同的组合形成一个不同基因组成的被测基因系数特征向量
[0045][0045]
表示一个特征单元向量,η1、η2......ηn分别表示不同基因序列的系数。
[0046]
其中,η1表示tp53基因的系数,η2表示egfr基因的系数,ηn表示ep300基因的系数,但不限于此。
[0047]
在一些具体实施例中,所述风险基因特征数据库是将确诊患者的基因检测结果通过前述述方式处理后,经试验验证的癌变基因系数特征向量存储到数据库中。本发明认为判断肿瘤应受多个基因协同影响,因此将此处的基因组成的单元命名为基因协同突变单元。因此,将癌变基因系数特征向量中,系数高的基因进行提取,组成的基因协同突变单元并存储到数据库中作为结果评估参考。
[0048]
在一些更为具体的实施例中,所述风险基因特征数据库包括多个癌变基因系数特征向量以及多个第一基因协同突变单元,每个所述第一基因协同突变单元包括多个经试验验证的基因系数高的癌变基因系数特征向量;优选的,所述第一基因协同突变单元表示为:
[0049][0050]
在一些具体实施例中,所述基因数据分析模块是将前述被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量进行相似度匹配,并根据经验值设定合适的阈值,提取出被测基因系数特征向量与癌变基因系数特征向量相似度高的基因系数特征向量。
[0051]
在一些更为具体的实施例中,所述基因数据分析模块至少采用如式(1)所示的余弦相似计算公式分别计算每一个被测基因系数特征向量与风险基因特征数据库中的癌变
基因系数特征向量的相似值,并输出相似系数大于第一选定阈值的被测基因系数特征向量;
[0052][0053]
其中代表相似系数,表示被测基因系数特征向量,表示癌变基因系数特征向量。
[0054]
进一步地,所述第一选定阈值为0.6~1。
[0055]
在一些具体实施例中,所述结果评估输出模块是对前述基因数据分析模块提取出的被测基因系数特征向量的同一基因系数进行处理,设置一个合适的阈值。如果该基因大于这一阈值,则认为其为突变基因。如此分别大于一定阈值的基因组成一个基因协同突变单元,并与风险基因特征数据库中的基因协同突变单元进行比较,根据基因重合程度进行结果评估,判断并输出被测基因数据患者患有肿瘤的风险程度。
[0056]
在一些更为具体的实施例中,所述结果评估输出模块至少根据基因数据分析模块中获取的被测基因系数特征向量提取出第二基因协同突变单元,并将所述第二基因协同突变单元与风险基因特征数据库中的第一基因协同突变单元进行比较,根据基因重合度进行结果评估,判断并输出被测基因患者患有肿瘤的风险程度。
[0057]
进一步地,所述结果评估输出模块至少将基因数据分析模块中获取的被测基因系数特征向量中的各个基因系数进行处理,如计算均值及有效性,并将所获基因系数与第二选定阈值进行比较,将大于该第二选定阈值的基因组成所述第二基因协同突变单元。
[0058]
在一些更为具体的优选实施例中,本发明的肿瘤基因检测系统包含:
[0059]
基因序列化模块,用以处理经过高通量测序的肿瘤基因簇数据。通过对基因簇数据序列化处理,然后与全基因组数据相似性计算获得被测基因簇数字矩阵;
[0060]
基因特征提取模块,用以进一步对基因序列化后的被测基因矩阵进行聚类降维分析,即使用特征提取算法提取数字化矩阵特征,该特征以基因对应的向量表示;
[0061]
风险基因特征数据库,用以存储通过基因序列化和基因特征提取模块中的基因数据处理方法处理后的肿瘤癌变基因系数特征向量以及基因协同突变单元。本发明认为组织癌变的产生是癌变基因与正常基因共同作用的结果。将癌变基因系数特征向量中基因系数高的基因进行提取,组成的基因协同突变单元并存储到数据库中作为结果评估参考;
[0062]
基因数据分析模块,用以获取并分析基因特征提取模块的被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量的相似性。根据设定的阈值,输出被测基因数据的癌变基因系数特征向量;
[0063]
以及,结果评估输出模块,根据基因数据分析模块中获取的被测基因数据的基因系数特征向量提取出基因协同突变单元,并与风险基因特征数据库中的基因协同突变单元比较。根据基因的重合比例,输出被测基因数据患者患有肿瘤的风险程度。
[0064]
本发明实施例的另一个方面还提供了一种肿瘤基因检测的数据处理方法,所述数据处理方法主要基于前述的肿瘤基因检测系统而实施,并且所述数据处理方法包括:
[0065]
采用基因序列化模块对细胞的被测基因簇数据进行序列化处理,获得被测基因序列数字化矩阵;
[0066]
采用基因特征提取模块对所述被测基因序列数字化矩阵进行聚类降维分析,即通过特征提取算法获得被测基因系数特征向量;
[0067]
采用风险基因特征数据库存储多个癌变基因系数特征向量以及基因协同突变单元作为结果评估参考;
[0068]
采用基因数据分析模块将所述被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量进行相似度匹配,并提取出相似系数大于第一选定阈值的被测基因系数特征向量;
[0069]
以及,采用结果评估输出模块将基因数据分析模块提取出的被测基因系数特征向量与风险基因特征数据库的输出结果中的基因协同突变单元进行比较,并根据基因重合程度进行评估,从而判断并输出被测基因簇数据患者患有肿瘤的风险程度。
[0070]
在一些具体实施例中,所述的数据处理方法,其特征在于包括:至少先采用基因序列化模块对被测基因簇数据进行序列化处理,获得序列化矩阵,之后被测各基因序列分别与全基因组数据以向量的形式进行相似度计算,获得被测基因序列数字化矩阵td;
[0071]
m代表被测基因序列数字化矩阵的行数,即被测基因簇基因个数;n代表被测基因序列数字化矩阵的列数,即全基因组数据库基因个数,每一列代表一个基因序列与全基因组序列的相似值。
[0072]
在一些具体实施例中,所述数据处理方法包括:至少采用非负矩阵算法对所述被测基因序列数字化矩阵进行特征提取,从而获得不同基因序列的组合,不同的组合形成一个不同基因组成的被测基因系数特征向量
[0073][0073]
表示一个特征单元向量,η1、η2......ηn分别表示不同基因序列的系数;例如,η1表示tp53基因的系数,η2表示egfr基因的系数,ηn表示ep300基因的系数,但不限于此。
[0074]
在一些具体实施例中,所述风险基因特征数据库包括多个癌变基因系数特征向量以及多个第一基因协同突变单元,每个所述第一基因协同突变单元包括多个经试验验证的基因系数高的癌变基因系数特征向量。
[0075]
在一些具体实施例中,所述数据处理方法包括:至少采用如式(1)所示的余弦相似计算公式分别计算每一个被测基因系数特征向量与风险基因特征数据库中的癌变基因系数特征向量的相似值,并输出相似系数大于第一选定阈值的被测基因系数特征向量;
[0076][0077]
其中代表相似系数,表示被测基因系数特征向量,表示癌变基因系数特征向
量。
[0078]
在一些具体实施例中,所述数据处理方法包括:至少根据基因数据分析模块中获取的被测基因系数特征向量提取出第二基因协同突变单元,并将所述第二基因协同突变单元与风险基因特征数据库中的第一基因协同突变单元进行比较,根据基因重合度进行结果评估,判断并输出被测基因患者患有肿瘤的风险程度。
[0079]
进一步地,所述数据处理方法包括:至少将基因数据分析模块中获取的被测基因系数特征向量中的各个基因系数进行处理,如计算均值及有效性,并将所获基因系数与第二选定阈值进行比较,将大于该第二选定阈值的基因组成所述第二基因协同突变单元。
[0080]
综上所述,本发明提供的肿瘤基因检测系统及数据处理方法可对肿瘤基因检测中的高通量基因测序数据进行序列化并分析处理得出诊断结果,可准确判断并输出被测基因数据患者患有肿瘤的风险程度。
[0081]
下面将配合图式及本发明的一较佳实例,对本发明实施例中的技术方案进行清楚、完整地描述,进一步阐述本发明为达成预定发明的所采取的技术手段。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件,或按照制造厂商所建议的条件。
[0082]
关于本发明一种肿瘤基因检测系统及数据处理方法的一较佳实施例,请参考图1所示,其中包括一基因序列化模块10、一基因特征提取模块20、一风险基因特征数据库30、一基因数据分析模块40、一结果评估输出模块50。
[0083]
该基因序列化模块10,首先对测序基因簇进行序列化,获得序列化矩阵t1;t1的每个基因序列分别与人类全基因组t的每一个基因序列以向量的形式用余弦相似公式(1)计算相似值(这里取t1与t中取相似值最大的基因序列片段作为计算向量),从而获得以各个基因序列与全基因数字相似计算后的数字化矩阵td。
[0084]
m代表基因数字化矩阵的行数,即被测基因簇基因个数;n代表基因数字化矩阵的列数,即全基因组数据库基因个数。每一列代表一个基因序列与全基因组序列的相似值。在相似值计算之前在t1中已经确定每一基因序列是什么基因,如第一列代表肿瘤易感基因tp53,第二列代表肿瘤易感基因egfr,第三列代表肿瘤易感基因ep300等等。
[0085]
该特征提取模块20,采用非负矩阵算法对td进行特征提取,从而获得不同基因序列的组合,不同的组合形成一个不同基因组成的被测基因系数特征向量。
[0086][0086]
表示一个特征单元向量,如η1表示tp53基因的系数,η2表示egfr基因的系
数,ηn表示ep300基因的系数。
[0087]
该风险基因特征数据库30,其存储了大量的已经确认的类似η的特征向量单元。同时,存储大量的基因协同突变单元,如λ表示一基因协同突变单元。
[0088]
该基因数据分析模块40,使用余弦相似计算公式(1)分别计算每一个被测基因在前述获取的被测基因系数特征向量与风险基因特征数据库的癌变基因系数特征向量的相似值,并输出相似系数大于0.5的被测基因数据的基因系数特征向量。
[0089][0090]
其中代表相似系数,表示被测基因数据的基因系数特征向量,表示癌变基因系数特征向量。
[0091]
该结果评估输出模块50,根据基因数据分析模块输出的结果,将取出的被测基因系数特征向量中的各个基因系数进行计算均值及有效性。如果该基因的系数有效且均值大于0.8(不同基因可以取不同的阈值,此处为方便描述取同一阈值),那么将其判断为变异基因,如此获得一个基因突变单元(即基因协同突变单元)。将被测基因数据的基因协同突变单元(即前文所述第一基因协同突变单元)与风险数据库中基因协同突变单元(即前文所述第二基因协同突变单元)进行比对,当重合度为85%~100%,输出被测基因数据的基因协同突变单元及被测基因数据患者患肿瘤风险极高;当重合度为70%~85%,输出被测基因数据的基因协同突变单元及被测基因数据患者患肿瘤风险较高;当重合度为55%~70%,输出被测基因数据的基因协同突变单元及被测基因数据患者患肿瘤风险高;当重合度为30%~55%,输出被测基因数据的基因协同突变单元及被测基因数据患者患肿瘤风险一般;当重合度为0%~30%,输出被测基因数据患者患肿瘤风险低。
[0092]
藉由上述技术方案,本发明提供的肿瘤基因检测系统及数据处理方法可对肿瘤基因检测中的高通量基因测序数据进行序列化并分析处理得出诊断结果,可准确判断并输出被测基因数据患者患有肿瘤的风险程度。
[0093]
尽管已参考说明性实施例描述了本发明,但所属领域的技术人员将理解,在不背离本发明的精神及范围的情况下可做出各种其它改变、省略及/或添加且可用实质等效物替代所述实施例的元件。另外,可在不背离本发明的范围的情况下做出许多修改以使特定情形或材料适应本发明的教示。因此,本文并不打算将本发明限制于用于执行本发明的所揭示特定实施例,而是打算使本发明将包含归属于所附权利要求书的范围内的所有实施例。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。