半导体设备和电机控制设备
1.相关申请的交叉引用
2.在2021年2月25日提交的日本专利申请号2021-028740的公开内容(包括说明书、附图和摘要),通过整体引用并入本文。
技术领域
3.本发明涉及半导体设备和电机控制设备,并且例如涉及包括无线脉冲响应(iir)滤波器的半导体设备和包括该半导体设备的电机控制设备。
背景技术:
4.专利文献1公开了一种能够以高速执行iir滤波器运算的微处理器。该微处理器包括多个寄存器和滤波运算电路,该滤波运算电路被配置为使用来自多个寄存器的数据执行iir滤波运算,并且输出与一个样本相对应的运算数据并且传输数据用于下一滤波运算。多个寄存器被配置为利用新的传输数据来覆写并更新过去的传输数据、并且利用运算数据来覆写并更新待被运算的数据。
5.下面列出公开的技术。
6.[专利文献1]日本未审查专利申请公开号2009-33371
技术实现要素:
[0007]
如专利文献1所描述的,iir滤波运算例如通过使安装在微处理器中的滤波运算电路执行循环处理来实现。另一方面,iir滤波器在很多情况下通常是级联连接的。在这种情况下,滤波运算电路通常执行串行处理,其从第一级的iir滤波器的运算处理开始,并且在所有运算处理完成后转移到下一级的iir滤波器的运算处理。然后,当末级的iir滤波器的运算处理完成时,滤波运算电路输出多级iir滤波器的输出数据。
[0008]
然而,当使用这种串行处理时,从将输入数据给予多级的iir滤波器到获得输出数据需要时间。例如,当iir滤波器被应用于各种类型的控制系统时,控制系统通常需要执行多级的iir滤波器的运算处理,并且在控制周期内使用输出数据进一步执行处理。如果获得输出数据需要较长时间,则恐怕可能难以在控制周期内完成必要的处理。
[0009]
下面描述的实施例是考虑了上述情况而做出的,并且根据说明书描述和附图,其他问题和新颖特征将是清楚的。
[0010]
根据实施例的半导体设备包括:算术单元,其包括乘法器和加法器;存储器,其被配置为保持算出数据;控制电路,其被配置为控制算术单元和存储器。控制电路接收来自外部的指令,并且通过使用来自外部的输入数据和保持在存储器中的算出数据、使算术单元执行m次(m为2或更大的整数)算术运算,从而使算术单元和存储器充当包括乘法块、加法块和延迟块的iir滤波器。在这里,iir滤波器是能够通过m次(k<m)中的k次算术运算来确定输出数据的滤波器。控制电路接收来自外部的指令,然后使算术单元预先执行k次算术运算,从而确定输出数据并且在确定时将输出数据输出到外部。
[0011]
根据上述实施例,可以缩短获得来自iir滤波器的输出数据前的时间。
附图说明
[0012]
图1是示出本发明第一实施例的半导体设备的配置示例的示意图。
[0013]
图2是示出图1中的硬件加速器的配置示例的示意图。
[0014]
图3a是示出由图2中的硬件加速器实现的iir滤波器的配置示例的框图。
[0015]
图3b是用于描述图3a中的iir滤波器的运算示例的图。
[0016]
图4a是示出由图2中的硬件加速器实现的另一iir滤波器的配置示例的框图。
[0017]
图4b是用于描述图4a中的iir滤波器的运算示例的图。
[0018]
图5是示出与图3a不同的iir滤波器的配置示例的框图。
[0019]
图6是示出与图4a不同的iir滤波器的配置示例的框图。
[0020]
图7是示出在实际使用由图2中的硬件加速器实现的iir滤波器时的配置示例的框图。
[0021]
图8是示出图2中的硬件加速器的控制电路的处理内容的示例的流程图。
[0022]
图9是示出图8中的流程中的算术单元的详细的算术运算程序的示例的图。
[0023]
图10是示出与图9不同的算术运算程序的示例的图。
[0024]
图11是示出比较使用图8中的实施例的流程的情况与使用图14中的比较示例流程的情况的控制系统处理流程的概念图。
[0025]
图12是示出关于根据本发明第二实施例的电机控制设备的配置示例的示意图。
[0026]
图13a是示出各种处理系统中的算术运算方法的示例的概念图。
[0027]
图13b是示出各种处理系统中的算术运算方法的示例的概念图。
[0028]
图14是示出在根据本发明比较示例的半导体设备中的硬件加速器的控制电路的处理内容的示例的流程图。
具体实施方式
[0029]
在下面描述的实施例中,为方便起见,将在需要时在多个部分或实施例中描述本发明。然而,除非另有说明,否则这些部分或实施例不是彼此无关的,而是一个实施例涉及作为对其的修改、细节或补充解释的另一实施例部分的整体或一部分。而且,在下面描述的实施例中,当提及要素的数量(包括个数、值、量、范围等)时,原则上除非另有说明或除将该数量明显限制为具体数字的情况外,否则要素的数量并不限于具体数字,并且大于或小于具体数字也是适用的。
[0030]
此外,在下面描述的实施例中,不言而喻,原则上除非另有明确规定或除非该组件明显是必不可少的,否则每个组件(包括元素步骤)都不是必不可少的。同样,在下面描述的实施例中,当提及组件的形状、位置关系等时,原则上除非另有明确规定或除非从上下文中看出组件的形状、位置关系等明显不同,否则都包括大致近似的形状、类似的形状等。这同样适用于上述的数值和范围。
[0031]
而且,构成实施例中每个功能块的电路元件也没有被特别限定,并且通过诸如cmos(互补型mos晶体管)之类的熟知的集成电路技术被形成在由单晶硅等制成的半导体衬底上。
[0032]
在下文中,将参考附图对本发明的实施例进行详细描述。注意,在用于描述实施例的附图各处,原则上相同的构件由相同的参考字符标示,并且将省略其重复的描述。
[0033]
(第一实施例)
[0034]
(半导体设备的概要)
[0035]
图1是示出本发明第一实施例的半导体设备的配置示例的示意图。图1中所示的半导体设备dev通常是微控制器、soc(片上系统)等。半导体设备dev包括处理器prc、诸如ram(随机存取存储器)和非易失性存储器nvm之类的存储器、各种外围电路peri、以及硬件加速器hwa。这些部件中的每一个通过总线bs相互连接。
[0036]
处理器prc包括cpu(中央处理单元)。cpu通过执行存储器中存储的程序来实现预定功能。硬件加速器hwa是支持cpu处理的电路。硬件加速器hwa经由总线bs接收来自cpu的指令,并且响应于来自cpu的指令执行例如iir滤波运算等。
[0037]
各种外围电路peri包括以模数转换器、数模转换器、pwm(脉冲宽度调制)单元、外部通信接口等为代表的各种电路。例如,除了微控制器等之外,根据第一实施例的半导体设备还可以是fpga(现场可编程门阵列)、asic(专用集成电路)等。
[0038]
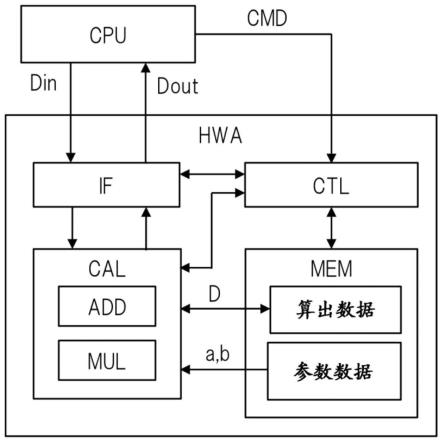
图2是示出图1中的硬件加速器的配置示例的示意图。图2中所示的硬件加速器hwa包括接口if、算术单元cal、存储器mem、以及控制电路ctl。接口if将来自cpu的输入数据din输出到算术单元cal,并且将来自算术单元cal的输出数据dout输出到cpu。
[0039]
例如,存储器mem包括多个寄存器等。存储器mem使用多个寄存器等保持被用于iir滤波器中的参数数据a和b以及在iir滤波运算期间获得的算出数据d。与此同时,存储器mem还具有iir滤波器中包括的延迟块(db)的功能。
[0040]
算术单元cal包括乘法器mul和加法器add。乘法器mul充当在iir滤波器中包括的乘法块(mb),并且将预定数据与来自存储器mem的参数数据a和b相乘。加法器add充当在iir滤波器中包括的加法块(ab),并且将多个预定数据相加。
[0041]
控制电路ctl从外部(即,cpu)接收指令cmd,并且控制接口if、算术单元cal、以及存储器mem。一般而言,控制电路ctl接收来自cpu的指令cmd,并且通过使用来自cpu的输入数据din和算出数据d以及保持在存储器mem中的参数数据a和b,使算术单元cal执行m次(m为2或更大的整数)算术运算。因此,控制电路ctl使算术单元cal和存储器mem充当包括乘法块、加法块和延迟块的iir滤波器。此外,控制电路ctl使算术单元cal经由接口if将iir滤波器的输出数据dout输出到cpu。
[0042]
(由硬件加速器实现iir滤波器的方法)
[0043]
图3a是示出由图2中的硬件加速器实现的iir滤波器的配置示例的框图,并且图3b是用于描述图3a中的iir滤波器的运算示例的图。图3a中所示的iir滤波器是二阶双二阶iir滤波器,并且具有直接形式ii的翻转配置。iir滤波器包括两个延迟块db1和db2,五个乘法块mb1到mb5,以及三个加法块ab1到ab3。在图3a中,左半部分用作前馈部分,而右半部分用作反馈部分。
[0044]
乘法块mb1、mb2和mb3通过将输入数据din分别地乘以参数数据b0、b1和b2而生成算出数据d1、d2和d3。乘法块mb4和mb5通过将输出数据dout分别地乘以参数数据a1和a2而生成算出数据d4和d5。加法块ab3通过将算出数据d3和算出数据d5相加而生成算出数据d7。延迟块db2通过将算出数据d7延迟一个采样周期而生成算出数据(换言之,延迟数据)d7'。
[0045]
加法块ab2通过将算出数据d2、算出数据d4和算出数据(延迟数据)d7'相加而生成算出数据d6。延迟块db1通过将算出数据d6延迟一个采样周期而生成算出数据(延迟数据)d6'。加法块ab1通过将算出数据d1和算出数据(延迟数据)d6'相加而生成输出数据dout。
[0046]
乘法块mb1至mb5由图2中的算术单元cal中的乘法器mul来实现。此时的参数数据b0、b1、b2、a1、a2被预先保持在存储器mem中。加法块ab1至ab3由算术单元cal中的加法器add来实现。延迟块db1和db2由存储器mem来实现。即,存储器mem将算出数据d6、d7作为延迟数据d6'、d7'保持1个采样周期。
[0047]
在图3a中的iir滤波器中,为了获得算出数据d4,必需以输出数据dout为前提,并且为了得到输出数据dout,又必需以算出数据d1为前提。以这种方式,每个数据都具有依赖关系。图3b示出了基于这种数据依赖关系的处理顺序。图2中的控制电路ctl使算术单元cal基于这种数据依赖关系来执行m次(这个示例中m=8)的算术运算,从而使算术单元cal、存储器mem等充当图3a中的iir滤波器。
[0048]
在这里,从图3b可以看出,图3a的iir滤波器具有这种配置,其中通过在k<m的情况下执行m次(m=8)中的k次(在这个示例中k=2)算术运算可以确定输出数据dout。即,控制电路ctl只使算术单元cal执行乘法块mb1的算术运算,然后执行加法块ab1的算术运算。在加法块ab1进行算术运算时,算术单元cal只将与乘法块mb1相关联的算出数据d1和由存储器mem保持的算出数据(延迟数据)d6'相加。
[0049]
在第一实施例中的硬件加速器hwa中,在从cpu接收指令cmd之后,控制电路ctl使算术单元cal预先执行k次(k=2)算术运算,从而确定输出数据dout。然后,在确定的时候,控制电路ctl使算术单元cal将输出数据dout输出到cpu。
[0050]
例如,当图3b中所示的m次(m=8)所有算术运算完成时,作为比较示例的硬件加速器将输出数据dout输出到cpu。另一方面,当m次中的k次(k=2)算术运算完成时,第一实施例的硬件加速器hwa可以将输出数据dout输出到cpu。结果,有可能缩短获得输出数据dout之前的时间。
[0051]
注意,在图3b中所示的m次(m=8)算术运算被划分为输出数据运算和延迟数据运算。输出数据运算是确定输出数据dout所必需的算术运算,并且对应于图3b示例中的算出数据d1的算术运算和输出数据dout的算术运算。另一方面,延迟数据运算是确定在充当延迟块db1、db2的存储器mem中保持的数据(即,与延迟数据d6'和d7'相对应的算出数据d6、d7)所必需的算术运算。
[0052]
延迟数据运算对应于至少6次算术运算,除了图3b的示例中的输出数据运算。然而,为了确定与延迟数据相对应的算出数据d6和d7,输出数据dout也是必需的。因此,在输出数据dout未知的前提下,延迟数据运算对应一共8次算术运算。在第一实施例的硬件加速器hwa中,控制电路ctl使算术单元cal预先执行输出数据运算,然后执行延迟数据运算。
[0053]
图4a是示出由图2中的硬件加速器实现的另一iir滤波器的配置示例的框图,而图4b是用于描述图4a中的iir滤波器的运算示例的图。图4a中所示的iir滤波器也是二阶双二阶iir滤波器,但具有与图3a中滤波器不同的直接形式i的翻转配置。iir滤波器包括四个延迟块db1到db4、五个乘法块mb1到mb5、以及四个加法块ab1到ab4。在图4a中,左半部分用作反馈部分,而右半部分用作前馈部分。
[0054]
加法块ab1通过将输入数据din和算出数据(延迟数据)d7'相加而生成算出数据
d1。乘法块mb1、mb2和mb3通过将算出数据d1分别乘以参数数据b0、b1和b2而生成算出数据d2、d3和d4。乘法块mb4和mb5通过将算出数据d1分别乘以参数数据a1和a2而生成算出数据d5和d6。
[0055]
延迟块db2通过将算出数据d6延迟一个采样周期而生成算出数据(延迟数据)d6'。延迟块db4通过将算出数据d4延迟一个采样周期而生成算出数据(延迟数据)d4'。加法块ab2通过将算出数据d5和算出数据(延迟数据)d6'相加而生成算出数据d7。加法块ab4通过将算出数据d3和算出数据(延迟数据)d4'相加而生成算出数据d8。
[0056]
延迟块db1通过将算出数据d7延迟一个采样周期而生成算出数据(延迟数据)d7'。延迟块db3通过将算出数据d8延迟一个采样周期而生成算出数据(延迟数据)d8'。加法块ab3通过将算出数据d2和算出数据(延迟数据)d8'相加而生成输出数据dout。
[0057]
与图3a的情况类似,图4a中的乘法块mb1到mb5由乘法器mul实现,加法块ab1到ab4由加法器add实现,而延迟块db1到db4由存储器mem实现。此外,图4b示出了基于与图4a的情况类似的数据依赖关系的用于图4a的iir滤波器的处理顺序。图2中的控制电路ctl使算术单元cal基于这种数据依赖关系执行m次(在这个示例中m=9)的算术运算,从而使算术单元cal、存储器mem等充当图4a中的iir滤波器。
[0058]
在这里,从图4b可以看出,类似于图3a的情况,图4a中的iir滤波器还具有这样的配置,其中可以通过执行m次(m=9)中的k次(在该示例中为k=3)算术运算来确定输出数据dout。即,控制电路ctl仅使算术单元cal执行加法块ab1的处理,随后执行乘法块mb1的处理,然后执行加法块ab3的处理。
[0059]
与图3a和3b的情况类似,在接收到来自cpu的指令cmd后,图2中的控制电路ctl使算术单元cal预先执行算术运算k次(k=3),从而确定输出数据dout。然后,在确定的时候,控制电路ctl使算术单元cal将输出数据dout输出到cpu。
[0060]
因此,第一实施例的硬件加速器hwa可以在m次(m=9)中的k次(k=3)算术运算完成时将输出数据dout输出到cpu。结果,有可能缩短获得输出数据dout之前的时间。此时,在图3a中所示的配置示例中,与图4a中所示的配置示例相比,可以将时间缩短相当于一次算术运算的量。注意,类似于图3a和图3b的情况,控制电路ctl在使算术单元cal预先执行输出数据运算之后,使算术单元cal执行延迟数据运算。
[0061]
图5是示出与图3a不同的iir滤波器的配置示例的框图,而图6是示出与图4a不同的iir滤波器的配置示例的框图。图5中所示的iir滤波器具有与图3a中所示的直接形式ii的翻转配置不同的直接形式i的配置。图6中所示的iir滤波器具有与图4a中所示的直接形式i的翻转配置不同的直接形式ii的配置。
[0062]
图3a中直接形式ii的翻转配置和图5中直接形式i的配置在延迟块位置上有所不同。类似地,图4a中直接形式i的翻转配置和图6中直接形式ii的配置在延迟块位置上也有所不同。即,在图3a和图4a的情况下,在执行乘法和加法之后执行延迟,而在图5和图6的情况下,在执行延迟之后执行乘法和加法。
[0063]
当配置不是如图5和图6中所示的翻转配置时,与图3a和图4a中所示的翻转配置的情况不同,使用所有的乘法块和加法块的m次算术运算是必需的,以便确定输出数据dout。即,输出数据运算的次数k等于运算的总次数m,在图5中k=m=8而在图6中k=m=9。因此,当配置不是翻转配置时,即使输出数据运算在先,也可能难以缩短在获得输出数据dout之
前的时间。
[0064]
(硬件加速器详情)
[0065]
图7是示出由图2中的硬件加速器实现的iir滤波器的实际使用的配置示例的框图。如图7中所示,在实际使用中,iir滤波器在很多情况下被用作以多级(这里为三级)级联连接的iir滤波器。第一级的iir滤波器flt1、第二级的iir滤波器flt2、以及末级的iir滤波器flt3中的每一个都具有图3a中所示的直接形式ii的翻转配置。
[0066]
第一级的iir滤波器flt1接收输入数据din[1]并输出输出数据dout[1]。第二级的iir滤波器flt2接收第一级的输出数据dout[1]作为输入数据din[2],并且输出输出数据dout[2]。末级的iir滤波器flt3接收第二级的输出数据dout[2]作为输入数据din[3],并输出输出数据dout[3]。以这种方式,三级iir滤波器接收输入数据din[1],并且将输出数据dout[3]作为整体输出。
[0067]
图8是示出图2中的硬件加速器的控制电路的处理内容的示例的流程图。在此,假设一种情况,即,控制电路ctl使算术单元cal和存储器mem充当图7中所示的三级iir滤波器。在图8中,控制电路ctl接收来自cpu的指令cmd,并且首先设置n=1(步骤s101)。
[0068]
随后,控制电路ctl通过使用来自cpu的输入数据(即,图7中第一级处的输入数据din[1])使算术单元cal执行在第n级处的输出数据运算(步骤s102)。接着,控制电路ctl重复执行步骤s102和s103的处理,同时使n递增(步骤s103,直到n变得大于最大级数n(这里,n=3)(步骤s104)。
[0069]
结果,末级的iir滤波器的输出数据,即,图7的输出数据dout[3]由算术单元cal获得。当在步骤s104中n变得大于n时,控制电路ctl使算术单元cal经由接口if将末级的iir滤波器的输出数据输出到cpu(步骤s105)。
[0070]
此后,控制电路ctl再次设置n=1(步骤s106)。随后,控制电路ctl使算术单元cal在第n级处执行延迟数据运算(步骤s107)。接着,控制电路ctl重复执行步骤s107和s108的处理,同时使n递增(步骤s108),直到n变得大于最大级数n(n=3)(步骤s109)。结果,将被保持在图7中的iir滤波器flt1到flt3的每一个中的延迟块db1和db2中和图2的存储器mem中的算出数据(延迟数据)d6'和d7'被确定,并且作为三级iir滤波器的一系列处理被完成。
[0071]
图9是示出图8中的流程中的算术单元的详细的算术运算程序的示例的图。在这里假设这样一种情况,即,图2中的算术单元cal包括一个被配置为将两个数据相加的加法器add和一个被配置为将两个数据相乘的乘法器mul,并且加法器add和乘法器mul可以在处理器prc的一个时钟周期内执行一个算术运算并且可以并行执行该算术运算。在这种情况下,例如,三个数据相加(x=a b c)通过在两个时钟周期中相加来实现(tmp=a b,x=tmp c)。
[0072]
作为图9的示意性运算,在接收来自cpu的指令cmd后,控制电路ctl首先使算术单元cal从第一级到末级顺序执行多级(这里为三级)iir滤波器中的输出数据运算。此后,控制电路ctl使算术单元cal从第一级到末级顺序执行多级iir滤波器中的延迟数据运算。然后,在末级的iir滤波器中的输出数据运算完成时,控制电路ctl使算术单元cal将末级iir滤波器的输出数据dout[3]输出到cpu。.
[0073]
作为图9的详细运算,算术单元cal首先在两个时钟周期中执行第一级的输出数据运算,然后分别在两个时钟周期中执行第二级和第三级的输出数据运算。在第一级的输出数据运算中,算术单元cal从cpu接收输入数据din[1],在第一时钟周期中生成算出数据d1
[1],并且在第二时钟周期中生成输出数据dout[1]。在这里,[x]中的“x”表示级数。
[0074]
在第二级的输出数据运算中,算术单元cal接收第一级的输出数据dout[1]作为输入数据din[2],并且类似地生成算出数据d1[2]和输出数据dout[2]。这同样适用于第三级的输出数据运算。
[0075]
此后,算术单元cal在五个时钟周期中在第一级处执行延迟数据运算,随后分别在五个时钟周期中在第二级和第三级处执行延迟数据运算。在这里,控制电路ctl在如上所述的第一级的输出数据运算之前使存储器mem保持来自cpu的输入数据din[1]。然后,控制电路ctl通过使用所保持的输入数据din[1]使算术单元cal从第一级到第三级顺序执行延迟数据运算。换言之,算术单元cal从头开始再次执行多级处的iir滤波器的运算。
[0076]
在第一级的延迟数据运算中,算术单元cal在五个时钟周期中的第一个时钟周期和第二时钟周期中顺序生成算出数据d1[1]和d2[1],并且还在第二时钟周期中并行生成输出数据dout[1]。然后,算术单元cal在第三、第四和第五时钟周期中顺序生成算出数据d3[1]、d4[1]和d5[1],并且与之并行,在第三时钟周期和第五时钟周期中分别生成算出数据d6[1]。关于算出数据d6[1],具体而言,算术单元cal在第三时钟周期中将算出数据d2[1]与延迟数据d7'[1]相加,并且在第五时钟周期中将相加结果与算出数据d4[1]相加。
[0077]
除以下两个不同之外,在第二级处的延迟数据计算与第一级处的相同。第一个不同之处在于,算术单元cal通过将第一级的输出数据dout[1]用作第二级的输入数据din[2]来执行运算处理。第二个不同之处在于,与在第二级处生成算出数据d1[2]并行,算术单元cal在五个时钟周期中的第一时钟周期中在第一级处生成算出数据d7[1]。在第三级处的延迟数据运算与在第二级处的相同。
[0078]
图10是示出与图9不同的算术运算程序的示例的图。在图10中,第一级、第二级和第三级处的输出数据运算与图9相同。然而,在图10中,不同于图9的情况,控制电路ctl使存储器mem保持通过在第一至第三级处的输出数据运算而获得的算出数据,在这个示例中是输出数据dout[1]、dout[2]和dout[3]。然后,控制电路ctl通过使用所保持的算出数据使算术单元cal执行第一级到第三级处的延迟数据运算。
[0079]
在此,在第一级处的iir滤波器flt1的延迟数据运算的时候,当输出数据dout[1]被保持时,算术单元cal可以生成算出数据d4[1],d5[1]等,而不生成算出数据d1[1]。这同样适用于第二级和第三级。因此,在图10中的第一级、第二级和第三级处的延迟数据运算中,与图9的情况相比,删除了用于生成算出数据d1[1]、d1[2]和d1[3]的时钟周期。
[0080]
结果,算术单元cal可以在四个时钟周期中执行在第一级处的延迟数据运算,随后分别在四个时钟周期中执行在第二级和第三级处的延迟数据运算。此外,在四个时钟周期中的第一时钟周期中,算术单元cal在前一级生成算出数据d7[1]和d7[2],它们与图9中的算出数据d1[2]和d1[3]并行地被生成。即,算术单元cal在第二级处的延迟数据运算中的第一时钟周期中与算出数据d2[2]并行地生成第一级的算出数据d7[1],并且在第三级处的延迟数据运算中的第一时间周期中与算出数据d2[3]并行地生成第二级的算出数据d7[2]。
[0081]
当对图9的方法和图10的方法进行比较时,从延迟数据运算所需的时钟周期数的观点来看,图10的方法是有益的。然而,在图10的方法中,由于有必要使存储器mem保持与iir滤波器的级数相对应的输出数据dout[1]、dout[2]和dout[3],因此图9的方法从电路规模(例如,寄存器数量等)的观点来看是有益的。虽然图3a的配置示例在此被用于每一级的
iir滤波器,但是当图10的方法通过使用图4a的配置示例而被使用时,控制电路ctl只是使存储器mem保持在输出数据运算中获得的每一级的算出数据d1。
[0082]
(第一实施例的主要效果)
[0083]
如上所述,通过使用第一实施例的方法,有可能缩短获得来自iir滤波器的输出数据之前的时间。结果,在各种控制系统中,可以在控制周期内完成必要的处理,而不用例如增加处理器的时钟频率的速度。从另一角度来看,可以缩短控制周期,并且可以构建高精度控制系统。下面将描述其细节。
[0084]
图14是流程图,其示出根据本发明的比较示例的半导体设备中的硬件加速器中的控制电路的处理内容的示例。在图14中所示的流程中,与图8中所示的流程不同,在每一级的处理中,第n级的延迟数据运算(步骤s107)在第n级的输出数据运算(步骤s102)之后被执行。然后,在末级的输出数据运算和延迟数据运算被完成时(步骤s104),输出数据被输出到cpu(步骤s105)。
[0085]
图11是概念图,其示出使用图8的实施例的流程的情况与使用图14中的比较示例的流程之间的控制系统的处理流程的比较。如图11中所示,在包括iir滤波器的一般控制系统中,在控制周期tc中提供cpu处理周期cpu_p[1]、cpu_p[2]和cpu_p[3]以及iir滤波器运算等待周期iir_w[1]和iir_w[2]。
[0086]
例如,cpu在cpu处理周期cpu_p[1]内执行预定处理,然后通过输出指令cmd和输入数据din使硬件加速器hwa执行iir滤波器的运算。随后,cpu等待,直到在等待周期iir_w[1]中获得来自硬件加速器hwa的输出数据dout。此后,当获得输出数据dout时,cpu通过在cpu处理周期cpu_p[2]中使用输出数据dout来执行下一处理。
[0087]
在上述控制系统的处理中,为了获得输出数据dout,比较示例的方法中的cpu需要等待,直到末级(在这里是第三级)的延迟数据运算被完成,即,多级的iir滤波器中所有的输出数据运算和延迟数据运算被完成。因此,担心的是,等待周期iir_w[1]、iir_w[2]变长并且必需的处理时间超过控制周期tc。此外,为了缩短必需的处理时间,需要提高处理器的时钟频率的速度,这可能导致成本增加和功耗增加。
[0088]
另一方面,为了获得输出数据dout,本实施例方法中的cpu只等待到多级的iir滤波器中的输出数据运算被完成。cpu可以通过使用通过该输出数据运算获得的输出数据dout来执行下一处理。此外,cpu可以使硬件加速器hwa在多级的iir滤波器中与下一处理并行地执行延迟数据运算。
[0089]
结果,通过使用本实施例的方法,与比较示例的方法相比,可以缩短等待周期iir_w[1]和iir_w[2],并且可以在控制周期tc内将必需的处理时间缩短时间δt。因此,也可以缩短控制周期tc。
[0090]
(第二实施例)
[0091]
(电机控制设备的应用示例)
[0092]
图12是示意图,其示出本发明第二实施例的电机控制设备周围的配置示例。图12示出了包括半导体设备dev、预驱动器pdv、逆变器inv、电机mt和位置传感器pg的电机控制系统。其中例如,半导体设备dev、预驱动器pdv、逆变器inv被安装在布线板上以形成电机控制设备。电机mt例如是三相(u相、v相、w相)无刷直流电机等,并且对被控制对象的位置执行控制。位置传感器pg被附接到电机mt并检测电机mt的旋转位置。
[0093]
逆变器inv包括三相高侧开关元件和三相低侧开关元件,三相高侧开关元件被连接在高电位侧电源与电机mt的三相输入端子之间,三相低侧开关元件被连接在低电位侧电源与电机mt的三相输入端子之间。逆变器inv通过切换每个开关元件向电机mt供给电功率,具体而言是三相交流电功率。预驱动器pdv接收来自半导体设备dev的三相pwm信号,并且基于pwm信号来控制逆变器inv中的每个开关元件。
[0094]
如第一实施例中所描述的,半导体设备dev例如由微控制器等构成,并且包括位置/速度控制器psct、电流控制器ict、以及pwm单元pwmu。位置/速度控制器psct和电流控制器ict例如通过图1中的处理器prc的程序处理而被实现,并且pwm单元pwmu例如由图1中的各种外围电路peri中包括的硬件单元来实现。
[0095]
基于将以预定控制周期输入的电机mt的感测结果,半导体设备dev经由逆变器inv示意性地控制电机mt。电机mt的感测结果包括由位置传感器pg检测的位置值和由电流传感器(未示出)检测的电机的三相电流值。当感测结果是模拟值时,半导体设备dev通过使用在各种外围电路peri中包括的模数转换器将其转换成数字值,然后将数字值输出到位置/速度控制器psct和电流控制器ict。
[0096]
位置/速度控制器psct基于来自位置传感器pg的位置检测值来控制电机mt的位置和速度。在位置/速度控制器psct中,例如基于预定的控制序列,位置指令单元10生成用于确定受控对象位置的位置指令值。减振控制单元11校正来自位置指令单元10的位置指令值并生成校正的位置指令值,以便抑制受控对象在该位置确定期间可能发生的残余振动。速度前馈(简称ff)运算单元12基于校正的来自减振控制单元11的位置指令值,来计算速度ff补偿值。
[0097]
pi(比例/积分)控制与相位补偿单元13计算用于使该误差接近零的操纵值,即,基于来自减振控制单元11的校正的位置指令值与来自位置传感器pg的位置检测值之间的误差的速度指令值。此时,pi控制与相位补偿单元13计算该速度指令值,同时反映来自速度ff运算单元12的速度ff补偿值。此外,pi控制与相位补偿单元13计算用于使误差接近零的操纵值,即,基于速度指令值与来自瞬时速度观测器17的检测速度值之间的误差的转矩指令值。
[0098]
例如,机械共振抑制滤波器14是用于抑制受控对象共振的陷波滤波器,并且对来自pi控制与相位补偿单元13的操纵值进行滤波。转矩补偿单元15对来自机械共振抑制滤波器14的滤波后的操纵值进行补偿,即,例如根据电机mt的负载大小的转矩指令值。
[0099]
基于来自转矩补偿单元15的转矩指令值,弱磁通控制单元16生成d轴电流指令值和q轴电流指令值。瞬时速度观测器17基于来自位置传感器pg的位置检测值和来自转矩补偿单元15的转矩指令值来计算该速度检测值。具体而言,例如基于位置检测值的微分值和转矩指令值的积分值,瞬时速度观测器17计算该速度检测值。
[0100]
基于来自位置传感器pg的位置检测值、来自位置/速度控制器psct的d轴电流指令值和q轴电流指令值、以及来自电流传感器(未示出)的上面提及的三相检测电流值,电流控制器ict控制电机mt的电流并最终控制转矩。在电流控制器ict中,基于来自位置传感器pg的位置检测值,dq转换单元25将来自电流传感器(未示出)的三相电流检测值转换成d轴检测电流值和q轴检测电流。
[0101]
死区时间补偿单元24校正由pwm单元pwmu插入的死区时间引起的电压指令与实际
输出电压之间的误差,并且基于来自电流传感器(未显示)的三相检测电流值对电压指令值进行补偿。死区时间是需要在逆变器inv每个相位中的高侧开关元件的导通/截止时间与低侧开关元件的截止/导通时间之间提供的间隔。
[0102]
基于来自位置/速度控制器psct、具体而言来自弱磁通控制单元16的d轴电流指令值和q轴电流指令值,电压ff运算单元20计算电压ff补偿值。电压ff补偿值例如对由于死区时间引起的电压误差进行补偿。基于来自位置/速度控制器psct的d轴电流指令值和q轴电流指令值与来自dq转换单元25的d轴电流检测值和q轴电流检测值之间的误差,pi控制与相位补偿单元21计算使误差接近零的操纵值,即,d轴电压指令值和q轴电压指令值。此时,pi控制与相位补偿单元21计算d轴电压指令值和q轴电压指令值,同时反映来自电压ff运算单元20的电压ff补偿值。
[0103]
通过使用来自位置传感器pg的位置检测值来执行逆停车转换,dq逆转换单元22将来自pi控制与相位补偿单元21的d轴电压指令值和q轴电压指令值转换成α轴电压指令值和β轴电压指令值。基于指定的调制模式,空间矢量调制单元23将来自dq逆转换单元22的α轴电压指令值和β轴电压指令值调制成三相电压指令值,并且最终调制成三相pwm占空比指令值。
[0104]
基于来自电流控制器ict,具体地来自空间矢量调制单元23的三相pwm占空比指令值,pwm单元pwmu生成反映占空比指令值的三相pwm信号。此时,pwm单元pwmu插入死区时间,以防止由于高侧开关元件和低侧开关元件同时导通而导致短路。然后,pwm单元pwmu通过使用三相pwm信号经由预驱动器pdv来控制逆变器inv中的每个开关元件。
[0105]
在上述的半导体设备dev中,例如,双二阶iir滤波器被安装在位置/速度控制器psct中的减振控制单元11、机械共振抑制滤波器14、转矩补偿单元15和瞬时速度观测器17中。例如,级联连接的六级iir滤波器被安装在减振控制单元11中,级联连接的五级iir滤波器被安装在机械共振抑制滤波器14中。此外,级联连接的五级iir滤波器被安装在转矩补偿单元15中,级联连接的两级iir滤波器被安装在瞬时速度观测器17中。
[0106]
在这种电机控制设备中使用的半导体设备dev中,有必要在电机mt的控制周期内完成包括位置/速度控制器psct、电流控制器ict和pwm单元pwmu在内的一系列处理。另一方面,特别是当需要以高速和高精度控制电机mt时,可能如图12中所示需要许多提供了iir滤波器的控制块。因此,担心的是,如图11中所示,半导体设备dev的处理时间会增加并超过控制周期tc。电机mt的控制周期tc例如被设置为几十μs。
[0107]
作为具体的示例,参考图11,半导体设备dev中的cpu在cpu处理周期cpu_p[1]内完成位置指令单元10的处理,然后在等待周期iir_w[1]内使硬件加速器hwa执行减振控制单元11中的iir滤波器的算术运算。随后,cpu接收来自硬件加速器hwa的输出数据dout,并且在cpu处理周期cpu_p[2]内执行速度ff运算单元12和pi控制与相位补偿单元13的处理。此后,cpu在等待周期iir_w[2]内使硬件加速器hwa执行机械谐振抑制滤波器14中的iir滤波器的算术运算。然后,以相同的方式顺序执行必要的过程。
[0108]
因此,如果如第一实施例中所述使用预先执行输出数据运算的方法,则有可能如图11中所述缩短半导体设备dev的处理时间。结果,实现高速和高精度的电机控制变成可能。具体地,例如,可以缩短控制周期,并且可以在控制周期内实现iir滤波器的更多运算处理。
[0109]
图13a和图13b是概念图,其示出各种处理系统中的算术运算方法的示例。图13a示出了批量运算方法的处理流程。批量运算方法例如是在非实时处理中使用的方法,其中对在一定程度上收集的输入数据din执行一次运算处理,然后生成输出数据dout。例如,可以呈现一种情况,即,如在音频处理中,缓冲一定量的输入数据din被缓冲并且定期对多个输入数据din进行一次处理。
[0110]
图13b示出了单一运算方法的处理流程。单一运算方法例如是在实时处理中使用的方法,其中只需要在输入第二输入数据之前完成对第一输入数据din的运算处理。在图13a的方法的情况下,有必要在完成对第一输入数据din的输出数据运算和延迟数据运算之后对第二输入数据din执行运算处理。因此,难以获得预先执行输出数据运算的效果,并且例如,仅能较早获得与最终运算处理相关联的输出数据的效果。
[0111]
另一方面,在电机控制中,图13b中所示的单一运算方法可以在电机控制中被使用。在图13b的方法的情况下,如上所述,通过预先执行输出数据运算可以获得大的效果。在将其应用于除了上述的电机控制之外还使用单一运算方法的处理系统和控制系统时,本实施例的方法能够获得有益效果。
[0112]
(第二实施例的主要效果)
[0113]
如上所述,通过使用第二实施例的方法,可以获得与第一实施例中描述的各种效果相同的效果。除此之外,还可以实现高速、高精度的电机控制。
[0114]
在上文中,基于实施例具体描述了本发明人做出的发明,但本发明不限于上述实施例,并且可以在不脱离其主旨的范围内对其进行各种修改。例如,为了让本发明容易理解,对上述实施例进行了详细描述,但本发明不必限定于具有全部所述配置的实施例。此外,可以将一个实施例的配置的一部分替换为另一实施例的配置,并且可以将一个实施例的配置添加到另一实施例的配置。此外,也可以将另一配置添加到每个实施例的配置的一部分,并且每个实施例的配置的一部分也可以被去除或者用另一配置来替换。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。