一种基于多变量多步lstm模型的气体浓度预测方法
技术领域
1.本发明涉及气体浓度的预测,具体涉及一种基于多变量多步lstm模型的气体浓度预测方法,属于环境气体检测领域。
背景技术:
2.在我国经济不断发展的背景下,人们的生活水平得到了显著的提高,但是因经济发展带来的环境污染问题也越来越严重,特别是近几年,人口总量不断增加,经济快速发展,大量排放的汽车尾气、工厂废气等都对大气环境造成了严重污染,还出现了雾霾现象。已经严重威胁到人们的健康。面对当今社会的环境问题,有效解决的前提就是实行环境气体监测。因此,通过技术对有害气体浓度进行检测、分析、提出合理有效的解决措施是很有必要的。
3.在煤矿安全生产管理当中,气体浓度监测也占据着重要地位,及时对煤矿气体浓度进行检测不仅能保障人民的生命财产安全,还能促进煤矿安全防控技术发展。煤矿热动力耦合灾害是危害性极大的灾害,它的发生严重威胁矿井生产和井下工人的生命安全,同时有害气体直接影响工人的身体健康甚至使人窒息死亡。针对煤矿安全尤其是爆炸相关的气体浓度预测得到了研究者的广泛重视。
4.20世纪70年代前,大多采用人工取样对气体进行分析,效率低。随着机器学习的发展,如人工神经网络、支持向量机、专家系统等开始应用于环境气体检测(赵羚宇.基于神经网络的危险气体扩散预测模型研究[d].中国石油大学(北京),2020.doi:10.27643/d.cnki.gsybu.2020.001534.)。同时,机器学习也广泛用于采空区灾害气体的定量评价与分析中(付华.煤矿瓦斯灾害特征提取与信息融合技术研究[d].阜新:辽宁工程技术大学,2006.c)。煤与瓦斯含量以及传感器测量得到的氧气、温度或co等数据属于典型的时间序列,应用时间序列的机器学习预测方法对气体浓度进行预测逐渐成为一种新的趋势。
技术实现要素:
[0005]
本发明的目的在于实现一种基于多变量多步lstm模型的气体浓度预测方法,能为环境气体监测提供了一套完整、高效、可行的解决方案。
[0006]
本发明提供的一种基于多变量多步lstm模型的气体浓度预测方法,具体包括:1)对输入的多种气体浓度及温度的时间序列数据做预处理,选择关键的指标气体;2)利用所选取指标气体浓度及温度时间序列数据构建滑动窗口数据集;3)构建多变量多步lstm模型;4)训练多变量多步lstm模型;5)用验证集对训练好的模型进行验证评估;6)用测试集测试多变量多步模型,调整并选择最优模型参数;7)用构建的模型对现场气体浓度进行预测;具体来说,本发明的方法包括下列步骤:
[0007]
a.对输入的多种气体浓度及温度的时间序列数据做预处理,选择关键的指标气体,具体步骤如下:
[0008]
a1.将输入的多种气体浓度及温度的时间序列数据做归一化处理;
[0009]
a2.分析不同气体浓度与温度之间以及不同气体浓度两两之间的关联关系;
[0010]
a3.综合步骤a2的结果,选择相关性最大的k种气体以及温度做气体浓度预测;
[0011]
b.利用所选取的k种指标气体浓度及温度时间序列数据构建滑动窗口数据集,具体步骤如下:
[0012]
b1.选取指标气体1的时间序列数据记为a,a={ai},i》=1;ai表示第i个时间节点的气体浓度值;
[0013]
b2.构造一个长度为l,滑动步长为s的滑动窗口,窗口从a1开始滑动提取时间序列数据中的元素形成滑动窗口数据集;其中,l》=1,s》=1,具体步骤如下:
[0014]
b2.1选取a1至a
1 l
的元素构成第一个样本w
11
=(d
x1
,d
y1
),d
x1
作为模型的输入值,记为d
x1
={ai},1《=i《=l;d
y1
作为模型的期望输出,d
y1
=a
1 l
;
[0015]
b2.2选取a
1 s
至a
1 l s
的元素构成第二个样本w
12
=(d
x2
,d
y2
),d
x2
作为模型的输入值,记为d
x2
={a
i s
},1《=i《=l;d
y2
作为模型的期望输出,d
y2
=a
1 l s
;
[0016]
b2.3按照步骤b2.1和b2.2所述方式构造后续的样本w
1t
,3《=t《=n,n表示预设的样本个数;
[0017]
b2.4样本1到样本n构成气体1的滑动窗口数据集,记为w1,w1={w
1t
},1《=t《=n;
[0018]
b3.按照步骤b1和b2所述方式为k种指标气体及温度分别构建滑动窗口数据集;
[0019]
b4.将温度及所有气体的滑动窗口数据集合并为样本集w={wj},1《=j《=k 1;
[0020]
b5.按比例r1:r2:r3将样本集划分为训练集o、验证集p和测试集q,每个集合的样本个数记为no,np,nq;训练集用于模型训练,验证集用于模型评估,测试集用于模型测试;
[0021]
c.构建多变量多步lstm模型,具体步骤如下:
[0022]
c1.构建lstm1,单元状态记为ct1,隐藏状态记为ht1;
[0023]
c2.构建lstm2,将ct1和ht1传输给lstm2,lstm2的单元状态记为ct2,隐藏状态记为ht2;
[0024]
c3.重复以上操作,将k 1个lstm单元并联成为多变量多步lstm模型,记为mlstm,mlstm={lstmj},1《=j《=k 1;
[0025]
d.训练mlstm,具体步骤如下:
[0026]
d1.设定训练的超参数,包括模型初始化的随机种子数seed、学习率lr、模型训练总轮数epoch,一个训练批次的样本个数batch_size;
[0027]
d2.根据设定的随机种子数seed初始化mlstm状态种子;
[0028]
d3.获取训练集o,记为o={o
ji
},1《=i《=no,1《=j《=k 1;
[0029]
d4.用batch_size个样本作为一批数据训练模型,1《=batch_size《=no,具体步骤如下:
[0030]
d4.1把第j列的样本集oj当中的batch_size个样本{o
ji
}作为一批数据,1《=j《=k 1,1《=i《=batch_size;
[0031]
d4.2把该批数据中的每个样本o
ji
=(d
xi
,d
yi
)j中的d
xi
作为lstmj的输入,得到预测输出yj,1《=i《=batch_size;
[0032]
d4.3用该批数据中的每个样本o
ji
=(d
xi
,d
yi
)j中的d
yj
作为lstmj的期望输出,用期望输出d
yj
和预测输出yj计算每个样本的损失loss;
[0033]
d4.4用该批数据所有样本的损失loss,计算批数据损失mloss;
[0034]
d4.5用批数据损失mloss计算梯度,用梯度和学习率lr更新模型的参数;
[0035]
d5.用全部训练集中的后续批次数据,按照步骤d4所述方式迭代训练并更新模型的参数,直到批数据损失mloss收敛达到预设标准,作为一轮训练;
[0036]
d6.按照epoch的设置重复训练epoch轮,判断批数据损失mloss是否达到预设标准;
[0037]
d7.如批数据损失mloss未达到预设标准,则调整参数lr、epoch以及batch_size,按照步骤d3到d6所述方式迭代训练模型;如已达到指定标准,则结束训练,导出训练好的模型的参数;
[0038]
e.用验证集对训练好的模型进行验证评估,具体步骤如下:
[0039]
e1.获取验证集p,记为p={p
ji
},1《=i《=np,1《=j《=k 1;
[0040]
e2.把验证集中所有样本输入模型,得到模型的预测结果,具体步骤如下:
[0041]
e2.1把第j列的样本集pj当中的每个样本p
ji
=(d
xi
,d
yi
)j中的d
xi
作为lstmj的输入,得到预测输出yj,1《=i《=np;
[0042]
e2.2把k 1个lstm单元的期望输出的集合,记为mlstm的期望输出;把k 1个lstm单元的预测输出的集合,记为mlstm的预测输出;
[0043]
e3.使用mlstm的期望输出和预测输出,计算均方误差rmse;
[0044]
e4.用rmse对模型进行评估,该值越小,表示模型的准确率越高;
[0045]
e5.若准确率没有达到预设标准,则重复d所述步骤,调整滑动窗口数据集的长度l和步长s、一个训练批次的样本个数batch_size、模型训练总轮数epoch和学习率lr,重新训练模型;
[0046]
f.用测试集测试mlstm模型,调整并选择最优模型参数,具体步骤如下:
[0047]
f1.用步骤e所述方式,用测试集代替验证集,把数据输入模型预测气体浓度,并判断是否达到rmse的预设标准;
[0048]
f2.若准确率没有达到预设标准,则重复d所述步骤,调整滑动窗口数据集的长度l和步长s、一个训练批次的样本个数batch_size、模型训练总轮数epoch和学习率lr,重新训练模型;
[0049]
f3.如果达到预设标准,将预测效果最优的模型导出,作为最终模型;将最优的滑动窗口数据集长度记为l0,步长记为s0;
[0050]
g.用构建的模型对现场气体浓度进行预测,具体步骤如下:
[0051]
g1.按照步骤f得到的最优滑动窗口数据集长度l0和步长s0,截取k种现场气体的浓度及温度时间序列数据,具体步骤如下:
[0052]
g1.1选取指标气体1的时间序列数据记为a,a={ai},i》=1;ai表示第i个时间节点的气体浓度值;
[0053]
g1.2构造一个长度为l0的滑动窗口,窗口从a1开始滑动提取时间序列数据中的元素形成滑动窗口数据单元u1;
[0054]
g1.3按照步骤g1.1和g1.2所述方式为k种指标气体及温度分别构建滑动窗口数据单元;
[0055]
g1.4将k种气体及温度的滑动窗口数据单元合并为k 1个元素的矩阵记为u,u={uj},1《=j《=k 1;
[0056]
g2.将矩阵u中的每个单元uj输入lstmj,得到每种气体浓度的预测结果;
[0057]
g3.按照滑动步长s0,截取下一段现场气体浓度及温度时间序列数据,按照步骤g1和g2所述方式,预测后续的气体浓度。
[0058]
本发明与现有技术相比,具有以下优点:实现了一套完整的基于多变量多步lstm模型预测多种气体浓度的方法,包括关键指标气体的选取、滑窗数据集的构建、多变量多步lstm的具体构建方法及训练、评估模型、用模型对现场气体进行预测的完整过程和步骤,为环境气体监测提供了一套完整、高效、可行的解决方案,具有较高的应用价值及推广价值。
附图说明
[0059]
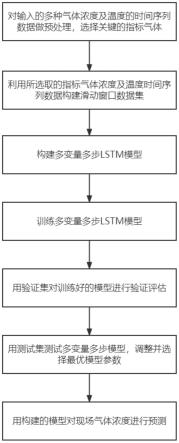
图1本发明基于多变量多步lstm的气体浓度预测方法的流程图;
[0060]
图2本发明具体实施例中氧气浓度为20.9%时气体浓度随温度变化趋势;
[0061]
图3本发明具体实施例中气体浓度数据相关性分析;
[0062]
图4本发明具体实施例中滑动窗口数据构建示意图;
[0063]
图5本发明具体实施例中mlstm的loss曲线。
具体实施方式
[0064]
下面结合附图和具体实施例对本发明进行详细说明。
[0065]
本实施例使用的气体检测环境供气流量为100cm3/min,在25~80℃范围内升温速率为0.5℃/min,在80~200℃范围内为1℃/min,在200~300℃范围内为2℃/min。采集的数据有13240条,通过数据清洗和剔除异常数据后剩余11342条数据。
[0066]
本发明流程图如图1所示,本发明方法包括:1)对输入的多种气体浓度及温度的时间序列数据做预处理,选择关键的指标气体;2)利用所选取指标气体浓度及温度时间序列数据构建滑动窗口数据集;3)构建多变量多步lstm模型;4)训练多变量多步lstm模型;5)用验证集对训练好的模型进行验证评估;6)用测试集测试多变量多步lstm模型,调整并选择最优模型参数;7)用构建的模型对现场气体浓度进行预测;
[0067]
下面按照步骤,结合数据实例对本发明作进一步描述,以一组实验数据作为示例:
[0068]
1.对输入的多种气体浓度及温度的时间序列数据做预处理,选择关键的指标气体,具体步骤如下:
[0069]
选取10种输入气体,分别为o2、n2、co、co2、ch4、c2h6、c2h4、c3h8、c3h6、c2h2;o2和n2浓度单位为%,其他为ppm浓度;
[0070]
1.1将输入的12种气体浓度及温度的时间序列数据做归一化处理;
[0071]
根据公式(1-1)将输入的每一种气体浓度归一化到区间[0,1];
[0072][0073]
1.2分析不同气体的浓度与温度之间以及不同气体浓度两两之间的关联关系;
[0074]
co、ch4、c2h6、c3h8、c2h4、c3h6气体与温度的关联关系如图2所示;随着温度的升高,当供氧气浓度为20.9%,150℃时,co及ch4浓度呈一致趋势迅速上升,c3h8、c2h4、c2h6、c3h6呈一致趋势缓慢增加;
[0075]
对采集的原始数据进行相关性分析,正值表明正相关,负值表明负相关,绝对值越
大,相关性越强;多种气体两两之间的关联关系如图3所示,co2及n2两种气体与其他气体的相关性均不高,故排除;co及ch4两种气体与c2h2、c3h6,c3h8与c2h2,c2h6与c2h2,c2h4与c2h2及c3h6之间的相关系数在0.75左右,co、c2h4、c3h6、c2h2、ch4、c2h4/c2h6、c3h8/c2h6两两间的相关性均接近1;
[0076]
1.3综合步骤1.2的结果,选择相关性最大的7种气体以及温度做气体浓度预测;
[0077]
根据上述分析,实验变量选取共计8项分别是[temperature,co,c2h4,c3h6,c2h2,ch4,c2h4/c2h6,c3h8/c2h6];
[0078]
2.利用所选取的7种指标气体浓度及温度时间序列数据构建滑动窗口数据集,具体步骤如下:
[0079]
2.1选取指标气体1的时间序列数据记为an,an={ai},i》=1;ai表示第i个时间节点的气体浓度值;
[0080]
2.2构造长度l为7,滑动步长s分别为5的滑动窗口,窗口从a1开始滑动提取时间序列数据中的元素形成滑动窗口数据集;
[0081]
滑动窗口数据构建示意图如图4所示:
[0082]
2.3按照步骤2.1和2.2所述方式为其他6种指标气体及温度构建滑动窗口数据集;
[0083]
2.4将温度及所有气体的滑动窗口数据集合并为样本集w={wj},1《=j《=8;
[0084]
表1输入数据格式
[0085]
tab...k1a1xb1x...k1x2a2xb2x...k2x3a3xb3x...k3x4a4xb4x...k4x5a5xb5x...k5x6a6xb6x...k6x7a7xb7x...k7x
[0086]
2.5按比例6:3:1将样本集划分为训练集o、验证集p和测试集q,每个集合的样本个数记为no,np,nq;训练集用于模型训练,验证集用于模型评估,测试集用于模型测试;3.构建多变量多步lstm模型,具体步骤如下:
[0087]
3.1将8个lstm单元并联成为多变量多步lstm模型,记为mlstm,mlstm={lstmj},1《=j《=8;
[0088]
构建mlstm预测模型的整体框架包括输入层、隐藏层、输出层3个功能模块;输入层是对指标气体时间序列数据进行处理满足网络输入要求,并且对数据进行窗口数据划分;隐藏层采用单层循环神经网络;输出层提供预测结果;
[0089]
4.训练多变量多步lstm模型,具体步骤如下:
[0090]
4.1设定训练的超参数,包括模型初始化的随机种子数seed、学习率lr=0.001、模型训练总轮数epoch=300,一个训练批次的样本个数batch_size=32;
[0091]
4.2根据设定的随机种子数seed初始化mlstm状态种子;
[0092]
4.3获取训练集o,记为o={o
ji
},1《=i《=1360,1《=j《=8;
[0093]
4.4用32个样本作为一批数据训练模型,计算批数据损失mloss,并计算梯度,用梯
度和学习率lr更新模型的参数;
[0094]
4.5用全部训练集中的后续批次数据,迭代训练并更新模型,直到批数据损失mloss收敛达到预设标准,作为一轮训练;
[0095]
4.6重复训练300轮,loss曲线如图4所示,达到指定标准,结束训练,导出训练好的模型参数;
[0096]
5.用验证集对训练好的模型进行验证评估,具体步骤如下:
[0097]
5.1获取验证集p,记为p={p
ji
},1《=i《=680,1《=j《=8;
[0098]
5.2把验证集中所有样本输入模型,得到模型的预测结果;
[0099]
5.3使用mlstm的期望输出和预测输出,计算均方误差rmse和平均绝对误差mae,定量评估模型的拟合和预测精度;
[0100]
5.4用rmse和mae对模型进行评估,已达到预设标准;
[0101]
6.用测试集测试mlstm模型,调整并选择最优模型参数,具体步骤如下:
[0102]
6.1.用步骤5所述方式,用测试集代替验证集,测试滑动步长为5,10,30的样本集训练出来的三种模型的预测精度结果如表2:
[0103]
表2不同步长下的预测精度
[0104][0105][0106]
结果表明采用窗口长度为11,步长为5的滑动窗口截取时间序列数据来构造数据单元时,mlstm模型预测精度最高;
[0107]
7.用构建的模型对现场气体浓度进行预测,能够达到应用的需求。
[0108]
最后需要注意的是,公布实施的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。