1.本发明涉及一种具有情感与记忆机制的迷宫机器人自主搜索的认知学习方法,属于智能机器人技术领域。
背景技术:
2.情感作为人们日常生活中不可或缺的元素,它时刻影响着我们的认知、决策、交流等。实现机器人情感智能,把情感对人的有益影响迁移到机器人系统中,让机器人能够与人类和社会更自然、和谐的相处是机器人领域努力的目标之一。同时,只有机器人具有情感反应,也才会引起人们真正的关心,情感是实现人类对机器人可信度主要手段之一。因此,机器人情感对人类与机器人本身都有着重要作用。具有情感机制的机器人认知研究,是在认知机器人的基础上加入了类似于人的情感因素,让情感参与到机器人与人、物体和环境的交互学习中,从而影响其感知、推理和决策等能力,使机器人的学习与认知过程更接近于人类学习与认知的过程。在机器人研究中加入情感能有效提高机器人学习效率以及自主性。
3.情感与认知之间联系有着积淀已久的理论性基础和神经生理性结构原理,因此情感参与到认知与行为机制是必须要明确解决的关键性问题。因此,本发明以心理学与神经生理学学基础,为机器人搭建情感-记忆认知模型与认知学习方法,通过模仿人的心理与思考过程,赋予机器人类似于人的情感因素与思维方式。相关的专利如申请号cn201811343603.6提出了一种具有发育机制的感知行动认知学习方法,以心理学与生理学为基础结合潜在动作理论,通过引入好奇心的方式,提高了机器人的学习速度与稳定性。申请号cn202110918358.2传统的sarsa算法基础上,引入走过的路径矩阵p(s,a),实现动态调整贪婪因子ε,提高算法的探索能力。2009年daglarli等受计算机体系结构emib的启发把基于情感的控制方法和认知模型相结合,为四轮移动机器人提出一种基于人工情感的自主机器人控制结构,该结构有三部分组成:行为系统、人工认知模型和核心的情感-动机模块,实现了机器人根据当前的情感对未来的行为进行预测和路径规划。
4.本发明以情感与认知的心理学与生理学为基础结合强化学习,提出一种具有情感与记忆机制的迷宫机器人自主搜索的认知学习方法,使得机器人在探索迷宫的过程中具有类似生物的产生情感与记忆过程,引入具有情感与记忆机制,提高了机器人的自主性与学习效率。
技术实现要素:
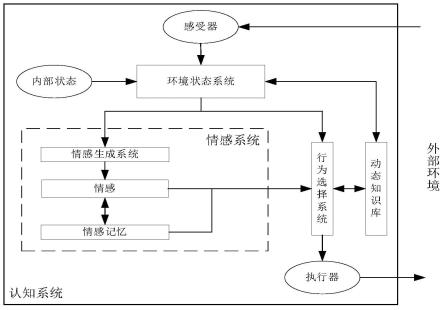
5.本发明涉及一种具有情感与记忆机制的迷宫机器人自主搜索的认知学习方法,属于智能机器人技术领域。所公开的的情感与记忆机制的认知学习方法依赖于情感-记忆认知模型,具体结合新的奖励机制,设计了模型结构的迷宫机器人自主搜索的认知学习方法,提高了迷宫机器人的学习速度与稳定性。模型结构如图1所示,包括感受器、内部状态、环境状态系统、情感系统、行为选择系统、动态知识库以及执行器七部分,各部分含义具体如下:
6.(1)感受器:感受事物表示为三元组:《s,a,ga》,其中,s={si|i=1,2,
…
,ns}为离散状态集合,si∈s为可感受第i个状态,s(t)∈s为第t时刻机器人所处状态,ns为可感知到的离散状态的个数;针对需要“能量补给”的迷宫搜索任务,离散状态为迷宫节点;a={ai|i=1,2,
…
,ns}为离散状态对应的可选动作集合,ai∈a为第i状态下可选动作子集;ga={gai|i=1,2,
…
,ns}为最大环境补给集合,gai∈ga为第i个离散状态给予机器人的最大内部能量补给,ga(t)∈ga为第t时刻机器人所处状态对应的大环境补给,最大环境补给设置为 19,-2,0三种情况。
7.(2)内部状态:机器人内部能量状态表示为h(t),h={h(t)|t=0,1,
…
,n
t
}为机器人内部能量状态集合,h(t)∈h为第t个时刻内部能量状态,n
t
为存活时间数,t=0代表机器人开始任务时刻,t=n
t
代表机器人内部能量状态为0或完成迷宫搜索时刻,n
t
一般大于50s。
8.(3)环境状态系统:机器人内部状态与感受信息中枢,接收与处理的信息表示为五元组;《s,a,ga,h,g》,g={g(t)|t=0,1,
…
,n
t
}为机器人从环境获得的内部能量收益集合,g(t)∈h为第t个时刻机器人获得的内部能量收益,g(t)定义如下:
[0009][0010]
(4)情感系统:机器人的情感中心,包括情感生成系统,情感记忆,情感状态三部分,情感元素表示为三元组:《e,r
emo
,r
mem
》,情感生成系统为机器人建立人工情感状态e(t),e={e(t)|t=0,1,
…
,n
t
}为情感状态集合,e(t)∈e为第t时刻情感状态,e(t)∈e为机器人完成第t次周期时刻情感状态;情感记忆根据生成的情感状态获得情感即时奖励和情感记忆奖励:r
emo
={r
emo
(t)|t=0,1,
…
,n
t
}为情感即时奖励集合,r
emo
(t)∈r
emo
为第t时刻情感即时奖励;r
mem
={r
mem
(t)|t=1,2,
…
,n
t
}为情感记忆奖励集合,r
mem
(t)∈r
mem
为第t搜索周期情感记忆奖励,t=1代表机器人第一次搜索完回到能量补给点,t=n
t
代表机器人完成搜索任务最大所需周期。
[0011]
(5)行为选择系统:根据环境状态与情感状态,并结合动态知识库选择行为与相应动作,表示为二元组:<π,a》,π={πz|z=1,2,
…
,nz}为机器人行为选择集合,πz∈π为机器人第z种行为,π(t)∈π第t时刻机器人的行为选择,nz为机器人行为种类数,针对需要“能量补给”的迷宫搜索任务,机器人行为分为搜索,能量补给两种;a={am|m=1,2,
…
,nm}为机器人动作集合,am∈a为机器人第m种动作,a(t)∈a第t时刻机器人的动作选择,nm为机器人动作种类数,针对迷宫搜索任务,机器人动作为节点处东、南、西、北方向选择。
[0012]
(6)动态知识库:包括机器人从环境学到的知识,以及认知模型学习算法,表示为六元组:《sta_pwo,sta_act,a
′
,d,l,u》,其中,sta_pwo={(yz,bz)|z=1,2,
…
,nz}为状态-能量记忆集合,(y,b)记录周期内离散状态以及所对应返回能量补给点所需内部能量状态b,b(t)∈b第t时刻机器人所处状态返回能量补给点所需内部能量状态,nz为周期内所遇离散状态个数;sta_act=《(y,r),(y
′
,r
′
)》={(yk,rk),(y
′c,r
′c)|k=1,2,
…
,nk,c=1,2,
…
,nc}为状态-动作记忆集合,(y,r)为逐次记录周期内所遇状态与动作选择的序列,nk为周期内所遇状态的总个数,(y
′
,r
′
)为记录周期内最后一遍所遇状态与动作选择的序列,nc为周期内所遇不同状态的个数;a'={a'i|i=1,2,
…
,ns}为离散状态下能量补给行为对应的最佳动作集合,a'i∈a'为第i状态下能量补给行为的动作选择,a(t)
′
∈a
′
为第t时刻机器人所处状态最大价值动作;d={d(t)|t=0,1,
…
,n
t
}为环境搜索状态集合,d(t)∈d为第t时
刻已搜索迷宫节点与总节点比值;l={l(t)|t=1,2,
…
,n
t
}为路径搜索状态集合,l(t)∈l为第t周期迷宫路径搜索状态,为已搜索路径与未搜索路径区分标记;u为认知模型学习算法,需要“能量补给”的迷宫搜索任务分为两阶段,第一阶段为寻找内部能量补给点,第二阶段为利用所找到内部能量补给点信息获取后的搜索,具体步骤如下。
[0013]
step1:开始任务第一阶段:数据初始化:初始化《sta_pwo,sta_act,a
′
,d,l,h》。
[0014]
step2:根据状态选择动作,将“状态-动作”写入sta_act;更新至下一状态;获得环境奖励r
env
(t),并更新q值。
[0015]
step3.1:判断是否找到能量补给点,若找到则执行step4,否则转step3.2;
[0016]
step3.2:判断是否满足h(t)》0,若满足则转step2,否则结束。
[0017]
step4:开始第二阶段任务:更新情感状态e(t);获得情感记忆奖励r
mem
(t),并更新q值;由记忆模块2获得l(t)。
[0018]
step5:判断是否满足d(t)=1(判断迷宫是否搜索完),若满足则结束,否则执行step6。
[0019]
step6:将sta_pwo与sta_act重置清空。
[0020]
step7:更新情感状态e(t),由记忆模块1更新b(t);判断状态是否在sta_pwo,若在则转step9。
[0021]
step8:获得情感即时奖励r
em
o(t),并更新q值。
[0022]
step9:根据状态选择动作,将“状态-动作”写入sta_act;更新至下一状态;获得环境奖励r
env
(t),并更新q值。
[0023]
step10:判断是否满足继续搜索条件,若满足则转step7,否则执行step11。step11:根据状态选择最大价值动作a(t)
′
,将“状态-动作”写入sta_act;更新至下一状态;获得环境奖励r
env
(t),并更新q值;
[0024]
step12:判断是否回到能量补给点,若是则转step4,否则执行step11。
[0025]
(7)执行器:机器人执行机构,本文选取两轮迷宫机器人,动作执行机构表示为二元组:《v1,v2》,其中,v1={v1m|m=1,2,
…
,nm}为左轮转矩集合,v2={v2m|m=1,2,
…
,nm}为右轮转矩集合。
[0026]
一、本发明所述情感生成系统函数表达式为如下:
[0027]
其中,k1,k2,k3,k4,k5,k6为认知模型参数,当(3)式值为正时为积极的高兴情感,为负值时则为恐惧情感,(4)式产生愤怒情感,|e(t)|越大则情感越强烈。
[0028][0029]
二、本发明所述所述分别由环境奖励r
env
(t)、情感即时奖励r
emo
(t)以及情感记忆奖励r
mem
(t)组成,机器人从节点1(能量补给点)搜索至节点6再返回节点1的一次搜索周期的奖励过程示意如图3所示,奖励设置如下(5)-(12)式:
[0030]
[0031][0032][0033]
其中,环境即时奖励r
env
(t)的q值更新公式如下。q即为q(s(t),a(t)),就是在某一个时刻t的状态下,采取动作a(t)能够获得收益的期望,环境状态会根据机器人的动作反馈相应的奖励,主要思想就是将状态和动作构建成一张q表来存储q值,然后根据q值来选取能够获得最大价值的动作。其中,s(t)为当前状态,a(t)为当前状态选择的动作,α为学习率,maxq(s(t),a(t))为当前状态选择动作后下一状态最大收益;
[0034]
q(s(t),a(t))=(1-α)q(s(t),a(t)) α[r
env
(t) maxq(s(t 1),a(t 1))]
ꢀꢀ
(13)
[0035]
情感即时奖励r
emo
(t)的q值更新公式如下,对搜索路径逆方向进行强化,a(t)
′
为t时刻进入该状态时的逆方向动作。
[0036]
q(s(t),a(t)
′
)=r
emo
(t)
ꢀꢀ
(14)
[0037]
情感记忆奖励r
mem
(t)的q值更新公式如下,用于再次返回补给点后获得的情感强化上一遍搜索返回补给点所经过的路径中选择动作。
[0038]
q(s(t),a(t))=(1-α)q(s(t),a(t)) α[r
mem
(t) maxq(s(t 1),a(t 1))]
ꢀꢀ
(15)
[0039]
三、本发明所述实现机器人思考与回忆机制的相关记忆模块1步骤如下;
[0040]
stepa1:判断当前状态是否在sta_pwo中,若不在则转stepa3。
[0041]
stepa2:调取sta_pwo中当前状态对应的bz,令b(t)=bz。
[0042]
stepa3:令b(t)=b(t-1) 1,令b(t)=bz,将“状态-能量”写入sta_pwo。
[0043]
四、本发明所述实现机器人思考与回忆机制的相关记忆模块2步骤如下;
[0044]
stepb1:判断(y,r)的第k状态是否在前k-1个状态中,若在则转stepb3。
[0045]
stepb2:判断第k个状态的动作子集ai是否搜索完,若否则将(y,r)中第k-1个状态对应的动作选择标记重置。
[0046]
stepb3:判断是否满足k》0,若满足则令k=k-1,并转stepb1,否则结束。
[0047]
五、本发明所述机器人行为决策规则,即继续搜索条件,从认知模型从生物角度出发,设计了所处状态下行为决策由愤怒情感趋向于搜索,恐惧情感趋向于避险的机制如下;
[0048][0049]
与现有技术相比,本发明具有以下优点;首先,利用了现有心理学与生理学基础,在机器人进行自主学习过程加入情感因素与情感决策,提高机器人丰富性,实现机器人模拟生物学习与认知环境的知识积累过程。其次,通过加入情感与记忆机制,实现机器人对环境信息有效利用,提高了机器人学习效率;
附图说明
[0050]
图1为本发明情感-记忆认知模型;
[0051]
图2为本发明所涉及的学习算法图;
[0052]
图3为本发明所涉及的学习算法奖励机制图;
[0053]
图4为迷宫环境图;
[0054]
图5为移动机器人自主搜索迷宫轨迹图;
[0055]
图6为搜索过程能量值变化图;
[0056]
图7为搜索过程情感变化曲线图;
[0057]
图8为搜索过程搜索范围变化图;
具体实施方式
[0058]
下面结合附图和具体实施方式对本发明作进一步说明。
[0059]
在机器人仿真软件v-rep中搭建迷宫环境如图4所示,迷宫共设有21个节点对应21种离散状态,节点处可能存在东、南、西、北四个方向的选择动作,迷宫中两处节点存在着能量补给点与陷阱点,节点13为能量补给点,节点5为陷阱点,移动机器人能量值代表内部能量状态值,在每次选择动作时会损失1点能量值,若走到能量源处则可加满至19点能量值,遇到陷阱则额外损失2点能量。移动机器人起初被给予9点能量值,只掌握避障技能的情况下找到能量源在迷宫中的位置此时算完成第一阶段任务,然后获得能量补给点信息后的移动机器人需要利用能量补给点继续搜索迷宫,直至迷宫环境节点被完全搜索完成第二阶段任务。
[0060]
在迷宫环境数学模型已知的情况下,需要对本发明情感-记忆认知模型进行设置,具体如下:
[0061]
(1)针对迷宫环境,将迷宫中每个节点设置为机器人感知的状态,所以模型共有ns=21,以可选方向为该节点的动作子集,迷宫存在着以绝对坐标的东、南、西、北4种动作选择,最大可选动作子集为环境收益存在着陷阱点、能量补给点与普通节点分别为-2、19和0,环境收益即能量获得集合ga
i∈
{19,-2,0},机器人在迷宫环境中行为选择集合πz∈{搜索,补充能量}:
[0062]
(2)迷宫环境中,本发明所述所述情感生成系统函数如下:
[0063][0064]
实验1:移动机器人寻找能量补给点过程
[0065]
如图5为一次完整迷宫搜索过程图,(a)-(b)为移动机器人寻找能量补给点的任务第一阶段过程,将能机器人起始位置置于节点3与节点4间。起初,移动机器人在迷宫环境未知的情况下获得9点能量值(如图6所示),在每个状态下,对该状态的可选动作都会随机选择,随着学习的进行,对于再次遇到的状态,机器人则会选择之前未选择过的动作,通过之前的记忆让移动机器人尽快的找到能量源。
[0066]
实验2:移动机器人搜索迷宫并返回补充能量的自主探索过程
[0067]
如图5(c)-(f)为移动机器人利用能量补给点信息的任务第二阶段过程,由图6可
以看出移动机器人在能量补给点获得能量补充,此时图7机器人情感由于找到能量补给点而变为高兴,补充能量后机器人再出去对迷宫进行搜索,高兴的情感强度也随着离能量补给点“距离”与自身的能量值下降而衰减;t=14时,移动机器人遇到陷阱点,能量值被额外扣除2点,机器人情感变为生气,机器人更倾向于搜索行为的选择,即当返回能量值刚好等于自身能量值时才会选择补充能量行为,随后移动机器人补充能量再进行迷宫探索;直到t=36时,机器人情感变为恐惧且自身能量值为快接近返回所需能量值时,机器人行为转变为补充能量开始返回能量补给点的路径,并且由图5的轨迹可以看出,探索过程中的记忆机制让移动机器人有效减少已探索路径的探索。图8可见迷宫内的探索范围随时间稳定上升,其中探索范围存在不上升状态部分是由于移动机器人走入死路节点或者返回能量补给点时经过同一路径。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。