1.本发明涉及第三方组件测试技术领域,尤其涉及一种基于问答模型的第三方组件文档细粒度自动化提取方法及系统。
背景技术:
2.随着开源社区的不断推进,各类第三方组件迎来蓬勃发展,目前已经广泛应用到各行各业软件的开发当中。然而,最近的研究和实际事件表明在使用第三方组件给软件开发人员带来便利的同时,第三方组件在使用过程中产生的安全问题令人担忧。由于缺乏有效的方法来对开发人员在使用第三方组件的过程中进行严格规范,基于各类第三方组件开发的软件可能存在严重的安全威胁。例如,部分第三方组件的函数要求在被调用后需要释放,开发人员可能忽略或遗漏类似使用规则,从而造成严重的安全威胁。此类威胁轻则影响用户隐私,重则影响国家关键设备的安全。
3.为了检测开发人员在使用第三方组件中是否严格按照使用规则来调用第三方组件,研究人员提出了各种检测系统用于挖掘此类第三方组件误用情况。这些检测系统有一个共同点,即都需要准确获取第三方组件的使用规则。目前研究人员主要通过人工获取、正则表达式匹配以及语法依赖树等方法从第三方组件文档中获取相应使用规则。然而,通过人工阅读第三方组件来获取使用规则的方式费时费力。一个第三方组件往往含有上百个函数,每一个函数有多条使用规则,因此一个第三方组件可包含多达上千条使用规则。其次通过正则表达式匹配方法获得的使用规则往往会产生大量的漏报,无法全面获取第三方组件的使用规则,从而影响后续对第三方组件误用情况检测的准确率。另外,通过语法依赖树方法来挖掘规则需要经过大量文档预处理工作,对于结构松散的第三方组件文档效果欠佳,很难应用于大规模检测。
4.设计一个有效的第三方组件文档细粒度自动化提取方法存在以下挑战:(1)适配不同格式的第三方组件文档。目前,第三方组件文档的撰写没有统一的格式,任意两个第三方组件文档之间都可能存在显著的差异。仅用正则表达式匹配的方法无法适用到不同类别的第三方组件文档。(2)全面获取第三方组件使用规则。由于第三方组件文档中含有大量干扰语句,例如对函数的功能描述,大大影响了全面获取第三方组件使用规则的难度,从而造成大量的误报错报。其次,部分第三方组件的使用规则描述含糊不清,即使通过人工判断有时也无法判定是否为真实的使用规则。
5.由于第三方组件的文档没有统一格式,其使用规则也千差万别,目前还没有自动化细粒度获取第三方组件使用规则的有效方法,设计一种能够从第三方组件文档中细粒度自动化提取相应使用规则对于后续检测因第三方组件误用情况造成的漏洞是重要和必要的。
技术实现要素:
6.针对第三方组件使用规则细粒度自动化提取工作存在的不足,本发明提供了一种基于问答模型的第三方组件文档细粒度自动化提取方法及系统,该方法能够对第三方组件中每个函数的使用规则进行精确提取。
7.本发明的具体技术方案如下:
8.本发明的第一个目的在于提供一种基于问答模型的第三方组件文档细粒度自动化提取方法,包括如下步骤:
9.步骤1:收集多个不同第三方组件的文档,对文档进行预处理,构建文档仓库;使用注意力模型对文档仓库中的待测试文档进行语句精炼,获取第三方组件的粗粒度使用规则;
10.步骤2:根据第三方组件的误用种类,设计问答模型的相应问题;从文档仓库中的待测试文档中挑选部分文档,根据设计的问题标记出答案;
11.步骤3:将标记好的待测试文档分为训练集和验证集,利用训练集对自然语言处理模型进行训练,直至验证集的测试准确率满足预设要求;利用训练好的自然语言处理模型对文档仓库中的剩余未标记答案文档的粗粒度使用规则进行细粒度挖掘。
12.本发明的第二个目的在于提供一种基于问答模型的第三方组件文档细粒度自动化提取系统,用于实现上述的方法,所述的提取系统包括:
13.第三方组件文档预处理模块,其用于收集多个不同第三方组件的文档,对文档进行预处理,构建文档仓库;使用注意力模型对文档仓库中的待测试文档进行语句精炼,获取第三方组件的粗粒度使用规则;
14.文档问答树构建模块,其用于根据第三方组件的误用种类,设计问答模型的相应问题;从文档仓库中的待测试文档中挑选部分文档,根据设计的问题标记出答案;
15.基于问答的第三方组件使用规则提取模块,其用于将标记好的待测试文档分为训练集和验证集,利用训练集对自然语言处理模型进行训练,直至验证集的测试准确率满足预设要求;利用训练好的自然语言处理模型对文档仓库中的剩余未标记答案文档的粗粒度使用规则进行细粒度挖掘。
16.与现有技术相比,本发明的有益效果为:
17.(1)本发明给出了一种第三方组件文档细粒度自动化提取系统,提出了基于问答模型的第三方组件文档细粒度自动化提取方法,解决了第三方组件使用规则细粒度自动化提取的问题,能够有效提取不同类型第三方组件的使用规则,具有实用性;
18.(2)本发明给出了基于注意力模型的文档预处理方法,解决了无统一格式的第三方组件文档粗粒度提炼问题;本发明给出了基于问答模型的文档内容提取方法,为构建文档问答树以及细粒度提取无统一格式的第三方组件使用规则提供了依据。
附图说明
19.图1为基于问答模型的第三方组件文档细粒度自动化提取系统的整体模块结构示意图;
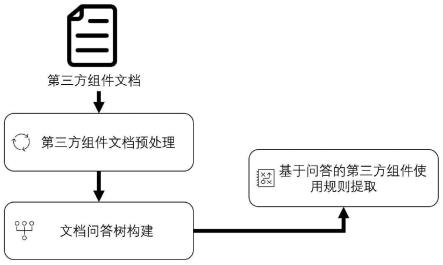
20.图2为基于问答模型的第三方组件文档细粒度自动化提取方法的流程示意图;
21.图3为第三方组件文档预处理方法示意图;
22.图4为第三方组件文档问答树构建方法示意图;
23.图5为基于问答的第三方组件使用规则提取方法示意图。
具体实施方式
24.下面结合附图和实施例对本发明作进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
25.如图1所示,本发明基于问答模型的第三方组件文档细粒度自动化提取系统,包括第三方组件文档预处理模块、文档问答树构建模块以及基于问答的第三方组件使用规则提取模块。
26.整个第三方组件文档细粒度自动化提取系统的工作流程如图2所示,包括以下步骤:
27.(1)收集多个不同第三方组件的文档,例如openssl、sqlite以及uclibc等文档,对文档进行预处理,形成大规模的文档仓库。使用注意力模型对文档仓库中的待测试文档进行语句精炼,获取第三方组件粗粒度使用规则;
28.(2)针对第三方组件误用种类,设计相应问题用于之后的问答模型;从文档仓库中的待测试文档中挑选至少5份文档,根据设计的问题,对文档进行人工答案标记;
29.(3)将标记好的待测试文档分为训练集和验证集,将训练集输入自然语言处理模型训练,并在验证集上测试准确率。将训练好的模型用于文档仓库中未标记的待测试文档,对每一个涉及的第三方组件的使用规则进行细粒度挖掘。
30.本发明中,步骤(1)的核心是获取第三方组件使用规则的特征,利用注意力模型粗略过滤掉与使用规则无关的内容。基于经验的,即使是不同撰写风格的文档,其中有关使用规则的内容都包含有强调的语气,会使用can(could),may(might),must,need,ought to,dare(dared),shall(should),will(would)等情态语气词。因此,为了粗略过滤第三方组件文档中的无关内容,本发明提出了基于注意力的自然语言处理模型的过滤方法,主要包括:
31.(1-1)根据linux帮助文档,收集其中所记录的第三方组件的相关文档。对文档叙述不清,或者文档缺失严重的第三方组件进行过滤;
32.(1-2)根据第三方组件使用规则的上述特征,使用注意力模型对第三方组件文档内容进行粗粒度过滤,保留文档中具有强调语气的语句,得到粗粒度过滤后的使用规则。
33.本发明中,步骤(2)的核心是深度人工分析第三方组件误用种类,根据误用类别设计对应问题,从而构建问答树,主要包括:
34.(2-1)基于公开的第三方组件误用数据集,深度人工分析第三方组件误用种类,得到的误用种类包括:过时函数误用、返回值误用、调用顺序误用、参数误用四大类;
35.(2-2)为每一种误用种类设计对应的查询问题,用于问答模型构建,查询问题包括:函数是否过时、函数是否有返回值、函数哪些情况有返回值、函数的返回值在上述情况下分别是什么、是否有其他函数需要提前调用、是否有其他函数需要被之后调用、参数类型是什么七大类;
36.(2-3)根据设计的问题,挑选文档仓库中的待测试文档进行人工标记,为每个第三方组件文档构建问答树结构。
37.本发明中,步骤(3)的核心是利用问答模型对使用规则进行细粒度提取。基于经验
的,利用正则表达式等方法无法处理结构松散,撰写风格迥异的大量第三方组件文档。因此,为了自动化处理大量风格各异的第三方组件文档,本发明提出了基于问答模型的第三方组件文档细粒度提取方法,主要包括:
38.(3-1)将步骤(2-3)标记完成的待测试文档按照8:2的比例分为训练集和验证集,利用基于roberta开发的自然语言处理模型在训练集上进行迭代训练,并在验证集上进行验证,直到损失函数收敛;
39.(3-2)使用训练完成的模型对文档仓库中剩余的待测试第三方组件文档进行细粒度抽取。模型将每个问题的最高置信概率答案作为正确回答,同时为每一个待测试文档生成问答树。根据问答模型的处理结果,提取出每一个第三方组件生成细粒度使用规则。
40.以下对各个模块分别进行说明:
41.1.第三方组件文档预处理模块,其采用注意力模型对第三方组件使用规则进行粗粒度过滤,如图3所示,过程如下:
42.首先根据linux帮助文档,收集其中所记录的第三方组件的相关文档。对文档叙述不清,或者文档缺失严重的第三方组件进行过滤;
43.接着根据第三方组件使用规则特征,使用注意力模型对第三方组件文档内容进行粗粒度过滤,保留文档中具有强调语气的语句,得到粗粒度过滤后的使用规则。
44.2.文档问答树构建模块,其用于获取第三方组件的误用类型,并为每一类型设计查询问题,对待测试文档进行人工标记相关问题答案,从而构建文档问答树。如图4所示,过程如下:
45.首先基于公开的第三方组件误用数据集,深度人工分析第三方组件误用种类,得到的误用种类包括:过时函数误用、返回值误用、调用顺序误用、参数误用四大类;
46.接着为每一种误用种类设计对应的查询问题,用于问答模型构建,查询问题包括:函数是否过时、函数是否有返回值、函数哪些情况有返回值、函数的返回值在上述情况下分别是什么、是否有其他函数需要提前调用、是否有其他函数需要被之后调用、参数类型是什么;
47.最后根据设计的问题,挑选文档仓库中的待测试文档进行人工标记,为每个第三方组件文档构建问答树结构。
48.3.基于问答的第三方组件使用规则提取模块,其基于第三方组件误用类型所设计的相应问题,结合基于roberta模型的自然语言处理模型,获得与第三方组件相关的细粒度使用规则。如图5所示,过程如下:
49.首先将文档问答树构建模块标记完成的待测试文档按照8:2的比例分为训练集和验证集,利用roberta模型在训练集上进行迭代训练,并在验证集上进行验证,直到损失函数收敛;
50.接着使用训练完成的模型对文档仓库中剩余的待测试第三方组件文档进行细粒度抽取。模型将每个问题的最高置信概率答案作为正确回答,同时为每一个待测试文档生成问答树。根据问答模型的处理结果,生成每一个第三方组件的细粒度使用规则。
51.以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
