eeg[j].biomedical signal processing and control,2018,42:107-114》中采用多层cnn的结构,同时为了更好地建模分期规则,将四个相邻的epoch数据串联在一起作为一个样本输入,但这也意味着模型的输入存在冗余,模型输入的维度就会增大,模型的训练时间也会增加。chen等人在文献《chen k,zhang c,ma j,et al.sleep staging from single-channel eeg with multi-scale feature and contextual information[j].sleep and breathing,2019,23(4):1159-1167》中提出一个基于多尺度cnn rnn(循环神经网络)的方法,使用多尺度cnn代替单尺度卷积层,能够提取特定eeg特征,再用rnn将提取的相邻epoch特征中的时间信息编码,最后用crf(条件随机场)捕捉阶段转换规则,并在健康人和阻塞性睡眠呼吸暂停症患者的数据集上取得较好结果,但它的问题是将n1期和n2期合并为单个阶段,无法区分。sun等人在文献《sun c,chen c,li w,et al.a hierarchical neural network for sleep stage classification based on comprehensive feature learning and multi-flow sequence learning[j].ieee journal of biomedical and health informatics,2019,24(5):1351-1366》中从eeg、eog和emg中提取手工特征,并且利用三尺度cnn网络提取抽象特征,再将手工特征和抽象融合后输入lstm结构中,根据睡眠数据序列包含的信息,建立一个“序列到序列”的映射关系,但此种方法的问题是过程过于繁琐,提取手工特征也就意味着需要睡眠领域先验知识,同时模型对输入数据是有要求的,需要同时输入eeg、eog和emg的数据到网络中,这对数据集的要求较高。dong等人在文献《dong,hao,et al."mixed neural network approach for temporal sleep stage classification."ieee transactions on neural systems and rehabilitation engineering 26.2(2017):324-333》中提出了使用三层mlp加lstm的模型,先对单通道eeg数据做短时傅里叶变换(stft),然后计算出功率谱密度等特征,再将特征工程得到的时域、频域特征输入到模型中,模型的结构非常简单,但存在的问题是需要先做特征工程的工作,这也就意味着需要睡眠领域先验知识。supratak等人在文献《supratak,akara,et al."deepsleepnet:a model for usingbased on raw single-channel eeg."ieee transactions on neural systems and rehabilitation engineering 25.11(2017):1998-2008.mbvcxzzxcvbnm》中针对单通道脑电数据提出一种cnn 双向lstm(bi-lstm)的模型。它包含两个部分:一个提取时不变特征的表征学习模块和一个序列残差学习模块。
[0006]
以上都是基于监督学习的方法,即方法中的模型训练完全依赖于标记的数据。虽然模型的分期结果是行的,但通常需要大量带标签训练数据以保证模型的效果。但实际情况是,在睡眠数据资源中,标签数据只占少部分,大部分睡眠数据是没有标签的,因此如何利用无标签睡眠数据来训练睡眠分期模型是目前研究的一大难题。为了能够充分利用无标签睡眠数据,引入半监督的解决方法来识别睡眠阶段是可行的。半监督模型可以同时利用有标签和无标签睡眠数据构建模型,模型最终达到的分类性能与监督模型相似甚至更好。但目前存在的基于半监督的睡眠分期模型存在着一个问题,即模型结构过于复杂或者可移植性差。
技术实现要素:
[0007]
本发明的目的在于克服现有技术的不足,提供一种采用伪标签训练方法对shnn模型进行训练,在不改变模型结构的情况下,增强了模型的睡眠分期性能的基于半监督学习
的单通道脑电睡眠分期方法。
[0008]
本发明的目的是通过以下技术方案来实现的:基于半监督学习的单通道脑电睡眠分期方法,包括以下步骤:
[0009]
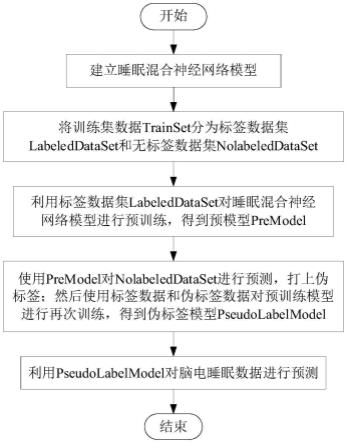
s1、建立睡眠混合神经网络模型;
[0010]
s2、将训练集数据trainset分为标签数据集labeleddataset和无标签数据集nolabeleddataset,并将训练数据集trainset中的脑电数据按照每30秒为一个数据片段进行数据划分,标签数据集labeleddataset中每个数据片段的标签为w、n1、n2、n3或rem中的一种;
[0011]
s3、利用标签数据集labeleddataset对睡眠混合神经网络模型进行预训练,得到预模型premodel;
[0012]
s4、使用premodel对无标签数据集nolabeleddataset进行预测,并打上伪标签;然后使用标签数据和伪标签数据对预训练模型进行再次训练,得到伪标签模型pseudolabelmodel;
[0013]
s5、利用pseudolabelmodel对脑电数据进行预测,得到分期结果。
[0014]
进一步地,所述睡眠混合神经网络模型包括特征提取模块、时间上下文信息提取模块和分类模块;
[0015]
特征提取模块利用两个拥有不同卷积核大小的cnn分支分别从30秒脑电数据中提取特征,然后将提取到的特征向量进行融合,并输入到时间上下文信息提取模块中;时间上下文信息提取模块使用bi-gru结构来获取睡眠数据序列的时间上下文信息,然后输入到分类模块中;最后,使用分类模块的全连接层和的softmax函数来进行睡眠阶段的预测。
[0016]
进一步地,所述特征提取模块的两个cnn分支都包含三个卷积层、两个池化层;其中,第一个池化层在第一个卷积层之后,第二个池化层在第三个卷积层之后;其中每个卷积层都包含一个批处理归一化层,并使用整流线性单位函数作为激活函数,然后将两个特征张量通过reshape函数调整后连接起来;在两个cnn分支的第一个池化层之后和两个cnn分支进行特征连接之后均连接dropout层;
[0017]
提取特征的过程为:假设有n个30秒的脑电epoch数据,记为{x1,x2,x3......xn},使用两个cnn分支从脑电epoch数据x
t
中提取特征,如下式所示:
[0018]
x
1t
=cnn1(x
t
)
[0019]
x
2t
=cnn2(x
t
)
[0020]
feature
t
=x
1t
||x
2t
[0021]
其中,cnn1(x
t
)、cnn2(x
t
)分别为cnn分支1和cnn分支2中,将30秒脑电epoch数据x
t
转化为特征向量x
1t
和x
2t
的卷积操作,t=1,...,n;符号||表示连接操作;
[0022]
将经过连接操作的n个特征向量{feature1,feature2,feature3,...,featuren}输入到时间上下文信息提取模块中。
[0023]
进一步地,所述时间上下文信息提取模块的利用bi-gru提取时间上下文信息的过程为:将n个特征向量{feature1,feature2,feature3,...,featuren}顺序排列,然后使用双向gru中的正向gru和反向gru从特征向量序列中提取睡眠数据序列的时间相关性,如下式所示:
[0024]
[0025][0026][0027]
其中和代表着正向和反向gru,代表正向gru的前一个隐藏单元状态和当前隐藏单元状态,代表反向gru的后一个隐藏单元状态和当前隐藏单元状态;正向gru最开始的隐藏单元状态和反向gru最开始的隐藏单元状态被设置为零向量;所有单元的输出{out1,out2,out3,...,outn}输入到分类模块中。
[0028]
进一步地,所述分类模块由两个全连接层和一个梯度对数归一化层组成;使用全连接层对{out1,out2,out3,...,outn}的特征进行加权求和得到每个类别的分数;再经过梯度对数归一化层映射为概率,如下式所示:
[0029]yt
=softmax(w2(w1*out
t
b1) b2)
[0030]
其中w1、w2是权重参数,b1、b2是偏置项,y
t
是分类结果,softmax表示梯度对数归一化层。
[0031]
进一步地,所述步骤s3具体实现方法为:将标签数据集labeleddataset输入到睡眠混合神经网络模型中计算出预测值,并计算损失值,根据损失值,反向传播并更新模型的参数,得到预训练后的模型premodel。
[0032]
进一步地,所述步骤s4具体实现方法为:用premodel对无标签数据集nolabeleddataset中的数据进行预测,得到伪标签数据集pseudolabelset;然后将标签数据集labeldataset和伪标签数据集pseudolabelset数据集输入到premodel中计算出预测值,并计算损失值,更新模型,得到伪标签模型pseudolabelmodel。
[0033]
进一步地,所述步骤s3和s4中,采用交叉熵作为损失函数,损失函数如下所示:
[0034][0035]
其中t指标签数据的第t个样本,t
′
指无标签数据的第t
′
个样本;n,n
′
是标签数据和伪标签数据的样本数;指标签数据样本的真实类别是否是i,1代表是,0代表不是;指伪标签数据样本的真实类别是否是i,1代表是,0代表不是;指标签数据样本的每个类别预测概率,伪标签数据样本的每个类别预测概率;α是平衡差异的权重因子,wi是每个类别的权重因子;l是交叉熵损失函数,c是类别总数;
[0036]
权重因子α的范围由以下分段动态方程确定:
[0037][0038]
其中z是训练迭代次数,α
′
=0.1,t1=60,t2=100;模型开始训练时,α初始化为0,得到预训练模型,当迭代次数超过t1时,α加入到总损失函数中进行训练,并随着训练迭代次数的增加而增大,直到模型达到指定的训练次数时,训练结束。
[0039]
本发明的有益效果是:本发明提出了一种基于伪标签的端到端的自动睡眠分期模
型,模型基于原始单通道eeg进行睡眠阶段的自动分期,同时不需要利用领域先验知识进行人工设计特征。该模型利用cnn提取脑电信号的不变特征,在利用bi-gru从脑电信号序列数据中提取时间上下文信息,最后模型根据cnn和bi-gru提取到的信息进行睡眠脑电分期。在此基础上,采用伪标签训练方法对shnn模型进行训练,在不改变模型结构的情况下,增强了模型的睡眠分期性能。由于本发明的模型的分类性能可以与目前的单通道脑电自动分期方法达到相同的程度,同时利用伪标签方法,可以将那些无标签的数据利用起来,进一步增强模型的分类性能。将本发明的模型和伪标签训练方法迁移到具有睡眠疾病的数据集上,不仅能够用于正常人的睡眠分期,同时也能够用于对睡眠障碍的数据集进行睡眠分期。
附图说明
[0040]
图1为本发明的单通道脑电睡眠分期方法的流程图;
[0041]
图2为本发明的睡眠混合神经网络模型的结构示意图;
[0042]
图3为本发明的特征提取模块结构示意图;
[0043]
图4为本法明的时间上下文信息提取模块结构示意图;
[0044]
图5为本发明的脑电数据处理流程图。
具体实施方式
[0045]
基于深度学习的自动睡眠分期方法一般是借助深度神经网络自动提取睡眠信号特征,再结合分类器进行自动睡眠分期。深度神经网络能从不同角度学习输入数据并进行深层次抽象。睡眠分期深度神经网络对睡眠信号进行整合抽象进而得到高维睡眠特征向量的过程,就是睡眠分期自动特征提取过程。这种方式的显著优点是可以最大程度地在无人工干扰下通过睡眠数据集找到睡眠分期模型所需的最佳特征空间。特征对于睡眠分期是至关重要的,一般来说发现新的且有效的特征需要丰富的领域先验知识,而人类专家根据领域先验知识设计特征这一过程是非常复杂且困难的,因此需要设计足够简单而且能有效提取有用特征的方法。深度学习中的cnn刚好能够胜任特征提取的工作,cnn结构擅长捕捉信息的局部相关性和空间不变性。此外cnn网络中的权值是共享的,这也就意味着,只要合理设计cnn的结构,那么模型的参数量和复杂度能够大大降低。由于cnn提取特征的特性,目前已经有各种基于cnn的睡眠分期模型被提出。睡眠时期遵循特定的转换模式,大多数睡眠分期方法试图使用时间状态模型来捕捉睡眠时期转换的时间依赖性。比如:rnn、lstm或gru,这些模型都能够有效捕捉输入序列之间的关系特征。gru是rnn的一个变种模型,能够很有效捕获输入序列的依赖关系,同时类似于lstm,具有控制单元内部信息流的门控单元,能够有选择的将重要信息传递给下一个单元,而不会传递所有信息,然后相比于lstm结构,gru的参数更少,模型收敛速度更快。最后,针对gru模型只能从前一个单元获取信息,无法从后面的单元获取信息的问题,bi-gru做了进一步的改进,bi-gru是一种双向的gru结构,这意味着当前单元能够同时从前后单元获取信息。bi-gru结构能很好地完成提取睡眠脑电序列数据中的时间上下文信息的任务。在本文所提出的shnn模型中就包含cnn和bi-gru部分,cnn用来提取原始脑电信号中的特征,bi-gru提取睡眠脑电序列数据中的时间上下文信息。
[0046]
半监督学习(ssl)是一种学习范式,用于构造同时使用标签数据和无标签数据的模型。与只能使用标签数据的监督学习算法相比,半监督学习方法可以通过使用额外的无
标签数据来提高学习性能。通过扩展有监督学习算法,可以很容易地获得半监督学习算法。半监督学习算法提供了一种从无标签数据中探索潜在模式的方法,减轻了对大量标签的需求。
[0047]
睡眠分期本身是一个分类问题,因此本研究的研究重点是基于半监督学习的睡眠分类方法。半监督分类的思想是,假设一个训练数据集包含有标签的实例和无标签的实例,半监督分类的目标是同时从有标签和无标签的数据中训练分类器,这样它的性能比只在有标签的数据上训练的有监督分类器更好。
[0048]
伪标签方法提出的是一种以半监督方式训练神经网络的方法,其中网络以一种监督的方式训练,选择具有高置信度的未标记样本作为训练目标(伪标签),训练过程同时使用有标签和无标签的数据。在损失函数的监督方式下,对标签数据进行模型训练。对于无标签的数据,使用训练好的模型对无标签的数据进行预测。将拥有模型的最大置信度的预测记为伪标签,它具有最大的预测概率。伪标签对应的方程如公式(1),然后给无标记数据打上伪标签,将伪标签数据和标签数据再次输入模型进行训练的过程。
[0049]
其中c是真实类别,i
′
是预测类别,y
′c是判断真实类别是否是c,1代表是,0代表不是,x是模型的输入,fi′
(x)表示半监督模型的输出—某预测类别的概率输出。
[0050]
下面结合附图进一步说明本发明的技术方案。
[0051]
如图1所示,本发明的一种基于半监督学习的单通道脑电睡眠分期方法,包括以下步骤:
[0052]
s1、建立睡眠混合神经网络模型;所述睡眠混合神经网络模型(shnn模型)包括特征提取模块(part
ꢀⅰ
)、时间上下文信息提取模块(part
ꢀⅱ
)和分类模块(part
ꢀⅲ
),如图2所示;
[0053]
特征提取模块利用两个拥有不同卷积核大小的cnn分支分别从30秒脑电数据中提取特征,其中,小卷积核可以更好地提取短时域信息,大卷积核能更好地捕捉长时域信息;然后将提取到的特征向量进行融合,并输入到时间上下文信息提取模块中;时间上下文信息提取模块使用bi-gru结构来获取睡眠数据序列的时间上下文信息,然后输入到分类模块中;最后,使用分类模块的全连接层(fc)和的softmax函数来进行睡眠阶段的预测。
[0054]
所述特征提取模块的双尺度cnn的主要思想是学习不同大小时域的特征,它有两个分支,每个分支可以看成一个滤波器组来提取eeg特征,两个滤波器组的目的是捕捉生理信号中的不同时间粒度的特征。细时间粒度滤波器分支具有小的卷积核和步长,粗时间粒度滤波器组分支具有大的卷积核和步长。两个cnn分支都包含三个卷积层(convid)、两个池化层(maxpool),如图3所示。其中,第一个池化层在第一个卷积层之后,第二个池化层在第三个卷积层之后。其中每个卷积层都包含一个批处理归一化层(bn),并使用整流线性单位函数(rectified linear unit,relu)作为激活函数,然后将两个特征张量通过reshape函数调整后连接(concat)起来;为了避免网络过拟合,在两个cnn分支的第一个池化层之后和两个cnn分支进行特征连接之后均连接dropout层;
[0055]
提取特征的过程为:假设有n个30秒的脑电epoch数据,记为{x1,x2,x3......xn},使用两个cnn分支从脑电epoch数据x
t
中提取特征,如下式所示:
[0056]
x
1t
=cnn1(x
t
)
ꢀꢀꢀ
(2)
[0057]
x
2t
=cnn2(x
t
)
ꢀꢀꢀꢀ
(3)
[0058]
feature
t
=x
1t
||x
2t
ꢀꢀꢀꢀ
(4)
[0059]
其中,cnn1(x
t
)、cnn2(x
t
)分别为cnn分支1和cnn分支2中,将30秒脑电epoch数据x
t
转化为特征向量x
1t
和x
2t
的卷积操作,t=1,...,n;符号||表示连接操作;
[0060]
将经过连接操作的n个特征向量{feature1,feature2,feature3,...,featuren}输入到时间上下文信息提取模块中。
[0061]
在对睡眠脑电序列数据进行睡眠分期时,当前30秒epoch的分期与其之前和之后的epoch关系密切。这是因为睡眠阶段之间存在着时间相关性,比如,rem期通常出现在n2期之后,较不常见的是出现在w期或n1阶段之后。在这种情况下,如果某一个epoch之前是n2期,那么根据睡眠阶段的时间相关性就可以把后面的阶段记为n2期或rem期,而不是w期或n1期。由此可见睡眠阶段的时间相关性对于睡眠分期是非常重要的,因为在睡眠分期中,w期,n1期和rem期更难识别,如果能够借助睡眠阶段之间的时间相关性,能提高w期、n1期和rem期的分类性能。
[0062]
如图4所示,时间上下文信息提取模块的利用bi-gru(双向循环门控单元)提取时间上下文信息的过程为:将n个特征向量{feature1,feature2,feature3,...,featuren}顺序排列,然后使用双向gru中的正向gru和反向gru从特征向量序列中提取睡眠数据序列的时间相关性,如下式所示:
[0063][0064][0065][0066]
其中和代表着正向和反向gru,代表正向gru的前一个隐藏单元状态和当前隐藏单元状态,代表反向gru的后一个隐藏单元状态和当前隐藏单元状态;正向gru最开始的隐藏单元状态和反向gru最开始的隐藏单元状态被设置为零向量;所有单元的输出{out1,out2,out3,...,outn}输入到分类模块中。
[0067]
分类模块由两个全连接层和一个梯度对数归一化层组成;使用全连接层对{out1,out2,out3,...,outn}的特征进行加权求和得到每个类别的分数;再经过梯度对数归一化层映射为概率,如下式所示:
[0068]yt
=softmax(w2(w1*out
t
b1) b2)
ꢀꢀꢀꢀ
(8)
[0069]
其中w1、w2是权重参数,b1、b2是偏置项,y
t
是分类结果,softmax表示梯度对数归一化层。
[0070]
s2、将训练集数据trainset分为标签数据集labeleddataset和无标签数据集nolabeleddataset,并将训练数据集trainset中的脑电数据按照每30秒为一个数据片段进行数据划分,标签数据集labeleddataset中每个数据片段的标签为w、n1、n2、n3或rem中的一种;
[0071]
s3、利用标签数据集labeleddataset对睡眠混合神经网络模型进行预训练,得到预模型premodel;具体实现方法为:将标签数据集labeleddataset输入到睡眠混合神经网
络模型中计算出预测值,首先根据公式(2)、公式(3)和公式(4)计算出特征向量,然后将特征向量输入到公式(5)、公式(6)和公式(7)中得到gru输出,最后根据公式(8)计算出预测值,使用公式(9)计算损失值(使用标签数据集时,权重因子α设为0,损失函数公式只有第一项),根据损失值,反向传播并更新模型的参数,得到预训练后的模型premodel。
[0072]
s4、使用premodel对无标签数据集nolabeleddataset进行预测,并打上伪标签;然后使用标签数据和伪标签数据对预训练模型进行再次训练,得到伪标签模型pseudolabelmodel;具体实现方法为:用premodel对无标签数据集nolabeleddataset中的数据进行预测,得到伪标签数据集pseudolabelset;然后将标签数据集labeldataset和伪标签数据集pseudolabelset数据集输入到premodel中,首先根据公式(2)、公式(3)和公式(4)计算出特征向量,然后将特征向量输入到公式(5)、公式(6)和公式(7)中得到gru输出,最后根据公式(8)计算出预测值,使用公式(9)计算损失值,更新模型,得到伪标签模型pseudolabelmodel。
[0073]
s5、利用pseudolabelmodel对脑电数据进行预测,得到分期结果。
[0074]
所述步骤s3和s4中,采用交叉熵作为损失函数,由于模型是由有标签数据和伪标签数据一起训练得到,而有标签数据和伪标签数据的总数量是不同的,因此有标签数据和无标签数据的损失权重比例对模型的性能至关重要,因此设计损失函数如下所示:
[0075][0076]
其中t指标签数据的第t个样本,t
′
指无标签数据的第t
′
个样本;n,n
′
是标签数据和伪标签数据的样本数;指标签数据样本的真实类别是否是i,1代表是,0代表不是;指伪标签数据样本的真实类别是否是i,1代表是,0代表不是;指标签数据样本的每个类别预测概率,伪标签数据样本的每个类别预测概率;α是平衡差异的权重因子,wi是每个类别的权重因子;l是交叉熵损失函数,c是类别总数;等式右边第一个多项式表示标签数据的加权损失值,第二个多项式表示伪标签数据的加权损失值。
[0077]
权重因子α对伪标签模型的训练起着至关重要的作用,因此需要让α在一个合适的范围,并随着模型训练的迭代次数改变,以便模型能够更新参数,达到对模型最终性能的提升。权重因子α的范围由以下分段动态方程确定。
[0078][0079]
其中z是训练迭代次数,α
′
=0.1,t1=60,t2=100;模型开始训练时,α初始化为0,得到预训练模型,当迭代次数超过t1时,α加入到总损失函数中进行训练,并随着训练迭代次数的增加而增大,直到模型达到指定的训练次数时,训练结束。
[0080]
下面通过实验进一步验证本发明的技术效果。
[0081]
本文用来评估我们方法的数据集是一个公开可用的睡眠psg数据集—sleep-edfx数据集,此数据集来自physionet,其中一共有197条整夜psg睡眠记录,包括eeg、eog、emg的通道数据和事件标记。睡眠阶段是根据rechtschaffen和kales提出的r&k手册,由睡眠分期专家手动分期得到的。在这个数据集中的睡眠阶段一共包括觉醒期(w期)、快速眼动期(rem
期),非快速眼动1-4期(n1期,n2期,n3期,n4期),运动阶段和无分期阶段。在本研究中,我们移除了占比极少的运动阶段和未知分期阶段,并且按照aasm手册,将n3期和n4期合并为一个n3期。本研究使用的sleep-edfx数据集数据中包括两个子数据集。第一个是sleep-cassette(sc数据集),研究年龄对睡眠的影响,研究对象是年龄在25岁至101岁之间的健康受试者,除了3个受试者只有一个录音之外,其它每个受试者都有两个录音,录音有大约20个小时。第二个是sleep-telemetry(st文件),研究了在没有其他药物的情况下,药物羟基安定对22名白人男性和女性睡眠的影响。采用sleep-cassette数据集,并使用eeg的两个通道(fpz-cz和pz-oz)数据作为实验中的各种模型的输入数据,采样频率为100hz。在每段录音的开始和结束,都会有很长一段时间处于w期,在这段时间里,受试者没有睡觉。因为睡眠周期的数据是本次研究的重点,因此,我们将睡眠周期和前后的30分钟截取下来作为实验数据,每个受试者的每个睡眠文件数据都截取9个小时。
[0082]
使用了sleep-edfx中sleep-cassette数据集的单通道脑电数据训练和测试模型。首先将数据集按照每30秒划分为一个睡眠阶段,sleep-edfx数据集中每个睡眠阶段的30秒epochs数量如表1所示。s={w,n1,n2,n3,rem}作为睡眠数据集的标签分类,得到睡眠数据集sleepset,由于不同受试者的脑电信号通常具有不同地幅度(μv),为了使信号无量纲化,将sleepset中的数据标准化,得到standardsleepset。然后将数据集standardsleepset按4:1的比例分为训练集trainset和测试集testset。最后为了测试我们的伪标签模型,使用一部分有标签数据来模拟无标签数据,将训练集trainset中的数据按照1:2的比例分为标签数据集labeleddataset和无标签数据集unlabeleddataset,无标签数据集中的数据是使用标签数据来模拟的(去掉标签)。eeg数据处理的流程图如图5所示。
[0083]
表1 sleep-edfx数据集中睡眠阶段30秒epochs数量
[0084]
datasetwn1n2n3remtotalsleep-edfx5396717663597111241421474165229
[0085]
实验设置
[0086]
(1)参数设置
[0087]
为了评估shnn模型的性能和伪标签优化算法的效果,使用了五折交叉验证实验来分析。五折交叉验证是将sleepedfx所有受试者的数据按照4:1的比例划分训练集trainset和测试集testset。再将训练集trainset中的数据按照1:2的比例分为标签数据集labeled dataset和无标签数据集nolabeled dataset。
[0088]
首先使用标签数据集labeled dataset对模型进行有监督的预训练,我们使用premodel来表示这个预训练所得到的模型,模型训练使用adam优化器,学习率为lr1=10-3
。然后进行伪标签训练,训练过程是使用标签数据集labeled dataset和无标签数据集nolabeleddataset联合对预训练模型premodel进行训练得到最终的伪标签模型pseudomodel,伪标签训练使用adam优化器,学习率为lr2=10-4
。为了避免梯度消失的问题,我们采用批标准化batch normalization来改善。预训练步骤的迭代次数设置为40,伪标签训练迭代次数设置为60。网络超参数及其对应的值总结在表2中。超参数选择的过程是通过实验调整它们直到在测试集中获得最好的结果,例如批大小、dropout概率、bi-gru的层数、序列长度。
[0089]
表2网络超参数及其值
[0090][0091]
使用pytorch实现了我们的模型,这是一个深度学习库。这个库允许我们将模型训练部署到cpu或gpu上。我们在nvidia gtx1660 super图形处理单元上训练模型。五折交叉验证的每一折模型的迭代训练数量是100次,大约需要1个小时。
[0092]
(2)评价指标
[0093]
为了评价和比较不同方法的表现,本研究使用每类精确度(pre),每类召回率(re),每类f1-score(f1)来衡量每个睡眠阶段的分类表现,使用宏观平均f1-score(mf1),总体准确率(acc),和cohen的kappa系数(kappa)来评估所有类别的整体表现。每个类的度量时将某个类视为正类别,并将其他类别合并为负类别来计算的。以上评价指标的计算公式如公式(11)-(16)所示。
[0094][0095][0096][0097][0098]
其中tp,fp,tn,fn分别代表真阳性、假阳性、真阴性和假阴性样本的数量。
[0099]
[0100][0101]
其中f1i表示第i类的f1-score,pe表示由于随机性产生的符合比例。
[0102]
(3)对比试验,将提出的模型与三项相关的研究做了对比:
[0103]
a)arnaud在文献《tsinalis o,matthews p m,guo y,et al.automatic sleep stage scoring with single-channel eeg using convolutional neural networks[j].arxiv preprint arxiv:1610.01683,2016》中设计了一种1维多层cnn的网络模型,以4个30秒epoch睡眠数据为一组睡眠数据序列作为网络输入。cnn的层设置为12层,前七层的卷积核大小设置为7,中间三层的卷积核大小设置为5,最后两层的卷积核大小设置为3。该模型使用adam优化器来进行训练,学习率为lr1=3*10-5
,adam其余的超参数为β1=0.9,β2=0.999。批量大小为128,使用交叉熵作为损失函数。
[0104]
b)supratak在文献《supratak,akara,et al."deepsleepnet:a model for usingbased on raw single-channel eeg."ieee transactions on neural systems and rehabilitation engineering 25.11(2017):1998-2008.mbvcxzzxcvbnm》提出了一个用于自动睡眠分期的网络,它包含两个部分:一个提取时不变特征的表征学习模块和一个处理连续30秒样本的序列残差学习模块。表征学习模块基于频率信息使用两个不同的cnn,序列学习模块使用两层blstm。通过使用25个连续的30秒样本来训练模型,并使用adam优化器的过采样策略。模型训练包括两步,第一步中的adam的学习率设置为lr1=10-4
,adam其余的超参数为β1=0.9,β2=0.999,ε=10-8
。第二步对整个模型进行训练,其中表征学习模块的adam的学习率设置为lr2=10-6
,其余部分的adam的学习率设置为lr1=10-4
,adam其余的超参数为β1=0.9,β2=0.999,ε=10-8
,使用交叉熵作为损失函数。
[0105]
c)wenpeng neng在文献《neng w,lu j,xu l.ccrrsleepnet:a hybrid relational inductive biases network for automatic sleep stage classification on raw single-channel eeg[j].brain sciences,2021,11(4):456》中提出了一种端到端的混合关系归纳偏置网络。将脑电数据分为三个层次:帧、epoch和序列,同时采用多尺度空洞卷积块(msacb)来学习特征。该网络是帧级cnn、epoch层cnn和序列层rnn的混合体。帧层的cnn使用两个不同的卷积核来获得不同频率的信号特征。epoch层使用cnn来提取时不变特征,使用rnn提取时变特征。序列层使用bi-lstm来捕捉睡眠阶段之间的潜在相关性。模型训练采用两阶段训练方法。首先对帧级和纪元级子网络进行预训练,然后对整个网络进行微调。两个阶段都采用了焦点损失函数和adam优化器,其中beta1和beta2分别设置为0.9和0.99。在预训练阶段,学习率设置为lr1=10-3
。微调阶段的网络部分设置固定学习率lr2=10-6
。在预训练阶段将批量大小设置为256,在微调阶段批量大小设置为10。
[0106]
d)本发明模型使用伪标签训练法在sleep-edfx数据集在fpz-cz通道上的5折交叉验证的总体准确率为78.62%,kappa为0.7051。在表3中显示了5折交叉验证的总体混淆矩阵和精确度、召回率和f1分数。由于fpz-cz通道数据训练的模型相比于比pz-oz通道的性能更好,因此我们在此没有展示在pz-oz通道上的实验结果。表中每行和每列分别代表真实标签和模型分期的预测每个睡眠阶段的数量。粗体的数字表示被模型正确分期的数量。每行的最后三列表示从混淆矩阵计算出的每类性能指标,包括精确度,召回率和f1分数。从表中看出召回率和f1分数最差的是n1期,召回率为31.3%,f1分数小于40,而其他分期的分类召
回率和f1表现要好得多,分类召回率最高的是w期,w期召回率为90.45%,n2期、n3期和rem期随后,分别为83.43%、80.43%和72.36%,f1分数范围在70到90之间。
[0107]
表3伪标签训练的五折交叉验证结果
[0108][0109]
表4显示本发明的方法和以上三种方法在acc、mf1、cohen’s kappa(kappa)和f1分数等性能指标上的结果比较。需要说明的是,粗体的数字表示所有方法的最高性能指标。
[0110]
表4各种睡眠分期模型结果对比
[0111][0112][0113]
从表4可以看到,在使用相同脑电通道和数据集的情况下,相比于最先进的方法,本发明的模型在使用伪标签方法训练的得到的结果,在总的性能指标如:准确率、mf1和kappa上是优于a)、b)、c)。还应该强调的是,本发明的模型在每类的f1分数结果上,也几乎没有落后于目前最先进的基于单通道脑电的方法,甚至在n2和n3期上,f1分数的有着小幅度领先。根据kappa系数,这表明睡眠专家的分期标签和我们的模型预测结果之间的一致性是相当高的(介于0.61到0.80之间)。还应该注意的是,本发明的模型在fpz-cz通道上应用时比在pz-oz通道上应用时性能更好。
[0114]
另外,为了估计本发明与其他方法之间的准确性是否存在显着差异,采用了统计学中假设检验的p-value来进行分析。我们一共计算了四个p-value,如表4所示,结果表明我们的模型相比于a)和文献c),模型性能有着显著提升存在显着差异(p《0.05)。
[0115]
(4)消融实验:为了验证模型中不同模块对模型分类性能的影响,进行了消融实验,表5中展示了将shnn模型中的特征提取模块或者时间上下文信息提取模块去掉之后的模型分类结果,实验结果均在fpz-cz通道上进行五折交叉验证实验得到。表中用
“‑”
指明去除该部分后进行的实验。粗体的数字表示所有方法的最高性能指标。
[0116]
表5消融实验结果对比
[0117][0118]
可以看到,模型在去掉特征提取模块或者时间上下文信息提取模块之后,性能指标如准确率、mf1和kappa都出现了大幅下降,每类的f1分数也有不同程度的下降。出现这种现象的原因是,part i部分中的cnn负责对原始脑电数据进行特征提取,提取到抽象特征之后再进行分类,而去掉part i部分,也就意味着无法对原始脑电数据提取特征,模型只剩下bi-gru部分是无法获得好的分类效果的。而bi-gru能够提取睡眠脑电序列数据之间的时间上下文信息,而提取到的时间上下文信息能够改善类似于n1期和rem期这些比较难分类的分期结果,当模型去掉part ii结构之后,模型没有了bi-gru部分,也就无法可以利用到相邻的阶段信息对当前阶段进行分类,从而提高分类性能。因此我们的shnn模型里的所有模块对分类性能都有着巨大影响,也就是说所有模块都是不可缺少的。
[0119]
(5)独立测试集:为了验证伪标签方法是否适用于其他的模型,在a)、b)和c)的模型训练过程中,使用伪标签训练方法。得到的结果如表6所示,表中分组一是a)、b)、c)和本发明的模型在没有使用伪标签训练得到的分期结果,分组二是使用伪标签训练方法后得到的结果。粗体的数字表示每个组所有方法中的最高性能指标。
[0120]
表6睡眠分期模型使用伪标签训练前后结果对比
[0121][0122]
从表6可以很明显的看到,使用伪标签训练方法之后,deepsleepnet和cnn的模型分类结果在准确率、mf1和kappa都有了较大幅度的提升,同时模型的每类f1分数都有不同幅度的上升,只有deepsleepnet在使用伪标签训练方法之后,w期的f1分数有1%的下降。不同的模型使用伪标签训练方法之后,在准确率、mf1和kappa都有了较大幅度的提升,特别是n1分期和rem期的结果,大概有6%-7%的性能提升。这是由于n1是w期和其他睡眠阶段之间的过渡期,这时人的睡眠状态不稳定,而且样本量小。同时w期和n1期特征波形均为α波。由于睡眠状态是逐渐变化的,处于过渡阶段的睡眠阶段信号波形比较接近,很难区分,容易产生误判。而在使用无标签数据训练模型之后,相当于增加了n1期和rem期的样本数量,从而提升n1和rem期的分类结果。表6的实验结果说明伪标签训练方法确实能够提升模型的总体分类性能,同时模型的性能提升是在没有牺牲任何分期的分类效果情况下实现的。
[0123]
本发明提出了一种基于伪标签的端到端的自动睡眠分期模型,模型基于单通道脑
电图来进行睡眠脑电自动分期,同时输入模型的是原始脑电数据,不需要进行人工设计特征和特征工程部分的工作。该模型利用cnn提取脑电信号的时不变特征,同时利用bi-gru从脑电数据序列中提取时间上下文信息,最后模型根据cnn和bi-gru提取到的信息进行睡眠分期。因为模型是端到端的,不需要领域先验知识来进行信号预处理或者特征选择,网络可以自动学习最适合分类任务的特征。在此基础上,模型采用伪标签训练方法对模型进行训练,以增强模型的自动分期性能。shnn模型的特征提取模块结构简单,只包含三层卷积层,相比于其他的模型结构,卷积层的数量和参数量都要少很多,因此训练时间也少很多,同时模型的时间上下文提取模块使用的是bi-gru,因此可以利用gpu进行加速计算。总体来说,本发明的模型进行一次五折交叉验证的时间为5小时左右,相比于其他模型训练的时间要少很多。
[0124]
对无标签的睡眠数据打上伪标签并加入到模型的训练中,通过伪标签模型的不断迭代训练,伪标签不断接近真实结果。这是因为模型可以从无标签数据中获取参考信息,并在训练时更新模型参数,为下一次分期生成置信度更高的伪标签。
[0125]
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
