1.本发明涉及工序流程配置领域,具体涉及一种设备工序流程动态配置方法。
背景技术:
2.基于当前电子制造生产线配置资源,研究制造单元及系统负载平衡,科学地管理和使用生产设备;研究基于spt、mwkr、edd、sst多目标优化算法,对多种smt车间生产方案进行优化,形成优化的车间排产方案,最大限度地发挥设备生产加工能力和生产效率;研究多优化目标条件下动态工序配置方法,根据当前生产资源动态变化自适应调整,形成生产线流程、设备和计划,并对执行情况进行实时监控、跟踪和记录,减少人工干预,降低生产成本。
3.现有的设备工序流程动态配置方法存在数据传输时间长,效率低的技术问题。本发明提供一种设备工序流程动态配置方法,用以解决该问题。
技术实现要素:
4.本发明所要解决的技术问题是现有技术中存在的数据传输时间长,效率低的技术问题。提供一种新的设备工序流程动态配置方法,该设备工序流程动态配置方法具有数据传输时间长,效率低的特点。
5.为解决上述技术问题,采用的技术方案如下:
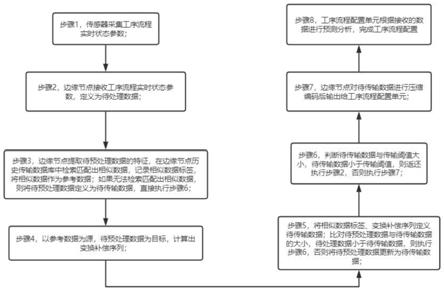
6.一种设备工序流程动态配置方法,设备工序流程动态配置方法包括:
7.步骤1,传感器采集工序流程实时状态参数;
8.步骤2,边缘节点接收工序流程实时状态参数,定义为待处理数据;
9.步骤3,边缘节点提取待预处理数据的特征,在边缘节点历史传输数据库中检索匹配出相似数据,记录相似数据标签,将相似数据作为参考数据;如果无法检索匹配出相似数据,则将待预处理数据定义为待传输数据,直接执行步骤6;
10.步骤4,以参考数据为源,待预处理数据为目标,计算出变换补偿序列;
11.步骤5,将相似数据标签、变换补偿序列定义待传输数据;比对待预处理数据与待传输数据的大小,待处理数据小于待传输数据,则执行步骤6,否则将待预处理数据更新为待传输数据;
12.步骤6,判断待传输数据与传输阈值大小,待传输数据小于传输阈值,则返还执行步骤2,否则执行步骤7;
13.步骤7,边缘节点对待传输数据进行压缩编码后输出给工序流程配置单元;
14.步骤8,工序流程配置单元根据接收的数据进行预测分析,完成工序流程配置。
15.为了科学地管理和使用生产设备,更多形成优化的车间排产方案,并根据当前生产资源动态自适应调整,最大限度地发挥设备生产加工能力和生产效率,本发明拟从制造单元的负载平衡、工序动态平衡方面开展研究。
16.上述方案中,为优化,进一步地,步骤2包括:
17.步骤2.1,定义一个特征提取框,特征提取框的宽度为w;
18.步骤2.2,使用特征提取框遍历待预处理数据,完成特征提取;
19.步骤2.3,将提取的特征与边缘节点历史传输数据库中的历史数据特征进行匹配,将匹配率大于预设阈值的历史数据定义为相似数据。
20.进一步地,步骤3包括;
21.步骤3.1,以特征提取框为单位确定源数据内的源数据子元,目标数据内的目标数据子元;
22.步骤3.2,定义变换方程为:e=d η
×
s;补偿方程为:i
‘’
=αi' β;
23.其中,η为预设的权权重值,i'表示形变后的源数据子元,i
‘’
表示经过幅度补偿之后的源数据子元;相邻源数据子元的连通性s,s=0表示不连通,s=1表示连通;
24.步骤3.3,确定源数据子元到目标数据子元的距离d,幅度补偿系数α和β;
25.步骤3.4,将源数据子元标签、目标数据子元标签、距离变换参数d、连通性s、幅度变换参数α和β定义为变换补偿序列。
26.进一步地,所述工序流程分析预测单元执行分析预测程序,包括数据归一化处理,对归一化数据进行工序流程分析,归一化处理包括:
27.步骤a,选出2个样本数据集分别定义为特征样本c和特征样本d,将特征样本c和特征样本d变换分解为z个子样本,每一个子样本分解为2部分,第一部分滤波系数定义为第二部分滤波系数定义为c/d表示特征样本c或特征样本d,1≤γ≤z表示第γ次分解;
28.步骤b,对于第γ次分解的第一部分滤波系数,采用第一融合准则进行融合,遍历特征样本c或特征样本d,计算特征样本c或特征样本d的相关度,得到融合权重,第一融合准则准则为:
29.确定p
×
q的窗口为区域r,计算区域r内每个特征样本的子点在水平方向和垂直方向的梯度幅值g
x
[i,j]和gy[i,j],计算出梯度值g(i,j)
[0030][0031]
计算出区域r的中心点的内积能量为e(p(x,y))
[0032]
《》为区域内积运算;
[0033]
计算出特征样本c和特征样本d的相关性为:
[0034][0035]
假设阈值为a,权重系数wc和wd为:
[0036]
当时,wc=0,wd=0;
[0037]
时,wd=1-wc;
[0038]
计算出第一部分融合后特征为rf(x,y)=wc·
rc(x,y) wc·
rc(x,y);
[0039]
步骤c,对于第γ次分解的第二部分系数,采用第二融合准则进行融合,定义p
×
q的窗口为区域r;第二融合准则为计算区域能量的最大值e进行融合;
[0040]
其中w(i,j)为区域中每个相邻点像素的权值;
[0041]
步骤d,采用与步骤a对应的逆变换对步骤b和步骤c的融合结果进行重构,得到归一化特征f。
[0042]
本发明的有益效果:本发明,在工序分析配置的过程中所需的数据采集和传输过程中,采用分级传输数据,减少传输开销,提高传输效率。在此基础上,本发明选择将新采集的数据与边缘节点的历史数据进行相似性判断,在判断出相似数据后,直接将两者的相似性参数(即变换补偿序列)作为待传输参数,进行传输。但是,为了防止浪费开销和降低传输效率,在此时,需要对处理前和处理后的数据段大小进行比对,有所减少后才使用新的数据段进行传输。接收端接收后,对应判断是否有相似性参数(即变换补偿序列),并通过逆运算解出数据。在此方案中,已经被传输给接收端的数据是存储在接收端的,如果存在相似数据,不用重新传输新数据,仅传输两者之间的变换关系,能够极大的节约传输带宽,增加传输效率。同时,采用将工序配置分析策略所需的不同种类数据进行规划处理,分析的效率。
附图说明
[0043]
下面结合附图和实施例对本发明进一步说明。
[0044]
图1,设备工序流程动态配置方法示意图。
[0045]
图2,基于规则的工序动态调度控制方法框图。
具体实施方式
[0046]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0047]
实施例1
[0048]
本实施例提供一种设备工序流程动态配置方法,设备工序流程动态配置方法包括:
[0049]
步骤1,传感器采集工序流程实时状态参数;
[0050]
步骤2,边缘节点接收工序流程实时状态参数,定义为待处理数据;
[0051]
步骤3,边缘节点提取待预处理数据的特征,在边缘节点历史传输数据库中检索匹配出相似数据,记录相似数据标签,将相似数据作为参考数据;如果无法检索匹配出相似数据,则将待预处理数据定义为待传输数据,直接执行步骤6;
[0052]
步骤4,以参考数据为源,待预处理数据为目标,计算出变换补偿序列;
[0053]
步骤5,将相似数据标签、变换补偿序列定义待传输数据;比对待预处理数据与待传输数据的大小,待处理数据小于待传输数据,则执行步骤6,否则将待预处理数据更新为待传输数据;
[0054]
步骤6,判断待传输数据与传输阈值大小,待传输数据小于传输阈值,则返还执行
步骤2,否则执行步骤7;
[0055]
步骤7,边缘节点对待传输数据进行压缩编码后输出给工序流程配置单元;
[0056]
步骤8,工序流程配置单元根据接收的数据进行预测分析,完成工序流程配置。
[0057]
本实施例中,在进行预测分析时,首先进行制造单元数学模型建立:
[0058]
工厂制造单元实质上混合装配线,通常采用最小生产循环描述一个生产循环,整个生产是由一系列的mps重复运作形成的。建立制造单元系统数学模型:在计划期内生产个品种的系列产品,每个品种的需求量是dm,在给定m个无回路的有向作业顺序图g=(e,p)中,节点e代表ti(i=1,2,3...n)作业元素集,弧p代表装配作业之间的先后关系集,一个节点i∈e注有一个值表示作业时间,将所有品种作业顺序图综合为综合作业顺序图,求节点集e的一个划分使一定的目标得到优化,满足一定的作业优先先关系、节拍及其它约束。并选定目标函数给定装配线节拍与最小化工作站数;给定装配线工作站数与最小化节拍两种主要类型,将作业元素的优先关系合并为联合优先关系,作业时间转化为综合作业时间。
[0059]
第二,制造单元负载平衡算法设计
[0060]
设计改进遗传混合算法来解决制造单元负载平衡问题,主要包括:
[0061]
初始化:随机生成初始种群设定相关遗传参数;
[0062]
适应度函数评估:建立适应度函数,适应度越大,则目标函数越小,即空闲时间越短,装配线越平衡;
[0063]
选择操作:采用最优保存策略和轮盘赌选择相结合的方法
[0064]
交叉操作:以交叉概率pc选择出两个个体以后按照交叉的方法单点进行交叉,然后对交叉后个体进行检验是否满足约束条件,再把最优的两个个体加入新的种群中;
[0065]
变异操作:以变异概率pm,在父体上任意选取两段基因进行交换,得到新的个体,这段基因在变异后也要检验是否满足约束条件;
[0066]
算法终止条件:算法在进化代后结束。
[0067]
优选地,步骤2包括:
[0068]
步骤2.1,定义一个特征提取框,特征提取框的宽度为w;
[0069]
步骤2.2,使用特征提取框遍历待预处理数据,完成特征提取;
[0070]
步骤2.3,将提取的特征与边缘节点历史传输数据库中的历史数据特征进行匹配,将匹配率大于预设阈值的历史数据定义为相似数据。
[0071]
优选地,步骤3包括;
[0072]
步骤3.1,以特征提取框为单位确定源数据内的源数据子元,目标数据内的目标数据子元;
[0073]
步骤3.2,定义变换方程为:e=d η
×
s;补偿方程为:i
‘’
=αi' β;
[0074]
其中,η为预设的权权重值,i'表示形变后的源数据子元,i
‘’
表示经过幅度补偿之后的源数据子元;相邻源数据子元的连通性s,s=0表示不连通,s=1表示连通;
[0075]
步骤3.3,确定源数据子元到目标数据子元的距离d,幅度补偿系数α和β;
[0076]
步骤3.4,将源数据子元标签、目标数据子元标签、距离变换参数d、连通性s、幅度变换参数α和β定义为变换补偿序列。
[0077]
优选地,所述工序流程分析预测单元执行分析预测程序,包括数据归一化处理,对归一化数据进行工序流程分析,归一化处理包括:
[0078]
步骤a,选出2个样本数据集分别定义为特征样本c和特征样本d,将特征样本c和特征样本d变换分解为z个子样本,每一个子样本分解为2部分,第一部分滤波系数定义为第二部分滤波系数定义为c/d表示特征样本c或特征样本d,1≤γ≤z表示第γ次分解;
[0079]
步骤b,对于第γ次分解的第一部分滤波系数,采用第一融合准则进行融合,遍历特征样本c或特征样本d,计算特征样本c或特征样本d的相关度,得到融合权重,第一融合准则准则为:
[0080]
确定p
×
q的窗口为区域r,计算区域r内每个特征样本的子点在水平方向和垂直方向的梯度幅值g
x
[i,j]和gy[i,j],计算出梯度值g(i,j)
[0081][0082]
计算出区域r的中心点的内积能量为e(p(x,y))
[0083]
《》为区域内积运算;
[0084]
计算出特征样本c和特征样本d的相关性为:
[0085][0086]
假设阈值为a,权重系数wc和wd为:
[0087]
当时,wc=0,wd=0;
[0088]
时,wd=1-wc;
[0089]
计算出第一部分融合后特征为rf(x,y)=wc·
rc(x,y) wc·
rc(x,y);
[0090]
步骤c,对于第γ次分解的第二部分系数,采用第二融合准则进行融合,定义p
×
q的窗口为区域r;第二融合准则为计算区域能量的最大值e进行融合;
[0091]
其中w(i,j)为区域中每个相邻点像素的权值;
[0092]
步骤d,采用与步骤a对应的逆变换对步骤b和步骤c的融合结果进行重构,得到归一化特征f。
[0093]
此外,本实施例还进行多目标优化算法设计。
[0094]
车间生产管理模块主要包括smt车间排产优化、smt车间物料管理、车间生产计划管理、生产管理数据及制造数据的可视化等内容。其中,smt车间排产优化smt车间排产优化技术,是将smt车间的生产计划细化为具体的生产作业过程,即对企业现有的流程、设备、计划定单细化为生产作业过程,形成优化的车间排产方案。
[0095]
在smt车间级对多种生产方案进行优化,是实现科学地管理设备、应用设备,最大
限度地发挥设备的生产加工能力,提高其生产效率和快速反应能力的一个重要环节。smt车间生产方案的制定是根据企业现有的流程、设备、计划定单进行,设计以下优先调度规则和优化方法:
[0096]
spt(shortest processing time)法则:优先选择所需加工时间最短的工件进行加工。方法使平均流程时间最短,减少在制品量,可获得最好的设备使用率。
[0097]
mwkr(most work remaining)法则:优先选择余下加工时间最长的工件进行加工。该方法使最长流程时间最短,减少在制品量,提高设备使用率。
[0098]
edd(earliest due date)法则:优先选择要求完工时间最早的工件进行加工。该方法使最大的延迟时间(延误≥0)最短。对交付期限严格的工件往往采取此规则。
[0099]
sst(shortest slack time)法则:优先选择松弛时间最短的工件进行加工。松弛时间=完工期限-当前时间-工件余下加工时间。该方法与edd规则类似,但是更能反映任务的紧迫程度。
[0100]
scr(smallest critical ratio)法则:优先选择关键比最小的工件进行加工。关键比=(完工期限-当前时间)/工件余下加工时间。关键比实际涵义:关键比小,表示相对松弛时间少,反映相对的任务紧迫程度。该方法此规则易于建立各工件间优先级的比较标准,综合性能较优。
[0101]
同时,根据当前生产资源条件,设计优先规则组合方法,如spt mwkr random。
[0102]
最后针对多品种变批量的生产任务,对生产计划的生成、调度、变更等执行情况进行实时监控、跟踪和记录,设计网络计划与滚动计划的工序动态配置算法。
[0103]
在进行动态工序配置设计时,针对多品种变批量的生产任务,对生产计划的生成、调度、变更等执行情况进行实时监控、跟踪和记录,设计网络计划与滚动计划的工序动态配置算法。
[0104]
网络计划模型由节点、支线和流三个基本要素构成。支线(弧)表示各项活动之间的逻辑关系(先后顺序),节点表示组成工程的各项独立的活动(任务),流表示完成各活动所需的时间、费用和资源等参数。网络计划模型生成后即可进行工序形成和动态调整等步骤。
[0105]
工序自动形成
[0106]
将当前任务分解成若干个独立的活动,并按照各活动间的工艺逻辑关系以及绘制网络图的规则,正确地绘成网络计划图后,就可以根据各活动的延续时间计算网络计划的各种时间参数。活动延续时间是在特定条件下,按质量完成该项活动的时间消耗。各项工作的延续时间取决于劳动组织,工作人员的技术或操作水平等多种因素。工程网络计划时间参数计算内容如下:一是完成任务所需要的最少时间(工程工期);二是工程中各项活动可能开始和结束时间;三是在不影响工期条件下,各活动允许拖延的机动时间(活动的时差)。
[0107]
工序分配及推进
[0108]
根据网络模型的多级嵌套网络计划把产品装配任务分解为各种多层的网络计划,按照层级的递推,将作业层层细化。上一层网络图可以递推到下一层的网络图,而下一层的网络图也可以回溯到上一层网络图,整个网络结构层次清楚地反应了产品装配的工艺路线和装配层次。
[0109]
工序动态配置
[0110]
车间的客观环境是不断变化的,为了适应车间的动态环境,提高计划的准确度,需要对车间作业计划进行实时调整。本实施例设计了基于规则的工序动态调度方法,该方法适用于广泛的动态变化的系统环境的全局最优化方法。系统运行时,根据实际状态动态选择规则集中的规则进行调度控制。以合理的额外计算时间为代价,换得比单纯启发式规则所得到的更好的调度。
[0111]
在图2中,对输入和输出两种状态使用fifo、spt方法进行动态换调度控制。输入状态变量:零件在队列中的平均等待时间;动态选择:当零件在队列中平均等待时间小于某一设定值时,选用spt规则进行调度,若零件等待时间超过该设定值,则选用fifo规则进行调度;计算决策:spt有效时,计算各零件的加工时间,选择最短者进行处理;fifo有效时,计算各零件的到达时间,选择最长路径进行处理。
[0112]
本实施例在工序分析配置的过程中所需的数据采集和传输过程中,采用分级传输数据,减少传输开销,提高传输效率。在此基础上,本发明选择将新采集的工序数据与边缘节点的历史数据进行相似性判断,在判断出相似数据后,直接将两者的相似性参数(即变换补偿序列)作为待传输参数,进行传输。但是,为了防止浪费开销和降低传输效率,在此时,需要对处理前和处理后的数据段大小进行比对,有所减少后才使用新的数据段进行传输。接收端接收后,对应判断是否有相似性参数(即变换补偿序列),并通过逆运算解出数据。在此方案中,已经被传输给接收端的数据是存储在接收端的,如果存在相似数据,不用重新传输新数据,仅传输两者之间的变换关系,能够极大的节约传输带宽,增加传输效率。同时,采用将工序配置分析策略所需的不同种类数据进行规划处理,分析的效率。
[0113]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员能够理解本发明,但是本发明不仅限于具体实施方式的范围,对本技术领域的普通技术人员而言,只要各种变化只要在所附的权利要求限定和确定的本发明精神和范围内,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。