1.本发明涉及生物工程领域,特别涉及一种合成聚(3-羟基丁酸酯-co-4
‑ꢀ
羟基丁酸酯)的菌株及其构建方法和应用。
背景技术:
2.生物聚酯(也称微生物聚酯,或聚羟基脂肪酸酯,polyhydroxyalkanoates, pha)是一类重要的非石油基高分子材料,它是利用可再生的天然原料通过微生物发酵而得到的。目前已发现超过百种pha高分子,它们具有各自的特性,其中聚3-羟基丁酸酯(phb)是pha早期最典型的代表,也是最廉价的pha材料。而近几年出现的3-羟基丁酸酯和4-羟基丁酸共聚酯 (poly(3-hydroxybutyrate-co-4-hydroxybutyrate,简称p34hb),是一种崭新的最具前景的pha高分子材料,其4hb含量在0-100%之间,随着4hb 含量的增加,共聚物由半结晶性的硬脆塑料逐渐改变为强度及韧性均大幅提高的塑料,后转变成非结晶富有弹性的弹性体,使得p34hb高分子的性能可以在很大范围内调节,p34hb具有良好的热稳定性,熔点可在 130-151℃内改变,分解温度约180℃,加工性较好,可完全生物降解,降解时间随材料中4hb含量和结晶度的高低而变化。p34hb兼具有良好的生物相容性能,生物可分解性和塑料的热加工性能,因此可作为生物医用材料和生物可分解包装材料。由于p34hb是综合性能较为优异的可生物降解高分子材料,国内已有公司开始工业化生产p34hb这种生物聚酯高分子原料,并对其在可降解塑料和生物医学产品方面进行应用开发和推广。
3.现有技术中制备3-羟基丁酸(p3hb)时需要使用化学催化剂进行酯化反应,酯化反应是需要强酸/高温剧烈条件进行,只能在发酵结束后进行酯化,耗能,成本高,周期长,不易于提取精制,制备的3-羟基丁酸乙酯也容易发生水解,且发酵过程需要灭菌,极大的浪费能源;使用的γ-丁内酯, 4羟基丁酸等作为p4hb聚酯的前体化合物因价格昂贵,具有毒性,属于易制毒化学品有很大的局限性,p34hb是3hb和4hb的聚合物,因此目前亟需一种成本低、安全无毒、生产效率高的制备p34hb的方法。
技术实现要素:
4.针对现有技术中的缺陷,本发明提出了一种新的p34hb的合成途径,在mdf-9菌株本身具有合成p3hb途径的基础上,再利用基因工程加入一条以使用谷氨酸(可生物发酵制取)作为前体化合物合成4hb的代谢途径,达成生产p34hb的目的。
5.本发明提供一种合成聚(3-羟基丁酸酯-co-4-羟基丁酸酯)的菌株的构建方法,包括如下步骤:
6.s1:体外扩增gadb*、gabt、yqhd三个基因序列;
7.s2:将s1所述的gadb*、gabt、yqhd三个基因序列插入载体中,得到载体质粒;
8.s3:将s2得到的载体质粒转入halomonas lutescens mdf-9感受态细胞中;所述halomonas lutescens mdf-9的保藏编号为gdmcc no.61850。
9.本技术中使用的halomonas lutescens mdf-9菌株已于2021年8月2日保藏于广东省微生物菌种保藏中心(简称gdmcc地址:广州市先列中路100号大院59号楼5楼,广东省微生物研究所,邮编510070)。保藏号为gdmcc no: 61850。菌株名称为mdf-9,分类命名为盐单胞菌(halomonas lutescens)。
10.本技术的halomonas lutescens mdf-9菌株已经在在先申请中公开,申请号为202110929333.2,发明名称为“一株盐单胞菌及其应用”。
11.进一步的,所述步骤s1中目的基因的扩增体系为:
[0012][0013]
进一步的,所述步骤s1中目的基因的扩增程序为:
[0014][0015]
进一步的,所述步骤s2中通过重叠延伸pcr得到gadb*基因,将gadb* 与大肠杆菌中的gabt和yqhd通过酶切一起插入pcs27载体的一个操纵子中,得到载体质粒。
[0016]
进一步的,所述酶切体系为:
[0017][0018]
本发明还提供一种合成聚(3-羟基丁酸酯-co-4-羟基丁酸酯)的工程菌株,由所述的构建方法得到。
[0019]
本发明还提供一种使用所述的工程菌株生产聚(3-羟基丁酸酯-co-4-羟基丁酸酯)的方法,包括如下步骤:
[0020]
(1)平板种子培养:菌种活化;
[0021]
(2)摇瓶种子培养;
[0022]
(3)溶氧和ph电极校正;
[0023]
(4)发酵参数的设定;
[0024]
(5)接种;
[0025]
(6)发酵过程控制;
[0026]
(7)菌体中pha的提取。
[0027]
进一步的,所述步骤(6)中控制发酵罐温度36~38℃。
[0028]
进一步的,所述步骤(6)中控制ph为7.5~9.5。
[0029]
进一步的,控制ph为8.2~8.5。
[0030]
综上,与现有技术相比,本发明达到了以下技术效果:
[0031]
1.本发明中p4hb聚酯可以由生物发酵制得,能够降低生产成本、且安全无毒。
[0032]
2.本发明使用生物工程材料谷氨酸作为前体化合物,具有环保无污染,价格低,易获得,生产安全系数高的优势。
[0033]
3.本发明所用的谷氨酸工程菌自身可产生,降低人工劳动量,工艺上更加先进,工厂效率更高。
[0034]
4.本发明使用嗜盐单胞菌mdf-9为底盘生物,发酵过程为高盐高碱,因此发酵过程不需要灭菌,操作更加方便,可实现连续接种或补充底物进行不间断发酵,与使用埃希氏菌属、假单胞菌属、气单胞菌属的菌株相比更加节省能源。
附图说明
[0035]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
[0036]
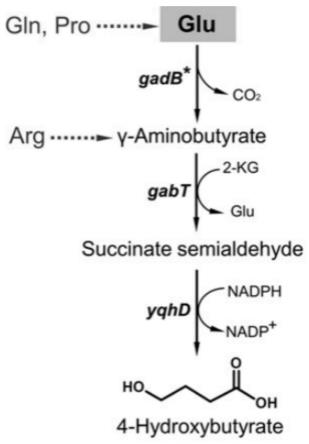
图1为本发明的工程菌(加入gadb*、gabt、yqhd三种基因序列)进行的生产4hb的代谢过程。
[0037]
图2为本发明构建中使用的载体结构图。
[0038]
图3为本发明实施例1制备得到的工程菌的pcr验证结果。
具体实施方式
[0039]
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
[0040]
gadb*基因的作用是将谷氨酸转化为γ-氨基丁酸(4-氨基丁酸,简称 gaba),gabt基因的作用是将gaba转化为琥珀酸半醛,简称ssa。 yqhd基因作用是将ssa转化为4-羟基丁酸(简称4hb)。4hb在mdf-9 菌株特有的酶pha聚合酶(基因为phac)作用下合成聚4-羟基脂肪酸酯(简称p4hb)。因mdf-9本身具有生产聚3-羟基脂肪酸酯的代谢途径,本发明主要是在此基础上新增一条生产p4hb的代谢途径(如图1所示)。菌株构建成功后可达到生产3hb、4hb共聚物(简称p34hb)的目的。
[0041]
本发明的工程菌株构建过程大致分为以下几步:
[0042]
s1:体外扩增gadb*、gabt、yqhd三个基因序列;
[0043]
s2:将上述基因序列插入载体质粒;
[0044]
s3:将载体质粒转入mdf-9感受态细胞。
[0045]
实施例1本发明合成p34hb的工程菌株的构建
[0046]
gadb*、gabt、yqhd基因表达
[0047]
(1)质粒构建:将pcr扩增的基因产物用适当的限制性内切酶酶切并连接到相同的酶切载体上。通过重叠延伸pcr得到gadb*(gadb来自大肠杆菌e89q,c端452-466被截断)。将gadb*与大肠杆菌中的gabt和yqhd 一起插入pcs27(pllaco1,p15a ori,kanr,10-12copies)的一个操纵子中,得到4hb途径质粒p4hb,载体图如图2所示。
[0048][0049]
具体的,主要通过下述步骤构建:
[0050]
从大肠杆菌e89q利用ecgadb-e89q-rl、ecgadb-e89q-fl得到 gadb;利用ecgadb-de452-466-r(ndei)得到突变体gadb*;分别利用 ecgadb-f(acc65i)、ecgadb-r(ndei)、ecgabt-f(ndei)、ecgabt-r(ecori)、ecyqhd-f(ecori)、ecyqhd-r(bamhi)将gadb*、gabt、yqhd连接到pcs27 上,得到全新质粒p4hb。
[0051]
(2)引物序列(5
’‑3’
)如下:
[0052]
ecgadb-f(acc65i):
[0053]
gggaaaggtaccatggataagaagcaagtaacggatttaag
[0054]
ecgadb-r(ndei):
[0055]
gggaaacatatgtcaggtatgtttaaagctgttctgttgg
[0056]
ecgadb-de452-466-r(ndei):
[0057]
gggaaacatatgtcagtgatcgctgagatatttcagggag
[0058]
ecgadb-e89q-rl:
[0059]
gattgcggatattgttctttgtcgatccagtttttg
[0060]
ecgadb-e89q-fl:
[0061]
ggatcgacaaagaacaatatccgcaatccgcagccatc
[0062]
ecgabt-f(ndei):
[0063]
gggaaacatatgaggagatataccatgaacagcaataaagagttaa tgcag
[0064]
ecgabt-r(ecori):
[0065]
gggaaagaattcctactgcttcgcctcatcaaaacactg
[0066]
ecyqhd-f(ecori):
[0067]
gggaaagaattcaggagatataccatgaacaactttaatctgcacac ccca
[0068]
ecyqhd-r(bamhi):
[0069]
gggaaaggatccttagcgggcggcttcgtatatacggc
[0070]
(3)目的基因的扩增
[0071]
扩增体系如下:
[0072][0073]
pcr反应完成后,配制相应浓度的琼脂糖凝胶,进行电泳以便观察dna 的条带大小,将凝胶置于紫外灯下,迅速的切下目的dna片段的凝胶,尽可能的将多余的凝胶切掉。
[0074]
(4)载体的限制性酶切反应
[0075]
按照如下体系进行双酶切反应,加完所有试剂后放置于37℃孵育器中 3-4h,然后将产物进行电泳,以便观察其酶切是否成功。
[0076][0077]
pcr反应完成后,配制相应浓度的琼脂糖凝胶,进行电泳以便观察dna 的条带大小,将凝胶置于紫外灯下,迅速的切下目的dna片段的凝胶,尽可能的将多余的凝胶切掉。
[0078]
(5)扩增产物与载体酶切产物回收
[0079]
步骤1.将扩增产物和酶切产物用琼脂糖凝胶dna回收试剂盒(hipure gel pure dna mini kit)进行回收;
[0080]
步骤2.将在紫外灯下切的目的dna片段的凝胶装入2ml收集管中,加入500μl buffer gdp。如果凝胶浓度较大,可以适当的增加buffer gdp 的体积。将凝胶放入烘箱10-15min,期间颠倒混匀,以至完全溶解;
[0081]
步骤3.将hipure dna mini colum装到2ml离心管中,将溶胶液转移至柱子中,如果溶胶液超过700μl则分两次转入。12000rpm离心1min;
[0082]
步骤4.弃掉滤液,将柱子重新装入2ml收集管中,加入300μl buffer gdp,并且静置1min;
[0083]
步骤5.弃掉滤液,将柱子重新装入2ml收集管中,加入600μl buffer dw2(已提前加入无水乙醇)到柱子中。12000rpm离心1min;
[0084]
步骤6.重复上述步骤一次;
[0085]
步骤7.弃掉滤液,将柱子重新装入2ml收集管中。空甩12000rpm离心2min;
[0086]
步骤8.将柱子重新装入新的1.5ml离心管中。放入烘箱中5min,打开柱子的盖子以彻底去除无水乙醇(无水乙醇残留会影响后续反应);
[0087]
步骤9.往柱子膜中央加入15-30μl eb,室温(rt)放置2min。12000 rpm离心1min。可重复上柱一次,洗脱下来的dna保存于-20℃。
[0088]
(6)同源重组反应体系
[0089]
采用一步克隆酶(clon expressii one step cloning kit),按照如下反应加入微量管中混匀,短暂离心使反应液收集至管底。放置37℃孵育器30 min。拿出微量管立即放至冰上或降至4℃。
[0090][0091]
x(载体使用量)=(0.01
×
载体碱基数)/载体回收产物浓度;
[0092]
y(载体使用量)=(0.02
×
目的基因碱基数)/目的基因回收产物浓度。
[0093]
(7)mdf-9转化
[0094]
步骤1.将提前制备好的克隆感受态细胞从-80℃拿出,在冰上解冻,5 min后待菌块融化。
[0095]
步骤2.往感受态细胞中加入10μl连接产物,轻轻的弹管壁将反应液混匀(请勿振荡混匀),后将其冰上静10-30min。连接产物转化体积最多不应超过所用感受态细胞体积1/10;
[0096]
步骤3.42℃水浴热激45-90s后,立即置于冰上冷却2-3min,晃动会降低转化效率;
[0097]
步骤4.向离心管中加入700μl lb培养基(不含抗生素),混匀后放入37℃摇床中200rpm复苏60min;
[0098]
步骤5.5000rpm离心5min收菌,弃掉600μl上清留取100μl轻轻吹打重悬菌块并涂布到含相应抗生素的lb培养基上;
[0099]
步骤6.将培养基倒置到37℃培养箱中培养12-15h。
[0100]
(8)质粒小提
[0101]
采用magen生物公司质粒小提试剂盒(hipure plasmid micro kit)。
[0102]
步骤1.将阳性的单克隆菌落接种于5-10ml含有相应抗生素的lb培养基中,置于37℃摇床中12-16h。保存菌液于-80℃,以便后续接菌繁殖;
[0103]
步骤2.取2ml菌液装入提前准备好的2ml离心管中,12000rpm离心 30-60s,收集2-3次;
[0104]
步骤3.倒弃上清,在吸水纸上轻轻拍打吸尽残液。加入250μl预冷的 buffer p1/rnase a混合液,在振荡仪上高速涡旋彻底重悬细菌;
[0105]
步骤4.往2ml管中加入250μl buffer p2,上下轻轻颠倒混匀8-10次,溶液变得粘稠而透亮表明细菌已经充分裂解。如果涡旋会导致基因组dna 污染。这一步如果样品较多,操作要迅速;
[0106]
步骤5.往上述重悬液中加入350μl buffer p3,立即颠倒混匀8-10次让溶液中和,防止沉淀团聚而影响中和效果;
[0107]
步骤6. 12000rpm离心10min;
[0108]
步骤7.将hipure dna mini colum ii装入2ml collection tube中,将上清转至柱子中。12000rpm离心30-60s;
[0109]
步骤8.弃掉滤液,加入500μl buffer pw1至柱子中。12000rpm离心30-60s;
[0110]
步骤9.弃掉滤液,加入600μl已经用无水乙醇稀释过的buffer pw2至柱子中。12000rpm离心30-60s;
[0111]
步骤10.重复上一步骤;
[0112]
步骤11.将柱子装入提前准备好的1.5ml离心管中,往柱子膜中央加入15-30μl eb,室温放(rt)放置2min。12000rpm离心1min洗脱dna;
[0113]
步骤12.弃掉柱子,质粒用于后续反应保存于-20℃。
[0114]
(9)酶切、测序鉴定。结果表明本实施例mdf-9菌株中成功转入了 gadb*、gabt、yqhd基因,得到本发明用于发酵的工程菌。图3中显示的是上述基因的电泳图,通过目的产物的大小进行验证。上述三个基因的大小分别为1824bp、1929bp和2016bp,均符合预期结果。
[0115]
实施例2利用本发明的工程菌发酵制备p34hb
[0116]
(1)配制使用的培养基:
[0117]
lb平板培养基:酵母浸粉0.5%;胰蛋白胨1%;氯化钠6%,琼脂粉 1.8g/100ml,ph 8.0;
[0118]
lb摇瓶培养基:酵母浸粉0.1%;氯化钠6%,ph 8.0,30ml/250ml。
[0119]
组分i:硫酸镁:0.2g/l;尿素:0.6g/l;(配制50倍浓缩的母液:10 g/l硫酸镁,30g/l尿素);
[0120]
组分ii:磷酸二氢钾(5.2g/l),配50倍母液260g/l;
[0121]
葡萄糖溶液(30g/l):配葡萄糖母液500g/l;
[0122]
组分iii(10ml/l):柠檬酸铁铵5g/l,无水氯化钙1.5g/l,12mol/l 盐酸41.7ml/l);
[0123]
组分iv(1ml/l)(四):(七水硫酸锌100mg/l,四水硫酸锰30mg/l,硼酸300mg/l,六水氯化钴200mg/l,五水硫酸铜10mg/l,氯化镍六水合物20mg/l,钼酸钠30mg/l;
[0124]
发酵培养基:
[0125]
玉米浆干粉 36g(单独溶解后加入)
[0126]
mgso4(硫酸镁) 0.6g
[0127]
urea(尿素) 6g
[0128]
kh2po4(磷酸氢二钾) 15.6g
[0129]
c6h
12
o6(葡萄糖) 60g(20g/l)
[0130]
nacl(氯化钠) 150g
[0131]
补料培养基:
[0132][0133]
4%的naoh调节培养基ph,消泡剂5%量配置后添加。
[0134]
发酵过程ph控制在7.5-9.5。
[0135]
(2)平板种子培养:菌种活化
[0136]
实验室4℃冰箱取菌种,用酒精棉将双手消毒,待双手酒精干透后,点酒精灯。平皿底部写上接种菌名、日期和时间。用接种环挑取单菌落划线接种于平板上,培养24小时。重复上述操作,接种平板二级,培养24小时。
[0137]
(3)摇瓶种子培养:一级菌液:取二级平板,挑取单菌种接种于lb 摇瓶培养基中,将培养液置于摇床37℃、220rpm培养12小时。
[0138]
二级菌液:吸取一级菌液300微升(1%接种量),接种于二级摇瓶培养基中将培养液置于摇床37℃、220rpm培养12小时。
[0139]
(4)溶氧和ph电极校正:发酵罐用水冲洗干净,对do电极进行标零,ph电极进行两点校准(标准缓冲液放置常温),校准后正确安装在发酵罐上,空消。(ph电极和溶氧电极不用空消)
[0140]
(5)发酵参数的设定:准备好组分iii和组分iv(提前溶解),发酵罐温度控制在35~40℃。利用碱液调节ph 7.5~9.5(注意进罐阀门开度)加入消泡剂0.3ml,打开空气进罐阀调节初始空气流量2l/min进罐,初始转速调至400rpm,待od示数稳定后标定100%。
[0141]
(6)接种:挑选颜色均匀,少沉淀物的种子液300ml,将种子液接种进入发酵罐,发酵罐中使用发酵培养基,摇瓶残液并预留10ml菌液测定 od和残糖,接种后倒入组分iii(30ml)和组分iv(3ml)。
[0142]
(7)发酵过程控制:控制发酵罐温度37
±
1℃,ph8.5
±
1,转速和空气流量交替调节控制溶氧35~80%,初始转速为400rpm,通气量2l/min,转速每次调节50rpm,最高转速800rpm,空气流量每次调节0.5l/min,最高调节3l/min,前四个小时,每两个小时取样,测od和残糖。
[0143]
正常情况下,溶氧会逐渐下降,转气控制溶氧35%以上,每半个小时对罐内液面情况进行确认,液面太高,需要消泡(少量多次,避免过量)。
[0144]
每两小时取样,先放出几秒,再取菌液2ml,检测菌液离线ph,稀释,测残糖和和od值。流加控制残糖5-15g/l。
[0145]
(8)菌体中pha的提取
[0146]
重复加水10000prm弃上清离心6次后,即可得到产物。
[0147]
实施例3产物浓度的检测
[0148]
使用气相色谱检测,产物里只要有3hb/4hb,就可以说明工程菌构建成功。
[0149]
pha测定的基本原理是添加浓硫酸将pha结构中的酯健断裂,分解为低分子量的巴豆酸。在酸性条件下,巴豆酸还可以继续跟甲醇反应转化为巴豆酸甲酯,该组分含量可以通过气相色谱法(gc)进行检测。具体测定方法如下:
[0150]
(1)称取0.05g研磨后的实施例2发酵得到的干菌体,置于密封性良好的酯化管中,加入2ml氯仿、850μl甲醇及150μl浓硫酸,在100℃油浴下反应1h,室温冷却后加入1ml ddh2o,充分震荡混匀后,静置分层。待水相和有机相完全分离后,取氯仿层(一般为下层)采用0.22μm的有机滤膜过滤至液相瓶中,进行gc检测,采用gc-7800气相色谱仪、毛细管色谱柱(rtx-5型,长30m,内径0.25mm和固定相0.25μm)和氢火焰离子检测器(fid)。载气采用高纯氮。程序升温设定如下:
[0151][0152]
进样体积为1μl,采用外标法对pha进行定量分析,根据峰面积计算 pha的产量。
[0153]
(2)标准曲线的建立
[0154]
pha的定量分析采用外标法。待分析的样品pha样品经甲酯化预处理后分别成3-羟基丁酸甲酯及4-羟基丁酸甲酯,经gc程序的分析保留时间分别为2.3min和2.8min。将购买自sigma的标准品准确稀释至对应浓度,然后以样品浓度为x轴,峰面积为y轴分别绘制标准曲线,所得标准曲线方程为:
[0155]
3hb:y=21726x-1213.5(r2=0.9992)。
[0156]
4hb:y=45967x-1359.6(r2=0.9996)。
[0157]
参数结果1:在ph 8.5条件下5l发酵罐培养中获得细胞干重为80g/l,其中4hb含量为40%,3hb含量为60%。
[0158]
参数结果2:在ph 8.2条件下5l发酵罐培养中获得的细胞干重为 80g/l,其中4hb含量为55%,3hb含量为45%。
[0159]
p34hb是4hb和3hb共聚物的简称,3hb和4hb单体在pha聚合酶phac的作用下,单体的羧基与相邻的单体的羟基形成酯键,形成二元共聚p34hb。p34hb相较于p4hb和p3hb有着更高的拉伸强度,所以检测产物的拉伸强度可以证明合成p34hb新途径的建立。
[0160]
拉伸强度实验结果:
[0161][0162]
其中,p3hb和p4hb是购买的的市售化合物检测,1~3为三个重复;
[0163]
p34hb是参数1(ph 8.5)下的产物的检测结果,1~3为三个重复。因此,可以证明本发明的工程菌株发酵可以产生p34hb。
[0164]
综合以上实施例,本发明公开了一种合成聚(3-羟基丁酸酯-co-4-羟基丁酸酯)的菌株及其构建方法和应用。所述构建方法包括如下步骤:s1:体外扩增gadb*、gabt、yqhd三个基因序列;s2:将三个基因序列插入载体中,得到载体质粒;s3:将s2得到的载体质粒转入halomonas lutescensmdf-9感受态细胞中。本发明提出了一种新的p34hb的合成途径,在 mdf-9菌株本身具有合成p3hb途径的基础上,再利用基因工程加入一条以使用谷氨酸作为前体化合物合成p4hb的代谢途径,达成生产p34hb的目的。该工程菌能够在pha领域生产p34hb工艺中有效地降低原料价格,降低毒害风险,提高生产效率。
[0165]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
[0166]
序列表
[0167]
seq id no.1(yqhd基因序列)
[0168]
tgaacaactttaatctgcacaccccaacccgcattctgtttggtaaaggcgcaatcgctggttt acgcgaacaaattcctcacgatgctcgcgtattgattacctacggtggcggcagcgtgaaaaa aaccggcgttctcgatcaagttctggatgccctgaaaggcatggacgtgctggaatttggcggt attgagccaaacccggcttatgaaacgctgatgaacgccgtgaaactggttcgcgaacagaaa gtgactttcctgctggcggttggcggcggttctgtactggacggcaccaaatttatcgccgcag cggctaactatccggaaaatatcgatccgtggcacattctgcaaacgggcggtaaagagattaa aagcgccatcccgatgggctgtgtgctgacgctgccagcaaccggttcagaatccaacgcagg cgcggtgatctcccgtaaaaccacaggcgacaagcaggcgttccattctgcccatgttcagcc ggtatttgccgtgctcgatccggtttatacctacaccctgccgccgcgtcaggtggctaacggc gtagtggacgcctttgtacacaccgtggaacagtatgttaccaaaccggttgatgccaaaattc aggaccgtttcgcagaaggcattttgctgacgctgatcgaagatggtccgaaagccctgaaag agccagaaaactacgatgtgcgcgccaacgtcatgtggggggcgacgcaggcgctgaacggt ttgattggcgctggcgtaccgcaggactgggcaacgcatatgctgggccacgaactgactgcg atgcacggtctggatcacgcgcaaacactggctatcgtcctgcctgcactgtggaatgaaaaa cgcgagaccaagcgcgctaagctgctgcaatatgctgaacgcgtctggaacatcactgaaggt tccgatgatgagcgtattgacgccgcgattgccgcaacccgcaatttctttgagcaattaggcg tgccgacccacctctccgactacggt
ctggacggcagctccatcccggctttgctgaaaaaac tggaagagcacggcatgacccaactgggcgaaaatcatgacattacgttggatgtcagccgcc gtatatacgaagccgcccgctaagctttttacgcctcaaactttcgttttcgggcatttcgtcca gacttaagttcacaacacctcaccggagcctgctccggtgagttcatataaaggagga
[0169]
seq id no.2(gadb基因序列)
[0170]
atggataagaagcaagtaacggatttaaggtcggaactactcgattcacgttttggtgcgaagt ctatttccactatcgcagaatcaaaacgttttccgctgcacgaaatgcgcgacgatgtcgcattc cagattatcaatgacgaattatatcttgatggcaacgctcgtcagaacctggccactttctgcca gacctgggacgacgaaaatgtccacaaattgatggatttatccattaacaaaaactggatcgac aaagaagaatatccgcaatccgcagccatcgacctgcgttgcgtaaatatggttgccgatctgt ggcatgcgcctgcgccgaaaaatggtcaggccgttggcaccaacaccattggttcttccgagg cctgtatgctcggcgggatggcgatgaaatggcgttggcgcaagcgtatggaagctgcaggca aaccaacggataaaccaaacctggtgtgcggtccggtacaaatctgctggcataaattcgccc gctactgggatgtggagctgcgtgagatccctatgcgccccggtcagttgtttatggacccgaa acgcatgattgaagcctgtgacgaaaacaccatcggcgtggtgccgactttcggcgtgaccta cactggtaactatgagttcccacaaccgctgcacgatgcgctggataaattccaggccgatacc ggtatcgacatcgacatgcacatcgacgctgccagcggtggcttcctggcaccgttcgtcgccc cggatatcgtctgggacttccgcctgccgcgtgtgaaatcgatcagtgcttcaggccataaatt cggtctggctccgctgggctgcggctgggttatctggcgtgacgaagaagcgctgccgcagga actggtgttcaacgttgactacctgggtggtcaaattggtacttttgccatcaacttctcccgc ccggcgggtcaggtaattgcacagtactatgaattcctgcgcctcggtcgtgaaggctatacca aagtacagaacgcctcttaccaggttgccgcttatctggcggatgaaatcgccaaactggggc cgtatgagttcatctgtacgggtcgcccggacgaaggcatcccggcggtttgcttcaaactgaa agatggtgaagatccgggatacaccctgtatgacctctctgaacgtctgcgtctgcgcggctgg caggttccggccttcactctcggcggtgaagccaccgacatcgtggtgatgcgcattatgtgtc gtcgcggcttcgaaatggactttgctgaactgttgctggaagactacaaagcctccctgaaata tctcagcgatcacccgaaactgcagggtattgcccaacagaacagctttaaacatacctga
[0171]
seq id no.3(gadb*基因序列)
[0172]
atggataagaagcaagtaacggatttaaggtcggaactactcgattcacgttttggtgcgaagt ctatttccactatcgcagaatcaaaacgttttccgctgcacgaaatgcgcgacgatgtcgcattc cagattatcaatgacgaattatatcttgatggcaacgctcgtcagaacctggccactttctgcca gacctgggacgacgaaaatgtccacaaattgatggatttatccattaacaaaaactggatcgac aaagaagaatatccgcaatccgcagccatcgacctgcgttgcgtaaatatggttgccgatctgt ggcatgcgcctgcgccgaaaaatggtcaggccgttggcaccaacaccattggttcttccgagg cctgtatgctcggcgggatggcgatgaaatggcgttggcgcaagcgtatggaagctgcaggca aacccctggtgtgcggtccggtacaaatctgctggcataaattcgcccgctactgggatgtgga gctgcgtgagatccctatgcgccccggtcagttgtttatggacccgaaacgcatgattgaagcc tgtgacgaaaacaccatcggcgtggtgccgactttcggcgtgacctacactggtaactatgag ttcccacaaccgctgcacgatgcgctggataaattccaggccgataccggtatcgacatcgaca tgcacatcgacgctgccagcggtggcttcctggcaccgttcgtcgccccggatatcgtctggga cttccgcctgccgcgtgtgaaatcgatcagtgcttcaggccataaattcggtctggctccgctg ggctgcggctgggttatctggcgtgacgaagaagcgctgccgcaggaactggtgttcaacgtt gactacctgggtggtcaaattggtacttttgccatcaacttctcccgcccggcgggtcaggtaa ttgcacagtactatgaattcctgcgcctcggtcgtgaaggctataccaaagtacagaacgcctc ttaccaggttgccgcttatctggcggatgaaatcgccaaactggggccgtatgagttcatctgt acgggtcgcccggacgaaggcatcccggc
ggtttgcttcaaactgaaagatggtgaagatccg ggatacaccctgtatgacctctctgaacgtctgcgtctgcgcggctggcaggttccggccttca ctctcggcggtgaagccaccgacatcgtggtgatgcgcattatgtgtcgtcgcggcttcgaaat ggactttgctgaactgttgctggaagactacaaagcctccctgaaatatctcagcgatcacccg aaactgcagggtattgcccaacagaacagctttaaacatacctga
[0173]
seq id no.4(gabt基因序列)
[0174]
atgaacagcaataaagagttaatgcagcgccgcagtcaggcgattccccgtggcgttgggca aattcacccgattttcgctgaccgcgcggaaaactgccgggtgtgggacgttgaaggccgt gagtatcttgatttcgcgggcgggattgcggtgctcaataccgggcacctgcatccgaaggt ggtggccgcggtggaagcgcagttgaaaaaactgtcgcacacctgcttccaggtgctggct tacgagccgtatctggagctgtgcgagattatgaatcagaaggtgccgggcgatttcgccaa gaaaacgctgctggttacgaccggttccgaagcggtggaaaacgcggtaaaaatcgcccgc gccgccaccaaacgtagcggcaccatcgcttttagcggcgcgtatcacgggcgcacgcatta cacgctggcgctgaccggcaaggtgaatccgtactctgcgggcatggggctgatgccgggtc atgtttatcgcgcgctttatccttgcccgctgcacggcataagcgaggatgacgctatcgcca gcatccaccggatcttcaaaaatgatgccgcgccggaagatatcgccgccatcgtgattgagc cggttcagggcgaaggcggtttctacgcctcgtcgccagcctttatgcagcgtttacgcgct ctgtgtgacgagcacgggatcatgctgattgccgatgaagtgcagagcggcgcggggcgta ccggcacgctgtttgcgatggagcagatgggcgttgcgccggatcttaccacctttgcgaaa tcgatcgcgggcggcttcccgctggcgggcgtcaccgggcgcgcggaagtaatggatgccg tcgctccaggcggtctgggcggcacctatgcgggtaacccgattgcctgcgtggctgcgctg gaagtgttgaaggtgtttgagcaggaaaatctgctgcaaaaagccaacgatctggggcaga agttgaaagacggattgctggcgatagccgaaaaacacccggagatcggcgacgtacgcgg gctgggggcgatgatcgccattgagctgtttgaagacggcgatcacaacaagccggacgcc aaactcaccgccgagatcgtggctcgcgcccgcgataaaggcctgattcttctctcctgcgg cccgtattacaacgtgctgcgcatccttgtaccgctcaccattgaagacgctcagatccgtca gggtctggagatcatcagccagtgttttgatgaggcgaagcagtag。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。