1.本发明涉及目标检测技术邻域,具体涉及一种融合主观逻辑和不确定性分布建模的可信目标检测方法。
背景技术:
2.图像目标检测技术在人工智能、无人驾驶、智慧医疗等方面有着广泛运用。随着大型视觉图像数据集和深度学习技术的诞生,机器学习领域有了极大的发展。当今,确定性神经网络已被证明可作为极度高效的图像检测分类器,并在相关工作中表现出了惊人的结果,而其中最具代表性的可分为以r-cnn(region-based convolutional neural networks)为代表的两阶段目标检测网络和将目标检测问题转变为回归问题的yolo(you only look once)单阶段目标检测网络。同时归功于该领域内的许多重要发明,如dropout、batch normalization等方法的出现,确定性神经网络在目标检测问题上表现出了优异的预测精度和查全率。
3.在拥有庞大且类型丰富的训练样本的基础上,遵循一系列相关经验准则和规律,确定性神经网络可以学习到各类别物品所具备特征的基本规律并表现出优异的能力。但需要注意的是,现有的多数确定性神经网络针对训练范围内的目标,其检测效果良好,可一旦出现训练范围外的目标,确定性神经网络所表现出来的效果多不尽如人意。另一方面,面对干扰较为严重的图像数据,确定性神经网络会对其产生的错误结果表现出极高的肯定性,而不会对该结果进行一个置信度评估,对使用者的后续决策具有严重的误导作用。
4.在确定性神经网络的设计过程中有一条黄金准则,即使用softmax函数,将输出层连续激活函数的输出数值转变为对应的类别概率。该举措可以保证类别的可分性外,还可体现出不同类别之间的关系比较。同时利用交叉熵损失函数,可以快速高效地优化神经网络参数。但不足的是,交叉熵损失无法推断预测分布的方差;同时,softmax函数还会夸大神经网络输出层某个预测类别的概率。根据上述原因,确定性神经网络给出的结果大多缺少整体可信度评估。
5.针对上述的多种问题,确定性神经网络无法给出一个具备可信度评估的结果,因此有必要发明一种融合主观逻辑并进行不确定性分布建模的可信目标检测方法。
技术实现要素:
6.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种融合主观逻辑和不确定性分布建模的可信目标检测方法。
7.为了解决上述技术问题,本发明公开了一种融合主观逻辑和不确定性分布建模的可信目标检测方法,包括如下步骤。
8.步骤1,采集图像数据,对所述图像数据进行预处理,对预处理后的图像进行目标标注,构建第一数据集。
9.步骤2,构建可信目标检测模型。
10.步骤3,训练所述可信目标检测模型,获得训练后的可信目标检测模型。
11.步骤4,将第一数据集中的测试图像输入训练后的可信目标检测模型,获得图像中各个目标定位信息、目标类别识别结果和目标类别识别结果的整体可信度评估结果。
12.进一步的,步骤2中所述可信目标检测模型包括aspp-yolov5目标检测模型,并在aspp-yolov5目标检测模型的输出层融入主观逻辑和狄利克雷分布,完成不确定性分布建模。
13.进一步的,步骤2中所述aspp-yolov5目标检测模型依次包括yolov5目标检测模型中的骨干网络、aspp(atrous spatial pyramid pooling,空洞空间金字塔池化)网络和yolov5目标检测模型中的融合网络,第一数据集中的训练图像输入骨干网络,骨干网络输出训练图像的第一特征图像;第一特征图像输入aspp网络,aspp网络输出训练图像的第二特征图像;第二特征图像输入融合网络,融合网络输出维数为s
×s×
(b*(5 k))的特征向量,其中s表示将aspp-yolov5目标检测模型的输入图像分割为s
×
s的网格,b表示一个网格中预测框的数量,k表示目标类别的数量;每个预测框包括预测框边界信息、预测框置信度和对目标类别的预测结果,所述预测框边界信息包括4位:预测框的中心点坐标x和y、该预测框的宽度w和高度h;所述预测框包含物体的概率pr(object)占1位;对目标类别的预测结果包括k位,即各类别在预测框置信度c下的条件概率pr(classk|c),k表示目标类别索引,1 ≤ k ≤k;预测框置信度,表示目标预测框predictbox与标注框groundtruth的交并比。
14.计算各类别概率。
15.进一步的,步骤2中在aspp-yolov5目标检测模型的输出层融入主观逻辑和狄利克雷分布,包括将所述由维数为s
×s×
(b*(5 k))的特征向量计算得到的每个预测框中各类别概率pr(classk)作为主观证据ek,并与狄利克雷参数联立,获得狄利克雷参数αk、各类别的信念质量bk和整体的不确定质量u,各参数表达式如下。
16.α
k = e
k 1b
k = (αkꢀ‑ꢀ
1) / s
dirichlet
u = k / s
dirichlet
上述表达式中,s
dirichlet
为狄利克雷强度,s
dirichlet
数值大小为狄利克雷参数αk的和,同时各类别的信念质量bk和整体的不确定质量u非负,且和为1,表示为。
17.进一步的,步骤2中aspp网络包括5个网络层和1个由拼接层与卷积核大小1*1的卷积网络所构建的网络,所述5个网络层分别为卷积核大小1*1的卷积网络、3个卷积核大小3*3,膨胀率分别为1、3、5的空洞卷积网络以及一个全局平均池化层,第一特征图像分别经过所述5个网络层,将所述5个网络层的输出结果拼接后,再经过一个卷积核大小1*1的卷积网络,输出第二特征图像。
18.aspp-yolov5目标检测模型包括三个尺度层面的网格图,三个层面的网格图分别用于预测大目标、中等目标和小目标,每个网格包括b个不同大小的预测框用于预测不同长宽比的目标;预先设定的各个预测框尺寸采用k-means聚类算法,以第一数据集中目标边界
框和聚类中心预测边界框的重合度作为聚类距离基准,选取3*b个聚类中心的目标边界框尺寸。其中,第一数据集中目标边界框和聚类中心预测边界框的重合度为训练样本目标边界框与聚类中心目标边界框的交并比。
19.进一步的,步骤3中训练所述可信目标检测模型包括如下步骤。
20.步骤3-1,良好的初始化模型参数,对于模型的训练、收敛十分重要,采用迁移学习算法,使用imagenet数据集中和所述第一数据集中目标类别一致的图像数据,对aspp-yolov5目标检测模型骨干网络所构成的分类模型进行训练,获得初始化模型参数;使用迁移学习算法,获得其他数据集中图像的知识,然后用于下游目标识别,能够取得较好的识别效果。
21.步骤3-2,将所述初始化模型参数作为所述可信目标检测模型中骨干网络的初始化参数,使用所述第一数据集中的训练图像对所述可信目标检测模型进行训练,获得训练后的可信目标检测模型。
22.进一步的,步骤3-2中对所述可信目标检测模型进行训练依赖于梯度下降算法,损失函数loss包括预测框定位损失l
giou
、预测框置信度损失l
obj
和预测框类别判定损失l
class
,即loss = l
giou l
obj l
class
,其中l
giou
和l
obj
分别为yolov5目标检测模型网络中的预测框的定位损失和预测框置信度损失,两者分别采用广义交并比损失(giou损失)和二元交叉熵损失(bcewithlogits损失)进行计算;由于aspp-yolov5目标检测模型网络引入了狄利克雷分布,原有yolov5对于预测框类别判定的损失函数不再适用,故预测框类别判定损失l
class
使用狄利克雷分布作为多项式似然的先验概率,并通过对类别概率积分取得边际似然的负对数作为类别预测损失函数,同时加入kl正则化项,对所述可信目标检测模型的类别预测加以约束。
23.利用定义好的损失函数loss,基于第一数据集中的训练图像训练所述可信目标检测模型的参数,直到损失函数loss收敛,获得训练好的不确定性分布建模的可信目标检测模型。
24.进一步的,预测框类别判定损失l
class
表示为该式中,s2和b分别代表特征图中对应的网格数和网格中预测框数目;表示第i个网格中的第j个预测框是否用于预测目标,0 ≤ i ≤ s
2-1,0 ≤ j ≤ b-1;挑出目标标注边界框中心所在的网格所包含的预测框,选取其中与标注的目标边界框交并比最大的预测框用于预测目标,置1,否则置0;λ
t = min(1.0, t/10)∈[0,1]是退火系数,t是当前训练周期的代数(epoch数);l
i,j
(α
i,j
)表示第i个网格中第j个预测框各类别预测损失,定义为对类别概率积分取得边际似然的负对数,表达式如下所示。
[0025]
该式中,y
i,j,k
为独热向量,该向量中有且只有一个元素即目标类别一项为1,其余元素为0,是真实边界框的类别标签;p
i,j,k
表示所述可信目标检测模型预测获得的第i个网格第j个预测框信息中的各类别信念质量,p
i,j
表示第i个网格第j个预测框整体的类别信念质量;β(
·
)表示k维贝塔多项式函数;s
i,j
表示第i个网格第j个预测框的狄利克雷强度,α
i,j,k
表示第i个网格第j个预测框第k个类别的狄利克雷参数,α
i,j
=[α
i,j,1
,α
i,j,2
,
…
,α
i,j,k
]。
[0026]
表示kl正则化项,表达式如下。
[0027][0027]
是去除非误导性证据后的狄利克雷参数;γ(
·
)是伽玛函数;ψ(
·
)是双伽马函数。
[0028]
进一步的,步骤4包括:将第一数据集中的测试图像输入训练后的可信目标检测模型,设置阈值iou
thres
和pr(class)
thres
,筛选出符合要求的预测框信息;再采用非极大值抑制的方法,去冗余的预测框,保留合适的预测框;最后,取出筛选后的各个预测框信息,将其中目标定位信息、目标类别识别结果以及目标类别识别结果的整体可信度评估结果作为最终的目标检测结果输出,其中目标定位信息包括目标预测框边界信息,目标类别识别结果包括目标所属的类别和最大类别信念概率,目标类别识别结果的整体可信度评估结果包括整体的不确定质量。
[0029]
进一步的,步骤1中对所述图像数据进行预处理包括采用mosaic数据增强将两张或更多的图像以随机缩放、随机裁剪、随机排布的方式进行拼接,获得一张新的图像,再将所述新的图像进行图像几何变换,获得预处理后的图像。
[0030]
构建第一数据集包括按照8:1:1的比例,对该第一数据集进行分割,获取训练集、验证集和测试集,所述训练集和验证集用于所述可信目标检测模型训练,所述测试集用于对训练后的可信目标检测模型进行测试。
[0031]
有益效果:与现有技术相比,本技术所述可信目标检测方法首先通过修改yolo v5网络结构,将原有的spp(spatial pyramid pooling,空间金字塔池化)网络替换为aspp网络;然后将网络输出的类别概率视为主观证据,并引入狄利克雷分布,进行参数联立,得到所需的狄利克雷参数、各类别的信念质量和整体的不确定质量;再利用迁移学习的方法,使用预训练好的分类模型参数作为所述可信目标检测模型中共有结构的初始化参数;修改损失函数,并基于所构建的第一数据集,对所述可信目标检测模型参数进行微调;最后利用所训练的目标检测模型检测相关图像目标。本发明技术方案的优点有:(1)本发明修改了原有yolov5模型各个网格中预测框的数目与相关预测类别数,通过k-means聚类生成更多大小尺寸的预测框,有效提高了目标捕捉能力,进而提高了模型在目标检测上的查全率。
[0032]
(2)本发明使用aspp网络替换yolov5原有的spp网络,提高了模型在目标检测任务中的查全率。
[0033]
(3)本发明在确定性神经网络的基础上,融合了主观逻辑和狄利克雷分布,进行不确定性建模,从而实现对确定性神经网络输出结果进行一个可信度评估,可为使用者后续决策提供依据。
附图说明
[0034]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0035]
图1是本发明所述的可信目标检测方法中第一数据集构建的流程图。
[0036]
图2是本发明所述的可信目标检测方法中目标检测模型训练的流程图。
[0037]
图3是本发明所述的可信目标检测方法中图像目标检测的流程图。
[0038]
图4是本发明所述的可信目标检测模型的结构框图。
[0039]
图5是k-means聚类算法选取预测框预设尺寸的流程图。
[0040]
图6是本发明所使用的aspp网络的结构示意图。
[0041]
图7是迁移学习过程中预训练的目标分类模型的结构示意图。
[0042]
图8是本发明所述的可信目标检测方法中图像目标检测结果示意图一。
[0043]
图9是本发明所述的可信目标检测方法中图像目标检测结果示意图二。
具体实施方式
[0044]
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。需要说明的是,实施例并不限定本发明要求保护的范围。
[0045]
本实施例提供的图像目标识别方法可以获得一副图像中非固定数量的检测目标的分类预测信息、定位信息和预测结果的整体置信度评估结果,且可以应用到自动驾驶、智慧医疗等方面。
[0046]
本实施例提供的一种融合主观逻辑和不确定性分布建模的可信目标检测方法基于yolov5目标检测模型,修改原有模型结构,并融合主观逻辑和不确定性建模,对图像中的目标进行检测,包括如下步骤。
[0047]
如图1所示,步骤1,采集图像数据,对所述图像数据进行预处理,对预处理后的图像进行目标标注,构建第一数据集。
[0048]
采集可信目标检测模型检测目标所属类别的图像数据,先采用mosaic数据增强技术,使用随机缩放、随机裁剪、随机排布的方式,将多张图像合成出一张新的图像。再使用几何变换等其他数据增广方式对数据进行处理,包括将训练图像随机进行水平位移t
x
和垂直位移ty,目标位移距离大小t
x
和ty的范围在(-width/4,-width/4)和(-height/4,-height/4)之间,width表示对应图像的宽度,height表示对应图像的高度;将训练图像按其中心点位置进行随机逆时针旋转变换,旋转角度变化范围为(-π, π);对训练图像中小样本目标图像进行重复采样;最后将图像大小按比例缩放至608*608像素大小。
[0049]
将经过数据增广后的图像数据集中的图像进行标注,标注各个预测目标的实际边界框位置和大小,以及各个目标所属的类别;同时按一定比例(8:1:1)划分图像数据集,构建目标检测网络所需的训练集、验证集和测试集。所述训练集和验证集用于可信目标检测模型训练,所述测试集用于对训练后的可信目标检测模型进行测试。
[0050]
步骤2,构建可信目标检测模型。
[0051]
所述可信目标检测模型包括aspp-yolov5目标检测模型,并在aspp-yolov5目标检测模型的输出层融入主观逻辑和狄利克雷分布,完成不确定性分布建模。
[0052]
如图4所示,所述aspp-yolov5目标检测模型依次包括yolov5目标检测模型中的骨
干网络、aspp网络和yolov5目标检测模型中的融合网络,第一数据集中的训练图像输入骨干网络,骨干网络输出训练图像的第一特征图像;第一特征图像输入aspp网络,aspp网络输出训练图像的第二特征图像;第二特征图像输入融合网络,融合网络输出维数为s
×s×
(b*(5 k))的特征向量,其中s表示将aspp-yolov5目标检测模型的输入图像分割为s
×
s的网格,b表示一个网格中预测框的数量,k表示目标类别的数量。
[0053]
本实施例所述可信目标检测方法将图像分割为3个不同尺度层面的网格图,三个层面的网格图分别用于预测不同大小尺寸的目标,即大目标、中等目标和小目标,对应的网格划分密度分别为19*19、38*38和76*76,即三个层面对应的s分别为19、39和76;每个网格中又划分b=6个不同大小预测框用于预测不同长宽比的目标,各个预测框的初始尺寸大小使用聚类方法得到,即使用k-means聚类方法,以所构建图像数据集中目标边界框与聚类中心目标边界框的重合度作为聚类距离指标,将所有数据样本中的目标边界框分为大中小三个大类,每类又细分为6个不同尺寸的聚类,取这18个聚类中心的目标边界框尺寸作为模型对应预测框的初始尺寸,具体流程如图5所示,首先随机选取18个第一数据集中目标边界框的大小初始化各个聚类中心,再按照目标边界框与聚类中心边界框的交并比,将各边界框分配给交并比最大的聚类中心,最后再计算边界框与其对应聚类中心的交并比的均方差,重新修改聚类中心边界框尺寸,并重新分配第一数据集中的目标边界框所属聚类中心,直至交并比的均方差收敛;交并比的均方差loss
k-means
具体公式如下。
[0054]
其中,n代表第一数据集中目标边界框的数量,代表目标边界框与其对应聚类中心的交并比。每个预测框包含3大类信息,即预测框边界信息(4位,包括预测框的中心点坐标x和y、该预测框的宽度w和高度h)、预测框包含物体的概率pr(object)(1位)和k=20类预测类别信息(20位),即各类别在预测框置信度c下的条件概率pr(classk|c),k表示目标类别索引,1 ≤ k ≤k;最终目标检测网络输出特征向量维数为:19*19*6*(4 1 20),38*38*6*(4 1 20)和76*76*6*(4 1 20)。
[0055]
预测框置信度c由该预测框含有物体的概率pr(object)和预测框的准确度两部分相乘得到,即其中是目标预测框predictbox与标注框groundtruth的交并比,具体公式如下。
[0056]
计算各类别概率。
[0057]
使用aspp网络替换原有yolov5模型中的spp网络。spp网络将输入的特征图通过多个不同尺寸的池化层,将所得到的各个结果进行合并,得到固定长度的输出。使用spp网络在不影响网络训练的情况下,可以处理不同纵横比和不同尺寸的输入图像,提高了图像的尺度不变并降低了过拟合。虽然spp网络可以提取输入特征图不同感受野的信息,但没有充
分体现全局信息和局部信息的关系。本实施例中aspp-yolov5目标检测模型通过使用aspp网络,将原网络中空间金字塔改进为空洞空间金字塔,构建aspp-yolov5检测模型。通过使用不同扩张率的空洞卷积实现原有spp网络池化操作,并将其结果与全局平均池化并联,在增大感受野的同时有效融合多尺度的上下文信息,防止小目标特征在信息传递时丢失。增强了模型对目标尺度变化的鲁棒性,提高模型在目标检测上的查全率。
[0058]
本实施例中,aspp网络具体结构如图6所示,该aspp网络将输入的特征图同时输出到5个不同的网络中,第一个网络是一个卷积核为1*1的卷积网络,用于保持原始感受野;第2个至第4个网络分别为扩张率为1、3、5,但卷积核大小均为3*3的空洞卷积网络,且包含bn层(batch normalization),用于特征提取,获得不同尺度的感受野,目的是为了在后续操作中,使特征图可以融合不同尺度的信息;第5个网络是将输入的特征图进行全局平均池化操作后,获取全局特征;最后将各网络输出特征拼接,经过1*1卷积和归一化处理后,将结果输出给融合网络完成上采样等操作。
[0059]
所述可信目标检测模型网络融合了主观逻辑和不确定性建模,将aspp-yolov5输出的3个不同尺度的特征向量中,各预测框的类别预测信息pr(classk)作为主观证据ek,并将其与狄利克雷分布的参数进行联立。因此,所述可信目标检测模型网络除获取不同层面的特征向量外,还可以得到对应数据所相关联的狄利克雷参数αk、各类别的信念质量bk和整体的不确定质量u,各参数可表示为α
k = e
k 1b
k = (αkꢀ‑ꢀ
1) / s
dirichlet
u = k / s
dirichlet
上述表达式中,k为目标类别预测中的所有类别数目,s
dirichlet
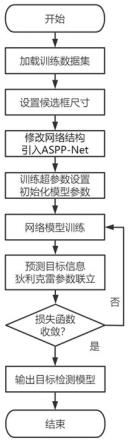
为狄利克雷强度,其数值大小为狄利克雷参数αk的和。同时各类别的信念质量bk和整体的不确定质量u非负,且和为1,可表示为步骤3,训练所述可信目标检测模型,获得训练后的可信目标检测模型,训练过程如图2所示。
[0060]
步骤3-1,良好的初始化模型参数,对于模型的训练、收敛十分重要,因此采用迁移学习的方法。使用imagenet数据集中和所述第一数据集中目标类别一致的图像数据,对aspp-yolov5目标检测模型骨干网络所构成的分类模型进行预训练,获得初始化模型参数。aspp-yolov5目标检测模型骨干网络所构成的分类模型结构如图7所示。
[0061]
步骤3-2,将所述初始化模型参数作为所述可信目标检测模型中骨干网络的初始化参数,使用所述第一数据集中的训练图像对所述可信目标检测模型进行训练,获得训练后的可信目标检测模型。
[0062]
步骤3-2中对所述可信目标检测模型的训练依赖于梯度下降算法,因此需要选择一个合适的损失函数loss作为该模型训练的评判指标,该损失函数loss具体由三部分组成,即预测框定位损失l
giou
、预测框置信度损失l
obj
和预测框类别判定损失l
class
,损失函数可以表示为loss = l
giou l
obj l
class
其中l
giou
和l
obj
分别为原有yolov5模型中的预测框定位损失和预测框置信度损失,两者分别采用广义交并比损失giou损失和二元交叉熵损失bcewithlogits损失进行计算,不作修改。
[0063]
由于网络引入了狄利克雷分布,原有yolov5对预测框类别判定的损失函数不再适用,需修改损失函数。针对预测框类别判定损失l
class
,使用狄利克雷分作为多项式似然的先验概率,并通过对类别概率积分取得边际似然的负对数作为类别预测损失函数,同时加入kl正则化项,对所述可信目标检测模型的类别预测加以约束,预测框类别判定损失函数l
class
可表示为该式中,s2和b分别代表特征图中对应的网格数和网格中预测框数目;表示第i个网格中的第j个预测框是否用于预测目标,挑出目标标注边界框中心所在的网格所包含的预测框,选取其中与标注的目标边界框交并比最大的预测框用于预测目标,置1,否则置0;λ
t = min(1.0, t/10)∈[0,1]是退火系数,t是当前训练周期的代数;l
i,j
(α
i,j
)表示第i个网格中第j个预测框各类别预测损失,定义为对类别概率积分取得边际似然的负对数,表达式如下所示。
[0064]
该式中,y
i,j,k
为独热向量,该向量中有且只有一个元素即目标类别一项为1,其余元素为0,是真实边界框的类别标签;p
i,j,k
表示所述可信目标检测模型预测获得的第i个网格第j个预测框信息中的各类别信念质量,p
i,j
表示第i个网格第j个预测框整体的类别信念质量;β(
·
)表示k维贝塔多项式函数;s
i,j
表示第i个网格第j个预测框的狄利克雷强度,α
i,j,k
表示第i个网格第j个预测框第k个类别的狄利克雷参数,α
i,j
=[α
i,j,1
,α
i,j,2
,
…
,α
i,j,k
]。
[0065]
表示kl正则化项,表达式如下。
[0066][0066]
是去除非误导性证据后的狄利克雷参数;γ(
·
)是伽玛函数;ψ(
·
)是双伽马函数。
[0067]
利用重新定义好的损失函数loss反向传播,训练、迭代目标检测网络的参数直到损失函数收敛,获得不确定性分布建模的可信目标检测模型。
[0068]
步骤4,将第一数据集中的测试图像输入训练后的可信目标检测模型,获得图像中各个目标的定位信息、目标类别识别结果以及目标类别识别结果的整体可信度评估结果。
[0069]
如图3所示,将第一数据集中的测试图像输入训练后的aspp-yolov5目标检测模
型,设置阈值iou
thres
和pr(class)
thres
,通过比较预测框与目标标注的检测框重合度是否大于iou
thres
,同时比较该检测框所预测目标的真实类别概率是否大于pr(class)
thres
,如果不符合,则删除对应的检测框,以此筛选出符合要求的预测框信息;再采用非极大值抑制的方法,去冗余的预测框,保留合适的预测框;最后,取出筛选后的各个预测框信息,将其中目标定位信息、目标类别识别结果以及目标类别识别结果的整体可信度评估结果作为最终的目标检测结果输出,其中目标定位信息包括目标预测框边界信息,目标类别识别结果包括目标所属的类别和最大类别信念概率,目标类别识别结果的整体可信度评估结果包括整体的不确定质量。
[0070]
图8和图9是本实施例测试图像目标检测结果示意图,对应的场景分别为一般街景图像与航拍图像,本实施例提供的一种融合主观逻辑和不确定性分布建模的可信目标检测方法会在对图像进行目标检测的同时,还会给出相关结果的不确定性质量(magnitude of uncertainty)。检测框有低不确定性(low-level)、中不确定性(mid-level)和高不确定性(high-level)三种,其中低不确定性代表网络检测给出的目标类别识别结果的不确定性小于10%;中不确定性则是该数值大于10%且小于30%;而高不确定性则代表较大的不确定性,且数值高于30%。同时对于检测信息输出,其显示的信息量也会根据检测框的大小有所调整。如较大的检测框不仅仅会输出目标的类别信息,还会显示该类别的概率和评估的不确定性大小;而对于较小的目标,只输出网络预测出的目标所属类别。
[0071]
具体实现中,本技术提供计算机存储介质以及对应的数据处理单元,其中,该计算机存储介质能够存储计算机程序,所述计算机程序通过数据处理单元执行时可运行本发明提供的一种融合主观逻辑和不确定性分布建模的可信目标检测方法的发明内容以及各实施例中的部分或全部步骤。所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random access memory,ram)等。
[0072]
本领域的技术人员可以清楚地了解到本发明实施例中的技术方案可借助计算机程序以及其对应的通用硬件平台的方式来实现。基于这样的理解,本发明实施例中的技术方案本质上或者说对现有技术做出贡献的部分可以以计算机程序即软件产品的形式体现出来,该计算机程序软件产品可以存储在存储介质中,包括若干指令用以使得一台包含数据处理单元的设备(可以是个人计算机,服务器,单片机,muu或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
[0073]
本发明提供了一种融合主观逻辑和不确定性分布建模的可信目标检测方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。