用于提高植物籽粒产量的组合物和方法
1.以电子方式递交的序列表的引用
2.该序列表的官方副本经由efs-web作为ascii格式的序列表以电子方式递交,文件名为“rts16139e_st25.txt”,创建于2019年11月25日,且具有120千字节大小,并与本说明书同时提交。包含在此ascii格式的文件中的序列表是本说明书的一部分并且通过援引以其全文并入本文。
技术领域
3.本公开涉及用于提高植物产量的组合物和方法。
背景技术:
4.全球对农作物的需求和消费正在迅速增长。因此,需要开发新的组合物和方法以增加植物产量。本发明提供此类组合物和方法。
技术实现要素:
5.本文提供了编码包含氨基酸序列的bg1多肽的多核苷酸,该氨基酸序列与选自由以下组成的组的氨基酸序列具有至少90%同一性:seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55。
6.还提供了重组dna构建体,其包含可操作地连接到多核苷酸的调节元件,该多核苷酸编码包含氨基酸序列的bg1多肽,该氨基酸序列与选自由以下组成的组的氨基酸序列具有至少90%同一性:seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55。在某些实施例中,调节元件是异源启动子。
7.提供了植物细胞、植物和种子,其包含编码bg1多肽的多核苷酸或重组dna构建体,该重组dna构建体包含可操作地连接到编码bg1多肽的多核苷酸的调节元件。在某些实施例中,调节元件是异源启动子。在某些实施例中,植物和/或种子来自单子叶植物。在某些实施例中,植物是单子叶植物。在某些实施例中,单子叶植物是玉蜀黍。
8.提供了用于通过在可再生植物细胞中表达重组dna构建体并产生该植物来增加植物中bg1活性的方法,该重组dna构建体包含可操作地连接到多核苷酸的调节元件,该多核苷酸编码包含氨基酸序列的bg1多肽,该氨基酸序列与选自由以下组成的组的氨基酸序列具有至少90%同一性:seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55的氨基酸序列,其中该植物在其基因组中包含该重组dna构建体。在某些实施例中,调节元件是异源启动子。在某些实施例中,植物是单子叶植物。在某些实施例中,单子叶植物是玉蜀黍。
9.提供了用于通过在可再生植物细胞中表达重组dna构建体并产生该植物来改善植物耐旱性或养分利用率的方法,该重组dna构建体包含可操作地连接到多核苷酸的调节元件,该多核苷酸编码包含氨基酸序列的bg1多肽,该氨基酸序列与选自由以下组成的组的氨基酸序列具有至少90%同一性:seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、
31、33、35、41、43、45、47、49、51、53和55的氨基酸序列,其中该植物在其基因组中包含该重组dna构建体。在某些实施例中,调节元件是异源启动子。在某些实施例中,植物是单子叶植物。在某些实施例中,单子叶植物是玉蜀黍。
附图说明
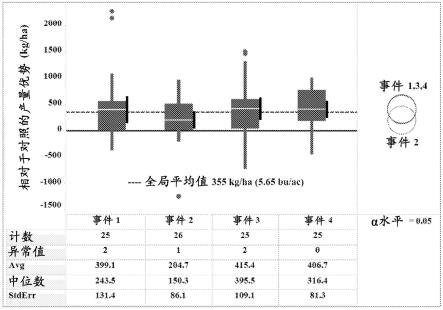
10.图1示出了zm-bg1h1 oe事件相比于对照无效的产量优势。两年测试中,4个转基因事件中的每一个的相对于无效非转基因杂交对照的杂交玉蜀黍产量差异(kg/ha)的箱线图。非转基因杂交对照平均产量值设为0轴。所有四个等位基因的平均产量优势为图中355kg/ha或5.65bu/ac处的中央虚线。每个事件的平均值(每个框内的白线),95%置信区间(附在每个框右侧的黑色垂直段),以及以上或以下的离群值(圆)。在0.05的α水平下,未拒绝显著性无效假设检验(即4个事件无差异),由右侧重叠环图表示。
11.图2示出了产量范围环境下相比于对照的产量。101个测试(包含每个测试年份和位置的4个独立的zm-bg1h1 oe事件)中的每一个的相对于无效非转基因杂交对照(在y轴上设为0)的杂交玉蜀黍产量差异(kg/ha)(y轴)。每个测试位置上的非转基因杂交对照产量平均值(t/ha)(x轴)。低于11.2t/ha的低产位点为中度胁迫(ms),11.2-14.4t/ha为轻度胁迫(ls),高于14.4t/ha为最佳(opt),这些划分由图底部的垂直虚线和标记标出。图中355kg/ha处的平均产量优势为虚线,1.0t/ha的参考线也是虚线。blup显著性检验按以下着色:蓝色,正显著(p<0.1);橘色,负显著(p<0.1);中度灰,正不显著;浅灰,负不显著。图标形状:事件1,菱形;事件2,圆形;事件3,星形;事件4,十字形。
12.图3是与zm-bg1h1 oe产量优势相关的次级农艺性状的图示。与zm-bg1h1过表达玉蜀黍植物中的产量优势相关的14个次级性状。参见性状定义的方法。次级性状按类别分组着色:冠层或绿度(绿色);开花(橘色);植物大小(深灰)、水分(蓝色)、产量(褐红色)。所有性状值都是所有四个事件的平均值,并将每一个都转换为与性状无效平均值的百分比差异(y轴)。将所有性状百分比差异相对于可用田间位置和年份的产量百分比差异线性回归(每个性状最多可达101次测量)。相关性的斜率体现在x轴上。回归的r2是图标大小。因此,2.4%的整体产量差异与其自身相关,其中斜率为1.0并且图标大小单位大小的最大值为1.0。
13.图4展示相对于对照,zm-bg1h1 oe的穗和仁(kernel)性状分析结果。将所有性状归一化,以比较所有四个事件中的所有植物与对照平均值的平均百分比差异。标准误差条根据与对照平均值的相应个体植物百分比差异得出。t检验显著性通过比较所有4个事件中所有个体植物的对照平均值的一组百分比差异与个体对照植物与对照平均值之间的一组百分比差异进行。
14.图5显示zm-bg1h1 oe增加仁行数。四个事件与对照的krn的直方图分布。绘制出每个事件或对照无效的所有植物的百分比。注意,在所有四个zm-bg1h1 oe事件中,krn从krn16相对转移到krn18,但在对照组中下降。
15.图6在416个近交系中,每个zm-bg1h1等位基因在v6温室生长叶中的平均叶表达。通过高分辨率遗传标记分析推断出单倍型等位基因组,并且然后使用选择的近交系zm-bg1h1基因序列(包括产生参考等位基因序列的五个近交系)将每个单倍型分为五个等位基因。展示了每个单倍型组的平均基因表达水平。(由于遗传标记分辨率不明确,在此合并单
倍型a1和a2)。每个条的标准误差条须。图中的水平线是组合组中所有测量值的全局平均值(实线)和stdev(上下虚线)。这些等位基因单倍型的表达没有明显的实质性差异。
16.图7提供了杂交亲本种子大小(体积、重量和密度)的结果。对照无效和四个事件中平均每个的200个仁体积(ml)、重量(g)和密度(g/ml)。条是标准误差须下的平均值。图中的横条是所有4个事件和无效的总体平均值和标准偏差。
17.图8显示相同krn值下的穗和仁差异。归一化krn值时的穗和仁的性状值。因此,针对相同的krn值进行与对照无效的所有比较,并且然后将所有此类比较的百分比差异取平均值(灰色条),并与所有比较的等效性状百分比差值(所有合计(未归一化)krn值(黑色条))并列。
18.图9显示五个krn值的zm-bg1h1 oe所有事件植物(黑色条)相对于对照无效(灰色条)的平均穗直径。提供se条。
19.序列表简述
20.从形成本技术的一部分的以下详细说明和所附序列表中可以更全面地理解本公开。这些序列描述以及所附序列表遵守如37 c.f.r.
§§
1.821和1.825所列出的管理专利申请中核苷酸和氨基酸序列公开内容的规则。这些序列描述包含如在37 c.f.r.
§§
1.821和1.825中所定义的用于氨基酸的三字母代码,将其通过援引并入本文。
21.表1:序列表说明(prt-蛋白质/多肽)
22.23.24.25.具体实施方式
26.i.组合物
27.a.bg1多核苷酸和多肽
28.本公开提供编码bg1多肽的多核苷酸。玉蜀黍bg1多肽包含独特的植物特定基因家族。bg1蛋白质家族分析描述了具有富含谷氨酸和天冬氨酸重复但无有序的结构倾向的n-末端区域和与其他特征功能结构域没有显著相似性的保守c-末端区域的蛋白质基因家族。如本文使用的,玉蜀黍bg1“多肽”、“蛋白质”等,是指具有与其他bg1相关蛋白质相似的结构域结构的蛋白质,其由seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25或与前述序列中
的一个具有至少90%-100%同一性的序列的通式结构表示。
29.本公开的一个方面提供编码包含氨基酸序列的bg1多肽的多核苷酸,该氨基酸序列与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55中的任一个的氨基酸序列具有至少90%同一性。在某些实施例中,编码bg1多肽的多核苷酸包含与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55中的任一个的氨基酸序列具有至少95%同一性的氨基酸序列。
30.如本文使用的,关于指定核酸的“编码”(“encoding”、“encoded”等)意指包含用于翻译成指定蛋白质的信息。编码蛋白质的核酸在该核酸的翻译区之内可以包含非翻译序列(例如,内含子)或可能缺乏此类插入的非翻译序列(例如,在cdna中)。通过密码子使用来详细说明用来编码蛋白质的信息。典型地,氨基酸序列通过使用“通用”遗传密码的核酸来编码。然而,当核酸使用以下这些生物体表达时,可以使用通用密码的变体,诸如存在于一些植物、动物、和真菌线粒体、细菌山羊支原体(mycoplasma capricolum)(yamao等人,(1985)proc.natl.acad.sci.usa[美国科学院院报]82:2306-9)或纤毛虫大核中的通用密码变体。
[0031]
当合成地制备或改变核酸时,可以利用要表达核酸的预期宿主的已知密码子偏好性。例如,虽然在单子叶和双子叶植物物种中均可以表达本发明的核酸序列,但是可以修饰序列,以解释单子叶植物或双子叶植物的特定密码子偏好和gc含量偏好,因为这些偏好已经表现出了差异(murray等人(1989)nucleic acids res.[核酸研究]17:477-98)。
[0032]
如本文使用的,“多核苷酸”包括提及具有天然核糖核苷酸的基本性质的脱氧核糖多核苷酸、核糖多核苷酸、或其类似物,因为在严格的杂交条件下,它们与和天然存在的核苷酸基本上相同的核苷酸序列杂交和/或允许翻译成与一个或多个天然存在的核苷酸相同的一个或多个氨基酸。多核苷酸可以是结构基因或调控基因的全长或子序列。除非另外指明,否则该术语包括提及指定序列以及其互补序列。因此,出于稳定性或其他原因而具有经修饰的主链的dna或rna是“多核苷酸”,如该术语在本文中所意指的。此外,仅举两个例子,包含稀有碱基(诸如肌苷)或修饰的碱基(诸如三苯甲基化的碱基)的dna或rna是多核苷酸,如该术语在本文中所使用的。应当理解,已经对dna和rna进行了多种修饰,这些修饰具有本领域技术人员已知的许多有用目的。如本文采用的术语多核苷酸涵盖诸如多核苷酸的化学修饰形式、酶修饰形式或代谢修饰形式,以及病毒和细胞(尤其包括简单和复杂细胞)所特有的dna和rna的化学形式。
[0033]
术语“多肽”、“肽”以及“蛋白质”在本文中可互换使用,是指氨基酸残基的聚合物。这些术语适用于其中一个或多个氨基酸残基是相应的天然存在的氨基酸的人工化学类似物的氨基酸聚合物,以及适用于天然存在的氨基酸聚合物。
[0034]
如本文使用的,在两个核酸或多肽序列的上下文中的“序列同一性”或“同一性”包括,当在指定比较窗口上对齐最大对应性时,提及两个序列中的相同残基。当使用关于蛋白质的序列同一性百分比时,认识到不相同的残基位置通常相差保守氨基酸取代,其中氨基酸残基被具有相似化学性质(例如电荷或疏水性)的其他氨基酸残基取代,并且因此不改变分子的功能性质。当序列在保守取代方面不同时,可以向上调节序列同一性百分比,以校正该取代的保守性质。相差此类保守取代的序列被称为具有“序列相似性”或“相似性”。用于进行此调节的方法是本领域技术人员所熟知的。典型地,这涉及作为部分而不是完全错配对保守取代打分,从而提高百分比序列同一性。因此,例如,当相同的氨基酸得分为1,并且
protocols in molecular biology[分子生物学实验指南],第19章,ausubel等人编辑,greene publishing and wiley-interscience[格林出版与威利交叉科学出版社],纽约(1995)。
[0039]
gap使用上文的needleman和wunsch的算法来找到使匹配数目最大化并且使空位数目最小化的两个完整序列的对齐。gap考虑所有可能的对齐和空位位置,并且产生具有最大匹配碱基数量和最少空位的对齐。它允许以匹配碱基单位提供空位产生罚分和空位延伸罚分。gap必须为它插入的每个空位获取空位产生罚分匹配数目的收益。如果选择大于零的空位延伸罚分,gap必须另外地为每个所插入空位获取空位长度乘以空位延伸罚分的收益。在wisconsin genetics software的版本10中,默认空位产生罚分值和空位延伸罚分值分别为8和2。空位产生罚分和空位延伸罚分可以表示为选自由0至100组成的整数组的整数。因此,例如,空位产生罚分和空位延伸罚分可以为0、1、2、3、4、5、6、7、8、9、10、15、20、30、40、50或更大。
[0040]
gap代表最佳对齐家族的一个成员。可以存在此家族的许多成员,但是其他成员没有更好的品质。gap展示出用于对齐的四个性能因数:质量、比率、同一性和相似性。为了对齐序列,质量是最大化的度量。比率是质量除以更短区段中的碱基数。同一性百分比是实际匹配的符号的百分比。相似性百分比是相似符号的百分比。空位对面的符号被忽略。当一对符号的评分矩阵值大于或等于相似性阈值0.50时,相似性得分。wisconsin genetics software 的版本10中使用的评分矩阵为blosum62(参见henikoff和henikoff,(1989)proc.natl.acad.sci.usa[美国科学院院报]89:10915)。
[0041]
除非另外说明,否则本文提供的序列同一性/相似性值是指使用blast 2.0程序包、使用默认参数获得的值(altschul等人,(1997)nucleic acids res.[核酸研究]25:3389-402)。
[0042]
如本领域技术人员将理解,blast搜索假设蛋白质可被建模为随机序列。然而,许多真实蛋白质包含非随机序列的区域,其可是同聚序列段(homopolymeric tracts)、短周期重复序列、或富含一种或多种氨基酸的区域。即使蛋白质的其他区域完全不同,这种低复杂性的区域也可在不相关蛋白质之间对齐。许多低复杂性滤波器程序可用来减少此类低复杂性比对。例如,可单独使用或组合使用seg(wooten和federhen,(1993)comput.chem.[计算机化学]17:149-63)和xnu(claverie和states,(1993)comput.chem.[计算机化学]17:191-201)低复杂性滤波器。
[0043]
因此,在本文所述的任何实施例中,bg1多核苷酸可编码与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55中的任一个具有至少80%同一性的bg1多肽。例如,bg1多核苷酸可编码与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55中的任一个的氨基酸序列具有至少81%同一性、至少82%同一性、至少83%同一性、至少84%同一性、至少85%同一性、至少86%同一性、至少87%同一性、至少88%同一性、至少89%同一性、至少90%同一性、至少91%同一性、至少92%同一性、至少93%同一性、至少94%同一性、至少95%同一性、至少96%同一性、至少97%同一性、至少98%同一性或至少99%同一性的bg1多肽。
[0044]
b.重组dna构建体
[0045]
还提供了包含本文所述的任何bg1多核苷酸的重组dna构建体。在某些实施例中,
重组dna构建体进一步包含至少一种调节元件。在某些实施例中,重组dna构建体的至少一种调节元件包含启动子。在某些实施例中,启动子是异源启动子。
[0046]
如本文使用的,“重组dna构建体”包含两个或更多个可操作地连接的dna区段,优选在自然界中不可操作地连接(即,异源)的dna区段。重组dna构建体的非限制性实例包括与异源序列(也称为调节元件)可操作地连接的目的多核苷酸,这些异源序列有助于目的序列的表达、自主复制和/或基因组插入。此类调节元件包括例如启动子、终止序列、增强子等,或表达盒的任何组分;质粒、粘粒、病毒、自主复制序列、噬菌体、或线性或环状单链或双链dna或rna核苷酸序列;和/或编码异源多肽的序列。
[0047]
可以提供本文所述的bg1多核苷酸,以在目的植物或任何目的生物体中表达。盒可以包括可操作地连接到bg1多核苷酸的5
′
和3
′
调节序列。“可操作地连接”旨在意指两个或更多个元件之间的功能性连接。例如,目的多核苷酸和调节序列(例如,启动子)之间的可操作连接是允许目的多核苷酸表达的功能性连接。可操作地连接的元件可以是连续的或非连续的。当用于指两个蛋白质编码区的连接时,可操作地连接意指这些编码区处于相同的阅读框中。盒可以额外含有至少一个待共转化到生物体中的额外的基因。可替代地,一个或多个额外的基因可以在多个表达盒上提供。此类表达盒装备有多个限制性位点和/或重组位点,用于将bg1多核苷酸插入到调节区的转录调节之下。表达盒可额外含有可选择标记基因。
[0048]
表达盒以5
′‑3’
转录的方向包括转录和翻译起始区(例如,启动子)、bg1多核苷酸、和在植物中起作用的转录和翻译终止区(例如,终止区)。调节区(例如,启动子、转录调节区、和翻译终止区)和/或bg1多核苷酸对于宿主细胞而言或彼此之间可以是天然的/类似的。可替代地,调节区和/或bg1多核苷酸对于宿主细胞或彼此之间可以是异源的。
[0049]
如本文使用的,关于序列的“异源性”是指该序列源于外来物种,或者,如果源于相同物种的话,则是通过蓄意人为干预从其在组合物和/或基因组基因座中的天然形式进行实质性修饰得到的序列。例如,可操作地连接到异源多核苷酸的启动子来自与从其衍生该多核苷酸的物种不同的物种,或者,如果来自相同/类似的物种,那么一方或双方基本上由它们的原来形式和/或基因组基因座修饰得到,或者该启动子不是可操作地连接到多核苷酸的天然启动子。
[0050]
终止区对于转录起始区、对于植物宿主而言可是天然的,或可衍生自对于启动子、bg1多核苷酸、植物宿主、或其任何组合而言的另一种来源(即外源的或异源的)。
[0051]
表达盒可以额外含有5
′
前导序列。此类前导序列可以起到增强翻译的作用。翻译前导子在本领域是已知的并且包括病毒翻译前导序列。
[0052]
在制备表达盒时,可以操作各种dna片段,以提供处于适当取向以及合适时,处于适当阅读框中的dna序列。为此,可采用衔接子(adapter)或接头以连接dna片段,或可以涉及其他操作以提供方便的限制位点、移除多余的dna、移除限制位点等。出于这个目的,可以涉及体外诱变、引物修复、限制性酶切(restriction)、退火、再取代(例如转换和颠换)。
[0053]
如本文使用的,“启动子”指dna的在转录开始的上游并参与rna聚合酶以及其他蛋白质的识别和结合以启动转录的区域。“植物启动子”是能够在植物细胞中启动转录的启动子。示例性植物启动子包括但不局限于从植物、植物病毒以及包含在植物细胞中表达的基因的细菌(如农杆菌属(agrobacterium)或根瘤菌属(rhizobium))获得的那些启动子。某些
启动子类型优先在某些组织(诸如叶、根、种子、纤维、木质部导管、管胞或厚壁组织)中启动转录。此类启动子被称为“组织偏好的”。“细胞类型”特异性启动子主要驱动在一个或多个器官中的某些细胞类型(例如,根或叶中的维管细胞)中的表达。“诱导型”或“调节型”启动子是指在环境控制下的启动子。可通过诱导型启动子影响转录的环境条件的实例包括厌氧条件或光照的存在。另一类型的启动子是发育调节启动子,例如在花粉发育期间驱动表达的启动子。组织偏好性启动子、细胞类型特异性启动子、发育调节启动子、和诱导型启动子构成“非组成型”启动子类别。“组成型”启动子是在大多数环境条件下有活性的启动子。组成型启动子包括,例如rsyn7启动子的核心启动子和其他在wo 99/43838和美国专利号6,072,050中公开的组成型启动子;核心camv 35s启动子(odell等人,(1985)nature[自然]313:810-812);稻肌动蛋白(mcelroy等人,(1990)plant cell[植物细胞]2:163-171);泛素(christensen等人,(1989)plant mol.biol.[植物分子生物学]12:619-632和christensen等人,(1992)plant mol.biol.[植物分子生物学]18:675-689);pemu(last等人(1991)theor.appl.genet.[理论与应用遗传学]81:581-588);mas(velten等人,(1984)embo j.[欧洲分子生物学学会杂志]3:2723-2730);als启动子(美国专利号5,659,026)等。其他组成型启动子包括例如美国专利号5,608,149;5,608,144;5,604,121;5,569,597;5,466,785;5,399,680;5,268,463;5,608,142;和6,177,611。
[0054]
还考虑了包括一种或多种异源调节元件的组合的合成启动子。
[0055]
本发明的重组dna构建体的启动子可以是本领域已知的任何类型或类别的启动子,使得许多启动子中的任一个都可以用来表达本文公开的多种bg1多核苷酸序列,该启动子包括目的多核苷酸序列的天然启动子。可以基于期望的结果选择用于在本发明重组dna构建体中使用的启动子。
[0056]
c.植物和植物细胞
[0057]
提供了包含本文所述的bg1多核苷酸序列或本文所述的重组dna构建体的植物、植物细胞、植物部分、种子、和籽粒,使得植物、植物细胞、植物部分、种子、和/或籽粒具有增加的bg1多肽表达。在某些实施例中,植物、植物细胞、植物部分、种子、和/或籽粒将本文所述的bg1多核苷酸稳定地掺入其基因组中。在某些实施例中,植物、植物细胞、植物部分、种子、和/或籽粒可以包含多个bg1多核苷酸(即,至少1个、2个、3个、4个、5个、6个或更多个)。
[0058]
在特定实施例中,植物、植物细胞、植物部分、种子、和/或籽粒中的一种或多种bg1多核苷酸可操作地连接到异源调节元件,诸如,但不限于组成型启动子、组织偏好性启动子、或用于在植物中表达的合成启动子或组成型增强子。
[0059]
如本文使用的,“基因组基因座”通常指在植物的染色体上的位置,在该位置上发现了基因,诸如编码bg1多肽的多核苷酸。如本文使用的,“基因”包括表达功能性分子的核酸片段,诸如但不限于特定蛋白质编码序列和调节元件,诸如在编码序列之前(5
′
非编码序列)和之后(3
′
非编码序列)的那些调节元件。
[0060]“调节元件”通常是指参与调节核酸分子(诸如基因或靶基因)的转录的转录调节元件。调节元件是核酸,并且可以包括启动子、增强子、内含子、5
’‑
非翻译区(5
’‑
utr,还被称为前导序列)、或3
’‑
utr或其组合。调节元件能以“顺式”或“反式”起作用,并且通常以“顺式”起作用,即其激活位于调节元件所在的相同核酸分子(例如染色体)上的基因的表达。
[0061]“增强子”元件是当功能性连接至启动子时(无论其相对位置如何)都可增加核酸
分子的转录的任何核酸分子。
[0062]
将“阻遏物”(本文中有时也被称为沉默子)定义为当在功能上与启动子连接时(无论相对位置如何)都抑制转录的任何核酸分子。
[0063]
术语“顺式元件”通常是指影响或调控可操作地连接的可转录的多核苷酸表达的转录调节元件,其中该可转录的多核苷酸存在于相同dna序列中。顺式元件可以起到结合转录因子的作用,这些转录因子是调节转录的反式作用多肽。
[0064]“内含子”是转录成rna、但是然后在产生成熟mrna的过程中被切除的基因中的间插序列。该术语也用于切除的rna序列。“外显子”是经转录的基因的序列的一部分,并且在源自该基因的成熟信使rna中被发现,但不一定是编码最终基因产物的序列的一部分。
[0065]5′
非翻译区(5’utr)(也称为翻译前导序列或前导rna)是直接位于起始密码子上游的mrna的区域。此区域涉及通过病毒、原核生物和真核生物中的不同机制对转录物的翻译的调节。
[0066]“3’非编码序列”是指位于编码序列下游的dna序列,并且包括聚腺苷酸化识别序列和编码能够影响mrna加工或基因表达的调节信号的其他序列。聚腺苷酸化信号通常表征为影响聚腺苷酸片添加到mrna前体的3
′
端。
[0067]“遗传修饰”、“dna修饰”等是指在植物的特定基因组基因座上改变或变更核苷酸序列的位点特异性修饰。本文所述的组合物和方法的遗传修饰可以是本领域已知的任何修饰,诸如,例如,插入、缺失、单核苷酸多态性(snp)、和或多核苷酸修饰。另外,基因组基因座上的靶向dna修饰可位于基因组基因座上的任何位置,诸如,例如,所编码的多肽的编码区(例如,外显子)、非编码区(例如,内含子)、调节元件、或非翻译区。
[0068]
如本文使用的,“靶向”遗传修饰或“靶向”dna修饰是指对生物体基因的直接操作。靶向修饰可以使用本领域已知的任何技术引入,诸如,例如,植物育种、基因组编辑、或单基因座转化。
[0069]
bg1多核苷酸的dna修饰的类型和位置不受特别限制,只要dna修饰导致由bg1多核苷酸编码的蛋白质的表达和/或活性增加即可。
[0070]
在某些实施例中,植物、植物细胞、植物部分、种子、和/或籽粒包含存在于编码bg1多肽的内源性多核苷酸的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区,或(e)(a)-(d)的任何组合中的一种或多种核苷酸修饰。
[0071]
如本文使用的“增加的”、“增加”等是指与对照组(例如,不包含dna修饰的野生型植物)相比,实验组(例如,具有本文所述的dna修饰的植物)中的任何可检测的增加。因此,增加的蛋白质表达包含样本中蛋白质总水平的任何可检测的增加,并且可使用本领域的常规方法来确定,诸如,例如,蛋白质印迹法和elisa。
[0072]
在某些实施例中,基因组基因座具有超过一个(例如,2个、3个、4个、5个、6个、7个、8个、9个、或10个)dna修饰。例如,基因组基因座的翻译区和调节元件可各自包含靶向dna修饰。在某些实施例中,植物的超过一个基因组基因座可包含dna修饰。
[0073]
如本文使用的,术语“植物”包括植物原生质体、可再生植物的植物细胞组织培养物、植物愈伤组织、植物块和在植物或植物部分(诸如胚、花粉、胚珠、种子、叶、花、枝、果、仁、穗、穗轴、壳、茎、根、根尖、花药等)中的完整植物细胞。籽粒意指由商业种植者出于栽培或繁殖物种之外的目的所生产的成熟种子。再生植物的子代、变体和突变体也包括在本公
开的范围内,其条件是这些部分包含引入的多核苷酸或一种或多种遗传修饰。
[0074]
本文公开的多核苷酸或重组dna构建体可用于任何植物物种(包括但不限于单子叶植物和双子叶植物)的转化。另外,本文所述的遗传修饰可用于修饰任何植物物种(包括但不限于单子叶植物和双子叶植物)。
[0075]
目的植物物种的实例包括但不限于玉蜀黍(maize,zea mays)、芸苔属(brassica)物种(例如,欧洲油菜(b.napus)、芜菁(b.rapa)、芥菜(b.juncea))(特别是可用作种子油来源的那些芸苔属物种)、苜蓿(紫花苜蓿(medicago sativa))、水稻(rice,oryza sativa)、黑麦(rye,secale cereale)、高粱(两色高粱、高粱(sorghum vulgare))、粟(例如,珍珠粟(御谷(pennisetum glaucum))、黍(粟米(panicum miliaceum)),粟(谷子)、穇子(龙爪稷(eleusine coracana)))、向日葵(sunflower,helianthus annuus)、红花(safflower,carthamus tinctorius)、小麦(wheat,triticum aestivum)、大豆(soybean,glycine max)、烟草(tobacco,nicotiana tabacum)、马铃薯(potato,solanum tuberosum)、花生(peanut,arachis hypogaea)、棉花(海岛棉(gossypium barbadense)、陆地棉(gossypium hirsutum))。
[0076]
蔬菜包括例如番茄(tomato,lycopersicon esculentum)、莴苣(例如,莴苣(lactuca sativa))、青豆(菜豆(phaseolus vulgaris))、利马豆(lima bean,phaseolus limensis)、豌豆(香豌豆属(lathyrus)物种)和黄瓜属的成员,诸如黄瓜(cucumber,c.sativus)、香瓜(cantaloupe,c.cantalupensis)和甜瓜(musk melon,c.melo)。观赏植物包括杜鹃(杜鹃花属(rhododendron)物种)、八仙花(hydrangea,macrophylla hydrangea)、朱槿(hibiscus,hibiscus rosasanensis)、玫瑰(蔷薇属(rosa)物种)、郁金香(郁金香属(tulipa)物种)、水仙(水仙属(narcissus)物种)、矮牵牛(petunias,petunia hybrida)、康乃馨(carnation,dianthus caryophyllus)、一品红(poinsettia,euphorbia pulcherrima)和菊花。
[0077]
其他目的植物包括例如提供目的种子的谷物类植物、油料种子植物和豆科植物。目的种子包括例如谷物种子,诸如玉米、小麦、大麦、水稻、高粱、黑麦等。油料种子植物包括例如棉花、大豆、红花、向日葵、芸苔属、玉蜀黍、苜蓿、棕榈、椰子等。豆科植物包括豆类和豌豆。豆类包括瓜耳豆、槐豆、胡芦巴、大豆、四季豆、豇豆、绿豆、利马豆、蚕豆、小扁豆、鹰嘴豆。
[0078]
例如,在某些实施例中,提供了玉蜀黍植物,其在其基因组中包含编码bg1多肽的多核苷酸,该bg1多肽包含与seq id no:1、3、5、7、9、11、13和15中的任一个具有至少90%同一性的氨基酸序列。
[0079]
d.堆叠其他目的性状
[0080]
在一些实施例中,本文公开的本发明的bg1多核苷酸被工程化为分子堆叠物。因此,本文公开的各种宿主细胞、植物、植物细胞、植物部分、种子、和/或籽粒可进一步包含一种或多种目的性状。在某些实施例中,宿主细胞、植物、植物部分、植物细胞、种子、和/或籽粒与目的多核苷酸序列的任何组合堆叠,以产生具有所需性状的组合的植物。如本文使用的,术语“堆叠”是指具有存在于同一目的植物或生物体中的多种性状。例如,“堆叠性状”可包含其中序列在物理上彼此相邻的分子堆叠物。如本文使用的,性状是指源自特定序列或序列组群的表型。在一个实施例中,分子堆叠物包含赋予对草甘膦的耐受性的至少一种多
核苷酸。赋予对草甘膦的耐受性的多核苷酸是本领域已知的。
[0081]
在某些实施例中,分子堆叠物包含赋予对草甘膦的耐受性的至少一种多核苷酸和赋予对第二除草剂的耐受性的至少一种额外的多核苷酸。
[0082]
在某些实施例中,具有本发明的多核苷酸序列的植物、植物细胞、种子、和/或籽粒可与赋予对以下的耐受性的一个或多个序列堆叠:als抑制剂;hppd抑制剂;2,4-d;其他苯氧基生长素除草剂;芳氧基苯氧基丙酸除草剂;麦草畏;草铵膦除草剂;靶向原卟啉原氧化酶(也称为“原卟啉原氧化酶抑制剂”)的除草剂。
[0083]
具有本发明的多核苷酸序列的植物、植物细胞、植物部分、种子、和/或籽粒也可与至少一个其他性状组合,以产生进一步包含多种所需性状组合的植物。例如,具有本发明的多核苷酸序列的植物、植物细胞、植物部分、种子、和/或籽粒可以与编码具有杀有害生物活性和/或杀昆虫活性的多肽的多核苷酸堆叠,或具有本发明的多核苷酸序列的植物、植物细胞、植物部分、种子、和/或籽粒可以与植物抗病性基因组合。
[0084]
这些堆叠的组合可以通过如下任何方法产生,该方法包括但不限于,通过任何常规的方法学进行植物育种、或遗传转化。如果通过遗传转化植物来堆叠序列,则目的多核苷酸序列可以在任意时间并以任意顺序组合。可以用共转化方案将这些性状与转化盒的任何组合所提供的目的多核苷酸一起引入。例如,若引入两个序列,则这两个序列可包含在分开的转化盒(反式)或包含在同一个转化盒(顺式)中。序列的表达可以通过相同的启动子或通过不同的启动子驱动。在某些情况下,可能需要引入将抑制目的多核苷酸的表达的转化盒。这可以与其他抑制盒或过度表达盒的任何组合进行组合以在该植物中产生所需性状组合。进一步应当认识到,可以使用位点特异性重组系统在所需的基因组位置堆叠多核苷酸序列。参见例如,wo 99/25821、wo 99/25854、wo 99/25840、wo 99/25855、以及wo 99/25853,将其全部通过援引并入本文。
[0085]
可以使用具有本文公开的本发明的多核苷酸序列的任何植物来制造食品或饲料产品。此类方法包括获得包含多核苷酸序列的植物、外植体、种子、植物细胞、或细胞,并且加工所述植物、外植体、种子、植物细胞、或细胞以生产食品或饲料产品。
[0086]
ii.使用方法
[0087]
a.用于在植物中增加产量、提高耐旱性、和/或增加bg1活性的方法
[0088]
提供了用于增加植物产量、提高植物耐旱性、增加侧根发育和/或增加植物中的bg1活性的方法,该方法包括将重组dna构建体引入植物、植物细胞、植物部分、种子和/或籽粒中,借此使多肽在植物中表达,该重组dna构建体包含本文所述的本发明的多核苷酸中的任一种。还提供了用于增加植物产量、提高植物耐旱性、和/或增加植物中的bg1活性的方法,该方法包括在植物的基因组基因座处引入遗传修饰,该基因组基因座编码包含氨基酸序列的bg1多肽,该氨基酸序列与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55中的任一个所列出的氨基酸序列具有至少90%同一性。
[0089]
用于在本发明的方法中使用的植物可以是本文所述的任何植物物种。在某些实施例中,植物是谷物类植物、油料种子植物和豆科植物。在某些实施例中,植物是谷物类植物,诸如玉蜀黍。
[0090]
如本文使用的,“产量”是指收获的农业产量/单位土地,并且可包括提及收获时农
作物的蒲式耳/英亩,如针对籽粒水分进行了调整(例如,玉蜀黍典型地为15%)。在籽粒收获时测量籽粒水分。确定调整后的籽粒测试重量为重量(磅)/蒲式耳,在收获时针对籽粒水分水平进行了调整。
[0091]
如本文使用的,“耐旱性”是指植物在延长的时间段内在干旱条件下存活而没有表现出严重的生理或物理恶化的性状。
[0092]
植物“提高的耐旱性”是指如相对于参考或对照植物测量的,生理或物理特征(如产量)的任何可测量的改善。典型地,当植物(在其基因组中包含重组dna构建体或dna修饰)表现出相对于参考或对照植物提高的耐旱性时,参考或对照植物在其基因组中不包含该重组dna构建体或dna修饰。
[0093]
本领域技术人员熟悉模拟干旱条件并评价植物耐旱性的规程,这些植物已经遭受了模拟的或天然存在的干旱条件。技术人员可以通过给予植物比正常需要更少的水或在一个时段内不提供水来模拟干旱条件,并且技术人员可通过寻找在生理和/或物理条件上的差异来评价耐旱性,包括(但不限于)活力、生长、大小、或根长、或特别地叶颜色或叶面积大小。用于评价耐旱性的其他技术包括测量叶绿素荧光、光合作用速率和换气速率。
[0094]
如本文使用的,与合适的对照相比,bg1活性的增加是指bg1蛋白质活性的任何可检测的增加。bg1活性可以是任何已知的生物学特性,并且包括例如蛋白质复合物的形成增加和/或生化途径的调节。
[0095]
可以使用各种方法来将目的序列引入植物、植物部分、植物细胞、种子、和/或籽粒。“引入”旨在意指以这样一种方式将本发明的多核苷酸或所得多肽提供给植物、植物细胞、种子、和/或籽粒,使得该序列得以进入该植物的细胞内部。本公开的方法不取决于将序列引入植物、植物细胞、种子、和/或籽粒的具体方法,只要该多核苷酸或多肽进入植物的至少一个细胞的内部即可。
[0096]“稳定转化”旨在意指被引入植物中的多核苷酸整合到目的植物的基因组中,并且能够被其子代遗传。“瞬时转化”旨在意指将多核苷酸引入目的植物中并且不整合到该植物或生物体的基因组中,或者将多肽引入植物或生物体中。
[0097]
转化方案连同用于将多肽或多核苷酸序列引入植物中的方案可以取决于被靶向转化的植物或植物细胞的类型(即,单子叶植物或双子叶植物)而变化。将多肽和多核苷酸引入植物细胞中的合适的方法包括显微注射法(crossway等人(1986)biotechniques[生物技术]4:320-334)、电穿孔(riggs等人(1986)proc.natl.acad.sci.usa[美国科学院院报]83:5602-5606)、农杆菌介导的转化(美国专利号5,563,055和美国专利号5,981,840)、直接基因转移(paszkowski等人(1984)embo j.[欧洲分子生物学学会杂志]3:2717-2722)、以及弹道粒子加速(参见例如,美国专利号4,945,050;美国专利号5,879,918;美国专利号5,886,244;和5,932,782;tomes等人(1995)plant cell,tissue,and organ culture:fundamental methods[植物细胞、组织和器官培养:基本方法],编辑gamborg和phillips(springer-verlag,berlin[柏林施普林格出版社]);mccabe等人(1988)biotechnology[生物技术]6:923-926);以及lec1转化(wo 00/28058)。还参见weissinger等人(1988)ann.rev.genet.[遗传学年鉴]22:421-477;sanford等人(1987)particulate science and technology[微粒科学与技术]5:27-37(洋葱);christou等人(1988)plant physiol.[植物生理学]87:671-674(大豆);mccabe等人(1988)bio/technology[生物/技术]6:923-926(大
豆);finer和mcmullen(1991)in vitro cell dev.biol.[体外细胞生物学和发育生物学]27p:175-182(大豆);singh等人(1998)theor.appl.genet.[理论与应用遗传学]96:319-324(大豆);datta等人(1990)biotechnology[生物技术]8:736-740(水稻);klein等人(1988)proc.natl.acad.sci.usa[美国科学院院报]85:4305-4309(玉蜀黍);klein等人(1988)biotechnology[生物技术]6:559-563(玉蜀黍);美国专利号5,240,855;5,322,783;和5,324,646;klein等人(1988)plant physiol.[植物生理学]91:440-444(玉蜀黍);fromm等人(1990)biotechnology[生物技术]8:833-839(玉蜀黍);hooykaas-van slogteren等人(1984)nature[自然](伦敦)311:763-764;美国专利号5,736,369(谷物);bytebier等人(1987)proc.natl.acad.sci.usa[美国科学院院报]84:5345-5349(百合科(liliaceae));de wet等人(1985)the experimental manipulation of ovule tissues[胚珠组织的实验操作],chapman等人编辑(longman[朗文出版社],纽约),第197-209页(花粉);kaeppler等人(1990)plant cell reports[植物细胞报告]9:415-418和kaeppler等人(1992)theor.appl.genet.[理论与应用遗传学]84:560-566(晶须介导的转化);d
′
halluin等人(1992)plant cell[植物细胞]4:1495-1505(电穿孔);li等人(1993)plant cell reports[植物细胞报告]12:250-255以及christou和ford(1995)annals of botany[植物学年报]75:407-413(水稻);osjoda等人(1996)nature biotechnology[自然生物技术]14:745-750(经由根癌农杆菌(agrobacterium tumefaciens)的玉蜀黍);将其全部通过援引并入本文。
[0098]
在特定实施例中,可以使用各种瞬时转化方法将bg1序列提供给植物。此类瞬时转化方法包括但不限于将bg1蛋白质直接引入植物中。此类方法包括例如显微注射或粒子轰击。参见,例如,crossway等人,(1986)mol gen.genet.[分子遗传学和普通遗传学]202:179-185;nomura等人,(1986)plant sci.[植物科学]44:53-58;hepler等人(1994)proc.natl.acad.sci.[美国科学院院报]91:2176-2180以及hush等人(1994)the journal of cell science[细胞科学杂志]107:775-784,所有这些文献都通过援引并入本文。
[0099]
在其他实施例中,可以通过使植物与病毒或病毒核酸接触将本文公开的本发明的多核苷酸引入植物中。通常,此类方法涉及将本公开的核苷酸构建体并入dna或rna分子内。应当认识到,本发明的多核苷酸序列最初可以被合成为病毒多蛋白的一部分,然后可以通过体内或体外蛋白水解而被加工,以产生所需的重组蛋白。此外,应当认识到,本文公开的启动子也涵盖用于通过病毒rna聚合酶进行转录的启动子。涉及病毒dna或rna分子、用于将多核苷酸引入植物中并表达其中所编码的蛋白质的方法是本领域已知的。参见,例如,美国专利号5,889,191、5,889,190、5,866,785、5,589,367、5,316,931,以及porta等人(1996)molecular biotechnology[分子生物技术]5:209-221;通过援引并入本文。
[0100]
技术人员将认识到,在将含有本发明的多核苷酸的表达盒稳定地并入转基因植物中并且确认是有效的之后,其可以通过有性杂交被引入其他植物中。可以使用许多标准育种技术中的任何一种,这取决于待杂交的物种。
[0101]
在无性繁殖的作物中,成熟的转基因植物可以通过取出插条或通过组织培养技术进行繁殖,以产生多个相同的植物。进行所希望的转基因学的选择,并且获得并且无性繁殖新品种用于商业用途。在种子繁殖的作物中,成熟的转基因植物可以自交以产生纯合的自交系植物。自交系植物产生含有新引入的异源核酸的种子。这些种子可以生长,以产生植物,这些植物僵产生选择的表型。
[0102]
包括从再生植物获得的部分,诸如花、种子、叶、枝、果实等,条件是这些部分包含细胞,这些细胞包含本发明的多核苷酸。还包括再生植物的后代和变体、以及突变体,条件是这些部分包含引入的核酸序列。
[0103]
在一个实施例中,可通过将含有单个添加的异源核酸的杂合转基因植物有性交配(自交),使产生的种子中的一些发芽,并且针对相对于对照植物(即天然的、非转基因的),改变的细胞分裂,分析产生的所得植物。还考虑了与亲本植物回交和与非转基因植物外交。
[0104]
因此,在某些实施例中,该方法包括:(a)在可再生植物细胞中表达本文所述的本发明的多核苷酸中的任一个,例如包含编码氨基酸序列的多核苷酸的重组dna构建体,以及(b)产生该植物,该氨基酸序列与seq id no:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33、35、41、43、45、47、49、51、53和55中的任一个的氨基酸序列具有至少90%同一性,其中该植物在其基因组中包含目的重组dna构建体,。
[0105]
已经公开了主要通过使用根癌农杆菌来转化双子叶植物并获得转基因植物的方法,尤其是对于棉花(美国专利号5,004,863、美国专利号5,159,135);大豆(美国专利号5,569,834、美国专利号5,416,011);芸苔属(美国专利号5,463,174);花生(cheng等人,plant cell rep.[植物细胞报告]15:653 657(1996),mckently等人,plant cell rep.[植物细胞报告]14:699 703(1995));木瓜(ling等人,bio/technology[生物/技术]9:752 758(1991));和豌豆(grant等人,plant cell rep.[植物细胞报告]15:254 258(1995))。对于其他常用的植物转化方法的综述参见如下文献:newell,c.a.,mol.biotechnol.[分子生物技术]16:53 65(2000)。这些转化方法之一使用发根土壤杆菌(agrobacterium rhizogenes)(tepfler,m.和casse-delbart,f.,microbiol.sci.[微生物科学]4:24 28(1987))。已经公开了采用如下手段使用dna的直接递送进行的大豆转化:peg融合(pct公开号wo 92/17598)、电穿孔(chowrira等人,mol.biotechnol.[分子生物技术]3:17 23(1995);christou等人,proc.natl.acad.sci.u.s.a.[美国科学院院报]84:3962 3966(1987))、显微注射或粒子轰击(mccabe等人,biotechnology[生物技术]6:923-926(1988);christou等人,plant physiol.[植物生理学]87:671 674(1988))。
[0106]
有各种各样的方法用于从植物组织再生植物。特定的再生方法将取决于起始植物组织和待再生的特定植物种类。来自单一植物原生质体转化体或来自各种转化的外植体的植物的再生、发育和培养是本领域所熟知的(weissbach和weissbach编辑;methods for plant molecular biology[植物分子生物学方法];academic press,inc.[学术出版社有限公司]:圣地亚哥,加利福尼亚州1988)。这种再生和生长过程典型地包括如下步骤:选择转化的细胞,通过胚性发育的通常阶段或通过生根苗阶段培养那些个体化细胞。以同样的方式再生转基因胚和种子。然后将所得的转基因生根芽苗种植在合适的植物生长培养基(如土壤)中。优选地,再生植物自花授粉以提供纯合的转基因植物。或者,将得自再生植物的花粉与农学上重要的品系的产生种子的植物进行杂交。相反地,将来自这些重要品系的植物的花粉用于给再生植物授粉。使用本领域技术人员熟知的方法培养含有所需多肽的本公开的转基因植物。
[0107]
以下是本发明一些方面的特定实施例的实例。提供这些实例仅出于说明目的而无意以任何方式限制本发明的范围。
[0108]
实例1
[0109]
bg1基因家族鉴定与表征
[0110]
搜索玉蜀黍基因组和转录组并鉴定出10个候选玉蜀黍家族成员。玉蜀黍中有8个bg1相关基因家族成员,这些成员与os-bg1具有超过20%的氨基酸同一性(aaid)(表2)。基因组草图refgen2中的一个基因grmzm2g027519与7号染色体上的grmzm5g843781同一,并且仅7号染色体基因座仍在新的agpv4基因组草图中。
[0111]
表2.bg1和bg1样家族成员
[0112][0113]
水稻os-bg1的基因名称、公共基因座名称、肽长度(氨基酸)、染色体位置、以及全局氨基酸同一性(aaid)和相似性(aasim)。与os-bg1的蛋白质关系最接近的同源物(65.1%同一性)是基因座grmzm2g178852,我们称之为玉蜀黍big grain1同源物1(zm-bg1h1)。与os-bg1第二接近的同源物(56.3%-57.6%同一性)是9号染色体上的单个或重复基因座。在b73基因组组装refgen2.0或agpv4.0中,此区域由两个非常密切相关(97.8%aaid)且紧密间隔的基因座grmzm2g007134(zm-bg1h2)和grmzm2g438606(zm-bg1h3)表示。在公共基因组草图refgen2和agpv4中,将这两个基因之间的区域用50kb n间隔子间隙填充。不同硬茎品系的专有基因组草图表明这两个基因在排列上以atg-atg相连、相距31.5kb,表明直接的区域串联重复,其中变体grmzm2g438606位于这两个基因的最末端(端粒)。然而,在一些专有非硬茎品系基因组草图中,此区域表现为基因座grmzm2g438606的单个拷贝,表明此基因座可能被复制(或优先保留)以仅在玉蜀黍谱系的子集中呈现grmzm2g007134。此复合基因座对的基因表达和基因单倍型分析(以下)可能合并了这两个基因座,因为它们在orf中99.3%nt同一且非常紧密间隔,并且因此我们通常将它们统称为zm-bg1h2(3)。zm-bg1h1基因与zm-bg1h2(3)基因对具有至少约65%aaid。
[0114]
另外两个更远相关的基因(zm-bg1lh1(grmzm2g110473)和zm-bgllh2(grmzm2g110473))(玉蜀黍bg1样同源物1和2)与os-bg1具有41.1%和39.3%aaid,但分别与os-bg1样基因座(loc_os10g25810.1)具有更高的54.4%和49.6%的氨基酸相似性。bg1家族分为主要进化枝(区分bg1同源物和bg1样同源物)。这两个基因归类为bg1样。这两个玉蜀黍基因是73.8%aaid,表明它们最近复制过。另外三种bg1样基因(zm-bg1lh3、zm-bg1lh4和zm-bg1lh5)与os-bg1具有非常低(低于26%)的氨基酸相似性。zm-bg1lh3和zm-bg1lh4是具有74.9%aatd的一对,而zm-bg1h5是最独特的,与所有其他家族成员具有低于23%的id
(表2)。
[0115]
zm-bg1h1和zm-bg1h2(3)对被鉴定为候选os-bg1直系同源物。1号和9号染色体共享基因组内同线性的大区域。zm-bg1h1周围的局部1号染色体区域与zm-bg1h2(3)周围的9号染色体区域中的基因具有多个基因同源物。并且正如zm-bg1h1和zm-bg1h2(3)在它们各自的染色体上是相反的方向(分别是反向和正向),它们的局部同线同源基因邻居的相对基因顺序也相反。高粱仅有一个os-bg1同源物,并且当它与zm-bg1h1(77.5%)具有更高同一性(与zm-bg1h2(3)(69.6%)相比,)时,序列介于两者之间。这表明玉蜀黍-高粱最近共同祖先(ca.11.9m.y.a.)可能具有单个bg1同源物基因,并且基因组复制事件(ca.>4.8m.y.a.)导致了1号和9号染色体上的玉蜀黍基因座,但自玉蜀黍-高粱前祖先以来的其他基因缺失/保留情况是可能的。
[0116]
实例2
[0117]
基因表达分析
[0118]
使用产生的一组755 b73 rnaseq样本来分析zm-bg1家族的基因表达。os-bg1在芽尖分生组织和发育中的花序中表现最高的表达水平,但在发育中的种子表达水平较低,在叶和根中表达水平仍较低(参见bar.utoronto.ca的水稻efp浏览器,查询别名loc_0s03g07920)。在755个不同组织处理mrna分析样本(分为五个主要的组织类别)中观察玉蜀黍基因家族表达模式。在来自基于b73的基因表达图谱中的五个玉蜀黍组织类别(根、绿色组织、分生组织、穗和雄穗)中进行zm-bg1基因家族mrna表达。以平均pptm(千万分之一)测量每个组织类别的表达值。所有样本中最高的平均表达是zm-bg1h1。zm-bg1h2(3)表达模式没有区别因为它们99.3%nt同一,但是似乎它们总体具有比zm-bg1h1更低的表达水平,尽管在一些组织中公共efp浏览器表明zm-bg1h2(3)具有更高的表达。剩余的家族成员甚至具有更低的表达水平。
[0119]
表3.内源和转基因zm-bg1h1基因表达水平比较
[0120][0121]
测量所有四个事件和对照无效的内源天然zm-bg1h1 mrna表达,表明天然基因表达在事件和无效中不同。另外,相对于天然内源zm-bg1h1表达估计转基因zm-bg1h1(mod1)
pcr内部组成型对照grmzm5g877316_t02与其在基因表达图谱中的基准表达)。在生长室植物中,相对于zm-bg1h1天然基因座,zm-bg1h1(mod1)表达升高,在所有四个事件中预计平均升高>57倍,并且在田间生长的植物中升高>32倍(表2)。这是推断的相对倍数变化因为zm-bg1h1天然基因和zm-bg1h1 mod1转基因涉及不同的qrt-pcr测定。它们的相对表达通过比较每个与常见的内部基因pcr对照(广泛表达的基因转录物grmzm5g877316_t02)进行估计。由于天然基因的表达水平非常低,在天然基因测定中,即使是适度的背景qrt-pcr信号也可能导致对转基因的相对倍数变化诱导的低估。虽然转基因使用zm-gos2 pro的特定分离dna片段,但当使用468 rnaseq b73样本比较zm-gos2(grmzm2g073535)和zm-bg1h1之间的相对内源天然基因表达水平时,zm-gos2基因表达平均比zm-bg1h1高375倍。按11种主要组织类型分解时,比率的范围为从在叶/芽和胚乳中分别高553倍和541倍,至在雄穗和茎/秆(stalk)中分别高21倍和18倍。zm-gos2的平均叶组织表达是6500pptm,比以下rt-pcr转基因估计高3至6倍。这些结果表明天然zm-gos2表达不仅比zm-bg1h1表达更高,而且它相对于天然zm-bg1h1也具有不同的组织-空间-时间模式。
[0129]
在两年多的测试中,在多个田间位置和环境中,对zm-bg1h1 oe事件(e1-e4)的产量进行了田间测试(与非转基因无效对照相比)。这些产量检验在总共26个位点位置进行,其在这两年中产生了各种产量环境,其中对照产量范围从9.4至17.4t/ha。这些位点的选择通常是为了提供环境和胁迫变化,其中水分可用性胁迫是这些位点产量差异的一个常见驱动因素。产量最低的环境(低于11.2t/ha)被分类为中度胁迫,11.2-14.4t/ha的那些被分类为轻度胁迫,并且所有高于14.4t/ha的那些被分类为最佳生长条件。相对于对照,所有四个事件都增加了两年的单位面积产量,总体测试平均值为355kg/ha(5.65bu/ac)(图1)。事件表现范围为事件e2,204.7kg/ha,至事件e1、e4和e3,分别为399.1、406.7和415.4kg/ha。事件与事件之间的差异很小,在α0.05显著性检验中未拒绝时没有差异。事件2落后,但事件e1、e3和e4在α0.05,平均407kg/ha(6.5bu/ac)优势时无法区分。所有101个事件-位置-年测试的产量差异示于图2中。83%的检验标称是正的,其中29个在blup p值0.1时是统计学上显著的,其中仅负产量值中的两个在blup p值0.1时是统计学上显著的。七个测试每公顷产生1吨以上的优势。这四个事件分布在整个性能谱中,其中所有四个事件在上或下10%产量差异值上均有代表。zm-bg1h1 oe测试在包括轻度胁迫至最佳条件的宽范围的环境下显示产量优势。在中度胁迫下几乎没有或没有优势,但这基于仅一个位置。相对于对照产量的产量优势线性回归分析仅为r2=0.05,表明几乎没有相关性。这表明zm-bglh1 oe在宽范围的环境、测试位置、以及胁迫水平下赋予产量优势(图2)。
[0130]
在田间测试中通过空中和地面观察的组合来评估zm-bg1h1 oe事件与对照在与玉蜀黍育种相关的一组农艺性状方面的差异。这些性状包括开花、冠层和植被绿度、植物大小和结构以及籽粒水分。将包括产量的所有这些性状转换为与对照的差异百分比,以便进行性状与性状之间的比较。计算各性状与每个产量优势zm-bg1h1的线性回归分析(合并所有事件)。这些性状中的每一个的与对照的百分比差异、以及产量差异相关斜率和回归相关性一同绘制在图3中。作为参考性状的产量优势的斜率为1,并且与自身相关。四个冠层绿度性状总体上与对照几乎没有差异,且与产量相关的组织斜率(organized slope)或相关性不大。相比于对照,四个开花时间测量值呈略微正趋势(差异范围:0.3%至0.6%),但它们实际上没有显示与产量优势的正斜率或相关性。植物高度和穗高均高于对照,分别为2.6%和
1.5%,但两者也几乎没有显示与产量优势的正斜率或相关性。籽粒水分(mst)略高于对照(1.4%)并且显示与产量呈轻微正斜率和相关性(r2=0.19)。当水分与产量结合(yldmst,或单位水分产量)时,如预期的,与产量的相关性更正并且更显著(斜率0.7和r2=0.8)。籽粒密度(tstwt)平均下降0.5%(斜率0.01,r2=0.31)。
[0131]
开花时间:在第3年(yr3-obs),将四个事件和对照移植到专用观测场,以确认或扩展产量试验中的表型观察结果。当植物高1.8m时,通过v11观察到萌发、幼苗直立计数、冠层郁闭、叶大小形状或颜色、分蘖数以及株高与对照无差异。开花测量在种植后的第62天(1353gdu生长热单位)开始并且每天进行到第68天(1488gdu)。对照和每个事件的开花图(flowering graph plot)用来插入花粉脱落和抽丝达到50%的点(表4)。相对于对照,所有四个事件的花粉脱落延迟10-40gdu,顺序为无效<e1<e3<e2<e4,或所有4个事件一起的花粉脱落平均延迟25gdu。相对于对照,所有四个事件抽丝延迟2-38gdu,顺序为无效<e1<e3<e2<e4,或所有四个事件一起的抽丝平均延迟21gdu。asi变化不大,对照(31gdu),4个事件的范围为23-34gdu,并且所有4个事件平均为27gdu。
[0132]
表4.zm-bg1h1 oe植物的开花时间差异
[0133][0134]
50%的植物表现出可见的穗丝出现或雄穗小花挤出时,自种植以来的小时数(hr)或累计热生长单位(gdu)数。50%植物的值通过观测场植物的累计抽丝或花粉脱落的线形图插值估计。计算每个事件相对于对照无效的小时或gdu差异。e-all值代表共同所有四个事件。无效和每个事件的雌雄穗开花(asi)间隔的小时和gdu显示在右侧。
[0135]
植物高度和穗高:分别于第74天和第75天(此时所有植物均已开花)测量每个植物从地面到第一个雄穗分枝或穗节的植物高度和穗高。所有4个事件的第一个雄穗分枝平均高度比对照高4.9-10.1cm,相对顺序为e4>e2>e2>e3>无效,其中所有四个事件平均高8.0cm(3.2%,t检验p<1x10-4)。4个事件中有3个事件的穗节平均高度比对照高,范围从-1.3至 7.5cm,相对顺序为e4>e2>e1>无效>e3,并且所有四个事件平均高2.8cm(2.1%,t检验p=0.0272)。然而,第一个雄穗分枝高度与穗节高度的比率相似,其中对照为1.94,事件的范围为从1.92-1.99并且平均为1.96,这表明植物高度相对于穗高变化不大。但在此比率中,事件顺序e3>e1>e2>无效>e4与植物高度或穗高的事件顺序相反,这表明在最高的事件中穗节高度相对雄穗高度可能略有上升。
[0136]
实例4
[0137]
穗和仁形态学
[0138]
通过直接种子体积和重量测量值的组合来评估用于种植第一年产量试验的相同f1杂交种子源的种子大小和密度。比较对照和四个转基因zm-bg1h1 oe转基因事件品系之间的种子体积、重量和密度(图7)。在三次重复测量所有四个事件中,平均仁体积比对照低2.5%,且平均仁重量低1.5%,并且仁密度低1.4%(图7)。然而,对这些指标中的每一个,无效假设(无差异)在α0.05时未被拒绝。与水稻中os bg1的观察相反,四个zm-bg1h1过量表达事件均未显示相对于对照增加的种子大小。这也表明,与对照种子相比,zm-bg1h1 oe事件杂交产量试验在播种更大种子时并没有受益。
[0139]
观测场穗和仁数据分析如图4所示。在所有四个事件中,每穗总仁数增加6.0%,总仁体积增加3.6%,并且总仁重量增加2.0%。由于每株植物仅有一个穗,因此仁重量的增加反映每株植物的产量增加。与此相关的是穗长增加2.6%,穗充满长度增加2.3%,并且穗直径增加2.4%。然而,每个穗上的每仁平均重量下降4.2%,每仁体积也减小2.4%,导致每仁密度略微下降1.4%(图4)。四个事件中每个的zm-bg1h1 oe植物穗均显示平均仁行数(krn)增加,总体上,相对于对照17.31krn(对照),所有事件为17.86krn(zm-bg1h1),增加半行或3.1%,其中t检验p值为0.02。在所有四个事件中都观察到此向上的krn迁移,并且16和18krn之间的差异最为显著(图5)。具有最大krn增加的事件e3也具有最大的田间产量增加。因此,考虑到2.4%平均增加的zm-bg1h1 oe产量可能主要是由于此3.1%增加的一半仁行数以及平均zm-bg1h1 oe仁体积的降低与空间限制有关(其具有按比例增加的更高krn穗的数量)的可能性,我们再次比较穗和仁性状但归一化每个离散krn值(图8)。结果表明,当比较相同krn或所有krn的穗时,图4中观察到的穗或仁性状中所有观察到的增加或减少模式保持大致相同的模式和幅度,其中无统计学上显著的百分比差异(t检验p值>0.1)。然而,正如预期的那样,对krn的控制确实名义上减少了穗直径和总仁数的差异,因为这两个性状应该随着krn的增加而增加。对于zm-bg1h1 oe和对照两者,穗直径随着krn的增加而增加,然而在此样本中在每个krn值处,无效落后于zm-bg1h1 oe(图9)。
[0140]
实例5
[0141]
天然zm-bg1h1同源物之间的启动子分析
[0142]
据报道,os-bg1和bg1同源物启动子具有生长素响应相关的基序(mishra等人2017)。对于5个物种的bg1同源物中的每一种:zm-bg1h1、os-bg1、和bg1同源物(来自高粱、短柄草属和狗尾草属),从头搜索近端启动子中发现的保守基序(atg上游前1000nt)。在atg-tata之间的区域以及它们共享的tata框上游搜索保守基序,以控制影响保守基序相对偏移位置的5-utr长度变化。在紧接可用的5’utr上游的所有基因中都存在明确定义的tata框环境ctatatcttc。在额外的5’utr序列保守性中,5
’‑
utr也存在保守基序gcattg。tata框上游的五个其他基序被确定为:cgccac、cccgt、caccc、gaaat和ggacg。总体上,所有这七个元件的相对顺序是保守的,并且它们距离zm-bg1h1-a1的tata框不到360nt。还有其他保守基序,但一些有多个拷贝和/或相对于这7个保守元素在不同的位置,降低了他们相关性的置信度。除了tata框,其他6种基序的功能是未知的。尽管如此,这些基序中有5种与富集的ldss七聚体重叠,并且2种与place数据库中的调节元件相匹配。然而,其中没有基序已知与生长素有关。此外,5种生长素响应基序不在这7种保守基序之间或与其中的任何一个重叠:
仅在一些启动子中发现acttta、tgacg、catatg;在多个位置发现tgtgnn和nngaca,表明非特异性;以及未发现cacgcaat和kgtcccat。
[0143]
亚细胞定位:研究zm-bg1h1蛋白质的亚细胞定位,以解决以下两个问题:(1)zm-bg1h1蛋白质是否定位于质膜(pm),如os-bg1报道的;以及(2)zm-bg1h1蛋白质是否定位于具有zm-gos2 pro异位表达的pm中。用两种颜色标记转染玉蜀黍原生质体:rfp用于照亮细胞核并归一化表达水平;以及gfp(根据是否与zm-bg1h1蛋白融合)用于探测zm-bg1h1细胞位置。控制gfp的广泛细胞定位,并且当rfp被nls(核定位信号)核靶向时,对细胞核进行界定。用不同启动子::gfp报告基因融合物转染的原生质体的显微图像如图底部所示。大多数原生质体的直径范围为20-30微米。绿色来自gfp报告基因,并且红色来自rfp报告基因。gfp优先定位于原生质体质膜。gfp与zm-bg1h1的n末端融合,并与zm-gos2 pro异位表达。结果表明,gfp主要定位于细胞表面,与pm一致。进行相关的实验,不同的是,融合zm-bg1h1编码区域而不是gfp的n末端。结果是相似的,表明无论zm-bg1h1蛋白的n末端还是c末端被融合的gfp蛋白占据,其本身都能够将gfp蛋白导向pm。天然zm-bg1h1 pro的表达非常低,并且在此原生质体实验中,它的表达水平也很低(至少低一个数量级),这需要更长的曝光才能揭示非靶向gfp表达的扩散定位。驱动gfp::zm-bg1h1融合表达的天然zm-bg1h1启动子产生的表达过低,无法清楚地看到任何pm定位。
[0144]
实例6
[0145]
zm-bg1h1等位基因变异
[0146]
使用少量已完成的高质量公共和独有的基因组草图,对育种种质中zm-bg1h1基因座的结构等位基因多样性进行了调查,并对582个近交系的一些低质量基因组和转录组组装进行了研究,分布为47%ss和53%nss。等位基因序列比较仅限于来自1000bp启动子/5utr/orf/3utr的核心基因区域,因为基因周围较大的区域可能包括更多的重组事件,这些事件因此可能细分为更多的单倍型,但不太可能代表功能独特的zm-bg1h1基因等位基因。对于同源物zm-bg1h1,观察到至少5个主要序列变体与可能总共8-13个次要序列变体。前五种变体(我们在此处称为等位基因)由高质量的基因区域序列表示。其他更具推测性的序列变体基于较低质量的共有序列,并且在任何一个近交系中都没有完全测序,并且因此在此不作详细阐述。呈现的这五个等位基因序列占所调查的种质系的93%。等位基因a1和a2几乎只在ss(硬茎,通常在杂交生产中为雌性)中发现并且共占所调查种质的约44%。等位基因a3、a4和a5占所调查的基因组的49%,并且几乎全部为nss(非硬茎,在杂交生产中通常为雄性)(表5)。其他推测性的低质量变体占余下部分。在此基因座没有任何存在-不存在变异(pav)的迹象。早先对416个种质系(与582个系调查组共有63%)的单独早期分析也未发现pav。
[0147]
表5.zm-bg1h1基因座处的玉蜀黍等位基因多样性和杂种优势组关系
[0148][0149]
五个最常见的玉蜀黍等位基因zm-bg1h1变体中的每个与水稻bg1或两色高粱bg1同源物的全局氨基酸同一性(aaid)(由clustalw比对算法确定)。具有五个玉蜀黍等位基因中的每个的参考近交名称,和用每个等位基因单倍型评估的所有品系的百分比,以及被认为是硬茎或非硬茎的那些品系的百分比。
[0150]
呈现的所有五个等位基因均包括一个完整的可读框,没有早熟截短或明显缺陷不完全蛋白。cds的核苷酸同一性的范围为94.8%-99.3%。编码的蛋白质都是不同的,他们本身之间的aaid的范围为95.4%-99.4%,以及与os-bg1的aaid为65.1%-66.9%并且与高粱sb-bg1(xp_021314015.1)的aaid为77.5%-80.3%(表5)。等位基因之间有7个肽区域差异。与高粱sb-bg1相比,在7个位置的3个处,zm-bg1h1a2(3)中“mqshqdl”中的组氨酸缺失,以及zm-bg1h1a1中的“apap”和“yghg”缺失,这些变异似乎是玉蜀黍谱系特异性的。cds比较表明额外的同义密码子变异,并且zm-bg1h1a1的“apap”变异可能是ssr。将7个变异肽区中的每个均与禾本科bg1同源物代表进行比较。在跨物种禾本科bg1肽中,所有7个位置也存在区域差异,这表明这些变体不太可能破坏关键的保守蛋白质功能。五个玉蜀黍等位基因的七个区域的变异模式表明多重基因内/等位基因间重组事件的历史。还在近1000nt启动子加5
′
utr区域比较了五个zm-bg1h1等位基因。5
′
utr和启动子区域两者均显示许多变异,包括插入缺失和点突变。然而,所有五个等位基因具有多物种保守的tata框(ctatatcttc),并且在来自多个物种的bg1同源物上共享的以上发现的6个其他基序中,所有基序在所有这五个等位基因中也都是保守的,表明这些变异不太可能破坏如在评估中观察到的保守启动子功能。
[0151]
等位基因功能差异可能体现在基因表达差异中。调查了一组416个近交系的在上午10-12am之间收获的v6叶组织表达。标记和谱系分析可以推断可能的ibd单倍型。通常,每个ibd单倍型中的关键品系都可以通过本文呈现的五个等位基因的等位基因iis序列相匹配,但一个此类推断的同源一致性单倍型通常含有a1和a2等位基因两者,这表明仅侧翼遗传标记可能无法准确区分这两个等位基因。所有等位基因均检测到叶表达,但如上所述,叶日表达量较低,此范围为从21.0至25.5pptm,但单倍型之间观察到的变化很小(图6)。对含有zm-bg1h1-a3等位基因的近交系ph184c和在此实验中用于转基因转化的相同品系使用田间生产样本进行rna图谱分析。在v10、vt/r1和r4阶段以及在干旱和充足水分条件下,对植物的11个组织取样。各组织的平均表达如图s11中所示。此实验没有直接比较其他品系或单倍型,但它揭示了zm-bg1h1-a3(nss,ph184c)等位基因在所有组织中均表达,且其组织空间模式与对zm-bg1h1-a1(ss,b73)进行的广泛组织调查一致;例如,未成熟穗表达相对较高,
但在叶中表达较低。
[0152]
评估了zm-bg1h1和zm-bg1h2(3)基因座是否与不同的遗传表型间隔(interval)(qtl、gwas、育种值等)相关。搜索3000多个玉蜀黍公共和内部基因间隔,涉及类别归类为以下性状:产量、仁、发育、结构、根、能育性和开花。一组涉及1860个公开和展示区域(curated region),另一组涉及超过1180个内部计算的qtl和gwas关联。值得注意的是,与zm-bg1h1或zm-bg1h2(3)基因座相关的区域非常少。有时,z产量植物高度和成熟区域与m-bg1h1和zm-bg1h2(3)重叠,但总体上,任一基因座处的任何性状都没有区域集中,而是在这两个基因座处存在明显的相对缺失。鉴于所涉及的异质聚集信息,此结论的统计意义难以确定。
[0153]
除非另有指定,否则权利要求书和说明书中使用的术语如下文阐述定义。必须注意,除非上下文另外清楚地指明,否则如本说明书及所附权利要求书中所用,单数形式“一个/一种(a/an)”和“该/所述(the)”包括复数指示物。
[0154]
本说明书中的所有出版物和专利申请都指示了本发明所属领域的普通技术人员的水平。将所有出版物和专利申请通过援引并入本文,其程度就像明确且单独指出通过引用每个单独出版物或专利申请一样。
[0155]
除非另外定义,否则本文所使用的全部技术术语和科学术语具有与本发明所属领域的普通技术人员通常所理解的相同意义。除非另外提及,否则本文采用或考虑的技术是本领域普通技术人员熟知的标准方法。材料、方法和实例仅为说明性的并且不是限制性的。
[0156]
借助前面的描述和随附的附图中给出的教导,这些发明所属领域的技术人员将会想到本发明的许多修改及其他实施例。因此,应当理解,本发明不限于所公开的特定实施例,并且修改和其他实施例旨在包括在所附权利要求的范围内。尽管本文中采用了具体的术语,但这些术语仅在一般性和描述性意义上使用而并非用于限制目的。
[0157]
单位、前缀和符号可以按它们si接受的形式来表示。除非另外指明,否则核酸从左向右以5
′
至3
′
方向书写;氨基酸序列都从左向右以氨基到羧基方向书写。数值范围包括限定该范围的数值在内。本文氨基酸可以通过它们普遍已知的三字母符号或通过iupac-iub生物化学术语委员会推荐的单字母符号来表示。同样,核酸可以通过它们普遍接受的单个字母代码来表示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
