1.本发明涉及人机交互技术领域,尤其涉及一种应用于人机交互中的远近场拾音方法。
背景技术:
2.随着社会的进步和技术的发展,手机设备、免提设备以及头戴设备等通讯产品在日常生活和专利领域中扮演的角色愈来愈重要,人机交互行为也越来越普遍,人们可通过语音控制来执行相应的功能;比如,受控设备检测到语音控制指令时,可以根据检测到的语音控制指令来执行相应的操作。
3.在使用语音识别技术进行语音控制中,声音输入容易受距离远近和噪音干扰的影响,导致无法及时做出指令操作,来执行相应操作,影响人们的正常使用。
技术实现要素:
4.有鉴于此,本发明所要解决的技术问题是:提供一种应用于人机交互中的远近场拾音方法,使语音指令输入不受距离影响,提高指令输入的稳定性;同时,降低环境噪音对指令输入的影响,提高指令输入的准确性,保证指令操作的正常执行。
5.为解决上述技术问题,本发明的技术方案是:
6.一种应用于人机交互中的远近场拾音方法,其特征在于,包括如下步骤:
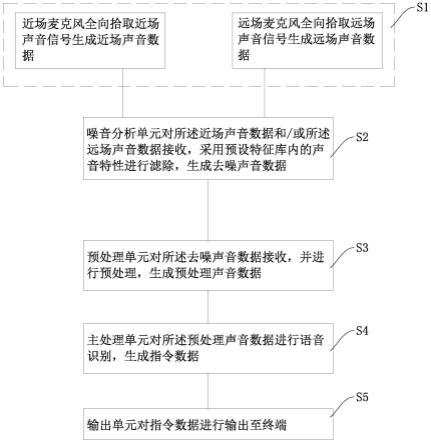
7.s1、通过近场麦克风全向拾取近场声音信号生成近场声音数据、通过远场麦克风全向拾取远场声音信号生成远场声音数据;
8.s2、噪音分析单元对所述近场声音数据和/或所述远场声音数据接收,采用预设特征库内的声音特性进行滤除,生成去噪声音数据;
9.s3、预处理单元对所述去噪声音数据接收,并进行预处理,生成预处理声音数据;
10.s4、主处理单元对所述预处理声音数据进行语音识别,生成指令数据;
11.s5、输出单元对指令数据进行输出至终端。
12.优选的,所述预设特征库内的声音特性包括时间特性、波形特性、频谱特性。
13.优选的,若s2中采用时间特性作为所述声音特性进行滤除条件,则包括如下步骤:
14.s21、判断所述近场声音数据和/或所述远场声音数据的时间长度是否满足进行滤除操作的预设时间长度,若不满足,则作为噪音滤除;
15.若满足,则生成所述去噪声音数据。
16.优选的,若s2中采用波形特性作为所述声音特性进行滤除条件,则包括如下步骤:
17.s22、判断所述近场声音数据和/或所述远场声音数据的波形振幅是否满足进行滤除操作的预设波形特征,若不满足,则作为噪音滤除;
18.若满足,则生成所述去噪声音数据。
19.优选的,判断所述波形振幅是否满足进行滤除操作的预设波形特征,包括如下步骤:
20.s221、采集所述近场声音数据和/或所述远场声音数据中位于0~2秒内的短波形振幅,判断是否满足进行滤除操作的预设波形特征,若不满足,则作为噪音滤除;
21.若满足,则进行s222步骤,包括:
22.s222、采集所述近场声音数据和/或所述远场声音数据中位于3~6秒内的长波形振幅,判断是否满足进行滤除操作的预设波形特征,若不满足,则作为噪音滤除;
23.若满足,则生成所述去噪声音数据。
24.优选的,若s2中采用频谱特性作为所述声音特性进行滤除条件,则包括如下步骤:
25.s23、判断所述近场声音数据和/或所述远场声音数据的频谱强度是否满足进行滤除操作的预设频谱特征,若不满足,则作为噪音滤除;
26.若满足,则生成所述去噪声音数据。
27.优选的,所述s3中还包括:
28.增益单元,所述预处理单元对所述去噪声音数据进行预处理后并经所述增益单元进行增益,生成所述预处理声音数据。
29.优选的,所述s5中还包括:
30.通信单元,所述输出单元与通信单元连接,通过所述通信单元将所述指令数据进行压缩后发送至所述终端。
31.采用了上述技术方案后,本发明的有益效果是:
32.本发明中,公开了应用于人机交互中的远近场拾音方法,包括:s1、通过近场麦克风、远场麦克风全向拾取近场声音信号、远场声音信号,生成近场声音数据、远场声音数据;s2、噪音分析单元进行滤除,生成去噪声音数据;s3、预处理单元生成预处理声音数据;s4、主处理单元生成指令数据;s5、输出单元输出至终端。本发明中,采用近场麦克风、远场麦克风对语音指令进行分别拾取,使语音指令输入不受距离影响,针对远端语音指令,能够及时接收,防止发生指令丢失情况,提高指令输入的稳定性;同时,通过噪音分析单元进行滤除,滤除语音指令中的环境噪音数据,降低环境噪音对指令输入的影响,提高指令输入的准确性,保证指令操作的正常执行。
附图说明
33.下面结合附图和实施例对本发明进一步说明。
34.图1是本发明实施例的流程图。
具体实施方式
35.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
36.如图1所示,本发明包括如下步骤:
37.s1、通过近场麦克风全向拾取近场声音信号生成近场声音数据、通过远场麦克风全向拾取远场声音信号生成远场声音数据;
38.s2、噪音分析单元对近场声音数据和/或远场声音数据接收,采用预设特征库内的声音特性进行滤除,生成去噪声音数据;
39.s3、预处理单元对去噪声音数据接收,并进行预处理,生成预处理声音数据;
40.s4、主处理单元对预处理声音数据进行语音识别,生成指令数据;
41.s5、输出单元对指令数据进行输出至终端。
42.本发明中,采用近场麦克风、远场麦克风对语音指令进行分别拾取,使语音指令输入不受距离影响,针对远端语音指令,能够及时接收,防止发生指令丢失情况,提高指令输入的稳定性;同时,通过噪音分析单元进行滤除,滤除语音指令中的环境噪音数据,降低环境噪音对指令输入的影响,提高指令输入的准确性,保证指令操作的正常执行。
43.其中,噪音分析单元对近场声音数据和/或远场声音数据进行全程接收,并采用预设特征库内的声音特性进行滤除。
44.预设特征库内的声音特性包括时间特性、波形特性、频谱特性。
45.其中,若s2中采用时间特性作为声音特性进行滤除条件,则包括如下步骤:
46.s21、判断近场声音数据和/或远场声音数据的时间长度是否满足进行滤除操作的预设时间长度,若不满足,则作为噪音滤除;
47.若满足,则生成去噪声音数据。
48.预设时间为0~2秒,针对近场声音数据和/或远场声音数据包含的瞬时声音,其拾音数据作为噪音,进行滤除。
49.若s2中采用波形特性作为声音特性进行滤除条件,则包括如下步骤:
50.s22、判断近场声音数据和/或远场声音数据的波形振幅是否满足进行滤除操作的预设波形特征,若不满足,则作为噪音滤除;
51.若满足,则生成去噪声音数据。
52.优选的,判断波形振幅是否满足进行滤除操作的预设波形特征,包括如下步骤:
53.s221、采集近场声音数据和/或远场声音数据中位于0~2秒内的短波形振幅,判断是否满足进行滤除操作的预设波形特征,若不满足,则作为噪音滤除;
54.若满足,则进行s222步骤,包括:
55.s222、采集近场声音数据和/或远场声音数据中位于3~6秒内的长波形振幅,判断是否满足进行滤除操作的预设波形特征,若不满足,则作为噪音滤除;
56.若满足,则生成去噪声音数据。
57.若s2中采用频谱特性作为声音特性进行滤除条件,则包括如下步骤:
58.s23、判断近场声音数据和/或远场声音数据的频谱强度是否满足进行滤除操作的预设频谱特征,若不满足,则作为噪音滤除;
59.若满足,则生成去噪声音数据。
60.优选的,s3中还包括:
61.增益单元,预处理单元对去噪声音数据进行预处理后并经增益单元进行增益,生成预处理声音数据。
62.s5中还包括:
63.通信单元,输出单元与通信单元连接,通过通信单元将指令数据进行压缩后发送至终端。
64.在本发明中,通信单元为有线传输通信单元、无线传输通信单元,无线传输通信单元为wifi通信单元、蓝牙通信单元、低功耗蓝牙通信单元等。
65.终端中自带有扬声器,人机交互过程中,需要获得的结果,可以通过扬声器进行输出。
66.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。