用于下一代测序样品中的污染检测的系统和方法
1.相关申请的交叉引用无。
2.以引用方式并入本说明书中提到的所有出版物和专利申请都以引用方式并入本文,所达到的程度如同每个单独的出版物或专利申请都被具体地和单独地指出以引用方式并入。
技术领域
3.本发明的实施例总体上涉及用于下一代测序的系统和方法,且更具体地涉及用于下一代测序样品中的污染检测的系统和方法。
背景技术:
4.新一代测序技术 (ngs) 已发展到可用于各种应用中的诊断分析,诸如载体筛选、传染病以及癌症检测和/或分析。在某些应用中,测序靶表(其可以是例如癌症中的突变(即,变体))可以以非常低的量存在于样品中。当靶标以如此低的量存在于样品中时,产生假阳性的风险会增加。
5.假阳性的一个潜在来源是测序错误。例如,原始读取准确度为 90% 的序列发生器预计对于通过一次通过确定的序列将会产生许多错误,从而难以区分错误与实际突变。减少这种测序错误的一种方式是通过多次测序靶标来确定共有序列,从而获得所需的共有序列准确度(即,例如,99%、99.9% 或 99.99%)。
6.假阳性的另一个来源可能是样品污染(即,样品交叉污染)。然而,在现有技术中描述的用于检测样品间污染的方法很少。因此,将希望系统和方法能够检测 ngs 样品中的污染,以降低假阳性的风险。
技术实现要素:
7.本发明总体上涉及用于下一代测序的系统和方法,且更具体地涉及用于下一代测序样品中的污染检测的系统和方法。
8.在一些实施例中,提供了一种用于检测污染的方法。该方法可以包括接收包括来自受试者的经测序样品的变体列表的电子文件;计算频率范围内针对一组变体的一组替代等位基因频率;基于对该一组替代等位基因频率的分析来确定该样品是否被污染;如果该样品未被污染,则至少部分地基于该变体列表施用药物;并且如果该样品被污染,则获得包括第二变体列表的未污染的经测序样品,并且至少部分地基于该第二变体列表施用药物。
9.在一些实施例中,该频率范围在 0 与 0.25 之间。在一些实施例中,该频率范围在 0 与 0.1 之间。
10.在一些实施例中,对该一组替代等位基因频率的分析包括将替代等位基因频率拟合至聚类模型。在一些实施例中,该聚类模型是混合模型。在一些实施例中,该混合模型是 β 混合模型。
11.在一些实施例中,该方法进一步包括确定替代等位基因频率中的任一者是否是异常值,并在对替代等位基因频率的分析之前从该一组替代等位基因频率中移除任何异常值。
12.在一些实施例中,确定替代等位基因频率中的任一者是否为异常值的步骤包括局部异常值因子计算。
13.在一些实施例中,该方法进一步包括通过对替代等位基因频率的所述分析来确定污染水平。
14.在一些实施例中,确定污染水平的步骤包括将替代等位基因频率拟合到混合模型。
15.在一些实施例中,该方法进一步包括确定围绕污染水平的置信水平。
16.在一些实施例中,确定置信水平包括自举变体及相应的替代等位基因频率。
17.在一些实施例中,该药物是癌症药物。
18.在一些实施例中,该癌症药物在具有特定变体的患者上比在没有该特定变体的患者上表现更好。
19.在一些实施例中,对该样品测序达至少 1000x 的平均测序深度。在一些实施例中,对该样品测序达至少 2000x 的平均测序深度。
20.在一些实施例中,提供了一种用于检测污染的系统。该系统包括处理器,该处理器经编程执行本文所述方法中的任一种方法中所列举的步骤。
21.在一些实施例中,提供了一种用于检测污染的方法。该方法可以包括接收包括来自受试者的经测序样品的变体列表的电子文件;计算频率范围内针对一组变体的一组替代等位基因频率;和基于对该一组替代等位基因频率的分析,确定该样品是否被污染。
22.在一些实施例中,提供了一种计算机产品。该计算机产品包括计算机可读介质,该计算机可读介质存储用于控制计算机系统执行以上所列举的方法中的任何方法的操作的多个指令。
23.在一些实施例中,提供了一种系统,该系统包括上述计算机产品;和一个或多个处理器,该一个或多个处理器用于执行存储在计算机可读介质上的指令。
附图说明
24.本发明的新颖特征在所附的权利要求书中具体阐述。通过参考以下具体实施方式并结合附图,可以更好地理解本发明的特征和优点,具体实施方式阐述了其中利用本发明原理的说明性实施例,在附图中:图 1 是示出被配置为实现本发明的一个或多个方面的计算机系统的一个实施例的框图。
25.图 2a 和 2b 示出了纯的、未污染的样品中的替代等位基因频率倾向于集中在三个水平附近:0.0 (aa)、0.5 (aa)、1.0 (aa)。
26.图 3a 至 3c 示出了纯样品的替代等位基因频率的低范围中的频率分布。
27.图 4a 至 4d 示出了被污染的样品的替代等位基因频率的低范围中的频率分布。
28.图 5a 至 5c 示出了靶向试剂盒小组的模拟结果;图 5d 至 5f 示出了扩展试剂盒小组的模拟结果;且图 5g 至 5i 示出了监视试剂盒小组的模拟结果。
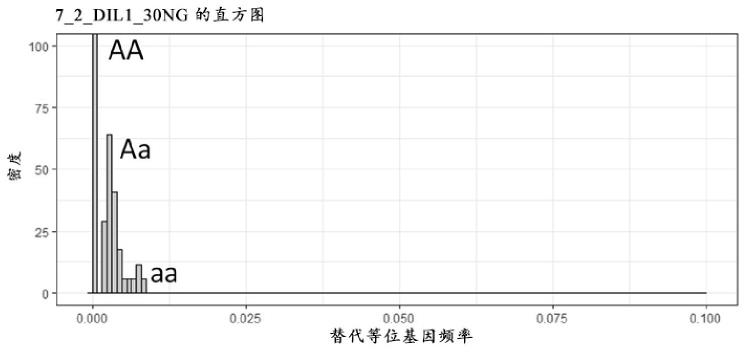
29.图 6 示出了直方图,其示出了被污染的样品的低范围内的替代等位基因频率的分布。
30.图 7a 示出了所预测的污染水平的平均值。
31.图 7b 示出了使用 1000 次自举的置信水平。
32.图 8a 示出了 1000 个合成样品的性能,这些样品具有单一污染源,并被测序至典型的覆盖深度。
33.图 8b 至 8f 示出了增加低污染水平(小于 1% 的污染)的 10,000 个样品的测序覆盖率的效果。
34.图 9a 示出了利用五个污染源的方法的性能,这些污染源被测序到典型的覆盖深度。
35.图 9b 至 9f 示出了改变测序深度对具有五个污染源的 10000 个合成样品的影响,这五个污染源总计达小于 1% 的低污染。
36.图 10 示出了所预测的污染水平与指定的污染水平相当,其中皮尔逊相关系数为 0.94。
具体实施方式
37.识别样品交叉污染在所有下一代测序 (ngs) 应用中都很重要,尤其是旨在检测以低频率存在于样品中的体细胞突变或任何其他变型的那些,如用于各种应用(诸如癌症检测和/或分析)的液体活检。在此类应用中,污染可能导致关键突变的假阳性结果,并对患者造成伤害,例如,导致患者被给予不必要的治疗或被开具无效或次优的药物处方。然而,在公共领域中可用的用于检测样品间污染的方法非常少。本文描述了一种基于 β 混合建模的统计方法,所述统计方法用于检测污染并报告污染水平,作为液体活检样品的点估计值和置信区间两者。我们通过计算机模拟和体外污染加标样品两者验证了我们的方法。尽管我们专注于液体活检样品,但同样的策略经过小幅修改,适用于任何一般的 ngs 应用。例如,可以根据本文所述的系统和方法使用来自活检的组织样品。
38.i. 下一代测序技术如上所指示,将测序分析作为确定多个微卫星位点的测序读段的程序的一部分,对所制备的靶标核酸分子(例如,测序文库)测序。可利用多种测序技术或测序分析中的任何一种。如本文所用,术语“新一代测序 (ngs)”指允许克隆扩增的分子和单个核酸分子大规模平行测序的测序方法。
39.适合与本文公开的方法一起使用的序列测定的非限制性实例包括纳米孔测序(美国专利公开号 2013/0244340、2013/0264207、2014/0134616、2015/0119259 和 2015/0337366)、桑格测序、毛细管阵列测序、热循环测序(sears 等人,《生物技术》(biotechniques) 13:626-633 (1992))、固相测序(zimmerman 等人,《分子细胞生物学方法》(methods mol. cell biol) 3:39-42 (1992))、用诸如基质辅助激光解吸/电离飞行时间质谱的质谱法测序(maldi-tof/ms;fu 等人,《自然生物技术》(nature biotech) 16:381-384 (1998))、通过杂交测序(drmanac 等人,《自然生物技术》16:54-58 (1998))和 ngs 方法,包括但不限于通过合成测序(例如,hiseq
™
、miseq
™ꢀ
或 genome analyzer,均可从 illumina 获得)、通过连接测序(例如 solid
™
、life technologies)、离子半导体测
序(例如,ion torrent
™
、life technologies)和 smrt
®ꢀ
测序(例如 pacific biosciences)。
40.市售的测序技术包括 affymetrix 有限公司(加利福尼亚州森尼维耳市)的边杂交边测序平台、illumina/solexa(加利福尼亚州圣地亚哥市)和 helicos biosciences(马萨诸塞州坎布里奇市)的边合成边测序平台、applied biosystems(加利福尼亚州福斯特城)的边连接边测序平台。其他测序技术包括但不限于 ion torrent 技术(thermofisher scientific)和纳米孔测序(加利福尼亚州圣克拉拉市 roche sequencing solutions 的 genia technology);以及 oxford nanopore technologies(英国牛津)。
41.ii. 用于实现算法的示例性计算机系统可以在计算机系统上实现本文所述的算法。例如,图 1 是示出被配置为实现本发明的一个或多个方面的计算机系统 100 的一个实施例的框图。如图所示,计算机系统 100 包括但不限于中央处理单元 (cpu) 102 和系统存储器 104,该系统存储器经由存储器桥 105 和通信路径 113 耦接到并行处理子系统 112。存储器桥 105 经由通信路径 106 进一步耦接到 i/o (输入/输出)桥 107,并且 i/o 桥接 107 转而耦接到交换机 116。
42.在操作中,i/o 桥 107 被配置为从输入设备 108(例如,键盘、鼠标、视频/图像捕获设备等)接收用户输入信息并将该输入信息转发给 cpu 102 用于经由通信路径 106 和存储器桥 105 进行处理。在一些实施例中,该输入信息是来自相机/图像捕获设备的实时馈送或存储在对象检测操作在其上执行的数字存储介质上的视频数据。交换机 116 被配置为在 i/o 桥 107 与计算机系统 100 的其他部件(诸如网络适配器 118 和各种扩展卡 120 和 121)之间提供连接。
43.又如图所示,i/o 桥 107 耦接到系统盘 114,该系统盘可以被配置为存储内容和应用程序以及供 cpu 102 和并行处理子系统 112 使用的数据。一般来讲,系统盘 114 为应用程序和数据提供非易失性存储,并且可以包括固定或可移动硬盘驱动器、闪存设备和 cd-rom(光盘只读存储器)、dvd-rom(数字通用光盘-rom)、蓝光光盘、hd-dvd(高清 dvd)或其他磁性、光学或固态存储设备。最后,尽管没有明确示出,但是诸如通用串行总线或其他端口连接件、光盘驱动器、数字通用光盘驱动器、影片录音设备等之类的其他部件也可以连接到 i/o 桥 107。
44.在各种实施例中,存储器桥 105 可以是北桥芯片,并且 i/o 桥 107 可以是南桥芯片。此外,通信路径 106 和 113 以及计算机系统 100 内的其他通信路径可以使用任何技术上合适的协议来实现,这些协议包括但不限于 agp (加速图形端口)、超传输或本领域已知的任何其他总线或点对点通信协议。
45.在一些实施例中,并行处理子系统 112 包括将像素传送到显示设备 110 的图形子系统,该显示设备可以是任何常规的阴极射线管、液晶显示器、发光二极管显示器等。在此类实施例中,并行处理子系统 112 中并入了针对图形和视频处理而优化的电路,包括例如视频输出电路。此类电路可以跨一个或多个包括在并行处理子系统 112 中的并行处理单元 (ppu) 进行并入。在其他实施例中,并行处理子系统 112 中并入了针对通用和/或计算处理而优化的电路。同样,此类电路可以跨一个或多个包括在并行处理子系统 112 中的 ppu 进行并入,该一个或多个 ppu 被配置为执行此类通用和/或计算操作。在还有其他实施例中,该一个或多个包括在并行处理子系统 112 中的 ppu 可以被配置为执行图形处
至 75%、30% 至 70%、35% 至 65%、40% 至 60% 或 45% 至 55% 之间)。在其他实施例中,可以分析低范围、中间范围和高范围替代等位基因频率的任何组合,以便从被污染的样品中识别纯的、未污染的样品。换句话说,在一些实施例中,可以使用从 0 到 100% 的全频率范围,或者全频率范围的任何部分或多个部分的组合。
53.为了构建模型,我们使用了 1000 个基因组计划 (tgp) 数据,并识别和选择了群体替代等位基因频率超过 0.5% 但低于 99.5% 的常见 snv。因此,我们在靶向、扩展和监视 avenio
®ꢀ
ctdna 分析试剂盒液体活检小组内选择了 285、868 和 707 种常见 snv。从 tgp 选择 625 个相关受试者用于该模型,且所作选择反映了美国群体:白人 (68.2%)、西班牙裔或拉丁裔 (15.4%)、黑人 (11.9%) 和亚裔 (4.5%)。在其他实施例中,被选择用于模型的群体可以代表国家、州、县、省、地区、洲等中的群体。例如,选择时所考虑的因素可以包括种族、民族、性别、年龄和/或地点。在一些实施例中,选择至少 100、200、300、400、500、600、700、800、900 或 1000 个 snv 用于该模型。在一些实施例中,选择至多 100、200、300、400、500、600、700、800、900 或 1000 个 snv 用于该模型。在一些实施例中,提供覆盖更多基因的更多测序数据的较大的小组产生了能够被选择用于该模型的更多 snv。在一些实施例中,小组覆盖至少 5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、200、300、400、500、600、700、800、900 或 1000 个基因。在一些实施例中,小组覆盖至多 5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、200、300、400、500、600、700、800、900 或 1000 个基因。在一些实施例中,较大的小组使 snv 的选择标准更严格。例如,群体替代等位基因频率在 5% 至 95%、10% 至 90%、15% 至 85%、20% 至 80%、25% 至 75%、30% 至 70%、35% 至 65%、40% 至 60% 或 45% 至 55% 之间的常见 snv 可被选择用于该模型,并产生足够数量的 snv。在一些实施例中,可以基于小组的大小来确定群体替代频率范围。
54.在一些实施例中,该方法使用在液体活检样品中检测到的替代等位基因频率的较低范围 (≤ 25%) 来对信息性基因座进行建模。基于每个小组的 10,000 次模拟,在选择了随机的靶标受试者和随机的污染受试者情况下,我们显示出,使用三个小组中的每一个小组处理的具有单一污染源的样品中,我们预期的信息性 snv 平均为 21(靶向试剂盒)、70(扩展试剂盒)和 54(监视试剂盒)。图 5a 至 5c 示出了靶向试剂盒小组的模拟结果;图 5d 至 5f 示出了扩展试剂盒小组的模拟结果;且图 5g 至 5i 示出了监视试剂盒小组的模拟结果。在一些实施例中,在被选择用于分析具有单一污染源的样品的 snv 总数中,至少有 5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95 或 100 个信息性 snv。
55.然后,我们确定信息性 snv 的替代等位基因频率,并使用 3 组分 β 混合为模型对它们进行建模,以用于污染检测。通用 β 混合模型的概率密度函数具有以下形式:f(x
│
π1,π2,α0, β0, α1, β1, α2, β2) = (1
ꢀ−ꢀ
π1ꢀ−ꢀ
π2)β(x
│
α0, β0) π
1 β(x
│
α1, β1) π
2 β(x
│
α2, β2)对于纯的样品,低替代等位基因频率范围的直方图图在 0.0 处仅具有单一峰值(未示出),而假设单一污染源,被污染的样品将具有两个至三个峰值,包括 0.0 (aa ) 处的峰值,如图 6 所示。假设 snv 是独立的,并且仅具有一个污染源,则该模型将具有总计三个 β 分量:(1) 背景 aa 污染 (aa);(2) 背景 aa 污染 aa;及 (3) 背景 aa 污
染 aa。
56.我们假设每个 snv 是独立的,每个 snv 在相同深度(,计算为选定位点的平均测序深度)被测序,并且仅存在一个污染源。因此,可以使用以下简化来减少模型中的参数数量:(1) 如图 6 在 0.0 替代等位基因频率(即,污染 aa 的背景 aa)处所示的第一个 β 分量用 α0=1、β0=10
4 直接参数化。我们期待具有急剧尖峰 (β0=104) 的严格递减分布 (α0=1),作为狄拉克 δ 分布的替代形式,但也允许出现测序错误。(2) 第二个 β 分量对应于背景 aa 和污染 aa。属于该分量的每个 snv 的替代等位基因的预期数量被参数化为 α1,并且每个位点的等位基因总数被设置为所有所选择的 snp 的平均覆盖深度 。每个 snv 在相同深度被测序。等效地,α1 β1=α2 β2=n,其中 n 被计算为每个样品所有所选择的 snv 的平均覆盖深度。(3) 第三个 β 分量对应于背景 aa 和污染 aa。由于 aa 有两个替代等位基因,因此属于该分量的每个 snp 的替代等位基因的预期数量为,其中每个位点剩余的等位基因总数为 。使用最大似然估计在替代等位基因频率上拟合 β 混合模型。换句话说,纯合子污染分布 (aa) 的中心是杂合子污染分布 (aa) 的中心的两倍,或者由于两个替代等位基因而为 α2=2α1。
57.通过上述简化,自由参数的数量从八个减少到三个,并且通用 β 混合模型被简化为以下方程:f(x
│
π1, π2, α1) = (1
−
π1−
π2)β(x
│
1, 104) π
1 β(x
│
α1, n
−
α1) π
2 β(x
│
2α1, n
−
2α1) f(x|π1, π2, α1)= (1
−
π1−
π2)β(x
│
1, 104) π
1 β(x|α1, n
−
α1) π
2 β(x
│
2α1, n
−
2α1)可使用似然函数
ꢀℒꢀ
(π1,2, α1│
x)=,使用拟牛顿法(即,具有边界约束的有限内存 broyden
–
fletcher
–
goldfarb
–
shannon 算法)来估计或确定具有最大似然性的 β 混合模型的参数 π1、π2、α1。可使用多重初始化来避免局部最大值。
58.由于最大似然估计方法对异常值(例如,测序错误和体细胞突变)敏感,因此我们使用局部异常因子 (lof) 在模型拟合之前去除异常值,从而产生对污染水平进行更稳健的估计。lof 测量一个点与其 k 个最近邻点相比的局部密度 (lrd)。
59.lof 》 1 意味着点 a 的局部密度小于其相邻点的平均局部密度,表明 a 可能是异常值。我们使用 k=5,lof 的截止值 = 3。
60.在一些实施例中,异常值检测的其他方法是可能的。例如,在一些实施例中,异常值检测方法可以是单变量或多变量的。在一些实施例中,异常值检测方法可以是参数的或非参数的。在一些实施例中,异常值检测方法可以是 z 分数或极值分析(参数的)、概率和统计建模(参数的)、线性回归模型、基于邻近度的模型、信息论模型、高维异常值检测方法、神经网络、贝叶斯网络、隐马尔可夫模型、基于模糊逻辑的方法和/或集成技术。
61.然后,将污染水平的点估计值估计为 2α1/n(即,第三个 β 分量的平均值,纯合子污染分布 aa)。图 7a 示出了,对于该实例,指定的污染水平 (0.5%) 与所预测的污染水平 (0.54%) 一致。通过自举 snv 位点(即,非参数自举)及其相应的替代等位基因频率构建污染水平的置信区间。图 7b 示出了对于 1000 次自举,该示例的污染水平的 90% 置信区间
是 (0.49%, 0.63%)。在存在测序错误的情况下,我们的方法的理论检测极限是至少是 (当
ꢀꢀ
或者每个位点至多一个测序错误时)。当每个位点的测序错误数量变得更大时(即测序错误率变得更大),该极限变得更大。为了得到更保守和更少的假阳性结果,我们仅报告所预测的污染水平大于 。在一些实施例中,使用至少 100、200、300、400、500、600、700、800、900、1000、1100、1200、1300、1400、1500、1600、1700、1800、1900、2000、3000、4000、5000、6000、7000、8000、9000 或 10000 次自举来产生置信区间。
62.对来自 tgp 的 30,000 个计算机合成样品的综合模拟研究表明,该方法的性能随着测序深度的增加而提高,并且对于来自扩展 avenio 试剂盒的深度经测序样品,其假阳性率和检测极限分别低至 0.02% 及 0.09%(表 1)。靶标个体和污染个体(一个污染源)是再次来自从 1000 个基因组项目中选择的群体中的样品。我们用二项分布为每个 snv 合成了多个( 个)替代等位基因。
63.其中
ꢀꢀ
是所有位点的平均测序深度,且
ꢀꢀ
是基于污染水平和特定位点的理论替代等位基因频率。对于
ꢀꢀ
或 ,我们将其调整为
ꢀꢀ
或
ꢀꢀ
以说明测序错误。然后计算每个位点的替代等位基因频率。更一般地,为了说明测序错误,p 可以被调整一个量,该量对应于系统的测序错误的预期幅度。在一些实施例中,这可能是共有测序错误。
64.在一些实施例中,测序深度覆盖率小于 25x、50x、75x、100x、200x、300x、400x、500x、600x、700x、800x、900x、1000x、2000x、3000x、4000x、5000x、6000x、7000x、8000x、9000x 或 10000x。在一些实施例中,覆盖率是至少 25x、50x、75x、100x、200x、300x、400x、500x、600x、700x、800x、900x、1000x、2000x、3000x、4000x、5000x、6000x、7000x、8000x、9000x 或 10000x。
65.在一些实施例中,合成数据包括 0 至 50% 污染之间的各种污染水平的样品。高于 50% 的污染,背景污染成为前景,因此没有必要模拟高于 50% 的污染水平。在一些实施例中,模拟的污染水平小于 50%、40%、30%、20%、10%、5%、4%、3%、2% 或 1%。图 8a 示出了 1000 个合成样品的性能,这些样品具有单一污染源,并被测序至典型的覆盖深度。
66.当污染水平低(即,小于 1%)时,性能在测序覆盖率小于约 2000x 时开始下降,如图 8b 至 8f 所示。图 8b 至 8f 示出了增加低污染水平(小于 1% 的污染)的 10,000 个样品的测序覆盖率的效果。
67.在多个污染源的情况下,尽管违反了模型的一个假设(即,一个污染源),该方法仍然能够标记比预期所预测的污染水平低的被污染的样品。为了评估该方法对于多个污染源的性能,产生了 1000 个具有五个污染源的合成样品数据,其中来自每个污染源的污染水平被随机化,且来自五个污染源的总污染水平为 0 至 50%。图 9a 示出了利用五个污染源的方法的性能,这些污染源被测序到典型的覆盖深度。图 9b 至 9f 示出了改变测序深度对具有五个污染源的 10000 个合成样品的影响,这五个污染源总计达小于 1% 的低污染。同样,当测序覆盖率小于 2000x 时,性能开始下降。
68.我们提出的方法进一步用 103 个体外加标血浆样品(一个污染源,0% 至 8% 的污染水平)进行了评价,这些样品用圣何塞的 clia 实验室的扩展 avenio 试剂盒处理。所
预测的污染水平与指定的污染水平相当,其中皮尔逊相关系数为 0.94,如图 10 所示。
69.表 1.在扩展 avenio 试剂盒的 30,000 个计算机合成数据上,对于样品污染所建议的方法的性能。fpr
ꢀ–ꢀ
假阳性率;lod
ꢀ–ꢀ
检测的极限;ci
ꢀ–ꢀ
clopper-pearson 精确置信区间。以 99.9% 的检测率用机率单位回归确定 lod。平均覆盖深度fpr1个来源lod(95%ci)5个来源lod(95%ci)《1000x0.135%0.97%(0.89%
–
1.09%)2.12%(1.97%
–
2.35%)1000x
–
2000x0.056%0.36%(0.33%
–
0.40%)1.27%(1.18%
–
1.40%)2000x
–
3000x0.035%0.12%(0.11%
–
0.13%)0.80%(0.74%
–
0.89%)3000x
–
4000x0.025%0.09%(0.09%
–
0.10%)0.57%(0.52%
–
0.64%)》4000x0.020%0.09%(0.09%
–
0.09%)0.41%(0.36%
–
0.48%)
70.这里描述的统计方法可以整合到任何为测序组内的大量位点产生替代等位基因频率的管线内。它有助于识别和并使得能够正确处理被污染的样品,从而大大提高分析结果的可信度。
71.i
ⅴ
. 治疗方法在一些实施例中,本文所述的系统和方法可用于基于对变体的正确识别而非基于来自样品污染的变体来指导对患者的治疗。例如,可以基于所识别的变体来选择癌症疗法,诸如施用癌症药物。在一些实施例中,某些治疗可能被排除,因为变体已被识别为源自或潜在源自样品污染。在一些实施例中,当检测到样品污染时,对患者进行重新测试(即,对样品重新测序),并且仅在重新测试和/或确认样品未被污染之后选择并给予适当的疗法。
72.当特征或要素在本文中被称为在另一特征或要素“上”时,它可以直接在另一特征或要素上,或者也可以存在中间特征和/或要素。相反,当特征或要素被称为“直接在”另一特征或要素“上”时,则不存在中间特征或要素。还将理解,当特征或要素被称为“连接”、“附接”或“耦接”至另一特征或要素时,它可以直接连接、附接或耦接至另一特征或要素,或者可以存在中间特征或要素。相反,当特征或要素被称为“直接连接”、“直接附接”或“直接耦接”至另一特征或要素时,则不存在中间特征或要素。尽管对于一个实施例进行了描述或示出,但是如此描述或示出的特征和要素可以应用于其他实施方案。本领域的技术人员还将认识到,提及与另一特征“相邻”设置的结构或特征可以具有与相邻特征重叠或位于其之下的部分。
73.本文所使用的术语仅出于描述特定实施方案的目的,而并非旨在限制本发明。例如,如本文所用,单数形式“一个”、“一种”和“该”也旨在包括复数形式,除非上下文另外明确地指出。还将进一步理解,当在本说明书中使用术语“包括”和/或“包含”时,其指定了所规定的特征、步骤、操作、要素和/或组分的存在,但并不排除存在或添加一个或多个其他特征、步骤、操作、要素、组分和/或它们的组。如本文所用,术语“和/或”包括相关联的列出项目中的一者或多者的任何组合和所有组合,并且可以缩写为“/”。
74.为了便于描述,在本文中可以使用空间上相对的术语,诸如“下方”、“下面”、“低于”、“上方”、“上面”等,以描述一个要素或特征与另外的要素或特征的关系,如附图中所展示。应当理解,除了附图中描绘的取向之外,空间上相对的术语还旨在涵盖装置在使用或操作中的不同取向。例如,如果附图中的装置是倒置的,则描述为在其他要素或特征“下方”或“之下”的要素于是将定向为在其他要素或特征“上方”。因此,示例性术语“下方”可以涵盖“上方”和“下方”这两个取向。可以以其他方式定向该装置(旋转90度或以其他取向),并且据此解释本文所用的空间上相对的描述语。类似地,除非另外具体地指出,否则“向上”、“向下”、“垂直的”、“水平的”等术语在本文中仅用于解释的目的。
75.尽管本文可以使用术语“第一”和“第二”来描述各种特征/要素(包括步骤),但是除非上下文另外指出,否则这些特征/要素不应受这些术语的限制。这些术语可以用于将一个特征/要素与另一个特征/要素区分开。因此,在不脱离本发明的教导内容的情况下,下面讨论的第一特征/要素可以被称为第二特征/要素,并且类似地,下面讨论的第二特征/要素可以被称为第一特征/要素。
76.在整个本说明书和随后的权利要求书中,除非上下文另外要求,否则词语“包括”和诸如“包含”和“含有”的变型意味着可以在方法和物品(例如,组合物以及包括装置和方法的设备)中共同采用各种组分。例如,术语“包括”将被理解为暗示包括任何所规定的要素或步骤,但是不排除任何其他要素或步骤。
77.如本文在说明书和权利要求书中所用,包括如在示例中所用,并且除非另外明确地指定,否则所有数字都可以被解读为好像前面有词语“约”或“大约”,即使该术语没有明确地出现。当描述幅度和/或位置时,可以使用短语“约”或“大约”来指示所描述的值和/或位置在值和/或位置的合理预期范围内。例如,数值可以具有为规定值(或值的范围)的 /
‑ꢀ
0.1%、规定值(或值的范围)的 /
‑ꢀ
1%、规定值(或值的范围)的 /
‑ꢀ
2%、规定值(或值的范围)的 /
‑ꢀ
5%、规定值(或值的范围)的 /
‑ꢀ
10% 等的值。除非上下文另外指出,否则本文给出的任何数值也应当被理解为包括约或大约该值。例如,如果公开了值“10”,则还公开了“约 10”。本文叙述的任何数值范围旨在包括其中所包含的所有子范围。还应当理解,如本领域技术人员适当理解的那样,当公开了某个值时,则还公开了“小于或等于”该值、“大于或等于该值”以及值之间的可能范围。例如,如果公开了值“x”,则还公开了“小于或等于 x”以及“大于或等于 x”(例如,在 x 是数值的情况下)。还应当理解,在整个本技术中,数据以多种不同格式提供,并且该数据表示端点和起点以及数据点的任何组合的范围。例如,如果公开了特定数据点“10”和特定数据点“15”,则应当理解,大于、大于或等于、小于、小于或等于、等于 10 和 15 以及介于 10 和 15 之间的值被认为是公开的。还应当理解,还公开了两个特定单元之间的每个单元。例如,如果公开了 10 和 15,则还公开了 11、12、13 和 14。
78.尽管上面描述了各种说明性实施方案,但是在不脱离如权利要求书所描述的本发明范围的情况下,可以对各种实施方案进行多种改变中的任一种。例如,在替代性实施方案中,可以经常改变执行所描述的各种方法步骤的顺序,而在其他替代性实施方案中,可以完全跳过一个或多个方法步骤。在一些实施方案中,可以包括各种装置和系统实施方案的任选特征,而在其他实施方案中可以不包括。因此,前面的描述主要是为示例性目的而提供的,并且不应当解释为限制在权利要求书中阐述的本发明范围。
79.本文所包括的示例和图示以图示而非限制的方式示出了其中可以实践本主题的具体实施方案。如所提及的,可以利用其他实施方案并且从中得出其他实施方案,使得可以在不脱离本公开范围的情况下进行结构上和逻辑上的代替和改变。本发明主题的这些实施方案在本文可以单独或共同地由术语“本发明”来指代,这仅仅是为了方便,而并非要在实际上公开了多于一个本发明构思的情况下将本技术的范围主动限制于任何单个本发明构思。因此,尽管本文已经展示和描述了具体实施方案,但是为实现相同目的而计算的任何布
置可以代替所示的具体实施方案。本公开旨在覆盖各种实施方案的任何和所有的修改或变型。在回顾以上描述之后,以上实施方案的组合以及本文未明确描述的其他实施方案对于本领域的技术人员将是显而易见的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。