1.本发明属于药物预测技术领域,具体涉及一种应用内源性物质预测肾移植药物剂量的模型的构建方法。
2.
背景技术:
3.钙调神经磷酸酶抑制剂 (cnis) 自20世纪80年代问世以来,已经成为目前临床常用的治疗干预手段,改善了移植患者的结局,提高了移植患者的生存率。目前,钙调神经磷酸酶抑制剂主要有环孢素、他克莫司、西罗莫司等。
4.然而,目前免疫抑制剂的治疗窗窄,不同个体间药动学和药效学差异大。剂量过高容易免疫抑制过度,增加严重感染的风险;剂量过低,容易免疫抑制不足,从而增加移植器官发生排斥反应的风险。因此给临床应用带来一定的困扰。
5.随着药物代谢组学技术的发展,通过分析给药前血浆或尿液代谢概况来预测药物不良反应或药物疗效已经成为研究的热点。药物吸收,分布,代谢和消除是体内的基本过程,可能受遗传 (如遗传多态性),生理状态和环境因素 (如饮食,年龄和吸烟) 的影响。内源性小分子作为基因与环境相互作用的最终产物,其代谢特征能够兼容更多的信息,而另一方面,部分免疫抑制剂主要通过抑制t淋巴细胞发挥免疫抑制作用,因此t淋巴细胞含量可以表征免疫抑制剂的药物生效情况。
6.现有技术中,若想检测药物生效情况需要监测免疫抑制剂的血药浓度,尤其是全血谷浓度,及时调整给药剂量,增加疗效,降低不良反应。但是,监测谷浓度需要严格采集定时血样,这对于临床繁忙的工作环境难以操作和实现。因此,需要一种方法能够建立一个预测免疫抑制剂优选剂量的模型。
7.
技术实现要素:
8.基于现有技术中存在的上述缺点和不足,本发明的目的之一是至少解决现有技术中存在的上述问题之一或多个,换言之,本发明的目的之一是提供满足前述需求之一或多个的一种应用内源性物质预测肾移植药物剂量的模型的构建方法。
9.为了达到上述发明目的,本发明采用以下技术方案:一种应用内源性物质预测肾移植药物剂量的模型的构建方法,包括以下步骤:s1、收集待测样本,将所述待测样本中的蛋白质沉淀;所述待测样本为个体使用免疫抑制剂后的血液样本;s2、将所述个体使用所述免疫抑制剂的效果分为高反应组、正常组和低反应组,所述效果根据t淋巴细胞含量判断;s3、使用质谱仪分析所述待测样本的代谢特征,所述代谢特征包括所述待测样本中的若干种内源性代谢物质含量;
s4、通过偏最小二乘法分析所述代谢特征与所述效果分组的相关性,筛选出与所述效果分组具有强相关性的代谢特征;s5、获取所述个体使用所述免疫抑制剂后的临床特征,所述临床特征包括所述个体的年龄、bmi、肾功能指标、肝功能指标、红细胞压积、白蛋白含量参数;s6、通过分析所述临床特征与所述效果分组的相关性,筛选出与所述效果分组具有强相关性的临床特征;s7、根据相关性分析和多项逻辑回归模型,以筛选后的所述代谢特征及所述临床特征与所述效果分组的相关性建立所述免疫抑制剂的药物剂量预测模型。
10.作为优选方案,所述使用质谱仪分析所述待测样本的代谢特征,具体包括如下步骤:s31、以随机方式分析所述待测样本,首先连续检测3-5个质控样本,然后每10个所述待测样本插入1个质控样本,且同时检测正离子和负离子模式;s32、在所述同时检测正离子和负离子模式下,通过预设数据库获得待测样本的碎片离子峰作为所述代谢特征。
11.作为优选方案,所述获得待测样本的碎片离子峰作为所述代谢特征之后还包括数据预处理过程s221:s321、对所述代谢特征进行峰提取、峰对齐、缺失值筛选、缺失值填补,并基于质控样本进行局部线性回归校正。
12.作为优选方案,所述步骤s4具体为通过两次独立的偏最小二乘法分析所述待测样本的代谢特征数据与所述效果的相关性进行筛选,包括以下步骤:s41、以所有检测鉴定到的碎片离子峰为基础变量,目标效应值为结局变量,建立第一个独立的偏最小二乘法模型;s42、通过第一个独立的偏最小二乘法模型,获得所述碎片离子峰对第一个独立的偏最小二乘法模型的首轮贡献指数;s43、筛选首轮贡献指数大于1.5的碎片离子峰作为候选变量,建立第二个独立的偏最小二乘法模型;s44、通过第二个独立的偏最小二乘法模型,获得所述候选变量对第二个独立的偏最小二乘法模型的二轮贡献指数;s45、筛选二轮贡献指数大于1的碎片离子峰作为目标变量,以目目标变量离子峰对应的内源性代谢物质作为筛选后的所述代谢特征。
13.作为优选方案,所述步骤s45之后还包括步骤s46:s46、通过相关性分析确定所述代谢特征与效果分组的相关性,以相关性的显著水平小于0.05为标准,缩小并优化代谢特征的范围。
14.作为优选方案,所述步骤s7具体包括s71、根据多项逻辑回归模型,从所述初选临床特征中进一步筛选得到筛选后的所述临床特征;通过多项逻辑回归,选用似然比检验实现变量筛选,将显著水平小于0.05的所述初选临床特征纳入最终回归方程。
15.s72、根据所述初选临床特征建立多项逻辑回归方程。
16.作为优选方案,所述方法还包括步骤s8、使用正交最小二乘法判别模型验证模型
的预测能力;具体包括:s81、使用筛选后的所述代谢特征及所述临床特征形成正交最小二乘法判别模型的协变量;s82、根据所述协变量构建正交最小二乘法判别模型,验证所述模型的预测能力。
17.作为优选方案,所述使用质谱仪分析所述待测样本的代谢特征的参数具体为:运用uplc-q-tof/mse质谱仪分析,飞行质谱采用esi源,毛细管电压2.5 kv,锥孔电压40 v,离子源温度100 ℃,脱溶剂温度450 ℃,锥孔反吹氮气流速50 l/h,脱溶剂气 (氮气) 流速800 l/h;扫描时间0.2 s,ms/ms二级质谱分析时碰撞能量设定为20-30 ev。质量扫描范围为50-1200 m/z;色谱柱选用hss t3柱 (100 mm
×
2.1 mm,1.8 μm);流动相为0.1 %甲酸水溶液 (溶剂a) 和乙腈 (溶剂b),梯度洗脱设置如下:0-0.5 min,5 % b;0.5-2 min,5-20 % b;2-3.5 min,20-27.5 % b;3.5-4 min,27.5-70 % b;4-7.5 min,70-75 % b;7.5-8.5,75-95 % b,8.5-13.5 min,95 % b,13.5-16 min,95-5 % b,16-18 min,5 % b;流速为0.3 ml/min,柱温为35 ℃,进样量2 μl。
18.作为优选方案,所述免疫抑制剂为他克莫司;所述若干种内源性代谢物质包括血清肌酐、胆红素原、l-异亮氨酸、5-甲氧基吲哚乙酸、二十碳五烯酸、n2-琥珀酰精氨酸、色氨酸精氨酸和丁酸。
19.另一方面,本发明提供一种免疫抑制剂剂量预测的方法,使用如上述任一项的方法所构建的模型,包括如下步骤:s1、将目标样本的参数代入所述模型,获得疗效预测结果;s2、根据所述疗效预测结果迭代药物剂量,获得不同疗效预测对应的药物剂量,实现剂量预测本发明与现有技术相比,有益效果是:(1)本发明的方法所构建的模型能够预测个体所适用的给药量,避免潜在的药物不良反应,有助于个体化给药;(2)本发明的方法所构建的模型,通过筛选代谢特征和临床特征,提高了变量的准确程度,具有优秀的预测能力,减少了过拟合风险。
20.附图说明
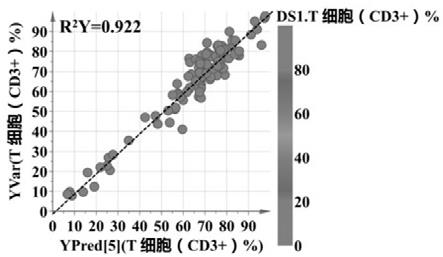
21.图1是本发明实施例的第一次偏最小二乘法模型的相关图;图2是本发明实施例的第一次偏最小二乘法模型的载荷图;图3是本发明实施例的第二次偏最小二乘法模型的相关图;图4是本发明实施例的置换检验的结果分析图;图5是本发明的正交最小二乘法判别模型的分析结果。
22.具体实施方式
23.为了更清楚地说明本发明实施例,下面将对照附图说明本发明的具体实施方式。
显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
24.实施例:本实施例的一种应用内源性物质预测肾移植药物剂量的模型的构建方法,首先收集个体使用免疫抑制剂后采集的血液样本,然后根据血液样本中代谢特征、临床特征与使用效果的相关性筛选出具有强相关的代谢特征和临床特征,并将二者结合进行预测模型的构建。
25.具体的,本实施例的方法首先进行步骤s1、收集待测样本,将待测样本中的蛋白质沉淀;待测样本为个体使用免疫抑制剂后采集的血液样本。在本实施例中,免疫抑制剂可以具体为他克莫司。
26.s2、将个体使用免疫抑制剂的效果分为高反应组、正常组和低反应组,效果根据t淋巴细胞含量判断。
27.t淋巴细胞的含量是免疫抑制剂疗效的体现,在移植排斥反应中起着重要的作用。血清肌酐、胱抑素c和肾小球率过滤是评价肾移植后肾脏功能的重要指标,经过临床研究后发现t淋巴细胞与肾脏功能指标中的血清肌酐、胱抑素c和肾小球滤过率有显著相关性,表明t淋巴细胞含量可表示肾移植患者在免疫抑制剂发挥免疫抑制作用后的疗效结果。
28.根据免疫抑制剂疗效的情况可以将用药效果分为三组,低反应组即所测t淋巴细胞百分比高于参考范围值上限 (n=16)、正常反应组即所测t淋巴细胞百分比在参考范围值内 (n=73) 和高反应组即所测t淋巴细胞百分比低于参考范围值下限 (n=20)。其中在高反应组更容易发生延迟复功 (p《0.05),低反应组与正常组在急性排斥反应发生率方面无显著差异,但是在低反应组急性排斥反应发生率远高于正常组。
29.s3、使用质谱仪分析待测样本的代谢特征,代谢特征主要包括待测样本中的若干种内源性代谢物质含量。内源性代谢物质即机体代谢过程中所形成的产物或中间产物,具体包括氨基酸类、脂类、脂肪酸、类固醇、激素、生物胺、单糖、双糖、羧酸等具体来说,药物可以影响代谢特征,而临床特征可以影响药物效果,因此结合临床特征和代谢特征可以更好的反应药物疗效。
30.进一步的,使用质谱仪分析待测样本可以包括以下步骤:s31、以随机方式分析待测样本,首先连续检测3-5个质控样本,然后每10个待测样本插入1个质控样本,且同时检测正离子和负离子模式;详细的,待测样本的分析可以使用以下方案:非靶向代谢组学分析在uplc-q-tof质谱仪上进行,质谱采用mse continuum模式,离子源:电喷雾电离模式 (esi),正离子和负离子模式均检测,毛细管电压2.5 kv,锥孔电压40 v,离子源温度100 ℃,脱溶剂温度450 ℃,锥孔反吹氮气流速50 l/h,脱溶剂气 (氮气) 流速800 l/h。扫描时间0.2 s;扫描间隔0.015 s,低通道碰撞能量6 ev;高通道碰撞能量20-30 ev。质量扫描范围为50-1200 m/z。
31.液相条件如下:样品在hss t3柱 (100 mm
×
2.1 mm,1.8 μm) 上分离。流动相为0.1 %甲酸水溶液 (溶剂a) 和乙腈 (溶剂b),梯度洗脱0-0.5 min,5 % b;0.5-2 min,5-20 % b;2-3.5 min,20-27.5 % b;3.5-4 min,27.5-70 % b;4-7.5 min,70-75 % b;7.5-8.5,75-95 % b,8.5-13.5 min,95 % b,13.5-16 min,95-5 % b,16-18 min,5 % b。流速为0.3 ml/min,柱温为35 ℃,进样量2 μl,自动进样器温度为10 ℃。
32.亮氨酸-脑啡肽 (5 ng/ml) 作为校正液随行于在整个分析中,用于判断仪器质量轴是否有偏差。此外,3-5个空白样品在正式进样前运行,用于平衡色谱柱并分析样品引入的背景离子。待测样本以随机方式于uplc-qtof-ms分析。待测样品分析前连续检测3-5个质控样品,然后每10个样本后插入1个质控样本。
33.s32、在同时检测正离子和负离子模式下,通过预设数据库获得待测样本的碎片离子峰作为代谢特征,在每个样品中,测量的离子峰面积表示该代谢物的相对强度。
34.为了确保数据的可靠性,本实施例中还进一步的对数据了进行以下预处理:s321、对代谢特征进行峰提取(选择合适的加合离子提取峰)、删除样本中缺失值超过80 %的代谢物,用k-最近邻算法 (knn) 填充缺失值,qc的相对标准偏差(rsd)小于30 %,并根据质控样品进行局部多项式拟合。经过数据预处理后,质控样品(qc) 峰的变异系数(cv)得到降低,更加可靠。
35.得到代谢特征的数据后,进行步骤s4、通过偏最小二乘法分析代谢特征与效果分组的相关性,筛选出与效果分组具有强相关性的代谢特征;具体的,为了选择与t淋巴细胞显著相关的代谢物,本实施例选择连续两次偏最小二乘法分析,从而步骤s4可以包括以下过程:s41、以所有检测鉴定到的碎片离子峰为基础变量,目标效应值为结局变量,建立第一个独立的偏最小二乘法模型:以所有检测鉴定到的碎片离子峰为基础,建立初始pls模型,pls模型的相关图如图1所示。以每个点代表一个个体,x变量是所有检测到的离子峰,y变量是t淋巴细胞百分比。
36.s42、通过第一个独立的偏最小二乘法模型,获得碎片离子峰对第一个独立的偏最小二乘法模型的首轮贡献指数;模型的载荷图如图2所示,载荷图显示了每个预测变量和响应变量之间的相关性。图2右上角的x变量与t淋巴细胞百分比呈正相关,而左下角的变量与t淋巴细胞百分比呈负相关,vip是代表x变量对pls模型贡献的指数。
37.s43、筛选首轮贡献指数大于1.5的碎片离子峰作为候选变量,建立第二个独立的偏最小二乘法模型,来筛选具有较强相关性的代谢特征 (vip》1.5) 以预测个体t淋巴细胞百分比。
38.s44、通过第二个独立的偏最小二乘法模型,获得候选变量对第二个独立的偏最小二乘法模型的二轮贡献指数;如图3所示,以上一轮筛选的代谢特征为x变量再次建立pls模型,其模型载荷图如图4所示。通过置换检验 (n=200) 进行模型内部验证,以检验模型是否过度拟合,若没有则模型可靠。
39.进一步的,一般非靶向代谢组学采集的数据比较庞大,可以获得成千上万的代谢特征,如果仅使用一种筛选方法,例如仅使用采用贡献指数大于1的一次筛选,得到筛选后的数据仍然比较多,而两次独立筛选可以产生叠加效应,通过数据迭代分析,获得两次独立筛选的筛选条件,可以获得更加精确的目标代谢物。因而,通过步骤s42进行第一轮筛选以后,从成千上万个(非靶向代谢组学的)代谢特征中筛选得到数百个具有相关性的代谢特征,接下来需要进一步缩减范围,得到更具相关性的代谢特征。重复上一轮的筛选过程,但vip更加严格,进行步骤s45、筛选二轮贡献指数大于1的碎片离子峰作为目标变量,以目标变量离子峰所对应的内源性代谢物质作为筛选后的代谢特征,经过这一步筛选的代谢特征
具有更强的相关性,两次筛选后得到的代谢特征可以缩减到一百种左右,进一步缩减后续物质鉴定的工作量,提高预测效率及精确度。
40.进一步的,为了加强所筛选出代谢特征与t淋巴细胞百分比的相关性,还可以进行步骤s46、通过相关性分析确定代谢特征与效果分组的相关性,以相关性的显著水平小于0.05为标准,缩小并优化代谢特征的范围。
41.筛选完具有强相关的代谢特征,还需要筛选具有相关性的临床特征,因此进行步骤s5、采集个体使用免疫抑制剂后的临床特征,临床特征包括年龄、bmi、肾功能指标、肝功能指标、红细胞压积、白蛋白含量参数;临床信息也能够解释一部分个体疗效差异,因此也需要考虑被纳入到剂量预测模型中。
42.s6、通过相关性分析筛选出与效果分组具有强相关性的临床特征;在本实施例中,可以使用pearson相关分析进行筛选,筛选得到的临床特征为年龄和血清肌酐,这两个临床特征与t淋巴细胞百分比显著相关(p《0.05)。
43.筛选完代谢特征和临床特征后,进行步骤s7、根据相关性分析和多项逻辑回归模型,以筛选后的代谢特征及临床特征与效果分组的相关性建立免疫抑制剂的药物剂量预测模型进一步的,步骤s7包括以下步骤:s71、根据多项逻辑回归模型,从初选临床特征中进一步筛选得到筛选后的临床特征;通过多项逻辑回归,选用似然比检验实现变量筛选,将显著水平小于0.05的初选临床特征纳入最终回归方程。
44.在本实施例中,初选的代谢特征和临床特征包括血清肌酐、胆红素原、l-异亮氨酸、5-甲氧基吲哚乙酸、二十碳五烯酸、n2-琥珀酰精氨酸、色氨酸精氨酸和丁酸。
45.s72、根据初选临床特征建立多项逻辑回归方程。
46.拟合情况如下表所示:多项逻辑回归模型拟合情况
在本实施例中根据上述多项逻辑回归模型,可以得到以下方程:g1=log[p(正常反应组)/p(低反应组)]=-3.875-0.113(日剂量)-0.753(log
10 (血清肌酐)) 0.126(胆红素原)-0.432(l-异亮氨酸)-0.068(5-甲氧基吲哚乙酸) 0.079(二十碳五烯酸) 0.013 (n2-琥珀酰精氨酸) 0.147(色氨酸精氨酸)-0.11(丁酸)g2=log[p(高反应组)/p(低反应组)]=-13.151-0.588(日剂量) 4.461(log
10 (血清肌酐)) 0.301(胆红素原)-1.362(l-异亮氨酸) 1.156(5-甲氧基吲哚乙酸) 0.522(二十碳五烯酸) 0.014 (n2-琥珀酰精氨酸) 0.305(色氨酸精氨酸)-0.117(丁酸)g3=0 (对照组)根据三组g1、g2、g3的值,带入以下公式,最终可得到三个疗效组的概率。
[0047]
p1=exp(g1)/[exp(g1) exp(g2) exp(g3)]p2=exp(g2)/[exp(g1) exp(g2) exp(g3)]p3=exp(g3)/[exp(g1) exp(g2) exp(g3)]上述方程能够较好地解释解释个体服用免疫抑制剂服用后t淋巴细胞含量的差异,进而根据疗效可以递归反馈进行剂量调整。
[0048]
作为上述模型预测准确度的验证,本实施例的方法还包括步骤s8、使用正交最小二乘法判别模型验证模型的预测能力。
[0049]
步骤s8可以具体包括:s71、使用筛选后的所述代谢特征及所述临床特征形成正交最小二乘法判别模型的协变量;s72、根据所述协变量构建正交最小二乘法判别模型。
[0050]
根据所选特异性内源物质和临床特征建立正交最小二乘法判别模型,用正交最小二乘法判别模型能够上述筛选的代谢特征和临床特征的预测能力。模型的分析结果用图5表示,每个圆圈代表一个个体,得分图显示了聚类的概况。所选择的变量将高低疗效组清楚地分开,r2y为0.574,q2为0.415。同时,执行了200次迭代的置换检验,以防模型过度拟合结果表明,模型是稳定的,没有过度拟合的风险。由正交最小二乘法判别模型可以发现高反应组和低反应组中的这几个变量有显著差异,即该模型可以用于免疫抑制剂给药剂量的预测。
[0051]
本实施例还提供一种免疫抑制剂药物剂量预测的方法,应用上述方法所构建的模型进行免疫抑制剂给药剂量的预测,具体包括:将给药后目标样本中与模型相对应的特征参数代入该模型,获得t细胞含量的疗效预测结果。然后根据该t细胞含量偏高/低迭代给药剂量,从而获得不同疗效所对应的给药剂量,从而实现给药剂量的精准预测。
[0052]
应当说明的是,上述实施例仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
