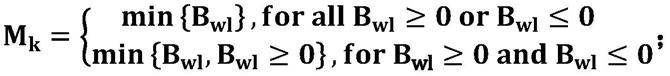
1.本发明涉及计算机集成制造技术领域,特别涉及一种基于增强拓扑神经进化的等效并行机动态智能调度方法。
背景技术:
2.并行机调度问题(parallel machine scheduling problem,pmsp)是将n类工件分配在m台机器上并确定工件在机器上加工顺序,以使得追求的绩效指标最优的问题,是生产调度中一类非常重要的调度优化问题,已被证明是np-hard问题。目前有关pmsp的研究主要围绕静态问题(如假设机器一直可用,工件到达时间确定等)展开,提出的求解方法有精确法(如动态规划法、数学规划法),启发式规则(如list scheduling,ls;shortest processing time,spt;weighted shortest processing time,wspt;longest processing time,lpt;best fit decreasing-longest processing time,bfd-lpt),随机邻域搜索算法(如禁忌搜索ts)以及群体智能算法(如nsga
‑ⅱ
,布谷鸟算法)等。由于现实生产中存在各种动态因素(如机器故障或维护、工件随机到达、紧急订单等),调度目标和约束一直处于动态变化和进化过程中,是典型的序列动态决策问题。随着强化学习技术的发展,将调度过程作为马尔可夫决策过程,根据调度问题的实时环境状态选择最合适的调度决策以最大化系统绩效成为动态调度问题的研究趋势。
3.早期基于强化学习的动态调度主要运用r-learning,q-learning,q
‑ⅲ
learning等算法,需要建立状态-行为-奖励之间的函数关系,适用于小规模简单问题的求解。对于中大规模复杂问题,需要采用结合神经网络的深度强化学习(deep reinforcement learning,drl)算法求解。然而,drl算法一般采取基于固定神经网络结构的智能体学习,自适应能力较差,将强化学习与进化算法混合可望成为新的研究热点。增强拓扑神经进化(neuro evolution of augmenting topologies,neat)是一种基于遗传算法同时优化神经网络的拓扑结构和神经网络的节点权重参数的强化学习方法。由于不需要设计奖励函数,从最小结构逐渐增长,使用物种形成保护结构创新以及不同拓扑交叉的原则等方法,具有求解效率高、质量好等优点,已经成功应用在动态调度问题的求解。
技术实现要素:
4.本发明的目的在于,提供一种基于增强拓扑神经进化的等效并行机动态智能调度方法。本发明具有实时响应工件动态到达、处理时间不确定且机器需要弹性预防维护等动态事件,智能生成平均流程时间最小的调度方案,且具有最小化在制品库存和改进生产稳定性的特点。
5.本发明的技术方案:一种基于增强拓扑神经进化的等效并行机动态智能调度方法;所述具体步骤为:
6.步骤s1:初始化等效并行机系统参数,定义机器mi数m(i=1,2,
…
,m),工件类型jj数n(j=1,2,
…
,n),工件jj的数量npj、到达时间rj、处理时间pj以及机器弹性预防维护的界
限值ut和维护时间t;
7.步骤s2:研究等效并行机问题的动态调度决策特征,设计与之匹配的调度行为,组成强化学习智能体的行为空间a;
8.步骤s3:研究等效并行机问题的动态调度环境特点,设计从工件、机器与暂存区三个维度描述环境的状态空间向量s;
9.步骤s4:生成规模为n的初始神经网络种群pop,每一个初始神经网络个体都只有输入层和输出层而无隐藏层;
10.步骤s5:将目标值平均流程时间的倒数设置为适应度值函数,用于评价神经网络个体的优劣;
11.步骤s6:种群pop中的每一个智能体所用的神经网络个体分别与等效并行机系统交互,感知实时状态,在新工件类型到达或工件完工的每一个决策时刻选择一种调度行为,通过一系列的动态决策,生成调度策略,得到适应度值;神经网络种群采用基于物种相容性阈值的种群分化、五种方式变异、交叉以及停滞物种淘汰等方式实现遗传进化,得到适应度值最高的神经网络p
best
;
12.步骤s7:使用步骤s6训练得到的最优神经网络p
best
作为调度智能体,当新工件到达或者工件完工时触发决策时刻,将实时车间环境状态s输入p
best
,p
best
输出行为空间中各个行为的q值{q1,q2,q3},智能体选择q值最大的行为a=argmaxq生成最优调度方案。
13.上述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s1中的初始化动态等效并行机系统按下述步骤进行:
14.步骤s1.1:问题描述与目标界定,等效并行机动态调度问题可以描述为将n类工件j={j1,j2,
…
,jj,
…
,jn},安排到m台等效的并行机上,其中每类工件ji的数量np={np1,np2,
…
,npj,
…
,npn},每类工件jj的到达时间为r={r1,r2,
…rj
,
…rn
},每类工件的处理时间为p={p1,p2,
…
,pj,
…
pn},任何工件在加工过程不可中断,机器在生产过程中需要进行弹性预防维护,即机器的连续加工时间或役龄不能超过界限值ut,每次维护的时间为t,优化目标为最小化平均流程时间决策内容是确定工件在机器上的分配与加工顺序;
15.步骤s1.2:初始化等效并行机数字仿真模型,使用spyder软件进行编程,按照调度问题的基本构成生成三个列表list1、list2、list3,分别存储各类工件的加工时间pj、各类工件的到达时间rj和各类工件的数量npj,初始化机器弹性预防维护界限ut值和维护时间t值。
16.前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s2中的调度行为包括:
17.行为1:改进的启发式规则mspt;
18.行为2:改进的启发式规则mfifo;
19.行为3:等待不执行任何操作。
20.前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述改进的启发式规则mspt的步骤如下:
21.步骤s2.1.1:根据spt规则从等待队列中选择加工时间最短的工件jk;如果存在多个同类工件,则随机选择其中的一个工件jk;
22.步骤s2.1.2:将工件jk分别尝试安排在空闲机器m
l
上,根据机器m
l
上的剩余维护门
槛值计算每种安排的批浪费计算每种安排的批浪费将工件jk安排在批浪费最小的机器mk上,其公式如下所示:
[0023][0024]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述改进的启发式规则mfifo的步骤如下:
[0025]
步骤s2.2.1:根据fifo规则从等待队列中选择最先到达的工件jk;如果存在多个同时到达的工件,则选择加工时间最短的一个工件jk。
[0026]
步骤s2.2.2:将工件jk分别尝试安排在空闲机器m
l
上,根据机器m
l
上的剩余维护门槛值计算每种安排的批浪费计算每种安排的批浪费将工件jk安排在批浪费最小的机器mk上,其公式如下所示:
[0027][0028]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s3中的状态空间按照下述方法界定:
[0029]
针对等效并行机动态调度的环境特点,设置状态空间向量态调度的环境特点,设置状态空间向量从工件、机器与暂存区三个维度描述环境;其中qj为等待队列中各类工件的数量;为当前时刻与工件jj到达时间的时间间隔;ti为机器mi正在加工工件的加工时间,如需维护则增加维护时间t,如果机器mi处于空闲状态,则ti=0;为机器mi正在加工工件的已加工时间;为机器mi在当前时刻剩余的维护门槛值;整个并行机环境的状态空间向量s的维度大小为n n m m m=3m 2n。
[0030]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s5中的评价神经网络优劣的适应度函数按照下述方法确定:每一个基于神经网络的智能体与等效并行机系统进行交互,当所有工件都生产完毕,计算得到目标值平均流程时间基于目标值生成适应度函数,即:
[0031]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s6中的强化学习智能体学习与神经网络进化按下述步骤进行:
[0032]
步骤s6.1:初始化种群神经网络pop、迭代次数genes、g=0、超参数、等效并行机系统参数等;
[0033]
步骤s6.2:定义智能体与等效并行机系统仿真交互模块;
[0034]
步骤s6.3:定义神经网络进化过程,当达到最大迭代次数g=genes时停止迭代并且保存最优个体神经网络个体p
best
。
[0035]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s6.2的具体步骤如下:
[0036]
步骤s6.2.1:输入个体神经网络p、工件类型数量m、机器数量n、各类型工件加工时
间列表p、各类型工件到达时间列表r、各类型工件数量np;
[0037]
步骤s6.2.2:初始化最大决策次数maxn;
[0038]
步骤s6.2.3:初始化工件生产序列l1,用于记录生产完的工件类型编号;
[0039]
步骤s6.2.4:初始化工件完工时刻序列l2,用于记录完工工件的完工时刻;
[0040]
步骤s6.2.5:初始化总流程时间f=0,决策次数n=0;
[0041]
步骤s6.2.6:按照维度3m 2n初始化状态步骤s6.2.6:按照维度3m 2n初始化状态
[0042]
步骤s6.2.7:循环进行如下步骤操作,当所有工件都生产完毕或者决策次数达到最大值maxn,停止循环并且输出适应度值fitness和工件生产序列l1。
[0043]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s6.2.7的具体步骤如下:
[0044]
步骤s6.2.7.1:仿真时钟开始工作,记录即时时刻;
[0045]
步骤s6.2.7.2:如果有新工件类型到达等待队列或者有工件生产完成,将生产完毕的工件的类型编号存入工件生产序列l1的最后位置;
[0046]
步骤s6.2.7.3:将即使时刻存入工件完工时刻序列l2的最后位置;
[0047]
步骤s6.2.7.4:触发决策时刻:n=n 1;
[0048]
步骤s6.2.7.5:更新即时状态
[0049]
步骤s6.2.7.6:将状态s输入神经网络p,p输出三个调度行为的值:{q1,q2,q3},按照行为a=argmaxq的规则对等效并行机系统进行操作。
[0050]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述步骤s6.3的具体步骤如下:
[0051]
步骤s6.3.1:计算每一个神经网络与种群其它神经网络的距离;
[0052]
步骤s6.3.2:按照物种相容性阈值把种群分成多个物种;
[0053]
步骤s6.3.3:选择适应度最高的前ne个个体直接进入下一代;
[0054]
步骤s6.3.4:按照连接添加、节点添加、连接删除、节点删除、节点权重变异发生的概率生成新的神经网络p
new
;
[0055]
步骤s6.3.5:将p
new
输入步骤6.2定义的智能体与等效并行机仿真交互模块中,保存交互模块生成的适应度值fitness
new
;
[0056]
步骤s6.3.6:取pop前d的个体交叉操作产生子代神经网络p
offspring
,d=交叉率*100%;
[0057]
步骤s6.3.7:将每一个子代神经网络p
offspring
输入步骤6.2定义的智能体与等效并行机仿真交互模块中,保存交互模块生成的适应度值fitness
poffspring
;
[0058]
步骤s6.3.8:物种内竞争,淘汰物种内适应度值低的个体;
[0059]
步骤s6.3.9:根据物种停滞进化的代数删除与更新物种。
[0060]
前述的基于增强拓扑神经进化的等效并行机动态智能调度方法中,所述s7中的最优调度方案生成按照如下步骤进行:
[0061]
步骤s7.1:当新工件类型到达或者工件完工时触发决策时刻,智能体获取实时车间环境状态s;
[0062]
步骤s7.2:将状态s输入神经网络p
best
,p
best
输出三个调度行为的值:{q1,q2,q3};
[0063]
步骤s7.3:按照a=argmaxq选择调度行为;
[0064]
步骤s7.4:按照调度行为a执行调度操作,生成最优调度方案。
[0065]
与现有技术相比,本发明能实现工件动态到达、处理时间不确定且机器需要弹性预防维护等多种动态事件影响下的近优生产调度方案的自适应智能生成,最小化制品库存和改进生产稳定性。由于调度期间工件和机器状态的不确定性,本发明提出了基于neat的等效并行机智能调度方法,强化学习智能体感知实时状态,通过一系列的动态决策生成调度策略;neat是一种基于遗传算法优化神经网络拓扑结构和节点权重参数的深度强化学习算法,具有不需要设计奖励函数以及能解决稀疏奖励问题的特点;基于neat强化学习的调度方法具备较强的泛化性,训练完毕后的模型不需要再次训练就能对随机动态的因素变化(工件动态到达、处理时间不确定且机器需要弹性预防维护等)做出自适应反应。
附图说明
[0066]
图1是本发明基于增强拓扑神经进化的等效并行机动态调度方法的总体流程图;
[0067]
图2是本发明适用对象等效并行机问题实例图;
[0068]
图3是本发明智能体与等效并行机交互流程图;
[0069]
图4是本发明基于增强拓扑神经进化的等效并行机动态智能调度方法的神经网络训练流程图;
[0070]
图5是本发明不同调度方法的平均流程时间均值对比图;
[0071]
图6是本发明不同调度方法的响应时间对比图。
具体实施方式
[0072]
下面结合附图和实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。
[0073]
实施例:一种基于增强拓扑神经进化的等效并行机动态智能调度方法,如附图1所示,按下述步骤进行:
[0074]
步骤s1:初始化等效并行机系统参数,定义机器mi数m(i=1,2,
…
,m),工件类型jj数n(j=1,2,
…
,n),工件jj的数量npj、到达时间rj、处理时间pj以及机器弹性预防维护的界限值ut和维护时间t;
[0075]
如附图2所示,所述步骤s1中的初始化动态等效并行机系统按下述步骤进行:
[0076]
步骤s1.1:问题描述与目标界定,等效并行机动态调度问题可以描述为将n类工件j={j1,j2,
…
,jj,
…
,jn},安排到m台等效的并行机上,其中每类工件jj的数量np={np1,np2,
…
,npj,
…
,npn},每类工件jj的到达时间为r={r1,r2,
…rj
,
…rn
},每类工件的处理时间为p={p1,p2,
…
,pj,
…
pn},任何工件在加工过程不可中断,机器在生产过程中需要进行弹性预防维护(preventive maintenance,pm),即机器的连续加工时间或役龄不能超过界限值ut,每次维护的时间为t,优化目标为最小化平均流程时间决策内容是确定工件在机器上的分配与加工顺序;
[0077]
步骤s1.2:初始化等效并行机数字仿真模型,使用spyder软件进行编程,按照调度问题的基本构成生成三个列表list1、list2、list3,分别存储各类工件的加工时间pj、各类工件的到达时间rj和各类工件的数量npj,初始化机器弹性预防维护界限ut值和维护时间t
值;
[0078]
步骤s2:研究等效并行机问题的动态调度决策特征,设计与之匹配的调度行为,组成强化学习智能体的行为空间a;
[0079]
所述步骤s2中的调度行为包括:
[0080]
行为1:改进的启发式规则mspt(modified shortest processing time);
[0081]
所述改进的启发式规则mspt的步骤如下:
[0082]
步骤s2.1.1:根据spt规则从等待队列中选择加工时间最短的工件jk;如果存在多个同类工件,则随机选择其中的一个工件jk;
[0083]
步骤s2.1.2:将工件jk分别尝试安排在空闲机器m
l
上,根据机器m
l
上的剩余维护门槛值计算每种安排的批浪费计算每种安排的批浪费将工件jk安排在批浪费最小的机器mk上,其公式如下所示:
[0084][0085]
行为2:改进的启发式规则mfifo(modified first in first out);
[0086]
所述改进的启发式规则mfifo的步骤如下:
[0087]
步骤s2.2.1:根据fifo规则从等待队列中选择最先到达的工件jk;如果存在多个同时到达的工件,则选择加工时间最短的一个工件jk。
[0088]
步骤s2.2.2:将工件jk分别尝试安排在空闲机器m
l
上,根据机器m
l
上的剩余维护门槛值计算每种安排的批浪费计算每种安排的批浪费将工件jk安排在批浪费最小的机器mk上,其公式如下所示:
[0089][0090]
行为3:等待不执行任何操作;
[0091]
工件加工完成或新类型工件到达触发调度决策时刻,此时强化学习智能体根据环境状态选择三种调度行为中的一种;针对以下三种特殊情况的调度行为选择说明如下:
[0092]
a.当等待队列中没有工件时,智能体只能选择行为3;
[0093]
b.当有新类型工件到达而没有空闲机器时,智能体只能选择行为3;
[0094]
c.当所有机器都处于空闲状态而等待队列中有工件时,智能体不允许选择行为3;
[0095]
步骤s3:研究等效并行机问题的动态调度环境特点,设计从工件、机器与暂存区三个维度描述环境的状态空间向量s;
[0096]
所述步骤s3中的状态空间按照下述方法界定:
[0097]
针对等效并行机动态调度的环境特点,设置状态空间向量针对等效并行机动态调度的环境特点,设置状态空间向量从工件、机器与暂存区三个维度描述环境;其中qj为等待队列中各类工件的数量;为当前时刻与工件jj到达时间的时间间隔;ti为机器mi正在加工工件的加工时间,如需维护则增加维护时间t,如果机器mi处于空闲状态,则ti=0;为机器mi正在加工工件的已加工时间;为机器mi在当前时刻剩余的维护门槛值;整个并行机环境的状态空间向量s的维度大
小为n n m m m=3m 2n;
[0098]
步骤s4:生成规模为n的初始神经网络种群pop,每一个初始神经网络个体都只有输入层和输出层而无隐藏层;
[0099]
步骤s5:将目标值平均流程时间的倒数设置为适应度值函数,用于评价个体神经网络个体的优劣;
[0100]
所述步骤s5中的评价神经网络优劣的适应度函数按照下述方法确定:每一个基于神经网络的智能体与等效并行机系统进行交互,当所有工件都生产完毕,计算得到目标值平均流程时间基于目标值生成适应度函数,即:
[0101]
步骤s6:种群pop中的每一个智能体所用的神经网络个体分别与等效并行机系统交互,感知实时状态,在新工件类型到达或工件完工的每一个决策时刻选择一种调度行为,通过一系列的动态决策,生成调度策略,得到适应度值;神经网络种群采用基于物种相容性阈值的种群分化、五种方式变异、交叉以及停滞物种淘汰等方式实现遗传进化,得到适应度值最高的神经网络个体p
best
;
[0102]
如附图3所示,所述步骤s6中的强化学习智能体学习与神经网络进化按下述步骤进行:
[0103]
步骤s6.1:初始化种群神经网络pop、迭代次数genes、g=0、超参数(交叉率、连接添加率、节点添加率、连接删除率、节点删除率、物种相容性阈值、节点权重变异率、适应度最高的个体直接复制到下一代的个数ne、物种停滞允许延长的代数max_stagnation)、等效并行机系统参数(机器数量m、工件类型n、均分分布随机生成工件加工时间p、均分分布随机生成工件到达时间r、均分分布随机生成每类工件数量np);
[0104]
步骤s6.2:定义智能体与等效并行机系统仿真交互模块;
[0105]
所述步骤s6.2的具体步骤如下:
[0106]
步骤s6.2.1:输入个体神经网络p、工件类型数量m、机器数量n、各类型工件加工时间列表p、各类型工件到达时间列表r、各类型工件数量np;
[0107]
步骤s6.2.2:初始化最大决策次数maxn;
[0108]
步骤s6.2.3:初始化工件生产序列l1,用于记录生产完的工件类型编号;
[0109]
步骤s6.2.4:初始化工件完工时刻序列l2,用于记录完工工件的完工时刻;
[0110]
步骤s6.2.5:初始化总流程时间f=0,决策次数n=0;
[0111]
步骤s6.2.6:按照维度3m 2n初始化状态步骤s6.2.6:按照维度3m 2n初始化状态
[0112]
步骤s6.2.7:循环进行如下步骤操作,当所有工件都生产完毕或者决策次数达到最大值maxn,停止循环并且输出适应度值fitness和工件生产序列l1;
[0113]
如附图4所示,所述步骤s6.2.7的具体步骤如下:
[0114]
步骤s6.2.7.1:仿真时钟开始工作,记录即时时刻;
[0115]
步骤s6.2.7.2:如果有新工件类型到达等待队列或者有工件生产完成,将生产完毕的工件的类型编号存入工件生产序列l1的最后位置;
[0116]
步骤s6.2.7.3:将即使时刻存入工件完工时刻序列l2的最后位置;
[0117]
步骤s6.2.7.4:触发决策时刻:n=n 1;
[0118]
步骤s6.2.7.5:更新即时状态
[0119]
步骤s6.2.7.6:将状态s输入神经网络p,p输出三个调度行为的值:{q1,q2,q3},按照行为a=argmaxq的规则对等效并行机系统进行操作;
[0120]
步骤s6.3:定义神经网络进化过程,当达到最大迭代次数g=genes时停止迭代并且保存最优个体神经网络个体p
best
;
[0121]
所述步骤s6.3的具体步骤如下:
[0122]
步骤s6.3.1:计算每一个神经网络与种群其它神经网络的距离;
[0123]
步骤s6.3.2:按照物种相容性阈值把种群分成多个物种;
[0124]
步骤s6.3.3:选择适应度最高的前ne个个体直接进入下一代;
[0125]
步骤s6.3.4:按照五种变异(连接添加、节点添加、连接删除、节点删除、节点权重变异)发生的概率生成新的神经网络p
new
;
[0126]
步骤s6.3.5:将p
new
输入步骤6.2定义的智能体与等效并行机仿真交互模块中,保存交互模块生成的适应度值fitness
new
;
[0127]
步骤s6.3.6:取pop前d的个体交叉操作产生子代神经网络p
offspring
,d=交叉率*100%;
[0128]
步骤s6.3.7:将每一个子代神经网络p
offspring
输入步骤6.2定义的智能体与等效并行机仿真交互模块中,保存交互模块生成的适应度值fitness
poffspring
;
[0129]
步骤s6.3.8:物种内竞争,淘汰物种内适应度值低的个体;
[0130]
步骤s6.3.9:根据物种停滞进化的代数删除与更新物种;
[0131]
步骤s7:使用步骤s6训练得到的最优神经网络p
best
作为调度智能体,当新工件到达或者工件完工时触发决策时刻,将实时车间环境状态s输入p
best
,p
best
输出行为空间中各个行为的q值{q1,q2,q3},智能体选择q值最大的行为a=argmaxq生成最优调度方案;
[0132]
所述s7中的最优调度方案生成按照如下步骤进行:
[0133]
步骤s7.1:当新工件类型到达或者工件完工时触发决策时刻,智能体获取实时车间环境状态s;
[0134]
步骤s7.2:将状态s输入神经网络p
best
,p
best
输出三个调度行为的值:{q1,q2,q3};
[0135]
步骤s7.3:按照a=argmaxq选择调度行为;
[0136]
步骤s7.4:按照调度行为a执行调度操作,生成最优调度方案。
[0137]
为了验证本文提出方法的有效性,设计了如表1所示的问题实验环境,实验所需的工件加工时长p和到达时间r都基于均匀分布生成;实验按照m、n的数值大小可把问题分成小规模、中规模和大规模三类问题,每一个规模按照均匀分布随机生成10组数据,规模分类如表1所示,neat在训练完成后重复测试运行5次以测试训练效果;按照问题规模的大小确定neat的迭代次数和初始种群大小如表2所示。
[0138]
表1仿真实验的问题参数
[0139][0140]
表2 neat的实验参数
[0141][0142]
以经典启发式规则spt和fifo作为对比,重复测试5次得到的平均流程时间均值、标准差以及求解一个完整实例问题所需的运行时间rt的平均值如表3所示。
[0143]
表3不同调度方法的实验结果
[0144]
[0145][0146]
由表3可知,随着问题规模变大(即n和m都增加),基于neat算法获得的平均流程时间明显优于spt与fifo规则,同时运行时间也明显大于启发式调度规则,原因在于neat需要与等效并行机环境进行多次循环交互训练才得到最优策略,因此运行时间更长;从平均流程时间的标准差来看,neat与spt的值小,表明neat有较好的稳定性;而fifo值较大,表明稳定性较弱;因此,neat强化学习可以得到的更优的调度方案,但是需要更长的训练时间。
[0147]
neat不但具备较好的求解能力,同时neat也具备较好的泛化能力,泛化能力是基于neat强化学习算法的动态调度方法的核心能力,只有具备了一定的泛化能力,才具有自适应动态环境的能力;为验证基于neat算法的泛化能力,随机生成表1大规模问题的10组实例,对每一组实例分别使用spt、fifo规则与训练好的neat算法求解10次,求得的平均流程时间的平均值和针对动态事件的响应时间t分别如附图5和附图6所示,任何一组对比实验中,neat找到的目标值都优于spt与fifo规则,响应时间也相对较短,表明neat调度方法具备较强的泛化能力,训练完毕后的模型不需要再次训练就能对随机变化的动态环境做出自适应反应。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。