一种快速top-n排序方法
技术领域
1.本发明涉及数据统计和处理技术领域,特别涉及一种快速top-n排序方法。
背景技术:
2.随着科学技术的快速发展以及移动互联网的普及,各行各业中均开始使用互联网相关的技术。随着各行各业在日常运作中对互联网的使用,每天将产生海量蕴含丰富信息的数据,并且这些数据可能具有较高的应用价值。因此,需要对这些数据进行处理分析,以挖掘这些数据的价值。
3.目前,对海量数据进行处理分析,可以采用多种方法,如数据排序分析、数据建模分析、数据统计分析等技术方法。其中,对海量数据中的对象进行排序,以获取海量数据中有价值的数据信息是一种常用的技术手段。但是这些海量数据中,并非每个数据的价值均相同,如积分排名中的前10名,全国污染指数最低的前10名,人均产值最高的城市前10名,这些数据将比其他的数据具有更大的意义,因此,我们需要采用排序的方法从海量数据中挑选出这些数据的top-n。
4.top-n的含义为依照排序方式输出前n个对象,其中n为非零自然数。当排序方式为升序排列时,top-n的含义为输出数据值最小的前n个对象;当排序方式为降序排列时,top-n的含义为输出数据值最大的前n个对象。top-n的排序方法目前常用在大数据对比、底库搜素等领域,如人脸比对、车辆比对等。通过提取目标的特征值,将特征与底库的样本特征进行相似度计算,再对相似对进行排序找出最接近的n个目标。目前人员比对底库样本数量已经高达亿量级,因此,top-n排序方法的效率很大程度上决定了整个比对算法的效率。
5.在专利cn110262770a《一种按位的排序方法》中,提供一种按位的排序方法,在排序过程中均按照位数和每一个位数上的数字来进行排序,但是在该方法中,仍然需要对所有的样本进行排序,时间复杂度将会随着样本的增多而增大。
6.在专利cn105574344a《一种金字塔排序算法》中,先找到一个为2的整数次幂的整数,然后把要排序的n个数据放入b数组中,再逐一比较b数组中相邻数据,将相对大数的下标放入c数组的m/2-m-1单元中;然后在逐个比较b[c[m/2]]-b[c[m-1]]中的相邻数据,并将相对大数的下标放入c[m/2-1]-c[m/4]中,依次类推,最后整个b数组最大数数据的下标就会被放入c[1]中,然后不断找出b数组中的最大值,完成排序。该专利中提供的方法具有如下缺点:(1)在该方法中,仍然需要对所有的样本进行排序;(2)该方法在排序序列基本有序的情况下,其排序速度明显优于快速排序,但是在实际应用中,并不是每个排序序列都是基本有序的,因此,该方法的应用场景较为有限,并不能在所有的top-n排序中均能达到提速的效果。
[0007]
目前现有的top-n排序方法共有的缺陷是:top-n排序最终有效的数据集中包含的数据只有n个,但是参与排序的数据却是整个数据集中的所有样本,当总样本的数量m远大于n时,排序计算中绝大部分的计算都是无效的,这些无效的计算将极大地降低top-n排序方法的效率。
[0008]
因此,亟需一种快速的top-n排序方法,其能在对任何数据进行top-n排序时,均能提高排序方法的效率。
技术实现要素:
[0009]
为了解决上述技术问题,本发明提供一种快速top-n排序方法。该方法通过先提取有效样本,再对有效样本进行排序找到top-n数据的方法,基本上去除了冗余的排序的计算,从而极大地提高了top-n排序方法的效率,尤其是对于样本数量较大但是有效数据n较小的情况,该方法将极大地减少了参与排序的样本数据,提高了排序方法的计算效率。
[0010]
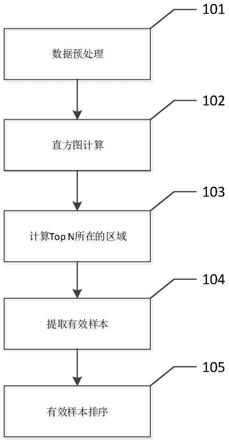
为了实现上述发明目的,本发明提供一种top-n排序方法,其包括以下步骤:数据预处理,所述数据预处理步骤用于确定直方图中区域的个数和区域的范围;直方图计算,所述直方图计算步骤用于确定每个直方图区域中的样本数;在进行直方图计算时,读取每个样本值的大小,并根据样本值的大小判定该样本哪个直方图区域中,该样本落在哪个bin范围内,将该bin上的样本数加1;通过所述直方图计算步骤中的计算结果,确定top-n的有效样本区域;在确定top-n的有效样本区域时,计算方法如下:计算从第m个bin到第n个bin的样本数的总数sum,在top-n的排序中,m或者n其中之一是确定的,第m个bin为最小bin或者第n个bin为最大bin,然后按照顺序对各个bin中的样本数相加,直到样本数的总数sum大于等于n,确定此时的n或者m值;则第m个bin到第n个bin中的值为有效样本区域;提取有效样本;以及对有效样本进行top-n排序。
[0011]
采用本发明中提供的top-n排序方法,通过先提取有效样本,再对有效样本进行排序找到top-n数据的方法,基本上去除了冗余的排序的计算,从而极大地提高了top-n排序方法的效率,尤其是对于样本数量较大但是有效数据n较小的情况,该方法将极大地减少了参与排序的样本数据,提高了排序方法的计算效率。
[0012]
优选地,在进行最大值排序时,确定top-n的有效样本区域时,从最大的bin向最小的bin方向上对每个bin上的样本个数进行累加,直到累加总数大于等于n,则该区间范围则为有效样本区域。
[0013]
优选地,在进行最小值排序时,确定top-n的有效样本区域时,从最小的bin向最大的bin方向上对每个bin上的样本个数进行累加,直到累加总数大于等于n,则该区间范围则为有效样本区域。
[0014]
优选地,在所述数据预处理步骤中确定直方图中区域的个数时,根据样本数据的取值范围而定,样本数据的取值范围越大,直方图中区域的个数越多。直方图中区域的个数越多,在后续步骤中寻找到的有效区域将越精确(即有效区域中的数据量与有效数据量n越接近),在排序时进行的冗余计算将越少。
[0015]
优选地,在所述数据预处理步骤中确定直方图中区域的个数时,根据有效数据量n而定,当有效数据量n越大时,直方图中区域的个数越少。
[0016]
优选地,在提取有效样本时,对所有样本进行遍历,将样本值落在有效样本区域内的样本提取出来。
[0017]
优选地,在对有效样本进行top-n排序时,采用以下排序方法其中之一:冒泡排序、选择排序、快速排序和堆排序。
[0018]
优选地,在直方图计算时,对每个bin中的样本进行存储。
[0019]
优选地,在提取有效样本时,将落在有效样本区域内的样本提取出来。
[0020]
优选地,在对有效样本进行top-n排序时,先对有效样本区域中每个bin中的样本进行排序,然后从这些数据中找出top-n。通过对每个bin中的样本进行排序,减小了每次排序参与的样本数量,进一步提高了该排序方法的计算效率。
附图说明
[0021]
图1为本发明提供的一种top-n排序方法的流程图。
[0022]
图2为本发明中样本形成的直方图示意图。
[0023]
图3为本发明中最大值排序有效样本的范围计算示意图。
[0024]
图4为本发明中最小值排序有效样本的范围计算示意图
具体实施方式
[0025]
以下配合图式及本发明的较佳实施例,进一步阐述本发明为达成预定发明目的所采取的技术手段。
[0026]
如图1中所示,图1为本发明提供的一种top-n排序方法的流程图。
[0027]
步骤101,数据预处理。所述数据预处理步骤用于确定直方图中区域的个数和区域的范围。假设需要进行排序的总样本数量为m,所有在样本数据值均在[a,b]区间内(a和b的值一般是已知的),则样本数据的取值范围q为b-a,将其进行x等分,进而确定直方图中区域的个数和区域的范围。如果对取值范围为[a,b]的样本数据进行了x等分,则直方图将被分为x个区域,我们称这个直方图有x个bin,其中,第x个bin代表的区域范围为[a (x-1)*(q/x),a x*(q/x)]。
[0028]
在对样本数据进行x等分时,x可由样本数据的取值范围q决定,当样本数据的取值范围越大时,x将越大。其中,x越大,在后续步骤中寻找到的有效区域将越精确(即有效区域中的数据量与有效数据量n越接近),在排序时进行的冗余计算将越少。
[0029]
在对样本数据进行x等分时,x可由有效数据量n决定,当有效数据量n越大时,x将越小。当需要的有效数据量n越大时,则有效样本的精度将越低,直方图的每个区域可以集中更多的数据。
[0030]
步骤102,直方图计算。所述直方图计算用于确定每个直方图区域中的样本数。在进行直方图计算时,读取每个样本值的大小,并根据样本值的大小判定该样本落在哪个直方图区域,样本落在哪个bin的范围内,则该bin的值加1,最终得到每个bin上的样本数。如图2中所示,其示意出在直方图计算时,样本形成的直方图,其中横轴表示每个bin的数据范围,纵轴表示该bin的范围内的样本数量。
[0031]
可选的方案中,也可在对样本进行直方图计算时,同时对该样本进行存储,按照直方图上的区域范围,从小到大进行存储,并将落在相同直方图区域中的样本存储于同一存储空间中。
[0032]
步骤103,通过直方图计算结果确定top-n的有效样本区域,计算方法如下:
[0033]
[0034]
其中,sum为从第m个bin到第n个bin的样本总数,xi表示第i个bin中的样本数;计算从第m个bin到第n个bin的样本数的总数sum,在top-n的排序中,m或者n其中之一是确定的,即第m个bin为最小bin或者第n个bin为最大bin,然后按照顺序对各个bin中的样本数相加,直到sum大于等于n,确定此时的n或者m值;如果sum大于等于n,则第m个bin到第n个bin中的值即为有效样本区域。
[0035]
在进行最大值排序时,m,n的值通过如下方法确定:此时bin[n]表示直方图最后一个区域,第n个bin区域即直方图的最大值区域,从最大的bin向最小的bin方向上对bin上的样本个数进行累加,直到累加总数大于等于n为止,此时bin的序号为m,则有效样本的值的范围为[a (m-1)*(q/x),b]。也就是说,有效样本范围的最小值minvalid=a (m-1)*(q/x),有效样本范围最大值为b。如图3中所示为在本发明中最大值排序时,有效样本的范围计算方法。其从最大的bin向最小的bin方向上对每个bin上的样本个数进行累加,直到累加总数大于等于n,则该区间范围即为有效样本区域。在进行最大值排序时,top-n排序的有效样本一定在该范围内。
[0036]
在进行最小值排序时,m,n的值通过如下方法确定:此时bin[m]表示直方图第一个区域,第m个bin区域即直方图的最小值区域,从最小的bin向最大的bin方向上对bin上的样本个数进行累加,直到累加总数大于等于n为止,此时bin的序号为n,则有效样本的值的范围为[a,a (n-1)*(q/x)]。也就是说,有效样本范围的最小值为a,有效样本范围的最大值maxvalid=a (n-1)*(q/x)。如图4中所示为本发明中最小值排序时,有效样本的范围计算方法。其从最小的bin向最大的bin方向上对每个bin上的样本个数进行累加,直到累加总数大于等于n,则该区间范围即为有效样本区域。在进行最小值排序时,top-n排序的有效样本一定在该范围内。
[0037]
步骤104,提取有效样本。在步骤103中,已经确定了top-n的有效样本的范围,在提取有效样本时,可以对所有样本进行遍历,将样本值落在有效样本区域内的样本提取出来形成有效样本v。
[0038]
如果在步骤102中进行直方图计算的同时对该样本进行存储,此时则不再需要对样本进行遍历,仅需要将落在有效样本区域内的样本提取出来形成样本v。
[0039]
步骤105,对有效样本进行top-n排序。此时仅需要对样本v进行top-n排序。在对样本v进行排序时,可以采用冒泡排序、选择排序、快速排序、堆排序中的任意一种,此处不进行限制,只要该排序方法能达到排序目的即可。
[0040]
因为样本v中的样本数量将远小于总样本的数量,尤其是针对总样本数量极大,但是有效样本n较小的排序,该方法将能极大地减小参加排序的样本数,提高了排序方法的计算效率。
[0041]
如果在步骤102中进行直方图计算的同时对该样本进行存储,则步骤104和步骤105可以进行合并。因为步骤102中对每个bin中样本进行了存储,并且步骤103中确定了top-n的有效样本区域,在进行排序时,可以对有效样本区域中的每个bin中的样本进行排序,然后再在这些数据中找出top-n。在对每个bin中的样本进行排序时,可以采用冒泡排序、选择排序、快速排序、堆排序中的任意一种,此处不进行限制,只要该排序方法能达到排序目的即可。通过对每个bin中的样本进行排序,减小了每次排序参与的样本数量,进一步提高了该排序方法的计算效率。
[0042]
因此,采用本发明中提供的一种top-n排序方法,具有如下优势:在进行排序之前,先获取了有效样本,再对有效样本进行排序,采用该排序方法将极大地减小了参加排序的样本数量,提高了排序的计算效率,尤其针对总样本数量极大,但有效样本n数量极小时,该方法能显著地提高计算效率。
[0043]
以上所述仅是本发明的优选实施例而已,并非对本发明做任何形式上的限制,虽然本发明已以优选实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案的范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本实用发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
