技术特征:
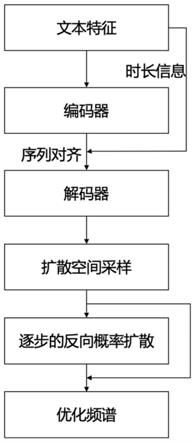
1.一种基于概率扩散模型的声学模型后处理方法,其特征在于,包括以下步骤:步骤一、模型训练,利用服务器对概率扩散模型进行训练,通过降低损失函数优化概率扩散模型的参数,直至模型收敛,获得概率扩散模型的权重;包括以下子步骤:s11、利用服务器对特定英文数据集中的文本和对应音频进行特征提取,具体为:从文本中提取语言学特征,从音频中提取对应的音高和音强,同时从音频中使用特定的声学参数提取出梅尔频谱作为真实频谱,并结合音频和语言学特征提取出音素序列,再结合梅尔频谱和音素序列使用对齐搜索的方法获得时长信息;s12、利用服务器对步骤s11得到的音素序列、时长信息、音高和音强、梅尔频谱进行声学模型的建模;所述声学模型的建模过程包括:首先对音素序列进行编码,然后使用时长信息将音素序列对齐到梅尔频谱的长度,再添加对应的音高和音强特征,接着进行序列解码,最终得到生成的预测频谱;s13、利用服务器对提取得到的真实频谱进行概率扩散模型的计算,具体为:通过设计特定的随扩散步数而变化的噪声系数,计算不同扩散步数下噪声系数所对应的条件概率的数据分布,该数据分布符合多元随机高斯分布,均值记为方差记为在经过设定的全部扩散步数的概率转移后,得到扩散空间的隐向量采样点;s14、利用服务器进行概率扩散模型训练,具体为:根据步骤s13中计算得到的扩散空间隐向量采样点与步骤s12生成的预测频谱计算损失函数l
m
,并通过概率扩散模型中的噪声估计网络计算概率扩散模型在不同扩散步数下对应的概率分布,该概率分布符合多元随机高斯分布,均值记为方差记为根据其与步骤s13得到的均值和方差计算损失函数l
n
,损失函数l
m
和l
n
按照预设的权重λ
m
和λ
n
进行加权,在服务器上进行统一训练,加权后的损失函数计算公式为l=l
m
λ
m
l
n
λ
n
;s15、利用服务器根据损失函数l计算梯度,具体为:使用adam优化器反向传播更新概率扩散模型的参数,使损失函数l降低直至收敛,至此训练结束,得到训练好的概率扩散模型的权重;步骤二、模型推断,根据训练阶段获得的模型权重,利用服务器对输入的预测频谱实现频谱优化;包括以下子步骤:s21、将预测频谱作为概率扩散空间的均值,以多元随机高斯分布的方差作为方差,得到扩散空间的采样点,然后将该采样点进行反向概率扩散,具体为:每扩散一步,使用训练好的噪声估计网络权重得到当前步数t下分布的均值和方差然后逐步实现概率分布的转移,最终在走完预设的步数时,得到优化的预测频谱;s22、利用服务器对优化的预测频谱进行波形重建,得到语音波形文件。2.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s11所取的声学参数具体为:最小频率和最大频率分别是0和8000hz,采样率为22050,fft计算的点数为1025,设定提取梅尔频谱为80维;所述的对齐搜索的方法设计为将三个音素作为一个单位,下一个单位包含上一个单位的后两个音素,将此搜索单位与梅尔频谱的每一帧计算相关系数,并使用动态规划算法将相关系数最大的项设为1,最后得到的时长信息是与音素序列等长的自然数序列,且该自然数序列的和与对应的梅尔频谱长度相符。
3.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s12中的对音素序列编码,使用基于多头注意力机制和一维卷积的运算作为一个编码层,共采用4层编码结构设计;所述使用时长信息将音素序列对齐到梅尔频谱的长度,包括:时长信息表示编码后隐序列中某个向量对应的发声时长,按照该时长将对应向量重复一定次数,然后对序列中所有向量进行相同操作,并在时间维度上串联,得到与梅尔频谱长度相同的隐序列;所述序列解码同样基于4层多头注意力机制和一维卷积结合的解码器结构,并在解码后使用线性层将隐序列的维度映射到梅尔频谱的维度,从而生成预测频谱。4.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s13中所述扩散步数为1000步,所述随扩散步数t而变化的噪声系数β
t
的计算公式为β
t
=β0 (β
1-β0)t,其中β0和β1分别取值为0.05和20;所述条件概率的数据分布的均值和方差计算公式为:式中x
t-1
为当前扩散步数前一步的隐向量,i表示单位矩阵。5.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s14中所述的噪声估计网络使用2个4层的二维卷积结构,第一个4层的二维卷积结构中,每层之间使用基于最大池化的下采样,将隐序列下采样一倍;第二个4层的二维卷积结构中,每层之间使用基于最近邻插值的上采样,将隐序列上采样一倍,且在每层的上采样计算时会将当前结果与对应分辨率的下采样隐序列在时间维度上进行并联,最后使用线性层将输出维度映射为梅尔频谱的维度。6.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s15中所述直至收敛的训练步数为1000。7.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s21中在使用训练好的模型进行反向概率扩散时,预设的步数为100,得到的优化预测频谱更加接近真实频谱,因此通过后处理进一步提升了声学模型合成频谱的质量。8.根据权利要求1所述的一种基于概率扩散模型的声学模型后处理方法,其特征在于,步骤s22中所述的波形重建具体为:首先初始化一个相位谱,根据优化后的预测频谱和初始化的相位谱,通过反短时傅里叶变换得到波形文件,然后再对波形文件计算短时傅里叶变换,得到新的频谱和相位谱,接着丢弃新的频谱,使用优化后的预测频谱和新的相位谱再次合成波形,对这个过程重复多次,直到获得较为自然的语音波形文件。9.一种服务器,包括存储器及处理器,所述存储器中储存有计算机程序,其特征在于,所述计算机程序被所述处理器执行时,使得所述处理器执行如权利要求1至8中任一项所述的基于概率扩散模型的声学模型后处理方法的步骤。10.一种可读存储器,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至8中任一项所述的基于概率扩散模型的声学模型后处理方法的步骤。
技术总结
本发明公开了一种基于概率扩散模型的声学模型后处理方法、服务器及可读存储器,该方法包括:模型训练,利用服务器对概率扩散模型进行训练,通过降低损失函数优化概率扩散模型的参数,直至模型收敛,获得概率扩散模型的权重;模型推断,根据训练阶段获得的模型权重,利用服务器对输入的预测频谱实现频谱优化。该方法通过学习输入的预测频谱和真实频谱之间的特征相似性,使用模型中噪声估计网络的数据拟合能力,实现基于扩散的概率分布转移,最终使输入的预测频谱更加近似于真实频谱。通过频谱质量的提高实现对合成语音自然度的提升。该方法针对各种声学模型得到的频谱都可以起到频谱细节优化的作用,与其他方法相比,取得了更优的频谱生成效果。优的频谱生成效果。优的频谱生成效果。
技术研发人员:张晨 张宗煜 陈积明 史治国
受保护的技术使用者:浙江大学
技术研发日:2021.12.30
技术公布日:2022/5/17
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。