1.本发明属于人机交互领域,涉及一种适用于多种交互设备的中文文本输入,具体为一种基于连续语音与轨迹纠错的多通道输入方法及终端设备。
背景技术:
2.一直以来,文本输入是人机交互领域研究的关键问题之一。中文作为一种发音和结构的结合体,它是一个单音节多声调的语言。在汉语中只有400多个无调音节,有1600多个带调音节,但常用的汉字却有40000多个,所以在汉语中一音多字和一字多音的情况非常普遍。由此可知,复杂的中文输入给人机交互领域中的文本输入带来了很大的挑战。
3.目前,主流的输入方法大多是单通道的输入方法,比如语音输入、拼音输入和手写输入。语音输入不仅输入效率高而且使用自然,但是由于中文的复杂性和语音本身的易干扰性,语音输入的准确性受到用户发音的准确性与环境等因素的影响较大。拼音输入不适合移动设备中的小屏幕,比如在移动设备中的9宫格输入情景下,每输入一个汉字都需要多次的按键次数;在移动设备中的全键盘输入情景下,很容易发生误触。而且拼音输入对于不会拼音的用户来说门槛较高。手写输入输入时间长,而且用户在书写时经常出现连笔的现象,所以手写识别较低效。综上,单输入通道的输入方法存在速度慢与识别准确率低的缺点。
4.经研究表明,多通道融合的输入方式可以有效的提高输入效率与识别的准确率(参考:oviatt,s.ten myths of multimodal interaction,communications of the acm,42,9(1999),74
‑
81)。目前已经有一些工作研究多通道输入,yue等人发现语音辅助手写的输入方法可以有效地提高用户的输入效率,但存储空间的成本太大,而且只对不连续的输入有效(参考文献:h.wang w.yue and g.wang.2005.research on speech assisted handwriting input of discontinuous chinese characters.joint academic conference on building a harmonious human
‑
machine environment 1,1(2005),1606
–
1612);bo在移动设备上将语音和键盘结合用于文本输入,系统将语音作为主要的输入通道,将键盘作为确认或纠错通道,但是将交互终端限制在移动设备中(参考文献:hsu,b.j.,mahajan,m.and aacero,a.multimodal text entry on mobiledevices.ieee workshop on automatic speech recognition and understanding(asru)2005);jiang等人将基于键盘的精确的输入方法与基于语音的模糊的输入方法相结合实现多通道输入,但适用的交互终端为移动设备(参考文献:yingying jiang,xugang wang,feng tian,xiang ao,guozhong dai,and hongan wang.2008.multimodal chinese text entry with speech and keypad on mobile devices);ao和wang用语音来纠正手写中文识别中的错误(参考文献:ao,x.,wang,x.g.,tian,f.dai,g.z.and wang h.a.crossmodal error dorrection ofcontinuous handwriting recognition by speech.in proc.iui 2007.acm press(2007),243
‑
250),但将手写作为主要的输入通道,这在一定程度上降低了输入的效率。
技术实现要素:
5.为了克服现有的单通道与多通道输入法低效的不足,本发明提供一种基于连续语音与轨迹纠错的多通道输入方法及终端设备,适用于多种交互终端。本发明采用基于连续语音与轨迹纠错的多通道输入方法,系统将语音作为主要的输入通道,因为语言是人类最高效、门槛最低的沟通方式,它为用户还原了生活中最真实的交流场景,所以语音输入不仅直观自然而且提升了输入速度,同时降低了用户的学习负担,对不习惯使用键盘与需要语音录入的用户较为友好。尽管基于语音识别的方法可以通过语句中字词之间的上下文关系,来提升输入识别的准确率,但识别错误仍然是难以避免的,这已经成为影响语音输入效率的主要因素。在目前的语音输入法中,当语音识别的文字结果出现错误时,用户再次使用语音读出错误的字词读音,亦或采用拼音或手写将目标字词重新输入。但二者都存在输入效率低下的现象,我们将采用语音输入与轨迹输入相结合的方式,通过轨迹输入来直接定位和纠错。当语音识别的文字结果出现错误时,用户通过手或笔点击错误字、词,输入正确字、词的特征笔划轨迹,进而对语音识别得到的top k个候选词列表进行过滤,得到正确的目标字、词,并在识别文字结果中进行直接替换。所以基于连续语音与轨迹纠错的多通道输入方法,不仅提升了输入效率而且提高了准确率。而且本输入方法适用于多种交互的终端设备,从移动手持设备的小屏到大屏,只要有收音模块(接收语音信号)和触摸屏或手写板或鼠标(得到目标词的特征笔划轨迹)都可以使用。
6.本发明解决其技术问题所采用的技术方案是:系统将语音作为主要的输入通道,采用轨迹输入来辅助纠错,用户通过手或用笔输入目标词的特征笔划轨迹(首笔或符合该字笔顺的连写多笔),其笔划轨迹的起点或终点接触错误字、词的首字显示区域,将错误的词选中,进而对语音识别得到的top k个候选词列表(可以被替换的词组合)进行过滤,得到最终的输出。系统由两大主要功能模块组成,分别是语音识别和笔划识别模块。
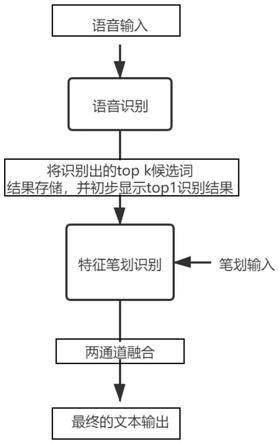
7.基于连续语音与轨迹纠错的多通道输入方法(如图1所示),其步骤为:
8.1)终端设备首先接收语音信号输入。
9.2)语音识别模块将输入的语音信号转化为文本识别结果,并会将语音输入的每个字、词得到的top k候选字、词列表存储在本地或云端,便于之后的纠错过程使用。并在文本输出区域显示出最有可能的识别结果,即top1候选字、词(文本识别结果)。候选字、词列表中的字、词顺序是根据该字、词在上下文字、词影响下计算的概率来决定的。
10.3)用户发现语音识别结果出现错误时,直接在错误字、错误词的首字上绘制对应正确目标字的特征笔划轨迹(首笔或符合该字笔顺的连写多笔),其笔划轨迹的起点或终点与该错误字相接触,从而在输入纠错笔划的过程中将错误的词选中。
11.4)系统通过结合语音输入信息与纠错笔划信息,从候选词列表中过滤出目标输入字,并在纠错笔划输入完毕时(笔尖、手指离开输入平面或鼠标按键抬起),直接在原文字识别结果中替换在上一步中选中的错误字,得到最终的输出。
12.一种终端设备,其特征在于,包括语音识别模块、笔划识别模块和校正模块;其中,
13.语音识别模块,用于将用户输入的语音信号转化为文本识别结果,并对该文本识别结果中的每个字、词生成一对应的候选字、词列表;然后将该该文本识别结果发送到终端设备的文本输出区域进行显示;
14.笔划识别模块,用于识别用户输入的特征笔画轨迹;其中当用户判定该文本识别
结果中出现错误字或错误词时,在所述错误字或所述错误词的首字上绘制对应正确目标字的特征笔划轨迹;
15.校正模块,用于根据错误字、词及其对应的所述特征笔划轨迹,从对应候选字、词列表中过滤出目标输入字或错误词替换对应的错误字或错误词。
16.进一步的,所述特征笔划轨迹为目标字的首笔或符合该目标字笔顺的连写多笔。
17.进一步的,通过所述特征笔划轨迹的起点与所述错误字或所述错误词的首字相接触的方式选中所述错误字或错误词;或者通过所述特征笔划轨迹的终点与所述错误字或所述错误词的首字相接触的方式选中所述错误字或错误词。
18.进一步的,将所述候选字、词列表存储在终端设备本地或云端。
19.进一步的,用户通过手或笔点击错误字、错误词的方式选中所述错误字或所述错误词的首字相接触的方式选中所述错误字或错误词。
20.本发明的优点和有益效果如下:
21.1)基于连续语音与轨迹纠错的多通道输入方法可以在保持输入自然性的同时提高输入的效率。
22.2)采用语音和轨迹这两种输入通道,可以有效的结合两者的优点,从而提高语音输入的准确率。
23.3)本输入方法适用于多种交互的终端设备,从移动手持设备的小屏到大屏,只要有收音模块(接收语音信号)和触摸屏或手写板或鼠标(得到目标词的特征笔划轨迹)都可以使用。
24.4)本输入方法适合不会使用拼音的用户使用,易于学习和使用。
附图说明
25.图1是本发明整体的流程图。
26.图2是语音识别中第一种可能的识别情况的概率转移图。
27.图3是语音识别中第二种可能的识别情况的概率转移图。
具体实施方式
28.为了使本技术领域的人员更好的理解本发明,下面结合附图和实施方式对本发明作进一步的详细说明。
29.下面给出一个例子,使用本发明的方法输入中文“项目开发时间”的过程。本发明的具体实施方式如下:
30.1)首先进行普通的语音识别,终端设备接收到待输入词组的发音,在本实例中,即为“xiang(四声)mu(四声)kai(一声)fa(一声)shi(四声)jian(四声)”。
31.2)根据我们所拥有的历史语料数据,这个词组有多种识别可能,此处便体现了纠错的重要性。假设语音识别系统符合隐马尔科夫模型。第一种可能的情况为(如图2所示):三个确定的状态是“项目”“开发”和“时间”这三个词。从“项目”转移到“开发”的概率是0.25,从“开发”转移到“时间”的概率是0.3。从“项目”输出“xiang(三声)mu(四声)”的概率是0.1,输出”xiang(四声)mu(四声)”的概率是0.8,输出“xiang(四声)mu(一声)”的概率是0.1,“开发”和“时间”也有类似的输出概率。基于以上概率分布,得到最终这个词组“项目开
发时间”的生成概率:p(项目)
×
p(xiang(4)mu(4)|项目)
×
p(开发|项目)
×
p(kai(1)fa(1)|开发)
×
p(时间|开发)
×
p(shi(4)jian(4)|时间)=p(项目)
×
0.8
×
0.25
×
0.9
×
0.3
×
0.05=p(项目)
×
0.0027;第二种可能的情况为(如图3所示):三个确定的状态是“橡木”“开发”和“事件”这三个词。从“橡木”转移到"开发"的概率是0.015,从“开发”转移到“事件”的概率是0.05。从“橡木”输出“xiang(一声)mu(四声)”的概率是0.2,输出“xiang(四声)mu(四声)”的概率是0.8,“开发”和“事件”也有类似的输出概率。基于以上概率分布,得到最终这个词组“项目开发时间”的生成概率:p(橡木)
×
p(xiang(4)mu(4)|橡木)
×
p(开发|橡木)
×
p(kai(1)fa(1)|开发)
×
p(事件|开发)
×
p(shi(4)jian(4)|事件)=p(橡木)
×
0.8
×
0.015
×
0.9
×
0.05
×
0.85=p(橡木)
×
0.000459。最后比较第一种和第二种情况产生的概率,分别是p(项目)
×
0.0027和p(橡木)
×
0.000459。假设p(项目)和p(橡木)相等,那么“项目开发时间”这个词组的概率更高。所以“xiang(四声)mu(四声)kai(一声)fa(一声)shi(四声)jian(四声)”这组发音,系统会识别为“项目开发时间”。但是系统也会分别将“橡木”、“事件”作为候选词保存,为下一步可能发生的纠错提供支持。
32.3)若在语音识别中发生错误,要采用轨迹输入来纠错。在此实例中,语音识别后的最有可能的结果为“橡木开发事件”,但目标词组为“项目开发时间”。直接在错误词“橡木”的首字上绘制首字的特征笔划“木”,其笔划轨迹的起点或终点与该错误词相接触,从而在输入纠错笔划的过程中将错误的词选中。输入的特征笔划结果将被传递到语言识别模块的末尾,用于过滤语音识别后得到的候选词列表以获得最优输出。
33.尽管为说明目的公开了本发明的具体实施例和附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变换和修改都是可能的。本发明不应局限于本说明书最佳实施例和附图所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。