1.本发明涉及人工智能技术领域,针对语音合成质量有待提高的问题,提出了一种基于概率扩散模型的声学模型后处理方法,通过对预测频谱的细节优化,提高了合成语音的自然度。
背景技术:
2.随着人工智能技术的不断发展,基于人工智能技术的各领域问题都取得了巨大的进展。语音合成是人工智能技术中一个重要的方向。语音合成详细是指从文本到音频的合成。语音合成技术的目标是让机器能够发出像人一样的说话声音。高质量的语音合成技术能够满足当前社会中人机交互的需求。
3.现有的语音合成技术首先向文本转换为语言学特征,并结合说话人特征进行特征融合,然后采样深度学习的方式进行编码和解码,得到声学频谱或者直接得到合成的语音波形文件。但存在着得到的声学频谱质量不够高的特点,因此合成的语音波形文件也会相应的有较低的自然度。
技术实现要素:
4.基于此,本发明针对现有语音合成技术的不足,提出了一种基于概率扩散模型的声学模型后处理方法,该方法能够对声学模型得到预测频谱后进行处理,该处理后得到的结果具有更加丰富的频谱细节,也更加接近真实频谱,从而提高合成的语音波形文件的自然度表现。
5.为达到上述发明目的,本发明采用以下技术方案,一种基于概率扩散模型的声学模型后处理方法,包括以下步骤:
6.步骤一、模型训练,利用服务器对概率扩散模型进行训练,通过降低损失函数优化概率扩散模型的参数,直至模型收敛,获得概率扩散模型的权重;包括以下子步骤:
7.s11、利用服务器对特定英文数据集中的文本和对应音频进行特征提取,具体为:从文本中提取语言学特征,从音频中提取对应的音高和音强,同时从音频中使用特定的声学参数提取出梅尔频谱作为真实频谱,并结合音频和语言学特征提取出音素序列,再结合梅尔频谱和音素序列使用对齐搜索的方法获得时长信息;
8.s12、利用服务器对步骤s11得到的音素序列、时长信息、音高和音强、梅尔频谱进行声学模型的建模;所述声学模型的建模过程包括:首先对音素序列进行编码,然后使用时长信息将音素序列对齐到梅尔频谱的长度,再添加对应的音高和音强特征,接着进行序列解码,最终得到生成的预测频谱;
9.s13、利用服务器对提取得到的真实频谱进行概率扩散模型的计算,具体为:通过设计特定的随扩散步数而变化的噪声系数,计算不同扩散步数下噪声系数所对应的条件概率的数据分布,该数据分布符合多元随机高斯分布,均值记为方差记为在经过设
定的全部扩散步数的概率转移后,得到扩散空间的隐向量采样点;
10.s14、利用服务器进行概率扩散模型训练,具体为:根据步骤s13中计算得到的扩散空间隐向量采样点与步骤s12生成的预测频谱计算损失函数lm,并通过概率扩散模型中的噪声估计网络计算概率扩散模型在不同扩散步数下对应的概率分布,该概率分布符合多元随机高斯分布,均值记为方差记为根据其与步骤s13得到的均值和方差计算损失函数ln,损失函数lm和ln按照预设的权重λm和λn进行加权,在服务器上进行统一训练,加权后的损失函数计算公式为l=lmλm lnλn;
11.s15、利用服务器根据损失函数l计算梯度,具体为:梯度是指损失函数表达式对模型中可学习参数求偏导,然后使用adam优化器反向传播更新概率扩散模型的参数,使损失函数l降低直至收敛,至此训练结束,得到训练好的概率扩散模型的权重;
12.步骤二、模型推断,根据训练阶段获得的模型权重,利用服务器对输入的预测频谱实现频谱优化,包括以下子步骤:
13.s21、将预测频谱作为概率扩散空间的均值,以多元随机高斯分布的方差作为方差,得到扩散空间的采样点,然后将该采样点进行反向概率扩散,具体为:每扩散一步,使用训练好的噪声估计网络权重得到当前步数t下分布的均值和方差然后逐步实现概率分布的转移,最终在走完预设的步数时,得到优化的预测频谱;
14.s22、利用服务器对优化的预测频谱进行波形重建,得到语音波形文件。
15.进一步地,步骤s11所取的声学参数具体为:最小频率和最大频率分别是0和8000hz,采样率为22050,fft计算的点数为1025,设定提取梅尔频谱为80维。
16.所述的对齐搜索的方法设计为将三个音素作为一个单位,下一个单位包含上一个单位的后两个音素,将此搜索单位与梅尔频谱的每一帧计算相关系数,并使用动态规划算法将相关系数最大的项设为1,最后得到的时长信息是与音素序列等长的自然数序列,且该自然数序列的和与对应的梅尔频谱长度相符。
17.进一步地,步骤s12中的对音素序列编码,使用基于多头注意力机制和一维卷积的运算作为一个编码层,共采用4层编码结构设计;
18.所述使用时长信息将音素序列对齐到梅尔频谱的长度,包括:时长信息表示编码后隐序列中某个向量对应的发声时长,按照该时长将对应向量重复一定次数,然后对序列中所有向量进行相同操作,并在时间维度上串联,得到与梅尔频谱长度相同的隐序列;
19.所述序列解码同样基于4层多头注意力机制和一维卷积结合的解码器结构,并在解码后使用线性层将隐序列的维度映射到梅尔频谱的维度,从而生成预测频谱。
20.进一步地,步骤s13中所述的扩散步数为1000步,所述随扩散步数t而变化的噪声系数β
t
的计算公式为β
t
=β0 (β
1-β0)t,其中β0和β1分别取值为0.05和20。
21.所述条件概率的数据分布的均值和方差计算公式为:
[0022][0023]
式中x
t-1
为当前扩散步数前一步的隐向量,i表示单位矩阵。
[0024]
进一步地,步骤s14中所述的噪声估计网络使用2个4层的二维卷积结构,第一个4层的二维卷积结构中,每层之间使用基于最大池化的下采样,将隐序列下采样一倍;第二个4层的二维卷积结构中,每层之间使用基于最近邻插值的上采样,将隐序列上采样一倍,且
在每层的上采样计算时会将当前结果与对应分辨率的下采样隐序列在时间维度上进行并联,最后使用线性层将输出维度映射为梅尔频谱的维度。
[0025]
所述的权重λm和λn取值分别为1和0.4。
[0026]
进一步地,步骤s15中所述直至收敛的训练步数为1000。
[0027]
进一步地,步骤s21中在使用训练好的模型进行反向概率扩散时,预设的步数为100,得到的优化预测频谱更加接近真实频谱,因此通过后处理进一步提升了声学模型合成频谱的质量。
[0028]
进一步地,步骤s22中所述的波形重建,具体为:首先初始化一个相位谱,根据优化后的预测频谱和初始化的相位谱,通过反短时傅里叶变换(istft)得到波形文件,然后再对波形文件计算短时傅里叶变换(stft),得到新的频谱和相位谱,接着丢弃新的频谱,使用优化后的预测频谱和新的相位谱再次合成波形,对这个过程重复多次,直到获得较为自然的语音波形文件,该得到的语音波形文件采样率为22050,输出格式为wav。
[0029]
本发明还提供一种服务器,包括存储器及处理器,所述存储器中储存有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如上方法的步骤。
[0030]
本发明还提供一种可读存储器,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上方法的步骤。
[0031]
本发明的优点及有益效果如下:
[0032]
(1)通过基于概率扩散模型的设计使模型学习到预测频谱和真实频谱之间的差异,从而能够合成质量更高的优化频谱;
[0033]
(2)通过合理的模型和参数设计及模型训练使合成的优化频谱能够得到自然度更高的语音结果。
附图说明
[0034]
图1为本发明方法的步骤流程图;
[0035]
图2为本发明的实施效果,上下两幅图分别是预测频谱和优化频谱;
[0036]
图3为一个实施例中服务器的内部结构示意图。
具体实施方式
[0037]
为了更好地解释本发明所述的方法,下面通过具体实施例结合附图对本发明的技术方案作进一步描述说明,使得本方法更加清楚明白。通过本说明书所揭露的内容,本领域技术人员可轻易地了解本发明的作用。本发明还可以通过其他的具体实施方法进行实施或应用,本说明书的各项细节也可以基于不同观点进行修改,在没有背离本发明的实质下进行各种修饰或改变。需要说明的是,在不冲突的情况下,以下实施例及其中的特征可以进一步进行组合。
[0038]
详细来讲,本发明提出了一种基于概率扩散模型的声学模型后处理方法,包括以下具体实施内容:
[0039]
步骤一、模型训练,利用服务器对概率扩散模型进行训练,通过降低损失函数优化概率扩散模型的参数,直至模型收敛,获得概率扩散模型的权重;包括以下子步骤:
[0040]
s11、利用服务器对特定英文数据集中的文本和对应音频进行特征提取,具体为:
从文本中提取语言学特征,从音频中提取对应的音高和音强,同时从音频中使用特定的声学参数提取出梅尔频谱作为真实频谱,并结合音频和语言学特征提取出音素序列,再结合梅尔频谱和音素序列使用对齐搜索的方法获得时长信息;
[0041]
s12、利用服务器对步骤s11得到的音素序列、时长信息、音高和音强、梅尔频谱进行声学模型的建模;所述声学模型的建模过程包括:首先对音素序列进行编码,然后使用时长信息将音素序列对齐到梅尔频谱的长度,再添加对应的音高和音强特征,接着进行序列解码,最终得到生成的预测频谱;
[0042]
s13、利用服务器对提取得到的真实频谱进行概率扩散模型的计算,具体为:通过设计特定的随扩散步数而变化的噪声系数,计算不同扩散步数下噪声系数所对应的条件概率的数据分布,该数据分布符合多元随机高斯分布,均值记为方差记为在经过设定的全部扩散步数的概率转移后,得到扩散空间的隐向量采样点;
[0043]
s14、利用服务器进行概率扩散模型训练,具体为:根据步骤s13中计算得到的扩散空间隐向量采样点与步骤s12生成的预测频谱计算损失函数lm,并通过概率扩散模型中的噪声估计网络计算概率扩散模型在不同扩散步数下对应的概率分布,该概率分布符合多元随机高斯分布,均值记为方差记为根据其与步骤s13得到的均值和方差计算损失函数ln,损失函数lm和ln按照预设的权重λm和λn进行加权,在服务器上进行统一训练,加权后的损失函数计算公式为l=lmλm lnλn;
[0044]
s15、利用服务器根据损失函数l计算梯度,具体为:梯度是指损失函数表达式对模型中可学习参数求偏导,然后使用adam优化器反向传播更新概率扩散模型的参数,使损失函数l降低直至收敛,至此训练结束,得到训练好的概率扩散模型的权重;
[0045]
步骤二、模型推断,根据训练阶段获得的模型权重,利用服务器对输入的预测频谱实现频谱优化,包括以下子步骤:
[0046]
s21、将预测频谱作为概率扩散空间的均值,以多元随机高斯分布的方差作为方差,得到扩散空间的采样点,然后将该采样点进行反向概率扩散,具体为:每扩散一步,使用训练好的噪声估计网络权重得到当前步数t下分布的均值和方差然后逐步实现概率分布的转移,最终在走完预设的步数时,得到优化的预测频谱;
[0047]
s22、利用服务器对优化的预测频谱进行波形重建,得到语音波形文件。
[0048]
其中,步骤s11所取的声学参数详细为:最小频率和最大频率分别是0和8000hz,采样率为22050,fft计算的点数为1025,设定提取梅尔频谱为80维。
[0049]
所述的特定英文数据集是语音领域公开的学术数据集,包含了13100条单说话人的、来自7部非小说类书籍的阅读段落音频剪辑。剪辑的长度从1秒到10秒不等,总长度约为24小时。
[0050]
所述的对齐搜索方法设计为将三个音素作为一个单位,下一个单位包含上一个单位的后两个音素,将此搜索单位与梅尔频谱的每一帧计算相关系数,并使用动态规划的算法将相关系数最大的项设为1,最后得到的时长信息是与音素序列等长的自然数序列,且该自然数序列的和与对应的梅尔频谱长度相符。
[0051]
所述相关系数的计算,具体为计算搜索单位上三个音素分别与当前一帧梅尔频谱的欧式距离,然后将三个计算得到的欧式距离相加,即得到此搜索单位与一帧梅尔频谱的
相关系数。
[0052]
步骤s12中的对音素序列编码,使用基于多头注意力机制和一维卷积的运算作为一个编码层,共采用4层编码结构设计;
[0053]
所述使用时长信息将音素序列对齐到梅尔频谱的长度,包括:时长信息表示编码后隐序列中某个向量对应的发声时长,按照该时长将对应向量重复一定次数,然后对序列中所有向量进行相同操作,并在时间维度上串联,得到与梅尔频谱长度相同的隐序列;
[0054]
所述序列解码同样基于4层多头注意力机制和一维卷积结合的解码器结构,并在解码后使用线性层将隐序列的维度映射到梅尔频谱的维度,从而生成预测频谱。
[0055]
步骤s13中所述的扩散步数为1000步,所述随扩散步数t而变化的噪声系数β
t
的计算公式为β
t
=β0 (β
1-β0)t,其中β0和β1分别取值为0.05和20。
[0056]
所述条件概率的数据分布的均值和方差计算公式为:
[0057][0058]
式中x
t-1
为当前扩散步数前一步的隐向量,i表示单位矩阵。
[0059]
步骤s14中所述的噪声估计网络使用2个4层的二维卷积结构,第一个4层的二维卷积结构中,每层之间使用基于最大池化的下采样,将隐序列下采样一倍;第二个4层的二维卷积结构中,每层之间使用基于最近邻插值的上采样,将隐序列上采样一倍,且在每层的上采样计算时会将当前结果与对应分辨率的下采样隐序列在时间维度上进行并联,最后使用线性层将输出维度映射为梅尔频谱的维度。
[0060]
对该噪声估计网络进行详细距离说明:设输入序列长度为n,输入的隐序列表示为x=(x1,x2,
…
,xn),则在第一个4层的二维卷积结构中,每层下采样的输出表示为x1=(x1,x2,
…
,x
n/2
),x2=(x1,x2,
…
,x
n/4
),x3=(x1,x2,
…
,x
n/8
)和x4=(x1,x2,
…
,x
n/16
),其中,每层下采样隐序列的长度将缩减为原来的即对应长度分别为和在第二个4层的二维卷积结构中,第一次上采样的输入为y4=(x1,x2,
…
,x
n/16
),输出为y3=(x1,x2,
…
,x
n/8
),接下来每层上采样计算时首先将yi和xi在时间维度上并联,然后再上采样输出为y
i-1
,经过4次上采样后输出y1,再通过线性层得到输出的梅尔频谱。
[0061]
所述的权重λm和λn取值分别为1和0.4。
[0062]
步骤s15中所述直至收敛的训练步数为1000。
[0063]
步骤s21中在使用训练好的模型进行反向概率扩散时,预设的步数为100,得到的优化预测频谱更加接近真实频谱,因此通过后处理进一步提升了声学模型合成频谱的质量。
[0064]
步骤s22中所述的波形重建,详细为:首先初始化一个相位谱,根据优化后的预测频谱和初始化的相位谱,通过反短时傅里叶变换(istft)得到波形文件,然后再对波形文件计算短时傅里叶变换(stft),得到新的频谱和相位谱,接着丢弃新的频谱,使用优化后的预测频谱和新的相位谱再次合成波形,对这个过程重复多次,直到获得较为自然的语音波形文件,该得到的语音波形文件采样率为22050,输出格式为wav。
[0065]
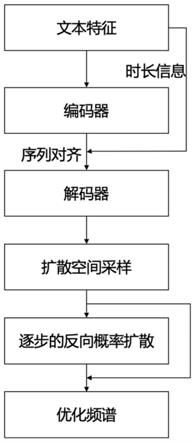
如图1所示,输入的文本首先转换为文本特征,即所述的音素序列,同时也包括基于文本和音频提取出的音高和音强特征,然后将文本特征输入所述的编码器中,得到编码后的隐序列,此时隐序列的长度与文本编码的长度一致,接着通过旁路,也就是提取得到的
时长信息,对文本编码后得到的隐序列进行对齐操作,也就是所述的根据时长对特定向量进行时长次数的重复,将得到的与频谱序列对齐的隐向量输入到所述的解码器中,得到解码后产生的预测频谱。
[0066]
如图2所示,预测频谱较为平滑,虽然具备了合成语音的绝大部分信息,但缺少一些细粒度的频谱特征,因此在合成语音中会降低自然度表现。
[0067]
如图1所示,将得到的预测频谱作为扩散空间的均值,在扩散空间中通过特定的数据分布得到采样点,然后通过共100步的逐步反向概率扩散计算,在概率扩散中使用训练好的噪声估计网络对每步的分布计算转移概率,最后得到合成的优化频谱。
[0068]
如图2所示,下面一幅图是优化频谱,相比于预测频谱更加富有细节,该频谱细节使得合成语音提高了自然度表现。
[0069]
图3为一个实施例中服务器的内部结构示意图。如图3所示,该服务器包括通过系统总线连接的处理器和存储器。其中,该处理器用于提供计算和控制能力,支撑整个服务器的运行。存储器可包括非易失性存储介质及内存储器。非易失性存储介质存储有操作系统和计算机程序。该计算机程序可被处理器所执行,以用于实现以下各个实施例所提供的一种基于概率扩散模型的声学模型后处理方法。内存储器为非易失性存储介质中的操作系统计算机程序提供高速缓存的运行环境。该服务器可以是手机、平板电脑或者个人数字助理或穿戴式设备等。
[0070]
本发明实施例还提供了一种计算机可读存储介质。一个或多个包含计算机可执行指令的非易失性计算机可读存储介质,当计算机可执行指令被一个或多个处理器执行时,使得处理器执行基于概率扩散模型的声学模型后处理方法的步骤。
[0071]
一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行基于概率扩散模型的声学模型后处理方法。
[0072]
本发明实施例所使用的对存储器、存储、数据库或其它介质的任何引用可包括非易失性和/或易失性存储器。合适的非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram),它用作外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddr sdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)。
[0073]
以上实施例仅表达了本发明的几种实施方式,其描述较为具体和详细但并不能因此而理解为对本技术专利范围的限制。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。