1.本发明涉及声学场景分类领域,尤其涉及一种声学场景分类方法。
背景技术:
2.随着智能语音技术的快速发展和人工智能相关应用的兴起,声学场景分类技术已逐渐被应用到人们的日常生活中。声学场景分类技术是利用音频信号处理和深度学习技术完成对声学场景(家庭、公园和街道场景等)的识别与分类,从而达到识别周围环境的目的。
3.声学场景分类技术在人们的生活中有着广泛的作用,如上下文感知服务、可穿戴智能设备和机器人导航系统等。在基于场景分类的自适应降噪技术中,若判断当前场景为机场,自动开启机场去噪模式,若判断为街道场景,则开启街道去噪模式;huawei 动态降噪耳机,利用asc技术快速辨认周围环境,主动切换到恰当的降噪模式,削弱安静场景下的空调、冰箱等机器噪声,削弱地铁和飞机带来的重低频噪声,使用户静享安逸,远离喧嚣。在基于场景的asr技术中,智能机器可以自主加载特定声学环境下的声学模型,以达到对该场景下语音的精准识别。asc技术也用于盲人助听器和机器人轮椅时,设备可根据周围环境变化进行功能自主调节。以上所述这些技术均可大幅提升用户体验和产品满意度。
4.基于深度学习的声学场景分类技术可以充分学习声场谱图中的信息,提高声学场景类别准确率。深度神经网络中的分类模型是样本到样本标签的一个映射关系,通常为“街道交通”、“机场”、“购物中心”、“火车”、“地铁”和“公交车”等等,在得到分类结果时,也会统计在不同录音设备下的场景分类准确度。但在实际应用中,收集的场景数据常由不同的录音设备进行录制,而设备引起的失真导致不同类别间的混淆程度的加重,因此基于多设备的声学场景分类模型性能仍然不佳,难以达到实际应用所需要的精准度。
技术实现要素:
5.有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是现有技术中存在的收集场景数据常因不同设备录制而引起的失真,从而导致不同类别间的混淆程度加重,且多种设备的声学场景分类模型性能不佳,难以达到实际所需的精度。因此,本发明提供了一种声学场景分类方法,将设备特性分类和自动识别功能加入到声学场景分类模型的构建和训练过程中,提升声学场景分类模型的性能和自适应能力。其在使用过程中,能对用户的使用设备及数据进行自动收集和整理,为每位用户定制特定的声学场景分类模型,使模型更大程度忽略特定设备引起的失真,提升系统性能,为用户带来较佳的体验感。
6.为实现上述目的,本发明提供了一种声学场景分类方法,包括以下步骤:
7.首先针对采用参考设备录制的场景数据,训练基本场景分类模型;
8.然后根据采用移动设备录制的场景数据,训练设备独立场景分类模型;
9.根据训练好的设备独立场景分类模型,训练设备分类模型;
10.利用训练好的设备分类模型提取设备特性,结合设备分类模型,获得设备识别模型;
11.所有模型建立之后,进行数据自动录制并收集存储,并对收集的录制数据进行声学场景命名,并存储至云端;
12.根据用户参数,获得个性化定制的场景分类模型。
13.进一步地,首先针对采用参考设备录制的场景数据,训练基本场景分类模型,具体包括:
14.利用参考设备a的声学场景数据集,提取对数梅尔频谱图作为声学特征,用9层卷积神经网络对声学场景数据集的声学特征进行训练,获得基本场景分类模型a
‑
asc。
15.进一步地,提取对数梅尔频谱图作为声学特征之前,对声学场景数据集进行预处理,再对预处理后的音频数据进行语音分析,提取对数梅尔频谱图作为声学特征。
16.进一步地,对数梅尔声谱图是将声学场景数据集中的音频数据进行傅里叶变换转换到频域上,采用梅尔频率滤波器对频域信号进行再处理;然后接入一组梅尔频率滤波器,将声谱图转换到更符合人耳听觉的mel域,获得维度较低的梅尔频谱图,在梅尔频谱图的基础上,将每个频段的特征值进行对数运算,可以获得对数梅尔频谱图。
17.进一步地,然后根据采用移动设备录制的场景数据,训练设备独立场景分类模型,具体包括:
18.从一个或多个移动设备录制的音频形成移动设备音频数据集,提取移动设备音频数据集中数据的声学特征,并在基本场景分类模型a
‑
asc上进行微调,获得与设备无关的设备独立场景分类模型bc
‑
asc。
19.进一步地,根据训练好的设备独立场景分类模型,训练设备分类模型,具体包括:
20.加载训练好的设备独立场景分类模型bc
‑
asc,分别提取声学场景数据集、不同设备录制的同一信号的数据集的网络中层表征;根据声学场景数据集的表征向量进行加权平均获得类均值向量e
k
,k表示第k类场景,将不同设备录制的同一信号的数据集中音频片段的表征向量定义为e
kn
,表示第k类的第n个音频片段的网络表征,从而获得不同设备录制的同一信号的数据集中每条音频记录存在的设备特性表示第k类的第n个由第d个设备录制音频片段的所含的设备特性,网络表征最后用2层卷积神经网络和1层全连接层组成的模型cnn2对设备特性进行学习和分类,获得设备分类模型device
‑
c。
21.进一步地,利用训练好的设备分类模型提取设备特性,结合设备分类模型,获得设备识别模型,具体包括:
22.利用提取的设备特性和设备分类模型device
‑
c,将模型cnn2作为设备识别模型的编码器部分,并设定网络参数,利用解码器部分对设备特性进行重构,获得设备识别模型device
‑
r。
23.进一步地,根据用户参数,获得个性化定制的场景分类模型包括个性化注册和个性化分类;其中,
24.个性化注册包括根据用户设备参数,加载相关模型,识别用户的某段输入音频,识别音频所表征的声学场景及使用的移动设备,对用户的使用数据进行分类,获得用户专属数据;根据用户专属数据,提取用户专属数据的声学特征,并于设备独立场景分类模型中进行微调,获得个性化定制的场景分类模型;
25.个性化分类包括当用户使用时,获得的测试语句会经过个性化的声学场景分类模型user
‑
asc,判断出用户当前所处的声学场景类别,辅助其它应用软件。
26.进一步地,还包括更新声学场景分类模型,利用收集移动设备录制的声学场景的数据,用以更新设备独立场景分类模型bc
‑
asc,从而获得更新后的个性化定制的场景分类模型。
27.进一步地,在具体实施例中,声学场景数据集为声音场景分类和声音事件检测挑战赛的开发集的音频数据,每段音频均是10s时长、采样率为44.1khz、24bit量化率的单声道音频数据集。
28.技术效果
29.本发明的一种声学场景分类方法具有数据自动手机存储、设备识别判决和云端更新的功能,可以对不同设备录制的场景数据进行收集整理,生成用户的专属训练数据,解决用户数据量匮乏的问题,并且可以通过微调模型获得针对具体用户个性化定制的声学场景分类模型,可更大程度地忽略设备带来的失真,更准确地确定相应的声学场景。
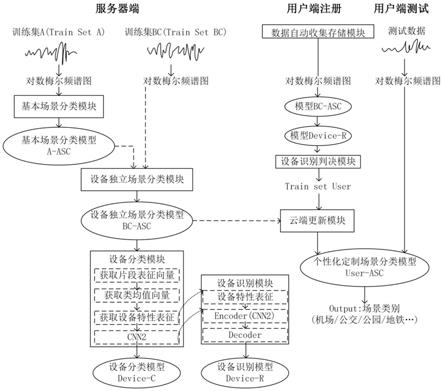
30.以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
31.图1是本发明的一个较佳实施例的一种声学场景分类方法的流程示意图;
32.图2是本发明的一个较佳实施例的一种声学场景分类方法的对数梅尔频谱图的提取流程图;
33.图3是本发明的一个较佳实施例的一种声学场景分类方法的基于cnn9的声学场景分类流程图;
34.图4是本发明的一个较佳实施例的一种声学场景分类方法的设备分类模型流程图;
35.图5是本发明的一个较佳实施例的一种声学场景分类方法的设备识别框架流程图;
36.图6是本发明的一个较佳实施例的一种声学场景分类方法的设备识别及数据整理流程示意图;
37.图7是本发明的一个较佳实施例的基于个性化定制的声学场景分类方法的数据分配比例图。
具体实施方式
38.为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
39.以下描述中,为了说明而不是为了限定,提出了诸如特定内部程序、技术之类的具体细节,以便透彻理解本发明实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
40.如图1所示,本发明实施例提供了一种声学场景分类方法,包括以下步骤:
41.步骤100,首先针对采用参考设备录制的场景数据,训练基本场景分类模型;具体
包括:利用参考设备a的声学场景数据集(train set a),提取对数梅尔频谱图作为声学特征,用9层卷积神经网络对声学场景数据集的声学特征进行训练,获得基本场景分类模型a
‑
asc。
42.步骤200,然后根据采用移动设备录制的场景数据,训练设备独立场景分类模型;具体包括:从一个或多个移动设备录制的音频形成移动设备音频数据集(train set bc),提取移动设备音频数据集中数据的声学特征,并在基本场景分类模型a
‑
asc上进行微调,获得与设备无关的设备独立场景分类模型bc
‑
asc。
43.步骤300,根据训练好的设备独立场景分类模型,训练设备分类模型;具体包括:
44.加载训练好的设备独立场景分类模型bc
‑
asc,分别提取声学场景数据集(trainset a)、不同设备录制的同一信号的数据集(train set abc)的网络中层表征;根据声学场景数据集(train set a)的表征向量进行加权平均获得类均值向量e
k
,k表示第k 类场景,将不同设备录制的同一信号的数据集(train set abc)中音频片段的表征向量定义为e
kn
,表示第k类的第n个音频片段的网络表征,从而获得不同设备录制的同一信号的数据集中每条音频记录存在的设备特性表示第k类的第n个由第d个设备录制音频片段的所含的设备特性,网络表征最后用2层卷积神经网络和1层全连接层组成的模型cnn2对设备特性进行学习和分类,获得设备分类模型device
‑
c。
45.步骤400,利用训练好的设备分类模型提取设备特性,结合设备分类模型,获得设备识别模型device
‑
r;具体包括:利用提取的设备特性和设备分类模型device
‑
c,将模型cnn2作为设备识别模型的编码器部分,并设定网络参数,利用解码器部分对设备特性进行重构,获得设备识别模型device
‑
r。
46.步骤500,所有模型建立之后,进行数据自动录制并收集存储,并对收集的录制数据进行声学场景命名,并存储至云端;当用户使用与语音相关应用软件(聊天软件、购物软件、导航软件等)时,自动启用环境音录制功能,忽略用户聊天内容,保护用户的隐私,将录制的声学场景数据命名为user
‑
n(n=1、2、
…
、n)格式,n表示音频数据的总数目,为了节省客户端内存,将用户的所有数据转存到云端;提取用户专属数据train set user的声学特征,并在已于服务端训练好的模型bc
‑
asc上进行微调,使模型可以更大程度的忽略设备带来的失真,更精准的确定相应声学场景,获得个性化定制的场景分类模型user
‑
asc。
47.步骤600,根据用户参数,获得个性化定制的场景分类模型,包括个性化注册和个性化分类;其中,
48.个性化注册包括根据用户设备参数,加载相关模型,识别用户的某段输入音频,识别音频所表征的声学场景及使用的移动设备,对用户的使用数据进行分类,获得用户专属数据(即设备识别判决);根据用户专属数据,提取用户专属数据的声学特征,并于设备独立场景分类模型中进行微调,获得个性化定制的场景分类模型;
49.个性化分类包括当用户使用时,获得的测试语句会经过个性化的声学场景分类模型user
‑
asc,判断出用户当前所处的声学场景类别,辅助其它应用软件,进一步提升用户使用感。
50.其中,提取对数梅尔频谱图作为声学特征之前,对声学场景数据集进行预处理,再对预处理后的音频数据进行语音分析,提取对数梅尔频谱图作为声学特征。对数梅尔声谱图是将声学场景数据集中的音频数据进行傅里叶变换转换到频域上,采用梅尔频率滤波器
对频域信号进行再处理;然后接入一组梅尔频率滤波器,将声谱图转换到更符合人耳听觉的mel域,获得维度较低的梅尔频谱图,在梅尔频谱图的基础上,将每个频段的特征值进行对数运算,可以获得对数梅尔频谱图。
51.进一步地,还包括更新声学场景分类模型,利用收集移动设备录制的声学场景的数据,用以更新设备独立场景分类模型bc
‑
asc,从而获得更新后的个性化定制的场景分类模型。
52.进一步地,设备识别判决是指加载相关模型bc
‑
asc、device
‑
r,给定用户的某段输入音频user
‑
n,识别该段音频所表征的声学场景及所使用的移动设备,因此可以对用户的使用数据进行分类,获得用户的专属数据train set user。
53.本发明的一种声学场景分类方法包括了基本场景分类模块、设备独立场景分类模块、设备分类模块、设备识别模块、数据自动收集存储模块、设备识别判决模块、云端更新模块。其中,数据自动收集存储模块、设备识别判决模块和云端更新模块属于用户端注册阶段,其余模块均属于服务器端。
54.本发明一种声学场景分类方法主要设置了数据自动收集存储模块、设备识别判决模块和云端更新模块,用于用户数据的收集整理和场景分类模型的更新。位于用户端的数据自动收集存储模块,当用户使用语音相关的应用程序时,会启动环境声录制功能,尽可能避开用户的聊天内容,仅自动收集用户所处声学环境的音频,并存储到云端,方便后续的使用;为了达到对设备分类和识别的目的,收集的用户数据作为模型 bc
‑
asc、device
‑
r的输入,并将模型device
‑
r的输出作为设备识别判决模块的输入,当输入音频的得分小于所设阈值,则将其判为已知设备,输出设备标签,否则将其归为未知设备。因此可以对不同设备录制的场景数据进行收集整理,生成用户的专属训练数据(train set user),解决用户数据量匮乏的问题;云端更新模块位于用户端,为了达到个性化的声学场景分类的目的,利用用户的专属训练数据train set user再次微调模型bc
‑
asc,获得针对该用户个性化定制的声学场景分类模型(user
‑
asc)。该模型user
‑
asc会更大程度的忽略设备带来的失真,更准确地确定相应的声学场景。
55.以下将详细阐述本发明实施例的具体实施方式:
56.步骤100,首先针对采用参考设备录制的场景数据,训练基本场景分类模型:对参考设备所录制的声学场景数据集train set a提取声学特征—对数梅尔频谱图。在提取声学特征前,可以先对音频数据进行预处理操作,以保证对数梅尔声谱图提取过程的顺利性,再对预处理后的音频数据进行语音分析,提取对数梅尔频谱图(logmel spectrogram)作为声学特征。对数梅尔声谱图是将音频数据进行傅里叶变换转换到频域上,采用梅尔频率滤波器对频域信号进行再处理。由于原始信号就是1维的声学信号,对一维信号进行预加重、分帧和加窗操作后,再短时傅里叶变换(stft) 得到二维信号,即标准的声谱图。由于声谱图维度较大,包含了大量冗余信息,且人耳对声音的感知是非线性的,因此接入一组梅尔频率滤波器,将声谱图转换到更符合人耳听觉的mel域,也可以获得维度较低的梅尔频谱图,在梅尔频谱图的基础上,将每个频段的特征值进行对数运算,可以获得对数梅尔频谱图,有利分离频谱包络和频谱细节。具体流程如图2所示。
57.本实施例中,选择cnn9网络作为模型a
‑
asc的网络结构,将对数梅尔频谱图作为cnn9的输入,经过网络的学习可实现声学场景分类。cnn9模型是由多层卷积层堆叠的网络,
由4个卷积块(conv block)的堆叠,每个卷积块实际包括两次卷积(conv layer)和一次平均池化(avgpooling),并且每次卷积之间均进行批标准化操作(bn),激活函数是线性修正单元(relu),然后利用池化层进行降维,最后接入全连接层,全连接层使用的激活函数是softmax函数,输出当前输入属于场景类别的概率值,损失函数是交叉熵损失函数。
58.基于cnn9的声学场景分类流程图如图3所示,cov表示二维卷积,卷积核的大小为3
×
3,设置步长为1,激活函数为线性修正单元(relu),批处理(bn), 平均池化层(avgpooling)设置池化核分别为2
×
2、1
×
1,最后的池化层用来进行降维,设置全连接层的神经元个数为10,softmax输出当前输入属于场景类别的概率值。
59.步骤200,然后根据采用移动设备录制的场景数据,训练设备独立场景分类模型:利用移动设备的训练集train set bc对模型a
‑
asc进行微调,更新网络参数,获得设备独立场景分类模型bc
‑
asc;
60.步骤300,根据训练好的设备独立场景分类模型,训练设备分类模型:为了获取音频片段的网络表征,定义cnn9网络的最后一层池化层的输出为表征提取层,提取的表征向量为512维,提取数据集train set a的网络表征向量,并计算场景类别均值表征e
k
,具体计算如公式(1)所示:
[0061][0062]
式中,k表示第k个场景类别,n
k
表示使用参考设备a录制的第k类的音频数据, e
kn
表示第k类的第n个音频片段的网络表征,e
k
表示第k类的类均值表征,使第k类声学场景的表征。
[0063]
然后根据要求筛选不同设备录制的相同信号,提取该数据集train set abc相应的网络表征信息,并计算每一段音频记录存在的设备特性。定义train set abc的片段表征向量与类均值向量e
k
的差值为当前片段的设备特性作为设备分类模型的输入。关于设备特性的计算如公式(2)所示:
[0064][0065]
式中,k表示第k个场景类别,e
k
表示第k类的类均值向量,表示属于第k类的第n个音频数据的表征向量,d表示所使用的录音设备,分别为设备a、b和c。
[0066]
最后搭建设备分类模型,该模型由2层一维卷积层和1层全连接神经网络 (dense layer)、线性修正单元(relu)激活函数构成,softmax输出为设备的类别,损失函数是交叉熵损失函数,在训练集train set abc上进行学习,并获得最佳的设备分类模型device
‑
c。
[0067]
如图4所示,设备分类模型由2层一维卷积层和一层全连接组成,分别设置卷积核的个数为256、128,设置全连接层神经元的个数为10。
[0068]
步骤400,利用训练好的设备分类模型提取设备特性,结合设备分类模型,获得设备识别模型device
‑
r:选择自编码器作为设备识别模型,主要由编码器(encoder)和解码器(decoder)组成,使用模型device
‑
c的网络结构作为encoder 部分,并固定该部分参数。decoder则是与encoder对称的网络结构,使用最小误差函数作为损失函数,训练decoder部分,从而完成对设备特性的重构,获得设备识别模型device
‑
r;
[0069]
如图5所示,conv1d表示一维卷积,卷积核的大小为2
×
1,设置步长为1,其中卷积
层的个数分别设置为相对称的个数256、128、128、256个,激活函数为线性修正单元(relu),引入bn机制。
[0070]
步骤500,所有模型建立之后,进行数据自动录制并收集存储,并对收集的录制数据进行声学场景命名,并存储至云端。该步骤实际上包括数据自动收集存储模块和设备识别判决模块和云端更新模块。
[0071]
1、数据自动收集存储模块:为了提升用户的使用感,且考虑到移动设备录制的数据录制成本较高,因此在用户使用过程中,对各用户的使用数据进行收集并整理。当用户使用与语音相关应用软件(聊天软件、购物软件、导航软件等)时,自动启用环境音录制功能,忽略用户聊天内容,保护用户的隐私,将录制的声学场景数据命名为user
‑
n(n=1、2、
…
、n)格式,n表示音频数据的总数目,然后将用户的所有数据转存到云端,方便后续使用。
[0072]
2、设备识别判决模块:加载模型bc
‑
asc、device
‑
r,将用户数据作为上述模型的输入,根据输出结果,识别用户数据所表征的声学场景及所使用的移动设备,对用户使用数据进行分类,达到获得用户的专属数据train set user的目的。当模型device
‑
r的得分小于阈值θ时,则将录制设备判断为已知设备,并给出设备标签,若得分大于阈值,则直接将其判断为未知设备。随机抽取用户的一条数据,本发明提出的设备识别及数据整理流程如图6所示。
[0073]
3云端更新模块:由于上述步骤已获取了用户常用的设备和常在的声学场景环境数据集train set user,利用用户数据再次微调分类模型bc
‑
asc。该模型会学习到用户使用的移动设备特性,提高对用户常用设备所录制的音频数据的分类准确度,建立个性化定制的场景分类模型user
‑
asc,提升用户使用感。
[0074]
以下将举一例子来说明上述实施例。
[0075]
另外,为了验证本发明所提方法的有效性,在声学场景分类和检测的国际评测 dcase的相应任务上进行了初步的验证,具体介绍如下:
[0076]
(1)数据集配置:
[0077]
本实例获取到的音频数据集来自声音场景分类和声音事件检测挑战赛 (detection and classification of acoustic scenes and events(dcase),选用dcase2019中声学场景分类任务(acoustic scenes classification)的音频数据集tuturban acoustic scenes 2019,该数据集分别记录了11个不同城市的十种声学场景,分别为:机场、商场、站台、人行接到、公共广场、街道(机动车道)、电车、公交、城市公园。每个场景类别已预定义过,并且选择合适的位置进行录制。
[0078]
该数据集包括开发集(development dataset,共16560段)和验证集(evaluationdataset,共10800段)。本实施例仅使用开发集数据(development),开发集数据被进一步划分为一个训练集(train set,共10265段)、一个测试集(test set,共5265段) 用于系统训练。每段音频均是10s时长、采样率为44.1khz、24bit量化率的单声道音频数据集。使用的录音设备为soundman okm ii klassik/studio a3、驻极体双耳麦克风和一个使用48khz采样率和24位分辨率的zoom f8录音机,称为参考设备a;其它常见的移动设备包含三星galaxy s7、苹果iphone se,分别称为设备 b、c;当待测音频不是由上述4种设备所录制时,称为未知设备数据。
[0079]
针对声学场景音频数据集的训练集数据进行再次划分,将参考设备a录制的音频
数据集定义为train set a,将移动设备b、c录制的音频数据集定义为 train set bc,将参考设备和移动设备共同录制的音频数据集定义为train set abc,关于数据集配置的具体细节如图7所示。
[0080]
以上,是本实例所使用的数据集,下面将介绍特征提取的细节。
[0081]
(2)特征提取:
[0082]
提取对数梅尔声谱图作为声学特征,对数梅尔声谱图提取的主要流程为:首先对音频数据进行预处理操作(预加重、分帧、加窗);接着对每一帧信号进行傅里叶变换;然后将此时的频域特征通过一组梅尔频率滤波器频段的能量值进行叠加,得到数值表示该频带的特征值;最后进行取对数操作,将梅尔频谱能量进行对数处理后,有利分离频谱包络和频谱细节。在本实施例中,利用python编程语言,调用librosa工具包,通过调用内置mel spectrogram函数实现对数据集train seta/bc/abc的对数梅尔频谱图的提取和保存。在实验过程中,先对音频进行降采样操作,采样率为22.05khz,分别设置帧长为2048个采样点、帧移为512个采样点、三角滤波器的个数设置为256个和使用汉明窗进行加窗,所以提取的对数梅尔频谱图的大小为431帧、256维。
[0083]
(3)声学场景分类模型构建:
[0084]
利用参考设备所录制的的声学场景数据train set a的对数梅尔频谱图训练基本场景分类模型a
‑
asc。将提取的声学特征输入通用场景分类模型,该模型可以根据声学特征输出待识别音频数据属于声学场景类别的概率值。
[0085]
第一步,选择cnn9网络模型作为基本场景分类模型a
‑
asc,在训练集 train set a上学习获得最佳的声学模型。cnn9模型是由多层卷积层堆叠的网络,由4个卷积块(conv block)的堆叠,每个卷积块实际包括两次卷积(conv layer) 和一次平均池化(avgpooling)。卷积核的大小为3
×
3,设置步长为1,个数分别设置为64、128、256、512,池化核分别为2
×
2、1
×
1。
[0086]
本实例利用pytorch对网络进行训练,在模型的训练中,加入bn机制、比例为0.3的dropout机制。优化算法为adam,batch的大小为10,初始学习率为 0.0001,每50个epoch后,学习率以0.1倍呈线性衰减。
[0087]
第二步,使用由移动设备b、c所录制的场景数据组成的训练集train set bc的声学特征在预训练的模型a
‑
asc上进行微调,cnn9的网络参数会进一步更新,获得对不同设备录制的音频数据有较高鲁棒性的设备独立分类模型bc
‑
asc;
[0088]
第三步,分别提取数据集train set a的网络表征向量,并计算场景类别均值表征e
k
,根据要求筛选不同设备录制的相同信号,提取该数据集train set abc相应的网络表征信息,并计算每一段音频记录存在的设备特性。定义train set abc的片段表征向量与类均值向量e
k
的差值为当前片段的设备特性作为设备分类模型的输入,设备特性的计算如公式(2)、(3)所示。
[0089]
最后搭建设备分类模型,设备分类模型由2层一维卷积层和一层全连接组成,线性修正单元(relu)激活函数构成,softmax输出为设备的类别,损失函数是交叉熵损失函数,在训练集train set abc上进行学习,并获得最佳的设备分类模型 device
‑
c。
[0090]
本发明中设置模型device
‑
c的卷积核的个数为256、128,全连接层神经元的个数
为10。
[0091]
第四步,选择自编码器作为设备识别模型device
‑
r,模型device
‑
r由encoder、 decoder组成。encoder使用设备分类模型,由2层卷积层和1层全连接层,线性修正单元(relu)激活函数组成,并固定该部分的网络参数,decoder使用和encoder 对称的结构,损失函数为最小误差函数,从而完成对设备特性进行重构。模型 device
‑
r的输入是设备特性,在训练数据集train set abc上进行学习,利用自编码器对设备特性进行重构,完成对已知设备的分类和未知设备的识别。
[0092]
图5为本发明所提出的设备识别模型device
‑
r结构示意图,conv1d表示一维卷积,卷积核的大小为2
×
1,设置步长为1,其中卷积层的个数分别设置为相对称的个数256、128、128、256个,激活函数为线性修正单元(relu),引入bn机制。
[0093]
第五步,对测试集音频数据进行预处理、特征提取,将待测数据的声学特征分别输入到模型bc
‑
asc、模型device
‑
r,即可预测待测数据的场景类别和设备类别。预测的场景类别为模型bc
‑
asc的输出得分中选择概率最大值对应的场景类别,根据测试数据的输出结果计算总体准确率,具体计算方式如公式(3)所示:
[0094][0095]
式中n
all
表示测试样本的总数,n
true
表示测试时,样本被正确分类的个数。
[0096]
当模型device
‑
r的得分大于阈值θ时,则将录制设备判断为已知设备,并给出设备标签,若得分小于阈值,则直接将其判断为未知设备。具体公式如下所示:
[0097][0098]
式中,d表示设备类别的个数,d表示第d个设备类别,y
d
表示预测的概率值。
[0099]
(4)初次实验结果:
[0100]
本部分实验使用多设备录制的音频数据集,研究多设备条件下的asc系统性能。为保证提取的声学特征损失较少,选择尺寸大的对数梅尔频谱图作为网络的输入。首先对音频文件进行降采样,使其采样率为22.05khz,然后用窗长为2048、窗移512点的汉明窗进行分帧加窗,进行2048点的fft操作,提取256维的对数梅尔频谱图。因此,输入神经网络的特征图大小为256*431。
[0101]
相关实验结果如表1所示:
[0102]
表1 bc
‑
asc模型性能(分类准确率)
[0103][0104]
从表1中可以得知,使用移动设备b所录制的测试数据集(testb),与参考设备a所录制的测试数据集(testa)准确度相比,地铁和街道步行街的场景分类准确度下降较多,下降的程度侧面反映了模型不能有效学习到移动设备b录制的地铁、地铁站场景类别的特性,我们认为是设备b录制的该两类的场景数据相对其它类别较少,数据失衡导致模型不能学习到上述两类场景的特性。
[0105]
另外,从表1中也可以发现,使用移动设备c所录制的测试数据集(testc),与参考设备a、移动设备b所录制的测试数据集(testa、testb)准确度相比,公交车、地铁、地铁站、公共广场和街道步行街的场景分类准确度下降较多。结合testb的分类结果,也充分证明了声学场景分类模型未能有效学习到移动设备c的特性,导致分类性能的下降,也反映出不同移动设备b、c间仍存在一定的设备差异性。
[0106]
(5)声学场景分类模型的更新:
[0107]
根据表1展示了设备独立的声学场景分类模型的分类结果,我们尝试收集了5小时的设备b(iphone、trainsetb
‑
update)、5小时的设备c(三星、trainsetc
‑
update)录制的声学场景的数据,以用来更新模型bc
‑
asc,获得个性化定制的声学场景分类模型user
‑
asc。利用数据集trainsetb
‑
update再次微调声学场景分类模型,该模型会学习到用户使用的iphone设备特性,提高对该设备所录制的音频数据的分类性能。
[0108]
(6)模型更新后的实验结果:
[0109]
使用更新后的声学场景分类模型对测试数据进行测试,由于分别使用trainsetb
‑
update、trainsetc
‑
update,因此我们仅关注在b、c设备条件下的场景分类性能。具体实验结果如表2所示:
[0110]
表2user
‑
asc与bc
‑
asc的分类性能比较
[0111][0112]
从表2的结果可知,特定设备的用户数据的增加,带来了分类模型性能的提升。将bc
‑
user
‑
asc和b
‑
asc的分类性能进行比较,准确度分别从71.52%提升到75.86%、从59.70提升到63.32%。表中的结果也表明,用户声学场景分类模型 user
‑
asc有效的改善了部分场景类别识别率低的问题,如地铁站、街道步行街声学环境。
[0113]
以上结果为我们直观的显示了准确度相差较大的声学场景的类别,也给予我们一定的启发。因此在数据收集和整理中,我们需要着重关注不同设备所录制的地铁、地铁站、公共广场和街道步行街的场景数据的收集,更大程度的利用用户数据,避免数据不平衡带来的分类模型性能下降。这也充分证明了本发明的提出是有意义的,本实验对用户端的数据自动收集存储模块有指导作用,从而进一步加大对用户数据的利用程度,可以进一步提升声学场景分类模型性能,提升用户的使用感。
[0114]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。