1.本发明属于计算机视觉领域,主要涉及真实世界中的人脸属性编辑的问题;主要应用于影视娱乐产业,人机交互以及机器视觉理解等方面。
背景技术:
2.目前,影视娱乐,人机交互,计算机视觉等领域,对图像的生成与属性编辑的需求越来越大。例如:在角色扮演游戏中,玩家可以根据喜好控制参数生成人物头像;在早期教育中,可以根据文本生成匹配的图像,利用图像引导幼儿认识世界的多彩多样;在目前流行的短视频平台中,用户可以使用平台提供的图像编辑技术来修改视频中人脸的头发颜色,眼睛大小等属性,获得更有趣味性的使用体验。其中,人脸属性编辑的目的是操作给定人脸上的单个或多个属性,在保留其他细节的同时生成具有所需属性的新人脸图像。生成对抗网络(gan,generative adversarial networks)由于具有计算量小,生成图像质量高,模型构造简单等优点,通常被引用到人脸属性编辑任务当中。
3.近年来,许多基于gan的人脸属性编辑模型被提出。attgan在gan的基础上引入了编码器-解码器结构,以原始图像以及目标属性向量作为输入来控制gan的生成器编辑图像,在人脸属性编辑任务上取得了良好的效果。参考文献:he,z.,zuo,w.,kan,m.,shan,s.,&chen,x.(2019).attgan:facial attribute editing by only changing what you want.ieee transactions on image processing,28(11),5464-5478.但由于编码器-解码器结构存在下采样操作,会不可避免地损失一些图片信息,造成编辑后的图像模糊和丢失细节。在attgan的基础上,stgan将选择性转移单元融入编码器-解码器结构中,以同时提高属性操作能力和编辑后的图像质量。参考文献:liu,m.,ding,y.,xia,m.,liu,x.,ding,e.,zuo,w.,&wen,s.(2019).stgan:a unified selective transfer network for arbitrary image attribute editing.in proceedings of the ieee/cvf conference on computer vision and pattern recognition(pp.3673-3682).
4.现存的人脸属性编辑方法主要通过改进模型结构以及损失函数来提升属性编辑的准确率和编辑图像的质量。但由于训练数据集的人脸属性分布不均匀,导致属性编辑的效果容易受到影响,例如celeba数据集中的人脸具有秃头属性的情况十分少见,attgan、stgan等经过该数据集训练的模型在修改人脸的秃头属性时都出现了编辑后人脸的秃头属性没有改动或编辑质量不佳的现象。
5.目前的深度学习模型大都是由数据驱动,所以数据的好坏直接影响了深度学习模型的性能。由于分布不平衡的数据集,例如数据集中的样本的类别,属性分布不均衡,造成的深度模型公平性问题,如对人的种族、性别、年龄等的歧视引起了广泛的社会争议。均衡数据集的不平衡,消除模型潜在的属性歧视,构建公平的深度模型是推动人工智能进一步得到广泛应用的关键环节。参考文献:tan,s.,shen,y.,&zhou,b.(2020).improving the fairness of deep generative models without retraining.arxiv preprint arxiv:2012.04842.
6.代价敏感学习是指为不同类别的样本提供不同的权重,从而让深度学习模型进行学习的一种方法,可以很好的用来解决数据集的样本类别分布不均衡对模型性能的影响。本发明为了消除类别分布不平衡的数据集对人脸属性编辑模型的编辑效果的影响,基于代价敏感学习提出了一种可以公平训练人脸属性编辑模型的方法,取得了出色的效果。
技术实现要素:
7.本发明是一种基于代价敏感学习的人脸属性编辑方法,以生成对抗网络为基础模型,结合代价敏感学习,解决现有技术中由于数据集的样本分布不平衡而造成属性编辑效果受影响的问题。
8.该方法首先选择使用生成对抗网络作为人脸编辑模型,并对训练图片进行归一化和缩放裁剪至128*128*3的大小,以原始人脸图像和属性标签作为输入,生成128*128*3的大小的编辑人脸图像。该方法借鉴了代价敏感学习的思想,在训练生成对抗网络的时候,为不同的输入样本设置不同的损失函数的权重,从而让人脸编辑模型公平的学习对各个人脸属性的编辑操作。本发明从公平性训练的角度出发,提出了两个改进措施来均衡数据集的不平衡对属性编辑模型的影响:1)在训练生成对抗网络的判别器时,为数据集中分布概率低的人脸属性赋予更高的损失权重,以保证判别器能够公平的学习区分出每个人脸属性;2)在训练生成对抗网络的生成器时,为发生概率低的属性编辑操作赋予更高的损失权重,以保证生成器能够公平的去编辑每个人脸属性。通过上述方法,本发明充分利用了代价敏感学习和生成对抗网络的优势,提高了现有人脸属性编辑方法的属性编辑准确性和编辑人脸图像质量。
9.为了方便地描述本发明内容,首先对一些术语进行定义。
10.定义1:生成对抗网络。生成对抗网络包含两个不相同的神经网络,一个称为生成器g,另一个称为判别器d,这两个神经网络在训练过程中相互对抗,判别器的目的是区分真实数据分布pr和生成数据分布pg,而生成器的目的则是不让判别器将这两个分布区分开来,最终使得生成数据分布和真实数据分布一致:pr=pg。
11.定义2:代价敏感学习。在代价敏感学习中,代价的定义问题是首要解决的问题之一,本发明主要关注的是错分代价和错误编辑代价m为人脸属性个数,且每个人脸属性只有两种状态:0代表不存在,1代表存在。其中错分代价c
i1
是指将第i个人脸属性由0错误分类为1的代价,c
i2
是指将第i个人脸属性由1错误分类为0的代价;错误编辑代价a
i1
是对第i个人脸属性发生错误编辑的代价,错误编辑代价a
i2
是未对人脸的第i个属性发生编辑的代价。
12.定义3:批归一化层。这是一个深度神经网络训练的技巧,就是对每一批数据进行归一化,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。
13.定义4:实例归一化层。这是一个经常被用在风格迁移任务中的深度神经网络训练的技巧,就是对每一个图像样本的每一个通道单独进行归一化。可以加速模型收敛,并且保持每个图像样本之间的独立。
14.定义5:relu激活层。又称修正线性单元,是一种人工神经网络中常用的激活函数,通常指代以斜坡函数及其变种为代表的非线性函数,表达式为f(x)=max(0,x)
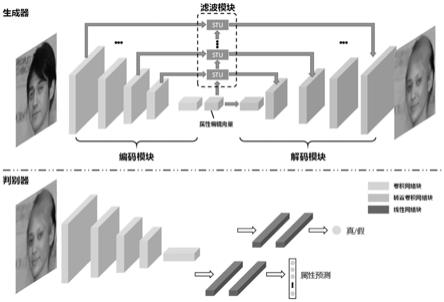
15.定义6:tanh激活层。可以用表达式tanh(x)=(e
x-e-x
)/(e
x
e-x
)定义。
16.定义7:u-net网络。unet是著名的图像分割网络,包括三部分:编码器和解码器以及对称跳跃连接。其中编码器通过卷积和下采样来降低图像的尺寸,逐级提取浅层的图像特征;编码器则通过卷积和上采样来恢复图像的尺寸,并逐级提取深层的图像特征;跳跃连接则是把编码器提取的浅层图像特征与解码器中对称的深层图像特征进行连接。
17.定义8:选择性转移单元(selective transferunits,stu)。stu是一种门控循环单元(gate recurrent unit,gru)的变体,由stgan提出。门控循环单元是循环神经网络的一种,和lstm(long-short term memory)一样,是为了解决长期记忆和反向传播中的梯度等问题而提出来的,但它较lstm网络的结构更加简单,而且效果也很好。
18.定义9:属性编辑成功率。属性编辑成功率是用来衡量人脸属性编辑模型的属性修改能力。这里我们在celeba数据集上训练了一个人脸属性分类器来判断生成的人脸的属性。该属性分类器在celeba数据集上进行训练,在celeba测试集上,每个属性的准确率达到了94.5%。
19.因而本发明技术方案为一种基于训练公平性的人脸属性编辑模型,该方法包括:
20.步骤1:对数据集进行预处理;
21.获取真实人脸图像,并将这些真实图像按照其中人脸显示的属性进行标注,对所有图片像素值进行归一化;
22.步骤2:构建生成对抗网络的判别器网络和生成器网络;
23.1)判别器网络构建
24.判别器网络输入为图片,输出为一个标量和一个向量;判别器网络d分为三个模块:特征提取模块de、对抗损失模块d
adv
和属性分类模块d
cls
;特征提取模块de的输入为图片,输出为图片的特征向量,特征提取模块de由5层卷积网络块依次连接而成;对抗损失模块d
adv
的输入为特征提取模块de提取的特征,输出为标量,值越大表示图像越真实,对抗损失模块d2采用两层线性网络块构成;属性分类模块d
cls
的输入为特征提取模块de的提取的特征,输出为属性分类向量,属性分类模块d
cls
由两层线性网络块构成。网络总结结构参见图1,卷积网络块参见图2,转置卷积网络块结构参见图3,线性网络块参见图4;
25.2)生成器网络构建
26.生成器网络输入为原始图像和图像的属性编辑向量,输出为属性编辑后图像;生成器网络g主要由三个部分构成:编码器模块g
enc
、解码器模块g
dec
、滤波模块gf。其中编码器模块g
enc
的输入原始图像,输出为图像特征,由5层卷积网络块依次连接而成;解码器模块g
dec
的输入为图像特征和图像的过滤特征,输出为编辑后人脸图像,由5层转置卷积网络块依次连接而成,并且编码器和解码器之间采用了unet网络中的对称跳跃连接;滤波模块gf的输入为图像特征,输出为图像的过滤特征,采用stu结构构成,主要用于选择性过滤编码器和解码器之间的对称跳跃连接中传递的图像特征。
27.步骤3:设计人脸属性编辑模型训练过程中的属性编辑操作;
28.本发明采取小批量梯度下降算法对模型进行优化,分批次向模型输入数据集中的n个图像样本一属性标签对:(x,l),属性标签l是一个长度为m二进制向量,每一位的0或1分别表示对应属性的无或有。属性编辑向量构造方式如下:以图像样本x本身的属性标签作为它的原始标签ls,并为每个图像样本x随机挑取其他图像样本的属性标签作为目标属性标
签l
t
,以保证属性编辑操作不会存在冲突,以δl=l
t-ls作为图像x的属性编辑向量。当δli=1时,表示为图像x增加第i个属性;当δli=0时,表示不改变图像x的第i个属性;当δli=-1时,表示为图像x去掉第i个属性。属性编辑向量构造方式参见图5。
29.步骤4:设计错分代价和错误编辑代价
30.1)统计数据集中的人脸属性分布概率p=[p1p2…
pm]:其中m为人脸属性个数,第i个属性在数据集中的分布概率为其中i=1,2,...,m表示第i个属性在数据集中出现的次数,n
data
为数据集的样本数量。然后根据人脸属性的分布概率p可以计算得到训练过程中第i个属性发生编辑的概率为2pi(1-pi)。
[0031]
2)计算错分代价其中将第i个属性由1分类为0的代价为c
i1
=1/pi;将第i个属性由0分类为1的代价为c
i2
=1/(1-pi)。即可得
[0032]
3)计算错误编辑代价当未对图像的第i个属性进行编辑时,而发生了错误编辑的代价为a
i1
=1/(1-2pi(1-pi));当对图像的第i个属性进行编辑时,而未发生编辑的代价为a
i2
=1/(2pi(1-pi))。即可得到
[0033]
步骤5:设计损失函数;
[0034]
1)从训练公平性角度出发,针对判别器网络设计损失函数,以均衡不平衡数据集的影响:设由生成器编辑后的图像xg~pg,pg为生成器拟合的图像分布。设真实图像——属性标签对(xr,lr)~p
data
,p
data
为真实图像数据集的分布。利用判别器的特征提取模块de来提取查询图像xr的图像特征:fr=de(xr),将真实图像的特征fr送到判别器的对抗损失模块d
adv
中计算图像的真实度估计:d
adv
(xr)。按照上述过程,可以得到生成图像xg的真实度估计d
adv
。这样可以构造生成对抗网络的判别器的对抗损失:
[0035][0036]
其中,d
adv
(xg)表示判别器的对抗损失模块对编辑图像的输出值,输出值越大表明编辑图像越真实,表示对该输出值的期望,d
adv
(xr)表示判别器的对抗损失模块对编辑图像的输出值,表示对该输出值的期望。即分布为数据集分布pr和生成图像分布pg的线性混合,∈
*
表示线性混合系数,表示判别函数关于混合图像求梯度,为梯度惩罚项,用来约束判别器模型的参数符合lipschitz连续条件,λ
gp
为梯度惩罚系数。
[0037]
将真实图像的特征fr送到判别器的属性分类模块d
cls
中预测图像的属性分类,输出表示为d
cls
(xr)。结合步骤4的2)中计算得到的错分代价c,可以为判别器构造具有代价敏感的分类损失函数:
[0038][0039]
其中,d
cls
(xr)表示判别器的属性分类模块对原始图像x
r*
的属性预测向量,表示对图像xr的第i个属性的预测值,要求与原始属性标签的第i个分量越一致越好。所以,判别器的总损失函数为:
[0040][0041]
其中,为判别器的对抗损失,为判别器的分类损失,λ
cls
为属性分类
损失函数的权重。
[0042]
2)从训练公平性角度出发,针对生成器网络设计损失函数,以均衡不平衡数据集的影响:设从数据集中抽取的原始图像——属性标签对为(xs,ls)~p
data
,同时按照步骤3的方法为每一张图片抽取目标属性标签l
t
,构造属性编辑向量δl。首先利用生成器的编码器提取原始图像的特征fs=d
enc
(xs),将原始图像特征fs和属性编辑向量δl进行拼接得到带有条件的图像特征f
t
,将原始图像特征fs和0向量(长度为m)进行拼接得到不带条件的图像特征fr以用于图像重建。然后分别将f
t
,fr送入滤波模块df中得到过滤特征f
′
t
,f
′r,然后将图像特征和过滤特征送入解码器d
dec
中,分别得到编辑人脸图像x
t
=d
dec
(f
t
,f
′
t
)和重建人脸图像xr=d
dec
(fr,f
′r),为了方便表示,这里简记为x
t
=g(xs,δl),xr=g(xs,0)。然后按照步骤5的1)中的过程得到编辑人脸x
t
的真实度d
adv
(x
t
),然后构造生成器的对抗损失函数:
[0043][0044]
其中,g(xs,δl)为生成器关于属性编辑向量δl对原始图像xs进行编辑后的图像,d(g(xs,δl))为判别器关于编辑图像x
t
=g(xs,δl)的真实度预测值,该值越高,表明编辑后图像越真实;表示对编辑后图像x
t
的真实度的数学期望。
[0045]
按照步骤5的1)中的过程得到编辑人脸x
t
的属性预测向量d
cls
(x
t
),结合步骤4的3)中计算的错误编辑代价a,构造生成器的属性编辑损失函数:
[0046][0047]
其中,1
[
·
]
为指示函数,当δl=0时,1
[δl]
=1,即a
il[δl]
=a
i1
;当δl≠0时,1
[δl]
=2,即a
i[δl]
=a
i2
。d
cls
(x
t
)表示判别器的属性分类模块对编辑人脸x
t
的属性预测向量,表示对图像x
t
的第i个属性的预测值,要求与目标属性标签的第i个分量越一致越好。
[0048]
同时,为了保证生成器g能够保留人脸的基本信息,要求重建人脸图像xr=g(xs,0)和原始人脸图像xs越一致越好,构造生成器的图像重建损失函数:
[0049][0050]
其中,||
·
||1为矩阵1范数,当重建图像xr=g(xs,0)与原始图像xs的每个像素点的取值越一致的时候,||x
s-g(xs,0)||1越小。所以,生成器的总损失函数为:
[0051][0052]
其中,λ
op
为属性编辑损失的权重,λ
rec
为图像重建损失的权重。
[0053]
步骤6:训练步骤2中构建的生成对抗神经网络,利用步骤5构建的损失函数进行网络训练,在更新生成器网络g时固定判别器网络d的参数,而更新判别器网络d时则固定生成器网络g的参数,每次迭代更新判别器5次然后更新生成器一次;
[0054]
步骤7:采用训练完成的生成器网络g来对测试集中的人脸图像进行属性编辑,并用属性编辑成功率来衡量本发明提出的模型的属性编辑效果。测试结果参见图6。
[0055]
本文的创新之处在于:
[0056]
1)首次在人脸属性编辑任务中引入了训练公平性的概念,根据数据集中样本属性的统计特性对模型训练过程的损失进行均衡,以消除样本分布不平衡的数据集对模型的影响。
[0057]
2)本发明结合代价敏感学习的思想,为生成对抗网络的判别器构造了带有代价敏
感的属性分类损失函数,以约束判别器能够公平的区分每个人脸属性的状态。
[0058]
3)本发明结合代价敏感学习的思想,为生成对抗网络的生成器构造了带有代价敏感的属性编辑损失函数,以约束生成器能够公平的去编辑每个人脸属性,同时尽可能的保留未要求编辑的人脸属性。最后在celeba数据集上验证本发明提出的方法,结果显示本发明提出的方法的人脸属性编辑成功率相较于之前的工作有了显著提高。
附图说明
[0059]
图1为本发明方法主要流程图。
[0060]
图2为本发明方法的卷积网络块结构图。(a)为生成器中的卷积网络块,(b)为判别器中的卷积网络块。
[0061]
图3为本发明方法的转置卷积网络结构图。
[0062]
图4为本发明方法的线性网络结构图
[0063]
图5为本发明方法构造属性编辑向量的示意图。
[0064]
图6为本发明方法的实验结果图。
具体实施方式
[0065]
步骤1:对数据集进行预处理;
[0066]
获取celeba数据集(http://mmlab.ie.cuhk.edu.hk/projects/celeba.html),celeba数据集[34]包含10177个名人身份的202599张人脸图片,每张图片都做好了40个二元属性标记,例如是否有眼镜、刘海、胡须等。本文将图像缩放并裁剪为128*128*3的像素尺寸,选择其中的182000张人脸图像和属性标签作为训练数据集,将另外20000张人脸图像和属性标签作为测试数据集,随机打乱训练顺序,最后对图片像素值进行归一化至范围[-1,1]。
[0067]
步骤2:构建生成对抗网络的生成器网络和判别器网络;
[0068]
1)判别器网络构建
[0069]
判别器网络输入为图片,输出为一个标量和一个向量;判别器网络d分为三个模块:特征提取模块de、对抗损失模块d
adv
和属性分类模块d
cls
;特征提取模块de的输入为图片,输出为图片的特征向量,特征提取模块de由5层卷积网络块依次连接而成;对抗损失模块d
adv
的输入为特征提取模块de提取的特征,输出为标量,值越大表示图像越真实,对抗损失模块d2采用两层线性网络块构成;属性分类模块d
cls
的输入为特征提取模块de的提取的特征,输出为属性分类向量,属性分类模块d
cls
由两层线性网络块构成。网络总结结构参见图1,卷积网络块参见图2,转置卷积网络块结构参见图3,线性网络块参见图4;
[0070]
2)生成器网络构建
[0071]
生成器网络输入为原始图像和图像的属性编辑向量,输出为属性编辑后图像;生成器网络g主要由三个部分构成:编码器模块g
enc
、解码器模块g
dec
、滤波模块gf。其中编码器模块g
enc
的输入原始图像,输出为图像特征,由5层卷积网络块依次连接而成;解码器模块g
dec
的输入为图像特征和图像的过滤特征,输出为编辑后人脸图像,由5层转置卷积网络块依次连接而成,并且编码器和解码器之间采用了unet网络中的对称跳跃连接;滤波模块gf的输入为图像特征,输出为图像的过滤特征,采用stu结构构成,主要用于选择性过滤编码
器和解码器之间的对称跳跃连接中传递的图像特征。
[0072]
步骤3:设计人脸属性编辑模型训练过程中的属性编辑操作;
[0073]
本发明采取小批量梯度下降算法对模型进行优化,分批次向模型输入数据集中的n个图像样本-属性标签对:(x,l),属性标签l是一个长度为m二进制向量,每一位的0或1分别表示对应属性的无或有。属性编辑向量构造方式如下:以图像样本x本身的属性标签作为它的原始标签ls,并为每个图像样本x随机挑取其他图像样本的属性标签作为目标属性标签l
t
,以保证属性编辑操作不会存在冲突,以δl=l
t-ls作为图像x的属性编辑向量。当δli=1时,表示为图像x增加第i个属性;当δli=0时,表示不改变图像x的第i个属性;当δli=-1时,表示为图像x去掉第i个属性。属性编辑向量构造方式参见图5。
[0074]
步骤4:设计错分代价和错误编辑代价
[0075]
1)首先统计数据集中的人脸属性分布概率p=[p1,p2,...,pm],其中m为人脸属性个数,第i个属性在数据集中的分布概率为其中i=1,2,...,m表示第i个属性在数据集中出现的次数,n
data
为数据集的样本数量。然后根据人脸属性的分布概率p可以计算得到训练过程中第i个属性发生编辑的概率为2pi(1-pi)。
[0076]
2)计算错分代价其中将第i个属性由1分类为0的代价为c
i1
=1/pi;将第i个属性由0分类为1的代价为c
i2
=1/(1-pi)。即可得
[0077]
3)计算错误编辑代价当未对图像的第i个属性进行编辑时,而发生了错误编辑的代价为a
i1
=1/(1-2pi(1-pi));当对图像的第i个属性进行编辑时,而未发生编辑的代价为a
i2
=1/(2pi(1-pi))。即可得到
[0078]
步骤5:设计损失函数;
[0079]
1)从训练公平性角度出发,针对判别器网络设计损失函数,以均衡不平衡数据集的影响:设由生成器编辑后的图像xg~pg,pg为生成器拟合的图像分布。设真实图像——属性标签对(xr,lr)~p
data
,p
data
为真实图像数据集的分布。利用判别器的特征提取模块de来提取查询图像xr的图像特征:fr=de(xr),将真实图像的特征fr送到判别器的对抗损失模块d
adv
中计算图像的真实度估计:d
adv
(xr)。按照上述过程,可以得到生成图像xg的真实度估计d
adv
(xg)。这样可以构造生成对抗网络的判别器的对抗损失:
[0080][0081]
其中,d
adv
(xg)表示判别器的对抗损失模块对编辑图像的输出值,输出值越大表明编辑图像越真实,表示对该输出值的期望,d
adv
(xr)表示判别器的对抗损失模块对编辑图像的输出值,表示对该输出值的期望。即分布为数据集分布pr和生成图像分布pg的线性混合,∈表示线性混合系数,表示判别函数关于混合图像求梯度,为梯度惩罚项,用来约束判别器模型的参数符合lipschitz连续条件,λ
gp
为梯度惩罚系数。
[0082]
将真实图像的特征fr送到判别器的属性分类模块d
cls
中预测图像的属性分类,输出表示为d
cls
(xr)。结合步骤4的2)中计算得到的错分代价c,可以为判别器构造具有代价敏感的分类损失函数:
[0083]
[0084]
其中,d
cls
(xr)表示判别器的属性分类模块对原始图像xr的属性预测向量,表示对图像xr的第i个属性的预测值,要求与原始属性标签的第i个分量越一致越好。所以,判别器的总损失函数为:
[0085][0086]
其中,为判别器的对抗损失,为判别器的分类损失,λ
cls
为属性分类损失函数的权重。
[0087]
2)从训练公平性角度出发,针对生成器网络设计损失函数,以均衡不平衡数据集的影响:设从数据集中抽取的原始图像——属性标签对为(xs,ls)~p
data
,同时按照步骤3的方法为每一张图片抽取目标属性标签l
t
,构造属性编辑向量δl。首先利用生成器的编码器提取原始图像的特征fs=d
enc
(xs),将原始图像特征fs和属性编辑向量δl进行拼接得到带有条件的图像特征f
t
,将原始图像特征fs和0向量(长度为m)进行拼接得到不带条件的图像特征fr以用于图像重建。然后分别将f
t
,fr送入滤波模块df中得到过滤特征f
′
t
,f
′r,然后将图像特征和过滤特征送入解码器d
dec
中,分别得到编辑人脸图像x
t
=d
dec
(f
t
,f
′
t
)和重建人脸图像xr=d
dec
(fr,f
′r),为了方便表示,这里简记为x
t
=g(xs,δl),xr=g(xs,0)。然后按照步骤5的1)中的过程得到编辑人脸x
t
的真实度d
adv
(x
t
),然后构造生成器的对抗损失函数:
[0088][0089]
其中,g(xs,δl)为生成器关于属性编辑向量δl对原始图像xs进行编辑后的图像,d(g(xs,δl))为判别器关于编辑图像x
t
=g(xs,δl)的真实度预测值,该值越高,表明编辑后图像越真实;表示对编辑后图像x
t
的真实度的数学期望。
[0090]
按照步骤5的1)中的过程得到编辑人脸x
t
的属性预测向量d
cls
(x
t
),结合步骤4的3)中计算的错误编辑代价a,构造生成器的属性编辑损失函数:
[0091][0092]
其中,1
[
·
]
为指示函数,当δl=0时,1
[δl]
=1,即a
i1[δl]
=a
i1
;当δl≠0时,1
[δl]
=2,即a
i[δl]
=ai2。d
cls
(x
t
)表示判别器的属性分类模块对编辑人脸x
t
的属性预测向量,表示对图像x
t
的第i个属性的预测值,要求与目标属性标签的第i个分量越一致越好。
[0093]
同时,为了保证生成器g能够保留人脸的基本信息,要求重建人脸图像xr=g(xs,0)和原始人脸图像xs越一致越好,构造生成器的图像重建损失函数:
[0094][0095]
其中,||
·
||1为矩阵1范数,当重建图像xr=g(xs,0)与原始图像xs的每个像素点的取值越一致的时候,||x
s-g(xs,0)||1越小。所以,生成器的总损失函数为:
[0096][0097]
其中,λ
op
为属性编辑损失的权重,λ
rec
为图像重建损失的权重。
[0098]
步骤6:训练步骤2中构建的生成对抗神经网络,利用步骤5构建的损失函数进行网络训练,在更新生成器网络g时固定判别器网络d的参数,而更新判别器网络d时则固定生成器网络g的参数,每次迭代更新判别器5次然后更新生成器一次;
[0099]
步骤7:采用训练完成的生成器网络g来对测试集中的人脸图像进行属性编辑,并
用属性编辑成功率来衡量本发明提出的模型的属性编辑效果,测试结果参见图6。本发明以attgan和stgan为基本模型,分别将本发明提出的公平性训练方法(fairness)对它们进行改进,从图6可见,通过施加本发明的公平性训练方法,attgan的属性编辑准确率提升了4.7%,stgan的属性编辑准确率提升了5.5%,可见本文的方法能够显著提升人脸属性编辑模型的编辑效果。
[0100]
图片大小:128*128*3
[0101]
编辑的人脸属性有:bald、bangs、black_hair、blond_hair、brown_hair、bushy_eyebrows、eyeglasses、male、mouth_slightly_open、mustache、no_beard、pale_skin、young,人脸属性数量m:13
[0102]
学习率:0.0002,在第100代后降为0.0001
[0103]
训练批次大小n:32
[0104]
迭代次数:200
[0105]
判别器的属性分类损失函数权重λ
cls
:1
[0106]
判别器的梯度惩罚系数λ
gp
:10
[0107]
生成器的属性操作损失函数权重λ
op
:10
[0108]
生成器的图像重建损失权重λ
rec
:100。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。