1.本发明属于生物技术领域,具体涉及一种代谢标志物及在制备慢性肾病的风险预测试剂盒中的应用和试剂盒。
背景技术:
2.通过提高生物标志物的识别技术,能够推进个体化医疗的发展并提高生存率。慢性肾病(chronic kidney disease, ckd),也被称为慢性肾衰竭,是指出现 ≥3 个月的肾脏结构或功能异常、且对健康有影响的状况。这意味着肾小球滤过率低于 60 ml/(min
·
1.73m
²
),或出现以下一种或多种肾损伤标志:白蛋白尿/蛋白尿、尿沉渣异常(例如血尿)、肾小管疾病引发的电解质紊乱、组织学检查发现异常、影像学检查发现结构异常或存在肾移植史。根据gfr可以将慢性肾脏病分为5期,早期发现和早期干预可以显著的降低ckd患者的并发症,明显的提高生存率。因此,需要一种更准确、无创、以体液(例如血液)为基础以及广泛接受的工具来提高检测的有效性和获取途径。
3.通过检索,尚未发现与本发明专利申请相关的专利公开文献。
技术实现要素:
4.本发明目的在于弥补现有技术的不足之处,提供一种代谢标志物及在制备慢性肾病的风险预测试剂盒中的应用和试剂盒。
5.本发明解决技术问题所采用的技术方案是:代谢标志物在制备慢性肾病的风险预测试剂盒中的应用,所述代谢标志物使用代谢组学特征表示,所述代谢组学特征为如下的至少一种的两种质荷比的比值水平:m/z 114.066 / m/z 249.061,m/z 205.068/ m/z 249.061,m/z 114.066 / m/z 307.018,m/z 114.066 / m/z 364.951,m/z 189.123/ m/z 364.951,m/z 205.068/ m/z 307.018,m/z 205.068/ m/z 364.951,m/z 189.123/ m/z 249.061,m/z 189.123/ m/z 307.018。
6.一种慢性肾病的风险预测标志物,为如下至少一种的两种代谢组学特征质荷比的比值水平:m/z 114.066 / m/z 249.061,m/z 205.068/ m/z 249.061,m/z 114.066 / m/z 307.018,m/z 114.066 / m/z 364.951,m/z 189.123/ m/z 364.951,m/z 205.068/ m/z 307.018,m/z 205.068/ m/z 364.951,m/z 189.123/ m/z 249.061,m/z 189.123/ m/z 307.018。
7.一种慢性肾病的风险预测试剂盒,所述试剂盒包括:至少包括一种慢性肾病的风险预测标志物的检测试剂,所述慢性肾病的风险预测标志物即为慢性肾病代谢标志物,所述慢性肾病代谢标志物为代谢组学特征比值,所述代谢组学特征比值为如下的至少一种的两种特征质荷比的比值水平:m/z 114.066 / m/z 249.061,m/z 205.068/ m/z 249.061,m/z 114.066 / m/z 307.018,m/z 114.066 / m/z 364.951,m/z 189.123/ m/z 364.951,
m/z 205.068/ m/z 307.018,m/z 205.068/ m/z 364.951,m/z 189.123/ m/z 249.061,m/z 189.123/ m/z 307.018。
8.进一步地,所述试剂盒的检测样本为血液样本、血清样本、尿液样本的至少一种。所述试剂盒的检测样本来自健康个体、慢性肾病患者、慢性肾病病变者、慢性肾病预后者中的一种。
9.所述试剂盒还包括标准品、质控品、缓冲液中的一种或多种。
10.本发明取得的有益效果为:1、本发明通过代谢组学特征比值来表征慢性肾病的风险预测标志物,进而能够预测慢性肾病的风险,使医学工作者能够进行更及时、更个性化的对慢性肾病进行风险预测,显著提高医学工作者对慢性肾病发病机制的认知。
11.2、本发明以代谢组学特征比值表征慢性肾病的风险预测标志物,能够以体液(例如血液)为基础,准确高效地检测慢性肾病标志物,并进一步预测慢性肾病进行风险。
12.检测样本取自体液,降低了患者在检测取样时的不适感,且检测准确度较高。
附图说明
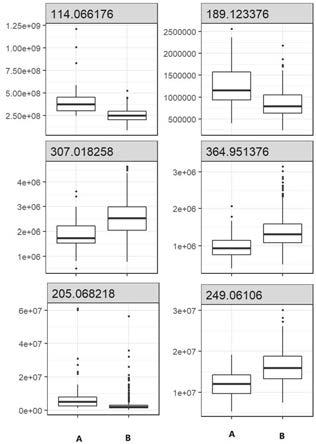
13.图1为本发明实施例中用于计算代谢组学特征比值的6个代谢组学特征在慢性肾病组和正常组的归一化信号强度值图,其中,a为慢性肾病组,b为正常对照组;图2为本发明中实施例中所有受试者的慢性肾病概率点图;图3为本发明实施例中检测模型rocauc在慢性肾病检测中的表现图。
具体实施方式
14.利于更好理解本发明,下面结合实施例对本发明做进一步地详细说明,但本发明要求保护的范围并不局限于实施例所表示的范围。
15.本发明中所使用的原料,如无特殊说明,均为常规市售产品,本发明中所使用的方法,如无特殊说明,均为本领域常规方法,本发明所使用的各物质质量均为常规使用质量。
16.本发明人在长期的研究工作中发现,人体血清中的代谢物与慢性肾病的诊断结果密切相关,因此可以将血清的代谢物作为检测慢性肾病的风险预测标志物,并通过代谢组学特征研究血清中慢性肾病的风险预测标志物,进而来预测慢性肾病进行风险。代谢标志物在制备慢性肾病的风险预测试剂盒中的应用,所述代谢标志物使用代谢组学特征表示,所述代谢组学特征为如下的至少一种的两种质荷比的比值水平:m/z 114.066 / m/z 249.061,m/z 205.068/ m/z 249.061,m/z 114.066 / m/z 307.018,m/z 114.066 / m/z 364.951,m/z 189.123/ m/z 364.951,m/z 205.068/ m/z 307.018,m/z 205.068/ m/z 364.951,m/z 189.123/ m/z 249.061,m/z 189.123/ m/z 307.018。
17.在ckd的不同阶段,其临床表现也各不相同。在ckd3期之前,病人可能无任何症状,或仅有乏力、腰酸、夜尿增多等轻度不适;小部分病人可能有食欲减退、代谢性酸中毒及轻度贫血症状。ckd3期以后,上述症状更趋明显,进入肾衰竭期以后会进一步加重,有时可出现高血压、心衰、严重高钾血症、酸碱平衡紊乱、消化道症状、贫血、矿物质骨代谢异常、甲状旁腺功能亢进和中枢神经系统障碍等,甚至存在生命危险。在某些情况下,受试者可能无慢性肾病症状,但有与慢性肾病相关的危险因素,如年龄(如老年)、ckd家族史(包括遗传性和
scientific,san jose,ca)。将10μl 血清提取物注入uplc系统,流动相为:含有0.1%甲酸的5%乙腈水溶液。
28.在一些实施例中,q exactive plus质谱仪参数设置如下:表1质谱仪条件在质谱代谢组学特征进行处理和标准化后,使用代谢的浓度/强度作为预测指标,基于所选代谢特征的权重,进行代谢组学途径富集分析,将慢性肾病受试者与正常对照区分开。
29.本发明共有674名受试者(队列),其中正常受试者(对照组)共632名,慢性肾病受试者(阳性组)共42名,所有受试者均采集血清样本。ms分析后,在546种代谢指标(代谢组学特征)中,首先对这些特征采用统计学的方法,进行单变量分析,筛选出慢性肾病受试者和正常受试者中显著差异变量。
30.具体地,按照p值《0.05,差异倍数《0.83 或 差异倍数》 1.2 以及rocauc》0.6,筛选出3个上调差异表达特征m/z 114.066,m/z 189.123,m/z 205.068和3个下调差异表达特征m/z 249.061, m/z 307.018, m/z 364.951。图1为慢性肾病患者不同发展阶段各特征归一化的信号强度值,其中图中a为慢性肾病患者组,b 为对照组。所有6种代谢组学特征在慢性肾病患者样本中均显著变化。
31.表2显示了慢性肾病受试者与正常受试者的9种特征比值的单变量分析结果。
32.表2 慢性肾病和正常受试者之间选定特征比值的单变量分析
进一步地,将3个上调特征和3个下调特征两两相除形成9个代谢组特征比值:m/z114.066 / m/z 249.061,m/z 205.068/ m/z 249.061,m/z114.066/ m/z 307.018,m/z114.066 / m/z 364.951,m/z 189.123/ m/z 364.951,m/z 205.068/ m/z 307.018,m/z 205.068/ m/z 364.951,m/z 189.123/ m/z 249.061,m/z 189.123/ m/z 307.018。
33.在质谱代谢组学特征进行处理和标准化后,使用代谢的浓度或强度作为预测指标。根据所述经过预处理的样本数据库,将结果代入xgboost算法进行监督学习,构建慢性肾病诊断模型。xgboost算法是目前最快最好的 boosted tree(提升树)算法,为基于gbdt(梯度提升树)原理进行改进的算法,可实现并行运算和增量学习,并可以处理大规模数据。
34.本发明通过充分利用代谢组特征数据,基于xgboost的机器学习模型预测样本分类,所述方法包括以下步骤:一、分别检测674名健康受试者和慢性肾病受试者的血清样本,得到如上所述的特征质荷比;二、将步骤一中所得数据代入xgboost模型,根据交叉验证进行参数优化,将rocauc得分最好的参数,以各个检测项为自变量,慢性肾病诊断结果为因变量进行计算;三、定义目标函数,目标函数包括损失与正则化两部分;其中,损失=上一棵树的误差(梯度),正则化=树的复杂度。需要优化目标函数,尽可能降低目标函数预测误差,尽可能降低数的复杂度。
35.将xgboost算法参数设置为:最大决策树数量=2000;学习率=0.01;最大规则深度=4;决策树生长所需达到最小gain值=0;决策树复杂度衡量参数=1。
36.四、利用贪心法进行切分点查找,构建决策树;可通过枚举所有不同的树结构,选取gain(增益)值最大且超过阈值的方案,若max(gain)小于阈值,则剪枝终止分裂。
37.五、决策树结构确定后,计算叶子结点的分数;六、更新决策树序列,保存构建好的所有决策树及其得分;七、计算训练集中各个样本的预测结果,即每棵树的得分之和,得到样本属于各个类别的概率;八、计算每一个变量的重要性得分,选择对模型影响显著的重要变量;可计算各个变量的gini(基尼)系数,其gini系数平均值即该变量的重要性得分。
38.九、利用重要变量构建慢性肾病诊断模型,并存储模型,用于后续测量数据的慢性
m/z 364.951,m/z 189.123的丰度值,并以此计算对应的特征比值m/z114.066 / m/z 249.061,m/z 205.068/ m/z 249.061,m/z114.066 / m/z 307.018,m/z 114.066/ m/z 364.951,m/z 189.123/ m/z 364.951,m/z 205.068/ m/z 307.018,m/z 205.068/ m/z 364.951,m/z 189.123/ m/z 249.061,m/z 189.123/ m/z 307.018,代入慢性肾病检测模型(即xgboost算法)进行打分,得出分值,小于临界值0.025,结果为阴性即慢性肾病低风险。
49.尽管为说明目的公开了本发明的实施例,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换、变化和修改都是可能的,因此,本发明的范围不局限于实施例所公开的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。