1.本发明涉及生物技术领域,具体涉及一种代谢标志物及在制备高尿酸血症的风险预测试剂盒方面中的应用和试剂盒。
背景技术:
2.通过提高生物标志物的识别技术,进一步推进个体化医疗的发展并提高生存率。
3.高尿酸血症(hua)是指在正常嘌呤饮食状态下,非同日两次空腹血尿酸水平男性高于420μmol/l,女性高于360μmol/l,即称为高尿酸血症。
4.尿酸是人类嘌呤化合物的终末代谢产物。嘌呤代谢紊乱导致高尿酸血症。本病患病率受到多种因素的影响,与遗传、性别、年龄、生活方式、饮食习惯、药物治疗和经济发展程度等有关。根据近年各地高尿酸血症患病率的报道,目前我国约有高尿酸血症者1.2亿,约占总人口的10%,高发年龄为中老年男性和绝经后女性,但近年来有年轻化趋势。尿酸与肾脏疾病关系密切。除尿酸结晶沉积导致肾小动脉和慢性间质炎症使肾损害加重以外,许多流行病学调查和动物研究显示,尿酸可直接使肾小球入球小动脉发生微血管病变,导致慢性肾脏疾病。由此可见,及早的检测和发现高尿酸血症具有重要的意义。因此,需要一种更准确、无创、以体液(例如血液)样本为基础以及广泛接受的工具来提高检测的有效性和获取途径。
5.通过检索,尚未发现与本发明专利申请相关的专利公开文献。
技术实现要素:
6.本发明的目的在于克服现有技术的不足之处,提供一种代谢标志物及在制备高尿酸血症的风险预测试剂盒方面中的应用和试剂盒。
7.本发明解决技术问题所采用的技术方案是:代谢标志物在制备高尿酸血症的风险预测试剂盒方面中的应用,所述代谢标志物使用代谢组学特征表示,所述代谢组学特征为如下的至少一种质荷比:m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269。
8.一种高尿酸血症的风险预测标志物,为如下的至少一种的代谢组学特征质荷比:m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269。
9.一种高尿酸血症的风险预测试剂盒,所述试剂盒包括:至少一种高尿酸血症的风险预测标志物的检测试剂,所述高尿酸血症的风险预测标志物为高尿酸血症代谢标志物,
所述高尿酸血症代谢标志物为代谢组学特征,所述代谢组学特征为如下的至少一种的两种特征质荷比的比值水平:m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269。
10.进一步地,所述试剂盒的检测样本为血液样本、血清样本、尿液样本的至少一种。
11.进一步地,所述试剂盒的检测样本来自健康个体、高尿酸血症患者、高尿酸血症病变者、高尿酸血症预后者的一种。
12.进一步地,所述试剂盒还包括质控品、标准品、缓冲液中的一种或多种。
13.本发明取得的有益效果是:1、本发明通过代谢组学特征来表征高尿酸血症的风险预测标志物,进而能够对高尿酸血症进行风险预测,使得医学工作者能够更及时地对高尿酸血症进行风险预测并为患者提供更个性化治疗,帮助医学工作者对高尿酸血症发病机制的认知。
14.2、本发明以代谢组学特征表征高尿酸血症的风险预测标志物,检测样本来源于体液(例如血液),能够准确、高效、无创地检测高尿酸血症标志物,并进一步地对高尿酸血症进行检测和评估,由于检测样本取自体液,可降低患者在检测取样时的不适感,且具有较高的检测准确度。
附图说明
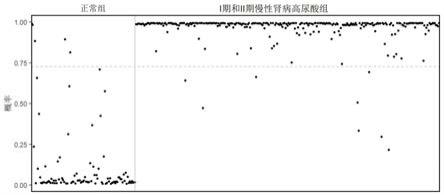
15.图1为本发明实施例中19个代谢组学特征在高尿酸血症组和正常组的归一化信号强度值图;其中,case为高尿酸血症组,control为正常对照组;图2为本发明实施例中所有受试者的高尿酸血症概率点图;图3为本发明实施例中检测模型rocauc在高尿酸血症检测中的表现。
具体实施方式
16.为更好理解本发明,下面结合实施例对本发明做进一步地详细说明,但是本发明要求保护的范围并不局限于实施例所表示的范围。
17.本发明中所使用的的原料,如无特殊说明,均为常规市售产品,本发明中所使用的方法,如无特殊说明,均为本领域常规方法,本发明所使用的各物质质量均为常规使用质量。
18.通过长期的研究工作,发明人发现,人体血清中的代谢与高尿酸血症的诊断有着密切相关性,因此可以将血清的代谢作为检测高尿酸血症的风险预测标志物,并通过代谢组学特征研究血清中高尿酸血症的风险预测标志物,进而对高尿酸血症进行风险预测。
19.代谢标志物在制备高尿酸血症的风险预测试剂盒方面中的应用,所述代谢标志物使用代谢组学特征表示,所述代谢组学特征为如下的至少一种质荷比:m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269。
20.在某些情况下,受试者可能会出现高尿酸血症的临床症状,如高血压、痛风、高甘油三酯血症,糖尿病、代谢综合征等。在其他情况下,受试者可能没有高尿酸血症的症状,也没有与高尿酸血症相关的危险因素。那么,此时就可以采用高尿酸血症代谢标志物的代谢组学特征来预测受试者是否患有高尿酸血症的风险。
21.一种高尿酸血症的风险预测标志物,为如下的至少一种的代谢组学特征质荷比:m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269。
22.一种高尿酸血症的风险预测试剂盒,所述试剂盒包括:至少一种高尿酸血症的风险预测标志物的检测试剂,所述高尿酸血症的风险预测标志物为高尿酸血症代谢标志物,所述高尿酸血症代谢标志物为代谢组学特征,所述代谢组学特征为如下的至少一种质荷比:m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269。
23.较优地,所述试剂盒的检测样本为血液样本、血清样本、尿液样本的至少一种。
24.较优地,所述试剂盒的检测样本来自健康个体、高尿酸血症患者、高尿酸血症病变者、高尿酸血症预后者的一种。
25.较优地,所述试剂盒还包括质控品、标准品、缓冲液中的一种或多种。
26.在本发明中,为使代谢组学分析具有较宽的动态范围,并可检测代谢物浓度的潜在变化,本发明实施例将高通量分析平台用于代谢组学分析,所述高通量分析平台包括ms耦合的液相色谱(lcms)、质谱耦合的气相色谱(gc-ms)、质子核磁共振(1h nmr)光谱,可以通过最少的样本进行分析检测,可靠地揭示跨越整个代谢组学系统的代谢组学途径,并具有提供深入了解高尿酸血症正常和病理发展所涉及的代谢过程的潜力。
27.以下详细介绍通过代谢组特征来表征标志物进而对高尿酸血症进行风险预测的方法建立过程和检测过程。
28.方法设计:根据尿酸检查确认结果,收集高尿酸血症患者组和正常对照组血清样品。经样本预处理后,通过质谱分析血清代谢提取物,并通过质谱峰鉴定和归一化平台处理,根据单变量和多变量分析比较高尿酸血症患者组和正常对照组的血清样本,以筛选出独特的代谢组学特征。
29.质谱(ms)分析:在5-15
µ
l血清中,加入200-400
µ
l预冷提取液(甲醇:乙腈:水=5:3:2)进行提取。在4℃下,将提取的样品进行连续涡旋20-40分钟,使蛋白质进行沉淀。将涡旋样品在4℃下,以12,000 g,离心20-40分钟,进行分离。进行ms分析之前,提取150-200μl上清液并保存在-20
°
c下或直接检测。
30.质谱分析使用超高效液相色谱-质谱法(uhplc-ms),使用security guard ultracartridge
–
uplc c18 2.1 mm id色谱柱分离(phenomenex,torrance, ca, us)。在30
°
c柱温及电喷雾模式下进行正、负离子扫描。
31.较优地,使用超高效液相色谱系统和高分辨质谱仪质谱仪,具体地,超高效液相色谱系统采用vanquish uhplc系统,高分辨质谱仪质谱仪采用q exactive plus质谱仪(thermo scientific,san jose,ca)。将10μl 血清提取物注入uhplc系统,流动相为:含有0.1%甲酸的5%乙腈溶液。
32.具体地,q exactive plus质谱扫描参数设置如下:表1质谱扫描参数项目参数设置扫描模式fullms扫描范围(m/z)60-900分辨率140,000极性正极/负极电喷雾电压(kv)4/3.3鞘气流速15辅助气流速12挡锥气流速0毛细管温度(摄氏度)325离子透镜射频电压55辅助气加热器温度(摄氏度)0将质谱代谢组学特征进行提取和标准化处理后,使用代谢特征的峰面积或强度作为预测指标,基于所选代谢特征的权重重要性,进行代谢组学途径富集分析,以区分高尿酸血症受试者与正常对照个体。
33.本发明队列共包含391名受试者,其中包括100名正常受试者,291名高尿酸血症受试者,每个受试者均进行了血清样本采集。
34.通过ms分析,在提取到的1557种代谢指标(代谢组学特征)中,首先采用统计学的方法对这些特征进行单变量分析,筛选出在高尿酸血症受试者和正常受试者中具有显著差异变量的代谢组学特征。
35.具体地,根据p值《0.05,差异倍数《0.83 或 差异倍数》 1.2 以及rocauc》0.6,筛选出19个代谢组学特征:m/z 212.999,m/z 343.224,m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982,m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209,m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323,m/z 354.269。图1为高尿酸血症患者不同发展阶段各特征归一化的信号强度值,其中图中case为高尿酸血症患者组,control 为对照组。19种代谢组学特征在高尿酸血症患者样本中均具有显著变化。
36.表2显示了高尿酸血症受试者与正常受试者的18种特征的单变量分析结果。
37.表2 高尿酸血症和正常受试者之间选定特征的单变量分析特征值(m/z)rocauc变化倍数阈值p值212.9990.9061.5542.328《0.001234.9820.8751.4051.822《0.001259.0050.9031.5011.568《0.001
272.9550.8911.5342.55《0.001280.9870.8671.4161.737《0.001286.9320.9051.8163.647《0.001317.2090.940.3490.33《0.001328.9160.8831.5162.127《0.001330.9130.8941.532.384《0.001338.9450.8161.5262.181《0.001343.2240.980.1160.112《0.001354.2690.7762.0021.073《0.001369.2990.8870.2710.345《0.001386.8750.8061.623.36《0.001400.3420.8551.4021.06《0.001413.3230.8920.4990.418《0.001530.3570.7940.7310.542《0.001534.7150.8050.7420.431《0.001796.5460.9650.2170.224《0.001通过对质谱代谢组学特征进行处理和标准化后,使用代谢特征的峰面积或强度作为预测指标。根据所述经过预处理的样本数据库,利用xgboost算法进行监督学习,构建高尿酸血症诊断模型。
38.xgboost算法是基于gbdt(梯度提升树)原理进行改进的算法,是目前最快最好的 boosted tree(提升树)算法,其可实现并行运算和增量学习,能进行大规模数据的处理。
39.本发明通过充分利用代谢组特征数据,基于xgboost的机器学习模型进行样本分类预测,所述方法包括以下步骤:步骤一、对391名受试者的血清样本进行检测,得到如上所述的特征质荷比;步骤二、将步骤一中所得数据代入xgboost模型,并通过交叉验证进行参数优化,选取rocauc得分最好的参数,自变量选择各个检测项,因变量选择高尿酸血症诊断结果;步骤三、进行目标函数定义,目标函数包括损失与正则化两部分;其中,损失=上一棵树的误差(梯度),正则化项=树的复杂度。通过目标函数优化,得到尽可能小的目标函数预测误差,及尽可能低的数的复杂度。在一个实施例中,可将xgboost算法参数配置为:最大决策树数量=2000;学习率=0.01;最大规则深度=4;决策树生长所需达到最小gain值=0;决策树复杂度衡量参数=1。
40.步骤四、根据贪心法进行切分点查找,构建决策树;具体地,可枚举所有不同的树结构,选取gain(增益)值最大且超过阈值的方案,如果max(gain)小于阈值则剪枝终止分裂。
41.步骤五、待决策树结构确定后,计算叶子结点的分数;步骤六、更新决策树序列,保存构建好的所有决策树及其得分;步骤七、计算训练集中各个样本的预测结果,即每棵树的得分之和,得到样本属于各个类别的概率;步骤八、计算每一个变量的重要性得分,挑选对模型影响显著的重要变量;
具体地,可计算各个变量的gini(基尼)系数,其gini系数平均值即该变量的重要性得分。
42.步骤九、高尿酸血症诊断模型根据重要变量进行构建及存储,用于后续测量数据的高尿酸血症风险预测;所述模型的输出值判定结果如下:(a)高尿酸血症低风险人群:风险值《0.726;(b)高尿酸血症高风险人群:风险值≥0.726,建议进行临床诊断。
43.本发明中,通过液质方法得出m/z 212.999,m/z 343.224,m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982,m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209,m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323,m/z 354.269,作为标志物,将所述标志物丰度输入xgboost训练测试后得到相应的预测高尿酸血症风险的模型。
44.使用10倍交叉法验证高尿酸血症模型的性能水平如表3所示。
45.表3 10倍交叉验证后的检测模型性能水平该检测确定了291名高尿酸血症患者中的283名高尿酸血症患者,其灵敏度为97.3%( 95%置信区间[ci], 95.2%
ꢀ‑ꢀ
99%),特异性为95% (95%ci,90%
ꢀ‑ꢀ
99%)。
[0046]
所有高尿酸血症患者和正常对照组受试者的高尿酸血症概率(检测得分)按组绘制,如图2所示,高尿酸血症样本可与正常样本显著分离。
[0047]
图3为正常组与高尿酸血症组roc曲线图,与正常对照相比,总的roc(receiver operating characteristic)的auc(area under curve)区分值分别为0.989,表明该检测方法效果良好。检测方法的临界值为区分值对应的阈值,本技术实施例获得的临界值为0.726,低于0.726判断为阴性,等于或大于0.726判断为阳性,即高尿酸血症高风险。
[0048]
本发明试剂盒及具体检测方法可以如下:在10
ꢀµ
l血清中,加入240
µ
l预冷提取液(甲醇:乙腈:水=5:3:2)进行提取。在4℃下,将提取的样品进行连续涡旋30分钟,使蛋白质进行沉淀。将涡旋样品在4℃下,以12,000 g,离心30分钟,进行分离。进行ms分析之前,提取170μl上清液并保存在-20
°
c下或直接检测。
[0049]
使用超高效液相色谱-质谱法(uhplc-ms),色谱柱为phenomenex c18柱(2.1 mm)。使用vanquish uhplc系统和qe-plus高分辨质谱仪(thermo scientific,san jose,ca)。将10μl血清提取物注入uhplc系统,流动相为:含有0.1%甲酸的5%乙腈溶液。
[0050]
样品在30℃柱温下通过phenomenex c18柱(2.1 mm),在esi正极和负极模式下扫
描。
[0051]
通过质谱方法得出m/z 212.999,m/z 343.224, m/z 796.546,m/z 259.005, m/z 286.932,m/z 400.342, m/z 386.875,m/z 234.982, m/z 330.913,m/z 272.955, m/z 534.715,m/z 280.987, m/z 338.945,m/z 317.209, m/z 530.357,m/z 328.916, m/z 369.299,m/z 413.323, m/z 354.269的丰度值,并输入高尿酸血症检测模型(即xgboost算法)进行打分,并根据分值进行风险预测,当分值小于临界值0.726,即可判断结果为阴性,即高尿酸血症低风险。
[0052]
尽管为说明目的公开了本发明的实施例,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换、变化和修改都是可能的,因此,本发明的范围不局限于实施例所公开的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。