1.本发明属于宏基因组学技术领域,具体涉及基于孪生神经网络的半监督宏基因组分箱方法。
背景技术:
2.使用宏基因组测序技术不需要培养微生物就可以得到微生物的基因组,所以宏基因组测序技术目前已经广泛地运用在了环境微生物的研究当中。很多研究使用宏基因组测序技术从人类,动物以及环境等样本中重构出了大量的基因组(mags)。标准的宏基因组分析流程为首先使用组装工具将宏基因组测序得到的短读片段(reads)组装成长读片段(contig),然后使用分箱工具(binning),将contig聚类成箱(bin),认为每一个bin中仅含有来自单个基因组的序列。
3.宏基因组分箱算法可以分为两类,取决于算法是否依赖于参考基因组。依赖于参考基因组的算法即只能找到参考基因组中存在的基因组,即已知的物种,意味着这样的方法不能发现新的物种。不依赖于参考基因组的方法是完全无监督的算法,因此这样的方法可以发现新的物种。
4.目前主流的宏基因组分箱工具都是不依赖于参考基因组的方法,例如metabat2,maxbin2,vamb和cocacola。solidbin是目前唯一的半监督宏基因组分箱工具,该方法存在两个问题,第一,物种注释的准确率较低,难以得到准确的must-link约束和cannot-link约束,尤其是must-link约束,数据中会存在着大量的噪声;第二,半监督谱聚类难以从大量的输入数据中学习到有价值的信息。所以需要一种新的分箱方法在减小数据噪声的同时提高分箱结果的准确性。
技术实现要素:
5.本发明的目的在于提供基于孪生神经网络的半监督宏基因组分箱方法,以解决背景技术中的问题。
6.本发明的目的可以通过以下技术方案实现:基于孪生神经网络的半监督宏基因组分箱方法,包括如下步骤:
7.步骤一:输入将较长的contig分割开,认为两个分开的短序列是一个must-link对,或者通过分裂不同的contig位置得到must-link约束;
8.使用物种注释工具或数据库进行物种注释,将注释到不同物种和不同属上的contig认为是一个cannot-link对,得到cannot-link约束。
9.步骤二:对k-mer频率特征以及丰度特征进行提取,设定k=4,即k-mer频率特征定义为4-mer片段在一个contig出现的频率,4-mer为类似atcg四个碱基组成的短序列片段;
10.假设某种4-mer片段在某个contig上出现的次数为ki,则k-mer频率特征(k
′i)的定义为:
[0011][0012]
丰度特征定义为比对到contig上某个位置的reads个数在contig上的平均值;如果在分箱的过程中使用的样本个数≥5,软件会使得丰度特征和k-mer频率特征在同一个数量级便于后续的训练;如果使用的样本的数量<5,则假设对比到contig上的每一个位置的reads的数量在整个contig上服从高斯分布,然后使用kl散度计算高斯分布间的相似性作为contig间的相似性,结合现有参考基因组的信息得到最终的丰度特征。
[0013]
步骤三:使用孪生神经网络模型从输入的must-link约束和cannot-link约束中进行学习;
[0014]
孪生神经网络模型使用对比损失函数进行学习,must-link约束中的特征表示距离较近,cannot-link约束中的特征表示距离较远;为了保证输入原始特征自身的特性,不受数据中噪声的影响,加入了一个均方误差损失函数来重构输入,使表示特征能够包含输入的信息;
[0015]
对比损失函数如下所示:
[0016][0017]
其中m
x
表示must-link约束,c
x
表示cannot-link约束,(x1,x2)表示输入数据,d(x1,x2)表示(x1,x2)间的欧式距离;y表示(x1,x2)中的指示变量,如果(x1,x2)∈m
x
,则值为1,如果(x1,x2)∈c
x
,则值为0;
[0018]
均方误差损失函数如下所示:
[0019][0020]
其中x表示输入数据,x
′
表示输出数据。
[0021]
步骤四:如果使用的样本数量≥5个,孪生神经网络的输入为k-mer频率特征以及丰度特征,则可以直接计算孪生网络的特征表示的欧式距离当做contig之间的相似性;
[0022]
如果使用的样本数量<5个,孪生神经网络的输入仅为k-mer频率特征,则只计算k-mer频率特征表示的欧式距离,然后假设比对到contig上的每一个位置的reads的数量在整个contig上服从高斯分布,使用kl散度计算高斯分布间的相似性作为contig间的相似性,结合现有参考基因组的信息,得到最终的contig间的相似性。
[0023]
步骤五:计算得到了contig之间的相似性后,将每一个contig当做是节点,然后将contig之间的相似性当做是节点的权重,每一个contig只考虑它权重最大的200条边,构造出一个稀疏网络;使用社团检测算法聚类,从稀疏网络中得到分箱的结果。
[0024]
进一步地,步骤三中模型训练使用的是adam优化器,2048的batchsize大小以及训练20个epoch;在训练结束之后,得到的新的特征表示将用于后续的聚类的步骤。
[0025]
进一步地,社团检测算法为infomap、gn、louvain和标签传播算法中的任意一种。
[0026]
本发明的有益效果:
[0027]
该基于孪生神经网络的半监督宏基因组分箱方法提出了一个新的生成must-link约束和cannot-link约束的方法,通过添加均方误差损失函数来交底数据中存在的噪声,有
利于提高物种注释的准确率;使用孪生神经网络处理must-link约束以及cannot-link约束,提高了分箱结果,并且提出了在不同样本数量的情况下,不同contig相似性的计算方式,便于从大量的输入数据中学习到有价值的信息。
附图说明
[0028]
下面结合附图对本发明作进一步的说明。
[0029]
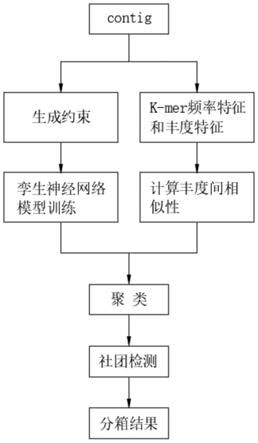
图1是本发明基于孪生神经网络的半监督宏基因组分箱方法的流程图;
[0030]
图2为实施例3中的分箱结果对比图。
具体实施方式
[0031]
下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0032]
实施例1
[0033]
请参阅图1,基于孪生神经网络的半监督宏基因组分箱方法,包括如下步骤:
[0034]
步骤一:将较长的contig分割开,认为两个分开的短序列是一个must-link对,得到must-link约束;
[0035]
使用gtdb参考数据库进行物种注释,将注释到不同物种和不同属上的contig认为是一个cannot-link对,得到cannot-link约束;
[0036]
步骤二:设定k=4,即k-mer频率特征定义为4-mer片段在一个contig出现的频率,4-mer为类似四个碱基组成的短序列片段;
[0037]
假设某种4-mer片段在某个contig上出现的次数为ki,则k-mer频率特征的定义为:
[0038][0039]
丰度特征定义为比对到contig上某个位置的reads个数在contig上的平均值;如果在分箱的过程中使用的样本个数≥5,软件会使得丰度特征和k-mer频率特征在同一个数量级便于后续的训练;如果使用的样本的数量<5,则假设对比到contig上的每一个位置的reads的数量在整个contig上服从高斯分布,然后使用kl散度计算高斯分布间的相似性作为contig间的相似性,结合现有参考基因组的信息得到最终的丰度特征;
[0040]
步骤三:使用孪生神经网络模型从输入的must-link约束和cannot-link约束中进行学习;孪生神经网络是对比学习中一个经典的框架,为两个贡献权值的神经网络,学习的目的是学一个新的映射,使得在同一个类中的样本距离近,在不同类中的样本距离远;
[0041]
孪生神经网络模型使用对比损失函数的学习目的为使得must-link中的特征表示距离较近,而使得cannot-link中的特征表示距离较远,并且为了尽可能保证输入原始特征自身的特性,不受数据中噪声的影响,加入了一个均方误差损失函数来重构输入,使得表示特征能够尽可能包含输入的信息。
[0042]
对比损失函数如下所示:
[0043][0044]
其中m
x
表示must-link约束,c
x
表示cannot-link约束,(x1,x2)表示输入数据,d(x1,x2)表示(x1,x2)间的欧式距离;y表示(x1,x2)中的指示变量,如果(x1,x2)∈m
x
,则值为1,如果(x1,x2)∈c
x
,则值为0。
[0045]
均方误差损失函数如下所示:
[0046][0047]
其中x表示输入数据,表示x
′
输出数据;
[0048]
模型训练使用的是adam优化器,2048的batch size大小以及训练20个epoch;在训练结束之后,得到的新的特征表示将用于后续的聚类的步骤;
[0049]
步骤四:计算丰度相似性,具体方式为:如果使用的样本数量≥5个,孪生神经网络的输入为k-mer频率特征以及丰度特征,因此可以直接计算孪生网络的特征表示的欧式距离当做contig之间的相似性;
[0050]
如果使用的样本数量<5个,孪生神经网络的输入仅为k-mer频率特征,然后只计算k-mer频率特征表示的欧式距离,假设比对到contig上的每一个位置的reads的数量在整个contig上服从高斯分布,然后使用kl散度计算高斯分布间的相似性,结合现有参考基因组的信息,得到最终的contig间的相似性;
[0051]
步骤五:计算得到了contig之间的相似性后,将每一个contig当做是节点,然后将contig之间的相似性当做是节点的权重,每一个contig只考虑它权重最大的200条边,构造出一个稀疏网络;使用infomap社团检测算法聚类,从稀疏网络中得到分箱的结果。
[0052]
实施例2
[0053]
请参阅图1,基于孪生神经网络的半监督宏基因组分箱方法,包括如下步骤:
[0054]
步骤一:分裂不同的contig位置,得到must-link约束;
[0055]
使用gtdb参考数据库进行物种注释,将注释到不同物种和不同属上的contig认为是一个cannot-link对,得到cannot-link约束;
[0056]
步骤二:设定k=4,即k-mer频率特征定义为4-mer片段在一个contig出现的频率,4-mer为类似四个碱基组成的短序列片段;
[0057]
假设某种4-mer片段在某个contig上出现的次数为ki,则k-mer频率特征的定义为:
[0058][0059]
丰度特征定义为比对到contig上某个位置的reads个数在contig上的平均值;如果在分箱的过程中使用的样本个数≥5,软件会使得丰度特征和k-mer频率特征在同一个数量级便于后续的训练;如果使用的样本的数量<5,则假设对比到contig上的每一个位置的reads的数量在整个contig上服从高斯分布,然后使用kl散度计算高斯分布间的相似性作为contig间的相似性,结合现有参考基因组的信息得到最终的丰度特征;
[0060]
步骤三:使用孪生神经网络模型从输入的must-link约束和cannot-link约束中进
行学习;孪生神经网络是对比学习中一个经典的框架,为两个贡献权值的神经网络,学习的目的是学一个新的映射,使得在同一个类中的样本距离近,在不同类中的样本距离远;
[0061]
孪生神经网络模型使用对比损失函数的学习目的为使得must-link中的特征表示距离较近,而使得cannot-link中的特征表示距离较远,并且为了尽可能保证输入原始特征自身的特性,不受数据中噪声的影响,加入了一个均方误差损失函数来重构输入,使得表示特征能够尽可能包含输入的信息。
[0062]
对比损失函数如下所示:
[0063][0064]
其中m
x
表示must-link约束,c
x
表示cannot-link约束,(x1,x2)表示输入数据,d(x1,x2)表示(x1,x2)间的欧式距离;y表示(x1,x2)中的指示变量,如果(x1,x2)∈m
x
,则值为1,如果(x1,x2)∈c
x
,则值为0。
[0065]
均方误差损失函数如下所示:
[0066][0067]
其中x表示输入数据,表示x
′
输出数据;
[0068]
模型训练使用的是adam优化器,2048的batch size大小以及训练20个epoch。在训练结束之后,得到的新的特征表示将用于后续的聚类的步骤;
[0069]
步骤四:计算丰度相似性,具体方式为:如果使用的样本数量≥5个,孪生神经网络的输入为k-mer频率特征以及丰度特征,因此可以直接计算孪生网络的特征表示的欧式距离当做contig之间的相似性;
[0070]
如果使用的样本数量<5个,孪生神经网络的输入仅为k-mer频率特征,然后只计算k-mer频率特征表示的欧式距离,假设比对到contig上的每一个位置的reads的数量在整个contig上服从高斯分布,然后使用kl散度计算高斯分布间的相似性,结合现有参考基因组的信息,得到最终的contig间的相似性;
[0071]
步骤五:计算得到了contig之间的相似性后,将每一个contig当做是节点,然后将contig之间的相似性当做是节点的权重,每一个contig只考虑它权重最大的200条边,构造出一个稀疏网络;使用infomap社团检测算法聚类,从稀疏网络中得到分箱的结果。
[0072]
实施例3
[0073]
选取来自toy human microbiome project datase中的cami i数据集和cami ii数据集。cami i数据集包括不同数目的微生物,其中有低复杂度(40个基因组,1个样本)、中复杂度(132个基因,2个样本)和高复杂度(596个基因,5个样本);cami i数据集模拟不同的人体部位,包括来自相同环境的多个模拟宏基因组。
[0074]
处理数据按实施例1中方法进行运用,将基于孪生神经网络的半监督宏基因组分箱方法(标记为a)与不使用孪神经网络学习的方法(标记为b)进行了比较,结果表明,基于孪生神经网络的半监督宏基因组分箱方法能够重构出更多的高质量基因组,并且在更加复杂的环境下表现更好(请参阅图2所示)。
[0075]
需要说明的是,在本文中,诸如术语“包括”、“包含”或者其任何其他变体意在涵盖
非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
[0076]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
