1.本发明涉及数据压缩编码技术领域,更为具体的,涉及一种支持行存的数据压缩编码方法、装置及时序数据库。
背景技术:
2.目前时序数据库非常多,比较有代表性的有hbase、influxdb、iotdb、pi实时数据库等。这些数据库的编码方式大多与gorrilla在《a fast,scalable,in-memory time series database》论文中提到的技术方案存在相似之处:如图1所示,描述了这种基于时间及浮点数的编码方式。另外,这些数据库厂商也开发出很多的编码算法,比如:simple8b、zigzag、行程编码(游程编码)、旋转门压缩算法等,这些数据库都有一个共同的特点就是采用列存方式,把相同的列的大量数据集中到一起进行编码,当处理数据库中某一列数据时效率非常高。但实际应用中存在大量需要按行处理数据的场景,并且需处理列数较多的情况下,列存性能并不理想,并且列存编码无法在数据逐行写入时马上进行编码。
技术实现要素:
3.本发明的目的在于克服现有技术的不足,提供一种支持行存的数据压缩编码方法、装置及时序数据库,提升存储空间使用率,增大存储量,提高了缓存的利用率,可以实现简洁的解码算法,从而极大提升数据库的整体性能等。
4.本发明的目的是通过以下方案实现的:
5.一种支持行存的数据压缩编码方法,包括步骤:
6.s1,定义数值型数据的表达式,按照定义的表达式定义数据块;
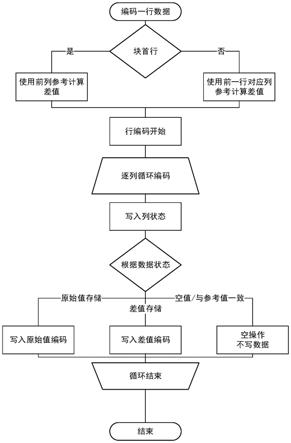
7.s2,输入一行数据后,判断是否为数据块首行,若为数据块首行,则使用其前一列参考并基于定义的数值型数据的表达式计算差值;若不是,则使用前一行对应列参考并基于定义的数值型数据的表达式计算差值,开始行编码,进入逐列循环编码,依照数据状态判断写入方式后,进行循环写入。
8.进一步地,所述数值型数据的表达式具体包括真正数字和小数位数,所述真正数字为数值的实际值把小数点去除后的表达方式,并将所述真正数字转为二进制表达;所述小数位数表示真正数字从右向左数第几个位置是小数点,即表示为乘以10的负多少次方。
9.进一步地,所述计算差值建立在两个数值的小数位数一致的情况下进行,计算方法为两个数值的真正数字进行异或运算得到。
10.进一步地,所述差值存储为可变长度模式。
11.进一步地,所述写入方式包括写入原始值、写入差值、空操作。
12.进一步地,所述数据块之间独立编码。
13.进一步地,所述开始行编码,进入逐列循环编码包括子步骤:数据块内第一行采取行内参考编码:第一列只存储原始值,从第二列开始如果满足小数位数相同则通过异或计算差值,如果差值存储空间小于设定值就存储差值,否则直接存储原始值;从第二行开始的
后续行中,采取对应列的值与前一行通过异或计算差值,如果能够计算差值且差值存储空间小于设定值就存储差值,否则直接存储原始值。
14.进一步地,在所述行编码过程中,数据类型用于描述数据的类别,字段描述信息用于描述数据存储的类型:原始值、差值、空值、与前一个完全一致共四种状态。
15.进一步地,在所述行编码过程中,数据组织操作按照4个字段共用一个字段描述信息,当状态为空值或与前一个完全一致时,不再额外占用空间;当四个字段均为与前一个完全一致时,则省略字段描述信息,并在字段位图上用1位标识一个0,一个字段位图字节管理8个字段描述信息即32个字段数据,在这32个字段的数据都未发生改变时,则在字段位图上存一个0。
16.进一步地,所述数据的类别包括首行数据或次行数据标识。
17.进一步地,在所述行存编码过程中,只需要参考前一行数据,数据库写入编码过程为写入一行编码一行。
18.进一步地,包括解码步骤;
19.s3,当数据库检索需求发生时,根据上层数据定位到需要读取的数据块,然后进行逐行解码。
20.进一步地,所述进行逐行解码包括子步骤:根据行存组织结构中的字段位图及字段描述信息,按照类型读取后续数据并进行运算即可得到实际值。
21.进一步地,包括数据恢复步骤,如果是原始值表示直接按编码规则即可恢复原来数据的样子,如果是差值表示需要用参考数据与差值进行异或运算并修正符号即可,如果是与参考数据一致表示则直接使用参考数据,如果是空值表示则数据为空。
22.进一步地,所述小数位数的状态具体为:正数表示含有小数,零表示该数为整数,负数表示该数有指数。
23.一种支持行存的数据压缩编码装置,包括数值型数据编码单元、数值型差值数据编码单元和行存编码单元;所述数值型数据编码单元,用于定义包括真正数字、小数位数和正负号信息的数值型数据表达方式;所述真正数字为数值的实际值把小数点去除后的表达方式,然后将所述真正数字转为二进制表达;小数位数表示当前真正数字从右向左数第几个位置是小数点,即乘以10的负多少次方后就与表达的数值一致;所述数值型差值数据编码单元,用于编码差值,且将差值存储为可变长度模式,而差值的计算则建立在两个数值的小数位数一致的情况下进行,计算方法为两个数值的真正数字进行异或运算得到;所述行存编码单元,用于数据库存储数据,且设计为按数据块进行独立编码;数据块内第一行采取行内参考编码:第一列只存储原始值,从第二列开始如果满足小数位数相同则通过异或计算差值,如果差值存储空间小于设定值就存储差值,否则直接存储原始值;从第二行开始的后续行中,采取对应列的值与前一行通过异或计算差值,如果能够计算差值且差值存储空间小于设定值就存储差值,否则直接存储原始值。
24.进一步地,包括数据解码单元和数据恢复单元;所述数据解码单元,用于当数据库检索需求发生时,根据上层数据定位到需要读取的数据块;然后进行逐行解码,即根据字段位图及字段描述信息,然后按照类型读取后续数据并进行运算即可得到实际值;所述数据恢复单元,用于执行如下流程:如果是原始值表示直接按编码规则即可恢复原来数据的样子,如果是差值表示需要用参考数据与差值进行异或运算并修正符号即可,如果是与参考
数据一致表示则直接使用参考数据,如果是空值表示则数据为空。
25.一种时序数据库,包括可读存储介质和程序,在可读存储介质上运行程序时,执行如上任一所述方法;或包括如上任一所述的支持行存的数据压缩编码装置。
26.本发明的有益效果是:
27.1.本发明实施例可以实现数据编码精确表示。
28.2.本发明实施例可以实现有效压缩存储空间
29.3.本发明实施例可以实现提高缓存利用效率。
30.4.本发明实施例可以实现现边插入边压缩。
31.5.本发明实施例可以实现提高数据处理效率。
32.本发明的有益效果不限于上述描述,具体在实施例中予以详细阐述。
附图说明
33.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
34.图1为现有基于时间及浮点数的编码方式示意图;
35.图2为简单数值型编码定义示意图;
36.图3为复杂数值型编码定义示意图;
37.图4为存储结构示意图;
38.图5为行的组织结构示意图;
39.图6为完成行存编码的步骤流程图。
具体实施方式
40.本说明书中所有实施例公开的所有特征,或隐含公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合和/或扩展、替换。
41.下面根据附图2~图6,对本发明主要解决的技术问题、设计思想、工作原理、有益效果和工作过程作进一步详细说明。
42.如图2~图6所示,本发明提供关于支持行存的数据压缩编码方法、装置及时序数据库的技术方案,至少解决了如下技术问题:
43.①
支持行存储,满足实际应用中存在大量需要按行处理数据的场景;
44.②
在处理列数较多的情况下,改善列存性能;
45.③
实现列存编码在数据逐行写入时,即能马上进行编码,实现边插入边压缩。
46.本发明主要设计思想是这样的:本发明技术方案中的方法主要面向数值型时序数据,提出支持行存的数据压缩编码方法。其中,数值型时序数据包括常见的整数、小数,其压缩编码按照层次分包括数值型数据编码、数值型差值数据编码和行存编码。其中,行存编码可以理解为整个编码数据的最终输出,而数值型数据编码、数值型差值数据编码为其基础表达方式。整个编码过程可以实现完全是无损压缩的模式。
47.本发明提供的空间压缩的主要技术手段包括:使用本发明实施例中的数值型数据
编码可以满足所有数值型时序数据存储要求、使用本发明实施例中的数值型差值数据编码可以缩小个体表达空间,使用本发明实施例中的行存编码可以实现大面积的空间节省及多种数据表达方式的管理。最终本发明实现数据空间减小,提升存储空间使用率,增大存储量。同时因为数据压缩,也提高了缓存的利用率,可以实现简洁的解码算法,从而极大提升数据库的整体性能。在实施时,具体包括:
48.a.数值型数据编码
49.其设计思想是这样的:本发明设计的数值型数据表达方式为真正数字、小数位数和正负号信息。其中真正数字为数值的实际值把小数点去除后的表达方式,比如123.4567890369,表示为1234567890369,同时在实际应用时,按照便于理解的方式可以每9个数字用30位二进制表达,考虑到尽量压缩掉末尾无效的零,所以第一个数据段为567890369、第二个数据段为1234,最多支持4个数据段,可表达最多36个十进制有效数字。小数位数表示真正数字从右向左数第几个位置是小数点,即乘以10的负多少次方后与表达的数值一致,这里的小数位数为10,则原始数据为1234567890369*10-10
=123.4567890369。需要说明的是,0表示整数,正数表示小数,负数表示指数。
50.在具体实施时,基于本发明如上设计思想的数值型数据编码设计为两类,即:简单数值型编码和复杂数值型编码,且数据编码设计为可变长度模式,所以真正数字部分仅保留有效数字部分,压缩掉无效的0,比如-1.23可表示为真正数字:123、小数位数:2、符号:负,其中真正数字仅用一个字节即可存储。
51.1、简单数值型编码定义:如图2所示,简单数值型编码的有效数据长度为1~8个字节。小数位数为3 1即4位,可表达0~15,真正数据有效位数最多为7*8-1=55位,可表达17位十进制数据。可见,满足常见数值型时序数据存储要求。
52.2、复杂数值型编码定义:如图3所示,复杂数值型编码的有效数据长度为1~17个字节。小数位数为8位有符号,可表达-127~127,真正数据有效位数最多为15*8=120位,可表达36位十进制数据。可见,满足所有数值型时序数据存储要求。
53.b、数值型差值数据编码
54.其设计思想是这样的:当需要存储的数据存在直接关系,比如相同列的前后时刻的数值,为了获得更高的压缩比率,可以存储两个数值的差值。一般情况下差值将会远远小于实际值。本发明设计的差值存储为可变长度模式,而差值的计算建立在两个数值的小数位数一致的情况下进行,计算方法为两个数值的真正数字进行异或运算得到,在具体实施中结果小于7字节整数表达范围。当解码恢复时,只需要用参考数据与差值进行异或运算,并修正符号即可得到实际数据,存储结构如图4所示。0个1表示整体占1字节,1~3个1表示整体占2~4字节,4个1表示整体占6字节,5个1表示整体占8字节。
55.c、行存编码
56.其设计思想是这样的:数据库存储数据为了照顾速度和编码压缩效率,因此本发明实施例设计为按数据块独立编码。数据块内第一行采取行内参考编码:即第一列只能存储原始值,从第二列开始如果满足小数位数相同即可通过异或计算差值,如果差值存储空间小就存储差值,否则直接存储原始值。从第二行开始的后续行中,采取对应列的值与前一行通过异或计算差值,如果可以计算差值且差值存储空间小就存储差值,否则直接存储原始值。在设计上,考虑的是存在列数非常多的情况,所以行的组织结构如图5所示。
57.在行编码中,数据类型描述数据的类别,比如首行数据或次行数据标识。字段描述信息为描述数据存储的类型:原始值、差值、空值、与前一个完全一致共四种状态,所以可采用两位表达。而数据组织操作中按字节处理会比较方便,所以按照4个字段共用一个字段描述信息,即可以完全使用8位。需要注意的是,当状态为空值或与前一个完全一致时,不再额外占用空间;当四个字段均为与前一个完全一致时,连字段描述信息也可以省略,只需要在字段位图上用1位标识一个0即可,所以一个字段位图字节可以管理8个字段描述信息即32个字段数据。特殊情况下,这32个字段的数据都未发生改变时,只需要在字段位图上存一个0即可解决,达到极致压缩水平。所以这种行存编码算法非常适合列数较多的情况。
58.行存编码过程中,只需要参考前一行数据即可,所以数据库写入编码可以是写入一行编码一行,更契合时序数据库。
59.d、数据解码
60.数据库检索需求发生时,可根据上层数据定位到需要读取的数据块。然后进行逐行解码,即根据字段位图及字段描述信息,然后按照类型读取后续数据并进行简单运算即可得到实际值,恢复方法为:原始值表示直接按编码规则即可恢复原来数据的样子,差值表示需要用参考数据与差值进行异或运算并修正符号即可,与参考数据一致表示可以直接使用参考数据,空值表示数据为空,整个解码过程计算快速准确。
61.如图6所示,输入一行数据,判断是否为块首行,若为块首行,则使用前列参照计算差值;若不是,则使用前一行对应列参考计算差值,开始行编码,进入逐列循环编码,依照数据状态判断写入方式(写入原始值、写入差值、空操作),循环结束,编码结束。
62.本发明在具体应用时的有益效果验证如下:
63.1.本发明中的数值型数据编码方法,对比gorrilla在《a fast,scalable,in-memory time series database》论文提到的数据存储方式不一样,在论文中存储的数据是原始的double数据值,占64位即8字节,而本发明存储的数据长度是可变的,长度在1~17个字节之间,数据表达也更准确。
64.2.本发明的差值编码方法,对比gorrilla的论文提到的差值不一样,该论文中使用的是浮点数原生类型,而本发明是基于自主设计的数值型表达方式进行,具体差别见下表1(小数位数及符号忽略):
65.表1
66.[0067][0068]
由表1可见,本发明能准确表达具体数值,而且所占内存也会比较小。且针对异或运算也确实反映数据的差值,相对于float、double更稳定。
[0069]
3.本发明所描述的行存编码方法,对比基于gorrilla的论文中提出的方案,具有更严格的管理组织信息,管理组织信息不仅仅使每一行数据都有一个头而且使得编码压缩率进一步提升,不是简单的把数据堆在一起。
[0070]
实施例1:一种支持行存的数据压缩编码方法,包括步骤:
[0071]
s1,定义数值型数据的表达式,按照定义的表达式定义数据块;
[0072]
s2,输入一行数据后,判断是否为数据块首行,若为数据块首行,则使用其前一列参考并基于定义的数值型数据的表达式计算差值;若不是,则使用前一行对应列参考并基于定义的数值型数据的表达式计算差值,开始行编码,进入逐列循环编码,依照数据状态判断写入方式后,进行循环写入。
[0073]
实施例2:在实施例1的基础上,所述数值型数据的表达式具体包括真正数字和小数位数,所述真正数字为数值的实际值把小数点去除后的表达方式,并将所述真正数字转为二进制表达;所述小数位数表示真正数字从右向左数第几个位置是小数点,即表示为乘以10的负多少次方。
[0074]
实施例3:在实施例1的基础上,所述计算差值建立在两个数值的小数位数一致的情况下进行,计算方法为两个数值的真正数字进行异或运算得到。
[0075]
实施例4:在实施例1的基础上,所述差值存储为可变长度模式。
[0076]
实施例5:在实施例1的基础上,所述写入方式包括写入原始值、写入差值、空操作。
[0077]
实施例6:在实施例1的基础上,所述数据块之间独立编码。
[0078]
实施例7:在实施例1的基础上,所述开始行编码,进入逐列循环编码包括子步骤:数据块内第一行采取行内参考编码:第一列只存储原始值,从第二列开始如果满足小数位数相同则通过异或计算差值,如果差值存储空间小于设定值就存储差值,否则直接存储原始值;从第二行开始的后续行中,采取对应列的值与前一行通过异或计算差值,如果能够计算差值且差值存储空间小于设定值就存储差值,否则直接存储原始值。
[0079]
实施例8:在实施例1的基础上,在所述行编码过程中,数据类型用于描述数据的类别,字段描述信息用于描述数据存储的类型:原始值、差值、空值、与前一个完全一致共四种状态。
[0080]
实施例9:在实施例8的基础上,在所述行编码过程中,数据组织操作按照4个字段共用一个字段描述信息,当状态为空值或与前一个完全一致时,不再额外占用空间;当四个字段均为与前一个完全一致时,则省略字段描述信息,并在字段位图上用1位标识一个0,一个字段位图字节管理8个字段描述信息即32个字段数据,在这32个字段的数据都未发生改变时,则在字段位图上存一个0。
[0081]
实施例10:在实施例8的基础上,所述数据的类别包括首行数据或次行数据标识。
[0082]
实施例11:在实施例1的基础上,在所述行存编码过程中,只需要参考前一行数据,数据库写入编码过程为写入一行编码一行。
[0083]
实施例12:在实施例1的基础上,包括解码步骤;
[0084]
s3,当数据库检索需求发生时,根据上层数据定位到需要读取的数据块,然后进行逐行解码。
[0085]
实施例13:在实施例12的基础上,所述进行逐行解码包括子步骤:根据行存组织结构中的字段位图及字段描述信息,按照类型读取后续数据并进行运算即可得到实际值。
[0086]
实施例14:在实施例12的基础上,包括数据恢复步骤,如果是原始值表示直接按编码规则即可恢复原来数据的样子,如果是差值表示需要用参考数据与差值进行异或运算并修正符号即可,如果是与参考数据一致表示则直接使用参考数据,如果是空值表示则数据为空。
[0087]
实施例15:在实施例2的基础上,所述小数位数的状态具体为:正数表示含有小数,零表示该数为整数,负数表示该数有指数。
[0088]
实施例16:一种支持行存的数据压缩编码装置,包括数值型数据编码单元、数值型差值数据编码单元和行存编码单元;所述数值型数据编码单元,用于定义包括真正数字、小数位数和正负号信息的数值型数据表达方式;所述真正数字为数值的实际值把小数点去除后的表达方式,然后将所述真正数字转为二进制表达;小数位数表示当前真正数字从右向左数第几个位置是小数点,即乘以10的负多少次方后就与表达的数值一致;所述数值型差值数据编码单元,用于编码差值,且将差值存储为可变长度模式,而差值的计算则建立在两个数值的小数位数一致的情况下进行,计算方法为两个数值的真正数字进行异或运算得到;所述行存编码单元,用于数据库存储数据,且设计为按数据块进行独立编码;数据块内第一行采取行内参考编码:第一列只存储原始值,从第二列开始如果满足小数位数相同则
通过异或计算差值,如果差值存储空间小于设定值就存储差值,否则直接存储原始值;从第二行开始的后续行中,采取对应列的值与前一行通过异或计算差值,如果能够计算差值且差值存储空间小于设定值就存储差值,否则直接存储原始值。
[0089]
实施例17:在实施例16的基础上,,包括数据解码单元和数据恢复单元;所述数据解码单元,用于当数据库检索需求发生时,根据上层数据定位到需要读取的数据块;然后进行逐行解码,即根据字段位图及字段描述信息,然后按照类型读取后续数据并进行运算即可得到实际值;所述数据恢复单元,用于执行如下流程:如果是原始值表示直接按编码规则即可恢复原来数据的样子,如果是差值表示需要用参考数据与差值进行异或运算并修正符号即可,如果是与参考数据一致表示则直接使用参考数据,如果是空值表示则数据为空。
[0090]
实施例18:在实施例1~15的基础上,一种时序数据库,包括可读存储介质和程序,在可读存储介质上运行程序时,执行如上任一所述方法;或在实施例16~17的基础上,包括如上任一所述的支持行存的数据压缩编码装置。
[0091]
本发明功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,在一台计算机设备(可以是个人计算机,服务器,或者网络设备等)以及相应的软件中执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、或者光盘等各种可以存储程序代码的介质,进行测试或者实际的数据在程序实现中存在于只读存储器(random access memory,ram)、随机存取存储器(random access memory,ram)等。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。