1.本发明涉及一种医疗大数据处理领域,特别是涉及一种医疗大数据治理系统及方法。
背景技术:
2.医疗数据是指患者就医过程中所产生的数据,包括患者基本信息、疾病主诉、检验数据、影像数据、诊断数据、治疗数据等,这类数据一般产生及存储在医疗机构的电子病历中,这也是医疗数据最主要的产生地。在电子病历的互通互联上,出于各自的利益性(限制病人转诊),各大电子病历企业也不愿意使数据互通互联。根据美国政府相关报告显示,其电子病历共享比例也仅为30%左右。
3.基于医疗大数据多源异构的特点,目前对医疗数据的格式没有标准的数据结构和统一的存储模式,如医学校验数据受限于数据格式不同、数据分布杂乱、数据情况未知等因素的影响,无法被有效利用,从而导致这部分医学数据的大数据查询以及挖掘等工作无法开展,无法为临床诊断和科研项目提供数据支撑。
4.因此,目前亟需一种能够方便医疗数据存储的、对医学数据进行治理的、使医学数据能够有效利用的一种医疗大数据治理系统及方法。
技术实现要素:
5.本发明要解决的技术问题是提供一种能够方便医疗数据存储的、对医学数据进行治理的、使医学数据能够有效利用的一种医疗大数据治理系统及方法。
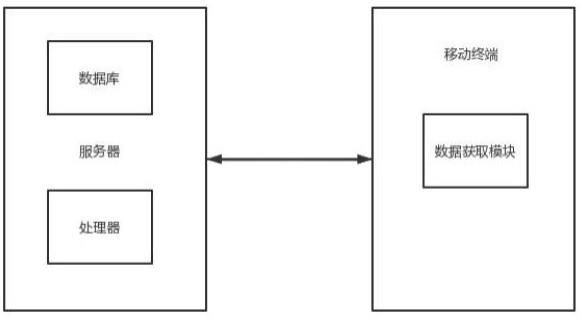
6.本发明一种医疗大数据治理系统,包括相互连接的移动终端和服务器;所述移动终端包括数据获取模块,所述数据获取模块能够获取第一医疗数据;所述服务器包括处理器和数据库;所述数据库中存储有第二医疗数据;所述处理器能够将所述第一医疗数据通过数据拆分法输出第一关键词数据,再通过第三方法将与所述第一关键词数据最匹配的所述第二医疗数据上传至所述服务器和所述移动终端存储。
7.本发明一种医疗大数据治理系统,其中所述第三方法为s1.1、所述处理器判断所述第二医疗数据中包括所述第一关键词数据的个数是否超过第二预设阈值a个;s1.2、若超过,则将所述第二医疗数据输出至服务器和所述移动终端存储;s1.3、若不超过,则所述处理器将所述第二预设阈值a减少第一变量后,跳转至s1.1;若是,则将所述第二医疗数据输出至服务器和所述移动终端存储;若否,所述处理器将所述第二预设阈值a减少重复次数f次第一变量,直至能够输出所述第二医疗数据,若所述重复次数f超过所述第一预设次数,则所述处理器将所述第一
医疗数据输出至服务器和所述移动终端。
8.本发明一种医疗大数据治理系统,其中所述数据拆分法为s2.1、所述数据库中还存储有第一助词数据、第一标点符号数据;s2.2、所述处理器用于判断所述第一医疗数据中是否有第一标点符号数据;若没有所述第一标点符号数据,则跳转至s2.3;若有所述第一标点符号数据,则所述处理器获取所述第一医疗数据中第一标点符号数据,并将第一个所述第一标点符号数据前的和两个相邻的所述第一标点符号数据之间的所述第一医疗数据输出为至少两个第三医疗数据;s2.3、所述处理器用于判断所述第三医疗数据中是否有第一助词数据;若有所述第一助词数据,则所述处理器获取多个所述第三医疗数据中的第一助词数据,并将第一个所述第一助词数据前的和所述第一助词数据后的所述第三医疗数据输出为至少两个第一预选关键词数据,所述处理器根据第二方法将所述第一预选关键词输出为第一关键词数据;若无所述第一助词数据,则所述处理器直接通过所述第二方法输出所述第一关键词数据;本发明一种医疗大数据治理系统,其中所述移动终端首先显示与所述第一关键词数据最匹配的所述第二医疗数,后面显示与所述第一关键词数据有关联的所述第二医疗数据。
9.本发明一种医疗大数据治理系统,其中所述第一助词数据为“的”、“得”、“地”。
10.本发明一种医疗大数据治理系统,其中所述移动终端包括电脑、手机、平板电脑。
11.本发明一种医疗大数据治理系统,其中所述移动终端与所述服务器的连接方式为无线连接。
12.本发明一种医疗大数据治理系统,其中所述第一医疗数据为标准化的医疗数据。
13.本发明一种医疗大数据治理系统,其中所述第二医疗信息有以下一项或多项组合而成:药品名称、疾病名称、疾病描述。
14.本发明一种医疗大数据治理系统的治理方法,其包括如下步骤:存储有第二医疗数据;获取第一医疗数据;处理器将所述第一医疗数据通过数据拆分法输出第一关键词数据;通过第三方法将与所述第一关键词数据最匹配的所述第二医疗数据上传至所述服务器和所述移动终端存储。
15.本发明一种医疗大数据治理系统及方法与现有技术不同之处在于本发明能够通过上述内容能够对医务人员在手动输入一些医疗数据时,能够通过处理器将其与所述数据库中存储的医疗数据做对比,将医务人员手动输入的医疗数据转化成数据库中存储的标准化的医疗数据,这样就能够将不同的医务人员输入的第一医疗数据转化成统一标准进行存储,能够对医疗数据进行标准化的治理,使医疗数据不会受限于数据格式不同、数据分布杂乱、数据情况未知等因素的影响而无法被有效利用,方便医疗数据的大数据查询以及挖掘等工作无法开展,为临床诊断和科研项目提供更多的数据支撑。
16.下面结合附图对本发明的一种医疗大数据治理系统及方法作进一步说明。
附图说明
17.图1是一种医疗大数据治理系统的无线连接图;图2是一种医疗大数据治理系统的第一流程图;图3是一种医疗大数据治理系统的第二方法流程图。
具体实施方式
18.如图1~3所示,参见图1、2,一种医疗大数据治理系统,包括相互连接的移动终端和服务器;所述移动终端包括数据获取模块,所述数据获取模块能够获取第一医疗数据;所述服务器包括处理器和数据库;所述数据库中存储有第二医疗数据;所述处理器能够将所述第一医疗数据通过数据拆分法输出第一关键词数据,再通过第三方法将与所述第一关键词数据最匹配的所述第二医疗数据上传至所述服务器和所述移动终端存储。
19.本发明通过上述内容能够对医务人员在手动输入一些医疗数据时,能够通过处理器将其与所述数据库中存储的医疗数据做对比,将医务人员手动输入的医疗数据转化成数据库中存储的标准化的医疗数据,这样就能够将不同的医务人员输入的第一医疗数据转化成统一标准进行存储,能够对医疗数据进行标准化的治理,使医疗数据不会受限于数据格式不同、数据分布杂乱、数据情况未知等因素的影响而无法被有效利用,方便医疗数据的大数据查询以及挖掘等工作无法开展,为临床诊断和科研项目提供更多的数据支撑。
20.其中,所述第一医疗数据为标准化的医疗数据。
21.其中,所述第二医疗数据为药品名称、疾病名称、疾病描述、药物单位等基础信息。
22.其中,所述移动终端与服务器的连接方式为无线连接。
23.本发明通过移动终端与服务器无线连接的方式能够使所述医生远程也能够使用本系统,不需要有线连接,减少成本,提高使用感。
24.优选的,参见图1、2,所述第三方法为s1.1、所述处理器判断所述第二医疗数据中包括所述第一关键词数据的个数是否超过第二预设阈值a个;s1.2、若超过,则将所述第二医疗数据输出至服务器和所述移动终端存储;s1.3、若不超过,则所述处理器将所述第二预设阈值a减少第一变量后,跳转至s1.1;若是,则将所述第二医疗数据输出至服务器和所述移动终端存储;若否,所述处理器将所述第二预设阈值a减少重复次数f次第一变量,直至能够输出所述第二医疗数据,若所述重复次数f超过所述第一预设次数,则所述处理器将所述第一医疗数据输出至服务器和所述移动终端。
25.本发明通过所述处理器判断从医生写的数据中提取出的关键词与数据库中存储的第二医疗数据进行对比,判断从医生写的数据中提取出的多个关键词中是否有第二预设
阈值个在所述第二医疗数据中能够搜索到,如果能搜索到,就将这个所述第二医疗数据当做最终的数据上传至移动终端和服务器。
26.其中,所述第一变量为5%-20%个,优选为10%个。
27.其中,所述第一预设次数为1-5次,优选为3次。
28.其中,所述第二预设阈值a为5%-99%。优选为80%。
29.其中,所述移动终端首先显示与所述第一关键词数据最匹配的所述第二医疗数,后面显示与所述第一关键词数据有关联的所述第二医疗数据。
30.本发明通过上述内容能够将与所述第一关键词数据有关的所述第二医疗数据都显示出来,将最匹配的排在第一位,以供医生进行选择。
31.例如,通过数据拆分法将所述第一医疗数据拆分成了10个所述第一关键词数据,则所述第二预设阈值a为10的80%,为8个,处理器需要判断这10个关键词数据是否有8个以上的词都包含在数据库存储的第二医疗数据中,如果超过了8个以上,则证明医生写的这段话与数据库中存储的标准的话比较匹配,将数据库中存的对应的所述第二医疗数据上传到移动终端和服务器存储;若没超过8个,则将所述第二预设阈值a减少10%,则所述第二预设阈值a为10*70%=7个,在重复上述步骤,判断这10个关键词数据是否有7个以上的词都包含在数据库存储的第二医疗数据中,如果超过了7个以上,数据库中存的对应的所述第二医疗数据上传到移动终端和服务器存储,若没超过7个,则将再次减少所述第二预设阈值a,若连续减少3次都没有超过所述第二预设阈值a个,则证明医生写的话与数据库中存储的没有匹配的,则将所述第一医疗数据,换句话说,也就是将医生写的话直接输出至移动终端和服务器进行存储。
32.优选的,参见图1、2,所述数据拆分法为s2.1、所述数据库中还存储有第一助词数据、第一标点符号数据;s2.2、所述处理器用于判断所述第一医疗数据中是否有第一标点符号数据;若没有所述第一标点符号数据,则将第一医疗数据输出为第三医疗数据;若有所述第一标点符号数据,则所述处理器获取所述第一医疗数据中第一标点符号数据,并将第一个所述第一标点符号数据前的和两个相邻的所述第一标点符号数据之间的所述第一医疗数据输出为至少两个第三医疗数据;s2.3、所述处理器用于判断所述第三医疗数据中是否有第一助词数据;若有所述第一助词数据,则所述处理器获取多个所述第三医疗数据中的第一助词数据,并将第一个所述第一助词数据前的和所述第一助词数据后的所述第三医疗数据输出为至少两个第一预选关键词数据,所述处理器根据第二方法将所述第一预选关键词输出为第一关键词数据;若无所述第一助词数据,则所述处理器直接通过所述第二方法输出所述第一关键词数据;本发明首先通过处理器将所述医务人员写的病情描述通过标点符号划分成几句话,然后再将这几句话从语气助词“的”处接着划分,从而将一句话划分成若干个字符较少的话,在筛选划分后通过所述第二方法将若干个字符较少的话,分割成若干个字符,将这若干个字符输出为所述第一关键词数据,本发明能够将一句较长的话分割成较短的话后再进行筛选关键词,能够减少系统的处理时间,从而较快的将标椎的医疗数据筛选出来,从而使
不同医生都描述的不同的话用同一标准显示出来,从而方便其他医务人员利用。
33.其中,若所述第一医疗数据中没有所述第一标点符号数据,则所述处理器判断所述第一医疗数据中是否有第一助词数据。
34.其中,所述第二方法为将所述第一预选关键词数据直接输出为第一关键词数据。
35.其中,所述第一助词数据为“的”、“得”、“地”。
36.例如,所述第一医疗数据为:患者经常出现小腿的抽筋,晚上的疼痛感觉居多,有疲劳乏力的症状。
37.所述第三医疗数据为:“患者经常出现小腿的抽筋”、“晚上的疼痛感觉居多”、“有疲劳乏力的症状”。
38.所述第一预选关键词数据为:“患者经常出现小腿”、“抽筋
”ꢀ
、“晚上”、“疼痛感觉居多”、“有疲劳乏力”、“症状”。
39.优选的,参见图1、2、3,所述第二方法为s3.1、所述数据库中存储有第一词语数据;s3.2、所述处理器获取每一个没有所述第一助词数据的所述第三医疗数据或所述第一预选关键词数据中的第一字符数据,并将第i个第一字符数据和第i 1个第一字符数据转化为第二词语数据;s3.3、所述处理器判断所述第二词语数据与所述第一词语数据是否一致;若一致,则将所述第二词语数据输出为第一关键词数据,并剔除所述第三医疗数据或所述第一预选关键词数据中的第二词语数据,并跳转至s3.2,当最后一个所述第一字符被剔除后结束指令;若不一致,则将第二词语数据和第i n个所述第一字符数据更新为新的第二词语数据;s3.4、判断新的所述第二词语数据与所述第一词语数据是否一致,若一致,则将所述新的第二词语数据输出为第一关键词数据,并剔除所述第三医疗数据或所述第一预选关键词数据中的第二词语数据,并跳转至s3.2;若不一致,跳转至s3.3,并将所述第二词语数据中的n转化为n=n 1;若当所述第二关键词数据有4个所述第一字符数据且与所述第一词语数据不一致时,将每一个没有所述第一助词数据的所述第三医疗数据或所述第一预选关键词数据中的第一个所述第一字符数据输出为所述第一关键词数据并将第一个所述第一字符数据剔除后再跳转至s3.2。
40.本发明通过将所述第一预选关键词或没有所述第一助词数据的所述第三医疗数据加工第一个字符与第二个字符组成一个词语并与数据库对比,判断这个是否为数据库中的词语,若是就将这个词语输出为关键词,若不是,就将前三个字符作为第一个词语在于数据库中对比判断,以此类推,因为词语最多为四个字,则最多就将4个相连的字符组在一起,从而能够将这段话中的每个词语分割出来,将这些词语输出为关键词,这种方法不会出现漏词的风险,能够将一段话中的所有词语都分割出来。
41.其中,n的初始值为2,当指令结束后n恢复为初始值。
42.其中,由于一个词语最多有4个汉字组成,则n的最大值为4,当n=n 1为n=4 1时,此时n=5》4,将每一个没有所述第一助词数据的所述第三医疗数据或所述第一预选关键词数
据中的第一个所述第一字符数据输出为所述第一关键词数据并将第一个所述第一字符数据剔除后再跳转至s3.2。
43.例如,所述第一医疗数据为:患者胸闷气短,说话不流畅,有三凹征,能够听到哮鸣音。
44.所述第三医疗数据为:“患者胸闷气短”、“说话不流畅”、“有三凹征”、“能够听到哮鸣音”。
[0045]“患者胸闷气短”中,当i=1时,i 1为2,也就是说将第一个所述第一字符数据“患”和第二个所述第一字符数据“者”输出为第二词语数据“患者”,上述步骤为s3.2;将“患者”与数据库中存储的第一词语数据进行对比,若数据库中有“患者”这个词,则将“患者”输出为第一关键词数据,并将“患者”从所述第三医疗数据中剔除,此步骤为s3.3,并接着重复上述s3.2的步骤,剔除“患者”后,所述“患者胸闷气短”就只剩下“胸闷气短”将第一个所述第一字符数据和第二个所述第一字符数据输出为第二词语数据“胸闷”,若数据库中有“胸闷”这个词,则将“胸闷”也输出为第一关键词数据,并将“胸闷”从所述第三医疗数据中剔除,所述“胸闷气短”就只剩下“气短”,若数据库中有“气短”这个词,则将“气短”输出为第一关键词数据,当所述最后一个所述第一字符“短”被剔除后则结束指令。
[0046]“有三凹征”中,当i=1时,i 1为2,也就是说将第一个所述第一字符数据和第二个所述第一字符数据输出为第二词语数据“有三”,上述步骤为s3.2,将“有三”与数据库中存储的第一词语数据进行对比,数据库存储的所述第一词语数据中无“有三”这个词,上述步骤为s3.3,则将“有三”和第i n个所述第一字符,也就是第1 2=3个所述第一字符“凹”组成新的所述第二词语数据为“有三凹”,接着将“有三凹”与数据库中存储的第一词语数据进行对比,数据库存储的所述第一词语数据中无“有三凹”这个词,上述步骤为s3.4,由于此时n=n 1,则i n为1 2 1=4,那么第四个所述第一字符为“征”,则将“有三凹”和征组成新的所述第二词语数据为“有三凹征”,将“有三凹征”与数据库中存储的第一词语数据进行对比,数据库存储的所述第一词语数据中无“有三凹征”这个词,则将所述第一个所述第一字符数据“有”输出为第一关键词数据,再将“三凹”输出为新的所述第二词语数据,与数据库中存储的所述第一词语数据进行对比,数据库中存储的所述第一词语数据中无“三凹”这个词,则将“三凹”与征组成新的所述第二词语数据为“三凹征”,与数据库中存储的所述第一词语数据进行比较,数据库中存储有“三凹征”,则将“三凹征”输出为所述第一关键词数据。
[0047]
通过上述方法可知“说话不流畅”、“能够听到哮鸣音”中的所述第一关键词为:“说话”、“不”、“流畅”、“能够”、“听到”、“哮鸣音”。
[0048]
优选的,参见图1、2,所述数据库中还存储有第一动词数据、第一时间数据、第一名称数据;所述处理器能够获取所述第一关键词数据中的第一动词数据、第一时间数据、第一名称数据并输出为第三词语数据;所述处理器根据所述第一关键词数据的第一个数数据b、所述第三词语数据的第二个数数据c并根据第一公式生成所述第二预设阈值a;。
[0049]
本发明通过上述公式能够将医务人员写的不同的描述中会生成不同个所述第一关键词数据,能够使用每个医务人员的写作习惯,因此,将所述第二预设阈值a改变成一个变化的值,从而能够当输出了不同个所述第一关键词数据时,能够产生不同的第二预设阈值,能够使对比的更加准确,从而输出最准确的所述第二医疗数据,其中所述第二词语数据为所述第一医疗数据中不会对判断产生决定性影响的一些词语,换句话说,所述第二词语数据为无用词,通过全部的所述第一关键词数据减去其中的无用词,也就是说b-c为有用的所述第一关键词,从而求出有用词在所述第一关键词中的比例,当所述第二医疗数据中包括所述第一关键词数据的个数没有超过第二预设阈值a个时,将所述第二预设阈值a减小第一变量,也就是说,重复次数f越大,所述第二预设阈值a应该越小,因此重复次数f位于公式的分母中,当第一次计算时,所述重复系数f为0。
[0050]
例如,所述第一关键词数据为:“患者”、“胸闷”、“气短”、“说话”、“不”、“流畅”、“有”、“三凹征”、“能够”、“听到”、“哮鸣音”,所述第一词语数据为:“患者”、“说话”、“不”、“有”、“能够”、“听到”,则所述第一个数数据b为11个,所述第二个数数据c为6个,若所述重复次数f为0,则所述第二预设阈值。
[0051]
其中,第一个数数据b为每一个没有所述第一助词数据的所述第三医疗数据或所述第一预选关键词数据中的第一关键词的个数。
[0052]
其中,第二个数数据c为每一个没有所述第一助词数据的所述第三医疗数据或所述第一预选关键词数据中的第三词语数据的个数。
[0053]
本发明一种医疗大数据治理系统的治理方法,包括如下步骤:步骤1、存储有第二医疗数据;步骤2、获取第一医疗数据;步骤3、处理器将所述第一医疗数据通过数据拆分法输出第一关键词数据;步骤4、通过第三方法将与所述第一关键词数据最匹配的所述第二医疗数据上传至所述服务器和所述移动终端存储。
[0054]
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。