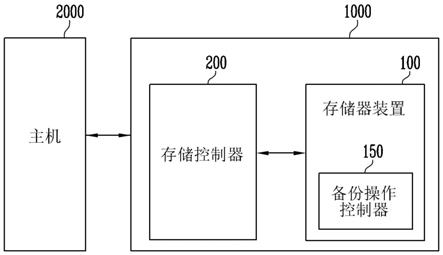
1.本发明涉及一种异构众核架构上基于算子融合的数据复用方法,属于深度学习技术领域。
背景技术:
2.近年来,人工智能的迅速发展将深刻改变世界发展模式和人类生活方式,为抢抓人工智能发展重大战略机遇,各国均在构筑先发优势。dnn算子库是针对人工智能的底层算力支撑库,是针对人工智能深度学习的基础,算子虽然已众核化加速,但每调用一个算子,都需将算子的输入数据从内存中读入ldm,完成运算后再将此算子的计算结果从ldm写回内存,这样每个算子调用就需要两次内存访问。现实中的ai应用需要对各种算子按需进行不断地调用,对于异构众核架构,频繁的内存访问势必会影响整体性能的提升。基于此况,如何减少内存的访问次数,提升数据复用率,对众核化背景下的ai应用具有重大的意义。
3.目前,dnn算子库算子已被众核化加速,虽然单个算子已经有了较大的性能提升,但是在异构众核架构下,带宽资源是系统的瓶颈,如何减少算子与内存不必要的交互才是优化性能的关键所在。如果只是单个算子的加速,虽然在计算速度上有了很大性能提升,但是对于现实的ai应用,需要对不同的算子进行不断的调用,单纯的算子调用并不能得到进一步的性能提升。虽然ai应用对算子的调用具有一定的规律性,前后相邻两个算子有如下关系:前一个算子的输出是后续算子的数据输入,如果只是单纯的调用已有算子,每个算子又不断地从内存中读取写入数据,会对内存造成很大的压力,目前还没有一项技术能够减少访存,节约带宽资源。
技术实现要素:
4.本发明的目的是提供一种异构众核架构上基于算子融合的数据复用方法,其极大减少了内存访问次数,缓解了访存压力,提高了数据的复用率,综合提升了可融合算子的效率。
5.为达到上述目的,本发明采用的技术方案是:提供一种异构众核架构上基于算子融合的数据复用方法,将dnn算子库中依次调用的至少两个算子a、b进行功能融合,获得融合算子c,执行以下操作:s1、融合算子c从主存中读取数据到局存中,并将读取的数据作为算子a的输入;s2、算子a将获取的数据作为输入,进行相应的运算,完成算子a的功能计算,此时算子a将结果保留在局存中不写回主存;s3、算子a将局存中的计算结果传递给算子b,作为算子b的输入;s4、算子b将来自算子a的数据作为输入,进行相应的运算,完成算子b的功能运算;s5、算子b完成运算后,将最终的计算结果从局存写回主存;s6、算子c运算结束。
6.由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
本发明利用异构众核架构,通过探索ai应用中算子调用的规律,将dnn算子库中依次调用的多个算子进行功能融合,在数据读入ldm后完成后续所有算子的更新,省略了中间算子计算结果存入内存以及后续算子从内存读取数据的访存操作,转而变成第一个算子从内存中读取数据,最后一个算子将结果一次性写入内存,极大减少了内存访问次数,缓解了访存压力,提高了数据的复用率,综合提升了可融合算子的效率,为众核化加速的ai应用性能的提升提供新的途径。
附图说明
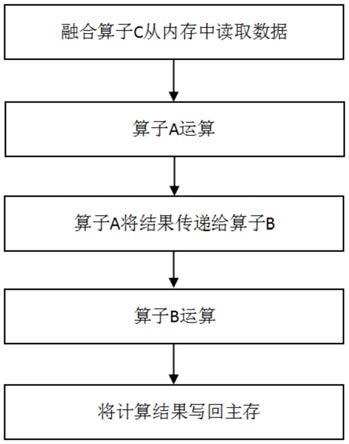
7.附图1为算子示意图;附图2为融合算子示意图;附图3为算子融合流程示意图。
具体实施方式
8.实施例:本发明提供一种异构众核架构上基于算子融合的数据复用方法,将dnn算子库中依次调用的两个算子以及两个以上的算子进行功能融合,获得融合算子,以算子a和b为例,融合为算子c,执行以下操作:s1、融合算子c从主存中读取数据到局存中,并将读取的数据作为算子a的输入;s2、算子a将获取的数据作为输入,进行相应的运算,完成算子a的功能运算,此时算子a不将结果写回主存,而是仍然保留在局存中;s3、算子a将局存中的计算结果传递给算子b,作为算子b的输入;s4、算子b将来自算子a的数据作为输入,进行相应的运算,完成算子b的功能运算;s5、算子b完成运算后,将最终的计算结果从局存写回主存;s6、算子c运算结束。
9.只进行了一次读取和一次写入操作,就同时完成了算子a和算子b的运算功能;相比于分别调用算子a和算子b,减少了一次读取和一次写入操作,大大减少了访存开销,降低了访存压力。
10.对上述实施例的进一步解释如下:本发明根据dnn算子库中实现的算子,以及常见ai应用调用算子的先后顺序,ai应用通常依次按序调用多个算子,前一个算子的输出,作为后一个算子的输入;同时,每个算子在计算前,都需要从主存中读取数据到局存,在局存中进行计算,计算完毕后将计算结果写回主存,这样,后续算子需要从主存中读取上一个算子的计算结果到局存中,再进行计算,这样会带来较大的访存压力,如果能够在局存中完成所有算子的计算,那么将减少不断读写主存的开销,为此,将具有前后顺序的两个甚至是两个以上的算子,融合为单个算子,就可以将原来每个算子不断读写主存的操作,转变为第一个算子读主存,最后一个算子写主存,中间算子只需要负责在局存中计算,极大减少了读写主存的次数,降低访存压力。
11.常见的算子如下图1所示,算子a从内存中读取数据后,进行相应的运算,运算完成后,将结果存入内存,算子b同理。
12.现假设某ai应用需要先后调用算子a和算子b,算子b的所需的数据来自于算子a的计算结果,直观上看,总共需要4次访存操作,两次读取两次存入。
13.算子a完成运算后,将结果存入内存,算子b再将a的计算结果从内存中读取,显然,这一步有些多余,对于立即可以使用的数据,没必要立刻存入内存,造成了不必要的额外访存开销。
14.为此,本发明为了省略算子a的存入操作和算子b的读取操作,进行了如下图2所示的算子融合,算子c对算子a、算子b进行功能融合,算子c完成了算子a和算子b的功能,对于同样的数据输入,调用算子c的结果输出,与先调用算子a,后调用算子b所得到的结果输出是相同的。
15.如图3所示,算子c将算子a和算子b进行了融合,读取数据并将数据作为算子a的输入,对于算子a的计算结果,不是先存入内存,而是直接将计算结果传递给算子b,在算子b完成运算后,再将最终结果存入内存。
16.这样,算子c只需要两次访存,一次读取一次存入就完成了算子a和算子b的功能,相对于最初的四次访存,降低为两次访存,理论上对内存带宽的压力将会减少一半,省略了中间算子读取和存入内存的操作,大大提升了算子的效率。
17.1、融合算子c从内存中读取数据,并将读取的数据作为算子a的输入;2、算子a将获取的数据作为输入,进行相应的运算,完成a的计算功能;3、算子a将最终计算结果传递给算子b,作为算子b的输入;4、算子b将来自a的数据作为输入,进行相应的运算;5、算子b完成运算后,将最终的计算结果存入内存;6、算子c运算结束。
18.采用上述一种异构众核架构上基于算子融合的数据复用方法时,其通过探索ai应用中算子调用的规律,将dnn算子库中依次调用的多个算子进行功能融合,在数据读入ldm后完成后续所有算子的更新,省略了中间算子计算结果存入内存以及后续算子从内存读取数据的访存操作,转而变成第一个算子从内存中读取数据,最后一个算子将结果一次性写入内存,极大减少了内存访问次数,缓解了访存压力,提高了数据的复用率,综合提升了可融合算子的效率,为众核化加速的ai应用性能的提升提供新的途径。
19.为了便于更好的理解本发明,下面将对本文中使用的术语进行简要的解释:ldm:处理器的局部存储空间。
20.dnn:深度神经网络,是深度学习的基础。
21.dnn算子库:一种实现了dnn常见算子的数学库。
22.上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。