1.本发明涉及图像处理与自然语言处理技术领域,尤其涉及一种基于笔画扰动与后处理的手写文字识别模型性能的提升方法。
背景技术:
2.文本识别近年来取得了阶段性的突破。模型的准确性取决于作为输入的图像的质量与模型准确性。而模型准确性取决于模型结构已经训练数据集的多样性。
3.通常评估一个文字识别模型的准确性分别有平均编辑距离、字符识别准确率、文本行识别准确率。平均编辑距离是指将预测结果转换成真实结果所需的最少的编辑次数。其中编辑方式包括替换字符、插入字符、删除字符。平均编辑距离越小说明识别率越高。字符识别准确率即识别对的字符数占总字符数的比例。文本行识别准确率即识别对的文本行占总文本行的比例。然而,在中文文本行识别的实际应用中面临的一个挑战是:字符识别准确率往往高于文本行识别的准确率。如图1所示(图片来源:a fast alignment scheme for automatic ocr evaluation of books by yalniz,ismet and manmatha,r.);从图1中可以看出character-level的准确率要远高于word-level的准确率;提高文本行准确性的一种方法是使用nlp(自然语言处理)技术将不正确的单词替换为正确的单词。
4.目前手写中文识别模型的性能远低于印刷体识别模型的性能,这是因为手写中文具有极高的多样性,不仅个体之间存在书写习惯的差异,个人书写同一个字也存在着一定的笔画差异。
5.因此,本发明提出了一种基于笔画扰动与后处理的手写文字识别模型性能的提升方法,利用后处理来提升文本行识别的准确率,同时除了利用后处理来提升模型的准确性,还利用笔画干扰来提高数据集的多样性。
技术实现要素:
6.本发明要解决的技术问题是,提供一种基于笔画扰动与后处理的手写文字识别模型性能的提升方法,利用后处理来提升文本行识别的准确率,同时除了利用后处理来提升模型的准确性,还利用笔画干扰来提高数据集的多样性。
7.为了解决上述技术问题,本发明采用的技术方案是:该基于笔画扰动与后处理的手写文字识别模型性能的提升方法,具体包括以下步骤:
8.s1基于笔画扰动的手写体数据集的制作:首先通过笔画提取,获得笔画像素联通区域,再对连通区域内的笔画进行笔画扰动,从而获得具有多样性的手写体数据集;
9.s2模型训练:将步骤s1中获得的手写体数据集采用文本识别模型进行训练,提取文本图片的特征,并获得模型预测结果;
10.s3后处理:对模型预测结果进行分词,再判断是否存在可疑词语,若存在可疑词语,则用候选字符进行替换并更正可疑词语,从而获得预测结果。
11.采用上述技术方案,通过笔画扰动提升数据集的多样性,再进行模型训练,再通过
后处理方法,可以有效提升文本行准确率,尤其是对一些较为模糊或尺寸较小的图片,有良好的提升效果。
12.作为本发明的优选技术方案,所述步骤s1具体包括以下步骤:
13.s11笔画提取:首先找到文本行的外接矩形框,其次从外接矩形框的第一个像素点开始分别向上、下、左、右四个方向进行遍历,寻找像素点的联通像素点,从而获得笔画像素联通区域;
14.s12笔画扰动:在获得笔画像素联通区域后,对笔画像素联通区域内的字体笔画进行笔画扰动,扰动方法包括旋转、畸变和位置偏移,获得多样性的手写字体,并存入手写字体数据集。
15.作为本发明的优选技术方案,所述步骤s2模型训练采用卷积循环神经网络crnn,所述卷积循环神经网络的结构包括卷积层、循环网络层和转录层;所述卷积层采用vgg16的结构,对输入的图片进行特征图的提取;所述循环网络层采用三层bilstm;所述转录层采用ctc算法,将rnn模型预测出的标签转换成预测结果,从而获得模型预测结果。rnn模型多用于自然语言处理(nlp),它被广泛应用于建立语言模型和语音识别任务中,其输入的值通常为语音特征。而在crnn模型中,rnn模型的输入则为图像特征;cnn模型与rnn模型的结合,使得网络既提取了文本图片的鲁棒特征,又结合了序列识别,极大程度上解决了传统算法在做文字识别时需要对字符串先进行单字符切割的难题。
16.作为本发明的优选技术方案,所述步骤s3后处理的具体步骤包括:
17.s31对模型预测结果进行分词:首先对所述步骤s2中的模型预测结果根据词性采用分词算法进行分词,获得列表l;
18.s32判断可疑词语:所述步骤s31中获得的列表l中的每个元素为一个词或一个字符,通过遍历列表l中的每个元素来判断是否存可疑词语,若存在可疑词语,则用候选字符进行替换并更正可疑词语。
19.作为本发明的优选技术方案,所述步骤s31采用分词算法进行分词的具体步骤为:
20.s311:基于trie树,生成句子中所有词可构成的dag,dag是有向无环图;在建立好trie树之后,进行查词操作,即可对待分词的句子找出全部可能的句子进行切分,生成dag;其中,生成的dag的健为起始字符的位置,值为一个列表,列表中的每个元素都代表结束词的位置,表示以健起,以列表中的元素x结束的词是词典中存在的词语;
21.s312:动态规划求出最大概率的分词路径;在得到所有可能的切分方式构成的有向无环图后,能够发现从起点到终点存在多条路径,即存在多种分词结果;因此采用动态规划计算最大概率路径;首先初始化路径route,从句子最右侧开始,加入当前词语,判断当前词语是否使分词路径的概率p变大,若变大,则把该词语和p加入到路径route中,故在计算最大概率路径时每到达一个节点,该节点前面的节点到终点的最大路径概率则已经计算出。其中采用动态规划计算最大概率路径的具体过程是:
22.s3121:初始化参数;
23.route={};
24.n=len(sentence);
25.route[n]=(0,0);
[0026]
logtotal=0;
[0027]
s3122:从句子最右侧开始计算;
[0028]
elements=dag[当前字符的位置];
[0029]
max=-inf;
[0030]
maxelement=none;
[0031]
for element in elements:
[0032]
通过route计算从当前字符到element的路径概率p:
[0033]
p=log(frequence(当前字符到element构成的词))-logtotal route[element的下一个位置][0]
[0034]
if p》max:max=p,maxelement=element;
[0035]
route[当前字符的位置]=(max,maxelement)。
[0036]
作为本发明的优选技术方案,所述步骤s32中通过遍历列表l中的每个元素来判断是否存可疑词语具体步骤为:
[0037]
s321:创建一个词频字典freq,字典的键为词或字符,freq对应的值为该词/字符出现的频率;
[0038]
s322:从左至右遍历列表l中的每个元素,若存在可疑词语,则用候选字符进行替换并更正可疑词语;
[0039]
s3221:若该元素为一个字符,则判断其是否符合判断条件中的任一条,若符合判断条件,则将该字符与下一个元素和下一个元素之后的下一元素分别进行临时合并形成临时词组,查找合并后的临时词组是否出现在词频字典freq中,若临时词组存在词频字典freq中,则在预测结果中添加频率高的组合,并将列表l更新为临时合并的结果;若临时词组不存在词频字典freq中,则根据候选词更正组合形成更正词组,再次判断更正组合词是否出现在词频字典freq中,若更正词组存在词频字典freq中,存在则在预测结果中添加频率高的组合;若更正词组不存在词频字典freq中,则拆分临时合并的临时词组并在结果中添加该字符;
[0040]
s3222:若该元素不是一个字符;则判断其是否出在词频字典freq中;若词频字典freq中存在该元素,则在结果中添加频率高的组合;若词频字典freq中不存在该元素,则根据候选词更正组合,再次判断更正组合是否出现在词频字典中,若存在则在预测结果中添加频率高的组合;若词频字典freq中不存在该元素,在预测结果中添加该元素。
[0041]
作为本发明的优选技术方案,所述步骤s3221中的所述判断条件包括:不在词频字典freq中、在词频字典freq中但频率低和该字符的词性不为数词。
[0042]
作为本发明的优选技术方案,所述步骤s322中根据候选词更正组合时通过模型预测结果进行候选词筛选,具体过程为:一张图片经过模型处理后预测出了m个序列,其中每个序列有n个值,n=字符种类;每个值代表该序列预测为字符k的概率,在这些概率中筛选出前n个概率最高的值,记录这n个概率值对应的字符,作为该序列的全部候选字符。
[0043]
作为本发明的优选技术方案,所述步骤s11笔画提取具体包括以下步骤:
[0044]
s111外接矩形框坐标提取:首先通过行列信息提取与外接矩形框定位对文本行的外接矩形框进行定位;
[0045]
s1111行列信息提取:遍历图像每一行,记录该行是否95%的像素点均为黑色背景,若是,记录改行信息为true,否则为false;遍历图像每一列,记录该行是否为95%的像
素点均为黑色背景,若是,记录改列信息为true,否则为false;
[0046]
s1112外接矩形框定位:通过步骤s1111取得图像所有行列信息后,对行列信息进行分析,获取外接矩形框坐标;即最右边界为列信息第一个为false的列;最左边界为列信息最后一个为false的列;最上边界为行信息第一个为false的行;最下边界为行信息最后一个为false的行,从而获得外接矩形框;
[0047]
s112笔画粗提取:获得外接矩形框后,从框内左上角第一个像素点开始逐点遍历,对于某待遍历点,将其加入一个新的联通像素点列表中,循环遍历联通像素点列表,对于列表中的每个点p,查看p点上下左右四个相邻点,若相邻点不是像素值为(0,0,0)的黑色背景点,则将该相邻点加入联通像素点列表中,p点四个相邻点检查完毕后,删除联通像素列表中的p点,继续循环联通像素点列表,直至列表未空,从而获得笔画像素联通区域;其中笔画粗提取的流程为:
[0048]
for x in range(left,right):
[0049]
for y in range(top,low):
[0050]
联通像素列表=[(x,y),]
[0051]
联通像素列表copy=[]
[0052]
while联通像素列表不为空:
[0053]
向联通像素列表copy中添加(x,y)
[0054]
联通像素列表删除(x,y)
[0055]
检查(x,y)点上下左右方向的四个点,将非背景点添加至联通像素列表返回联通像素列表copy。
[0056]
与现有技术相比,本发明具有的有益效果是:该基于笔画扰动与后处理的手写文字识别模型性能的提升方法通过笔画扰动提升数据集的多样性,再进行模型训练,再通过后处理方法,可以有效提升文本行准确率,尤其是对一些较为模糊或尺寸较小的图片,有良好的提升效果。
附图说明
[0057]
下面结合附图进一步描述本发明的技术方案:
[0058]
图1是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法的现有技术中关于字符识别准确率往往高于文本行识别的准确率的示意图;
[0059]
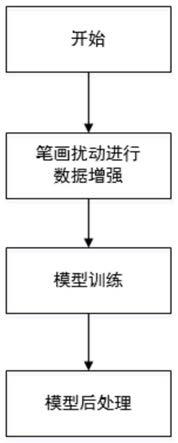
图2是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法的流程图;
[0060]
图3是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s11中的外接矩形框坐标提取方法的流程图;
[0061]
图4是采用图3中的外接矩形框坐标提取方法进行外接矩形框提取的效果图;其中(a)为原始手写字体图片,(b)为外接矩形框提取的效果图;
[0062]
图5是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s12中获得像素联通区域的效果图;
[0063]
图6是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s12进行笔画扰动的效果图;图(a)为未做数据增强的数据集,图(b)为已做数据增强的
数据集;
[0064]
图7是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s2中模型结构图;
[0065]
图8是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s31中的词性标注示意图;
[0066]
图9是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s31中trie树示意图;
[0067]
图10是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s31中dag结果的效果图;
[0068]
图11是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的步骤s32中进行候选词筛选时的列表示意图;
[0069]
图12是本发明的基于笔画扰动与后处理的手写文字识别模型性能的提升方法中的预测结果展示图。
具体实施方式
[0070]
为了加深对本发明的理解,下面将结合附图和实施例对本发明做进一步详细描述,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。
[0071]
实施例:如图2所示,该基于笔画扰动与后处理的手写文字识别模型性能的提升方法,具体包括以下步骤:
[0072]
s1基于笔画扰动的手写体数据集的制作:首先通过笔画提取,获得笔画像素联通区域,再对连通区域内的笔画进行笔画扰动,从而获得具有多样性的手写体数据集;所述步骤s1具体包括以下步骤:
[0073]
s11笔画提取:首先找到文本行的外接矩形框,其次从外接矩形框的第一个像素点开始分别向上、下、左、右四个方向进行遍历,寻找像素点的联通像素点,从而获得笔画像素联通区域;所述步骤s11笔画提取具体包括以下步骤:
[0074]
s111外接矩形框坐标提取:首先通过行列信息提取与外接矩形框定位对文本行的外接矩形框进行定位;以黑纸白字的文本行为例,在rgb图像三通道中,像素点的值均为0,则为黑色背景,否则为白色字迹;具体流程如图3所示,
[0075]
s1111行列信息提取:遍历图像每一行,记录该行是否95%的像素点均为黑色背景,若是,记录改行信息为true,否则为false;遍历图像每一列,记录该行是否为95%的像素点均为黑色背景,若是,记录改列信息为true,否则为false;
[0076]
s1112外接矩形框定位:通过步骤s1111取得图像所有行列信息后,对行列信息进行分析,获取外接矩形框坐标;即最右边界为列信息第一个为false的列;最左边界为列信息最后一个为false的列;最上边界为行信息第一个为false的行;最下边界为行信息最后一个为false的行,从而获得外接矩形框,如图4所示,图(b)中的白色框为外接矩形框;
[0077]
s112笔画粗提取:获得外接矩形框后,从框内左上角第一个像素点开始逐点遍历,对于某待遍历点,将其加入一个新的联通像素点列表中,循环遍历联通像素点列表,对于列表中的每个点p,查看p点上下左右四个相邻点,若相邻点不是像素值为(0,0,0)的黑色背景点,则将该相邻点加入联通像素点列表中,p点四个相邻点检查完毕后,删除联通像素列表
中的p点,继续循环联通像素点列表,直至列表未空,从而获得笔画像素联通区域,如图5所示;
‘
旧’被分为两个像素连通区域,同一颜色代表在同一个像素联通区域:
[0078]
其中笔画粗提取的流程为:
[0079]
for x in range(left,right):
[0080]
for y in range(top,low):
[0081]
联通像素列表=[(x,y),]
[0082]
联通像素列表copy=[]
[0083]
while联通像素列表不为空:
[0084]
向联通像素列表copy中添加(x,y)
[0085]
联通像素列表删除(x,y)
[0086]
检查(x,y)点上下左右方向的四个点,将非背景点添加至联通像素列表返回联通像素列表copy;
[0087]
s12笔画扰动:在获得笔画像素联通区域后,对笔画像素联通区域内的字体笔画进行笔画扰动,扰动方法包括旋转、畸变和位置偏移,获得多样性的手写字体,并存入手写字体数据集;其中扰动的角度不易过大,否则会出现笔画重叠严重的问题,导致字迹不易被辨别;如图6所示,其中图(a)为未做数据增强的数据集,图(b)为已做数据增强的数据集;图(b)由于扰动角度过大,导致有些字迹较难辨认;以框中的
‘
败’为例,做过干扰后,图b中的
‘
败’的部首已经出现严重的变形;
[0088]
s2模型训练:将步骤s1中获得的手写体数据集采用文本识别模型(如图7所示)进行训练,提取文本图片的特征,并获得模型预测结果;所述步骤s2模型训练采用卷积循环神经网络crnn,所述卷积循环神经网络的结构包括卷积层、循环网络层和转录层;所述卷积层采用vgg16的结构,对输入的图片进行特征图的提取;所述循环网络层采用三层bilstm;所述转录层采用ctc算法,将rnn模型预测出的标签转换成预测结果,从而获得模型预测结果;rnn模型多用于自然语言处理(nlp),它被广泛应用于建立语言模型和语音识别任务中,其输入的值通常为语音特征。而在crnn中,rnn的输入则为图像特征;cnn与rnn的结合,使得网络既提取了文本图片的鲁棒特征,又结合了序列识别,极大程度上解决了传统算法在做文字识别时需要对字符串先进行单字符切割的难题;
[0089]
s3后处理:对模型预测结果进行分词,再判断是否存在可疑词语,若存在可疑词语,则用候选字符进行替换并更正可疑词语,从而获得预测结果;所述步骤s3后处理的具体步骤包括:
[0090]
s31对模型预测结果进行分词:首先对所述步骤s2中的模型预测结果根据词性采用分词算法进行分词,获得列表l;中文分词指的是将一个汉字序列切分成一个一个单独的词;分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。词是语义完整的最小语言单位,词性标注如图8所示;
[0091]
s32判断可疑词语:所述步骤s31中获得的列表l中的每个元素为一个词或一个字符,通过遍历列表l中的每个元素来判断是否存可疑词语,若存在可疑词语,则用候选字符进行替换并更正可疑词语;
[0092]
所述步骤s31采用分词算法进行分词的具体步骤为:
[0093]
s311:基于trie树,trie是前缀树,也叫单词查找树。几个词语如果前面的几个字
相同就是具有相同的前缀;将词典中的词条放入trie树中,即可利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希表高;以北京,北京大学,北航,大连,大连理工这几个词为例,构造的trie树的结构如图9所示;生成句子中所有词可构成的dag,dag是有向无环图;在建立好trie树之后,进行查词操作,即可对待分词的句子找出全部可能的句子进行切分,生成dag;其中,生成的dag的健为起始字符的位置,值为一个列表,列表中的每个元素都代表结束词的位置,表示以健起,以列表中的元素x结束的词是词典中存在的词语;以句子“小明去北京大学读书”为例,这句话对应生成的dag结果为:{0:[0],1:[1],2:[2],3:[3,4,6],4:[4],5:[5,6],6:[6],7:[7,8],8:[8]},如图10所示;
[0094]
其中,
‘
3:[3,4,6]’表示:以句子中第三位
‘
北’为起始词,针对这句话,字典中出现了如下可以匹配的词语:
‘
北’,
‘
北京’,
‘
北京大学’。而对于句子中第0位的
‘
小’,没有前缀,只有一种划分方式。
[0095]
s312:动态规划求出最大概率的分词路径;在得到所有可能的切分方式构成的有向无环图后,能够发现从起点到终点存在多条路径,即存在多种分词结果;需要注意的是,在汉语中,从右向左计算得到的结果通常比从左向右计算的到的结果好;这是因为汉语的重心往往偏向后面;因此采用动态规划计算最大概率路径;首先初始化路径route,从句子最右侧开始,加入当前词语,判断当前词语是否使分词路径的概率p变大,若变大,则把该词语和p加入到路径route中,故在计算最大概率路径时每到达一个节点,该节点前面的节点到终点的最大路径概率则已经计算出,从而获得一个分词列表l;其中采用动态规划计算最大概率路径的具体过程是:
[0096]
s3121:初始化参数;
[0097]
route={};
[0098]
n=len(sentence);
[0099]
route[n]=(0,0);
[0100]
logtotal=0;
[0101]
s3122:从句子最右侧开始计算;
[0102]
elements=dag[当前字符的位置];
[0103]
max=-inf;
[0104]
maxelement=none;
[0105]
for element in elements:
[0106]
通过route计算从当前字符到element的路径概率p:
[0107]
p=log(frequence(当前字符到element构成的词))-logtotal route[element的下一个位置][0]
[0108]
if p》max:max=p,maxelement=element;
[0109]
route[当前字符的位置]=(max,maxelement);
[0110]
所述步骤s32中通过遍历列表l中的每个元素来判断是否存可疑词语具体步骤为:
[0111]
s321:创建一个词频字典freq,字典的键为词或字符,freq对应的值为该词/字符出现的频率;如:freq[
‘
北京大学’]=2507;
[0112]
s322:从左至右遍历列表l中的每个元素,若存在可疑词语,则用候选字符进行替
换并更正可疑词语;
[0113]
s3221:若该元素为一个字符,则判断其是否符合判断条件中的任一条,若符合判断条件,则将该字符与下一个元素和下一个元素之后的下一元素分别进行临时合并形成临时词组,查找合并后的临时词组是否出现在词频字典freq中,若临时词组存在词频字典freq中,则在预测结果中添加频率高的组合,并将列表l更新为临时合并的结果;若临时词组不存在词频字典freq中,则根据候选词更正组合形成更正词组,再次判断更正组合词是否出现在词频字典freq中,若更正词组存在词频字典freq中,存在则在预测结果中添加频率高的组合;若更正词组不存在词频字典freq中,则拆分临时合并的临时词组并在结果中添加该字符;所述步骤s3221中的所述判断条件包括:不在词频字典freq中、在词频字典freq中但频率低和该字符的词性不为数词;
[0114]
s3222:若该元素不是一个字符;则判断其是否出在词频字典freq中;若词频字典freq中存在该元素,则在结果中添加频率高的组合;若词频字典freq中不存在该元素,则根据候选词更正组合,再次判断更正组合是否出现在词频字典中,若存在则在预测结果中添加频率高的组合;若词频字典freq中不存在该元素,在预测结果中添加该元素;所述步骤s322中根据候选词更正组合时通过模型预测结果进行候选词筛选,具体过程为:一张图片经过模型处理后预测出了m个序列,其中每个序列有n个值,n=字符种类;每个值代表该序列预测为字符k的概率,在这些概率中筛选出前n个概率最高的值,记录这n个概率值对应的字符,作为该序列的全部候选字符;对于可以词可根据候选词来进行更正,候选词的选择与常用的通过平均编辑距离筛选的方式有所不同。平均编辑距离是指将预测结果转换成真实结果所需的最少的编辑次数;其中编辑方式包括替换字符、插入字符、删除字符,但从海量的词典中筛选出平均编辑距离较近的候选词是十分耗时的,因此本发明选择方法可以节省时间,从而提高效率。如图11所示;该图片经过模型预测的结果为
‘
北京影讯通物流有限公可’,b步骤判断出的可疑词为
‘
公可’。通过第9,10两个列表的排列组合,筛选出的候选词有:['公可','公肓','公司','公育','公百','企可','企肓','企司','企育','企百','岔可','岔肓','岔司','岔育','岔百','.可','.肓','.司','.育','.百','么可','么肓','么司','么育','么百']。经过筛选,词频最高的为
‘
公司’,将可疑此替换后,最终的预测结果为:
‘
北京影讯通物流有限公司’。
[0115]
如图12所示,从该基于笔画扰动与后处理的手写文字识别模型性能的提升方法的效果展示图中可以看出,该方法有效提升文本行准确率,尤其是对一些较为模糊或尺寸较小的图片,有良好的提升效果。
[0116]
对于本领域的普通技术人员而言,具体实施例只是对本发明进行了示例性描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的方法构思和技术方案进行的各种非实质性的改进,或未经改进将本发明的构思和技术方案直接应用于其它场合的,均在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。